Airtest实现在手机界面快速批量采集数据
一、问题
- Airtest使用的poco方法比较慢,寻找差不多一周,看完这篇文章能节省一周时间,希望帮到大家。

二、解决思路
使用Airtest图像识别,这样就会速度上提升效率。
三、解决办法
-
使用页面规律,要找到每条数据的附近规律(一般是图像规律),使用find_all(规律图像)计算得到坐标,再依据和图像同一条数据的坐标,计算得到差值四个(四个差值分别是左上和右下的X,Y坐标差值),图像和差值坐标经过计算得到每条数据的坐标,依据每条数据的坐标截图经过ocr识别出数据并保存。
(图像和poco方法都适用)
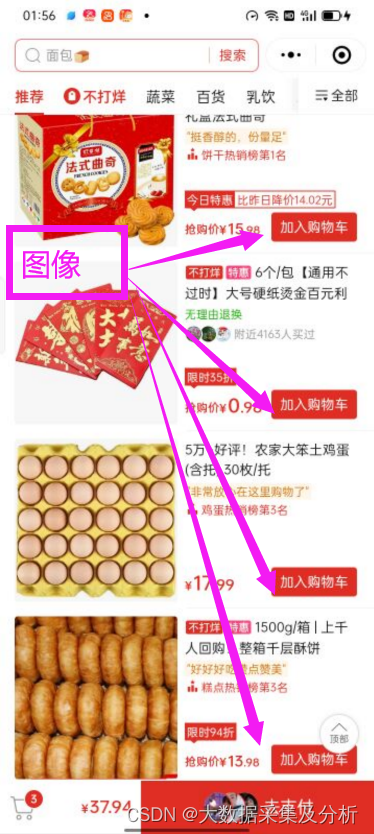
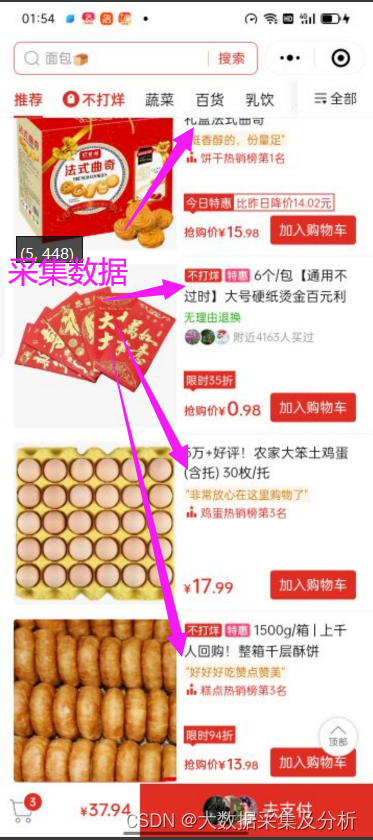

四、代码实现
# -*- encoding=utf8 -*-
__author__ = "Administrator"from airtest.core.api import *
import randomfrom airtest.aircv import *from PIL import Image
import pytesseract
import csvimport pyocr
import pyocr.buildersauto_setup(__file__)def zuobiao_new_txt(m,n):# 获取每个特征的图片坐标并完成转换# Airtest的多图查找与两图对比title_shibie = []# 参数==========日期,数据results_m= find_all(m)results_n= find_all(n)print("---------------日期-----------------")print("识别到图片的个数{}".format(len(results_m)))print(results_m)print(results_m[0]['rectangle'][0][0])print("----------------数据----------------")print(results_n)# x_0的差值m_x_0 = int(results_m[0]['rectangle'][0][0])n_x_0 = int(results_n[0]['rectangle'][0][0])x_0 =m_x_0 - n_x_0# y_0的差值m_y_0 = int(results_m[0]['rectangle'][0][1])n_y_0 = int(results_n[0]['rectangle'][0][1])y_0 = m_y_0 - n_y_0# x_1的差值m_x_1 = int(results_m[0]['rectangle'][2][0])n_x_1 = int(results_n[0]['rectangle'][2][0])x_1 = m_x_1 - n_x_1# y_1的差值m_y_1 = int(results_m[0]['rectangle'][2][1])n_y_1 = int(results_n[0]['rectangle'][2][1])y_1 = m_y_1 - n_y_1print(["两图坐标差",x_0,y_0,x_1,y_1])for i in range(len(results_m)):print("循环第{}开始".format(i))print(type(results_m[i]))print([results_m[i]['rectangle'][0]])print([results_m[i]['rectangle'][2]])new_01 = int(results_m[i]['rectangle'][0][0]) - x_0new_02 = int(results_m[i]['rectangle'][0][1]) - y_0new_03 = int(results_m[i]['rectangle'][2][0]) - x_1new_04 = int(results_m[i]['rectangle'][2][1]) - y_1print(["截图文字识别坐标",new_01,new_02,new_03,new_04])# 局部截图并识别screen = G.DEVICE.snapshot()local = aircv.crop_image(screen,(new_01,new_02,new_03,new_04))# 保存局部截图到指定文件夹中pil_image = cv2_2_pil(local)# pil_image.save("D:/test/score0.png", quality=99, optimize=True) image = Image.open(r'D:/test/score0.png')a_image = str(i)pil_image.save(r"G:/多多买菜数据/识别图片/{}.png".format(a_image), quality=99, optimize=True)sleep(random.randint(3,5))# 识别中文"G:\多多买菜数据\识别图片\20200922200802340.png"# 获取所有可用的OCR引擎tools = pyocr.get_available_tools()# 选择使用Tesseract引擎tool = tools[0]# 加载需要识别的图片# r'G:/多多买菜数据/识别图片/3.png'img = Image.open(r'G:/多多买菜数据/识别图片/{}.png'.format(a_image))# 进行文字识别text = tool.image_to_string(img, builder=pyocr.builders.TextBuilder(),lang='chi_sim')print("-----------识别出来的文字为:--------------")print(text)title_shibie.append(text)# log("识别出来的文字为:"+text)return(title_shibie)if __name__=="__main__":with open('多多商品数据02.csv', 'a', encoding='utf-8', newline='') as csvfile: # 新建并打开comment_con.csv文件writer = csv.writer(csvfile)writer.writerow(['商品标题', '商品类别']) # 写第一行titles = []# 次数设置for xunhuan in range(1):# 放入商品标题print("第几个{}标题页面循环".format(xunhuan))# 获取截图左上和右下的坐标# 循环截图处计算标题的相应坐标# for jietu_zuobiao in range(len(m_new)):conte = zuobiao_new_txt(Template(r"tpl1707239618153.png", record_pos=(0.403, -0.133), resolution=(720, 1600)),Template(r"tpl1707239627040.png", record_pos=(-0.201, -0.124), resolution=(720, 1600)))print(conte)if conte in titles:print("数据已经存在")else:print(conte)writer.writerow([conte,"蔬菜"])titles.append(conte)# 页面滑动random_int_1 = random.randint(500,502)random_int_2 = random.randint(1500,1520) random_int_3 = random.randint(502,503)random_int_4 = random.randint(600,650)swipe([random_int_1,random_int_2],[random_int_3,random_int_4])print("大页面滑动操作")五、总结
- python最大的优势是车轮(第三方库),不用我们去扣代码,上面的解决办法借助了ocr,我们一直应用于验证码识别,当然这种识别正确率达不到100%,要想提高正确率,借助于谷歌这些大平台服务,收费的服务也很棒,正确率确实高,上面的代码是借助于免费的第三方库,也觉得够用,当然大家有更好的办法,欢迎大家评论转发交流,一起共享更好的技术。