文章目录
- 前言
- 一、工作原理
- 二、追踪执行流程
- 三、追踪定时信息
- 四、perf使用 intel pt
- 4.1 perf record
- 4.2 perf report
- 4.3 perf script
- 五、与 Intel LBR 比较
- 六、perf 对 Intel pt 的支持
- 参考资料
前言
代码插装是最古老的性能分析方法之一。我们经常使用它。在函数开头插入printf语句来统计函数调用次数,这是一种最简单、最精确和详细的分析应用性能的技术。然而,代码插装也有严重的缺点。特别是,它会引入较大的开销,并且每次想要统计不同的内容时都需要重新编译应用程序。如今,人们不经常使用手动代码插装了。然而,在自动化代码插装仍然被使用,例如在PGO(Profile-Guided Optimization,基于剖析的优化)中。
自动化代码插装技术解决了这些问题。它们通过修改代码或使用专门的工具自动进行代码插装,而无需手动干预。这样可以更高效、更灵活地进行性能分析。比如PGO,它使用代码插装来收集运行时信息,并在编译过程中使用这些信息来指导优化。
自动化代码插装相对于手动插装具有几个优势:
减少开销:自动化插装技术旨在最大程度地减少对应用程序性能的影响。它们通常使用轻量级机制来收集数据,例如采样或统计分析,以在不显著影响执行时间的情况下获取性能信息。
动态分析:自动化插装技术可以提供运行时分析能力,允许实时收集性能数据或在特定场景下进行分析。这使得我们可以更深入地了解应用程序在不同条件下的行为。
灵活性:通过自动化插装,可以轻松修改性能分析参数或指标,而无需修改源代码。这种灵活性使得性能分析更加全面和适应性强,无需重新编译应用程序。
多年来,出现了许多新的性能分析方法。其中一种方法是基于中断的方法(PMI)。最简单的理解方式是使用调试器,每隔一秒钟暂停程序并记录停止的位置,这样可以得到一系列样本,告诉你程序花费时间最多的地方。这是对性能分析工具所做的过于简化的描述。你可以在“PMU counters and profiling basics”和“Basics of profiling with perf”中了解更多关于底层机制的内容。
但这并不是我们所拥有的全部方法。在本文中,我想介绍一项革命性的技术,它可以在不中断程序执行的情况下进行性能分析。这项技术被称为Intel Processor Trace(PT)。它具有追踪的特性,在某种程度上类似于Linux的跟踪工具,如ftrace/strace等。
那么,Intel PT是什么呢?它是一种CPU追踪功能,通过以非常压缩的格式编码数据包来记录程序的执行过程。它具有广泛的覆盖范围,而且开销相对较小,约为5%左右。它的主要用途是进行事后分析和找出性能故障的根本原因。
PT开销:
对于计算密集型应用程序(compute-bound application),性能开销可能来自于大量的分支语句,这会导致需要记录更多的数据。
对于内存密集型应用程序(memory-bound application),性能开销可能来自于PT将大量数据推送到DRAM中的事实。
这两种情况下,使用Intel PT进行性能分析都可能引入一定的开销。对于计算密集型应用程序,由于分支语句较多,需要记录的数据量较大,因此可能会对应用程序的执行时间产生一定的影响。对于内存密集型应用程序,PT将大量数据推送到DRAM中,这可能会导致内存带宽的压力增加,从而对应用程序的内存访问性能产生一定的影响。
一、工作原理
使用处理器跟踪的工具时,只需在其下运行程序即可。一旦启用处理器跟踪,软件工具开始将数据包写入DRAM(动态随机存取存储器)。与LBR(上次分支记录器)非常相似,英特尔的处理器跟踪通过记录分支来工作。当CPU在运行时遇到指令时,会记录该分支的情况。对于一个简单的条件跳转指令,CPU会记录它是否被执行。CPU只使用一个位来进行记录。
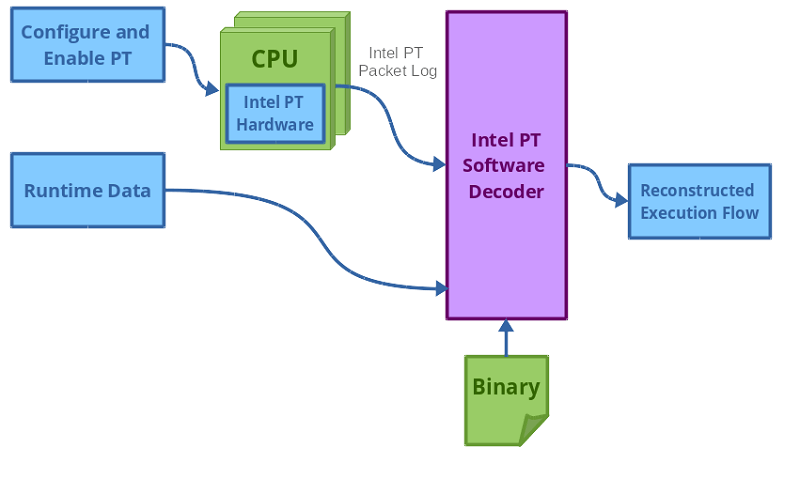
然后,CPU将高度压缩的程序跟踪以二进制形式存储在DRAM中。当我们进行分析时,需要将收集到的处理器跟踪和应用程序二进制文件结合起来。应用程序二进制文件由软件解码器使用,以重构程序的执行流程。程序的入口点是程序开始的地方,然后它利用收集到的所有跟踪作为查找参考,确定控制流程。即使使用了压缩格式的跟踪,处理大量数据仍然是一项挑战。
重构程序的执行流程时:
对于用户空间的执行流程需用该应用程序的二进制文件。
对于内核空间的执行流程需要用到 /proc/kcore 文件。
软件解码器结合包与其他信息(程序二进制文件/ /proc/kcore)还原程序原本控制流:需要将IPT包与程序二进制结合解码还原完整控制流才能与传统CFG比对。
二、追踪执行流程
与采样技术类似,Intel PT也不需要对源代码进行任何修改。只需要在启用了PT的工具下运行程序,就可以收集追踪信息。一旦启用了PT,软件工具就会开始将数据包写入DRAM。类似于LBR(Last Branch Record),Intel PT通过记录分支信息来工作。
Intel PT通过记录程序执行期间的分支信息来获取追踪数据。它使用一种被称为"packet"的数据结构来编码这些分支信息,将其存储在DRAM中。这些数据包包含了程序执行期间的分支目标地址、分支类型以及其他相关信息。通过解析这些数据包,可以还原程序的执行流程,并进行性能分析、调试或根因分析。
在运行时,每当CPU遇到任何分支指令(如je、call、ret),它都会记录该分支的执行情况。对于简单的条件跳转指令,CPU会使用1位来记录是否跳转(T)或不跳转(NT)。对于间接调用指令,CPU将记录目标地址。需要注意的是,无条件跳转指令会被忽略,因为我们在静态分析中已经知道它们的目标地址。比如:
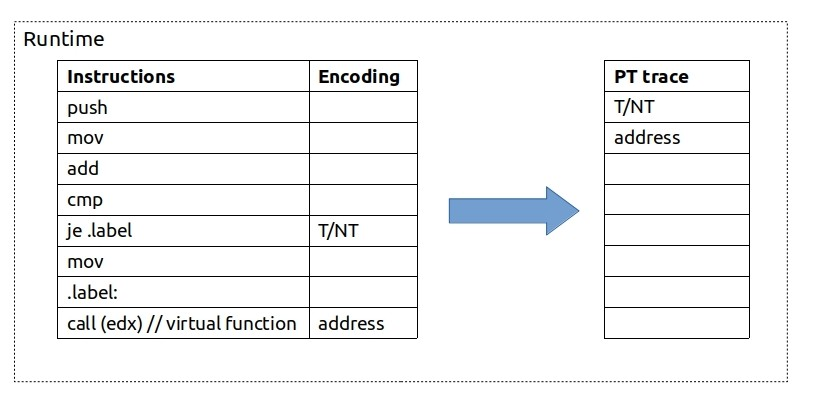
上述 je.labe就是条件跳转,使用1为来记录是否跳转(T)或不跳转(NT)。
call (edx) 就是间接跳转,间接跳转的起始地址我们可以从二进制源代码静态分析获取,只需要获取其目的地址address。
一旦CPU遇到分支指令并记录相关信息,Intel PT追踪数据以高度压缩的二进制形式存储在DRAM(动态随机存取存储器)中。
通过压缩,可以减少追踪数据所需的存储空间,从而有效地利用内存资源。
以二进制格式存储的压缩PT追踪数据包含了重构程序执行流程和分析其性能特征所需的必要信息。它包括分支目标、分支类型、是否跳转、以及其他相关元数据等细节。
在进行分析时,我们将应用程序的二进制文件和收集到的PT追踪数据结合在一起。软件解码器需要应用程序的二进制文件,以便重构程序的执行流程。它从程序的入口点开始,并使用收集到的追踪数据作为查找参考来确定控制流程。
通过将应用程序的二进制文件与PT追踪数据结合使用,可以还原程序的执行路径和分支跳转情况。软件解码器根据PT追踪数据中记录的分支信息,将其映射到应用程序的二进制指令,并根据分支是否被执行来确定程序的控制流。这样可以重现程序的执行过程,帮助进行性能分析、调试和优化。
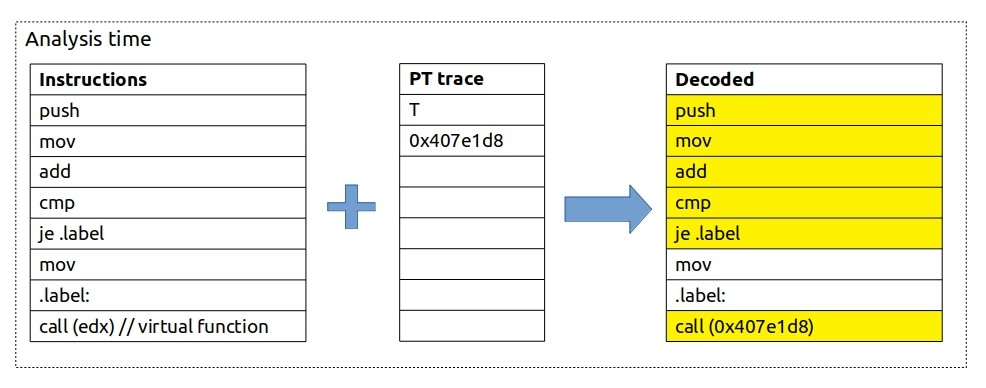
T代表跳转,可以看到解码后可以还原出程序的执行过程(跳过了mov指令),并获取到了间接跳转的目的地址。
注意,这是指令流程的精确重构。
即使考虑到追踪数据的压缩格式,数据量仍然很大。通常情况下,每条指令的编码数据只占用不到1字节的空间。因此,准备好至少具备每秒100MB的编码数据处理能力。在解码后,数据量可能增加到原来的10倍(约1GB/s)。这使得它在长时间运行的工作负载下难以使用。但是,在大型工作负载上,您可以仅在小时间段内运行它。因此,典型的用例可能与性能分析不同,而是在出现故障的时间段内附加到进程上。或者使用循环缓冲区,其中新的追踪数据将覆盖旧的数据,即始终保留最近约10秒的追踪数据。
如果这听起来数据量太大难以处理,您可以通过多种方式限制数据收集。您可以仅在用户/内核空间代码上收集追踪数据。此外,您还可以根据地址范围进行过滤,以便选择性地启用和禁用追踪,以限制带宽。这样可以仅追踪单个函数甚至单个循环。
还请记住,解码本身也需要一些时间。举个具体的例子,在我的Intel Core i5-8259U机器上,对于运行时间为7毫秒的工作负载,编码的PT追踪数据大约占用1MB的空间。使用 perf script对此追踪数据进行解码需要大约20秒的时间。
perf script的解码输出(perf script -F time,ip,sym,symoff,insn)占用约1.3GB的磁盘空间。
三、追踪定时信息
不仅可以追踪执行的流程,还可以追踪定时信息。

首先,我们可以看到jnz指令未被执行,所以我们将它和上面的所有指令的时间戳更新为0纳秒。然后,我们看到一个时间更新为2纳秒,并且je指令被执行,所以我们将它和je指令上面(以及jnz指令下面)的所有指令的时间戳更新为2纳秒。接下来是一个间接调用指令,但没有附加时间数据包,所以我们不会更新时间戳。然后,我们发现经过了100纳秒,并且jb指令未被执行,所以我们将jb指令上面的所有指令的时间戳更新为102纳秒。
从这个例子中可以看出,指令数据(控制流程)是完全准确的,但定时信息不够准确。显然,call (edx)、test和jb指令并不是同时发生的,但我们没有更好的定时信息来表示它们的时间。
具有时间戳信息非常重要,因为它允许将我们的程序的时间间隔与系统中的其他事件对齐,并且很容易与墙上时钟时间进行比较。
实际上(自Skylake以来),定时数据包中包含了与上一个数据包相隔的周期数。所有的定时信息都以单独的数据包发送。
四、perf使用 intel pt
使用 Linux perf tool(Linux 4.2 主线支持 perf intel pt)可以轻松收集英特尔PT跟踪:
perf-intel-pt - Support for Intel Processor Trace within perf tools
# perf list | grep intel_ptintel_pt// [Kernel PMU event]
4.1 perf record
perf record -e intel_pt/cyc=1/u ls
跟踪 shell ls命令 数据是通过perf record命令进行收集,并存储在perf.data文件中。
Intel PT内核驱动程序创建了一个新的PMU(性能监控单元)用于Intel PT。通过提供PMU名称,后面跟着由斜杠分隔的"config"来选择PMU事件。
这里选择 intel_pt PMU event。
请注意,与所有事件一样,事件后缀带有事件修饰符:
u 表示用户空间(userspace)事件。
k 表示内核空间(kernel)事件。
通过在事件名称后面添加这些修饰符,可以指定事件所属的执行上下文,即用户空间或内核空间。这样可以更精确地选择要跟踪的事件类型。例如,使用-e intel_pt/u将选择在用户空间中发生的Intel PT事件,而-e intel_pt/k将选择在内核空间中发生的Intel PT事件。
这里选择u表示之跟踪shell ls命令的用户态数据。
在这个例子中,我要求每个周期更新定时信息。但是很可能这样做并不能显著提高准确性,因为定时数据包只在与其他控制流数据包配对时发送。
NAMEperf-record - Run a command and record its profile into perf.dataSYNOPSISperf record [-e <EVENT> | --event=EVENT] [-a] <command>perf record [-e <EVENT> | --event=EVENT] [-a] — <command> [<options>]DESCRIPTIONThis command runs a command and gathers a performance counter profile from it, into perf.data - without displaying anything.
-e, --event=Select the PMU event.
4.2 perf report
之后,PT的原始编码(the raw encoding)可以这样获得:
perf report -D > trace.dump
NAMEperf-report - Read perf.data (created by perf record) and display the profileSYNOPSISperf report [-i <file> | --input=file]DESCRIPTIONThis command displays the performance counter profile information recorded via perf record.
-D, --dump-raw-traceDump raw trace in ASCII.
如果我们查看trace.dump,我们可能会看到以下内容:
. ... Intel Processor Trace data: size 92208 bytes
. 00000000: 02 82 02 82 02 82 02 82 02 82 02 82 02 82 02 82 PSB
. 00000010: 00 00 00 00 PAD
. 00000014: ef 08 CYC 0x9d
. 00000016: 19 f4 50 36 c4 7c 9a 30 TSC 0x309a7cc43650f4
. 0000001e: 00 00 00 00 00 00 00 00 PAD
. 00000026: 02 73 2e 71 00 00 00 00 TMA CTC 0x712e FC 0x0
. 0000002e: 00 00 PAD
. 00000030: 07 02 CYC 0x20
. 00000032: 59 26 MTC 0x26
. 00000034: 02 03 09 00 CBR 0x9
. 00000038: 02 23 PSBEND
. 0000003a: 67 12 CYC 0x12c
. 0000003c: 59 27 00 00 MTC 0x27
. 00000040: 57 12 CYC 0x12a
. 00000042: 59 28 MTC 0x28
. 00000044: 67 12 CYC 0x12c
......
(1)Taken Not-Taken (TNT) 数据包:
. 00000a55: 6f 04 CYC 0x4d
. 00000a57: 96 TNT NNTNTT (6)
. 00000a58: f7 02 CYC 0x3e
. 00000a5a: 0e TNT TT (2)
. 00000a5b: 2f 02 CYC 0x25
. 00000a5d: 59 9d MTC 0x9d
. 00000a5f: 3b CYC 0x7
. 00000a60: d4 TNT TNTNTN (6)
正如您所看到的,PT将在发出定时数据包之前捆绑多达6个条件分支。
(2)Target IP (TIP) 数据包:
. 00000917: 71 00 d1 0f 53 8f 7f 00 TIP.PGE 0x7f8f530fd100
. 0000091f: 00 PAD
. 00000920: 67 06 CYC 0x6c
. 00000922: 59 5c MTC 0x5c
. 00000924: 67 12 CYC 0x12c
. 00000926: 59 5d MTC 0x5d
目标地址:0x7f8f530fd100
(3)Flow Update Packets (FUP):
. 00000937: 7d 00 d1 0f 53 8f 7f 00 FUP 0x7f8f530fd100
. 0000093f: 00 PAD
. 00000940: 57 06 CYC 0x6a
. 00000942: 01 TIP.PGD no ip
. 00000943: 07 0c CYC 0xc0
. 00000945: 59 60 00 MTC 0x60
. 00000948: 67 12 CYC 0x12c
源地址:0x7f8f530fd100
4.3 perf script
NAMEperf-script - Read perf.data (created by perf record) and display trace output
用perf工具将原始的跟踪信息解析为函数调用流。
默认情况下,perf script将解码在perf.data文件中找到的跟踪数据。这可以进一步通过新选项–itrace进行控制。
新的–itrace选项:
如果没有指定选项,相当于使用以下选项:
--itrace
–itrace 是用于解码指令跟踪数据的选项。以下是可用的选项说明:
i:合成指令事件(synthesize instructions events)。
b:合成分支事件(synthesize branches events)。
c:合成分支事件(仅限调用)(synthesize branches events (calls only))。
r:合成分支事件(仅限返回)(synthesize branches events (returns only))。
x:合成事务事件(synthesize transactions events)。
w:合成ptwrite事件(synthesize ptwrite events)。
p:合成功耗事件(synthesize power events)。
o:合成由于使用 aux-output(参考 perf record)而记录的其他事件(synthesize other events recorded due to the use of aux-output)。
e:合成错误事件(synthesize error events)。
d:创建调试日志(create a debug log)。
g:合成调用链(与i或x一起使用)(synthesize a call chain (use with i or x))。
l:合成最后分支条目(与i或x一起使用)(synthesize last branch entries (use with i or x))。
s:跳过初始事件数量(skip initial number of events)。
默认情况下,所有事件都会被合成,即与–itrace=ibxwpe相同,但在perf script中默认为–itrace=ce。
要完全禁用解码,使用 --no-itrace。
即默认情况下perf script 使用了–itrace选择,用于解码指令跟踪数据。
perf script -i perf.data > script_out.txt
ls 2856758 [000] 3800166.501290: 1 branches:uH: 7f8f530fd100 _start+0x0 (/usr/lib/x86_64-linux-gnu/ld-2.31.so) => 0 [unknown] ([unknown])
ls 2856758 [000] 3800166.501302: 1 branches:uH: 7f8f530fd103 _start+0x3 (/usr/lib/x86_64-linux-gnu/ld-2.31.so) => 7f8f530fddf0 _dl_start+0x0 (/usr/lib/x86_64-linux-gnu/ld-2.31.so)
ls 2856758 [000] 3800166.501303: 1 branches:uH: 7f8f530fde18 _dl_start+0x28 (/usr/lib/x86_64-linux-gnu/ld-2.31.so) => 0 [unknown] ([unknown])
ls 2856758 [000] 3800166.501311: 1 branches:uH: 7f8f530fe128 _dl_start+0x338 (/usr/lib/x86_64-linux-gnu/ld-2.31.so) => 0 [unknown] ([unknown])
ls 2856758 [000] 3800166.501316: 1 branches:uH: 7f8f530fdff9 _dl_start+0x209 (/usr/lib/x86_64-linux-gnu/ld-2.31.so) => 7f8f531090b0 _dl_setup_hash+0x0 (/usr/lib/x86_64-linux-gnu/ld-2.31.so)
ls 2856758 [000] 3800166.501316: 1 branches:uH: 7f8f530fe047 _dl_start+0x257 (/usr/lib/x86_64-linux-gnu/ld-2.31.so) => 7f8f53118700 _dl_sysdep_start+0x0 (/usr/lib/x86_64-linux-gnu/ld-2.31.so)
ls 2856758 [000] 3800166.501317: 1 branches:uH: 7f8f53118700 _dl_sysdep_start+0x0 (/usr/lib/x86_64-linux-gnu/ld-2.31.so) => 0 [unknown] ([unknown])
ls 2856758 [000] 3800166.501327: 1 branches:uH: 7f8f53118737 _dl_sysdep_start+0x37 (/usr/lib/x86_64-linux-gnu/ld-2.31.so) => 0 [unknown] ([unknown])
ls 2856758 [000] 3800166.501335: 1 branches:uH: 7f8f5311881a _dl_sysdep_start+0x11a (/usr/lib/x86_64-linux-gnu/ld-2.31.so) => 0 [unknown] ([unknown])
ls 2856758 [000] 3800166.501342: 1 branches:uH: 7f8f53118a96 _dl_sysdep_start+0x396 (/usr/lib/x86_64-linux-gnu/ld-2.31.so) => 7f8f53116050 __GI___tunables_init+0x0 (/usr/lib/x86_64-linux-gnu/ld-2.31.so)
ls 2856758 [000] 3800166.501352: 1 branches:uH: 7f8f53118a9d _dl_sysdep_start+0x39d (/usr/lib/x86_64-linux-gnu/ld-2.31.so) => 7f8f53119f40 brk+0x0 (/usr/lib/x86_64-linux-gnu/ld-2.31.so)
......
从上面我们可以看到 shell ls 在用户态的指令执行流。
五、与 Intel LBR 比较
与Intel LBR相比,Intel PT在跟踪程序的基本块(Basic Block)方面并不像LBR那样 – 不跟踪无条件直接跳转输出。如果PT机制要跟踪每个分支,这将增加很大的开销。
LBR只能获取已经执行的分支的时间信息,而PT则对条件分支进行编码,不受分支是否执行的影响。
LBR的堆栈只能记录最近的32个已执行分支,而Intel PT可以收集无限深度的调用堆栈。
Intel PT产生的数据比LBR要多得多,解码这些数据可能需要一些时间。
Intel PT不依赖于PMI中断(Precise Machine Interrupt),而其他PerfMon功能如PEBS和LBR则会使用PMI中断。这使得Intel PT在实时系统中更加有用,因为你无需中断CPU即可获取数据。这无疑是从使用PMI跟踪转向了一种新的方式。
六、perf 对 Intel pt 的支持
Linux4.2主线perf pt增加的相关内容:
Add Instruction Tracing support (--itrace)
(1)
perf script: Add Instruction Tracing support
Add support for decoding an AUX area assuming it contains instruction tracing data.
(2)
perf report: Add Instruction Tracing support
Add support for decoding an AUX area assuming it contains instruction tracing data.
AUX area在perf工具中提供了一种机制,指的是"辅助空间"(Auxiliary area)。它是在perf的mmap缓冲区中为原始数据流添加的一个特定区域。
用于将高带宽的原始数据流导出到用户空间进行进一步分析和处理。它是为了应对某些特定的使用场景而引入的,例如指令流跟踪。
"高带宽的数据流"指的是数据流的速率或吞吐量较高的情况。在这种情况下,数据以较快的速度连续传输或生成,产生的数据量非常大。
在性能分析领域,高带宽的数据流可以指程序的执行过程中产生的大量事件或跟踪数据,例如指令流跟踪、函数调用跟踪等。这些数据流需要有效的方法来捕获、导出和分析,以便深入理解程序的行为和性能特征。
因此,高带宽的数据流通常需要特殊的处理和存储机制,以确保数据的完整性和有效性,并提供足够的处理能力来处理数据流中的信息。
AUX space是一个环形缓冲区,由perf中的user_page结构中的aux_{offset, size}字段定义。它具有自己的读写指针(aux_{head, tail}),遵循与主要perf缓冲区中的数据相关字段(data_*)相同的规则。
用户需要通过设置aux_offset和aux_size来分配/mmap AUX space。其中,aux_offset的值必须大于data_offset+data_size,而aux_size表示所需的缓冲区大小。这两个值需要按页对齐。然后,将相同的aux_offset和aux_size传递给mmap()函数,如果一切正确,就会创建一个AUX space缓冲区。
AUX space区域的页面映射受限于用户的mlock资源限制以及perf_event_mlock_kb允许的限制。
详细请参考:https://lkml.org/lkml/2014/11/14/303
// linux-5.4.18/tools/include/uapi/linux/perf_event.h/** Structure of the page that can be mapped via mmap*/
struct perf_event_mmap_page {....../** Control data for the mmap() data buffer.** User-space reading the @data_head value should issue an smp_rmb(),* after reading this value.** When the mapping is PROT_WRITE the @data_tail value should be* written by userspace to reflect the last read data, after issueing* an smp_mb() to separate the data read from the ->data_tail store.* In this case the kernel will not over-write unread data.** See perf_output_put_handle() for the data ordering.** data_{offset,size} indicate the location and size of the perf record* buffer within the mmapped area.*/__u64 data_head; /* head in the data section */__u64 data_tail; /* user-space written tail */__u64 data_offset; /* where the buffer starts */__u64 data_size; /* data buffer size *//** AUX area is defined by aux_{offset,size} fields that should be set* by the userspace, so that** aux_offset >= data_offset + data_size** prior to mmap()ing it. Size of the mmap()ed area should be aux_size.** Ring buffer pointers aux_{head,tail} have the same semantics as* data_{head,tail} and same ordering rules apply.*/__u64 aux_head;__u64 aux_tail;__u64 aux_offset;__u64 aux_size;
}
// include/linux/perf_event.h/*** struct pmu - generic performance monitoring unit*/
struct pmu {....../** Set up pmu-private data structures for an AUX area*/void *(*setup_aux) (struct perf_event *event, void **pages,int nr_pages, bool overwrite);/* optional *//** Free pmu-private AUX data structures*/void (*free_aux) (void *aux); /* optional */......
}
// /arch/x86/events/intel/pt.hstruct pt_pmu {struct pmu pmu;......
};
// arch/x86/events/intel/pt.cstatic struct pt_pmu pt_pmu;static __init int pt_init(void)
{......pt_pmu.pmu.capabilities |= PERF_PMU_CAP_EXCLUSIVE | PERF_PMU_CAP_ITRACE;pt_pmu.pmu.attr_groups = pt_attr_groups;pt_pmu.pmu.task_ctx_nr = perf_sw_context;pt_pmu.pmu.event_init = pt_event_init;pt_pmu.pmu.add = pt_event_add;pt_pmu.pmu.del = pt_event_del;pt_pmu.pmu.start = pt_event_start;pt_pmu.pmu.stop = pt_event_stop;pt_pmu.pmu.read = pt_event_read;pt_pmu.pmu.setup_aux = pt_buffer_setup_aux;pt_pmu.pmu.free_aux = pt_buffer_free_aux;pt_pmu.pmu.addr_filters_sync = pt_event_addr_filters_sync;pt_pmu.pmu.addr_filters_validate = pt_event_addr_filters_validate;pt_pmu.pmu.nr_addr_filters =......ret = perf_pmu_register(&pt_pmu.pmu, "intel_pt", -1);return ret;
}
arch_initcall(pt_init);
参考资料
Enhance performance analysis with Intel Processor Trace.