先看一下结果:

1,环境安装指令
conda create -n pytorch python=3.7
activate pytorch
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
pip install matplotlib
pip install IPython
pip install opencv-python2,训练过程
先构建判别器和生成器,判别器和生成器有各自的损失函数,损失迭代为顺序迭代更新各自的权值,先训练判别器,再训练生成器
第 1 部分-训练判别器
回想一下,训练判别器的目的是最大程度地提高将给定输入正确分类为真实或伪造的可能性。 就古德费罗而言,我们希望“通过提高其随机梯度来更新判别器”。 实际上,我们要最大化log D(x) + log(1 - D(G(z))。 由于 ganhacks 提出了单独的小批量建议,因此我们将分两步进行计算。 首先,我们将从训练集中构造一批真实样本,向前通过D,计算损失(log D(x)),然后在向后通过中计算梯度。 其次,我们将使用当前生成器构造一批假样本,将这批伪造通过D,计算损失(log(1 - D(G(z)))),然后反向累积梯度。 现在,利用全批量和全批量的累积梯度,我们称之为判别器优化程序的一个步骤。
第 2 部分-训练生成器
如原始论文所述,我们希望通过最小化log(1 - D(G(z)))来训练生成器,以产生更好的假货。 如前所述,Goodfellow 证明这不能提供足够的梯度,尤其是在学习过程的早期。 作为解决方法,我们希望最大化log D(G(z))。 在代码中,我们通过以下步骤来实现此目的:将第 1 部分的生成器输出与判别器进行分类,使用实数标签GT计算G的损失,反向计算G的梯度,最后使用优化器步骤更新G的参数。 将真实标签用作损失函数的GT标签似乎是违反直觉的,但这使我们可以使用 BCELoss 的log(x)部分(而不是log(1 - x)部分),这正是我们想要的。
最后,我们将进行一些统计报告,并在每个周期结束时,将我们的fixed_noise批量推送到生成器中,以直观地跟踪G的训练进度。 报告的训练统计数据是:
Loss_D-判别器损失,计算为所有真实批量和所有假批量的损失总和(log D(x) + log D(G(z)))。Loss_G-生成器损失计算为log D(G(z))D(x)-所有真实批量的判别器的平均输出(整个批量)。 这应该从接近 1 开始,然后在G变得更好时理论上收敛到 0.5。 想想这是为什么。D(G(z))-所有假批量的平均判别器输出。 第一个数字在D更新之前,第二个数字在D更新之后。 这些数字应从 0 开始,并随着G的提高收敛到 0.5。 想想这是为什么。
完整训练程序如下:
from __future__ import print_function
#%matplotlib inline
import argparse
import os
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML# Set random seed for reproducibility
manualSeed = 999
#manualSeed = random.randint(1, 10000) # use if you want new results
#print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)##############################
##1.参数设置
############################### Root directory for dataset
dataroot = "data/imgs"# Number of workers for dataloader
workers = 2# Batch size during training
batch_size = 128# Spatial size of training images. All images will be resized to this
# size using a transformer.
image_size = 256# Number of channels in the training images. For color images this is 3
nc = 3# Size of z latent vector (i.e. size of generator input)
nz = 100# Size of feature maps in generator
ngf = 64# Size of feature maps in discriminator
ndf = 64# Number of training epochs
num_epochs = 200# Learning rate for optimizers
lr = 0.0002# Beta1 hyperparam for Adam optimizers
beta1 = 0.5# Number of GPUs available. Use 0 for CPU mode.
ngpu = 1##############################
##2.数据加载
############################### We can use an image folder dataset the way we have it setup.
# Create the dataset
dataset = dset.ImageFolder(root=dataroot,transform=transforms.Compose([transforms.Resize(image_size),transforms.CenterCrop(image_size),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),]))
# Create the dataloader
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,shuffle=True, num_workers=workers)# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")# Plot some training images
# real_batch = next(iter(dataloader))
# plt.figure(figsize=(8,8))
# plt.axis("off")
# plt.title("Training Images")
# plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True).cpu(),(1,2,0)))#权重初始化,均值为 0,stdev = 0.02的正态分布中随机初始化
# custom weights initialization called on netG and netD
def weights_init(m):classname = m.__class__.__name__if classname.find('Conv') != -1:nn.init.normal_(m.weight.data, 0.0, 0.02)elif classname.find('BatchNorm') != -1:nn.init.normal_(m.weight.data, 1.0, 0.02)nn.init.constant_(m.bias.data, 0)##############################
##3.生成器
##############################
# Generator Codeclass Generator(nn.Module):def __init__(self, ngpu):super(Generator, self).__init__()self.ngpu = ngpuself.main = nn.Sequential(# input is Z, going into a convolutionnn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),nn.BatchNorm2d(ngf * 8),nn.ReLU(True),# state size. (ngf*8) x 4 x 4nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 4),nn.ReLU(True),# state size. (ngf*4) x 8 x 8nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 2),nn.ReLU(True),# state size. (ngf*2) x 16 x 16nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf),nn.ReLU(True),# state size. (ngf) x 32 x 32nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),nn.Tanh()# state size. (nc) x 64 x 64)def forward(self, input):return self.main(input)class Generator_256(nn.Module):def __init__(self, ngpu):super(Generator_256, self).__init__()self.ngpu = ngpuself.main = nn.Sequential(# input is Z, going into a convolutionnn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),nn.BatchNorm2d(ngf * 8),nn.ReLU(True),# state size. (ngf*8) x 4 x 4nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 4),nn.ReLU(True),# state size. (ngf*4) x 8 x 8nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 2),nn.ReLU(True),# state size. (ngf*2) x 16 x 16nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf),nn.ReLU(True),# state size. (ngf) x 32 x 32nn.ConvTranspose2d(ngf, ngf, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf),nn.ReLU(True),# state size. (ngf) x 64 x 64nn.ConvTranspose2d(ngf, ngf, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf),nn.ReLU(True),# state size. (ngf) x 128 x 128nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),nn.Tanh()# state size. (nc) x 256 x 256)def forward(self, input):return self.main(input)# Create the generator
netG = Generator_256(ngpu).to(device)# Handle multi-gpu if desired
if (device.type == 'cuda') and (ngpu > 1):netG = nn.DataParallel(netG, list(range(ngpu)))# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
netG.apply(weights_init)# Print the model
#print(netG)##############################
##3.判别器
##############################
class Discriminator(nn.Module):def __init__(self, ngpu):super(Discriminator, self).__init__()self.ngpu = ngpuself.main = nn.Sequential(# input is (nc) x 64 x 64nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),nn.LeakyReLU(0.2, inplace=True),# state size. (ndf) x 32 x 32nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 2),nn.LeakyReLU(0.2, inplace=True),# state size. (ndf*2) x 16 x 16nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 4),nn.LeakyReLU(0.2, inplace=True),# state size. (ndf*4) x 8 x 8nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 8),nn.LeakyReLU(0.2, inplace=True),# state size. (ndf*8) x 4 x 4nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),nn.Sigmoid())def forward(self, input):return self.main(input)class Discriminator_256(nn.Module):def __init__(self, ngpu):super(Discriminator_256, self).__init__()self.ngpu = ngpuself.main = nn.Sequential(# input is (nc) x 256 x 256nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),nn.LeakyReLU(0.2, inplace=True),# input is (nc) x 128 x 128nn.Conv2d(ndf, ndf, 4, 2, 1, bias=False),nn.LeakyReLU(0.2, inplace=True),# input is (nc) x 64 x 64nn.Conv2d(ndf, ndf, 4, 2, 1, bias=False),nn.LeakyReLU(0.2, inplace=True),# state size. (ndf) x 32 x 32nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 2),nn.LeakyReLU(0.2, inplace=True),# state size. (ndf*2) x 16 x 16nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 4),nn.LeakyReLU(0.2, inplace=True),# state size. (ndf*4) x 8 x 8nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 8),nn.LeakyReLU(0.2, inplace=True),# state size. (ndf*8) x 4 x 4nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),nn.Sigmoid())def forward(self, input):return self.main(input)# Create the Discriminator
netD = Discriminator_256(ngpu).to(device)# Handle multi-gpu if desired
if (device.type == 'cuda') and (ngpu > 1):netD = nn.DataParallel(netD, list(range(ngpu)))# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
netD.apply(weights_init)# Print the model
#print(netD)##############################
##4.损失函数,优化器
############################### Initialize BCELoss function# def wloss(target,label):
# return -target.mean()+label.mean()criterion = nn.BCELoss()#criterion = nn.MSELoss()# Create batch of latent vectors that we will use to visualize
# the progression of the generator
fixed_noise = torch.randn(64, nz, 1, 1, device=device)# Establish convention for real and fake labels during training
real_label = 1.
fake_label = 0.# # Setup Adam optimizers for both G and D
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))# optimizerD = optim.RMSprop(netD.parameters(),lr=lr)
# optimizerG = optim.RMSprop(netG.parameters(),lr=lr)##############################
##5.训练
##############################
# netG.load_state_dict(torch.load('netG_final.pkl'))
# netD.load_state_dict(torch.load('netD_final.pkl'))# Training Loop
if __name__=='__main__':# Lists to keep track of progressimg_list = []G_losses = []D_losses = []iters = 0real_batch = next(iter(dataloader))print("Starting Training Loop...")# For each epochfor epoch in range(num_epochs):# For each batch in the dataloaderfor i, data in enumerate(dataloader, 0):############################# (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))############################# Train with all-real batchnetD.zero_grad()# Format batchreal_cpu = data[0].to(device)b_size = real_cpu.size(0)label = torch.full((b_size,), real_label, dtype=torch.float, device=device)# Forward pass real batch through Doutput = netD(real_cpu).view(-1)# Calculate loss on all-real batcherrD_real = criterion(output, label)# Calculate gradients for D in backward passerrD_real.backward()D_x = output.mean().item()## Train with all-fake batch# Generate batch of latent vectorsnoise = torch.randn(b_size, nz, 1, 1, device=device)# Generate fake image batch with Gfake = netG(noise)label.fill_(fake_label)# Classify all fake batch with Doutput = netD(fake.detach()).view(-1)# Calculate D's loss on the all-fake batcherrD_fake = criterion(output, label)# Calculate the gradients for this batcherrD_fake.backward()D_G_z1 = output.mean().item()# Add the gradients from the all-real and all-fake batcheserrD = errD_real + errD_fake# Update DoptimizerD.step()############################# (2) Update G network: maximize log(D(G(z)))###########################netG.zero_grad()label.fill_(real_label) # fake labels are real for generator cost# Since we just updated D, perform another forward pass of all-fake batch through Doutput = netD(fake).view(-1)# Calculate G's loss based on this outputerrG = criterion(output, label)# Calculate gradients for GerrG.backward()D_G_z2 = output.mean().item()# Update GoptimizerG.step()# Output training statsif i % 50 == 0:print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'% (epoch, num_epochs, i, len(dataloader),errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))# 保存torch.save(netG.state_dict(), 'netG.pkl')torch.save(netD.state_dict(), 'netD.pkl')#model.load_state_dict(torch.load('\parameter.pkl'))# Save Losses for plotting laterG_losses.append(errG.item())D_losses.append(errD.item())# Check how the generator is doing by saving G's output on fixed_noiseif (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):with torch.no_grad():fake = netG(fixed_noise).detach().cpu()img_list.append(vutils.make_grid(fake, padding=2, normalize=True))iters += 1torch.save(netG.state_dict(), 'netG_final.pkl')torch.save(netD.state_dict(), 'netD_final.pkl')plt.figure(figsize=(10,5))plt.title("Generator and Discriminator Loss During Training")plt.plot(G_losses,label="G")plt.plot(D_losses,label="D")plt.xlabel("iterations")plt.ylabel("Loss")plt.legend()plt.show()#%%capturefig = plt.figure(figsize=(8,8))plt.axis("off")ims = [[plt.imshow(np.transpose(i,(1,2,0)), animated=True)] for i in img_list]ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)HTML(ani.to_jshtml())# Grab a batch of real images from the dataloaderreal_batch = next(iter(dataloader))# Plot the real imagesplt.figure(figsize=(15,15))plt.subplot(1,2,1)plt.axis("off")plt.title("Real Images")plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(),(1,2,0)))# Plot the fake images from the last epochplt.subplot(1,2,2)plt.axis("off")plt.title("Fake Images")plt.imshow(np.transpose(img_list[-1],(1,2,0)))plt.show()训练数据为:

训练程序及训练数据:下载pytorch版本DCGAN生成二次元头像,包含源码训练测试代码,以及训练数据
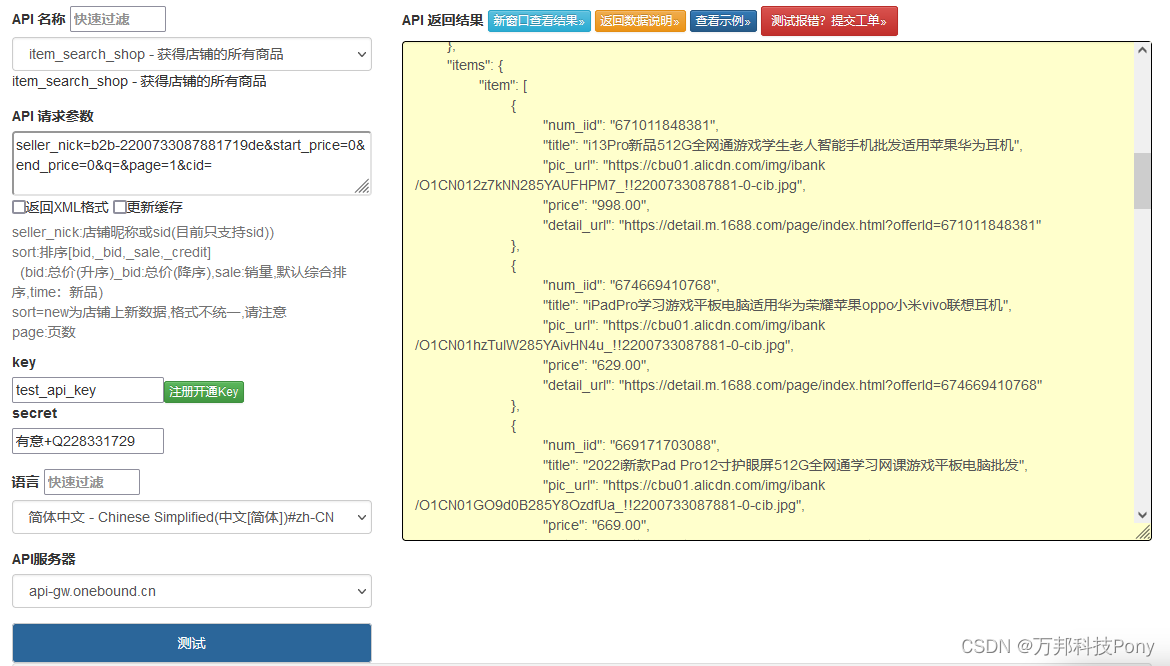
训练损失:
真假图对比:
3,测试推理
加载训练过程的权值,进行前向推理批量生成头像数据
from __future__ import print_function
#%matplotlib inline
import argparse
import os
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
import cv2# Set random seed for reproducibility
manualSeed = 999
#manualSeed = random.randint(1, 10000) # use if you want new results
#print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)##############################
##1.参数设置
############################### Spatial size of training images. All images will be resized to this
# size using a transformer.
image_size = 256# Number of channels in the training images. For color images this is 3
nc = 3# Size of z latent vector (i.e. size of generator input)
nz = 100# Size of feature maps in generator
ngf = 64# Size of feature maps in discriminator
ndf = 64# Number of GPUs available. Use 0 for CPU mode.
ngpu = 1# Decide which device we want to run on
#device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
device = torch.device("cpu")#权重初始化,均值为 0,stdev = 0.02的正态分布中随机初始化
# custom weights initialization called on netG and netD
def weights_init(m):classname = m.__class__.__name__if classname.find('Conv') != -1:nn.init.normal_(m.weight.data, 0.0, 0.02)elif classname.find('BatchNorm') != -1:nn.init.normal_(m.weight.data, 1.0, 0.02)nn.init.constant_(m.bias.data, 0)##############################
##生成器
##############################
# Generator Codeclass Generator(nn.Module):def __init__(self, ngpu):super(Generator, self).__init__()self.ngpu = ngpuself.main = nn.Sequential(# input is Z, going into a convolutionnn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),nn.BatchNorm2d(ngf * 8),nn.ReLU(True),# state size. (ngf*8) x 4 x 4nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 4),nn.ReLU(True),# state size. (ngf*4) x 8 x 8nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 2),nn.ReLU(True),# state size. (ngf*2) x 16 x 16nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf),nn.ReLU(True),# state size. (ngf) x 32 x 32nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),nn.Tanh()# state size. (nc) x 64 x 64)def forward(self, input):return self.main(input)class Generator_256(nn.Module):def __init__(self, ngpu):super(Generator_256, self).__init__()self.ngpu = ngpuself.main = nn.Sequential(# input is Z, going into a convolutionnn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),nn.BatchNorm2d(ngf * 8),nn.ReLU(True),# state size. (ngf*8) x 4 x 4nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 4),nn.ReLU(True),# state size. (ngf*4) x 8 x 8nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 2),nn.ReLU(True),# state size. (ngf*2) x 16 x 16nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf),nn.ReLU(True),# state size. (ngf) x 32 x 32nn.ConvTranspose2d(ngf, ngf, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf),nn.ReLU(True),# state size. (ngf) x 64 x 64nn.ConvTranspose2d(ngf, ngf, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf),nn.ReLU(True),# state size. (ngf) x 128 x 128nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),nn.Tanh()# state size. (nc) x 256 x 256)def forward(self, input):return self.main(input)# Create the generator
netG = Generator_256(ngpu).to(device)# # Handle multi-gpu if desired
# if (device.type == 'cuda') and (ngpu > 1):
# netG = nn.DataParallel(netG, list(range(ngpu)))# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
#netG.apply(weights_init)
netG.load_state_dict(torch.load('netG_final.pkl'))
# Print the model
print(netG)##############################
##推理
############################### Training Loop
if __name__=='__main__':# Generate batch of latent vectorsnoise = torch.randn(32, nz, 1, 1, device=device)# Generate fake image batch with Gfake = netG(noise)fake = fake.detach().numpy()i=0for f in fake:print(f.shape)dst_img = np.transpose(f, (1, 2, 0))dst_img = cv2.cvtColor(dst_img, cv2.COLOR_RGB2BGR)cv2.imwrite('./gen_imgs_256/'+str(i)+'.jpg',dst_img*255)i+=1cv2.imshow('dst',dst_img)cv2.waitKey(500) 资源下载:pytorch版本DCGAN生成二次元头像,包含源码训练测试代码,以及训练数据![]() https://download.csdn.net/download/qq_34106574/81276178?spm=1001.2014.3001.5503
https://download.csdn.net/download/qq_34106574/81276178?spm=1001.2014.3001.5503