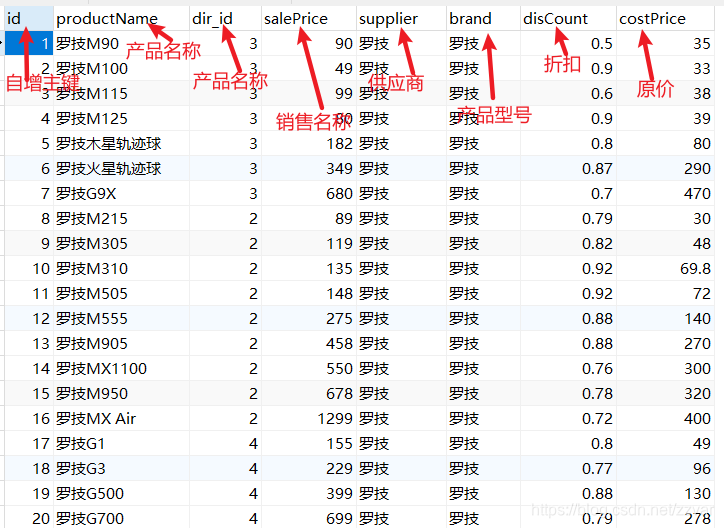
我们在建立数据模型后通常希望在外部数据验证模型的检验能力。然而当没有外部数据可以验证的时候,交叉验证也不失为一种方法。交叉验验证(交叉验证,CV)则是一种评估模型泛化能力的方法,广泛应用中于数证据采挖掘和机器学习领域,在交叉验证通常将数据集分为两部分,一部分为训练集,用于建立预测模型;另一部分为测试集,用于测试该模型的泛化能力。
在如何划分2个集合的问题上,统计学界提出了多种方法:简单交叉验证、留一交叉验证、k折交叉验证、多重三折交叉验证、分层法、自助法等。
简单交叉验证:是我们临床论文中最常使用到的,从数据中随机选择中随机选择70%点的数据作为训练集建立模型,30%的数据当做外部数据来验证模型的预测能力。但其最终所得结果与集合划分比率密切相关,不同划分比率结果变异可能较大。该方法在总数据据集并不是非常大的情形下很难达到准确实评模型的目的。
留一交叉验证是指:假设在总集合中共有有n个体,每次选取1个体作为测试试集,其余个体作为训练集。总共进行n 次训练,取平均值是最终评价指标。留一交叉验证较为可靠靠,在每次模型训练中纳入几度乎所有个体,当总集合中个体 数目轨迹的情势下计算时间较长。
k折交叉验证可以看成是留一交叉验证的简化版,是将原始数据据随机平均分为k个子集(通常5-10个),每个子集做测试集的同时,其余k-1个子集合并作为训练 ,进行 k 次训练,取各评价指标(灵敏度、特异度、AUC等)的平均值。 测试通过平均的评价指来降低训练集和测试集划分方式对预测结果的影响,有研究值表明k 折评估准准确性高,当k为5或10时在评估准准后性和计算复杂性下综合性能最优。
10折交叉验证是指将原始数据集随机划分为样本数近乎相等的10个子集,轮流将其中的9个合并作为训练集,其余1个作为测试试集。算正确率等评价指标,最终终通过K次试验验后取评价指标的平均值来评估该模型的泛化能力。
10折交叉证验证的基本步骤下:
( 1)原始数据集划分为10个样本量尽可均衡的子集;
( 2)使用第1个子集作为测试集,第2~9个子集合并作为训练集;
( 3)使用训练集对模型进行训练,计算多种评价指标在测试集下的结果;
( 4) 重复2 ~3 步流亜,轮将第2 ~10个子集作为测试集;
( 5)计算各评价指标的平均值作为最终结果。

今天我们通过R语言来演示k折交叉验证(K取10),需要使用到caret包和pROC包,需要使用到我们既往的不孕症数据(公众号回复:不孕症可以获得该数据)
首先导入包和导入数据
library("caret")
library(pROC)
bc<-read.csv("E:/r/test/buyunzheng.csv",sep=',',header=TRUE)
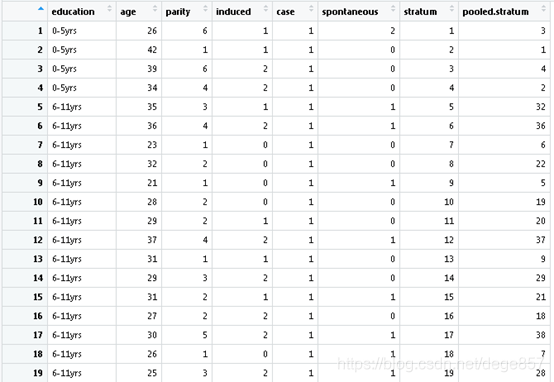
数据有8个指标,最后两个是PSM匹配结果,我们不用理他,其余六个为:
Education:教育程度,age:年龄,parity产次,induced:人流次数,case:是否不孕,这是结局指标,spontaneous:自然流产次数。
有一些变量是分类变量,我们需要把它转换一下
bc$education<-ifelse(bc$education=="0-5yrs",0,ifelse(bc$education=="6-11yrs",1,2))
bc$spontaneous<-as.factor(bc$spontaneous)
bc$case<-as.factor(bc$case)
bc$induced<-as.factor(bc$induced)
bc$education<-as.factor(bc$education)使用caret包的createFolds函数根据结果变量把数据分成10份,因为是随机分配,为了可重复性,我们先设立一个种子
set.seed(666)
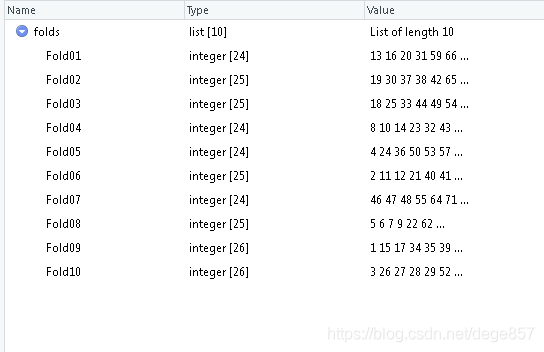
folds <- createFolds(y=bc$case,k=10)###分成10份数据已经分成了10份
接下来我们可以根据每一份的数据建立方程,并求出AUC,95%CI和截点,并且画出ROC曲线
我们先来做第一个数据的,要提取列表的数据,需要做成[[1]]这种形式,
fold_test <- bc[folds[[1]],]#取fold 1数据,建立测试集和验证集
fold_train <- bc[-folds[[1]],]#建立预测模型
fold_pre <- glm(case ~ age + parity +spontaneous,family = binomial(link = logit), data =fold_train )###建立模型
fold_predict <- predict(fold_pre,type='response',newdata=fold_test)##生成预测值
roc1<-roc((fold_test[,5]),fold_predict)
round(auc(roc1),3)##AUC
round(ci(roc1),3)##95%CI
得出结果后我们可以进一步画图
plot(roc1, print.auc=T, auc.polygon=T, grid=c(0.1, 0.2),grid.col=c("green", "red"), max.auc.polygon=T,auc.polygon.col="skyblue", print.thres=T)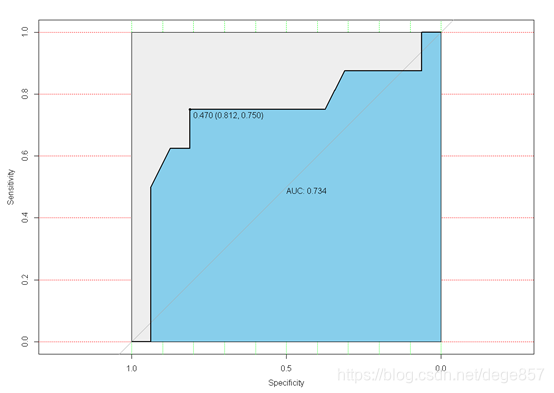
也可以化成这样的图
plot(1-roc1$specificities,roc1$sensitivities,col="red",lty=1,lwd=2,type = "l",xlab = "specificities",ylab = "sensitivities")
abline(0,1)
legend(0.7,0.3,c("auc=0.34","ci:0.457-0.99."),lty=c(1),lwd=c(2),col="red",bty = "n")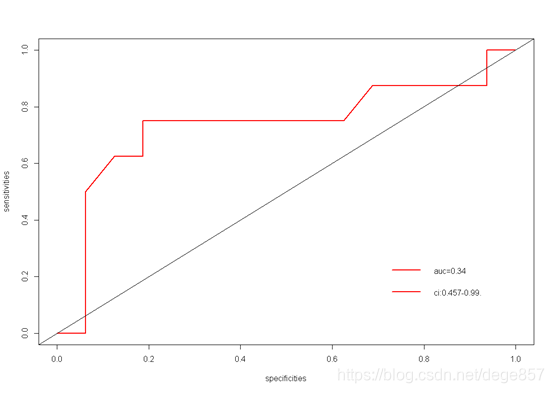
嫌一个一个做比较麻烦的话我们也可以做成循环,一次跑完结果
先建立一个auc的空值,不然跑不了
auc_value<-as.numeric()###建立空值
建立循环
for(i in 1:10){fold_test <- bc[folds[[i]],] #取folds[[i]]作为测试集fold_train <- bc[-folds[[i]],] # 剩下的数据作为训练集fold_pre <- glm(case ~ age + parity +spontaneous,family = binomial(link = logit), data =fold_train )fold_predict <- predict(fold_pre,type='response',newdata=fold_test)auc_value<- append(auc_value,as.numeric(auc(as.numeric(fold_test[,5]),fold_predict)))
}这样10个数据的AUC值就求出来了,你可以根据临床需要进行取舍,通常取平均值多一些

取平均值

这样模型的验证结果就出来啦,10折交叉验证在实践中存存在的局限性在于,当样本量较少时,将该样本随机分为10份会导致每次使用的训练集变化较大,导致最终10组评价指标的变异程度相对较大。 当样本量较少或数据不平衡衡程度较强时,可能会出现其中某次训练集中只有有单一预测结局的情况,此时应减小折数,重新随机划分子集,采用分层法进行交叉验证或使用自助法进行验证。
参考文献:
[1]梁子超, 李智炜, 赖铿,等. 10折交叉验证用于预测模型泛化能力评价及其R软件实现[J]. 中国医院统计, 2020, v.27(04):7-10.
[2]家会臣, 靳竹萱, 李济洪. Logistic模型选择中三种交叉验证策略的比较[J]. 太原师范学院学报(自然科学版), 2012, 011(001):87-90.
[3]胡局新, 张功杰. 基于K折交叉验证的选择性集成分类算法[J]. 科技通报, 2013(12):115-117.
[4]微信公众号:机器学习养成记. k折交叉验证(R语言)
[5]刘学艺, 李平, 郜传厚. 极限学习机的快速留一交叉验证算法[J]. 上海交通大学学报, 2011(08):49-54.
[6] Yadav S , Shukla S . Analysis of k-Fold Cross-Validation over Hold-Out Validation on Colossal Datasets for Quality Classification[C]// 2016 IEEE 6th International Conference on Advanced Computing (IACC). IEEE, 2016.