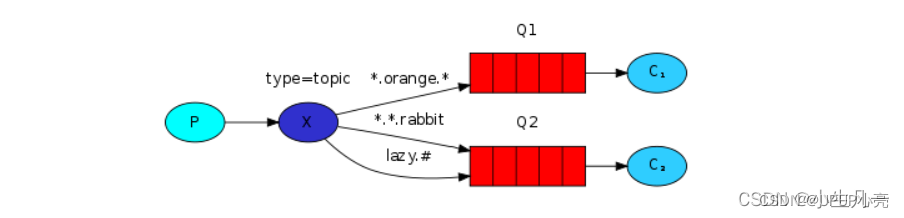
摘要
基于体素的形态学测量分析(VBM)通常用于灰质体积(GMV)的局部量化。目前存在多种实现VBM的方法。然而,如何比较这些方法及其在应用中的效用(例如对年龄效应的估计)仍不清楚。这会使研究人员疑惑他们应该在其项目中使用哪种VBM工具包。本研究以用户为中心,利用三个大型数据集(每个数据集n>500),系统地比较了五种VBM工具包,以及与通用模板或特定研究模板的配准。考虑到年龄效应对GMV的影响,本研究首先比较了这些工具包在个体水平上的年龄预测能力,发现结果存在显著差异。为了检查这些结果是否源于管道之间的系统差异,本研究根据GMV对它们进行分类,从而获得了近乎完美的准确性。为了获得更深入的见解,使用工具包之间的区域相似性检查了不同VBM步骤的影响。结果显示出明显的差异,这主要是由分割和配准步骤驱动的。本研究观察到受试者识别准确性存在很大差异,凸显了个体水平上GMV量化的工具包差异。作为一个具有生物学意义的标准,本研究将区域GMV与年龄相关联。结果与年龄预测分析一致,CAT和将fMRIPrep用于组织表征与FSL用于配准的组合更好地反映了年龄信息。
前言
对大脑结构的分析为了解其在健康和疾病中的组织提供了重要的见解。使用磁共振成像(MRI)获得的T1加权(T1w)图像通常用于此目的。然而,原始T1w图像由于其半定量性质以及被试间和被试内的变异性而无法直接比较。使用基于体素的形态学测量(VBM)对T1w图像进行体积分析,可以研究不同被试脑组织的体积组成。它估计每个体素中的组织体积,并将个体大脑置于一个共同参考空间中进行比较。VBM分析已经为诸如神经退行性疾病和精神障碍等领域提供了大量有价值的见解。VBM现已成功应用于衰老研究。最近,基于VBM的个体年龄预测已被证明是大脑完整性和整体健康状况的一种有效指标,并且具有个性化临床应用前景。大脑年龄预测是一个重要且广泛研究的主题,旨在估计健康大脑衰老的轨迹。
为了从T1w图像估计GVM,必须执行一些特定的步骤。VBM流程的主要步骤如下:(i)分割生成概率图,即每个体素被分配给特定脑组织(通常是灰质(GM)、白质(WM)和脑脊液(CSF))的概率。脑提取是从图像中去除颅骨并仅留下实际脑组织和CSF的过程,也是一个分割过程,但在某些情况下会在GM、WM和CSF分割之前执行。(ii)对参考脑空间进行空间配准/标准化,以使解剖区域对齐。参考空间可以是通用模板(例如,MNI-152)或特定研究/数据模板(以下称为数据模板)。数据模板主要用于将健康被试与患者进行比较,以避免因健康人群构建的通用模板而产生偏差。目前存在多种创建数据模板的方法,并且通常是为了匹配标准空间(如MNI空间)。大多数VBM工具包都会附带一个通用模板。(iii)标准化组织估计的调整旨在保留空间配准后的原始组织量。为此,标准化图像会根据局部体积变化量进行调整。
自1995年引入VBM以来,已经针对每个步骤提出了多种方法和多种选项。尽管各种VBM工具包使用相同的步骤,但步骤的顺序可能会有所不同,并且每个步骤可能使用具有多个可配置选项的不同算法。此外,工具包可以以不同的顺序使用这些步骤,或者同时和/或迭代地执行其中一些步骤。甚至还可以通过组合来自不同工具的步骤来创建混合工具包。即使用户选择了现成的VBM工具包,也不能完全免除进一步的选择。如何比较VBM工具包的输出及其在不同应用中的效用仍未得到充分的研究,这就有可能会导致次优选择。
先前比较VBM工具包的工作确实提供了工具包之间存在差异的证据。一项对计算解剖工具箱(CAT, v12.7)、两个基于FSL和一个混合(仍然依赖于FSL)工具包的全面比较表明,预处理管道的选择对年龄预测和性别分类都有影响。该研究还表明,选择组织概率图(TPM)作为分割先验会系统地影响分割结果,进而影响统计估计。与VBM8工具包相比,CAT12 VBM工具包在检测颞叶癫痫的体积变化方面表现更好。此外,一些研究调查了各个VBM步骤及其参数化的影响。对用于配准的14种变形算法进行比较发现,ANTs标准化工具和DARTEL (CAT)的SyN是性能最佳的算法之一,其中SyN在被试间具有最高一致性,并且对噪声、部分容积效应和磁场不均匀性等因素具有较好的鲁棒性。SPM、ANTs和FSL的分割算法在对照组中的差异相对较小,但在与萎缩大脑进行比较时出现显著差异,这表明应根据研究人群的大脑特征选择分割算法。对于大脑提取,虽然有研究认为FSL-BET性能较低,但它并不影响后续的分割。SPM12、SPM8和FreeSurfer5.3的比较显示,SPM12对颅内总体积(TIV)的估计更接近于手动分割。在自闭症谱系障碍和典型发育对照中,基于SPM的估计在TIV方面最接近手动分割,其次是FreeSurfer,而FSL似乎低估了TIV的值。
总而言之,不同的VBM工具包会产生不同的结果。VBM工具包的差异阻碍了下游分析中组织体积的精确定位和有效解释,例如多发性硬化症患者的萎缩。迄今为止,还没有计算GMV的标准方法,也没有适用于当前研究(例如年龄预测)的VBM实施指南。此外,在VBM估计脑灰质体积的每个步骤中,不同算法和参数的相互作用及其对整个成年期年龄估计的影响尚未得到彻底研究。而且,从健康被试创建的数据模板的实用性以及与通用模板的比较,特别是在跨站点研究中,仍然没有答案。为此,本研究致力于解决以下问题:
这些工具包在脑区和被试水平上有何不同?
大脑提取、分割和配准对GMV有何影响?
与通用模板相比,使用数据模板的效果如何?
单变量和多变量分析中的工具包结果如何比较?
哪种工具包能更好地反映大脑衰老,并在大脑年龄预测中表现最佳?
通过对VBM工具包进行全面、系统的比较分析,本研究旨在为研究人员提供必要的信息和建议,帮助他们选择最符合其研究目标的VBM工具包。
材料和方法
数据集
本研究分析了健康个体的T1w图像,数据来自三个大型数据集。eNKI:n=953名受试者,其中573名受试者在扫描时无精神、神经系统疾病或用药史(48.1±17.2岁,630名女性)。CamCAN:n=634名无严重精神疾病或认知障碍的老年人(54.8±18.4岁,320名女性)。IXI:n=582名正常和健康受试者(49.4±16.7岁,324名女性)的多站点样本。
工具包
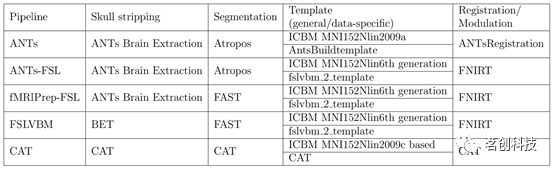
CAT是一个广泛使用的现成VBM工具,本研究使用了最新版本的CAT12.8(r1813)。一些通用的神经成像工具也提供了创建VBM工具包的功能。FSLVBM使用来自FSL的工具,该工具目前也被广泛使用。ANTs提供了广泛的图像处理和图像分析功能,包括执行VBM所需的所有功能。可以构建结合不同工具功能的混合VBM工具包,例如fMRIPrep,它使用ANTs执行大脑提取,然后使用FSL执行其余的步骤。
本研究按照文献中推荐的步骤和设置设计了五个VBM工具包:ANTs、ANTs-FSL、fMRIPrep-FSL、FSLVBM和CAT。选择这些工具包是为了反映常见且易于使用的做法。将每个工具包与标准模板(CAT和FSLVBM的默认模板)一起使用,无论数据集如何(通用模板),以及创建并用于配准的数据集特定模板(数据模板)。这总共产生了十种工具包。
ANTs:本研究使用了ANTs 2.2.0版本。首先,对每个扫描图像进行N4偏置场校正,然后使用基于Atropos的脑提取来选择颅内组织。接下来,应用K-means初始化的Atropos分割将图像分割成GM、WM和CSF。使用一系列转换将GM-map图像配准到模板。其次,应用刚体和仿射变换,然后再进行非线性BsplineSyN变换,参数设置如Tustison和Avants(2013)所示。利用空间变换的Jacobian矩阵来调整分割后的GM。数据特定模板是使用具有默认值的ANTs创建的。为了创建模板图像,对变换进行平均和迭代。为使模板形状在多次迭代中保持稳定,本研究计算了平均逆变换并将其应用于模板图像。为了便于分析,数据模板过程使用通用的MNI模板进行初始化。因此,最终的数据模板也是在MNI空间中。对于所有需要组织掩模和模板以及配准到MNI的过程,本研究使用了ICBM 152非线性非对称模板2009a版本和相应的组织概率图。
FSLVBM:本研究使用FSL 6.0版本。首先,通过自动重新定向和裁剪颈部、下颅部分来准备图像。然后,利用BET提取大脑颅内部分,利用FAST将其分割为GM、WM和CSF。数据特定模板是根据FSLVBM的流程使用给定数据集中的所有GM图像创建的。将分割后的GM图像与ICBM-152 GM模板进行仿射配准、拼接和平均。将平均后的图像沿x轴翻转,然后将两个镜像图像重新平均以获得首轮、研究特定的仿射GM模板。其次,GM图像通过非线性配准重新配准到该放射GM模板上,然后进行平均并沿x轴翻转。然后对两个镜像进行平均,以创建最终的对称的、研究特定的、非线性GM模板。生成的数据模板位于MNI空间中。然后将GM图像非线性配准到模板(通用模板或特定数据模板)并进行调整。对于通用模板,本研究使用FSL提供的模板(见表1)。
fMRIPrep-FSL:据报道,BET在脑提取方面的质量较差可能会导致虚假的结果;因此,本研究决定测试一个工具包,该工具包使用ANTs提供的更好的脑提取,然后使用FSL进行其余的VBM处理步骤。由于fMRIPrep已经得到很好的验证并且越来越受欢迎,本研究选择使用fMRIPrep结构处理的输出结果。在这个用于图像准备和分割的混合工具包中,本研究使用了fMRIPrep稳定版本20.0.6,它是基于ANTs版本2.1.0。使用N4BiasFieldCorrection对每个T1w体积进行强度不均匀性(INU)校正,并使用“antsBrainExtraction.sh”(使用OASIS模板)进行颅骨剥离。然后使用FSL FAST(与fMRIPrep FSL v5.0.9相同)将脑组织分割为CSF、WM和GM。这个FAST的参数与FSLVBM中的参数有所不同:(i)主分割阶段的马尔可夫随机场(MRF)beta值为H=0.2,而FSLVBM中的默认值为0.1;(ii)mixeltype的MRF beta值为R=0.2,而FSLVBM中的默认值为0.3。模板创建、空间标准化以及调整与FSLVBM工具包相同。
ANTs-FSL:使用与上述ANTs工具包完全相同的处理过程来准备图像、校正偏置场噪声、执行大脑提取,最后使用ANTs的Atropos执行组织分割。数据特定模板的创建、配准和调整与FSLVBM工具包相同。需要注意的是,该工具包与fMRIPrep-FSL之间的区别在于所使用的组织分割工具不同。
CAT:CAT12.8基于MATLAB (R2017b) 的统计分析SPM12 (v7771),并在Singularity (2.6.1)中进行容器化编译。CAT提供了一个完整的VBM工具包,包括使用空间自适应非局部均值进行去噪、偏差校正、颅骨剥离以及线性和非线性空间配准。通过具有部分体积模型的自适应最大后验方法来分割图像。对于非线性变换,采用geodesic shooting算法。默认模板提供了转换为MNI152NLin2009cAsym(基于IXI)的模板。对于数据模板,首先将所有结构T1图像分割为GM、WM和CSF,并使用仿射配准与MNI标准模板进行空间配准。利用仿射组织片段创建新的特定样本的geodesic shooting模板,该模板包含四个迭代的非线性归一化步骤。
表1.总结了每个工具包的VBM步骤所使用的软件/算法。
分割方案及质量控制
为了降低数据的维度,从而便于信息比较和机器学习方法的使用,本研究提取了区域水平的均值。然而,为了保持良好的空间分辨率,本研究选择了一个高粒度的分割方案。使用了覆盖整个大脑的三个图谱的组合,共计1073个感兴趣区域(ROI):包含来自Schaefer图谱的1000个皮层区域、Brainnetome图谱的36个亚皮层区域和37个小脑区域。区域GMV值计算为每个区域内非零体素的平均值。
年龄预测
以每个工具包的区域GMV为特征进行基于机器学习的分析,从而预测每个受试者的年龄。考虑到年龄与GMV具有可靠相关,并且大脑年龄作为整体大脑健康指标的重要性日益增加,本研究选此作为测试。通过以交叉验证(CV)一致的方式去除均值并缩放至单位方差,对所有特征进行标准化。本研究使用了四种机器学习算法:相关向量回归(RVR)、高斯过程回归(GPR)、最小绝对收缩和选择算子(LASSO)和核岭回归(KRR),在嵌套的5折CV方案中重复5次。使用平均绝对误差(MAE)评估年龄预测性能。为了确保差异不是由工具包以外的因素驱动的,本研究对每个工具包使用相同的数据和模型进行评估。评估分两种设置进行:数据集内和数据集间。在数据集间评估中,使用两个数据集训练模型,然后用于预测第三个数据集。
个体水平的识别
本研究检测了不同工具包处理下GMV模式的被试内一致性。为此,研究者使用最近邻搜索来识别不同工具包中的被试。使用每个工具包作为参考,将每个被试与其他工具包(数据库)的所有被试进行匹配。识别指标采用两个被试区域GMV之间的Pearson相关性。每个被试都与另一个工具包中相关系数最高的被试进行匹配。使用差异可识别性(Idiff)指标计算两个工具包之间的识别性能。
区域层面的比较
为了更好地了解导致工具包之间差异的区域,本研究使用单变量统计分析评估了不同工具包之间区域GMV估计的相似性。这些分析是针对所有合并数据集的被试进行的,同时也对每个数据集单独进行分析。使用所有可能工具包对(总共45个)的Pearson相关系数来估计被试之间区域GMV的相似性。为了研究分区大小是否影响区域相似性,本研究计算了每个ROI在工具包对之间相关系数的中值,并将其与每个区域的体素数量进行相关分析。对于Pearson r值的所有算术运算,首先应用Fisher’z变换,然后将结果转换回Pearson r值。
工具包之间相似性的外部评估
上述工具包比较本质上是内在的。虽然它们提供了有关工具包之间差异的重要信息,但并没有提供有关工具包在估计GMV时的准确性信息。由于缺乏真值数据,目前无法进行这样的准确性评估。相反,本研究根据工具包在捕获年龄相关信息方面的效用来比较它们。首先使用单变量统计分析测试了每个工具包的区域GMV估计值在多大程度上反映了被试的年龄。为此,本研究分别计算了每个工具包的区域GMV和被试年龄之间的Pearson r值。为了控制多重比较引起的FWER,再次对所有合并数据以及每个工具包的数据进行了比较,对所得相关系数的p值进行了校正。然后进行方差分析(ANOVA),以检验相关系数的均值是否存在显著差异。使用scikit-learn进行基于机器学习的分析。
结果
预处理和数据模板
在CAT和fMRIPrep的预处理结果中,不到0.4%的被试数据未通过质量控制(QC)。对于CAT,所有结果都通过了质量检查。对于FSLVBM,不到2%的被试未通过QC。对于fMRIPrep-FSL,未通过QC的被试比FSLVBM略少。有相当多的被试未通过ANTs分割(eNKI为13%,CamCAN为5%,IXI为12%)。ANTs-FSL混合工具包的QC结果与ANTs相似。最终符合进一步分析要求的被试人数为:eNKI=741人,CamCAN=593人,IXI=418人(总计n=1752)。与FSLVBM创建的数据模板相比,CAT和ANTs创建的数据模板更清晰且更类似于通用模板。
VBM工具包产生不同的结果
脑龄预测
首先使用四种机器学习算法,以区域GMV作为特征,对实际年龄进行个体层面的预测(图1)。数据集内CV性能在不同管道之间存在很大差异(图1(a))。在各种学习算法和数据集上,fMRIPrep-FSL通用模板(MAE=5.83)的平均性能最高,其次是FSLVBM通用模板(MAE=6.17)和fMRIPrepFSL数据模板(MAE=6.18)。使用数据模板和通用模板时,CAT表现出相似的性能,分别为MAE=6.37和6.39。基于KRR的fMRIPrep-FSL通用模板实现了跨数据集的最佳平均性能(MAE=5.59)。ANTs的平均性能最差。四种学习算法在每个工具包上的性能大致相似。
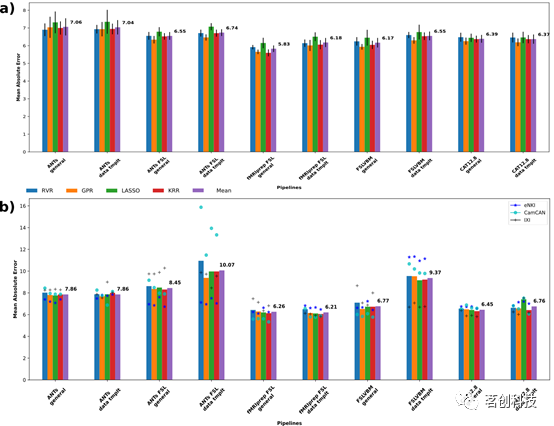
图1.每个工具包的脑龄预测情况。
对于跨数据集的预测结果(图1(b)),fMRIPrep-FSL工具包再次实现了跨数据集和模型的最佳平均性能,其中数据模板(MAE=6.21)的性能略优于通用模板(MAE=6.26),其次是CAT通用模板(MAE=6.45)。在这里,KRR算法再次提供了最佳的总体预测。对于fMRIPrep-FSL数据模板和通用模板,MAE分别为6.06和6.13。对于CAT,通用模板和数据模板的MAE=6.32和6.42。ANTs-FSL的GMV平均性能最差。
机器学习分析证实了不同的GMV模式
机器学习方法对工具包进行分类的精度接近100%。为了排除这种高精度是由于系统性差异(即某些工具包高估或低估了总体GMV)驱动的可能性,本研究进行了一项额外的分析,其中每个被试的特征向量均独立地进行z评分,从而有效地消除了GMV估计的总体差异。该分析还使所有数据集的分类精度都很高,接近100%。
个体水平的识别差异
仅模板不同的工具包显示出高差异可识别性43>Idiff>29。采用数据模板的fMRIPrep-FSL和FSLVBM具有最高的Idiff=45,其次是两个ANTs工具包(Idiff=43)。两个CAT工具包的平均Idiff值最低,其中数据模板工具包的值最低。使用数据模板的FSLVBM具有最高的平均Idiff。使用通用模板的FSL进行配准和调制的工具包,其平均Idiff=33.7。使用数据模板的相同工具包显示平均Idiff=37.7。当ANTs-FSL和fMRIPrep-FSL都使用通用模板时,Idiff=35,当使用数据模板时,Idiff=34。最后,ANTs和ANTs-FSL在配准(和调制)方面存在差异,当两者都使用通用模板时,Idiff=29;当两者都使用数据模板时,Idiff=30(图2)。
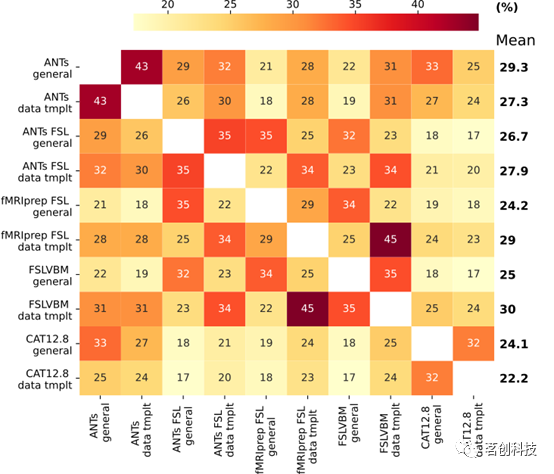
图2.差异可识别性方面的识别性能。
单变量分析和区域相似性
为了更好地了解哪些VBM步骤对GMV估计值的差异产生了更大的影响,以及识别出显示显著差异的区域,本研究进行了多项单变量统计分析。有些工具包仅在一个步骤上存在差异;因此,通过检查它们之间的相似性,可以得出有关此特定VBM步骤影响的深刻结论。本研究观察到,基于成对相关值的中值,工具包之间的总体一致性在各个区域中有所不同,而大多数区域显示出低到中等的一致性(图3)。只有靠近扣带回、颞叶和梭状区的区域在整个工具包之间显示出相对较高的一致性(中值r>0.6)。大多数皮层下区域表现出低一致性(中值r<0.4),尾状核除外(中值r>0.6)。在小脑中,所有区域的中值r<0.6。总体而言,这些结果表明工具包之间的一致性较低。
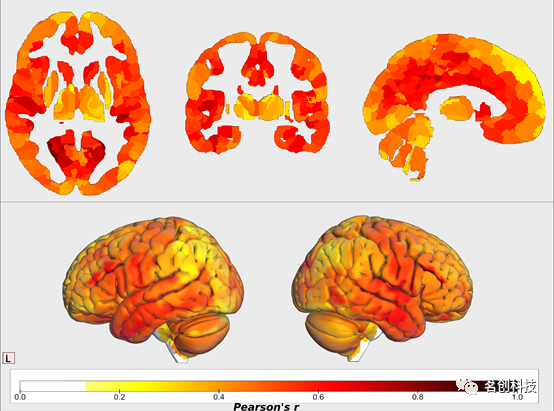
图3.所有管道对的区域相关性中值。
工具包对之间的区域相似性存在较大差异。当忽略仅在模板上不同的工具包对时,观察到fMRIPrep和FSLVBM在使用特定数据模板时具有最大相似性(平均r=0.76),而使用通用模板的ANTs-FSL和使用两种模板的CAT之间的相似性最低(平均r=0.306)。
ANTs与CAT的比较
尽管步骤、步骤顺序和每个步骤的算法存在差异,但CAT和ANTs工具包之间观察到高度相似性。当使用通用模板时,观察到的相似性最高(r=0.72),ANTs数据模板和CAT通用模板之间的r=0.66。当两个工具包都使用数据模板时,以及在ANTs通用模板和CAT数据模板之间,相似性略低(r=0.65)。
配准、分割和脑提取的效果
在随后的分析中,本研究比较了在特定VBM步骤上存在差异的工具包,以评估其具体影响。ANTs和ANTs-FSL之间的区域相似性仅在使用通用模板的配准(以及调制)方面有所不同,为中等偏低,平均r=0.51。当使用数据特定模板时,所有数据的相似性较高(0.58),而且三个数据集的相似性也较高(图4 a(i))。ANTs-FSL和fMRIPrep-FSL除分割外,步骤相同。当使用通用模板时,平均区域相似性为0.67,而对于数据特定模板,相应值为0.68(图4 a(ii))。FSLVBM和fMRIPrep-FSL的不同之处在于大脑提取步骤。当两个工具包都使用默认的FSL模板时,它们的相似性为0.67。当使用各自的数据特定模板进行配准时,相似性增加到0.76(图4 a(iii))。
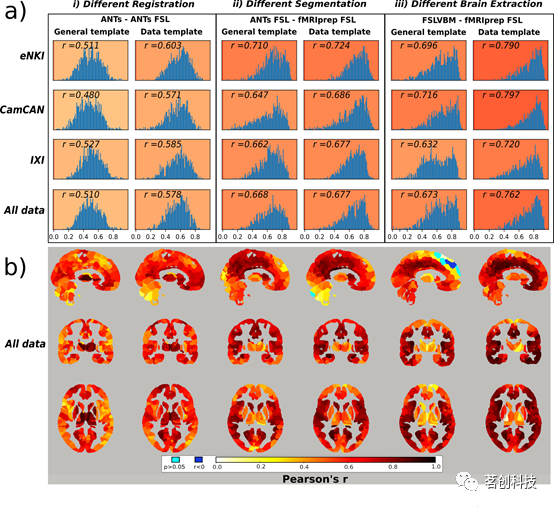
图4.(a)所有数据集的选定工具包对之间的区域相关值直方图。(b)利用所有数据计算所选工具包对的区域相似性脑图。
总体来说,使用数据模板时相似性更高。与ANTs-FSL相比,ANTs在皮层下区域的相似性值最高,而在腹外侧和背外侧前额叶皮层的相似性值最低,特别是在使用通用模板时(图4b(i))。ANTs-FSL和fMRIPrep-FSL在皮层下区域、枕叶和前额叶皮层中的相似性最小(图4b(ii))。最后,FSLVBM和fMRIPrep-FSL在皮层下区域的相似性值最低,在颞叶、内侧前额叶皮层和扣带回中的相似性值最高(图4b(iii))。
具有相同配准的工具包
ANTs-FSL和FSLVBM这两个工具包仅在配准步骤上相同,当使用FSL默认模板或数据特定模板时,所有数据的相似性为0.59。两个模板在eNKI数据集上的相似性为0.65;对于CamCAN数据集,通用模板和数据模板的相似性分别为0.60和0.63,IXI数据集的相似性分别为0.56和0.58。
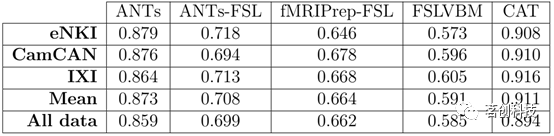
通用模板与数据特定模板
模板不同的工具包(即通用模板或数据模板)显示出不同程度的相似性(表2)。在所有三个数据集中,相似性最高的是CAT(r>0.9),其次是ANTs(r>0.86)。使用FSL进行配准和模板创建步骤的三个工具包(ANTs-FSL、FSLVBM和fMRIPrep-FSL),相似性为较低至中等。具体来说,ANTs-FSL、fMRIPrep-FSL和FSLVBM在这三个数据集上的平均相似性分别为r=0.71,r=0.66和r=0.59。单因素分析与Idiff识别结果一致。Idiff值与工具包对的区域相似性之间的Pearson相关系数较高,r=0.841,p<0.05。
表2.通用模板和数据特定模板的比较。
与年龄的关联
年龄与区域GMV的相关性
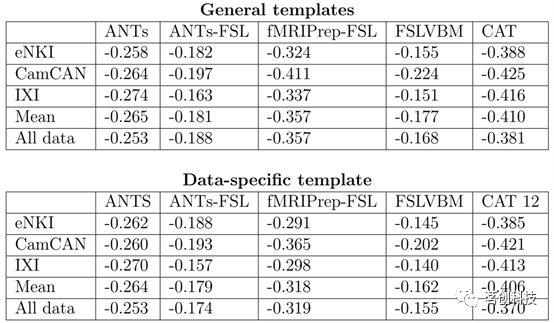
本研究进行了单变量分析来评估区域GMVs如何捕获与年龄相关的信息。无论使用何种模板,CAT在所有数据集上的区域GMV与年龄之间的平均相关性最高,其次是使用通用模板的fMRIPrep-FSL。对于CAT而言,通用模板和数据特定模板的平均相关性分别为r=-0.410和-0.406(表3)。CAT和ANTs的区域 GMV-年龄相关值分布较窄,而使用FSL的工具包分布较宽(图5(a))。总体而言,不同工具包之间的区域GMV-年龄相关性存在显著差异(图5)。单因素方差分析显示,所有数据集中至少有两个工具包之间的区域GMV-年龄的平均r系数存在显著差异。
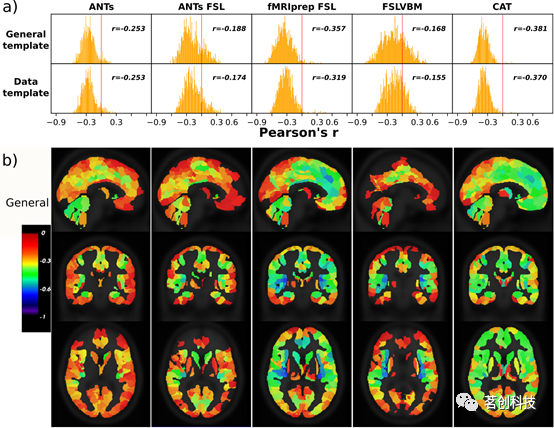
图5.eNKI数据集的区域GMV与年龄之间的相关性。
表3.被试年龄与所有区域GMVs之间的Pearson r值
不同工具包的区域-年龄信息比较
区域GMV-年龄相关值不仅存在差异,而且还呈现相反的效应(图6)。即,有些区域在一个工具包中与年龄呈正相关,但在另一个工具包中与年龄呈负相关。尤其是FSLVBM和ANTs-FSL,这两个工具包中存在许多与年龄呈正相关的区域。当使用不同的模板时,相同的两个工具包也显示出大量与年龄呈反相关的区域。
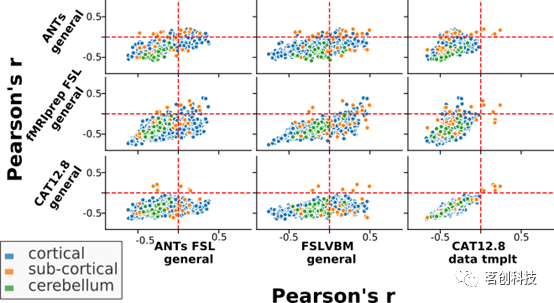
图6.区域GMV和年龄之间的Pearson r值。
当使用所有数据时(无论使用哪种模板),CAT的ROIs(n_rois=6)均与年龄呈正相关。fMRIPrep-FSL使用通用模板的n_rois=27,使用数据模板时的n_rois=22,而ANTs在两种模板下的n_rois=56。当使用通用模板时,ANTs-FSL和FSLVBM分别有218和280个区域与年龄呈正相关,而当使用数据模板时,分别有184和226个区域与年龄呈正相关。在所有工具包中,丘脑的两个区域与年龄呈正相关。总体而言,所有工具包与年龄呈正相关的区域大多位于皮质下(见图6)。
结论
综上所示,本研究结果表明,VBM工具包的所有步骤对GMV估计都有相当大的影响,因此,不同的工具包会产生不同的结果。这些GMV估计的差异在单变量和多变量分析中都有所体现。配准的选择对结果影响最大,其次是分割和脑提取算法。对于年龄预测这一特定情况,本研究建议使用ANTs进行脑提取和FSL进行分割(在fMRIPrep中实现),以及结合FSL非线性配准或CAT 12.8,后者的优势是可以作为现成的工具包使用。对于年龄相关研究和可能具有类似设置的其他研究,特别是在分析来自多个数据集的扫描时,首选使用通用模板。
参考文献:G. Antonopoulos, S. More, F. Raimondo et al., A systematic comparison of VBM pipelines and their application to age prediction. NeuroImage (2023), doi: https://doi.org/10.1016/j.neuroimage.2023.120292.