在之前的文章 “Elasticsearch 8.10 中引入查询规则 - query rules”,我们详述了如何使用 query rules 来进行搜索。这个交互式笔记本将向你介绍如何使用官方 Elasticsearch Python 客户端来使用查询规则。 你将使用 query rules API 将查询规则存储在 Elasticsearch 中,并使用 rule_query 查询它们。
安装
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么请参考一下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请选择 Elastic Stack 8.x 进行安装。在安装的时候,我们可以看到如下的安装信息:

环境变量
在启动 Jupyter 之前,我们设置如下的环境变量:
export ES_USER="elastic"
export ES_PASSWORD="xnLj56lTrH98Lf_6n76y"
export ES_ENDPOINT="localhost"
请在上面修改相应的变量的值。这个需要在启动 jupyter 之前运行。
拷贝 Elasticsearch 证书
我们把 Elasticsearch 的证书拷贝到当前的目录下:
$ pwd
/Users/liuxg/python/elser
$ cp ~/elastic/elasticsearch-8.12.0/config/certs/http_ca.crt .
$ ls http_ca.crt
http_ca.crt安装 Python 依赖包
python3 -m pip install -qU elasticsearch load_dotenv准备数据
我们在项目当前的目录下创建如下的数据文件:
query-rules-data.json
[{"id": "us1","content": {"name": "PureJuice Pro","description": "PureJuice Pro: Experience the pinnacle of wireless charging. Blending rapid charging tech with sleek design, it ensures your devices are powered swiftly and safely. The future of charging is here.","price": 15.00,"currency": "USD","plug_type": "B","voltage": "120v"}},{"id": "uk1","content": {"name": "PureJuice Pro - UK Compatible","description": "PureJuice Pro: Redefining wireless charging. Seamlessly merging swift charging capabilities with a refined aesthetic, it guarantees your devices receive rapid and secure power. Welcome to the next generation of charging.","price": 20.00,"currency": "GBP","plug_type": "G","voltage": "230V"}},{"id": "eu1","content": {"name": "PureJuice Pro - Wireless Charger suitable for European plugs","description": "PureJuice Pro: Elevating wireless charging. Combining unparalleled charging speeds with elegant design, it promises both rapid and dependable energy for your devices. Embrace the future of wireless charging.","price": 18.00,"currency": "EUR","plug_type": "C","voltage": "230V"}},{"id": "preview1","content": {"name": "PureJuice Pro - Pre-order next version","description": "Newest version of the PureJuice Pro wireless charger, coming soon! The newest model of the PureJuice Pro boasts a 2x faster charge than the current model, and a sturdier cable with an eighteen month full warranty. We also have a battery backup to charge on-the-go, up to two full charges. Pre-order yours today!","price": 36.00,"currency": "USD","plug_type": ["B", "C", "G"],"voltage": ["230V", "120V"]}}
]创建应用并展示
我们在当前的目录下打入如下的命令来创建 notebook:
$ pwd
/Users/liuxg/python/elser
$ jupyter notebook导入包及连接到 Elasticsearch
from elasticsearch import Elasticsearch
from dotenv import load_dotenv
import osload_dotenv()openai_api_key=os.getenv('OPENAI_API_KEY')
elastic_user=os.getenv('ES_USER')
elastic_password=os.getenv('ES_PASSWORD')
elastic_endpoint=os.getenv("ES_ENDPOINT")url = f"https://{elastic_user}:{elastic_password}@{elastic_endpoint}:9200"
client = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)print(client.info())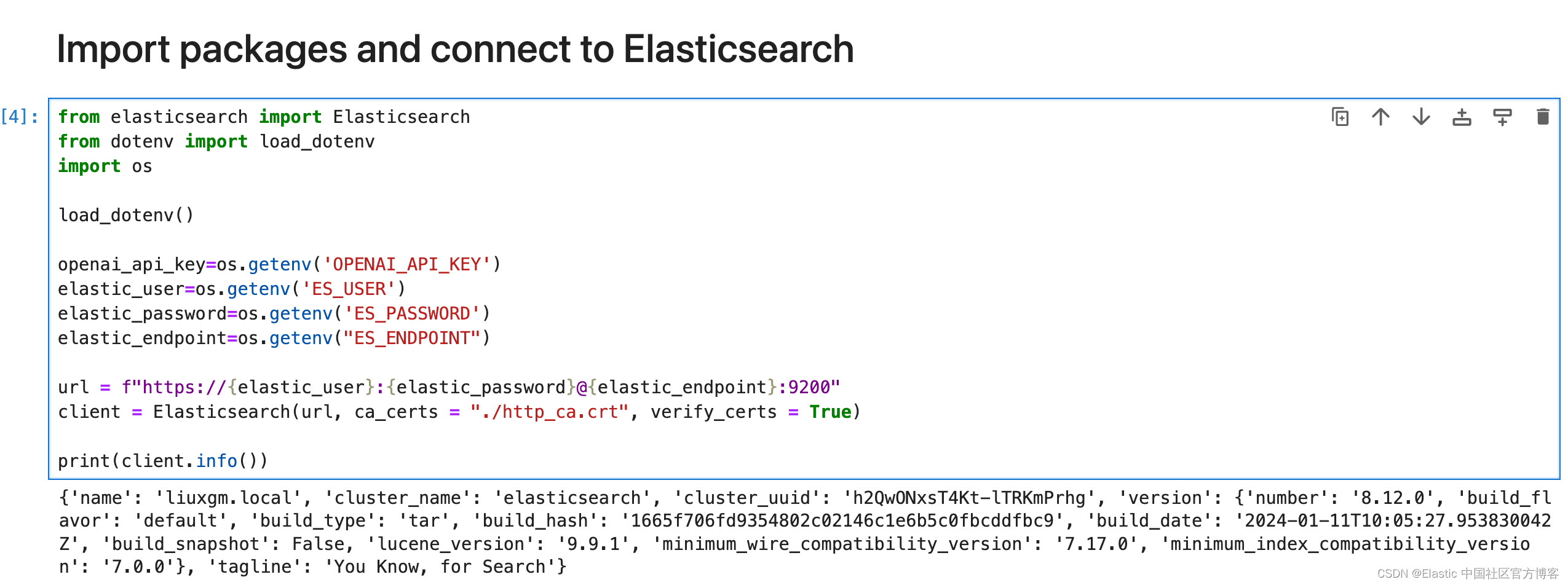
索引一些测试数据
我们的客户端已设置并连接到我们的 Elastic 部署。 现在我们需要一些数据来测试 Elasticsearch 查询的基础知识。 我们将使用具有以下字段的小型产品索引:
namedescriptionpricecurrencyplug_typevoltage
运行以下命令上传一些示例数据:
import json# Load data into a JSON object
with open('query-rules-data.json') as f:docs = json.load(f)operations = []
for doc in docs:operations.append({"index": {"_index": "products_index", "_id": doc["id"]}})operations.append(doc["content"])
client.bulk(index="products_index", operations=operations, refresh=True)
我们可以在 Kibana 中进行查看:
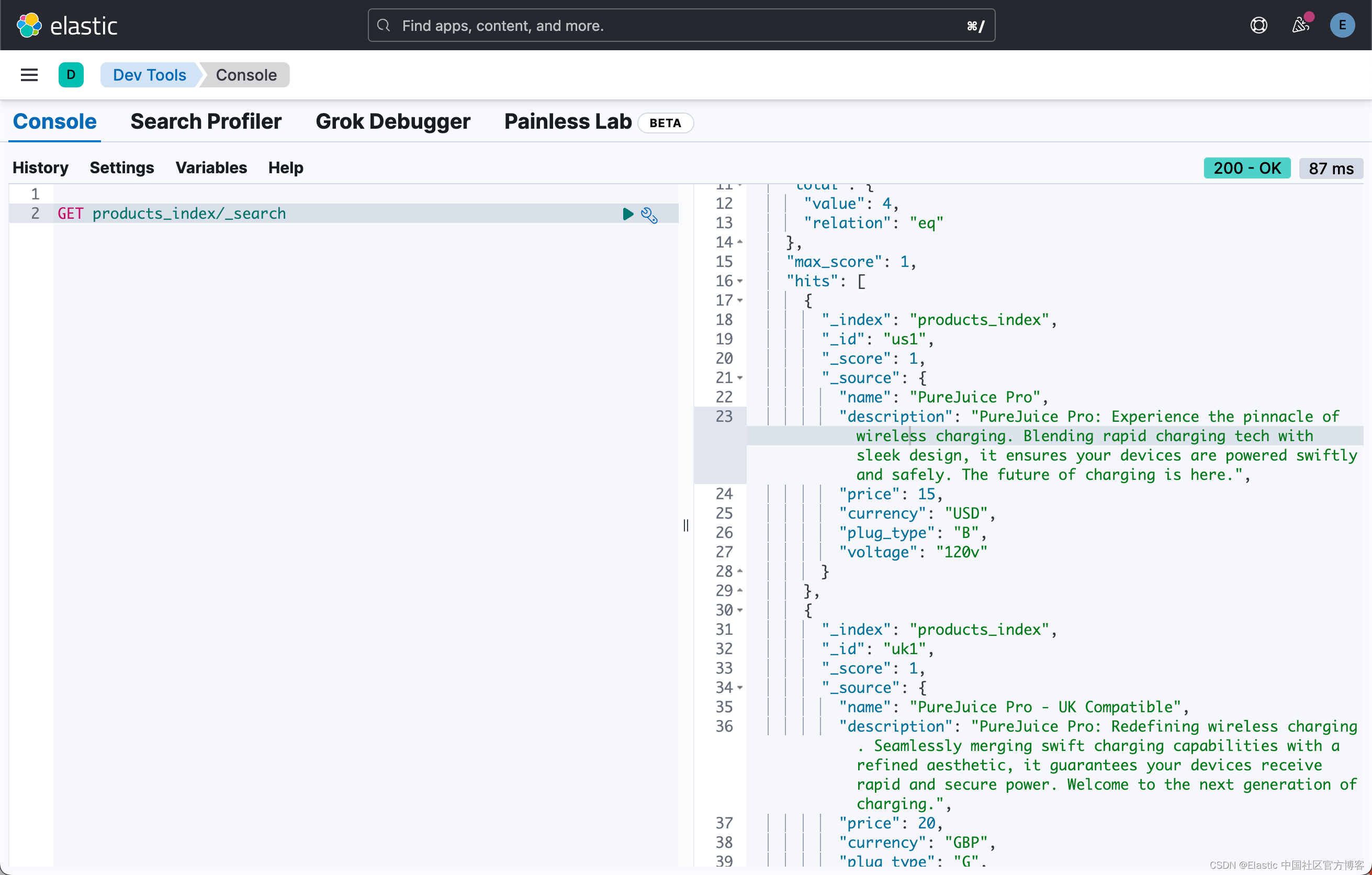
搜索测试数据
首先,让我们搜索数据寻找 “reliable wireless charger.”。
在搜索数据之前,我们将定义一些方便的函数,将来自 Elasticsearch 的原始 JSON 响应输出为更易于理解的格式。
def pretty_response(response):if len(response['hits']['hits']) == 0:print('Your search returned no results.')else:for hit in response['hits']['hits']:id = hit['_id']score = hit['_score']name = hit['_source']['name']description = hit['_source']['description']price = hit["_source"]["price"]currency = hit["_source"]["currency"]plug_type = hit["_source"]["plug_type"]voltage = hit["_source"]["voltage"]pretty_output = (f"\nID: {id}\nName: {name}\nDescription: {description}\nPrice: {price}\nCurrency: {currency}\nPlug type: {plug_type}\nVoltage: {voltage}\nScore: {score}")print(pretty_output)def pretty_ruleset(response):print("Ruleset ID: " + response['ruleset_id'])for rule in response['rules']:rule_id = rule['rule_id']type = rule['type']print(f"\nRule ID: {rule_id}\n\tType: {type}\n\tCriteria:")criteria = rule['criteria']for rule_criteria in criteria:criteria_type = rule_criteria['type']metadata = rule_criteria['metadata']values = rule_criteria['values']print(f"\t\t{metadata} {criteria_type} {values}")ids = rule['actions']['ids']print(f"\tPinned ids: {ids}")接下来,进行搜索
不使用 query rules 的正常搜索
response = client.search(index="products_index", query={"multi_match": {"query": "reliable wireless charger for iPhone","fields": [ "name^5", "description" ]}
})pretty_response(response)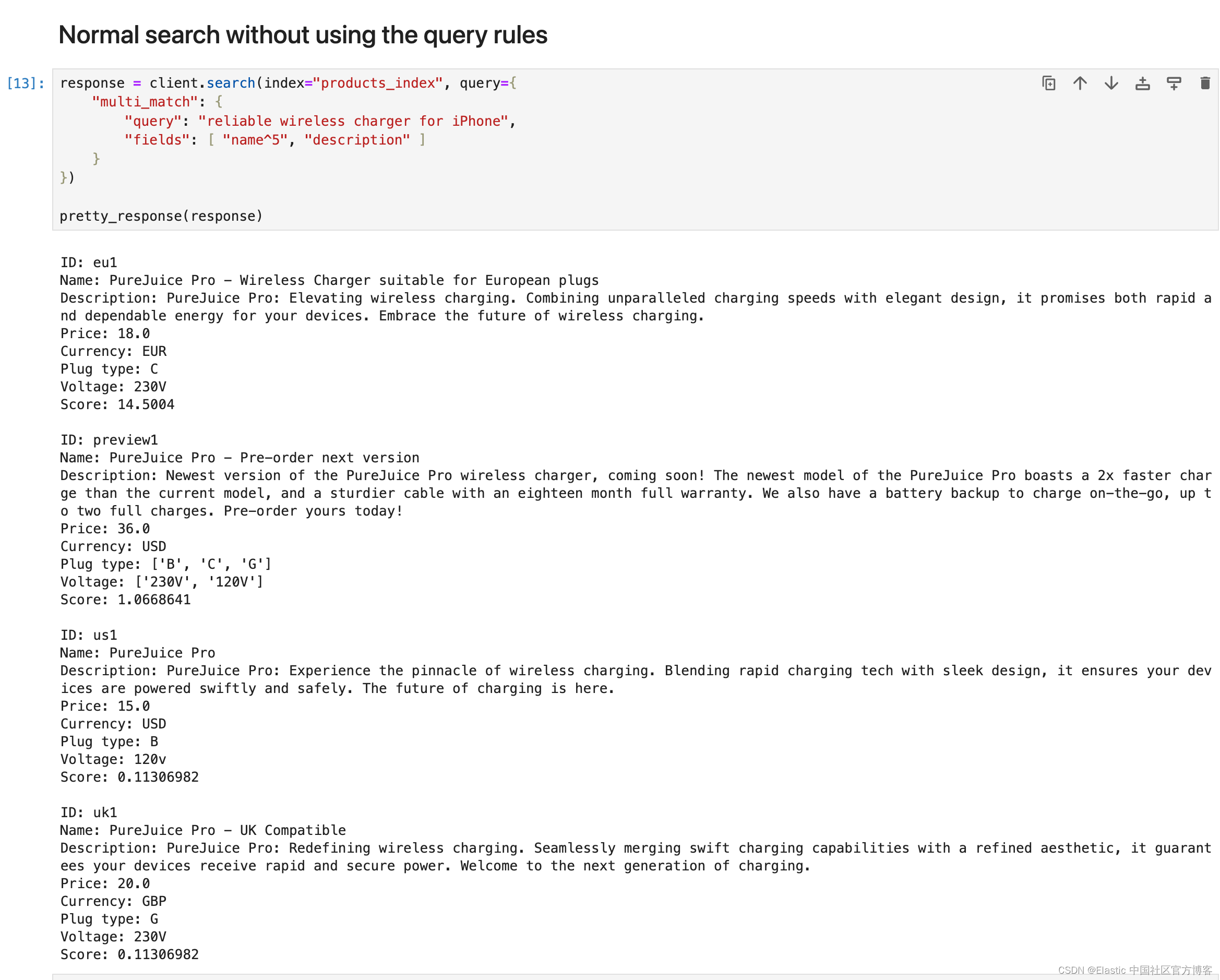
创建 query rules
我们分别假设,我们知道我们的用户来自哪个国家/地区(可能通过 IP 地址或登录的用户帐户信息进行地理位置定位)。 现在,我们希望创建查询规则,以便当人们搜索包含短语 “wireless charger (无线充电器)” 的任何内容时,根据该信息增强无线充电器的性能。
client.query_ruleset.put(ruleset_id="promotion-rules", rules=[{"rule_id": "us-charger","type": "pinned","criteria": [{"type": "contains","metadata": "my_query","values": ["wireless charger"]},{"type": "exact","metadata": "country","values": ["us"]}],"actions": {"ids": ["us1"]}},{"rule_id": "uk-charger","type": "pinned","criteria": [{"type": "contains","metadata": "my_query","values": ["wireless charger"]},{"type": "exact","metadata": "country","values": ["uk"]}],"actions": {"ids": ["uk1"]}}])为了使这些规则匹配,必须满足以下条件之一:
- my_query 包含字符串 “wireless charger” 并且 country “us”
- my_query 包含字符串 “wireless charger” 并且 country 为 “uk”
我们也可以使用 API 查看我们的规则集(使用另一个 Pretty_ruleset 函数以提高可读性):
response = client.query_ruleset.get(ruleset_id="promotion-rules")
pretty_ruleset(response)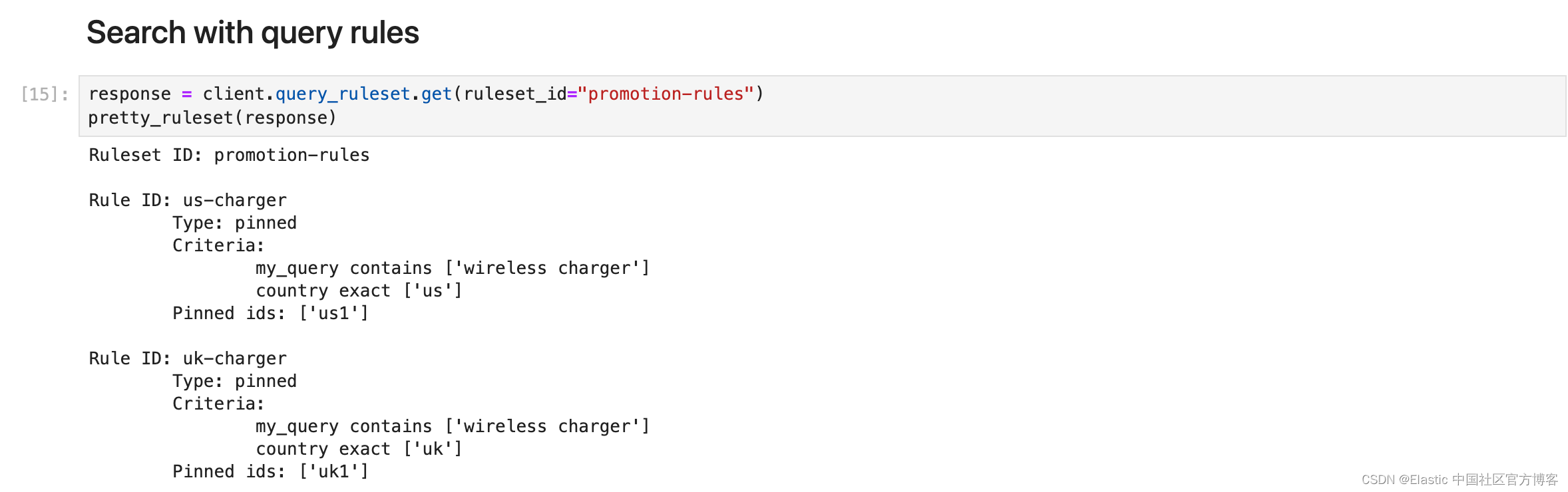
response = client.search(index="products_index", query={"rule_query": {"organic": {"multi_match": {"query": "reliable wireless charger for iPhone","fields": [ "name^5", "description" ]}},"match_criteria": {"my_query": "reliable wireless charger for iPhone","country": "us"},"ruleset_id": "promotion-rules"}
})pretty_response(response)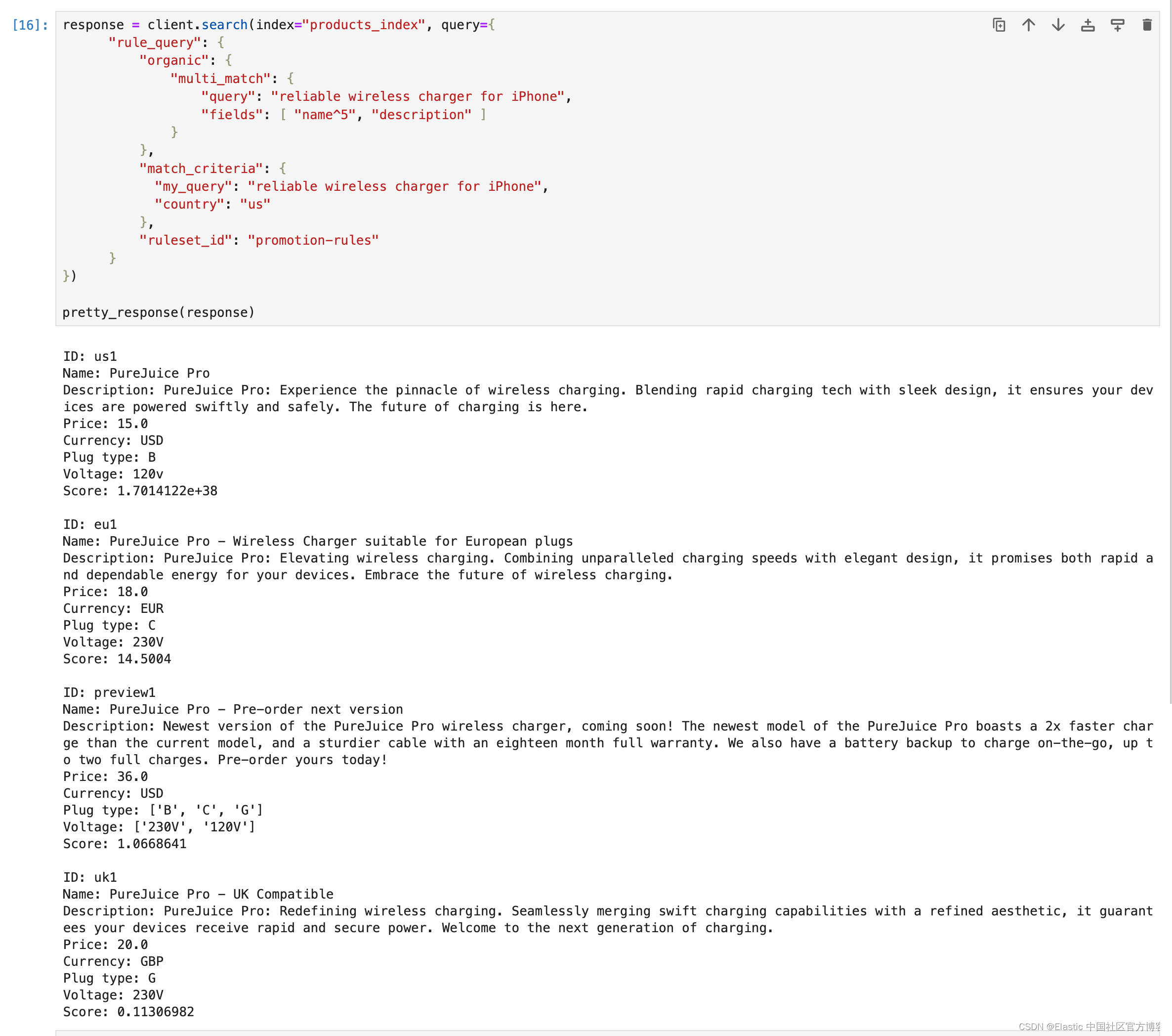
整个 notebook 的源码可以在地址下载:https://github.com/liu-xiao-guo/semantic_search_es/blob/main/search_using_query_rules.ipynb