1、DIM层概述
1.1、DIM定义
- DIM:维表的公共层,贯穿数据模型的各个层次
(1)贯穿数据模型的各个层次,保留业务过程中的实体信息
(2)用来关联事实表将数据宽表化
1.2、DIM数据组成
- DIM:存放维度数据&基础数据
(1)维度数据:一般指一些业务状态,代码的解释表(即码表)
(2)基础数据:存储业务需要关联的基础数据
2、DIM层数据规范
2.1、DIM数据规范
(1)最基础要求:不同字段的含义必须不同,相同字段的含义必须相同;
(2)DIM较多的是和DWS生成ADS;
2.2、DIM表结构
(1)表结构:实体(主键)+维度
(2)命名:dim_表名__di
- 前缀统一为dim,后缀统一(小时级别为h,天级别为1d,月级别为1m)
(3)生命周期:360天
3、DIM开发样例(小维表来源业务系统)
- 大维表:业务侧要求每天一个分区装维度数据
绪论、需求说明
- 将ODS维表数据全量抽取到DIM层,按天分区保留每天最新的维度数据
create table T_YYBZB_TGH_BANKINFO
(id int(8),bank_id int(8),bank_name varchar(200),source_date varchar(200)
);
insert into T_YYBZB_TGH_BANKINFO (ID, BANK_ID, BANK_NAME)values (11, 11, '工商银行(广州)','20210101');
3.1、创建hive目标表
(1)创建hive目标表
create table dim.dim_t_yybzb_tgh_bankinfo_di
(id int,bank_id int,bank_name string
)
partitioned by (`pt` string)
row format delimited fields terminated by ','
(2)配置SQL组件创建表
- 配置Spark数据源
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YTKA16fy-1639123208275)(C:\Users\PROTH\AppData\Roaming\Typora\typora-user-images\image-20211208164131511.png)]
(3)部署上线

(4)调试运行

- 运行结果日志

3.2、创建表分区
(1)编写SQL脚本
alter table dim.dim_t_yybzb_tgh_bankinfo_di drop if exists partition(pt=${pt})alter table dim.dim_t_yybzb_tgh_bankinfo_di add if not exists partition (pt=${pt})
(2)配置SQL组件
- 若分区存在则删除

- 创建表分区

3.3、Pyspark脚本导入数据
(1)编写Python脚本
- 编写主程序
#!/usr/bin/python
# encoding:utf-8from pyspark import SparkContext
from pyspark.sql import HiveContext
import sys
import re
import timeimport importlib
importlib.reload(sys)#进行相关配置项定义
def dropFrame(rows):x = ''for s in rows:x += str(s) + ','x = x[:-1]return xinput_pt = sys.argv[1]output_feature_hdfs_path = '/user/hive/warehouse/dim.db/dim_t_yybzb_tgh_bankinfo_di/' + '20211213' + '/'key_cal = 'ods_t_yybzb_tgh_bankinfo_di'#spark-job编写
sc = SparkContext(appName=key_cal + "_sql_daily")hsqlContext = HiveContext(sc)midsqlDf = hsqlContext.sql("select ""id,""bank_id,""bank_name ""from ods.ods_t_yybzb_tgh_bankinfo_di ""where pt = {pt}".format(pt=input_pt))#/user/hive/warehouse/dim.db/dim_t_yybzb_tgh_bankinfo_di/20190724
save_path = output_feature_hdfs_path
keySeconds = midsqlDf.rdd.map(lambda row: dropFrame(row))
keySeconds.repartition(5).saveAsTextFile(save_path)sc.stop()
(2)配置Spark组件
/opt/module/spark-3.1.2/bin/spark-submit --master local --queue default --driver-memory 512m --driver-cores 2 --num-executors 4 --executor-memory 1G --executor-cores 2 --conf spark.default.parallelism=4 test1.py
- 将脚本上传到资源中心

- 配置Spark组件
程序类型:python
程序参数:${pt}

(3)参数传递
- 设置全局参数为T-1

(4)定时任务设置
- 设置时间:固定每天6点跑批

- 原因未明:日志报错spark提交路径出错,but命令行提交能成功,待解决
3.4、SQL脚本导入数据
(1)编写SQL脚本
insert overwrite table dim.dim_t_yybzb_tgh_bankinfo_di partition (pt=${pt})
select id,bank_id,bank_name
from ods.ods_t_yybzb_tgh_bankinfo_di
(2)配置SQL组件
- 参数配置:${pt}

(3)调试运行
- 上线部署后运行

- 查看hive表分区文件

(4)定时调度
- 每天6点定时调度

4、DIM开发样例(小维表)
- 小维表规定:小维表(配置表)只能删除/新增,不能更新数据
绪论、需求说明
- 将ODS维表数据全量抽取到DIM层,按天分区保留每天最新的维度数据
create table T_YYBZB_TGH_BANKINFO
(id int(8),bank_id int(8),bank_name varchar(200),source_date varchar(200)
);
insert into T_YYBZB_TGH_BANKINFO (ID, BANK_ID, BANK_NAME)values (11, 11, '工商银行(广州)','20210101');
4.1、创建hive目标表
(1)编写建表SQL脚本
- 增加delete_flag标记,适用于源系统存在硬删除状况
create table dim.dim_t_yybzb_tgh_bankinfo3_di
(id int,bank_id int,bank_name string,delete_flag int
)
row format delimited fields terminated by ','#创建中间临时表
create table tmp.tmp_t_yybzb_tgh_bankinfo3_di
(id int,bank_id int,bank_name string,delete_flag int
)
partitioned by (`pt` string)
row format delimited fields terminated by ','
(2)配置SQL组件
- 数据源:spark
- sql类型:非查询

(3)部署上线

(4)运行脚本
- 进入画布

- 运行建表脚本
(5)查看日志

4.2、初始化导入数据
(1)编写初始化脚本
insert overwrite table dim.dim_t_yybzb_tgh_bankinfo3_di
select id,bank_id,bank_name,'1' as delete_flag
from ods.ods_t_yybzb_tgh_bankinfo_di
(2)配置SQL组件
- 数据源:Spark
- sql类型:非查询

(3)部署上线

(4)运行脚本
-
进入画布

-
运行脚本

4.3、增量更新数据
(1)创建临时表分区
alter table tmp.tmp_t_yybzb_tgh_bankinfo3_di drop if exists partition(pt=${pt})alter table tmp.tmp_t_yybzb_tgh_bankinfo3_di add if not exists partition (pt=${pt})
(2)临时表用来装载计算后的数据
insert overwrite table tmp.tmp_t_yybzb_tgh_bankinfo3_di partition(pt=${pt})
select
if(t1.bank_id is not null,t1.id,t2.id) as id,
if(t1.bank_id is not null,t1.bank_id,t2.bank_id) as bank_id,
if(t1.bank_id is not null,t1.bank_name,t2.bank_name) as bank_name,
if((t1.bank_id is not null) and (t2.bank_id is null),0,1) as delete_flag
from dim.dim_t_yybzb_tgh_bankinfo3_di t1 full join ods.ods_t_yybzb_tgh_bankinfo_di t2
on t1.bank_id = t2.bank_id
where t2.pt=${pt}
- 注意事项:中间结果数据一般建分区表保留时间一周,便于回滚
(3)将临时表数据导入目标表
insert overwrite table dim.dim_t_yybzb_tgh_bankinfo3_di
select id,bank_id,bank_name,delete_flag
from tmp.tmp_t_yybzb_tgh_bankinfo_di
where pt=${pt}
(4)配置SQL组件
①删除表分区后创建表分区

②配置任务前置依赖(依赖于ETL作业)
- 告警配置:超时告警&超时失败

③配置SQL组件一,将计算后的数据插入到临时表中

④配置SQL组件二,将临时表中更新数据插入到DIW表中

⑤配置全局参数
- 在保存画布后,设置全局进行全局参数配置

- 整体任务流程图如下

(5)调试运行
①将JOB部署上线

②进入画布

③调试运行

④查看运行结果

(6)定时调度
-
调度周期:每天凌晨6点开始跑数

-
定时管理查看


5、DIM开发样例(大维表)
绪论
- 将ODS上报数据增量抽取到DIM层,生成公共维度,按天分区
create table ods.ods_ios_di(
p_date string
,etl_time string
,server_ip string
,log_time string
,guid string
,gender string
,age String
,city String
,phone string
,appid string
,msgid string
,httpcode string
,httpcontent string
,msg string
)
partitioned by (`pt` string)
row format delimited fields terminated by ',';
5.1、创建hive目标表
(1)编写建表脚本
CREATE TABLE dim.dim_ios_di(
ftime,
guid,
basic_info
)
partitioned by (`pt` string)
row format delimited fields terminated by ',';
(2)配置SQL组件创建表
- 数据源:hive::dim
- sql类型:非查询

(3)部署上线运行
-
部署上线

-
进入画布单独运行建表脚本

3.2、测试数据
(1)编写业务处理逻辑脚本
- 处理逻辑:进行数据转换,生成公共维度
insert overwrite dim.dim_ios_di partition(pt=${pt})
select ftime,guid,concat(gender,'_',age_level,'_',city_level) basic_info
from(select p_date as ftime,guid as guid,if(gender in(1,2),cast(gender as string),'-')gender,case when age between 1 and 6 then'1'when age between 7 and 12 then'2'when age between 13 and 15 then'3'when age between 16 and 18 then'4'when age between 19 and 22 then'5'when age between 23 and 25 then'6' when age between 26 and 30 then'7'when age between 31 and 40 then'8'when age between 41 and 50 then'9'when age between 51 and 99 then'10' else '-' end age_level,if(city in (0,1,2,3,4,5,6),cast(city as string),'-') as city_level
from ods.ods_ios_di
where pt = 2222
and (gender is not null or age is not null or city is not null)
)tmp
(2)配置SQL组件
-
数据源:hive::dwd
-
sql类型:非查询
-
自定参数:${pt}
-
前置SQL:
alter table dim.dim_ios_di drop if exists partition(pt=${pt})
alter table dim.dim_ios_di add if not exists partition (pt=${pt})

(3)配置依赖
- 告警策略:超时告警、超时失败。
- 依赖周期:日、今天

(4)运行调试
- 部署上线

- 进入画布,运行链路

- 补数,跑一周数据后进行对数
- 串行执行:资源不足时使用
- 并行执行:资源充足时使用

3.3、定时调度
(1)调度周期
- 每天凌晨6点调度前一天数据

(2)失败策略
- 失败策略:结束

(3)通知策略
- 通知策略:失败发

6、常见问题
6.1、Spark数据源配置
(1)启动Spark thriftserver
sbin/start-thriftserver.sh --hiveconf hive.server2.thrift.port=10001 --master yarn --driver-cores 1 --driver-memory 1G --executor-cores 1 --executor-memory 1G -num-executors 2
- 运行结果

(2)dolphinscheduler配置Spark数据源
- 数据源中心 --> 配置数据源

6.2、Spark任务提交报错
(1)报错现状
- 报错现状:Cannot run program “python3”: error=2, 没有那个文件或目录

(2)报错原因
- 系统只有自带的python2,没有python3,需要安装
(3)解决方案
- 在linux下安装python3
6.3、/bin/spark-submit: 没有那个文件或目录
(1)问题现状

(2)问题原因
- dolphinscheduler_env.sh文件未正确配置spark路径
(3)解决方案
vim dolphinscheduler_env.sh#添加Spark环境变量,根据个人电脑路径添加
#SPARK_HOME
export SPARK_HOME=/opt/module/spark-3.1.2
export PATH=$PATH:$SPARK_HOME/bin
export PATN=$PATH:$SPARK_HOME/sbin
6.4、hive NullPointerException null
(1)问题原因
- 报错:空指针异常
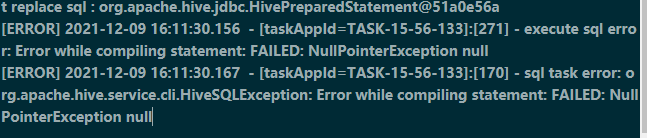
(2)问题原因
- hive的远程服务出错
(3)解决方案
- 重启hiveserver2服务
6.5、shell调PySpark出错
(1)问题现状
Exception in thread "main" java.io.IOException: Cannot run program "python3": error=2, 没有那个文件或目录

(2)问题原因
- pyspark脚本的解释器路径为 /usr/bin/python
- 实际环境如下

(3)解决方案
- 创建python3的软连接
sudo ln -s /opt/module/Python-3.6.5/ python3
- 修改脚本解释器路径为python3
#!/usr/bin/python