详解JPA 2.0动态查询机制:Criteria API(2)

JPA 2.0引入了 Criteria API,这个 API 首次将类型安全查询引入到 Java 应用程序中,并为在运行时动态地构造查询提供一种机制。本文介绍如何使用 Criteria API 和与之密切相关的 Metamodel API 编写动态的类型安全查询。
AD:干货来了,不要等!WOT2015 北京站演讲PPT开放下载!
持久化域的元模型
讨论 清单 2 时指出了一个不常见的构造:Person_.age,它表示 Person 的持久化属性age。清单 2 使用 Person_.age 形成一个路径表达式,它通过 p.get(Person_.age) 从 Root< Person> 表达式 p 导航而来。Person_.age 是 Person_ 类中的公共静态字段,Person_ 是静态、已实例化的规范元模型类,对应于原来的 Person 实体类。
元模型类描述持久化类的元数据。如果一个类安装 JPA 2.0 规范精确地描述持久化实体的元数据,那么该元模型类就是规范的。规范的元模型类是静态的,因此它的所有成员变量都被声明为静态的(也是 public 的)。Person_.age 是静态成员变量之一。您可以在开发时在源代码中生成一个具体的 Person_.java 来实例化 一个规范类。实例化之后,它就可以在编译期间以强类型的方式引用 Person 的持久化属性。
这个 Person_metamodel 类是引用 Person 的元信息的一种代替方法。这种方法类似于经常使用(有人可能认为是滥用)的 Java Reflection API,但概念上有很大的不同。您可以使用反射获得关于 java.lang.Class 的实例的元信息,但是不能以编译器能够检查的方式引用关于Person.class 的元信息。例如,使用反射时,您将这样引用 Person.class 中的 age 字段:
Field field = Person.class.getField("age");
|
不过,这种方法也存在很大的限制,类似于 清单 1 中基于字符串的 JPQL 查询存在的限制。编译器能够顺利编译该代码,但不能确定它是否可以正常工作。如果该代码包含任何错误输入,它在运行时肯定会失败。反射不能实现 JPA 2.0 的类型安全查询 API 要实现的功能。
类型安全查询 API 必须让您的代码能够引用 Person 类中的持久化属性 age,同时让编译器能够在编译期间检查错误。JPA 2.0 提供的解决办法通过静态地公开相同的持久化属性实例化名为 Person_ 的元模型类(对应于 Person)。
关于元信息的讨论通常都是令人昏昏欲睡的。所以我将为熟悉的 Plain Old Java Object (POJO) 实体类展示一个具体的元模型类例子(domain.Person),如清单 3 所示:
清单 3. 一个简单的持久化实体
package domain; @Entity public class Person {@Idprivate long ssn;private string name;private int age;// public gettter/setter methodspublic String getName() {...} } |
这是 POJO 的典型定义,并且包含注释(比如 @Entity 或 @Id ),从而让 JPA 提供者能够将这个类的实例作为持久化实体管理。
清单 4 显示了 domain.Person 的对应静态规范元模型类:
清单 4. 一个简单实体的规范元模型
package domain; import javax.persistence.metamodel.SingularAttribute;@javax.persistence.metamodel.StaticMetamodel(domain.Person.class)public class Person_ {public static volatile SingularAttribute< Person,Long> ssn;public static volatile SingularAttribute< Person,String> name;public static volatile SingularAttribute< Person,Integer> age; } |
元模型类将原来的 domain.Person 实体的每个持久化属性声明为类型为SingularAttribute< Person,?> 的静态公共字段。通过利用这个 Person_ 元模型类,可以在编译期间引用 domain.Person 的持久化属性 age — 不是通过 Reflection API,而是直接引用静态的 Person_.age 字段。然后,编译器可以根据 age 属性声明的类型实施类型检查。我已经列举了一个关于此类限制的例子:QueryBuilder.gt(p.get(Person_.age), "xyz") 将导致编译器错误,因为编译器通过 QueryBuilder.gt(..) 的签名和 Person_.age 的类型可以确定 Person 的age 属性是一个数字字段,不能与 String 进行比较。
其他一些需要注意的要点包括:
- 元模型
Person_.age字段被声明为类型javax.persistence.metamodel.SingularAttribute。SingularAttribute是 JPA Metamodel API 中定义的接口之一,我将在下一小节描述它。SingularAttribute< Person, Integer>的泛型参数表示该类声明原来的持久化属性和持久化属性本身的类型。 - 元模型类被注释为
@StaticMetamodel(domain.Person.class)以将其标记为一个与原来的持久化domain.Person实体对应的元模型类。
Metamodel API
我将一个元模型类定义为一个持久化实体类的描述。就像 Reflection API 需要其他接口(比如 java.lang.reflect.Field 或 java.lang.reflect.Method )来描述 java.lang.Class的组成一样,JPA Metamodel API 也需要其他接口(比如 SingularAttribute 和PluralAttribute)来描述元模型类的类型及其属性。
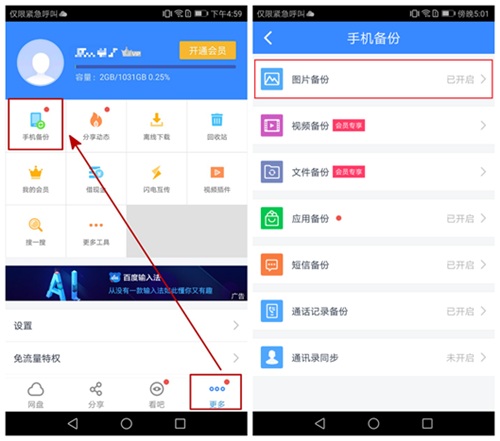
图 3 显示了在 Metamodel API 中定义用于描述类型的接口:
图 3. Metamodel API 中的持久化类型的接口的层次结构

图 4 显示了在 Metamodel API 中定义用于描述属性的接口:
图 4. Metamodel API 中的持久化属性的接口的层次结构

JPA 的 Metamodel API 接口比 Java Reflection API 更加专业化。需要更细微的差别来表达关于持久化的丰富元信息。例如,Java Reflection API 将所有 Java 类型表示为java.lang.Class。即没有通过独立的定义对概念进行区分,比如类、抽象类和接口。当然,您可以询问 Class 它是一个接口还是一个抽象类,但这与通过两个独立的定义表示接口和抽象类的差别不同。
Java Reflection API 在 Java 语言诞生时就被引入(对于一种常见的多用途编程语言而言,这曾经是一个非常前沿的概念),但是经过多年的发展才认识到强类型系统的用途和强大之处。JPA Metamodel API 将强类型引入到持久化实体中。例如,持久化实体在语义上区分为MappedSuperClass、Entity 和 Embeddable。在 JPA 2.0 之前,这种语义区分是通过持久化类定义中的对应类级别注释来表示的。JPA Metamodel 在 javax.persistence.metamodel 包中描述了 3 个独立的接口( MappedSuperclassType、EntityType 和 EmbeddableType ),以更加鲜明的对比它们的语义特征。类似地,可以通过接口(比如 SingularAttribute、CollectionAttribute和 MapAttribute)在类型定义级别上区分持久化属性。
除了方便描述之外,这些专门化的元模型接口还有实用优势,能够帮助构建类型安全的查询从而减少运行时错误。您在前面的例子中看到了一部分优势,随着我通过 CriteriaQuery 描述关于连接的例子,您将看到更多优势。
运行时作用域
一般而言,可以将 Java Reflection API 的传统接口与专门用于描述持久化元数据的javax.persistence.metamodel 的接口进行比较。要进一步进行类比,则需要对元模型接口使用等效的运行时作用域概念。java.lang.Class 实例的作用域由 java.lang.ClassLoader 在运行时划分。一组相互引用的 Java 类实例必须在 ClassLoader 作用域下定义。作用域的边界是严格或封闭 的,如果在 ClassLoader L 作用域下定义的类 A 试图引用不在 ClassLoader L 作用域之内的类 B,结果将收到可怕的 ClassNotFoundException 或 NoClassDef FoundError(对于处理包含多个 ClassLoader 的环境的开发人员或部署人员而言,问题就复杂了)。
现在将一组严格的可相互引用的类称为运行时作用域,而在 JPA 1.0 中称为持久化单元。持久化单元作用域的持久化实体在 META-INF/persistence.xml 文件的 < class> 子句中枚举。在 JPA 2.0 中,通过 javax.persistence.metamodel.Metamodel 接口让开发人员可以在运行时使用作用域。Metamodel 接口是特定持久化单元知道的所有持久化实体的容器,如图 5 所示:
图 5. 元模型接口是持久化单元中的类型的容器

这个接口允许通过元模型元素的对应持久化实体类访问元模型元素。例如,要获得对 Person持久化实体的持久化元数据的引用,可以编写:
EntityManagerFactory emf = ...; Metamodel metamodel = emf.getMetamodel(); EntityType< Person> pClass = metamodel.entity(Person.class); |
这是一个用类的名称通过 ClassLoader 获得 Class 的类比:
ClassLoader classloader = Thread.currentThread().getContextClassLoader();
Class< ?> clazz = classloader.loadClass("domain.Person");
|
可以在运行时浏览 EntityType< Person> 获得在 Person 实体中声明的持久化属性。如果应用程序在 pClass(比如 pClass.getSingularAttribute("age", Integer.class))上调用一个方法,它将返回一个 SingularAttribute< Person, Integer> 实例,该实例与实例化规范元模型类的静态 Person_.age 成员相同。最重要的是,对于应用程序可以通过 Metamodel API 在运行时引用的属性,是通过实例化静态规范元模型 Person_ 类向 Java 编译器提供的。
除了将持久化实体分解为对应的元模型元素之外,Metamodel API 还允许访问所有已知的元模型类 (Metamodel.getManagedTypes()),或者通过类的持久化信息访问元模型类,例如embeddable(Address.class),它将返回一个 EmbeddableType< Address> 实例(ManagedType< >的子接口)。
在 JPA 中,关于 POJO 的元信息使用带有源代码注释(或 XML 描述符)的持久化元信息进一步进行区分 —— 比如类是否是嵌入的,或者哪个字段用作主键。持久化元信息分为两大类:持久化(比如 @Entity)和映射(比如 @Table)。在 JPA 2.0 中,元模型仅为持久化注释(不是映射注释)捕捉元数据。因此,使用当前版本的 Metamodel API 可以知道哪些字段是持久化的,但不能找到它们映射到的数据库列。
规范和非规范
尽管 JPA 2.0 规范规定了规范的静态元模型类的精确样式(包括元模型类的完整限定名及其静态字段的名称),应用程序也能够编写这些元模型类。如果应用程序开发人员编写元模型类,这些类就称为非规范元模型。现在,关于非规范元模型的规范还不是很详细,因此对非规范元模型的支持不能在 JPA 提供者之间移植。您可能已经注意到,公共静态字段仅在规范元模型中声明,而没有初始化。声明之后就可以在开发 CriteriaQuery 时引用这些字段。但是,必须在运行时给它们赋值才有意义。尽管为规范元模型的字段赋值是 JPA 提供者的责任,但非规范元模型则不存在这一要求。使用非规范元模型的应用程序必须依赖于特定供应商机制,或开发自己的机制来在运行时初始化元模型属性的字段值。
注释处理和元模型生成
如果您有许多持久化实体,您将倾向于不亲自编写元模型类,这是很自然的事情。持久化提供者应该 为您生成这些元模型类。在规范中没有强制规定这种工具或生成机制,但是 JPA 之间已经私下达成共识,他们将使用在 Java 6 编译器中集成的 Annotation Processor 工具生成规范元模型。Apache OpenJPA 提供一个工具来生成这些元模型类,其生成方式有两种,一是在您为持久化实体编译源代码时隐式地生成,二是通过显式地调用脚本生成。在 Java 6 以前,有一个被广泛使用的称为 apt 的 Annotation Processor 工具,但在 Java 6 中,编译器和 Annotation Processor 的合并被定义为标准的一部分。
要像持久化提供者一样在 OpenJPA 中生成这些元模型类,仅需在编译器的类路径中使用 OpenJPA 类库编译 POJO 实体:
$ javac domain/Person.java |
将生成规范元模型 Person_ 类,它将位于 Person.java 所在的目录,并且作为该编译的一部分。
编写类型安全的查询
到目前为止,我已经构建了 CriteriaQuery 的组件和相关的元模型类。现在,我将展示如何使用 Criteria API 开发一些查询。
函数表达式
函数表达式将一个函数应用到一个或多个输入参数以创建新的表达式。函数表达式的类型取决于函数的性质及其参数的类型。输入参数本身可以是表达式或文本值。编译器的类型检查规则与 API 签名结合确定什么是合法输入。
考虑一个对输入表达式应用平均值的单参数表达式。CriteriaQuery 选择所有 Account 的平均余额,如清单 5 所示:
清单 5. CriteriaQuery 中的函数表达式
CriteriaQuery< Double> c = cb.createQuery(Double.class); Root< Account> a = c.from(Account.class);c.select(cb.avg(a.get(Account_.balance))); |
等效的 JPQL 查询为:
String jpql = "select avg(a.balance) from Account a";
|
在 清单 5 中,QueryBuilder 工厂(由变量 cb 表示)创建一个 avg() 表达式,并将其用于查询的 select() 子句。
该查询表达式是一个构建块,可以通过组装它为查询定义最后的选择谓词。清单 6 中的例子显示了通过导航到 Account 的余额创建的 Path 表达式,然后 Path 表达式被用作两个二进制函数表达式( greaterThan() 和 lessThan())的输入表达式,这两个表达式的结果都是一个布尔表达式或一个谓词。然后,通过 and() 操作合并谓词以形成最终的选择谓词,查询的 where() 子句将计算该谓词:
清单 6. CriteriaQuery 中的 where() 谓词
CriteriaQuery< Account> c = cb.createQuery(Account.class); Root< Account> account = c.from(Account.class); Path< Integer> balance = account.get(Account_.balance); c.where(cb.and(cb.greaterThan(balance, 100), cb.lessThan(balance), 200))); |
等效的 JPQL 查询为:
"select a from Account a where a.balance>100 and a.balance< 200"; |
符合谓词
某些表达式(比如 in())可以应用到多个表达式。清单 7 给出了一个例子:
清单 7. CriteriaQuery 中的多值表达式
CriteriaQuery< Account> c = cb.createQuery(Account.class); Root< Account> account = c.from(Account.class); Path< Person> owner = account.get(Account_.owner); Path< String> name = owner.get(Person_.name); c.where(cb.in(name).value("X").value("Y").value("Z")); |
这个例子通过两个步骤从 Account 进行导航,创建一个表示帐户所有者的名称的路径。然后,它创建一个使用路径表达式作为输入的 in() 表达式。in() 表达式计算它的输入表达式是否等于它的参数之一。这些参数通过 value() 方法在 In< T> 表达式上指定,In< T> 的签名如下所示:
In< T> value(T value); |
注意如何使用 Java 泛型指定仅对值的类型为 T 的成员计算 In< T> 表达式。因为表示Account 所有者的名称的路径表达式的类型为 String,所以与值为 String 类型的参数进行比较才有效,String 值参数可以是字面量或计算结果为 String 的另一个表达式。
将 清单 7 中的查询与等效(正确)的 JPQL 进行比较:
"select a from Account a where a.owner.name in ('X','Y','Z')";
|
在 JPQL 中的轻微疏忽不仅不会被编辑器检查到,它还可能导致意外结果。例如:
"select a from Account a where a.owner.name in (X, Y, Z)"; |
连接关系
尽管 清单 6 和 清单 7 中的例子将表达式用作构建块,查询都是基于一个实体及其属性之上的。但是查询通常涉及到多个实体,这就要求您将多个实体连接 起来。CriteriaQuery 通过类型连接表达式 连接两个实体。类型连接表达式有两个类型参数:连接源的类型和连接目标属性的可绑定类型。例如,如果您想查询有一个或多个 PurchaseOrder 没有发出的 Customer,则需要通过一个表达式将 Customer 连接到 PurchaseOrder,其中 Customer 有一个名为 orders 类型为 java.util.Set< PurchaseOrder> 的持久化属性,如清单 8 所示:
清单 8. 连接多值属性
CriteriaQuery< Customer> q = cb.createQuery(Customer.class); Root< Customer> c = q.from(Customer.class); SetJoin< Customer, PurchaseOrder> o = c.join(Customer_.orders); |
连接表达式从根表达式 c 创建,持久化属性 Customer.orders 由连接源(Customer)和Customer.orders 属性的可绑定类型进行参数化,可绑定类型是 PurchaseOrder 而不是 已声明的类型 java.util.Set< PurchaseOrder>。此外还要注意,因为初始属性的类型为java.util.Set,所以生成的连接表达式为 SetJoin,它是专门针对类型被声明为 java.util.Set的属性的 Join。类似地,对于其他受支持的多值持久化属性类型,该 API 定义CollectionJoin、ListJoin 和 MapJoin。(图 1 显示了各种连接表达式)。在 清单 8 的第 3 行不需要进行显式的转换,因为 CriteriaQuery 和 Metamodel API 通过覆盖 join() 的方法能够识别和区分声明为 java.util.Collection 或 List 或者 Set 或 Map 的属性类型。
在查询中使用连接在连接实体上形成一个谓词。因此,如果您想要选择有一个或多个未发送PurchaseOrder 的 Customer,可以通过状态属性从连接表达式 o 进行导航,然后将其与DELIVERED 状态比较,并否定谓词:
Predicate p = cb.equal(o.get(PurchaseOrder_.status), Status.DELIVERED).negate(); |
创建连接表达式需要注意的一个地方是,每次连接一个表达式时,都会返回一个新的表达式,如清单 9 所示:
清单 9. 每次连接创建一个唯一的实例
SetJoin< Customer, PurchaseOrder> o1 = c.join(Customer_.orders); SetJoin< Customer, PurchaseOrder> o2 = c.join(Customer_.orders); assert o1 == o2; |
清单 9 中对两个来自相同表达式 c 的连接表达式的等同性断言将失败。因此,如果查询的谓词涉及到未发送并且值大于 $200 的 PurchaseOrder,那么正确的构造是将 PurchaseOrder 与根 Customer 表达式连接起来(仅一次),把生成的连接表达式分配给本地变量(等效于 JPQL 中的范围变量),并在构成谓词时使用本地变量。
使用参数
回顾一下本文初始的 JPQL 查询(正确那个):
String jpql = "select p from Person p where p.age > 20";
|
尽管编写查询时通常包含常量文本值,但这不是一个良好实践。良好实践是参数化查询,从而仅解析或准备查询一次,然后再缓存并重用它。因此,编写查询的最好方法是使用命名参数:
String jpql = "select p from Person p where p.age > :age";
|
参数化查询在查询执行之前绑定参数的值:
Query query = em.createQuery(jpql).setParameter("age", 20); List result = query.getResultList(); |
在 JPQL 查询中,查询字符串中的参数以命名方式(前面带有冒号,例如 :age)或位置方式(前面带有问号,例如 ?3)编码。在 CriteriaQuery 中,参数本身就是查询表达式。与其他表达式一样,它们是强类型的,并且由表达式工厂(即 QueryBuilder)构造。然后,可以参数化清单 2 中的查询,如清单 10 所示:
清单 10. 在 CriteriaQuery 中使用参数
ParameterExpression< Integer> age = qb.parameter(Integer.class); Predicate condition = qb.gt(p.get(Person_.age), age); c.where(condition); TypedQuery< Person> q = em.createQuery(c); List< Person> result = q.setParameter(age, 20).getResultList(); |
比较该参数使用和 JPQL 中的参数使用:参数表达式被创建为带有显式类型信息 Integer,并且被直接用于将值 20 绑定到可执行查询。额外的类型信息对减少运行时错误十分有用,因为阻止参数与包含不兼容类型的表达式比较,或阻止参数与不兼容类型的值绑定。JPQL 查询的参数不能提供任何编译时安全。
清单 10 中的例子显示了一个直接用于绑定的未命名表达式。还可以在构造参数期间为参数分配第二个名称。对于这种情况,您可以使用这个名称将参数值绑定到查询。不过,您不可以使用位置参数。线性 JPQL 查询字符串中的整数位置有一定的意义,但是不能在概念模型为查询表达式树的 CriteriaQuery 上下文中使用整数位置。
JPA 查询参数的另一个有趣方面是它们没有内部值。值绑定到可执行查询上下文中的参数。因此,可以合法地从相同的 CriteriaQuery 创建两个独立可执行的查询,并为这些可执行查询的相同参数绑定两个整数值。
预测结果
您已经看到 CriteriaQuery 在执行时返回的结果已经在 QueryBuilder 构造 CriteriaQuery时指定。查询的结果被指定为一个或多个预测条件。可以通过两种方式之一在 CriteriaQuery 接口上指定预测条件:
CriteriaQuery< T> select(Selection< ? extends T> selection); CriteriaQuery< T> multiselect(Selection< ?>... selections); |
最简单并且最常用的预测条件是查询候选类。它可以是隐式的,如清单 11 所示:
清单 11. CriteriaQuery 默认选择的候选区段
CriteriaQuery< Account> q = cb.createQuery(Account.class); Root< Account> account = q.from(Account.class); List< Account> accounts = em.createQuery(q).getResultList(); |
在 清单 11 中,来自 Account 的查询没有显式地指定它的选择条件,并且和显式地选择的候选类一样。清单 12 显示了一个使用显式选择条件的查询:
清单 12. 使用单个显式选择条件的 CriteriaQuery
CriteriaQuery< Account> q = cb.createQuery(Account.class); Root< Account> account = q.from(Account.class); q.select(account); List< Account> accounts = em.createQuery(q).getResultList(); |
如果查询的预测结果不是候选持久化实体本身,那么可以通过其他几个构造方法来生成查询的结果。这些构造方法包含在 QueryBuilder 接口中,如清单 13 所示:
清单 13. 生成查询结果的方法
< Y> CompoundSelection< Y> construct(Class< Y> result, Selection< ?>... terms);CompoundSelection< Object[]> array(Selection< ?>... terms);CompoundSelection< Tuple> tuple(Selection< ?>... terms); |
清单 13 中的方法构建了一个由其他几个可选择的表达式组成的预测条件。construct() 方法创建给定类参数的一个实例,并使用来自输入选择条件的值调用一个构造函数。例如,如果CustomerDetails — 一个非持久化实体 — 有一个接受 String 和 int 参数的构造方法,那么CriteriaQuery 可以通过从选择的 Customer — 一个持久化实体 — 实例的名称和年龄创建实例,从而返回 CustomerDetails 作为它的结果,如清单 14 所示:
清单 14. 通过 construct() 将查询结果包放入类的实例
CriteriaQuery< CustomerDetails> q = cb.createQuery(CustomerDetails.class); Root< Customer> c = q.from(Customer.class); q.select(cb.construct(CustomerDetails.class,c.get(Customer_.name), c.get(Customer_.age)); |
可以将多个预测条件合并在一起,以组成一个表示 Object[] 或 Tuple 的复合条件。清单 15 显示了如何将结果包装到 Object[] 中:
清单 15. 将结果包装到 Object[]
CriteriaQuery< Object[]> q = cb.createQuery(Object[].class); Root< Customer> c = q.from(Customer.class); q.select(cb.array(c.get(Customer_.name), c.get(Customer_.age)); List< Object[]> result = em.createQuery(q).getResultList(); |
这个查询返回一个结果列表,它的每个元素都是一个长度为 2 的 Object[],第 0 个数组元素为 Customer 的名称,第 1 个数组元素为 Customer 的年龄。
Tuple 是一个表示一行数据的 JPA 定义接口。从概念上看,Tuple 是一个 TupleElement 列表 — 其中 TupleElement 是源自单元和所有查询表达式的根。包含在 Tuple 中的值可以被基于 0 的整数索引访问(类似于熟悉的 JDBC 结果),也可以被 TupleElement 的别名访问,或直接通过 TupleElement 访问。清单 16 显示了如何将结果包装到 Tuple 中:
清单 16. 将查询结果包装到 Tuple
CriteriaQuery< Tuple> q = cb.createTupleQuery(); Root< Customer> c = q.from(Customer.class); TupleElement< String> tname = c.get(Customer_.name).alias("name"); q.select(cb.tuple(tname, c.get(Customer_.age).alias("age"); List< Tuple> result = em.createQuery(q).getResultList(); String name = result.get(0).get(name); String age = result.get(0).get(1); |
这个查询返回一个结果列表,它的每个元素都是一个Tuple。反过来,每个二元组都带有两个元素 — 可以被每个 TupleElement 的索引或别名(如果有的话)访问,或直接被 TupleElement 访问。清单 16 中需要注意的两点是 alias() 的使用,它是将一个名称绑定到查询表达式的一种方式(创建一个新的副本),和 QueryBuilder 上的createTupleQuery() 方法,它仅是 createQuery(Tuple.class) 的代替物。
这些能够改变结果的方法的行为和在构造期间被指定为 CriteriaQuery 的类型参数结果共同组成 multiselect() 方法的语义。这个方法根据最终实现结果的 CriteriaQuery 的结果类型解释它的输入条件。要像 清单 14 一样使用 multiselect() 构造 CustomerDetails 实例,您需要将 CriteriaQuery 的类型指定为 CustomerDetails,然后使用将组成 CustomerDetails 构造方法的条件调用 multiselect(),如清单 17 所示:
清单 17. 基于结果类型的 multiselect() 解释条件
CriteriaQuery< CustomerDetails> q = cb.createQuery(CustomerDetails.class); Root< Customer> c = q.from(Customer.class); q.multiselect(c.get(Customer_.name), c.get(Customer_.age)); |
因为查询结果类型为 CustomerDetails,multiselect() 将其预测条件解释为CustomerDetails 构造方法参数。如将查询指定为返回 Tuple,那么带有相同参数的multiselect() 方法将创建 Tuple 实例,如清单 18 所示:
清单 18. 使用 multiselect() 方法创建 Tuple 实例
CriteriaQuery< Tuple> q = cb.createTupleQuery(); Root< Customer> c = q.from(Customer.class); q.multiselect(c.get(Customer_.name), c.get(Customer_.age)); |
如果以 Object 作为结果类型或没有指定类型参数时,multiselect() 的行为会变得更加有趣。在这些情况中,如果 multiselect() 使用单个输入条件,那么返回值将为所选择的条件。但是如果 multiselect() 包含多个输入条件,结果将得到一个 Object[]。




![华为手机[助手]备份的db通讯录文件如何恢复到其他手机](https://img-blog.csdnimg.cn/20190513214420796.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MzkxMTM3NA==,size_16,color_FFFFFF,t_70)