赫兹期货量化将继续为构建多重状态、可扩展的交易系统奠定基础。 在本文的框架内,我想为您展示如何利用前几篇文章中的发展成果,来进一步阐述交易过程的广泛可能性。 这有助于从这些层面评估策略,来弥补其它分析方法未能涵盖的地方。 在本文中,我探索了将复杂的、多重状态的样本转换为简单的双重状态样本的可能性。 这项分析是依照研究风格完成的。
简化数据的有用形式

假设有一种策略,一笔接一笔地进行多次交易,且无重叠;也就是说,严格遵守一笔新订单会在前一笔订单平仓后再开立。 如果我们需要评估成功或失败的概率,并衡量实现盈利或亏损所需的平均时间,我们将看到订单会出现大量不同的状态(它们以不同的结果了结)。 为了能够将分形公式应用于此类策略,我们首先需要将这些策略转换为可依据分形框架研究的情况。 为了实现这一点,我们需要将我们的策略表述为一个具有等距止损级别的订单,它有往上走和往下走的概率,就像我们的分形一样。 然后,我们可以应用分形公式。 此外,往上走和往下走会有不同的生存期。 为了把任何策略简化为我们在前一篇文章中发现的分形公式框架中可以描述的类型之一,我们首先需要判定哪些值必须已知,才能应用分形公式。 此处的一切都很简单:
-
P[1] – 往上走的概率
-
T[1] – 平均往上走形成时间
-
T[2] – 平均往下走形成时间
首先,当步阶数量趋于无穷大时,我们需要考虑极限值:
-
(P[1] * T[1] + (1 -P[1])*T[2]) * n = T(n)
-
(P[1] * Pr - (1 -P[1])*Pr) * n = P(n)
为了更好地理解上述表达式,有必要写出两个极限:
-
Lim(n --> +infinity)[P/P0(n)] = 1
-
Lim(n --> +infinity)[T/T0(n)] = 1
这些极限是说,赫兹期货量化以 “n” 的数量或交易量进行相同的实验,赫兹期货量化总是会从主要的广谱实验中,得到包含所有初级实验所用的总时间。 此外,我们总是会得到最终交易余额的不同位置。 另一方面,直觉上很清楚,在无限多次的实验中,实际值将趋于该极限。我们可以用随机数生成器来证明这个事实。
-
n - 模拟的步阶次数
-
1-P[1] – 往下走的概率
-
T0(n) – 在 “n” 步上花费的实际时间
-
P0(n) – “n” 步的余额或价格的实际偏移
-
T(n) - 在 “n” 步上花费的时间极限
-
P(n) – “n” 步的极限偏移
这一逻辑可导出两个方程,但其中的未知数太多。 这并不奇怪,因为这才只是开始。 但这些方程只描述了推导系统(我们需要得到的那个)。 对于源系统的方程也类似:
-
(P*[1] * T[1] + P*[2])*T*[2] + … + P*[N])*T*[N] ) * m = T(m)
-
(P*[1] * Pr*[1] + P*[2]*Pr*[2] + … + P*[N1]*Pr*[N1]) * m - (P*[N2] * Pr*[N1] + P*[N1+1]*Pr*[N1+1] + … + P*[N2]*Pr*[N2]) * m = P(m)
-
P*[1] + P[*2] + … + P*[N2] = 1 – 概率形成了一个完整的分组
极限也相同,并且它们显示相同的值:
-
Lim(m --> +infinity)[P/P0(m)] = 1
-
Lim(m --> +infinity)[T/T0(m)] = 1
此处用到的变量如下所述:
-
m – 模拟步阶数量
-
T0(m) – 在 “m” 步上花费的实际时间
-
P0(m) – “m” 步的余额或价格的实际变化
-
T(m) - 在 “m” 步上花费的实际时间
-
P(m) – “m” 步的实际偏移
-
T = Lim(m --> +infinity) [ T(m) ] – 极限时间
-
N1 – 交易收益为正的数量及其计数值
-
N2 – N1 + 1 – 亏损交易数量(N2 为其计数值)
基于源系统,赫兹期货量化需要创建一个新的、更简单的系统,它由一个更复杂的系统组成。 唯一的区别是我们知道原始系统的所有参数。 已知值以星号 * 作为后缀显示。 如果我们令来自两个系统的第二个和第一个方程相等,我们可以消除变量 P 和 T:
-
(P[1] * T[1] + (1 -P[1])*T[2]) * n = (P*[1] * T[1] + P*[2])*T*[2] + … + P*[N])*T*[N] ) * m
-
(P[1] * Pr - (1 -P[1])*Pr) * n = (P*[1] * Pr*[1] + P*[2]*Pr*[2] + … + P*[N1]*Pr*[N1]) * m - (P*[N2] * Pr*[N1] + P*[N1+1]*Pr*[N1+1] + … + P*[N2]*Pr*[N2]) * m
结果就是,赫兹期货量化丢弃了两个方程,但与此同时我们消除了两个不必要的未知数。 这种变换的结果,我们得到了一个方程,包含下列未知量:
-
P[1] – 往上走(停止)的概率
-
T[1] – 往上走的平均生存期
-
T[2] – 往下走的平均生存期
这两个方程拥有相似的结构:
-
A1*n = A2*m
-
B1*n = B2*m
该结构表明,可以排除其中一个变量 “n” 或 “m”,从而消除其中一个方程。 为此,我们需要表示其中一个值,例如第一个等式:
-
m = ( (P[1] * T[1] + (1 -P[1])*T[2]) / (P*[1] * T[1] + P*[2])*T*[2] + … + P*[N])*T*[N] ) )* n
然后,赫兹期货量化将表达式替换为第二个等式,并查看结果:
-
(P[1] * Pr - (1 -P[1])*Pr) * n = (P*[1] * Pr*[1] + P*[2]*Pr*[2] + … + P*[N1]*Pr*[N1]) * ( (P[1] * T[1] + (1 -P[1])*T[2]) / (P*[1] * T[1] + P*[2])*T*[2] + … + P*[N])*T*[N] ) ) * n - (P*[N2] * Pr*[N1] + P*[N1+1]*Pr*[N1+1] + … + P*[N2]*Pr*[N2]) * ( (P[1] * T[1] + (1 -P[1])*T[2]) / (P*[1] * T[1] + P*[2])*T*[2] + … + P*[N])*T*[N] ) ) * n
现在,方程的两部分都乘以 “n”。 那么,将它们除以 “n”,我们将得到一个仅取决于所需值的方程:
-
(P[1] * Pr - (1 -P[1])*Pr) = (P*[1] * Pr*[1] + P*[2]*Pr*[2] + … + P*[N1]*Pr*[N1]) * ( (P[1] * T[1] + (1 -P[1])*T[2]) / (P*[1] * T[1] + P*[2])*T*[2] + … + P*[N])*T*[N] ) ) - (P*[N2] * Pr*[N1] + P*[N1+1]*Pr*[N1+1] + … + P*[N2]*Pr*[N2]) * ( (P[1] * T[1] + (1 -P[1])*T[2]) / (P*[1] * T[1] + P*[2])*T*[2] + … + P*[N])*T*[N] ) )
“Pr” 值应视为自由值,因为所有系统都可以简化为无穷多个。 我们可以为步阶设置任意的绝对长度,因为往上走和往下走的步阶在绝对值上是相等的。 其它值将通过求解方程组来判定。 到目前为止,这个系统只有一个方程式。 赫兹期货量化还需要两个方程,其可从前一节中得到的方程推导而来。 首先,系统穿越上走廊边界和下走廊边界的概率应相同。 此外,它穿越边界的平均时间也应相同。 这两个需求将为我们提供两个缺失的方程。 我们从检测穿越走廊边界的平均时间开始。 穿越其中一个边界的平均时间由往上走和往下走的平均步数来决定。 考虑到前一篇文章的结果,我们可以描写如下:
-
T[U,D] = (S[U,u] * T[1] + S[U,d] * T[2]) * P[U] + (S[D,u] * T[1] + S[D,d] * T[2]) * ( 1 – P[U] )
该方程表明,穿越其中一个边界的平均时间取决于穿越另一个边界时的平均步数,以及穿越的概率。 这一准则将提供另一个可能的方程式,我们可以用它创建一个方程式系统,令我们能够将一个复杂的交易系统转换为一个更简单的交易系统。 该方程可切分为另外两个方程:
-
T[U] = S[U,u] * T[1] + S[U,d] * T[2]
-
T[D] = S[D,u] * T[1] + S[D,d] * T[2]
赫兹期货量化稍后需要这些方程式。 所有这些值都是根据前一篇文章中获得的数学模型计算得出的:
-
S[U,u], S[U,d], S[D,u], S[D,d], P[U] = f(n,m,p) – 所有这些值都是 "n,m,p" 的函数
-
n = B[U]/ Pr - 反过来,“n” 可以用至上限的距离和步长 “Pr” 来表示
-
m = B[D]/ Pr – 反过来,“m” 可以用至上限的距离和步长“Pr”来表示
-
Pr – 选定步阶
-
B[U] – 至上边界的距离
-
B[D] – 至上边界的距离
结果转换方法的基础知识
作为一个实例,赫兹期货量化可以采用随机策略,并将其转换为所需的等效策略。 我创建了一个变体,将复杂的多维系统转换为更简单的二维系统。 我将尝试一步一步地讲述这个过程。 在继续讲述之前,我实现了这个思路,并测试了该方法的性能。 程序附在本文之后。 在我的程序当中,我采用了略有不同、但同样有效的公式。 它基于上一篇文章中获得的数学模型。 我们用它可以获得以下值:
-
P[U], S[U,u], S[U,d], S[D,u], S[D,d]
从平均步阶,我们可以得到穿越上下边界前的平均时间。 对于目前来说,其目的可能还不太清晰。 随着进一步的解释,它应该变得更清晰。 要将多重状态策略变换为更简单的策略,我们首先应该制定相关的策略。 我已创建了一个基于随机数的策略生成器。 出于便利起见,我选用了五个随机生成的策略。 它们如下所示:
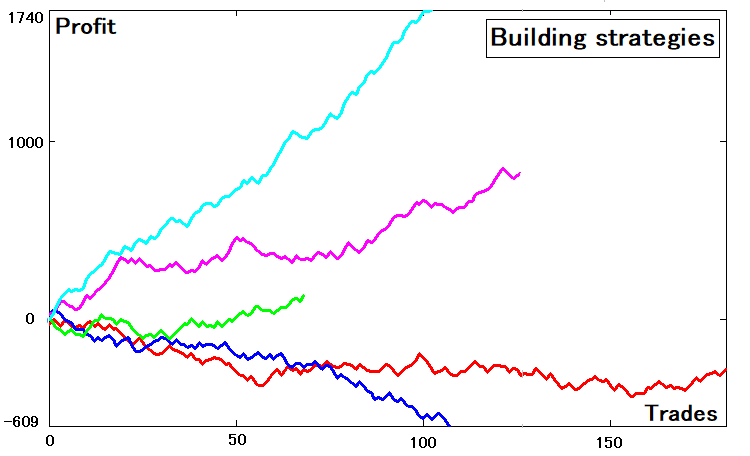
编辑切换为居中
添加图片注释,不超过 140 字(可选)
这些策略具有不同的预期回报指标、不同的交易数量和参数。 一些曲线正在亏损,但这是可接受的,因为它仍然是一条曲线,尽管其参数也许不是很好。 现在进入要点。 该图例展示了取决于交易数量的余额图,与策略测试器图形类似。 根此,每条曲线都有一个对应的余额数组:
-
B[i] , i = 0…N
-
N – 交易次数
这个数组可以从带有订单参数的数组中获得。 我假设包含订单数据的容器只包含订单盈亏值及其生存期:
-
Pr[i], T[i]
假设其他参数不可用。 我认为这是正确的,因为当赫兹期货量化想要分析任何回测或跟单信号时,我们往往无法获得这些数据,因为没有人保存这些数据。 更常见的情况是,用户检查恢复因子、最大回撤和类似度量衡。 仅有交易数据是始终保存的:
-
盈利
-
开单时间
-
平单时间
当然,某些数据的不可用性会影响准确性,但这与此无关。 现在,我们看看如何从盈利数组中提取一个余额数组:
-
B[i] = B[i-1] + Pr[i] if i > 0
-
B[i] = 0 else
为了能够根据时间分析获得的策略,赫兹期货量化需要创建一个类似的时间数组:
-
TL[i] = TL[i-1] + T[i] if i > 0
-
TL[i] = 0 else
在确定所有这些曲线的横坐标和纵坐标后,我们就能绘制它们。 您会看到差异,因为我们的这些函数并不依赖交易数量,而是依赖时间:

编辑切换为居中
添加图片注释,不超过 140 字(可选)
定义可还原性标准
我们可以进一步操控获得的数据。 现在,赫兹期货量化可以依据所检查曲线是否匹配两种利润状态来确定准则。 从相对于时间的表现角度来看,三个量就足够了:
-
P[U] – 穿越上边界的概率
-
T[U] – 触及上边界的平均时间
-
T[D] – 触及下边界的平均时间
第二个和第三个值的计算如下:
-
T[U] = S[U,u] * T[u] + S[U,d] * T[d]
-
T[D] = S[D,u] * T[u] + S[D,d] * T[d]
至于 P[U],这个值是由我们在前一篇文章中获得的数学模型提供的,正如您所记得的,“P[D]=1–P[U]”。 因此,根据数学模型提供的五个值,我们可以计算上述所需的三个值。 至于这两个方程,我们之前已经得到了它们,但为了方便起见,我在这里更改了时间标记符号。 这些值是可计算的。 为了将它们还原为某种东西,我们需要基于我们所拥有的东西,并以某种方式获得它们的真实数值。 之后,我们需要找到期望的、等效的双重状态曲线的参数,这三个参数都与实际值非常相似。 这就是我们得到的准则。 首先,我们引入已知值的标记符号:
-
P*[U] – 穿越选定走廊边界的实际概率
-
T*[U] – 穿越上边界的实际平均时间
-
T*[D] – 穿越下边界的实际平均时间
实际值和计算值的差值可以用相对值或百分比来衡量。 如果以百分比衡量,准则如下:
-
KPU = ( | P[U] – P*[U] | / ( P[U] + P*[U] ) ) * 100 %
-
KTU = ( | T[U] – T*[U] | / ( T[U] + T*[U] ) ) * 100 %
-
KTD = ( | T[D] – T*[D] | / ( T[D] + T*[D] ) ) * 100 %
定义与源系统进行比较的准则
最佳系统是所有这些值里拥有最小值的系统。 现在,为了能够获得计算值,赫兹期货量化首先需要判定走廊的大小,我们据其判定实际概率,和直至突破时的实际时间。 这个思路可以直观表示如下:
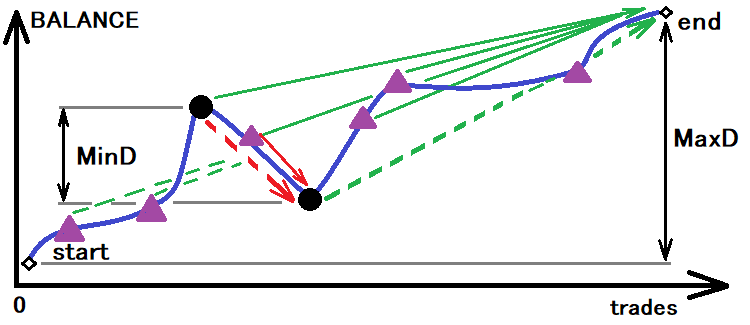
编辑切换为居中
添加图片注释,不超过 140 字(可选)
该图例展示的是为盈利策略判定此类走廊的示例。 紫色三角形象征着另一个可能的上、下移动的检查点。 所需的最小移动量处于黑点之间。 如果我们以有效期内发生的最大走势为基础,那么概率 P[U] 将为 1。 显而易见,这是最错误的选择。 因为我们需要最小值来保证与上下边界的交叉。
为计算所需数值,评估可能的走廊
然而,这还不够。 如果赫兹期货量化以这个值为基础,我们将只有一个下边界,这也是不精确的。 就我个人而言,我选用的走廊值小于给定最小值的三倍。 有了足够的触及边界的样本,这个值就足够了。 现在我们已经判定了走廊的尺寸,可以切分这条走廊了。 如果我们假设走廊本身是一个步阶,那么:
-
n, m = 1
-
p = P[U]
-
Pr * n = Pr * m = 1/3 * MinD – 走廊宽度的一半
-
Pr = ( 1/3 * MinD ) / n = ( 1/3 * MinD ) / m – 步阶模块
-
T[U,u] = T[U]
-
T[D,d] = T[D]
-
T[U,d] = 0
-
T[D,u] = 0
如果您有一组非常庞大的交易样本,也可以采用这个变体。 该方法的优点是,我们不需要使用数学模型来切分走廊,因为在这种情况下,赫兹期货量化的整个走廊就是一个步阶。 但在我的计算中,我用到了一个数学模型作为示例。 当用此方法时,有必要找到以下参数范围,并选择:
-
p = p1 … p2
-
N = m = nm1 …. nm2
在我的示例中,我采用了以下范围:
-
p1 = 0.4, p2 = 0.6, nm1 = 1, nm2 = 3
当然,您可以采用更大的范围。 或者,其中一个范围可以加宽,而另一个范围可以按原样使用。 例如,如果我们增加 “nm2”,那么该方法可以覆盖更广泛的各种策略。 如果数学模型不能处理下一个变体,那么我们可以切换到没有数学模型的那个。
定义与走廊上边界交叉的概率和平均时间
在成功地找到上述所有值后,我们只会得到一个往上走的概率 “p”。 之后,我们可以用该值作为计算平均穿越时间的基础。 这可以把上面图像经轻微变换来直观示意:
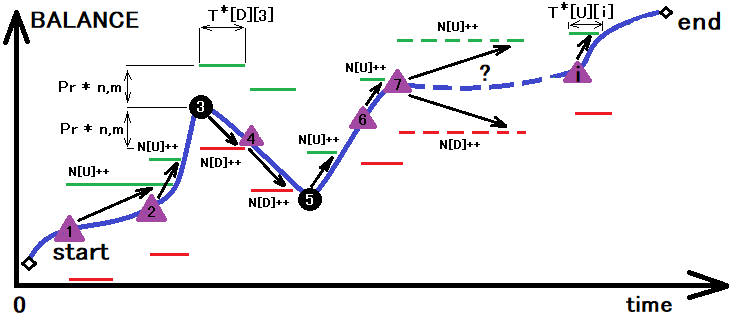
编辑切换为居中
添加图片注释,不超过 140 字(可选)
该图例展示了走廊上、下交叉的汇总过程,该走廊的大小是根据之前的转换来判定的。 除了这些交叉的总和,我们还计算了交叉所需的时间。 在一次操作中,赫兹期货量化可以用星号判定所需的所有数量:
-
N[U] – 走廊上边界的交汇点次数
-
N[D] – 走廊下边界的交汇点次数
-
T[U][i] – 直至穿越上边界的时间数组
-
T[D][i] – 直至穿越下边界的时间数组
利用这些数据,我们来计算穿越上边界的概率,以及穿越上、下边界的平均时间:
-
P*[U] = N[U]/ ( N[U] + N[D] )
-
T*[U] = Summ( 0…i ) [ T[U][i] ] / N[U]
-
T*[D] = Summ( 0…i ) [ T[D][i] ] / N[D]
我们已经找到了所有的值,我们的二维等价物应该据此简化。 现在,我们需要定义从哪里开始搜索。 为了做到这一点,我们需要判定这些值中哪一个在准确性方面具有最高优先级。 我已选择穿越上边界的概率作为示例。 这种方法降低了分析所需的计算。 如果我们选择在三个间隔内选择三个值,那么我们将获得三个自由度,这将增加计算时间。 有时,计算时间并不真实。 取而代之,我从往上走的概率开始,然后继续计算往上走和往下走的平均时间。
我要提醒你,走廊里有很多步阶,穿越时间不是步阶的时间。 此外,在某个方向上迈出一步的概率不是穿越边界的概率。 唯一的例外是开头描述的情况 n=m=1。
结果就是,我们得到以下步阶特征:
-
p – 往上走的概率
-
T[u] – 往上走的平均持续时间
-
T[d] – 往下走的平均持续时间
-
Pr – 按照盈利值得出的阶跃模数
评估简单转换的效率
假设我们已经找到了这些步阶的所有参数。 如何评估这种转换操作的总体效率? 为了评估效率,我们可以绘制出简化策略的直线。 直线的斜率可定义如下:
-
K = EndProfit / EndTime – 线斜率系数
-
P0 = K * t – 线方程
这就是它的样子:
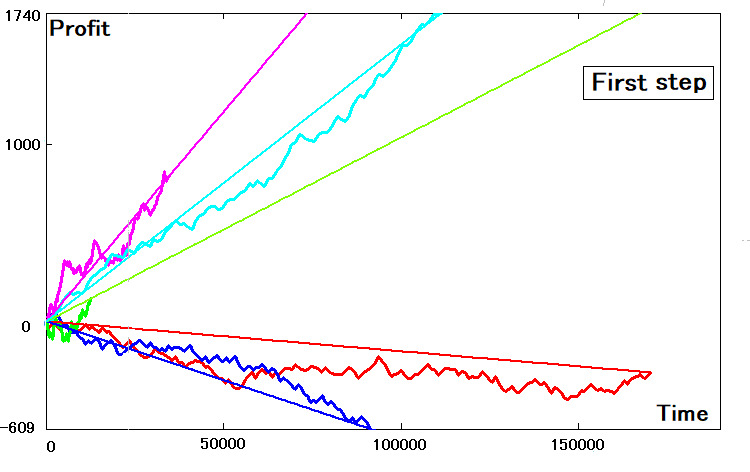
编辑切换为居中
添加图片注释,不超过 140 字(可选)
如果二维曲线的参数是理想的,那么与它们相似的直线也拥有完全相同的斜率,并在端点处与余额曲线相触。 我认为这很明显,大多的如此巧合永远不会发生。 为了找到等效的斜率系数,我们可以取用为该步阶找到的数据:
-
MP = p * Pr – (1-p) * Pr – 在任何步阶的上行偏转的数学预期
-
MT = p * T[u] + (1-p) * T[d] - 形成任何步阶所花费时间的数学期望
-
K = MP / MT – 线斜率系数。
我用同样的程序进行计算,每次我都得到一张类似的图片:
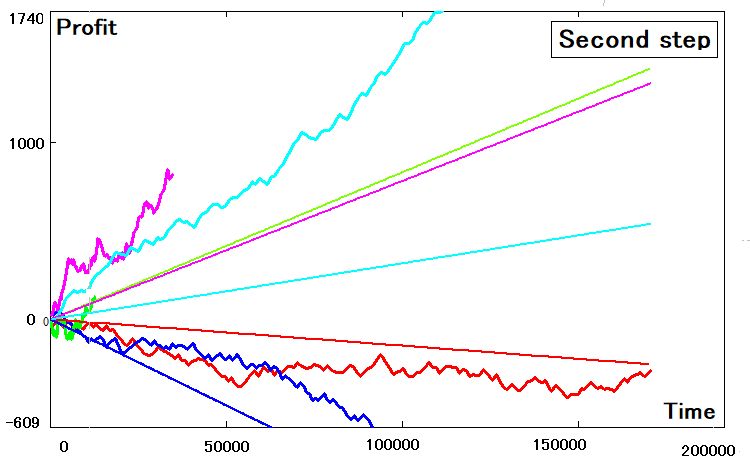
编辑切换为居中
添加图片注释,不超过 140 字(可选)
并不是所有的策略都能正确地转化为二维等价物。 其中一些存在明显的偏差。 这些偏差与以下原因有关:
-
计算带有星号的值时出错
-
二维模型的缺陷(不太灵活的模型)
-
可能的搜索尝试次数有限(以及有限的计算能力)
考虑到所有这些事实,赫兹期货量化可以调整平均步阶时间,如此至少令原始模型和推导模型的斜率系数相等。 当然,这种转换会影响我们正在降低的准则偏差,但没有其它解决方案。 我认为主要的准则是直线斜率系数,因为如果交易数量趋于无穷大,原始和推导策略应该合并为一条直线。 如果这种情况没有发生,那么这种转换就没有多大意义。 也许,这一切都与转换的方法无关,而是与隐藏的可能性有关,而这些目前还不太明朗。