目录
1.Logstash入门
1.1.安装Logstash
1.1.1.从下载的二进制安装
1.1.2.从包存储库安装
1.1.3.使用Homebrew在Mac上安装Logstash
1.1.4.使用Homebrew启动Logstash
1.1.5.Docker
1.2.简单使用
1.3.用Logstash解析日志
1.3.1.配置Filebeat以将日志行发送到Logstash
1.3.2.为Filebeat输入配置Logstash
1.3.3.使用Grok过滤器插件解析Web日志
1.3.4.使用Geoip过滤器插件增强数据
1.3.5.将您的数据索引到Elasticsearch中
1.3.6.测试管道
1.4.将多个输入和输出插件拼接在一起
1.4.1.从Twitter Feed阅读
1.4.2.配置Filebeat以将日志行发送到Logstash
1.4.3.将Logstash数据写入文件
1.4.4.写入多个Elasticsearch节点
1.4.5.测试管道
1.Logstash入门
本节将指导您完成安装Logstash并验证一切正常运行的过程。在学习如何使用第一个事件之后,您将继续创建一个更高级的管道,将Apache Web日志作为输入,解析日志,并将解析后的数据写入Elasticsearch集群。然后,您将学习如何将多个输入和输出插件拼接在一起,以统一来自各种不同来源的数据。
本节包括以下主题:
- 安装Logstash
- 简单使用
- 用Logstash解析日志
- 将多个输入和输出插件拼接在一起
1.1.安装Logstash
Logstash需要Java 8或Java 11.使用 官方Oracle发行版或OpenJDK等开源发行版。要检查Java版本,请运行以下命令:
java -version在安装了Java的系统上,此命令生成类似于以下内容的输出:
java version "11.0.1" 2018-10-16 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.1+13-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.1+13-LTS, mixed mode)在某些Linux系统上,您可能还需要JAVA_HOME在尝试安装之前导出环境,特别是如果您从tarball安装Java。这是因为Logstash在安装期间使用Java来自动检测您的环境并安装正确的启动方法(SysV init脚本,Upstart或systemd)。如果Logstash在程序包安装期间无法找到JAVA_HOME环境变量,则可能会收到错误消息,并且Logstash将无法正常启动。
1.1.1.从下载的二进制安装
Logstash二进制文件可从 https://www.elastic.co/downloads。下载主机环境的Logstash安装文件-TARG.GZ,DEB,ZIP或RPM。
解压缩文件。不要将Logstash安装到包含冒号(:)字符的目录路径中
这些软件包可以在弹性许可证下免费使用。它们包含开源和免费的商业功能以及对付费商业功能的访问。
开始为期30天的试用,试用所有付费商业功能。有关弹性许可证级别的信息,请参阅订阅页。或者,您可以下载一个OSS包,它只包含Apache2.0许可证下可用的功能。在支持的Linux操作系统上,您可以使用程序包管理器来安装Logstash。
1.1.2.从包存储库安装
我们还有基于APT和YUM的发行版的存储库。请注意,我们只提供二进制包,但没有源包,因为包是作为Logstash构建的一部分创建的。
我们已按版本将Logstash软件包存储库拆分为单独的URL,以避免跨主要版本的意外升级。对于所有7.xy版本,请使用7.x作为版本号。
我们使用PGP密钥 D88E42B4,Elastic的签名密钥,带指纹
4609 5ACC 8548 582C 1A26 99A9 D27D 666C D88E 42B4签署我们所有的包裹。它可以从https://pgp.mit.edu.
APT
下载并安装公共签名密钥:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -在继续之前,您可能需要在Debian上安装APT传输HTTPS包:
sudo apt-get install apt-transport-https将存储库定义保存到 /etc/apt/sources.list.d/elastic-7.x.list:
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list使用上述的echo方法添加Logstash存储库。 不要使用add-apt-repository,因为它也会添加一个deb-src条目,但是我们不提供源程序包。 如果添加了deb-src条目,将看到类似以下的错误:
Unable to find expected entry 'main/source/Sources' in Release file (Wrong sources.list entry or malformed file)只需从/etc/apt/sources.list文件中删除deb-src条目,安装即可按预期进行。
运行sudo apt-get update,存储库已准备就绪,可以使用。 您可以使用以下方法安装它:
sudo apt-get update && sudo apt-get install logstash有关将Logstash作为系统服务进行管理的详细信息,请参见 Running Logstash
YUM
下载并安装公共签名密钥:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch将以下内容添加到您的/etc/yum.repos.d/目录中的后缀为.repo的文件中,例如logstash.repo
[logstash-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md您的存储库就可以使用了。 您可以使用以下方法安装它:
sudo yum install logstash该存储库不适用于仍使用RPM v3的较旧的基于rpm的发行版,例如CentOS5。
请参阅“ Running Logstash”文档以将Logstash作为系统服务进行管理。
1.1.3.使用Homebrew在Mac上安装Logstash
Elastic会发布Homebrew公式,因此您可以使用Homebrew软件包管理器安装Logstash。
要使用Homebrew进行安装,您首先需要点击Elastic Homebrew存储库:
brew tap elastic/tap点击Elastic Homebrew存储库后,可以使用brew install安装Logstash的默认发行版:
brew install elastic/tap/logstash-full这将安装最新发布的Logstash默认发行版。 要安装OSS发行版,请指定elastic / tap / logstash-oss。
1.1.4.使用Homebrew启动Logstash
要立即启动启动elastic / tap / logstash-full并在登录时重新启动,请运行:
brew services start elastic/tap/logstash-full要运行Logstash,请在前台运行:
logstash1.1.5.Docker
映像可用于将Logstash作为Docker容器运行。 可从Elastic Docker注册表中获得它们。
有关如何配置和运行Logstash Docker容器的详细信息,请参阅Running Logstash on Docker。
1.2.简单使用
首先,我们通过运行最基本的Logstash管道来测试Logstash安装。
Logstash管道具有两个必需元素,即输入和输出,以及一个可选元素,即filter。 输入插件使用来自源的数据,过滤器插件根据您的指定修改数据,输出插件将数据写入目标。

要测试Logstash安装,请运行最基本的Logstash管道。 例如:
cd logstash-7.4.1
bin/logstash -e 'input { stdin { } } output { stdout {} }'bin目录的位置因平台而异。 请参阅 Directory layout 以找到bin \ logstash在系统上的位置。
-e标志使您可以直接从命令行指定配置。 在命令行中指定配置可以使您快速测试配置,而不必在两次迭代之间编辑文件。 该示例中的管道从标准输入stdin中获取输入,并将该输入以结构化格式移动到标准输出stdout中。
启动Logstash后,请等待直到看到“ Pipeline main已启动”,然后在命令提示符下输入hello world:
hello world
2013-11-21T01:22:14.405+0000 0.0.0.0 hello worldLogstash将时间戳和IP地址信息添加到消息中。 通过在运行Logstash的外壳中发出CTRL-D命令来退出Logstash。
恭喜你! 您已经创建并运行了基本的Logstash管道。 接下来,您将学习如何创建更现实的管道。
1.3.用Logstash解析日志
在“ Stashing Your First Event”中,您创建了一个基本的Logstash管道来测试Logstash设置。 在现实世界中,Logstash管道要复杂一些:它通常具有一个或多个输入,过滤器和输出插件。
在本部分中,您将创建一个Logstash管道,该管道使用Filebeat来获取Apache Web日志作为输入,解析这些日志以从日志中创建特定的命名字段,并将解析后的数据写入Elasticsearch集群。 您无需在命令行中定义管道配置,而可以在配置文件中定义管道。
首先,请转到here下载此示例中使用的样本数据集。 解压缩文件。
1.3.1.配置Filebeat以将日志行发送到Logstash
在创建Logstash管道之前,您需要配置Filebeat以将日志行发送到Logstash。Filebeat客户端是一种轻量级,资源友好的工具,可从服务器上的文件收集日志并将这些日志转发到Logstash实例进行处理。 Filebeat专为可靠性和低延迟而设计。 Filebeat在主机上的资源占用很少, Beats input插件使Logstash实例上的资源需求最小化。
在典型的用例中,Filebeat与运行Logstash实例的计算机在不同的计算机上运行。 就本教程而言,Logstash和Filebeat在同一台计算机上运行。
Logstash的默认安装包括Beats input插件。 Beats输入插件使Logstash能够从Elastic Beats框架接收事件,这意味着任何与Beats框架一起编写的Beat,例如Packetbeat和Metricbeat,也可以将事件数据发送到Logstash。
要在数据源计算机上安装Filebeat,请从 product page下载适当的软件包。 您还可以参考Beats文档中的 Getting Started with Filebeat以获取其他安装说明。
安装Filebeat之后,您需要对其进行配置。 打开位于Filebeat安装目录中的filebeat.yml文件,并将内容替换为以下几行。 确保路径指向您先前下载的示例Apache日志文件logstash-tutorial.log:
filebeat.inputs:
- type: logpaths:- /path/to/file/logstash-tutorial.log
output.logstash:hosts: ["localhost:5044"]- Filebeat处理的文件的绝对路径。
保存您的更改。
为了简化配置,您不会像在实际情况中那样指定TLS / SSL设置。
在数据源计算机上,使用以下命令运行Filebeat:
sudo ./filebeat -e -c filebeat.yml -d "publish"如果以root用户身份运行Filebeat,则需要更改配置文件的所有权(请参见 Config File Ownership and Permissions)。
Filebeat将尝试在端口5044上进行连接。在Logstash以活动的Beats插件启动之前,该端口上将没有任何答案,因此,您现在看到的任何关于在该端口上连接失败的消息都是正常的。
1.3.2.为Filebeat输入配置Logstash
接下来,创建一个使用Beats输入插件从Beats接收事件的Logstash配置管道。
# The # character at the beginning of a line indicates a comment. Use
# comments to describe your configuration.
input {
}
# The filter part of this file is commented out to indicate that it is
# optional.
# filter {
#
# }
output {
}此框架无法正常工作,因为输入和输出部分未定义任何有效的选项。
首先,将骨架配置管道复制并粘贴到主Logstash目录中名为first-pipeline.conf的文件中。
接下来,通过将以下行添加到first-pipeline.conf文件的输入部分,将Logstash实例配置为使用Beats输入插件:
beats {port => "5044"}您将配置Logstash以在以后写入Elasticsearch。 现在,您可以将以下行添加到输出部分,以便在运行Logstash时将输出打印到stdout:
stdout { codec => rubydebug }完成后,first-pipeline.conf的内容应如下所示:
input {beats {port => "5044"}
}
# The filter part of this file is commented out to indicate that it is
# optional.
# filter {
#
# }
output {stdout { codec => rubydebug }
}要验证您的配置,请运行以下命令:
bin/logstash -f first-pipeline.conf --config.test_and_exit--config.test_and_exit选项解析您的配置文件并报告任何错误。
如果配置文件通过配置测试,请使用以下命令启动Logstash:
bin/logstash -f first-pipeline.conf --config.reload.automatic--config.reload.automatic选项启用了自动重新加载配置,因此您不必在每次修改配置文件时都停止并重新启动Logstash。
当Logstash启动时,您可能会看到有关Logstash的一个或多个警告消息,而忽略了pipes.yml文件。 您可以放心地忽略此警告。 Pipelines.yml文件用于在单个Logstash实例中运行 multiple pipelines。 对于此处显示的示例,您正在运行单个管道。
如果管道正常运行,则应该在控制台上看到一系列类似以下的事件:
{"@timestamp" => 2017-11-09T01:44:20.071Z,"offset" => 325,"@version" => "1","beat" => {"name" => "My-MacBook-Pro.local","hostname" => "My-MacBook-Pro.local","version" => "6.0.0"},"host" => "My-MacBook-Pro.local","prospector" => {"type" => "log"},"input" => {"type" => "log"},"source" => "/path/to/file/logstash-tutorial.log","message" => "83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] \"GET /presentations/logstash-monitorama-2013/images/kibana-search.png HTTP/1.1\" 200 203023 \"http://semicomplete.com/presentations/logstash-monitorama-2013/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\"","tags" => [[0] "beats_input_codec_plain_applied"]
}
...1.3.3.使用Grok过滤器插件解析Web日志
现在,您有了一个工作管道,该管道从Filebeat中读取日志行。 但是,您会注意到日志消息的格式并不理想。 您想解析日志消息以从日志中创建特定的命名字段。 为此,您将使用grok过滤器插件。
grok过滤器插件是Logstash默认提供的几个插件之一。 有关如何管理Logstash插件的详细信息,请参阅插件管理器的reference documentation。
使用grok过滤器插件,您可以将非结构化日志数据解析为结构化和可查询的内容。
由于grok过滤器插件会在传入的日志数据中查找模式,因此配置该插件需要您做出有关如何识别用例感兴趣的模式的决策。 Web服务器日志示例中的代表行如下所示:
83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] "GET /presentations/logstash-monitorama-2013/images/kibana-search.png
HTTP/1.1" 200 203023 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel
Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"该行开头的IP地址很容易识别,括号中的时间戳也很容易识别。 要解析数据,可以使用%{COMBINEDAPACHELOG} grok模式,该模式使用以下模式从Apache日志中构造行:
| Information | Field Name |
| IP Address | clientip |
| User ID | ident |
| User Authentication | auth |
| timestamp | timestamp |
| HTTP Verb | verb |
| Request body | request |
| HTTP Version | httpversion |
| HTTP Status Code | response |
| Bytes served | bytes |
| Referrer URL | referrer |
| User agent | agent |
如果您需要构建grok模式的帮助,请尝试使用 Grok Debugger。 Grok调试器是基本许可证下的X-Pack功能,因此可以免费使用。
编辑first-pipeline.conf文件,并将整个过滤器部分替换为以下文本:
filter {grok {match => { "message" => "%{COMBINEDAPACHELOG}"}}
}完成后,first-pipeline.conf的内容应如下所示:
input {beats {port => "5044"}
}
filter {grok {match => { "message" => "%{COMBINEDAPACHELOG}"}}
}
output {stdout { codec => rubydebug }
}保存您的更改。 因为您启用了自动重新加载配置,所以不必重新启动Logstash即可获取更改。 但是,您确实需要强制Filebeat从头读取日志文件。 为此,请转到运行Filebeat的终端窗口,然后按Ctrl + C关闭Filebeat。 然后删除Filebeat注册表文件。 例如,运行:
sudo rm data/registry由于Filebeat会将其收集的每个文件的状态存储在注册表中,因此删除注册表文件会强制Filebeat从头读取其收集的所有文件。
接下来,使用以下命令重新启动Filebeat:
sudo ./filebeat -e -c filebeat.yml -d "publish"如果Filebeat需要等待Logstash重新加载配置文件,则在Filebeat开始处理事件之前可能会稍有延迟。
在Logstash应用grok模式之后,事件将具有以下JSON表示形式:
{"request" => "/presentations/logstash-monitorama-2013/images/kibana-search.png","agent" => "\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\"","offset" => 325,"auth" => "-","ident" => "-","verb" => "GET","prospector" => {"type" => "log"},"input" => {"type" => "log"},"source" => "/path/to/file/logstash-tutorial.log","message" => "83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] \"GET /presentations/logstash-monitorama-2013/images/kibana-search.png HTTP/1.1\" 200 203023 \"http://semicomplete.com/presentations/logstash-monitorama-2013/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\"","tags" => [[0] "beats_input_codec_plain_applied"],"referrer" => "\"http://semicomplete.com/presentations/logstash-monitorama-2013/\"","@timestamp" => 2017-11-09T02:51:12.416Z,"response" => "200","bytes" => "203023","clientip" => "83.149.9.216","@version" => "1","beat" => {"name" => "My-MacBook-Pro.local","hostname" => "My-MacBook-Pro.local","version" => "6.0.0"},"host" => "My-MacBook-Pro.local","httpversion" => "1.1","timestamp" => "04/Jan/2015:05:13:42 +0000"
}请注意,该事件包括原始消息,但日志消息也细分为特定字段。
1.3.4.使用Geoip过滤器插件增强数据
除了解析日志数据以进行更好的搜索外,筛选器插件还可以从现有数据中获取补充信息。 例如,geoip插件查找IP地址,从地址中获取地理位置信息,然后将该位置信息添加到日志中。
通过将以下行添加到first-pipeline.conf文件的过滤器部分,将Logstash实例配置为使用geoip过滤器插件:
geoip {source => "clientip"}geoip插件配置要求您指定包含要查找的IP地址的源字段的名称。 在此示例中,clientip字段包含IP地址。
由于过滤器是按顺序评估的,因此请确保geoip部分位于配置文件的grok部分之后,并且grok和geoip部分都嵌套在filter部分中。
完成后,first-pipeline.conf的内容应如下所示:
input {beats {port => "5044"}
}filter {grok {match => { "message" => "%{COMBINEDAPACHELOG}"}}geoip {source => "clientip"}
}
output {stdout { codec => rubydebug }
}保存您的更改。 若要像以前一样强制Filebeat从头开始读取日志文件,请关闭Filebeat(按Ctrl + C),删除注册表文件,然后使用以下命令重新启动Filebeat:
sudo ./filebeat -e -c filebeat.yml -d "publish"请注意,该事件现在包含地理位置信息:
{"request" => "/presentations/logstash-monitorama-2013/images/kibana-search.png","agent" => "\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\"","geoip" => {"timezone" => "Europe/Moscow","ip" => "83.149.9.216","latitude" => 55.7485,"continent_code" => "EU","city_name" => "Moscow","country_name" => "Russia","country_code2" => "RU","country_code3" => "RU","region_name" => "Moscow","location" => {"lon" => 37.6184,"lat" => 55.7485},"postal_code" => "101194","region_code" => "MOW","longitude" => 37.6184},...1.3.5.将您的数据索引到Elasticsearch中
现在,网络日志已细分为特定字段,您可以将数据导入Elasticsearch。
您可以在自己的硬件上运行Elasticsearch,或在Elastic Cloud上使用我们托管的 hosted Elasticsearch Service。 Elasticsearch Service在AWS和GCP上均可用。 Try the Elasticsearch Service for free.
Logstash管道可以将数据索引到Elasticsearch集群中。 编辑first-pipeline.conf文件,并将整个输出部分替换为以下文本:
output {elasticsearch {hosts => [ "localhost:9200" ]}
}通过此配置,Logstash使用http协议连接到Elasticsearch。 上面的示例假定Logstash和Elasticsearch在同一实例上运行。 您可以通过使用hosts配置指定一个主机=> [“ es-machine:9092”]来指定远程Elasticsearch实例。
此时,您的first-pipeline.conf文件已正确配置了输入,过滤器和输出部分,如下所示:
input {beats {port => "5044"}
}filter {grok {match => { "message" => "%{COMBINEDAPACHELOG}"}}geoip {source => "clientip"}
}
output {elasticsearch {hosts => [ "localhost:9200" ]}
}保存您的更改。 若要像以前一样强制Filebeat从头开始读取日志文件,请关闭Filebeat(按Ctrl + C),删除注册表文件,然后使用以下命令重新启动Filebeat:
sudo ./filebeat -e -c filebeat.yml -d "publish"1.3.6.测试管道
现在,Logstash管道已配置为将数据索引到Elasticsearch集群中,您可以查询Elasticsearch。
尝试根据grok过滤器插件创建的字段对Elasticsearch进行测试查询。 将$ DATE替换为当前日期,格式为YYYY.MM.DD:
curl -XGET 'localhost:9200/logstash-$DATE/_search?pretty&q=response=200'索引名称中使用的日期基于UTC,而不是Logstash运行所在的时区。 如果查询返回index_not_found_exception,请确保logstash-$DATE反映索引的实际名称。 要查看可用索引的列表,请使用以下查询:curl 'localhost:9200/_cat/indices?v'。
您应该会获得多次点击。 例如:
{"took": 50,"timed_out": false,"_shards": {"total": 5,"successful": 5,"skipped": 0,"failed": 0},"hits": {"total": 98,"max_score": 2.793642,"hits": [{"_index": "logstash-2017.11.09","_type": "doc","_id": "3IzDnl8BW52sR0fx5wdV","_score": 2.793642,"_source": {"request": "/presentations/logstash-monitorama-2013/images/frontend-response-codes.png","agent": """"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"""","geoip": {"timezone": "Europe/Moscow","ip": "83.149.9.216","latitude": 55.7485,"continent_code": "EU","city_name": "Moscow","country_name": "Russia","country_code2": "RU","country_code3": "RU","region_name": "Moscow","location": {"lon": 37.6184,"lat": 55.7485},"postal_code": "101194","region_code": "MOW","longitude": 37.6184},"offset": 2932,"auth": "-","ident": "-","verb": "GET","prospector": {"type": "log"},"input": {"type": "log"},"source": "/path/to/file/logstash-tutorial.log","message": """83.149.9.216 - - [04/Jan/2015:05:13:45 +0000] "GET /presentations/logstash-monitorama-2013/images/frontend-response-codes.png HTTP/1.1" 200 52878 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"""","tags": ["beats_input_codec_plain_applied"],"referrer": """"http://semicomplete.com/presentations/logstash-monitorama-2013/"""","@timestamp": "2017-11-09T03:11:35.304Z","response": "200","bytes": "52878","clientip": "83.149.9.216","@version": "1","beat": {"name": "My-MacBook-Pro.local","hostname": "My-MacBook-Pro.local","version": "6.0.0"},"host": "My-MacBook-Pro.local","httpversion": "1.1","timestamp": "04/Jan/2015:05:13:45 +0000"}},...尝试再次搜索从IP地址派生的地理信息。 将$ DATE替换为当前日期,格式为YYYY.MM.DD:
curl -XGET 'localhost:9200/logstash-$DATE/_search?pretty&q=geoip.city_name=Buffalo'
一些日志条目来自Buffalo,因此查询产生以下响应:
{"took": 9,"timed_out": false,"_shards": {"total": 5,"successful": 5,"skipped": 0,"failed": 0},"hits": {"total": 2,"max_score": 2.6390574,"hits": [{"_index": "logstash-2017.11.09","_type": "doc","_id": "L4zDnl8BW52sR0fx5whY","_score": 2.6390574,"_source": {"request": "/blog/geekery/disabling-battery-in-ubuntu-vms.html?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+semicomplete%2Fmain+%28semicomplete.com+-+Jordan+Sissel%29","agent": """"Tiny Tiny RSS/1.11 (http://tt-rss.org/)"""","geoip": {"timezone": "America/New_York","ip": "198.46.149.143","latitude": 42.8864,"continent_code": "NA","city_name": "Buffalo","country_name": "United States","country_code2": "US","dma_code": 514,"country_code3": "US","region_name": "New York","location": {"lon": -78.8781,"lat": 42.8864},"postal_code": "14202","region_code": "NY","longitude": -78.8781},"offset": 22795,"auth": "-","ident": "-","verb": "GET","prospector": {"type": "log"},"input": {"type": "log"},"source": "/path/to/file/logstash-tutorial.log","message": """198.46.149.143 - - [04/Jan/2015:05:29:13 +0000] "GET /blog/geekery/disabling-battery-in-ubuntu-vms.html?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+semicomplete%2Fmain+%28semicomplete.com+-+Jordan+Sissel%29 HTTP/1.1" 200 9316 "-" "Tiny Tiny RSS/1.11 (http://tt-rss.org/)"""","tags": ["beats_input_codec_plain_applied"],"referrer": """"-"""","@timestamp": "2017-11-09T03:11:35.321Z","response": "200","bytes": "9316","clientip": "198.46.149.143","@version": "1","beat": {"name": "My-MacBook-Pro.local","hostname": "My-MacBook-Pro.local","version": "6.0.0"},"host": "My-MacBook-Pro.local","httpversion": "1.1","timestamp": "04/Jan/2015:05:29:13 +0000"}},...如果使用Kibana可视化数据,则还可以在Kibana中浏览Filebeat数据:
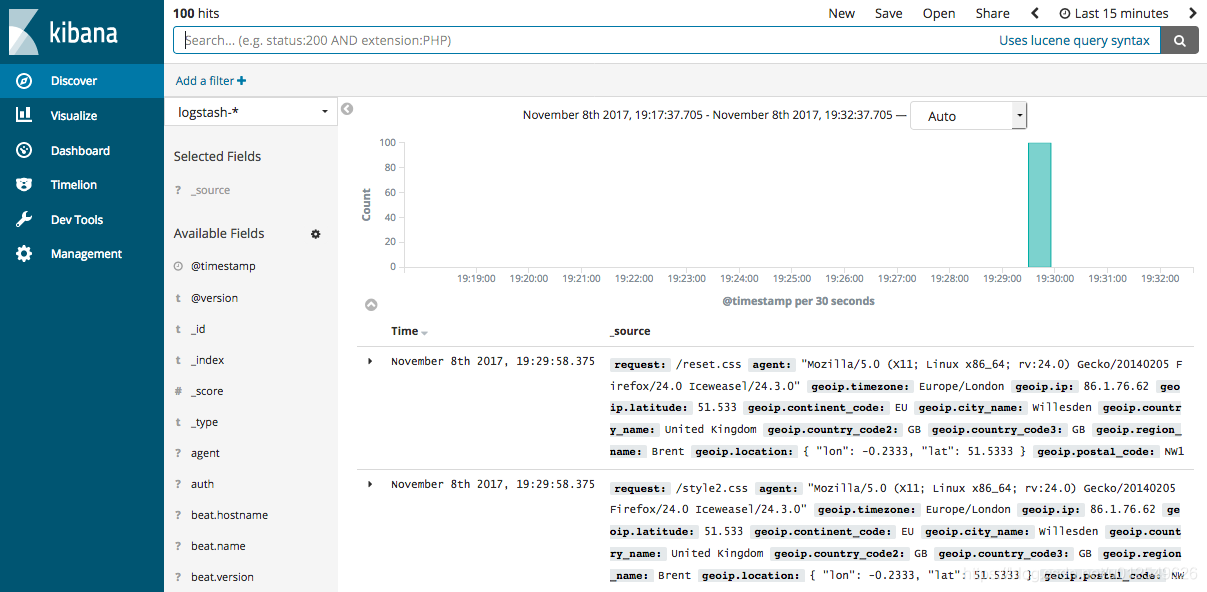
有关加载Filebeat的Kibana索引模式的信息,请参阅 Filebeat getting started docs 。
您已经成功创建了一个管道,该管道使用Filebeat来获取Apache Web日志作为输入,解析这些日志以从日志中创建特定的命名字段,并将解析后的数据写入Elasticsearch集群。 接下来,您将学习如何创建使用多个输入和输出插件的管道。
1.4.将多个输入和输出插件拼接在一起
您需要管理的信息通常来自多个不同的来源,用例可能需要多个目的地来存储数据。 您的Logstash管道可以使用多个输入和输出插件来满足这些要求。
在本部分中,您将创建一个Logstash管道,该管道从Twitter feed和Filebeat客户端获取输入,然后将信息发送到Elasticsearch集群,以及将信息直接写到文件中。
1.4.1.从Twitter Feed阅读
要添加Twitter feed,请使用twitter输入插件。 要配置插件,您需要一些信息:
- 使用者密钥,用于唯一标识您的Twitter应用程序。
- 消费者机密,用作您的Twitter应用程序的密码。
- 一个或多个关键字可在传入的Feed中进行搜索。 该示例显示了使用“ cloud”作为关键字,但是您可以使用任意内容。
- oauth令牌,用于标识使用此应用程序的Twitter帐户。
- oauth令牌密钥,用作Twitter帐户的密码。
访问 https://dev.twitter.com/apps来设置Twitter帐户并生成您的消费者密钥和机密以及访问令牌和机密。 如果不确定如何生成这些密钥,请参阅twitter输入插件的文档。
就像您之前使用Parsing Logs with Logstash时所做的一样,创建一个包含配置管道框架的配置文件(称为second-pipeline.conf)。 如果需要,可以重用之前创建的文件,但请确保在运行Logstash时传递正确的配置文件名。
将以下行添加到second-pipeline.conf文件的输入部分,用您的值替换此处显示的占位符值:
twitter {consumer_key => "enter_your_consumer_key_here"consumer_secret => "enter_your_secret_here"keywords => ["cloud"]oauth_token => "enter_your_access_token_here"oauth_token_secret => "enter_your_access_token_secret_here"}1.4.2.配置Filebeat以将日志行发送到Logstash
正如您先前在 Configuring Filebeat to Send Log Lines to Logstash中所了解的那样,Filebeat客户端是一种轻量级,资源友好的工具,它从服务器上的文件收集日志并将这些日志转发到Logstash实例进行处理。
安装Filebeat之后,您需要对其进行配置。 打开位于Filebeat安装目录中的filebeat.yml文件,并将内容替换为以下几行。 确保路径指向您的系统日志:
filebeat.inputs:
- type: logpaths:- /var/log/*.log fields:type: syslog
output.logstash:hosts: ["localhost:5044"]- Filebeat处理的文件的绝对路径。
- 向事件添加一个名为type的字段,其值为syslog。
保存您的更改。
为了简化配置,您不会像在实际情况中那样指定TLS / SSL设置。
通过将以下行添加到second-pipeline.conf文件的输入部分,将Logstash实例配置为使用Filebeat输入插件:
beats {port => "5044"}1.4.3.将Logstash数据写入文件
您可以配置Logstash管道,以使用文件输出插件将数据直接写入文件。
通过将以下行添加到second-pipeline.conf文件的输出部分,将Logstash实例配置为使用文件输出插件:
file {path => "/path/to/target/file"}1.4.4.写入多个Elasticsearch节点
写入多个Elasticsearch节点可减轻给定Elasticsearch节点上的资源需求,并在特定节点不可用时提供进入群集的冗余入口点。
要将Logstash实例配置为写入多个Elasticsearch节点,请编辑second-pipeline.conf文件的输出部分以读取:
output {elasticsearch {hosts => ["IP Address 1:port1", "IP Address 2:port2", "IP Address 3"]}
}在主机行中使用Elasticsearch集群中三个非主节点的IP地址。 当hosts参数列出多个IP地址时,Logstash会对整个地址列表中的请求进行负载均衡。 还要注意,Elasticsearch的默认端口是9200,在上面的配置中可以省略。
1.4.5.测试管道
此时,您的second-pipeline.conf文件如下所示:
input {twitter {consumer_key => "enter_your_consumer_key_here"consumer_secret => "enter_your_secret_here"keywords => ["cloud"]oauth_token => "enter_your_access_token_here"oauth_token_secret => "enter_your_access_token_secret_here"}beats {port => "5044"}
}
output {elasticsearch {hosts => ["IP Address 1:port1", "IP Address 2:port2", "IP Address 3"]}file {path => "/path/to/target/file"}
}Logstash正在使用您配置的Twitter feed中的数据,从Filebeat接收数据,并将此信息索引到Elasticsearch集群中的三个节点以及写入文件。
在数据源计算机上,使用以下命令运行Filebeat:
sudo ./filebeat -e -c filebeat.yml -d "publish"Filebeat将尝试在端口5044上进行连接。在Logstash以活动的Beats插件启动之前,该端口上将没有任何答案,因此,您现在看到的任何关于在该端口上连接失败的消息都是正常的。
要验证您的配置,请运行以下命令:
bin/logstash -f second-pipeline.conf --config.test_and_exit--config.test_and_exit选项解析您的配置文件并报告任何错误。 当配置文件通过配置测试时,使用以下命令启动Logstash:
bin/logstash -f second-pipeline.conf使用grep实用程序在目标文件中搜索以验证是否存在信息:
grep syslog /path/to/target/file运行Elasticsearch查询以在Elasticsearch集群中找到相同的信息:
curl -XGET 'localhost:9200/logstash-$DATE/_search?pretty&q=fields.type:syslog'将$ DATE替换为当前日期,格式为YYYY.MM.DD。
要查看Twitter feed中的数据,请尝试以下查询:
curl -XGET 'http://localhost:9200/logstash-$DATE/_search?pretty&q=client:iphone'同样,请记住将$ DATE替换为当前日期,格式为YYYY.MM.DD。







![[第七届蓝帽杯全国大学生网络安全技能大赛 蓝帽杯 2023]——Web方向部分题 详细Writeup](https://img-blog.csdnimg.cn/img_convert/58b8c6b6a86fed973e6fba1d21753664.png)