Elasticsearch 概念
入门学习:
- Index索引=>MySQL 里的表(table)
- 建表、增删改查(查询需要花费的学习时间最多)
- 用客户端去调用 ElasticSearch(3 种)
- 语法:SQL、代码的方法(4 种语法)
ES 相比于 MySQL,能够自动帮我们做分词,能够非常高效、灵活地查询内容。
索引(倒排索引)
正向索引:理解为书籍的目录,可以快速帮你找到对应的内容(怎么根据页码找到文章)
倒排索引:怎么根据内容找到文章
文章 A: 你好,我是 rapper
文章 B: 苏麟暴打小杨科
切词 :
| 词 | id |
| 你好 | 文章 A |
| 我 | 文章 A |
| rapper | 文章 A |
| 苏麟 | 文章 B |
| 暴打 | 文章 B |
| 杨科 | 文章 B |
用户搜索 : 苏麟杨科
ES切词 : 苏麟 , 杨科
然后去倒排索引表找对应的文章
ES 的几种调用方式
1) restful api 调用(http 请求)
GET请求 : localhost:9200
curl 可以模拟发送请求: curl -XGET"localhost:9200/?pretty
ES 的启动端口
1.9200:给外部用户(给客户端调用)的端口
2.9300:给 ES 集群内部通信的(外部调用不了的)
2) kibana devtools
自由地对 ES 进行操作(本质也是 restful api)
devtools 不建议生产环境使用
3)客户端调用
java 客户端、go 客户端等。
参考文档 : Getting started | Elasticsearch Java API Client [7.17] | Elastic
ES 的语法
DSL
json 格式,好理解;和 http 请求最兼容,应用最广
建表,插入数据 (文档就是MySQL里的表,映射就是MySQL里的字段)
post 就相当于表名 , title 和 content 就相当于字段
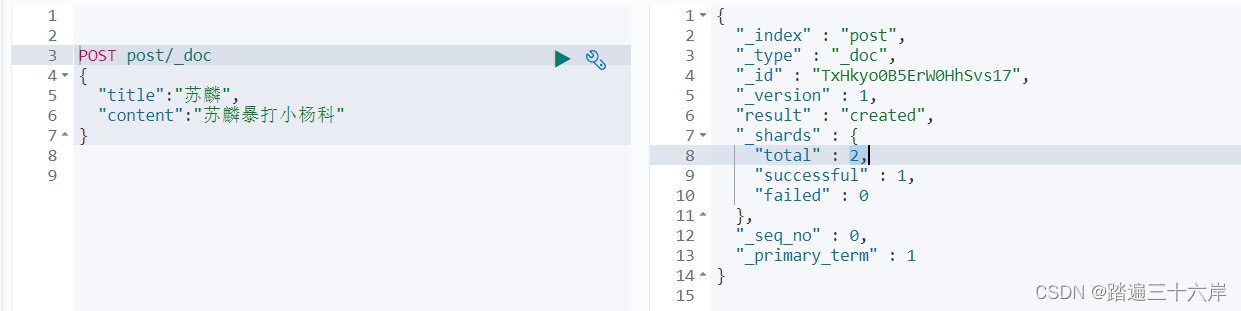
POST post/_doc
{"title":"苏麟","content":"苏麟暴打小杨科"
}有 successful 就代表存入成功了
查询
DSL (不要背) : Query DSL | Elasticsearch Guide [7.17] | Elastic
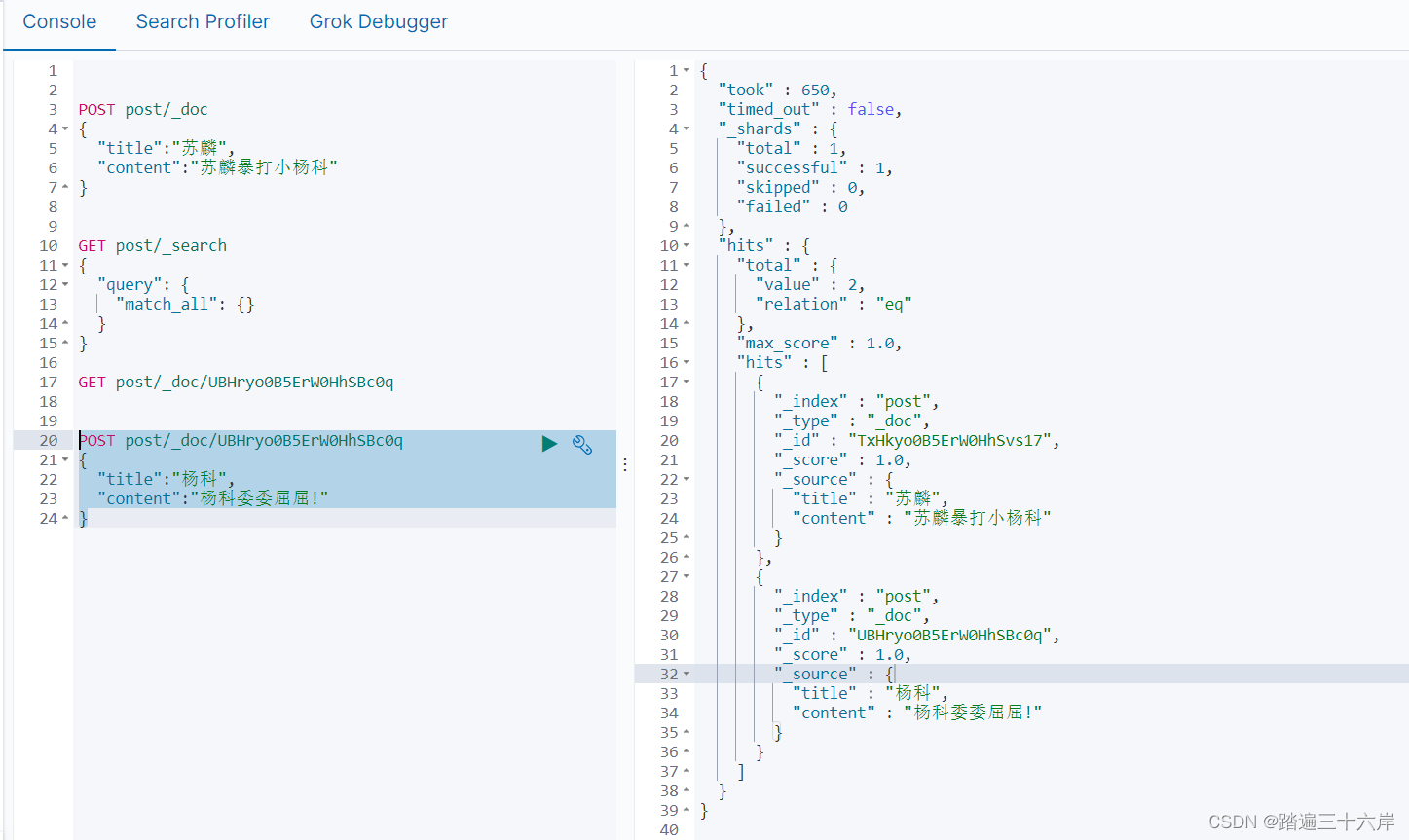
查询全部
GET post/_search
{"query": {"match_all": {}}
}
根据 id 查询
GET post/_doc/UBHryo0B5ErW0HhSBc0q

修改
根据 id 修改
POST post/_doc/UBHryo0B5ErW0HhSBc0q
{"title":"杨科","content":"杨科委委屈屈!"
}
删除
根据文档删除
DELETE post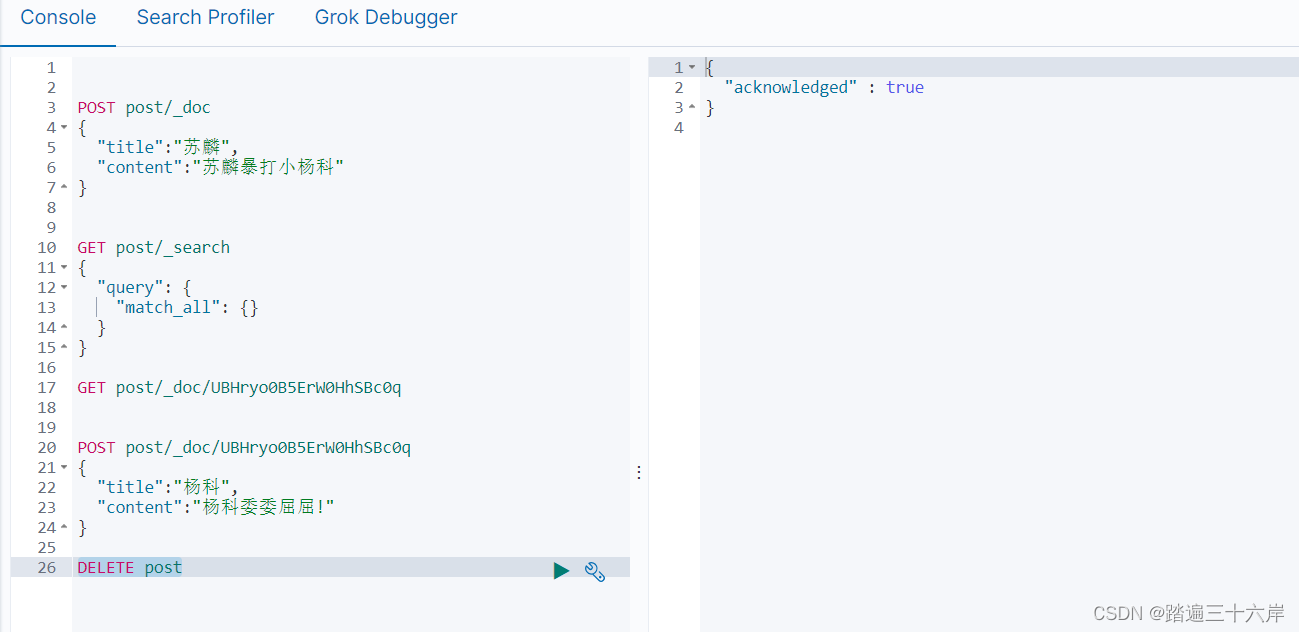
EQL
专门查询 ECS 文档(标准指标文档)的数据的语法,更加规范,但只适用于特定场景(比如事件流)
文档 : EQL search | Elasticsearch Guide [7.17] | Elastic
建表,插入
POST post_my/_doc
{"title": "苏麟爱看美女","@timestamp": "2099-05-06T16:21:15.000Z","event": {"original": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736"}
}查询
GET post_my/_search
{"query": {"match_all": { }},"sort": [{"@timestamp": "desc"}]
}
SQL
文档 : Getting Started with SQL | Elasticsearch Guide [7.17] | Elastic
查询
POST /_sql?format=txt
{"query": "SELECT * FROM post "
}
Painless Scripting language
编程式取值,更灵活,但是学习成本高
Mapping
文档 : Explicit mapping | Elasticsearch Guide [7.17] | Elastic
可以理解为数据库的表结构,有哪些字段、字段类型,
ES 支持动态 mapping,表结构可以动态改变,而不像 MySQL 一样必须手动建表,没有的字段就不能插入。
GET user/_mappingPUT /user
{"mappings": {"properties": {"age": { "type": "integer" }, "email": { "type": "keyword" }, "name": { "type": "text" } }}
}分词器
指定了分词的规则。
内置分词器 : Built-in analyzer reference | Elasticsearch Guide [7.17] | Elastic
示例 :
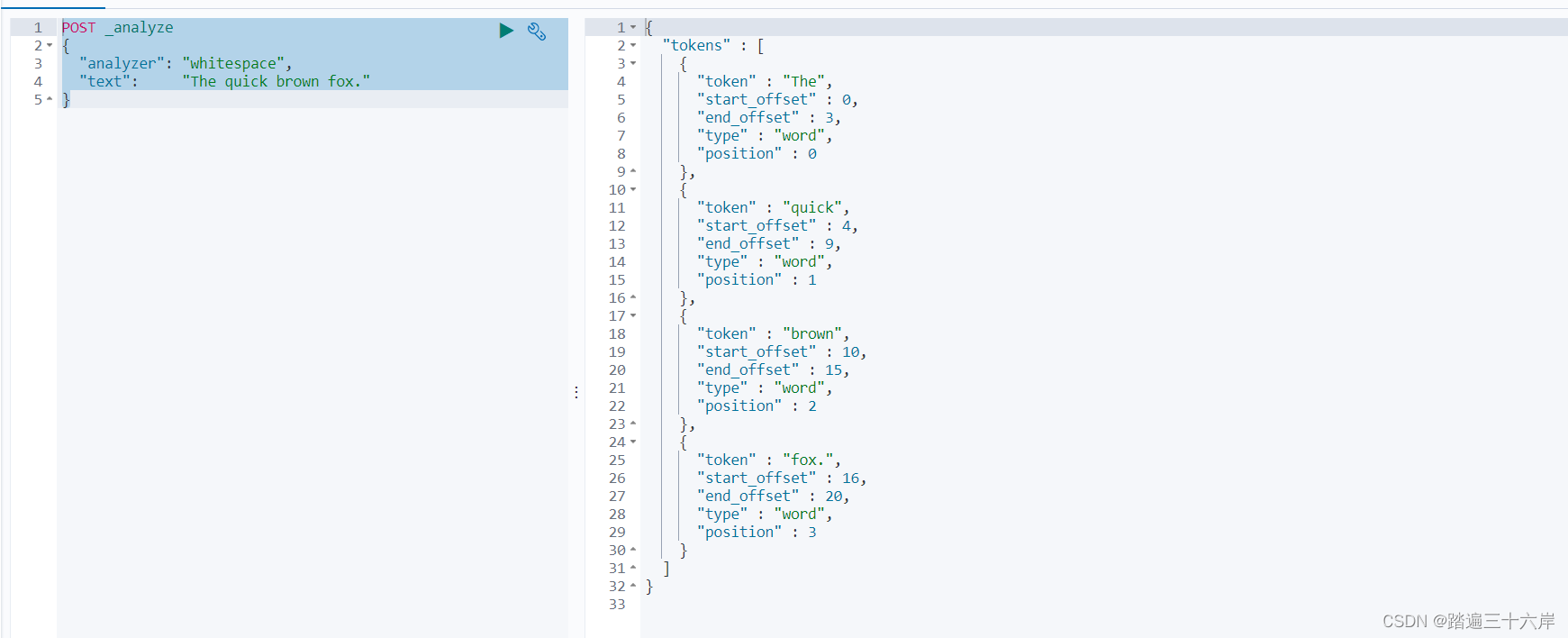
空格分词器: whitespace,结果The、quick、brown、fox.
POST _analyze
{"analyzer": "whitespace","text": "The quick brown fox."
}
标准分词规则,结果:is、this、deja、vu
POST _analyze
{"tokenizer": "standard","filter": [ "lowercase", "asciifolding" ],"text": "Is this déja vu?"
}
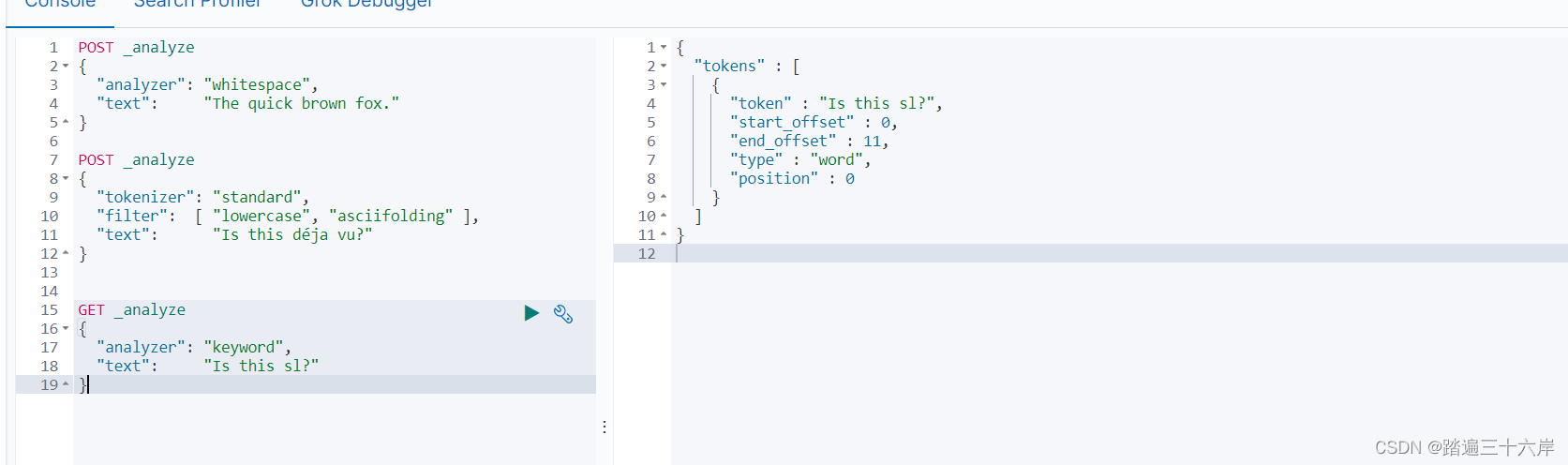
关键词分词器:就是不分词,整句话当作专业术语
GET _analyze
{"analyzer": "keyword", "text": "Is this sl?"
}
这期就到这里 , 下期见 !




![[计网底层小探索]:实现并部署多线程并发Tcp服务器框架(基于生产者消费者模型的线程池结构)](https://img-blog.csdnimg.cn/direct/c033820068dd452f96c57916b5fce352.jpeg#pic_center)

