日常工作软件安装总结
系统服务安装集成
Skywalking
SpringBoot集成Skywalking服务
地址:http://192.168.1.52:8686/general
nohup java -javaagent:/mnt/skywalking-agent/skywalking-agent/skywalking-agent.jar -DSW_AGENT_NAME=dev::rms-risk-service agent.service_name=rms-risk-service -Dskywalking.collector.backend_service=192.168.1.52:11800 -jar rms-risk-service.jar &
nohup java -javaagent:/mnt/skywalking-agent/skywalking-agent-system/skywalking-agent.jar -DSW_AGENT_NAME=dev::rms-system-service -Dskywalking.collector.backend_service=192.168.1.52:11800 -jar rms-system-service.jar &
nohup java -javaagent:/mnt/skywalking-agent/skywalking-agent-basic/skywalking-agent.jar -DSW_AGENT_NAME=dev::rms-basic-service -Dskywalking.collector.backend_service=192.168.1.52:11800 -jar rms-basic-service.jar &
skywalking9.1结合logback配置日志收集
首先保证自己已经有了SkyWalking APM服务(如果没有安装skywalking可参考https://blog.csdn.net/m0_49405757/article/details/134015206),接着去官网下载Java Agent。这里下载的是8.15.0版本的tar包。

直接将tar包解压出来,这边是将解压出来的文件夹直接放到了项目中(可以放到任意位置)

接着引入maven依赖
<properties><apm-logback.version>9.0.0</apm-logback.version></properties><dependency><groupId>org.apache.skywalking</groupId><artifactId>apm-toolkit-logback-1.x</artifactId><version>${apm-logback.version}</version></dependency>配置logback并在日志中打印traceId,在日志输出格式中添加%tid即可。可参考官网
<?xml version="1.0" encoding="UTF-8"?>
<configuration><!-- 日志输出格式 --><property name="FILE_LOG_PATTERN" value="[%d{yyyy-MM-dd HH:mm:ss.SSS}] %green(%-5level) [%thread] %yellow([%tid]) %cyan(%logger{50}) : %msg%n" /><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><!-- 默认日志打印的格式 --><!--<encoder><pattern>${CONSOLE_LOG_PATTERN}</pattern><charset>utf-8</charset></encoder>--><!-- 配置了skywalking的traceId的日志打印的格式 --><encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder"><layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout"><Pattern>${FILE_LOG_PATTERN}</Pattern></layout></encoder></appender><!-- 异步输出 控制台 --><appender name="ASYNC_STDOUT" class="ch.qos.logback.classic.AsyncAppender"><discardingThreshold>0</discardingThreshold><queueSize>256</queueSize><appender-ref ref="STDOUT"/></appender><root level="info"><appender-ref ref="ASYNC_STDOUT"/></root>
</configuration>在idea中配置服务启动时需要配置的jvm参数
-javaagent:skywalking-agent.jar的绝对路径
-Dskywalking.agent.service_name=你的服务名
-Dskywalking.agent.instance_name=你的实例名(可以和服务名保持一致)
-Dskywalking.collector.backend_service=ip:11800(如果skywlking服务不在本地,则需要配置上)
下面是我的参数配置
-javaagent:E:\ideaProject\mj-cloud\mj-registry\skywalking-agent\skywalking-agent.jar
-Dskywalking.agent.service_name=mj-permission
-Dskywalking.agent.instance_name=permission
接着启动服务(skywalking的服务也要启动),可以在控制台中看到tid已经打印出来了,但是由于启动时并没有调用其他服务,所以tid为N/A

启动之后调用了一个测试接口,可以看到tid已经打印出来了

skywalking还提供打印上下文的功能,只需将%tid替换为%sw_ctx,则日志会输出[$serviceName,$instanceName,$traceId,$traceSegmentId,$spanId]格式。

最后配置日志收集,需要在logback的配置文件中再添加一个appender
<!-- 使用gRpc将日志发送到skywalking服务端 --><appender name="GRPC_LOG" class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.log.GRPCLogClientAppender"><encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder"><layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout"><Pattern>${FILE_LOG_PATTERN}</Pattern></layout></encoder></appender><root level="info"><appender-ref ref="ASYNC_STDOUT"/><appender-ref ref="GRPC_LOG"/></root>
并且将下面的配置添加到我们下载的agent的config文件夹下的agent.config末尾
# 指定要向其报告日志数据的GRPC服务器主机
plugin.toolkit.log.grpc.reporter.server_host=${SW_GRPC_LOG_SERVER_HOST:skywalking服务所在机器的ip}
# 指定要向其报告日志数据的GRPC服务器端口
plugin.toolkit.log.grpc.reporter.server_port=${SW_GRPC_LOG_SERVER_PORT:11800}
# 指定GRPC客户端要报告的日志数据的最大大小
plugin.toolkit.log.grpc.reporter.max_message_size=${SW_GRPC_LOG_MAX_MESSAGE_SIZE:10485760}
# 客户端向上游发送数据时将超时多长时间,单位是秒
plugin.toolkit.log.grpc.reporter.upstream_timeout=${SW_GRPC_LOG_GRPC_UPSTREAM_TIMEOUT:30}

最后重启我们的服务,再次进行测试。打开skywalking的UI界面查看,选择我们的服务,点击log页签,可以看到测试的日志已经收集上了

点击日志可以看到追踪id和我们控制台打印的一样


至此,skywalking日志收集也已经完成。如果遇到问题一定要去查看日志,在我们安装的skywalking的logs文件夹下,主要看skywalking-oap-server.log
ELK
Sonarqube
Nacos
Docker
docker降级版本:
yum downgrade --setopt=obsoletes=0 -y docker-ce-19.03.13-3.el7 docker-ce-cli-19.03.13-3.el7 containerd.io
Centos7 安装docker
# centos7 安装docker
# 安装依赖
yum install -y yum-utils device-mapper-persistent-data lvm2#安装docker
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun#启动
service docker start# 设置开机启动
systemctl enable docker
Docker本地文件复制到容器
docker cp /mnt/prometheus.yml 082195e34a9d:/etc/prometheus/prometheus.yml
Docker复制容器文件到本地
docker cp 082195e34a9d:/etc/prometheus/prometheus.yml /mnt
构建、上传镜像到Harbor
1、构建镜像
docker build -t docker-risk .
2、运行镜像
docker run --name docker-risk -d -p 6080:6080 docker-risk
3、打标签
docker tag docker-risk01 192.168.1.107:80/rms/docker-risk01:latest
4、登录harbor
docker login 192.168.1.107:80
5、推送镜像到Harbor
docker push 192.168.1.107:80/rms/docker-risk01:latest
6、拉取镜像到本地
docker pull 192.168.1.107:80/rms/docker-risk01:latest
docker pull 192.168.1.107/rms/docker-system-service@sha256:4ddc493cd8cdc957e8228f8738e25f1ad3e4ebd076f906cdfa58c1fce9e18fb0
docker配置Harbor
{"exec-opts": ["native.cgroupdriver=systemd"],"storage-driver": "overlay2","log-driver": "json-file","log-opts": {"max-size": "100m"},"registry-mirrors": ["https://b9307g5p.mirror.aliyuncs.com"],"insecure-registries": ["192.168.1.107:80"]}
服务器位置:
/etc/docker/daemon.json
修改docker service
位置:
vim /usr/lib/systemd/system/docker.service
重新加载守护线程
systemctl daemon-reload
Docker安装部署Elasticsearch、kibana
一、安装Elasticsearch
1.1.创建网络
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-net
1.2.拉取
docker pull elasticsearch:7.12.1
1
1.3.运行
运行docker命令,部署单点es:
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
elasticsearch:7.12.1
命令解释:
-e “cluster.name=es-docker-cluster”:设置集群名称
-e “http.host=0.0.0.0”:监听的地址,可以外网访问
-e “ES_JAVA_OPTS=-Xms512m -Xmx512m”:内存大小
-e “discovery.type=single-node”:非集群模式
-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录
-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录
-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录
–privileged:授予逻辑卷访问权
–network es-net :加入一个名为es-net的网络中
-p 9200:9200:端口映射配置
在浏览器中输入:http://IP地址:9200 即可看到elasticsearch的响应结果:
二、部署kibana
2.1.部署
拉取镜像命令
docker pull kibana:7.12.1
运行docker命令,部署kibana
docker run -d
–name kibana
-e ELASTICSEARCH_HOSTS=http://es:9200
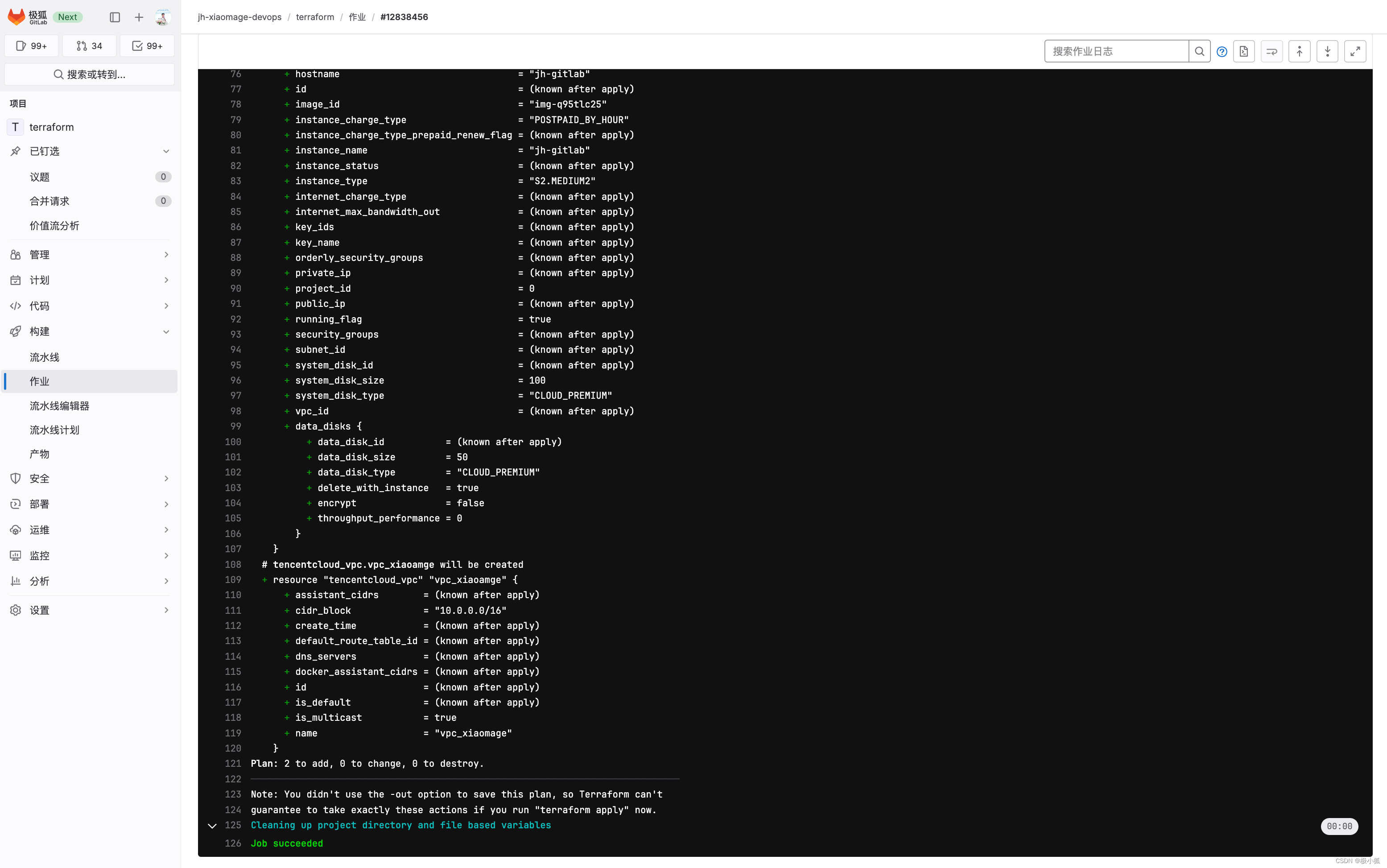
–network=es-net
-p 5601:5601
kibana:7.12.1
–network es-net :加入一个名为es-net的网络中,与elasticsearch在同一个网络中
-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch
-p 5601:5601:端口映射配置
此时,在浏览器输入地址访问:http://IP地址:5601,即可看到结果
Docker elasticserch集群搭建
useradd esUser
(base) [username@opencloudos ~]$ groups
username docker
或者
(base) [username@opencloudos ~]$ groups username
username : username docker
一般回复的是当前用户所在的分组,看看当前用户username在不在docker组中。如果不在,可以使用以下命令将用户添加到docker组。(注意将username替换成真实的用户名),此处需要使用root或者sudo权限。
usermod -aG docker esUser
#停止容器
docker stop d2c410563678
#删除容器
docker rm d2c410563678
查看镜像内容
docker logs <容器ID或名称>
报错:
this Docker version is not on the list of validated versions: 24.0.7. Latest validated version: 20.1
报错信息可以看出跟docker的版本有关系,意思是:此 Docker 版本不在已验证版本列表中:24.0.7。 最新验证版本:20.10
降低docker版本到20.10
1、查看当前仓库支持的docker版本
yum list docker-ce --showduplicates | sort -r
2、降低docker版本到3:20.10.9-3.el8
语法: yum downgrade --setopt=obsoletes=0 -y docker-ce-v e r s i o n d o c k e r − c e − s e l i n u x − {version} docker-ce-selinux-versiondocker−ce−selinux−{version}
降低docker版本到3:20.10.9-3.el8
yum downgrade --setopt=obsoletes=0 -y docker-ce-3:20.10.9-3.el8 docker-ce-cli-3:20.10.9-3.el8 containerd.io
3、查看降级后版本
systemctl start docker
docker version
Docker Elasticsearch集群部署
查看集群详情
192.168.1.113:9200/_cat/nodes?pretty
环境
(1)Centos7
(2)Docker 23.0.1
(3)Elasticsearch 7.16.3
服务器
| 名称 | ip地址 | 内存 |
|---|---|---|
| 节点一 | 192.168.1.113 | 16G |
| 节点二 | 192.168.1.114 | 16G |
| 节点三 | 192.168.1.115 | 16G |
部署
在三个服务器节点上执行如下操作:
准备映射目录
切换到/home目录中,创建elasticsearch目录,切换到elasticsearch目录中。
cd /home/
mkdir elasticsearch
cd elasticsearch
临时启动elasticsearch
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.16.3
复制容器中配置目录到磁盘目录
cd /home/elasticsearch
docker cp elasticsearch:/usr/share/elasticsearch/config .
docker cp elasticsearch:/usr/share/elasticsearch/data .
docker cp elasticsearch:/usr/share/elasticsearch/plugins .
授予elasticsearch目录及子目录改文件及子文件所有权限
chmod -R 777 elasticsearch
移除临时启动elasticsearch容器
docker stop elasticsearch
docker rm elasticsearch
3.1 节点一
修改/home/elasticsearch/config/elasticsearch.yml配置文件
# 集群名称 所有节点名称一致
cluster.name: es-clusters
# 当前该节点的名称,每个节点不能重复es-node-1,es-node-2,es-node-3
node.name: es-node-1
# 当前该节点是不是有资格竞选主节点
node.master: true
# 当前该节点是否存储数据
node.data: true
# 设置为公开访问
network.host: 0.0.0.0
# 设置其它节点和该节点交互的本机器的ip地址,三台各自为
network.publish_host: 192.16.109.113
# 设置映射端口
http.port: 9200
# 内部节点之间沟通端口
transport.tcp.port: 9300# 支持跨域访问
http.cors.enabled: true
http.cors.allow-origin: "*"# 配置集群的主机地址
discovery.seed_hosts: ["192.16.109.113","192.16.109.114","192.16.109.115"]
# 初始主节点,使用一组初始的符合主条件的节点引导集群
cluster.initial_master_nodes: ["es-node-1","es-node-2","es-node-3"]
# 节点等待响应的时间,默认值是30秒,增加这个值,从一定程度上会减少误判导致脑裂
discovery.zen.ping_timeout: 30s
# 配置集群最少主节点数目,通常为 (可成为主节点的主机数目 / 2) + 1
discovery.zen.minimum_master_nodes: 2
# 禁用交换内存,提升效率
bootstrap.memory_lock: false
正式运行elasticsearch
docker run --name=elasticsearch-node-1 -p 9200:9200 -p 9300:9300 \
-e ES_JAVA_OPTS="-Xms4g -Xmx4g" \
-v /home/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /home/elasticsearch/data:/usr/share/elasticsearch/data \
-v /home/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
--restart=always \
-d elasticsearch:7.16.3
节点二
修改/home/elasticsearch/config/elasticsearch.yml配置文件
# 集群名称 所有节点名称一致
cluster.name: es-clusters
# 当前该节点的名称,每个节点不能重复es-node-1,es-node-2,es-node-3
node.name: es-node-2
# 当前该节点是不是有资格竞选主节点
node.master: true
# 当前该节点是否存储数据
node.data: true
# 设置为公开访问
network.host: 0.0.0.0
# 设置其它节点和该节点交互的本机器的ip地址,三台各自为
network.publish_host: 192.16.109.114
# 设置映射端口
http.port: 9200
# 内部节点之间沟通端口
transport.tcp.port: 9300# 支持跨域访问
http.cors.enabled: true
http.cors.allow-origin: "*"# 配置集群的主机地址
discovery.seed_hosts: ["192.16.109.113","192.16.109.114","192.16.109.115"]
# 初始主节点,使用一组初始的符合主条件的节点引导集群
cluster.initial_master_nodes: ["es-node-1","es-node-2","es-node-3"]
# 节点等待响应的时间,默认值是30秒,增加这个值,从一定程度上会减少误判导致脑裂
discovery.zen.ping_timeout: 30s
# 配置集群最少主节点数目,通常为 (可成为主节点的主机数目 / 2) + 1
discovery.zen.minimum_master_nodes: 2
# 禁用交换内存,提升效率
bootstrap.memory_lock: false
正式运行elasticsearch
docker run --name=elasticsearch-node-2 -p 9200:9200 -p 9300:9300 \
-e ES_JAVA_OPTS="-Xms4g -Xmx4g" \
-v /home/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /home/elasticsearch/data:/usr/share/elasticsearch/data \
-v /home/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
--restart=always \
-d elasticsearch:7.16.3
节点三
修改/home/elasticsearch/config/elasticsearch.yml配置文件
# 集群名称 所有节点名称一致
cluster.name: es-clusters
# 当前该节点的名称,每个节点不能重复es-node-1,es-node-2,es-node-3
node.name: es-node-3
# 当前该节点是不是有资格竞选主节点
node.master: true
# 当前该节点是否存储数据
node.data: true
# 设置为公开访问
network.host: 0.0.0.0
# 设置其它节点和该节点交互的本机器的ip地址,三台各自为
network.publish_host: 192.16.109.115
# 设置映射端口
http.port: 9200
# 内部节点之间沟通端口
transport.tcp.port: 9300# 支持跨域访问
http.cors.enabled: true
http.cors.allow-origin: "*"# 配置集群的主机地址
discovery.seed_hosts: ["192.16.109.113","192.16.109.114","192.16.109.115"]
# 初始主节点,使用一组初始的符合主条件的节点引导集群
cluster.initial_master_nodes: ["es-node-1","es-node-2","es-node-3"]
# 节点等待响应的时间,默认值是30秒,增加这个值,从一定程度上会减少误判导致脑裂
discovery.zen.ping_timeout: 30s
# 配置集群最少主节点数目,通常为 (可成为主节点的主机数目 / 2) + 1
discovery.zen.minimum_master_nodes: 2
# 禁用交换内存,提升效率
bootstrap.memory_lock: false
正式运行elasticsearch
docker run --name=elasticsearch-node-3 -p 9200:9200 -p 9300:9300 \
-e ES_JAVA_OPTS="-Xms4g -Xmx4g" \
-v /home/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /home/elasticsearch/data:/usr/share/elasticsearch/data \
-v /home/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
--restart=always \
-d elasticsearch:7.16.3
查看集群是否成功
在浏览器上输入http://任一节点ip:9200/_cat/nodes?pretty查看集群信息,出现如下信息就代表集群搭建成功了。
192.16.109.113 20 99 1 0.03 0.04 0.06 cdfhilmrstw * es-node-3
192.16.109.114 12 99 3 0.03 0.05 0.06 cdfhilmrstw - es-node-1
192.16.109.114 56 89 2 0.19 0.12 0.13 cdfhilmrstw - es-node-2
注意事项
运行elasticsearch启动参数
注意:我们启动参数设置的-e ES_JAVA_OPTS="-Xms4g -Xmx4g",根据服务器内存实际情况调整。
● Xms 为jvm启动是分配的最大内存
● Xmx 为jvm运行过程分配的最大内存
修改虚拟内存最大映射数
系统虚拟内存默认最大映射数为65530,无法满足ES系统要求,需要调整为262144以上。
sudo vi /etc/sysctl.conf
#添加参数
vm.max_map_count = 655360
重新加载/etc/sysctl.conf配置
sysctl -p
各节点无法组成集群,各自都是master的解决办法
(1)关闭所有节点,或者直接删除容器
(2)在三个节点上清空/home/elasticsearch/data节点数据
cd /home/elasticsearch/data
rm -rf *
重新启动所有节点
Jenkins
1、下载Jenkins.war包,上传到Linux服务器
2、执行命令
注意:
必须在jenkins.war目录下执行
nohup java -jar jenkins.war --ajp13Port=-1 --httpPort=8081 &
jenkins启动默认密码:
*************************************************************
*************************************************************
*************************************************************Jenkins initial setup is required. An admin user has been created and a password generated.
Please use the following password to proceed to installation:d8657ad599424ba1b81e336b489f3602This may also be found at: /root/.jenkins/secrets/initialAdminPassword*************************************************************
*************************************************************
*************************************************************
3、等待Jenkins安装依赖,可能会报错
4、配置jdk路径、下载maven配置maven路径、下载git,配置git路径
5、
-Dmaven.test.skip=true
Prometheus
1、使用docker安装
2、镜像地址配置路径:
/etc/prometheus/prometheus.yml# my global config
global:scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.# scrape_timeout is set to the global default (10s).# Alertmanager configuration
alerting:alertmanagers:- static_configs:- targets:# - alertmanager:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:# - "first_rules.yml"# - "second_rules.yml"# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: "prometheus"# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ["localhost:9090"]
docker进入容器报:Error response from daemon: Container ******* is not running
根据docker所报的错,问题出现的有以下:
1、由于 docker容器未启动。
2、网络问题,网络配置修改了,但未重启网络。
3、配置文件问题,文件修改过程中出错了。
一、docker容器未启动解决方法:启动容器
操作步骤:
1.使用命令查看docker容器id:docker ps -a;

2.使用命令:docker start 容器id,启动docker容器。

3.然后即可使用命令:docker exec -it 容器id /bin/bash进入docker容器。

二、网络配置更改了,解决方法:重启网络
使用命令:source /etc/profile
三、配置文件问题,解决方法:修改配置文件
示例:mysql中的配置文件更改中出错了,操作步骤如下:
1、从容器中将配置文件复制到本地
docker cp 容器id:/etc/mysql/my.cnf /opt2、在本地修改配置文件,并保存
使用命令:vi /opt/my.cnf3、将更改后的配置文件复制到docker容器中
docker cp /opt/my.cnf 容器id:/etc/mysql4、重启容器
docker restart 容器id
5、查看docker容器中启动的进程
docker ps -a
即问题解决。
附注:
1.如果需要设置docker中MySQL自启,使用命令:docker update mysql --restart=always 容器id;
2.docker设置开机自启,使用命令:system enable docker;
java.lang.ClassNotFoundException: io.prometheus.client.Gauge
在Java开发中,我们经常会遇到各种异常,其中一个常见的异常是java.lang.ClassNotFoundException。这个异常通常是由于类路径问题引起的,即JVM无法找到所需的类。在本文中,我们将讨论一个特定的ClassNotFoundException:io.prometheus.client.Gauge。
io.prometheus.client.Gauge是一个Prometheus客户端库中的类,用于创建和管理Gauge指标。Prometheus是一个开源的监控系统,它可以收集和存储各种指标,并提供查询和可视化功能。Gauge是一种指标类型,它表示一个单一的数值,可以随时间变化。例如,我们可以使用Gauge来表示服务器的CPU使用率或内存使用量。
在使用Prometheus客户端库时,我们需要将其添加到我们的项目中。通常,我们可以使用Maven或Gradle等构建工具来管理依赖项。以下是一个使用Maven的示例pom.xml文件:
<dependencies><dependency><groupId>io.prometheus</groupId><artifactId>simpleclient</artifactId><version>0.11.0</version></dependency><dependency><groupId>io.prometheus</groupId><artifactId>simpleclient_pushgateway</artifactId><version>0.11.0</version></dependency><dependency><groupId>io.prometheus</groupId><artifactId>simpleclient_servlet</artifactId><version>0.11.0</version></dependency>
</dependencies>
prometheus.yml样例
# my global config
global:scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.# scrape_timeout is set to the global default (10s).# Alertmanager configuration
alerting:alertmanagers:- static_configs:- targets:- 192.168.1.56:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:# - "first_rules.yml"# - "second_rules.yml"- "/etc/prometheus/rules.yml"# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: "prometheus"# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ["192.168.1.56:9090"]
# - job_name: 'mysql'
# static_configs:
# - targets: ['192.168.1.101:3306']- job_name: 'nacos'# metrics_path defaults to '/metrics'# scheme defaults to 'http'.metrics_path: '/nacos/actuator/prometheus'static_configs:- targets: ['192.168.1.111:8848']# 新添加的采集目标admin服务- job_name: "rms-admin-service"metrics_path: '/actuator/prometheus'static_configs:- targets: ["192.168.1.51:6091"]# 新添加的采集目标risk服务- job_name: "rms-risk-service"metrics_path: '/actuator/prometheus'static_configs:- targets: ["192.168.1.51:6080"]- job_name: "rms-system-service"metrics_path: '/actuator/prometheus'static_configs:- targets: ["192.168.1.51:6060"]- job_name: "rms-basic-service"metrics_path: '/actuator/prometheus'static_configs:- targets: ["192.168.1.51:6070"]- job_name: "node-exporter"
# metrics_path: '/actuator/prometheus'static_configs:- targets: ["192.168.1.56:9100"]# # 新添加的采集目标elasticsearch服务
# - job_name: "elasticsearch"
# static_configs:
# - targets: ["192.168.1.55:9200"]
#
# # 新添加的采集目标web前端服务
# - job_name: "rms-web"
# static_configs:
# - targets: ["192.168.1.2:3110"]
#
# # 新添加的采集目标web前端服务
# - job_name: "skywalking"
# static_configs:
# - targets: ["192.168.1.52:8686"]
alertmanager.yml样例
global:resolve_timeout: 5mroute: # 告警路由配置,定义如何处理和发送告警receiver: webhookgroup_wait: 30sgroup_interval: 1mrepeat_interval: 4hgroup_by: [alertname]routes:- receiver: webhookgroup_wait: 10sreceivers: # 告警接收者配置,定义如何处理和发送告警
- name: webhookwebhook_configs:- url: http://192.168.1.56:8060/dingtalk/webhook1/send # 告警 Webhook URLsend_resolved: true # 是否发送已解决的告警。如果设置为 true,则在告警解决时发送通知
Grafana
Dashboards实例值:10467
docker run -d \--name mysql_exporter \--restart always \-p 9104:9104 \-e DATA_SOURCE_NAME="user:password@(192.168.1.56:3306)/" \prom/mysqld-exporter
version: '3.2'networks:mysql-exporter-test:driver: bridgeservices:mysql:image: mysqlcontainer_name: mysql-testvolumes:- ./docker-volumes/mysql/db_data:/var/lib/mysql- ./docker-volumes/mysql/config/init:/docker-entrypoint-initdb.d/command: ['--character-set-server=utf8mb4','--collation-server=utf8mb4_unicode_ci','--default-time-zone=+8:00']environment:MYSQL_ROOT_PASSWORD: rootMYSQL_USER: rootMYSQL_PASSWORD: Rlyy#234ports:- 3306:3306networks:- mysql-exporter-testmysqld-exporter:image: prom/mysqld-exportercontainer_name: exporter-testports:- 9104:9104environment:- DATA_SOURCE_NAME=exporter:Prometheus@(mysql-test:3306)/depends_on:- mysqlnetworks:- mysql-exporter-testprometheus:image: prom/prometheus:latestcontainer_name: prometheusvolumes:- ./docker-volumes/prometheus/config/prometheus.yml:/etc/prometheus/prometheus.yml- ./docker-volumes/prometheus/data/prometheus_data:/prometheusenvironment:- TZ=Asia/Shanghaiports:- 9090:9090networks:- mysql-exporter-testdocker run -d -p 9104:9104 \-e DATA_SOURCE_NAME="root:Rlyy#234@(192.168.1.56:3306)/rms_risk" \--name mysql-exporter prom/mysqld-exporter
Grafana常用监控模板大全
Grafana常用监控模板大全 - 眈眈逐逐 - 博客园 (cnblogs.com)
1.服务器系统性能监控:8919
2.微服务性能监控:4701
3.docker环境性能监控:893
4.nacos性能监控:13221
5.mysql性能监控:9362
6.elasticsearch:266
7.SpringBoot:6756,springcloud:12856
8、redis:763
Alertmanager
alertmanager配置短信告警
alertmanager配置日志目录
alertmanager配置短信接口
alertmanager配置文件监听
alertmanager配置监控
alertmanager配置动态加载
alertmanager配置webhook
alertmanager配置钉钉告警
alertmanager配置basicauth
alertmanager配置多个webhook
Docker部署Prometheus+dingtalk+alertmanager告警
准备工作
拉取镜像
docker pull prom/node-exporter
docker pull grafana/grafana
docker pull prom/prometheus
docker pull prom/alertmanager
docker pull timonwong/prometheus-webhook-dingtalk一、安装node-exporter
docker run -d -p 9100:9100 --name node-exporter -v /home/node-exporter/proc:/host/proc:ro -v /home/node-exporter/sys:/host/sys:ro -v /home/node-exporter/:/rootfs:ro prom/node-exporterhttp://192.168.0.201:9100/

二、安装Prometheus
1、配置prometheus.yml文件
[root@node1 prometheus]# vi /home/prometheus/opt/prometheus/prometheus.yml
global:scrape_interval: 60sevaluation_interval: 60s
scrape_configs:- job_name: prometheusstatic_configs:- targets: ['192.168.0.201:9190'] # 采取prometheus指标数据labels:instance: prometheus- job_name: linuxstatic_configs:- targets: ['192.168.0.201:9100'] # 采取本地指标数据labels:instance: localhost
2、启动
docker run -d -p 9190:9090 --name prometheus -v /home/prometheus/opt/prometheus:/etc/prometheus prom/prometheushttp://192.168.0.201:9190/

三、启动webhook-dingtalk
docker run -d -p 8060:8060 --name webhook timonwong/prometheus-webhook-dingtalk1、查询webhook映射,进入容器内修改配置文件
[root@node1 prometheus]# docker inspect webhook|grep Dir
2、进入mergerDir
[root@node1 prometheus]# cd /home/docker/overlay2/52933d06cee0e5135bf0bfc5907a581f8b19a480688af08d1c2b7ff2a8239e96/merged3、进入配置文件夹
[root@node1 merged]# cd etc/prometheus-webhook-dingtalk/4、修改配置文件
[root@node1 prometheus-webhook-dingtalk]# vi config.yml
## Request timeout
# timeout: 5s## Uncomment following line in order to write template from scratch (be careful!)
#no_builtin_template: true## Customizable templates path
#templates:
# - contrib/templates/legacy/template.tmpl## You can also override default template using `default_message`
## The following example to use the 'legacy' template from v0.3.0
#default_message:
# title: '{{ template "legacy.title" . }}'
# text: '{{ template "legacy.content" . }}'## Targets, previously was known as "profiles"
targets:webhook1:url: https://oapi.dingtalk.com/robot/send?access_token=ed49*************************7239514b010270f# secret for signaturesecret: SEC**********************webhook2:url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxxwebhook_legacy:url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx# Customize template contentmessage:# Use legacy templatetitle: '{{ template "legacy.title" . }}'text: '{{ template "legacy.content" . }}'webhook_mention_all:url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxxmention:all: truewebhook_mention_users:url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxxmention:mobiles: ['156xxxx8827', '189xxxx8325']
~
5、重启webhook
[root@node1 prometheus-webhook-dingtalk]# docker restart webhook6、查看webhook日志
[root@node1 prometheus-webhook-dingtalk]# docker logs webhook
复制webhook1地址
四、启动alertmanager
1、创建alertmanager.yml映射
[root@node1 /]# sudo mkdir /home/alertmanager/opt/alertmanager/
[root@node1 /]# cd /home/alertmanager/opt/alertmanager/
[root@node1 alertmanager]# vi alertmanager.yml
global:resolve_timeout: 5mroute: # 告警路由配置,定义如何处理和发送告警receiver: webhookgroup_wait: 30sgroup_interval: 1mrepeat_interval: 4hgroup_by: [alertname]routes:- receiver: webhookgroup_wait: 10sreceivers: # 告警接收者配置,定义如何处理和发送告警
- name: webhookwebhook_configs:- url: http://192.168.0.201:8060/dingtalk/webhook1/send # 告警 Webhook URLsend_resolved: true # 是否发送已解决的告警。如果设置为 true,则在告警解决时发送通知
注意webhook的url是前面webhookq启动日志里有的地址。将localhost改成服务器对应的ip即可。
2、修改prometheus.yml文件
[root@node1 alertmanager]# vi /home/prometheus/opt/prometheus/prometheus.yml
global:scrape_interval: 60sevaluation_interval: 60s
# Alertmanager配置
alerting:alertmanagers:- static_configs:- targets: ["192.168.0.201:9093"]
# rule配置
rule_files:- "/etc/prometheus/rules.yml"
scrape_configs:- job_name: prometheusstatic_configs:- targets: ['192.168.0.201:9190'] # 采取prometheus指标数据labels:instance: prometheus- job_name: linuxstatic_configs:- targets: ['192.168.0.201:9100'] # 采取本地指标数据labels:instance: localhost
3、启动
docker run -d -p 9093:9093 -v /home/alertmanager/opt/alertmanager/:/etc/alertmanager/ --name alertmanager prom/alertmanagerhttp://192.168.0.201:9093/

五、配置预警规则
[root@node1 alertmanager]# vi /home/prometheus/opt/prometheus/rules.yml
groups:- name: host_monitoringrules:- alert: 内存报警expr: netdata_system_ram_MiB_average{chart="system.ram",dimension="free",family="ram"} < 800for: 2mlabels:team: nodeannotations:Alert_type: 内存报警Server: '{{$labels.instance}}'#summary: "{{$labels.instance}}: High Memory usage detected"explain: "内存使用量超过90%,目前剩余量为:{{ $value }}M"#description: "{{$labels.instance}}: Memory usage is above 80% (current value is: {{ $value }})"- alert: CPU报警expr: netdata_system_cpu_percentage_average{chart="system.cpu",dimension="idle",family="cpu"} < 20for: 2mlabels:team: nodeannotations:Alert_type: CPU报警Server: '{{$labels.instance}}'explain: "CPU使用量超过80%,目前剩余量为:{{ $value }}"#summary: "{{$labels.instance}}: High CPU usage detected"#description: "{{$labels.instance}}: CPU usage is above 80% (current value is: {{ $value }})"- alert: 磁盘报警expr: netdata_disk_space_GiB_average{chart="disk_space._",dimension="avail",family="/"} < 4for: 2mlabels:team: nodeannotations:Alert_type: 磁盘报警Server: '{{$labels.instance}}'explain: "磁盘使用量超过90%,目前剩余量为:{{ $value }}G"- alert: 服务告警expr: up == 0for: 2slabels:team: nodeannotations:Alert_type: 服务报警summary: 'instance {{$labels.instance}} down'description: "netdata服务已关闭"
六、重启prometheus
[root@node1 alertmanager]# docker restart prometheus七、测试
[root@node1 alertmanager]# docker stop node-exporter
ps:通知内容待优化。。。
八、启动gafana
docker run -d -p 3000:3000 --name=grafana grafana/grafanahttp://192.168.0.201:3000/
admin/admin
第一次登陆需要修改密码

1、设置数据源



2、设置dashboards

填入 https://grafana.com/grafana/dashboards/405 点击load,即可下载Node-Exporter的dashboard
参考文章:
docker部署prometheus+grafana+alertmanager+dingtalk实现钉钉告警_prometheus钉钉告警_生夏夏夏的博客-CSDN博客
docker部署prometheus告警钉钉通知_POI操作Excel的技术博客_51CTO博客
Rancher
修改密码:
docker exec -ti rancher reset-password
https://blog.csdn.net/jiumingmao1991/article/details/124733879
Harbor
Harbor重置密码
1、进入容器
docker exec -it harbor-db /bin/bash
2、登录数据库
psql -h postgresql -d postgres -U postgres #默认密码为root123
3、进入 registry库
\c registry
4、查看用户表
select * from harbor_user;
5、修改用户密码
update harbor_user set password='c999cbeae74a90282c8fa7c48894fb00', salt='nmgxu7a5ozddr0z6ov4k4f7dgnpbvqky' where username='admin';
6、使用默认密码Harbor12345登录
Docker容器:docker推送镜像至Harbor
1、Harbor创建项目
2、进入test项目,查看推送命令
3、在docker服务器上准备一个镜像
4、修改docker客户端配置
5、重启docker服务
6、docker登录Harbor
7、docker镜像推送到Harbor
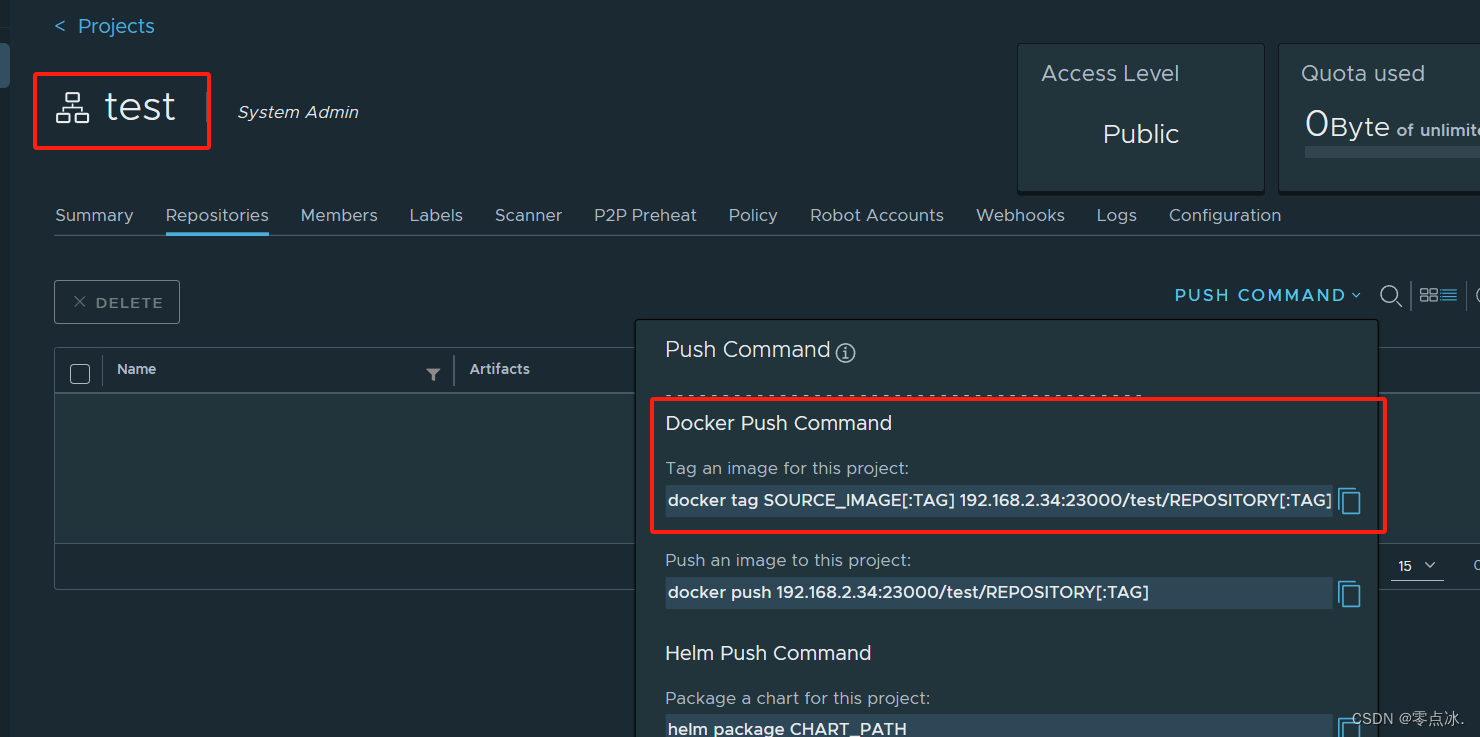
1、Harbor创建项目

2、进入test项目,查看推送命令
3、在docker服务器上准备一个镜像
docker pull nginxdocker tag nginx 192.168.2.34:23000/test/nginx:latest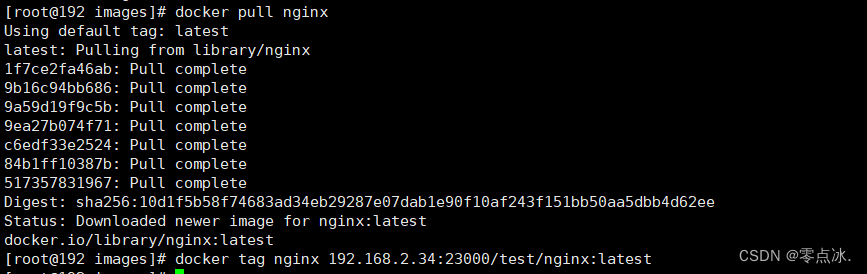
4、修改docker客户端配置
vi /etc/docker/daemon.json{"registry-mirrors": ["https://mirror.ccs.tencentyun.com"],"insecure-registries": ["http://192.168.2.34:23000"]
}
其中:
registry-mirrors配置的是加速镜像源。
insecure-registries配置就是Harbor的仓库地址。
常见的加速镜像源有:
腾讯云:https://mirror.ccs.tencentyun.com
七牛云:https://reg-mirror.qiniu.com
网易云:https://hub-mirror.c.163.com
DaoCloud:http://f1361db2.m.daocloud.io
科大镜像:https://docker.mirrors.ustc.edu.cn
5、重启docker服务
systemctl daemon-reload
systemctl restart docker6、docker登录Harbor
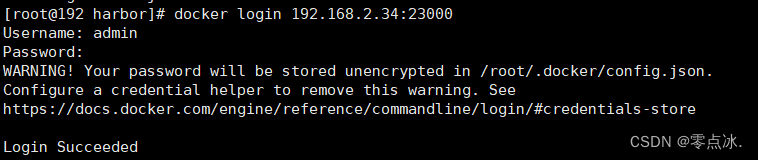
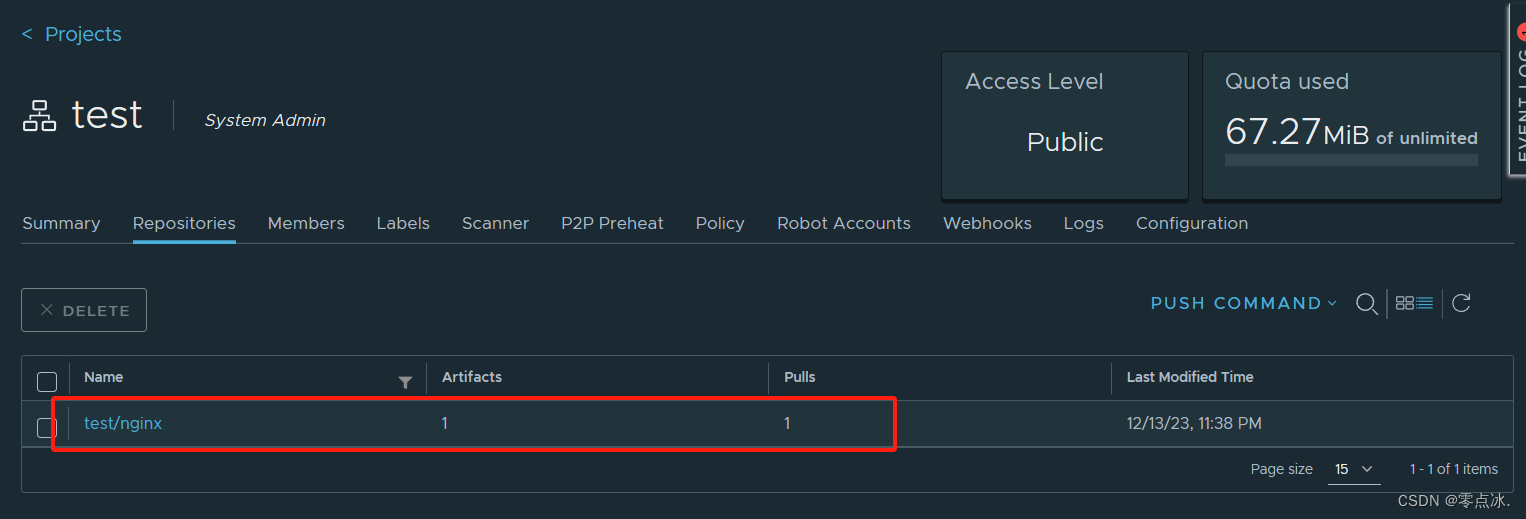
7、docker镜像推送到Harbor

Harbor 本地docker镜像仓库远程连接(镜像管理零距离!!)
简单几步,实现本地Harbor docker镜像仓库结合cpolar内网穿透实现远程推送和拉取镜像
1. 查看本地镜像
进入本地 Harbor docker 仓库,我们可以看到我们的本地镜像,这边方便测试,提前上传了一个镜像

在左侧可以看到推送命令,这里局域网ip没有出现端口,说明默认使用80端口,知道了端口,我们下面设置cpolar公网地址

2. 安装cpolar
上面我们在本地 Linux中查看了Harbor 里面的本地docker镜像,下面我们在Linux中安装cpolar内网穿透工具,通过cpolar的http公网地址,我们可以很容易实现远程连接Harbor中的镜像,并进行推送和下载,而无需自己注册域名购买云服务器.下面是安装cpolar步骤
cpolar官网地址: https://i.cpolar.com/m/56Ju (进入官网注册免费账号)
- 使用一键脚本安装命令
curl -L https://www.cpolar.com/static/downloads/install-release-cpolar.sh | sudo bash- 向系统添加服务
sudo systemctl enable cpolar- 启动cpolar服务
sudo systemctl start cpolarcpolar安装成功后,在外部设备通过浏览器上访问Linux 的9200端口即:【http://局域网ip:9200】,即可看到cpolar 管理界面.然后使用cpolar账号登录。

3. 配置公网连接地址
点击左侧仪表盘的隧道管理——创建隧道,创建一个我们上面看到的80端口的隧道!
- 隧道名称:可自定义命名,注意不要与已有的隧道名称重复
- 协议:选择http
- 本地地址:80 (Harbor默认端口,具体以自己的端口为准)
- 域名类型:免费选择随机域名
- 地区:选择China vip
点击创建

隧道创建成功后,点击左侧的状态——在线隧道列表,查看所生成的公网地址,有两种访问方式,一种是http 和https

4. 远程拉取镜像测试
上面我们创建了Harbor的公网地址,接下来使用cpolar公网地址将我们本地的docker镜像下载下来.
首先需要登录Harbor(这里的Harbor版本是最新的,登录比较容易,不会出现异常),输入命令:
docker login 公网地址 -u 用户名然后提示输入密码,登录后,出现succeeded 表示登录成功!

然后拉取我们本地镜像,进入本地镜像仓库,复制拉取命令

以下是本例子复制的拉取命令(实际以自己的为准),我们只需要把前面局域网IP地址换成cpolar公网地址即可, 注意!!! 协议名称http://不需要输入
docker pull
28395150.r3.vip.cpolar.cn/library/ghcr.io/lissy93/dashy@sha256:134b0c09c4d199e53c78a81fc07173a314bd63833da4a5afc47caadc72fe582c然后执行拉取,拉取后,查看docker镜像列表,即可看到我们拉取的镜像,表示成功!!,这样一个远程的连接就设置好了

5. 远程推送镜像测试
同样,远程推送也是,我们使用公网地址进行远程推送镜像到本地仓库,首先查看我们镜像ID
docker images查看我们需要推送的镜像ID,这里演示把tomcat镜像推送到本地仓库

先标记镜像
docker tag 镜像ID cpolar公网地址/Harbor上的项目名称/镜像名称执行后,输入推送命令
docker push cpolar公网地址/Harbor上的项目名称/镜像名称执行后,我们等待上传,这里使用的是cpolar公网地址,所以有带宽限制,可以使用cpolar中NAS套餐,带宽大一些,速度快一些!

推送上传成功后,我们打开本地的Harbor 镜像仓库,即可看到我们远程上传的tomcat镜像,表示上传成功!!

修改Cpolar Web UI默认端口号
如您本地已有服务使用了9200端口,那么您可以将cpolar web UI管理端口修改为其他端口,如127.0.0.1:9300
1. 找到cpolar配置文件
- windows系统: c:\Users\用户名.cpolar\cpolar.yml,右键点击“打开方式”——“记事本”,选择使用记事本打开
- linux系统:执行命令
nano /usr/local/etc/cpolar/cpolar.yml
2. 在配置文件中,增加一行参数:
client_dashboard_addr: 127.0.0.1:9300Bash
Copy
注:添加的一行,与authtoken是一个级别的参数。
3. 保存cpolar配置文件
4. 重启cpolar服务
- windows系统:在控制面板–管理工具—服务—cpolar service,重启服务。
- linux系统:执行命令
sudo systemctl restart cpolar
5. 浏览器访问本地9300端口http://127.0.0.1:9300/

Apifox
Nacos
tar.gz安装启动
1、下载压缩包
wget https://github.com/alibaba/nacos/releases/download/1.2.1/nacos-server-1.2.1.tar.gz
2、解压压缩包
tar -zxvf nacos-server-1.2.1.tar.gz
3、进入nacos目录
cd /mnt/nacos-1.2.1/nacos/bin
4、启动nacos服务
sh startup.sh -m standalone
#或者
./startup.sh -m standalone
[INFO] nacos-api 2.3.1-SNAPSHOT … SUCCESS [ 20.941 s]
[INFO] nacos-common 2.3.1-SNAPSHOT … SUCCESS [ 27.461 s]
[INFO] nacos-consistency 2.3.1-SNAPSHOT … SUCCESS [ 14.950 s]
[INFO] nacos-datasource-plugin 2.3.1-SNAPSHOT … SUCCESS [ 4.327 s]
[INFO] nacos-custom-environment-plugin 2.3.1-SNAPSHOT … SUCCESS [ 1.260 s]
[INFO] nacos-sys 2.3.1-SNAPSHOT … SUCCESS [ 5.294 s]
[INFO] nacos-persistence 2.3.1-SNAPSHOT … SUCCESS [ 4.658 s]
[INFO] nacos-auth-plugin 2.3.1-SNAPSHOT … SUCCESS [ 1.917 s]
[INFO] nacos-auth 2.3.1-SNAPSHOT … SUCCESS [ 5.680 s]
[INFO] nacos-trace-plugin 2.3.1-SNAPSHOT … SUCCESS [ 1.428 s]
[INFO] nacos-control-plugin 2.3.1-SNAPSHOT … SUCCESS [ 5.069 s]
[INFO] nacos-core 2.3.1-SNAPSHOT … SUCCESS [ 16.177 s]
[INFO] nacos-encryption-plugin 2.3.1-SNAPSHOT … SUCCESS [ 0.777 s]
[INFO] nacos-config-plugin 2.3.1-SNAPSHOT … SUCCESS [ 0.955 s]
[INFO] nacos-config 2.3.1-SNAPSHOT … SUCCESS [ 16.215 s]
[INFO] nacos-cmdb 2.3.1-SNAPSHOT … SUCCESS [ 1.049 s]
[INFO] nacos-naming 2.3.1-SNAPSHOT … SUCCESS [ 24.958 s]
[INFO] nacos-address 2.3.1-SNAPSHOT … SUCCESS [ 6.971 s]
[INFO] nacos-client 2.3.1-SNAPSHOT … SUCCESS [ 21.000 s]
[INFO] nacos-default-auth-plugin 2.3.1-SNAPSHOT … SUCCESS [ 11.854 s]
[INFO] nacos-default-control-plugin 2.3.1-SNAPSHOT … SUCCESS [ 1.692 s]
[INFO] nacos-default-plugin-all … SUCCESS [ 0.698 s]
[INFO] nacos-istio 2.3.1-SNAPSHOT … SUCCESS [ 31.199 s]
[INFO] nacos-prometheus 2.3.1-SNAPSHOT … SUCCESS [ 3.616 s]
[INFO] nacos-console 2.3.1-SNAPSHOT … SUCCESS [ 6.096 s]
[INFO] nacos-config-test 2.3.1-SNAPSHOT … SUCCESS [ 3.734 s]
[INFO] nacos-naming-test 2.3.1-SNAPSHOT … SUCCESS [ 3.951 s]
[INFO] nacos-core-test 2.3.1-SNAPSHOT … SUCCESS [ 3.782 s]
[INFO] nacos-test 2.3.1-SNAPSHOT … SUCCESS [ 1.108 s]
[INFO] nacos-example 2.3.1-SNAPSHOT … SUCCESS [ 2.315 s]
[INFO] nacos-distribution 2.3.1-SNAPSHOT … SUCCESS [ 1.496 s]
[INFO] nacos-plugin 2.3.1-SNAPSHOT … SUCCESS [ 0.653 s]
[INFO] nacos-plugin-default-impl 2.3.1-SNAPSHOT … SUCCESS [ 0.438 s]
[INFO] Alibaba NACOS 2.3.1-SNAPSHOT … SUCCESS [ 2.099 s]
Nacos用做配置中心时启动报错SocketTimeoutException http://localhost:8848
当使用nacos作为注册中心时,很顺利,进如下配置(仅仅配置了ip和端口)
启动类加@EnableDiscoveryClient注解
nacos作为配置中心
当继续将nacos作为配置中心时
添加加依赖
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
改配置
控制台添加了与项目同名的配置
启动项目后报错
如下:
ERROR 16160 — [ main] c.a.n.c.config.http.ServerHttpAgent : [NACOS SocketTimeoutException httpGet] currentServerAddr:http://localhost:8848
1
看样子是连不上nacos,而且连的是localhost:8848,我明明配置的是ip:8848,为何没用?
查阅官网资料后发现配置的不对,nacos需要在bootstrap.yml或bootstrap.properties进行配置,没在这配置默认配的http://localhost:8848
spring:
nacos-host: 47.99.123.209
nacos-port: 8848
main:
allow-bean-definition-overriding: trueapplication:
name: mall-membercloud:
nacos:discovery:server-addr: ip:8848userName: "nacos"password: "nacos"config:server-addr: ip:8848userName: "nacos"password: "nacos"file-extension: properties
Linux
常用软件:
wget
yum install wget
rsync 远程同步工具
基本语法:
rsync -rvl $pdir/$fname $user@$host:$pdir/$fname
安装命令:
yum install -y rsync
rsync -rvl /opt/lagou/software/ root@192.168.1.115:/opt/lagou/software
git
yum install gitSonarQube
Docker搭建SonarQube服务 - Linux
本文介绍如何在Linux服务器上使用docker简便并快速的搭建SonarQube服务。
参考文档:
Prerequisites and Overview|SonarQube Docs
Installing SonarQube from the Docker Image | SonarQube Docs
本文使用的镜像版本:
docker.io/postgres:12-alpine - sonarqube数据存储服务镜像
docker.io/sonarqube:8.9.0-community - sonarqube的社区版镜像
先决条件:
运行SonarQube的唯一先决条件是在计算机上安装Java(Oracle JRE 11或OpenJDK 11)。
安装jdk11
yum install java-11-openjdk
硬件要求
SonarQube 服务器的小规模(个人或小型团队)实例至少需要 2GB 的 RAM 才能高效运行,并且需要 1GB 的可用 RAM 用于操作系统。如果您要为大型团队或企业安装实例,请考虑以下其他建议。
您需要的磁盘空间量将取决于您使用 SonarQube 分析的代码量。
SonarQube必须安装在具有出色读写性能的硬盘驱动器上。最重要的是,“data”文件夹包含Elasticsearch索引,当服务器启动并运行时,将在其上完成大量的I / O。因此,出色的读写硬盘性能将对SonarQube服务器的整体性能产生重大影响。
SonarQube 不支持服务器端的 32 位系统。但是,SonarQube确实在扫描仪端支持32位系统。
Docker-compose安装Sonar服务
Linux安装docker与docker-compose-plugin
yum install docker # 安装docker
yum install docker-compose-plugin # 安装docker-compose-plugin
docker-compose version
如果dokcer-compose-plugin安装完成后,提示docker-compose命令不存在,需要查找插件安装的位置,然后创建软连接/usr/bin/docker-compose
示例:ln -s /usr/libexec/docker/cli-plugins/docker-compose /usr/bin/docker-compose
Install the Compose plugin | Docker Docs
创建docker-compose.yml
文件内容如下:
version: "3"services:sonarqube:image: sonarqube:8.9.0-communitycontainer_name: sonarqube-8.9depends_on:- dbenvironment:SONAR_JDBC_URL: jdbc:postgresql://postgres-12:5432/sonarSONAR_JDBC_USERNAME: sonarSONAR_JDBC_PASSWORD: sonarvolumes:- sonarqube_data:/opt/sonarqube/data- /opt/sonarqube/extensions:/opt/sonarqube/extensions- /opt/sonarqube/logs:/opt/sonarqube/logs- /opt/sonarqube/conf:/opt/sonarqube/confports:- "9000:9000"db:image: postgres:12-alpinecontainer_name: postgres-12environment:POSTGRES_USER: sonarPOSTGRES_PASSWORD: sonarvolumes:- postgresql_data:/var/lib/postgresql/dataports:- "5432:5432"volumes:sonarqube_data:postgresql_data:
创建并启动容器
docker-compose -f docker-compose.yml up -d
参考命令
启动服务
docker-compose -f docker-compose.yml start
停止服务
docker-compose -f docker-compose.yml stop
重启服务
docker-compose -f docker-compose.yml restart
首次登录sonar服务用户名和密码:admin/admin。强制需要修改密码。
安装汉化插件
在线安装
管理员登录soanr服务,导航到配置>应用市场>插件 ,搜索Chinese ,找到Chinese Pack,点击右侧安装按钮进行在线安装,在线安装会比较慢,安装完成需要重启项目。

线下安装
也可以选择线下手动安装。点击首页链接,进入github项目页面,点击Release,搜索对应的版本进行下载。
下载完成后,讲文件上传到服务器,放到容器内的/opt/sonarqube/extensions/plugins目录下,然后重启服务。
docker-compose.yml文件中,将容器的/opt/sonarqube/extensions目录挂载的宿主机的/opt/sonarqube/extensions目录,所以将插件jar包放到宿主机的/opt/sonarqube/extensions/plugins即可。
docker run --name db -e POSTGRES_USER=sonar -e POSTGRES_PASSWORD=sonar -p 5432:5432 -v /opt/postgresql/data:/opt/postgresql/data -d postgres:12-alpine
docker run --name sonar --link db -e SONARQUBE_JDBC_URL=jdbc:postgresql://192.168.1.113:5432/sonar -e SONARQUBE_JDBC_USERNAME=sonar -e SONARQUBE_JDBC_PASSWORD=sonar -p 9090:9090 -d sonarqube
Sonarqube扫描原理
SonarQube的扫描原理主要包括以下步骤:
- 源代码收集:SonarQube支持多种代码托管系统,如Git、SVN等,允许用户配置项目仓库地址以自动获取源代码。
- 语言解析:SonarQube能够处理多种编程语言,并将源代码转换成抽象语法树(AST),以便更有效地分析和理解代码。
- 指标计算:在这个阶段,SonarQube会根据代码的不同度量指标,如代码覆盖率、代码复杂度和代码重复率,评估代码质量和可维护性。
- 问题检测:SonarQube结合了语法和语义分析,以及内置的规则集,来检测代码中的潜在问题和违反编码规范的情况。
- 问题汇总:一旦检测到问题,SonarQube会将其汇总和分类,形成包含问题详细描述、位置和修复建议的完整代码质量报告。
- 持续集成:SonarQube可以与其他持续集成/持续部署(CI/CD)工具集成,实现代码质量的持续监测,并在代码提交时自动触发扫描和分析过程。
- 持续分析:SonarQube不仅可以进行单次扫描,还支持持续分析,即在代码提交或构建过程中自动进行代码质量的检查。
综上所述,SonarQube的扫描原理涉及到代码的收集、解析、指标的计算、问题的检测和问题的汇总,最终通过持续集成和持续分析来实现对代码质量的持续监控和管理
Zabbix
Docker安装启动
- 下载zabbix/zabbix-appliance镜像
docker pull zabbix/zabbix-appliance:latest
- 启动容器,要先确保端口没被占用
docker run --name zabbix-app -t -d\-p 5231:80 -p 10051:10051\-v zabbix_data:/var/lib/mysql\-v /etc/timezone:/etc/timezone \-v /etc/localtime:/etc/localtime \-e PHP_TZ="Asia/Shanghai"\zabbix/zabbix-appliance
- 查看是否运行
docker ps
-
在浏览器中输入虚拟机ip:5231,访问zabbix面板
-
初始账户密码:Admin zabbix
[zabbix-Get value from agent failed: cannot connect to [127.0.0.1]:10050]: [111] Connection refused
问题描述:

监控zabbix服务端这台服务器,然后显示Get value from agent failed: cannot connect to [[127.0.0.1]:10050]: [111] Connection refused
看到agent然后又看到10050端口
直接telnet语句去检测
第一种:端口不通
解决方法:
1、a``gent端的ip为192.168.85.11,``server端的ip为192.168.85.11
#本地电脑WIN7系统,执行语句 telnet 192.168.85.11 10051 查看agent端口是否开启

#本地电脑WIN7系统,执行语句 telnet 192.168.85.11 10050 查看server端口是否开启

#可以看到是10050这个端口不通,然后回到服务端查看agent服务状态,看到原来没开启服务原因

#开启agent服务

#然后就没有报错了!
ps -ef | grep zabbix-agent 看是否有zabbix-agent的进程。

#再配置一下开机自启动agent服务
systemctl enable zabbix-agent.service
Traefix
Linux Traefik 工具 dashboard远程访问
前言
Træfɪk 是一个云原生的新型的 HTTP 反向代理、负载均衡软件,能轻易的部署微服务。它支持多种后端 (Docker, Swarm, Mesos/Marathon, Consul, Etcd, Zookeeper, BoltDB, Rest API, file…) , 可以对配置进行自动化、动态的管理.
Træfɪk 支持docker一键部署,内置 Web UI,管理相对方便,下面介绍Linux 本地 docker 一键部署 traefik +cpolar 内网穿透工具实现远程访问Træfɪk Web UI 管理界面!
1. Docker 部署 Træfɪk
在任意目录,创建一个名称为 docker-compose.yml文件
vim docker-compose.yml把下面参数复制 进去,本例主要目的是演示如何远程访问Træfɪk dashboard 界面,如果需要更复杂的配置,可以参考官方文档进行详细参数配置!
version: "3"services:traefik:image: traefik:v3.0.0-beta3ports:- 8080:8080command: "--api=true --api.dashboard=true --api.insecure=true"tips: 上面参数挂载到宿主机8080端口,如需修改其他端口,可以自行修改,这里默认使用8080

输入完成后,保存配置文件,然后执行docker compose up,进行部署,如果卡在上述界面,可以先Ctrl+C退出,然后输入docker ps -a查询出traefik 容器ID,然后使用docker start 容器ID命令启动即可

启动成功后,输入docker ps 命令即可看到运行的traefik 容器

2. 本地访问traefik测试
本地部署完成后,我们在局域网设备中通过局域网方式访问Linux 8080 端口,即可看到traefik deshboard 界面, 本地访问就成功了,下面安装cpolar 内网穿透工具,实现远程访问

3. Linux 安装cpolar
上面在本地Linux中成功部署了Traefik,并局域网访问ok,下面我们在Linux安装cpolar内网穿透工具,通过cpolar 转发本地端口映射的http公网地址,我们可以很容易实现远程访问,而无需自己注册域名购买云服务器.下面是安装cpolar步骤
cpolar官网地址: https://www.cpolar.com
- 使用一键脚本安装命令
curl -L https://www.cpolar.com/static/downloads/install-release-cpolar.sh | sudo bash- 向系统添加服务
sudo systemctl enable cpolar- 启动cpolar服务
sudo systemctl start cpolarcpolar安装成功后,在外部浏览器上访问Linux 的9200端口即:【http://局域网ip:9200】,使用cpolar账号登录,登录后即可看到cpolar web 配置界面,结下来在web 管理界面配置即可

4. 配置Traefik公网访问地址
点击左侧仪表盘的隧道管理——创建隧道,创建一个Traefik的cpolar 公网地址隧道!
- 隧道名称:可自定义命名,注意不要与已有的隧道名称重复
- 协议:选择http
- 本地地址:8080 (局域网访问的端口)
- 域名类型:免费选择随机域名
- 地区:选择China
点击创建

隧道创建成功后,点击左侧的状态——在线隧道列表,查看所生成的公网访问地址,有两种访问方式,一种是http 和https

5. 公网远程访问Traefik
使用上面的cpolar https公网地址,在任意设备的浏览器进行访问,即可成功看到我们Traefik dashboard界面,这样一个公网地址且可以远程访问就创建好了,使用了cpolar的公网域名,无需自己购买云服务器,即可发布到公网进行远程访问,后续Traefik设置方法,可以参考官方文档进行学习!

6. 固定Traefik公网地址
由于以上使用cpolar所创建的隧道使用的是随机公网地址,24小时内会随机变化,不利于长期远程访问。因此我们可以为其配置二级子域名,该地址为固定地址,不会随机变化【ps:http://cpolar.cn已备案】
注意需要将cpolar套餐升级至基础套餐或以上,且每个套餐对应的带宽不一样。【http://cpolar.cn已备案】
登录cpolar官网,点击左侧的预留,选择保留二级子域名,设置一个二级子域名名称,点击保留,保留成功后复制保留的二级子域名名称

保留成功后复制保留成功的二级子域名的名称

返回登录cpolar web UI管理界面,点击左侧仪表盘的隧道管理——隧道列表,找到所要配置的隧道,点击右侧的编辑

修改隧道信息,将保留成功的二级子域名配置到隧道中
- 域名类型:选择二级子域名
- Sub Domain:填写保留成功的二级子域名
点击更新(注意,点击一次更新即可,不需要重复提交)

更新完成后,打开在线隧道列表,此时可以看到公网地址已经发生变化,地址名称也变成了固定的二级子域名名称的域名

最后,我们使用固定的公网地址访问,可以看到访问成功,这样一个固定且永久不变的公网地址就设置好了,随时随地都可以远程访问Traefik界面,提高工作效率!!

转载自cpolar极点云文章:Linux Traefik 工具 Dashboard远程访问
Graylog
DockerCompose 一键部署graylog
docker-compose配置参考:https://docs.graylog.org/en/3.3/pages/installation/docker.html
# docker-compose配置参考:https://docs.graylog.org/en/3.3/pages/installation/docker.html
version: '3'services:mongo:image: mongo:3container_name: graylog_demo_mongorestart: unless-stopped# volumes:# - ./graylog/mongo_data:/data/dbnetworks:- graylogelasticsearch:image: elasticsearchcontainer_name: graylog_demo_elasticsearchrestart: unless-stopped# volumes:# - ./graylog/es_data:/usr/share/elasticsearch/dataenvironment:- http.host=0.0.0.0- transport.host=localhost- network.host=0.0.0.0- "ES_JAVA_OPTS=-Xms512m -Xmx512m"ulimits:memlock:soft: -1hard: -1deploy:resources:limits:memory: 1gnetworks:- grayloggraylog:image: graylog/graylog:3.3container_name: graylog_demo_graylogrestart: unless-stopped# volumes:# - ./graylog/graylog_data_journal:/usr/share/graylog/data/journalenvironment:- GRAYLOG_PASSWORD_SECRET=somepasswordpepper # CHANGE ME (must be at least 16 characters)!- GRAYLOG_ROOT_PASSWORD_SHA2=8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918 # Password: admin- GRAYLOG_HTTP_EXTERNAL_URI=http://www.zhengqingya.com:9001/ # TODO 这里填写自己的ip地址ports:# Graylog web interface and REST API- 9001:9000# Syslog TCP- 1514:1514# Syslog UDP- 1514:1514/udp# GELF TCP- 12201:12201# GELF UDP- 12201:12201/udpnetworks:- graylogdepends_on:- mongo- elasticsearch# 网桥graylog -> 方便相互通讯
networks:graylog:driver: bridge创建上面的文件为docker-compose.yml,然后直接启动就可以
docker-compose -f docker-compose-graylog.yml -p graylog_demo up -d访问地址为 localhost:9001, 默认登录账号密码:admin/admin
Gitlab
代码分析工具
有几个常用的Java源码扫描工具可以帮助您进行源代码分析和检查。以下是其中一些工具:
FindBugs:FindBugs是一个静态分析工具,用于查找Java代码中的潜在缺陷和错误。它可以检测出空指针引用、资源未关闭、不良的代码实践等问题。FindBugs已经停止维护,但仍然是一个常用的工具。
PMD:PMD是另一个流行的静态代码分析工具,用于检测Java代码中的潜在问题和不良实践。它可以检查代码中的重复代码、未使用的变量、低效的代码等。
Checkstyle:Checkstyle是一个用于强制执行编码规范的工具,它可以确保代码符合一致的样式和规范。它可以检查代码缩进、命名约定、注释规范等。
SonarQube:SonarQube是一个功能强大的代码质量管理平台,可以对Java代码进行静态分析,并提供详细的代码质量指标和报告。它整合了多个静态分析工具,包括FindBugs、PMD和Checkstyle等。
这些工具可以作为独立的命令行工具使用,也可以与集成开发环境(IDE)或持续集成(CI)工具集成,以便在开发过程中自动执行代码扫描和检查。
请注意,这些工具都有自己的配置和规则集,您可以根据项目的需求进行自定义配置。此外,这些工具只能检测到一部分潜在问题,仍然需要开发人员进行代码审查和测试来确保代码质量。
建议您根据项目的具体需求选择适合的工具,并根据项目的要求进行配置和使用。
可视化工具
ES集群可视化管理工具-Cerebro
文章目录
-
-
- \1. Cerebro简介
- \2. 环境要求
- \3. Cerebro安装
- \4. 访问Cerebro
- \5. 面板介绍
- \6. LDAP集成
- \7. Docker方式安装
-
1. Cerebro简介
Cerebro是一个开源(MIT许可)Elasticsearch web管理工具,使用Scala、Play框架、AngularJS和Bootstrap构建。
GitHub地址:https://github.com/lmenezes/cerebro
2. 环境要求
软件环境:Cerebro需要Java 1.8或更高版本才能运行。
硬件配置推荐:4C 8G 500G,俄一般会和Kibana部署在同一台机器
3. Cerebro安装
从https://github.com/lmenezes/cerebro/releases下载最新安装包,本文档采用rpm方式安装,文末会有docker容器化部署介绍。
1、准备基础环境
yum install java -y
wget https://github.com/lmenezes/cerebro/releases/download/v0.9.2/cerebro-0.9.2-1.noarch.rpm
[root@kibana-164 /opt]# rpm -ivh cerebro-0.9.2-1.noarch.rpm
2、修改配置文件
~]# vim /etc/cerebro/application.conf
data.path = "/tmp/cerebro.db" #更改数据路径3、启动cerebro
[root@kibana ~]# systemctl start cerebro
[root@kibana ~]# systemctl enable cerebro4、检查端口?
cerebro侦听(默认为0.0.0.0:9000)
[root@kibana-164 ~]# lsof -i:9000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 1676 cerebro 130u IPv6 22234 0t0 TCP *:cslistener (LISTEN)补充其他方式启动:
bin/cerebro -Dhttp.port=1234 -Dhttp.address=127.0.0.1
4. 访问Cerebro
http://IP:9000



5. 面板介绍
集群名称:my-es
节点数:3 nodes
索引数:8 indices
分片数:16 shards
文档数:34 docs
磁盘使用量:21.08M6. LDAP集成
LDAP可以使用环境变量进行配置。如果通常使用docker运行cerebro,则可以传递包含所有env var的文件。该文件如下所示
#将其设置为ldap以激活ldap授权
AUTH_TYPE = ldap#您的ldap网址
LDAP_URL = ldap://exammple.com:389LDAP_BASE_DN = OU =用户,DC =示例,DC = com#通常方法应为“简单”,否则,将其设置为SASL机制
LDAP_METHOD =简单#用户模板执行string.format()操作,其中
先传入#用户名,然后传入base-dn。一些实例
# - %S =>假用户原封不动
# - %s@domain.com =>追加“@ domain.com”到用户名
# - UID =%S,%S =>通常的OpenLDAP的情况下
LDAP_USER_TEMPLATE=%s@example.com#可以执行搜索的用户标识符
LDAP_BIND_DN=admin@example.com
LDAP_BIND_PWD =管理员密码#组成员资格设置(可选)#如果未设置将使用LDAP_BASE_DN
# LDAP_GROUP_BASE_DN = OU =用户,DC =示例,DC = com#代表用户的属性,例如uid或mail
# LDAP_USER_ATTR = mail#如果未设置,将使用
LDAP_USER_TEMPLATE # LDAP_USER_ATTR_TEMPLATE =%s#用于测试组成员资格的过滤器。如果该属性是空的,则没有组成员资格检查
# AD示例=>的memberOf = CN = MYGROUP,OU = ouofthegroup,DC =域,DC = COM
# OpenLDAP的例子=> CN = MYGROUP
# LDAP_GROUP =的memberOf =的memberOf = CN = mygroup,ou =该组的其他人,DC =域,DC = com7. Docker方式安装
docker run -p 9000:9000 lmenezes/cerebro
也可以在官方docker hub仓库中找到官方docker映像。
docker run -p 9000:9000 --env-file env-ldap lmenezes/cerebro #可进行传参
可根据自己实际需求制作Docker镜像~
FROM openjdk:11-jre-slim
ENV CEREBRO_VERSION 0.9.2RUN apt-get update \&& apt-get install -y wget \&& rm -rf /var/lib/apt/lists/* \&& mkdir -p /opt/cerebro/logs \&& wget -qO- https://github.com/lmenezes/cerebro/releases/download/v${CEREBRO_VERSION}/cerebro-${CEREBRO_VERSION}.tgz \| tar xzv --strip-components 1 -C /opt/cerebro \&& sed -i '/<appender-ref ref="FILE"\/>/d' /opt/cerebro/conf/logback.xml \&& addgroup -gid 1000 cerebro \&& adduser -gid 1000 -uid 1000 cerebro \&& chown -R cerebro:cerebro /opt/cerebroWORKDIR /opt/cerebro
USER cerebroENTRYPOINT [ "/opt/cerebro/bin/cerebro" ]
zkui:好用的zookeeper ui工具
1 说明
1.1 项目地址
https://github.com/DeemOpen/zkui
1.2 安装方式
maven编译后,java控制台启动
1.3 准备事项
- 安装好JDK 7.0+,配置好JAVA_HOME。(java命令可用即可:java -version)
- 安装好MAVEN,配置好M2_HOME。(mvn命令可用即可: mvn -version)
- 已经安装了一个zookeeper。《Zookeeper安装》看这里。(默认地址和端口: localhost:2181)
- 下载zkui源码zip包,并解压到目录C:\,获得解压后路径:C:\zkui-master。(zkui与zookeeper安装在同一台设备上)
2 编译
cd C:\zkui-mastermvn clean package
3 启动
将C:\zkui-master\config.cfg(模块可用,也可以根据需要进行修改)拷贝到C:\zkui-master\target目录下(config.cfg与zkui-xx.jar文件同目录即可)。
zkui与zookeeper安装在同一台设备上,所以config.cfg不用任何修改就能够使用。如果不在同一台设备上,需要修改config.cfg文件。
java -jar target/zkui-2.0-SNAPSHOT-jar-with-dependencies.jar
4 访问控制台
http://localhost:9090
username: admin, pwd: manager (Admin privileges, CRUD operations supported)
username: appconfig, pwd: appconfig (Readonly privileges, Read operations supported)
5 其它
linux下运行:
nohup java -jar zkui-2.0-SNAPSHOT-jar-with-dependencies.jar &
Linux 安装禅道
一.下载禅官网:https://www.zentao.net/download/zentaopms18.3-82231.html

linux中下载
wget https://www.zentao.net/dl/zentao/18.3/ZenTaoPMS.18.3.zbox_64.tar.gz
(之前很早下载过所以和上面显示的版本比相同)

二.安装禅道
1.解压禅道的压缩包
将安装包直接解压到/opt目录下
特别说明:不要 解压到别的⽬录再拷⻉到/opt/,因为这样会导致⽂件的所有者和读写权限改变, 也不要解压后把整个⽬录777权限 。
命令:
sudo tar -zxvf ZenTaoPMS.18.3.zbox_64.tar.gz -C /opt
2.启动禅道
执行/opt/zbox/zbox start命令开启Apache和Mysql。
执⾏/opt/zbox/zbox stop命令停⽌Apache和Mysql。
执⾏/opt/zbox/zbox restart命令重启Apache和Mysql。
3.访问禅道
启动 Apache和Mysql服务后,
浏览器直接访问 http://禅道服务器ip:apache端⼝ 即可访问和登录禅道。
注:如果⽹⻚⽆法访问,请先关闭禅道所在电脑的防⽕墙和selinux再刷新⽹⻚访问试⼀下。(使⽤云服务器请注意在安全组中开放apache使⽤端⼝)
禅道默认管理员帐号是 admin,密码 123456。4.查看服务器IP的方法
5.浏览器直接访问即可
三.遇到的问题

大概率是因为禅道所在电脑的防⽕墙和selinux未关闭
首先查看防火墙的状态
systemctl status firewalld

关闭防火墙
systemctl stop firewalld
再次查看防火墙状态(已关闭)

最好把防火墙开机自启也关闭,避免不必要的麻烦
systemctl disable firewalld.service
之后再关闭selinux(可临时关闭也可以永久性关闭)
首先可以查看一下状态(注意看Current mode的状态)
/usr/sbin/sestatus
关闭前Current mode的状态为 enforcing
这里选择了永久性关闭
vim /etc/sysconfig/selinux
selinux=enforcing 改为 selinux=disabled

再次查看状态(请记得重启reboot)
/usr/sbin/sestatus
最后,再次通过浏览器访问禅道!!!
成功!!!
大数据组件
Hbase
1、拉取hbase镜像
# 查找镜像
docker search hbase# 拉取镜像
docker pull harisekhon/hbase:latest


2、创建容器
# 未指定主机名
docker run -d --name hbase -p 2181:2181 -p 16010:16010 -p 16020:16020 -p 16030:16030 harisekhon/hbase:latest# 指定主机名
docker run -d -h hbase \
-p 2181:2181 -p 8080:8080 -p 8085:8085 -p 9090:9090 \
-p 9095:9095 -p 16000:16000 -p 16010:16010 -p 16020:16020 \
-p 16201:16201 -p 16301:16301 \
--name hbase harisekhon/hbase:latest
这里注意一点,对于端口映射,hbase用到了很多端口,有的地方直接使用-P参数,而不是用-p做端口一一映射。
同时,-h选项中的参数hbase名字不要修改,否则会连不上节点。
docker run -d --name hbase -P harisekhon/hbase
如果通过-P参数,会将容器内部所有监听的端口都映射为随机端口,我们可以看看容器状态:

其中,16010端口是hbase提供的webui界面暴露的端口,映射为了32770,我们可以通过虚拟机地址,以及这个端口访问hbase webui。
hbase webui的地址如下:
http://192.168.1.113:16010/master-status

到了这里,通过web界面能够看到hbase状态,然后,可以进入容器,运行hbase shell,执行建表,添加数据,扫描数据都没有问题。但是如果外部程序,比如java需要操作hbase,就非常麻烦。
所以,这里不建议直接使用-P(大写)的方式启动hbase。
推荐的启动方式:
docker run -d –name hbase -p 2181:2181 -p 16010:16010 -p 16020:16020 -p 16030:16030 harisekhon/hbase
不推荐的启动方式:
docker run -d --name -P harisekhon/hbase
3、测试容器
# 进入容器
docker exec -it hbase /bin/bash# 启动shell
hbase shell# 查看表名列表
list# 创建表
# 语法:create <table>, {NAME => <family>, VERSIONS => <VERSIONS>}
create 'userinfo',{NAME => 'user', VERSIONS => 2},{NAME => 'score', VERSIONS => 2}

Clickhouse
项目常用组件
Hutool
常用工具类
<dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.5.2</version>
</dependency>
EasyExcel
excel文件导入导出
<dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>3.2.0</version>
</dependency>
Knife4j
接口文档
<dependency><groupId>com.github.xiaoymin</groupId><artifactId>knife4j-spring-boot-starter</artifactId><version>2.0.7</version>
</dependency>
Elasticsearch
搜索引擎
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.6.2</version>
</dependency>
Fastjson
json解析
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.70</version>
</dependency>
Aspectj
Aop切面
<dependency><groupId>org.aspectj</groupId><artifactId>aspectjweaver</artifactId>
</dependency>
Admin-server
服务端监控
<dependency><groupId>de.codecentric</groupId><artifactId>spring-boot-admin-starter-server</artifactId><version>2.6.6</version>
</dependency>
相关配置
server:port: 6091
spring:application:name: rms-monitorboot:admin:monitor:default-timeout: 30000ui:title: RMS监控中心server:enabled: true
Admin-client
客户端监控
<dependency><groupId>de.codecentric</groupId><artifactId>spring-boot-admin-starter-client</artifactId><version>2.6.6</version>
</dependency>
相关配置
server:port: 6080
spring:application:name: rms-risk-serviceservlet:multipart:max-file-size: 10MBmax-request-size: 20MBmvc:path-match:matching-strategy: ant_path_matcherboot:admin:monitor:default-timeout: 30000client:
# enabled: trueurl: http://192.168.1.51:6091instance:service-url: http://192.168.1.51:6091
Actuator
健康检查
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
Security
权限管理
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-security</artifactId>
</dependency>
相关配置
Mysql
数据库
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.6</version><scope>runtime</scope>
</dependency>
相关配置
datasource:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://192.168.1.101:3306/rms-system?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghaiusername: rootpassword: Rlyy#234
Mybatis-Plus
数据持久化
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.2</version>
</dependency>
相关配置
mybatis-plus:configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImplmapper-locations: classpath:/mapper/*.xmltype-aliases-package: com.rlcould.system.entity
Lombok
实体代码注解组件
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId>
</dependency>
Jwt
token组件
<dependency><groupId>com.auth0</groupId><artifactId>java-jwt</artifactId><version>4.0.0</version>
</dependency>
相关代码
package com.xxx.system.util;import cn.hutool.core.util.StrUtil;
import com.auth0.jwt.JWT;
import com.auth0.jwt.JWTCreator;
import com.auth0.jwt.algorithms.Algorithm;
import com.rlcloud.common.utils.JwtTokenThreadLocal;
import com.rlcloud.system.entity.User;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;/*** @version v1.0 创建时间:11:35* @author: 作者:xxx* @description 描述:auth0.jwt工具类*/
public class JwtHelper {//一般token过期时间30分钟或者1个小时private static long TOKEN_EXPIRE = 1000*60*30; //30分钟,单位为毫秒private static String salt = "xxxxxx"; //秘钥//1. 创建tokenpublic static String createToken(Map<String,Object> maps){//设置过期时间Date expiresAt = new Date(System.currentTimeMillis() + TOKEN_EXPIRE);Algorithm alg = Algorithm.HMAC256(salt); //秘钥进行加密,类似md5JWTCreator.Builder builder = JWT.create();for(String key : maps.keySet()){builder.withClaim(key, String.valueOf(maps.get(key)));}String token = builder.withExpiresAt(expiresAt).sign(alg);return token;}//2. 解析tokenpublic static String decode(String token, String who){if(StrUtil.isBlank(token)){throw new RuntimeException("非法用户,请登录");}return JWT.decode(token).getClaim(who).asString();}public static String getUserId(){return decode(JwtTokenThreadLocal.get(), JwtUserEnum.userId.name());}public static Integer getTenantId(){return Integer.valueOf(decode(JwtTokenThreadLocal.get(), JwtUserEnum.tenantId.name()));}//获取当前用户信息public static User getUser(){String token = JwtTokenThreadLocal.get();User curUser = new User();curUser.setTenantId(Integer.valueOf(decode(token, JwtUserEnum.tenantId.name())));curUser.setId(Long.valueOf(decode(token, JwtUserEnum.userId.name())));curUser.setName(decode(token, JwtUserEnum.userName.name()));curUser.setDeptId(decode(token, JwtUserEnum.deptId.name()));curUser.setDeptName(decode(token, JwtUserEnum.deptName.name()));curUser.setSuperLevel(Integer.valueOf(decode(token, JwtUserEnum.supperLevel.name())));return curUser;}//3. 校验token是否过期public static boolean verify(String token){//跟当前时间进行比较,如果超过当前时间返回true(过期),如果没有超过返回false(未过期)。return !JWT.decode(token).getExpiresAt().after(new Date());}public static void main(String[] args) {Map<String, Object> maps = new HashMap<>();maps.put(JwtUserEnum.userId.name(), "1");maps.put(JwtUserEnum.userName.name(), "tony");maps.put(JwtUserEnum.deptId.name(), "2");maps.put(JwtUserEnum.deptName.name(), "网易");maps.put("supperLevel", 9);String t = JwtHelper.createToken(maps);System.out.println(t);String userId = JwtHelper.decode(t, JwtUserEnum.userId.name());System.out.println(userId);String name = JwtHelper.decode(t, JwtUserEnum.userName.name());System.out.println(name);String supperLevel = JwtHelper.decode(t, "supperLevel");System.out.println(supperLevel);try {Thread.sleep(3000); //睡眠3秒}catch (Exception e){}System.out.println(JwtHelper.verify(t));}
}
枚举类
package com.rlcloud.system.util;/*** @version v1.0 创建时间:2023/11/20 15:59* @author: 作者:xxx* @description 描述:用于User信息获取,规定下面值*/
public enum JwtUserEnum {tenantId("tenant", 0),userId("userId",1),userName("userName",2),deptId("deptId",3),deptName("deptName",4),supperLevel("supperLevel",5);JwtUserEnum(String who, int i) {}
}Logstash-logback
集成Logstash
<dependency><groupId>net.logstash.logback</groupId><artifactId>logstash-logback-encoder</artifactId><version>5.3</version>
</dependency>
配置文件:logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration>
<configuration><include resource="org/springframework/boot/logging/logback/defaults.xml"/><include resource="org/springframework/boot/logging/logback/console-appender.xml"/><!--应用名称--><property name="SERVER_NAME" value="rms-risk-service"/><!--日志文件保存路径--><property name="LOG_FILE_PATH" value="${LOG_FILE:-${LOG_PATH:-${LOG_TEMP:-${java.io.tmpdir:-/tmp}}}/logs}"/><contextName>${APP_NAME}</contextName><!--每天记录日志到文件appender--><appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${LOG_FILE_PATH}/${APP_NAME}-%d{yyyy-MM-dd}.log</fileNamePattern><maxHistory>30</maxHistory></rollingPolicy><encoder><pattern>${FILE_LOG_PATTERN}</pattern></encoder></appender><!--输出到logstash的appender--><appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender"><!--可以访问的logstash日志收集端口--><destination>192.168.1.55:4560</destination><encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/></appender><root level="INFO"><appender-ref ref="CONSOLE"/><appender-ref ref="FILE"/><appender-ref ref="LOGSTASH"/></root>
</configuration>
Nacos
微服务配置与注册
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId><version>2.2.5.RELEASE</version>
</dependency>
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId><version>2.2.5.RELEASE</version>
</dependency>
Redis
缓存存储
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><version>2.2.8.RELEASE</version>
</dependency>
Redisson
分布式锁
<dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId><version>2.2.8.RELEASE</version>
</dependency>
Spring-boot-mail
发邮件
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-mail</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-thymeleaf</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-configuration-processor</artifactId><optional>true</optional>
</dependency>
相关代码
package com.rlcloud.mail.config;import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import com.rlcloud.mail.service.KingliMailSender;@Configuration
@EnableConfigurationProperties(MailProperties.class)
public class MailConfig {@Beanpublic KingliMailSender initMailSender() {return new KingliMailSender(); }}package com.rlcloud.mail.config;import java.nio.charset.Charset;
import java.util.HashMap;
import java.util.Map;import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Configuration;import lombok.Data;@Data
@Configuration
@ConfigurationProperties(prefix="spring.mail")
public class MailProperties {private String host;private String username;private String password;private Integer port;private String protocol = "smtp";private Charset defaultEncoding;private Map<String, String> properties = new HashMap<>();}package com.rlcloud.mail.constant;public interface MailConstant {public static final String CONFIG_ERROR = "未配置邮件服务!";public static final String SEND_ERROR = "邮件发送失败!";public static final String PARAM_ERROR = "参数错误!";public static final String SUCCESS = "发送成功!";}package com.rlcloud.mail.service;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.mail.MailException;
import org.springframework.mail.SimpleMailMessage;
import org.springframework.mail.javamail.JavaMailSenderImpl;
import org.springframework.util.StringUtils;
import com.rlcloud.mail.config.MailProperties;
import com.rlcloud.mail.constant.MailConstant;
import lombok.extern.slf4j.Slf4j;@Slf4j
public class KingliMailSender {@AutowiredMailProperties mailProperties;@AutowiredJavaMailSenderImpl javaMailSender;public String simpleSend(String subject, String[] to, String[] cc, String[] bcc, String content) {if (!check()) {return MailConstant.CONFIG_ERROR;}SimpleMailMessage simple = new SimpleMailMessage();simple.setSubject(subject);simple.setTo(to);simple.setFrom(mailProperties.getUsername());if (cc != null && cc.length > 0) {simple.setCc(cc);}if (bcc != null && bcc.length > 0) {simple.setBcc(bcc);}simple.setText(content);try {javaMailSender.send(simple);log.debug(String.format("邮件发送成功!【%s】To: %s", subject, to));} catch (MailException e) {e.printStackTrace();log.error("发送邮件失败!" + e.getMessage());return MailConstant.SEND_ERROR + e.getMessage();}return MailConstant.SUCCESS;}public String simpleSend(String subject, String to, String cc, String bcc, String content) {String[] toArray = to != null ? to.split(",") : null;String[] ccArray = cc != null ? cc.split(",") : null;String[] bccArray = bcc != null ? bcc.split(",") : null;return simpleSend(subject, toArray, ccArray, bccArray, content);}public String simpleSend(SimpleMailMessage smm) {if (!check()) {return MailConstant.CONFIG_ERROR;}if (smm == null) {return MailConstant.PARAM_ERROR + "不能发送空消息!";}try {smm.setFrom(mailProperties.getUsername());javaMailSender.send(smm);log.debug(String.format("邮件发送成功!【%s】To: %s", smm.getSubject(), smm.getTo()));} catch (MailException e) {e.printStackTrace();log.error("发送邮件失败!" + e.getMessage());return MailConstant.SEND_ERROR + e.getMessage();}return MailConstant.SUCCESS;}private boolean check() {if (StringUtils.isEmpty(javaMailSender.getHost())) {return false;}if (StringUtils.isEmpty(javaMailSender.getUsername())) {return false;}if (StringUtils.isEmpty(javaMailSender.getPassword())) {return false;}return true;}
}xxl-job
官网地址:https://www.xuxueli.com/xxl-job/
https://gitee.com/xuxueli0323/xxl-job
Poi-tl Word 模板引擎
<!-- Poi-tl Word 模板引擎-->
<dependency><groupId>com.deepoove</groupId><artifactId>poi-tl</artifactId><version>1.9.1</version>
</dependency>
Arthas
官网地址:https://arthas.aliyun.com/doc/download.html
curl -O https://arthas.aliyun.com/arthas-boot.jar
1、项目集成Skywalking
2、Elk安装资料整理
3、Skywalking软件安装整理
4、系统集成Gateway、nacos
5、集成Sonarqube
Prometheus
maven依赖:
<dependency><groupId>io.micrometer</groupId><artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
配置文件:prometheus.yml
# my global config
global:scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.# scrape_timeout is set to the global default (10s).# Alertmanager configuration
alerting:alertmanagers:- static_configs:- targets:- alertmanager:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:# - "first_rules.yml"# - "second_rules.yml"# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: "prometheus"# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ["192.168.1.56:9090"]
# - job_name: 'mysql'
# static_configs:
# - targets: ['192.168.1.101:3306']- job_name: 'nacos'# metrics_path defaults to '/metrics'# scheme defaults to 'http'.metrics_path: '/nacos/actuator/prometheus'static_configs:- targets: ['192.168.1.111:8848']# # 新添加的采集目标elasticsearch服务
# - job_name: "elasticsearch"
# static_configs:
# - targets: ["192.168.1.55:9200"]
#
# # 新添加的采集目标web前端服务
# - job_name: "rms-web"
# static_configs:
# - targets: ["192.168.1.2:3110"]
#
# # 新添加的采集目标web前端服务
# - job_name: "skywalking"
# static_configs:
# - targets: ["192.168.1.52:8686"]
文件转换
Markdown文件转换成Word文档
项目框架使用
Mysql转MarkDown文件
package com.rlcloud.risk.util;import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;
import java.util.regex.Matcher;
import java.util.regex.Pattern;/*** Mysql转MarkDown文件*/
public class Mysql2Markdown {public static void main(String[] args) {System.out.println("请输入文件路径,例如:d:\\outsourcing.sql");Scanner sc = new Scanner(System.in);String input = sc.nextLine();String path = "D:\\outsourcing.sql"; //文件路径File file = new File(path);StringBuffer sbf = new StringBuffer();BufferedReader reader = null;StringBuffer table_name_buff = new StringBuffer();String tableString;int tablenum = 0;FileWriter fileWriter = null;//把sql文件按照空行分段,每一段存到map1中,num表示有多少段int num = 0;Map<String, String> sql_section_map = new HashMap<String,String>();Map<String, String> table_section_map = new HashMap<String,String>(); //存储表片段Map<String, String> table_name_map = new HashMap<String,String>(); //存储表名Map<String, String> table_description_map = new HashMap<String,String>(); //存储表描述Map<String, String> row_name_map = new HashMap<String,String>(); //存储表列名Map<String, String> map_row_type = new HashMap<String,String>(); //存储列类型Map<String, String> map_row_description = new HashMap<String,String>(); //存储列描述try {reader = new BufferedReader(new FileReader(file));String tempStr;while ((tempStr = reader.readLine()) != null) {sbf.append(tempStr+"\n");if(tempStr.equals("")){sql_section_map.put("duan"+num, sbf.toString());sbf.setLength(0);num++;}}reader.close();String aaString = sbf.toString(); //读取sql文件后转为字符串String table_name_regex = "CREATE TABLE `(\\S*)`"; //匹配表名String table_description_regex = "COMMENT='([\u4e00-\u9fa5_a-zA-Z0-9\\S]*)';"; //匹配表描述String regex_row_description = "COMMENT '([\u4e00-\u9fa5_a-zA-Z0-9\\S]*)',"; //匹配列描述String table_row_name_regex = " `(\\S*)`"; //匹配字段String regex_type = " `(\\S*)` (\\S*)"; //匹配字段类型// 创建 Pattern 对象Pattern table_name_Pattern = Pattern.compile(table_name_regex);Pattern table_description_Pattern = Pattern.compile(table_description_regex);Pattern table_row_name_Pattern = Pattern.compile(table_row_name_regex);Pattern pattern_row_type = Pattern.compile(regex_type);Pattern pattern_row_description = Pattern.compile(regex_row_description);// 现在创建 matcher 对象for (int i = 0; i < num; i++) {tableString = sql_section_map.get("duan"+i);Matcher m1 = table_name_Pattern.matcher(tableString);if(m1.find()){int a = m1.start(1);//m1.find(a); //find(int start) //有参函数表示 重新设置该匹配器,然后尝试从指定的索引开始找,start:索引。table_name_buff.append(m1.group(1)+",");table_section_map.put("table"+tablenum, sql_section_map.get("duan"+i));tablenum++;}else{sql_section_map.remove("duan"+i);}}/**************************************段处理完成,下面根据获取的表的数量进行解析************************************************/String [] table_name_array = table_name_buff.toString().split(","); //表名for (int i = 0; i < table_name_array.length; i++) {table_name_map.put("table"+i, table_name_array[i]);}/*** 每一行分开,匹配列名*/String aa = "";String bb = "";String cc = "";for (int i = 0; i < table_section_map.size(); i++) {String[] aStrings = table_section_map.get("table"+i).split("\n");Matcher m2 = table_description_Pattern.matcher(table_section_map.get("table"+i));if (m2.find()) {table_description_map.put("table"+i, m2.group(1));//System.out.println("table"+i+":"+table_description_map.get("table"+i));}for (int j = 0; j < aStrings.length; j++) {Matcher m3 = table_row_name_Pattern.matcher(aStrings[j]);Matcher m4 = pattern_row_type.matcher(aStrings[j]);Matcher m5 = pattern_row_description.matcher(aStrings[j]);//System.out.println(m3.groupCount());while(m3.find()){aa +=m3.group(1)+",";}while(m4.find()){bb +=m4.group(2)+",";if(m5.find()){cc +=m5.group(1)+",";}else {cc += "null"+",";}}}row_name_map.put("table"+i, aa);map_row_type.put("table"+i, bb);map_row_description.put("table"+i, cc);aa = "";bb = "";cc = "";}//组织输出md文件内容String text = "# 数据库文档\n\n";text += "## 数据表列表\n\n";String table_desstr = ""; //表描述for (int i = 0; i < table_section_map.size(); i++) {table_desstr = table_description_map.get("table"+i);String tablenamestr = table_name_map.get("table"+i);if (table_desstr != null) {text += "## 表名:"+tablenamestr+"("+table_description_map.get("table"+i)+")\n\n";}else {text += "## 表名:"+tablenamestr+"\n\n";}//text += "## 表名:"+tablenamestr+"("+table_description_map.get("table"+i)+")\n\n";text += "字段名|数据类型|字段描述\n";text += ":---:|:---:|:---:\n";String[] rownames = row_name_map.get("table"+i).split(",");String[] rowtypes = map_row_type.get("table"+i).split(",");String[] rowdes = map_row_description.get("table"+i).split(",");try {for (int j = 0; j < rownames.length; j++) {if(rowdes[j].equals("null")){rowdes[j]="";}text += rownames[j]+"|"+rowtypes[j]+"|"+rowdes[j]+"\n";}} catch (Exception e) {// TODO Auto-generated catch blocke.printStackTrace();System.out.println("字段类型与字段描述匹配出错,请查看匹配规则与sql文件内容是否相符,\n测试过程中发现,自动导出的sql文件有可能出现字段名字后出现两个空格,匹配规则为1个空格");}//System.out.println(text);}System.out.println("表描述"+table_description_map);//文件输出fileWriter = new FileWriter("d:\\外包管理系统数据库设计文档.md",false);fileWriter.write(text);fileWriter.close();} catch (Exception e) {// TODO Auto-generated catch blocke.printStackTrace();}}
}
返回时间json格式问题
@JsonFormat(timezone = "GMT+8", pattern = "yyyy-MM-dd")
例如:
/**
* 子任务评估开始事件
*/
@ApiModelProperty(value = " 子任务评估开始事件")
@ExcelProperty(" 子任务评估开始事件")
@JsonFormat(timezone = "GMT+8", pattern = "yyyy-MM-dd")
private Date startTime;
Mybatis-plus in多个值(逗号)查询
QueryWrapper<RiskPool> qw = new QueryWrapper<>();
if(StrUtil.isNotEmpty(riskPool)){qw.lambda().in(RiskPool::getId, riskPool.split(","));
}
Springboot解决Long /BigInteger /BigDecimal类型数据传给前端损失精度问题
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.module.SimpleModule;
import com.fasterxml.jackson.databind.ser.std.ToStringSerializer;
import com.fasterxml.jackson.datatype.jsr310.JavaTimeModule;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.http.converter.json.Jackson2ObjectMapperBuilder;import java.math.BigDecimal;
import java.math.BigInteger;/*** 参数返回到前端,将Long /BigInteger /BigDecimal转换成String* @author xrj* @date 2020/5/13*/
@Configuration
public class WebMvcAutoConfiguration {/*** 初始化对象* @param builder*/@Bean@Primarypublic ObjectMapper jacksonObjectMapper(Jackson2ObjectMapperBuilder builder) {final JavaTimeModule simpleModule = new JavaTimeModule();//序列化将Long转String类型simpleModule.addSerializer(Long.class, ToStringSerializer.instance);simpleModule.addSerializer(Long.TYPE, ToStringSerializer.instance);SimpleModule bigIntegerModule = new SimpleModule();//序列化将BigInteger转String类型bigIntegerModule.addSerializer(BigInteger.class, ToStringSerializer.instance);SimpleModule bigDecimalModule = new SimpleModule();//序列化将BigDecimal转String类型bigDecimalModule.addSerializer(BigDecimal.class, ToStringSerializer.instance);return builder.createXmlMapper(false).modulesToInstall(simpleModule).build();}
}
Mybatis-Plus通过全局拦截实现查询SQL根据创建时间排序(create_time)
①自定义SQL拦截器(通过重写processSelect方法,对select进行拦截,并构建添加规则)
/*** 自定义SQL拦截器* @author xsong*/
@Slf4j
@Component
public class CustomSQLInterceptor extends JsqlParserSupport implements InnerInterceptor {@Overridepublic void beforePrepare(StatementHandler sh, Connection connection, Integer transactionTimeout) {// 这里固定这么写就可以了PluginUtils.MPStatementHandler mpSh = PluginUtils.mpStatementHandler(sh);MappedStatement ms = mpSh.mappedStatement();if (InterceptorIgnoreHelper.willIgnoreTenantLine(ms.getId())) {return;}PluginUtils.MPBoundSql mpBs = mpSh.mPBoundSql();mpBs.sql(parserMulti(mpBs.sql(), null));}/*** 查询操作拦截* 该方法由JsqlParserSupport提供,主要用于通过API的方式操作SQL* 思路:通过API构建出新的条件,并将新的条件和之前的条件拼接在一起*/@Overrideprotected void processSelect(Select select, int index, String sql, Object obj) {// 解析SQLPlainSelect plainSelect = (PlainSelect) select.getSelectBody();// 构建排序规则OrderByElement orderByElement = new OrderByElement();// 设置为从大到小(降序)orderByElement.setAsc(false);// 设置排序字段orderByElement.setExpression(new Column("create_time"));// 重新封装条件plainSelect.addOrderByElements(orderByElement);// System.out.println(plainSelect);}/*** 插入操作拦截*/@Overrideprotected void processInsert(Insert insert, int index, String sql, Object obj) {}/*** 更新操作拦截*/@Overrideprotected void processUpdate(Update update, int index, String sql, Object obj) {}/*** 删除操作拦截*/@Overrideprotected void processDelete(Delete delete, int index, String sql, Object obj) {}
}②将自定义SQL拦截器添加到MybatisPlus拦截器中
/*** MyBatisPlus配置类* @author xsong*/
@Configuration
public class MyBatisPlusConfig {/*** MybatisPlus拦截器*/@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();// 分页插件拦截器interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));// 自定义SQL拦截器interceptor.addInnerInterceptor(new CustomSQLInterceptor());return interceptor;}
}③实现效果

List转字符串 a,b,c
String riskDomainList = String.join(",", riskDomainIds);
String secondRiskDomainList = String.join(",", secondRiskDomainIds);
Java中将List列表转换为字符串的三种方法
如何在 Java中将List 转换为 String。接下来使用Java 8 Streams Collectors api和String.join()方法将带有逗号分隔符或自定义分隔符的集合转换为字符串。这种转换是通过使用 java api 方法的简单步骤完成的。首先了解如何使用toString()方法将 List 转换为 String,最后学习著名的 apache 库命令StringUtils.join()方法。
对于所有示例,输入列表必须是 String 作为List类型,否则我们需要将非字符串转换为 String。例如,List 是 Double 类型,然后需要先将 double 转换为字符串。
使用标准 toString() 方法
List.toString()是最简单的,但它在开头和结尾添加方括号,每个字符串用逗号分隔符分隔。
缺点是我们不能用另一个分隔符替换逗号,也不能去掉方括号。
import java.util.Arrays;
import java.util.List;public class ListToStringUsingToStringExample {public static void main(String args) {// creating a list with strings.List<String> list = Arrays.asList("One", "Two", "Three", "Four", "Five");// converting List<String> to String using toString() methodString stringFromList = list.toString();// priting the stringSystem.out.println("String : "+stringFromList);}
}输出:
String : [One, Two, Three, Four, Five]Java 8 String.join()
java 8 String添加了一个特殊的方法String.join()以将集合转换为具有给定分隔符的字符串。
public class ListToStringUsingString_JoinExample {public static void main(String args) {// creating a list with strings.List<String> list = Arrays.asList("One", "Two", "Three", "Four", "Five");// converting List<String> to String using toString() methodString stringFromList = String.join("~", list);// priting the stringSystem.out.println("String with tilde delimiter: "+stringFromList);// delimiting with pipe | symbol.String stringPipe = String.join("|", list);// printingSystem.out.println("String with pipe delimiter : "+stringPipe);}
}输出:
String with tilde delimiter: One~Two~Three~Four~Five
String with pipe delimiter : One|Two|Three|Four|FiveCollectors.joining()
Collectors.join()方法来自 java 8 stream api。Collctors.joining()方法将分隔符、前缀和后缀作为参数。此方法将列表转换为具有给定分隔符、前缀和后缀的字符串。
查看以下有关使用不同分隔符的 join() 方法的示例。但是,String.join() 方法不提供前缀和后缀选项。
如果您需要自定义分隔符、前缀和后缀,请使用这些。如果您不想要前缀和后缀,则提供空字符串以不在结果字符串前后添加任何内容。
public class ListToStringUsingString_JoinExample {public static void main(String args) {// creating a list with strings.List<String> list = Arrays.asList("One", "Two", "Three", "Four", "Five");// using java 8 Collectors.joining with delimiter, prefix and suffixString joiningString = list.stream().collect(Collectors.joining("-", "{", "}"));// printingSystem.out.println("Collectors.joining string : "+joiningString);String joiningString3 = list.stream().collect(Collectors.joining("@", "", ""));// printingSystem.out.println("Collectors.joining string with @ separator : "+joiningString3);}
}输出:
Collectors.joining string : {One-Two-Three-Four-Five}
Collectors.joining string with @ separator : One@Two@Three@Four@FiveApache Commons StringUtils.join()
最后的方法是使用来自 apache commons 包的外部库。该库有一个方法StringUtils.join() ,它采用类似于 String.join() 方法的列表和分隔符。
public class ListToStringUsingStringUtils_JoinExample {public static void main(String args) {// creating a list with strings.List<String> list = Arrays.asList("One", "Two", "Three", "Four", "Five");// using java 8 Collectors.joining with delimiter, prefix and suffixString joiningString = StringUtils.join(list, "^");// printingSystem.out.println("StringUtils.join string with ^ delimiter : "+joiningString);String joiningString3 = StringUtils.join(list, "$");// printingSystem.out.println("StringUtils.join string with @ separator : "+joiningString3);}
}输出:
StringUtils.join string with ^ delimiter : One^Two^Three^Four^Five
StringUtils.join string with @ separator : One$Two$Three$Four$Five结论
在本文中,我们已经看到了在 java 8 之前和之后如何使用不同的方法在 java 中将 List 转换为 String。对给定的分隔符使用 String.join() 方法从 List 生成字符串是很好的。或者,如果您想添加前缀或后缀,请使用带有分隔符、前缀和后缀值的流 api Collectors.joining() 方法。
Linux 检查java服务宕机
要在 Linux 上检查 Java 服务的状态并确定其是否已经停止运行,可以使用以下命令来完成:
-
首先,打开终端或 SSH 连接到目标 Linux 系统。
-
输入以下命令来检查正在运行的进程列表中是否存在与 Java 相关的进程:
ps -ef | grep java
如果有任何包含 “java” 字样的进程显示在结果中,则说明 Java 服务仍然在运行。
-
若要获取更详细的信息,可以使用
jps命令(Java Virtual Machine Process Status Tool)来列出所有正在运行的 Java 进程及其对应的进程 ID (PID):jps -l
-
此外,还可以通过检查特定的日志文件来判断 Java 服务是否异常退出。根据不同的配置和部署情况,日志文件位于
/var/log/、/opt/logs/等路径下。可以使用以下命令来查看最新的日志内容:tail -n <number_of_lines> /path/to/your/logfile.log
将
<number_of_lines>替换为想要查看的日志行数,/path/to/your/logfile.log替换为实际的日志文件路径。 -
如果需要重新启动 Java 服务,可以使用类似以下的命令:
sudo service your-service restart
这里的
your-service应该被替换为实际的 Java 服务名称。 -
如果希望自动化地执行上述操作,可以编写 Shell 脚本来处理。以下是一个简单的示例:
#!/bin/bash# Check if any Java process is running if pgrep -x "java" > /dev/null; thenecho "Java processes are still running." elseecho "No Java processes found." fi# Restart the Java service using systemctl command sudo systemctl restart your-service
注意修改脚本中的 your-service 为实际的 Java 服务名称。保存脚本后,添加执行权限并运行它。
Linux监控Springboot服务宕机,自动重启脚本:
# An highlighted block
#!/bin/bash# 设置变量,指向 jar 包的位置
jar_path=/mnt/chonggou/rms-basic-service.jar# 定义一个函数来检查程序是否宕机
check_status() {# 使用 ps 命令检查 jar 包是否在运行running=$(ps -ef | grep $jar_path | grep -v grep)if [ -z "$running" ]; thenreturn 1elsereturn 0fi
}# 循环检查程序是否宕机
while true; docheck_statusif [ $? -eq 1 ]; thenecho "rms-basic-Service is down, restarting..."# 如果宕机了,则启动 jar 包#nohup java -jar $jar_path &nohup java -javaagent:/mnt/skywalking-agent/skywalking-agent-basic/skywalking-agent.jar -DSW_AGENT_NAME=dev::rms-basic-service -Dskywalking.collector.backend_service=192.168.1.52:11800 -jar $jar_path &fisleep 10
doneList与String互相转换,并以“,”分割
String转List
String nameArr = "张三, 李四, 王五";
List<String> alName = Arrays.asList(nameArr .split(","));
List转String
List<String> alName = Arrays.asList("张三, 李四, 王五");
String nameArr = alName.stream().collect(Collectors.joining(","));
Mybatis-plus in用法
//根据主任务id查询风险问题List<RiskAssessmentResult> riskAssessmentResultList = new ArrayList<RiskAssessmentResult>();List<String> riskLevel = Stream.of("中","高").collect(Collectors.toList());QueryWrapper qw = new QueryWrapper();qw.eq("main_task_id",riskAssessmentTaskEntity.getId());qw.in(!CollectionUtils.isEmpty(riskLevel),"risk_level",riskLevel);List<RiskPoolSubtaskRel> riskPoolSubtaskRelList = riskPoolSubtaskRelService.list(qw);
Windows 常用命令
查看端口号
netstat -ano | findstr :8080
涨知识
Argo
开源组件文档地址
| 开源组件名称 | 地址 | 来源 |
|---|---|---|
| Easy Excel | https://easyexcel.opensource.alibaba.com/ | 阿里巴巴 |
| RunnerGo | https://wiki.runnergo.cn/docs/42 | |
| EasyPoi | http://doc.wupaas.com/docs/easypoi/easypoi-1c0u4mo8p4ro8 | http://doc.wupaas.com/docs/easypoi |
| 夜莺(Nightingale)v5.9 使用手册 | https://www.bookstack.cn/books/nightingale-5.9-zh | |
软件下载
| 软件名称 | 地址 | 来源 |
|---|---|---|
| SonarQube | https://www.sonarsource.com/products/sonarqube/downloads/ | 官网 |