MySQL语句优化
- 1.通过EXPLAIN分析低效SQL的执行计划
- 2.使用索引(其下测试效率通过查询结果的type列的值进行评判)
- 1)对于创建的多列索引,只要查询的条件中用到了最左边的列,索引一般就会被使用, 举例说明如下:
- 2)对LIKE语法的测试
- 3)IS NULL 条件测试
- 4)OR 测试
- 5)WHERE条件中不同类型测试
- 6)不建议在查询条件中使用函数
- 7)不等于(!=和<>)比较符的使用
- 8)大于小于(>或<)比较符的使用
- 3.语句优化
- 1)INSERT优化
- 2)GROUP BY优化
- 3)ORDER BY优化
- 最优排序
- 效率对比
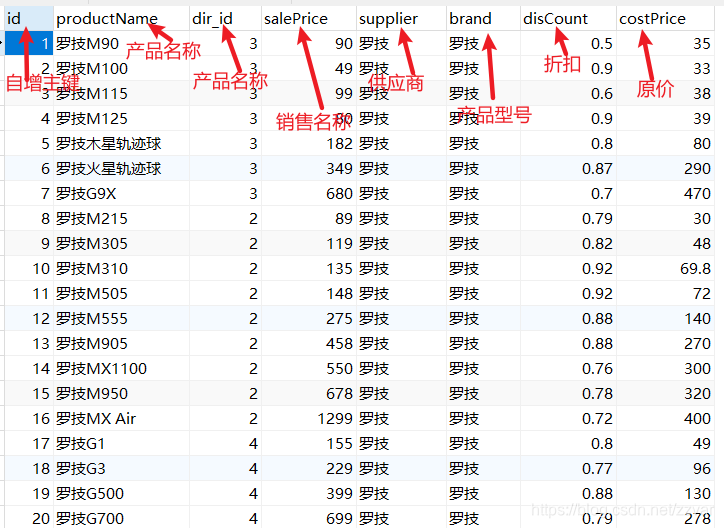
使用wk_test_table表进行以下测试,已有复合索引(按照先后顺序):(attachment_type,extension)
1.通过EXPLAIN分析低效SQL的执行计划
通过EXPLAIN或者DESC命令获取MySQL如何执行SELECT语句的信息,包括在SELECT语句执行过程中表如何连接和连接的顺序,比如对wk_test_table. file_size字段做求和(sum)操作,相应 SQL 的执行计划如下:
EXPLAIN SELECT SUM(sp.file_size )
FROM wk_test_table as sp

如上图所示每个列的简单解释如下:
select_type:表示 SELECT 的类型,常见的取值有:
SIMPLE(简单表,即不使用表连接 或者子查询)
PRIMARY(主查询,即外层的查询)
UNION(UNION 中的第二个或者后面的查询语句)
SUBQUERY(子查询中的第一个SELECT)等。
table:输出结果集的表。
type:表示表的连接类型,性能由好到差的连接类型为:
system(表中仅有一行,即常量表)。
const(单表中最多有一个匹配行,例如primary key或者unique index)。
eq_ref(对于前面的每一行,在此表中只查询一条记录,简单来说,就是多表连接中使用primary key或者unique index)。
ref(与eq_ref类似,区别在于不是使用primary key或者unique index,而是使用普通的索引)。
ref_or_null(与ref类似,区别在于条件中包含对NULL的查询)。
index_merge(索引合并优化)。
unique_subquery(in的后面是一个查询主键字段的子查询)。
index_subquery(与unique_subquery类似,区别在于in的后面是查询非唯一索引字段的子查询)。
range(单表中的范围查询)。
index(对于前面的每一行,都通过查询索引来得到数据)。
all(对于前面的每一行,都通过全表扫描来得到数据)。
possible_keys:表示查询时,可能使用的索引。
key:表示实际使用的索引。
key_len:索引字段的长度。
rows:扫描行的数量。
filtered:返回结果的行占需要读到的行(rows列的值)的百分比。
Extra:执行情况的说明和描述。
2.使用索引(其下测试效率通过查询结果的type列的值进行评判)
1)对于创建的多列索引,只要查询的条件中用到了最左边的列,索引一般就会被使用, 举例说明如下:
图一:
图二:

图三:

结论:
从三图比较来看 ,即便where条件中不使用attachment_type,extension字段的组合条件,索引仍然能用到,这就是索引的前缀特性(按照索引列顺序查询)。但是如果只按 extension条件查询表,虽然索引能被用到,但效率也是非常的不好。
2)对LIKE语法的测试
图一:

图二:

结论:
- 从图一可见 ,第一个SQL没有用到了索引,且效率很差,而第二个SQL使用索引,效率高于第一个SQL,区别就在于“%”的位置不同,前者把“%”放到第一位就执行效率极低,而后者没有放到第一位就执行效率略高。
- 从图二可知,如果like后面跟的是一个列的名字,会与双边%效率一样
3)IS NULL 条件测试

结论:
由图可见 , 如果列名是索引,使用 is null 条件时候效率较高。但是is not null条件会导致索引失效。
4)OR 测试

备注:第一条sql执行时只有复合索引 (attachment_type,extension),第二条sql执行时新增普通索引extension
结论:
- 由图可见 , 使用OR连接的所有条件列必须都有自己的索引(复合索引的第一个列或者单个普通索引),否则查询不会使用索引,效率极低。
- 对于同一字段,使用OR和IN,EXPLAIN展示的效率都是一样的。
5)WHERE条件中不同类型测试

结论:
- 由图可见 , 可见在attachment_type这个列上存在索引,两个SQL都用到了索引,但是第二个SQL语句的where条件中 字符常量值是int型,与attachment_type数据类型不相符,导致执行效率极低。
- 所以,如果列类型是字符串,那么一定记得在where条件中把字符常量值用引号引起来,否则即便这个列上有索引,MySQL执行效率也是极低的,因为MySQL默认把输入的常量值进行转换以后才进行检索。
6)不建议在查询条件中使用函数
使用函数就会操作索引列,会导致索引失效而转向全表扫描。
7)不等于(!=和<>)比较符的使用
在使用不等于(!=或者<>)的时候 无法使用索引会导致全表扫描。
8)大于小于(>或<)比较符的使用
最左索引使用>或<的时候 无法使用索引会导致全表扫描。
3.语句优化
1)INSERT优化
批量插入推荐使用以下语法:
insert into test values(1,2),(1,3),(1,4)…
2)GROUP BY优化

结论:
由图可知,MySQL会对GROUP BY之后的字段进行自动排序,这样会产生排序造成的不必要消耗。如果查询包括GROUP BY,但用户想要避免排序结果的消耗,则可以指定ORDER BY NULL禁止排序。
3)ORDER BY优化
- 无过滤条件(无where和limit)的order by 必然会出现 Using filesort。
- 过滤条件中的字段和order by 后跟的字段的顺序不一致,必然会出现 Using filesort。
- order by后跟的字段排序即有DESC也有ASC,必然会出现Using filesort。
- where条件的值确定,且order by后跟了跟了where条件的排序字段(order by 字段去除定值字段后剩余单字段),即使order by后跟的字段和组合索引字段顺序不一致,也不会出现Using filesort。
最优排序

效率对比

单/多字段order by:
- 对查询条件和排序列创建联合索引,排序没有Using filesort,高效。
- 对查询条件创建索引,但是排序列没有索引, 排序有Using filesort,不用索引。
- 对排序列创建索引,但是查询条件没有索引, 排序有Using filesort,不用索引。
结论:
- 由图可见,order by子句,尽量使用index方式排序,避免使用filesort方式。
- 走不走索引还是跟where条件里的字段是否建立索引有关,如果where条件里字段未建立索引,那查询不会使用索引,建立联合索引,减少了using_filesort的排序操作,可以提高查询效率。