现在让我们来谈谈 Elasticsearch 最简单和最有用的功能之一:别名 (alias)。为了区分这里 alias 和文章 “Elasticsearch : alias 数据类型”,这里的别名(alias)指的是 index 的别名。 别名正是他们听起来的样子; 它们是你可以使用的指针或名称,对应于一个或多个具体索引。 事实证明这非常有用,因为它在扩展集群和管理数据在索引中的布局方式时提供了灵活性。 即使使用 Elasticsearch 只有一个索引的集群,使用别名。
别名到底是什么?
你可能想知道别名究竟是什么,以及 Elasticsearch 在创建别名时涉及何种开销。 别名将其生命置于群集状态内,由主节点(master node) 管理; 这意味着如果你有一个名为 idaho 的别名指向一个名为 potato 的索引,那么开销就是群集状态映射中的一个额外键,它将名称 idaho 映射到具体的索引字符串。 这意味着与其他指数相比,别名的重量要轻得多; 可以维护数千个而不会对集群产生负面影响。 也就是说,我们会警告不要创建数十万或数百万个别名,因为在这一点上,即使映射中单个条目的最小开销也会导致集群状态增长到大小。 这意味着创建新群集状态的操作将花费更长时间,因为每次更改时都会将整个群集状态发送到每个节点。
为什么别名是有用的?
我们建议每个人都为他们的 Elasticsearch 索引使用别名,因为在重新索引时,它将在未来提供更大的灵活性。 假设你首先创建一个包含单个主分片的索引,然后再决定是否需要更多索引容量。 如果你使用原始别名 index,你现在可以将该别名更改为指向另外创建的索引,而无需更改你正在搜索的索引的名称(假设你从头开始使用别名进行搜索)。 另一个有用的功能是可以创建不同索引的窗口; 例如,如果你为数据创建每日索引,则可能需要创建一个名为 last-7-days 的别名的上周数据的滑动窗口; 然后每天创建新的每日索引时,可以将其添加到别名中,同时删除8天的索引。
另外的一种场景是,当我们修改了我们的 index 的 mapping,让后通过 reindex API 来把我们的现有的 index 转移到新的 index 上,那么如果在我们的应用中,我们利用 alias 就可以很方便地做这件事。在我们成功转移到新的 index 之后,我们只需要重新定义我们的 alias 指向新的 index,而在我们的客户端代码中,我们一直使用 alias 来访问我们的 index,这样我们的代码不需要任何的改动。


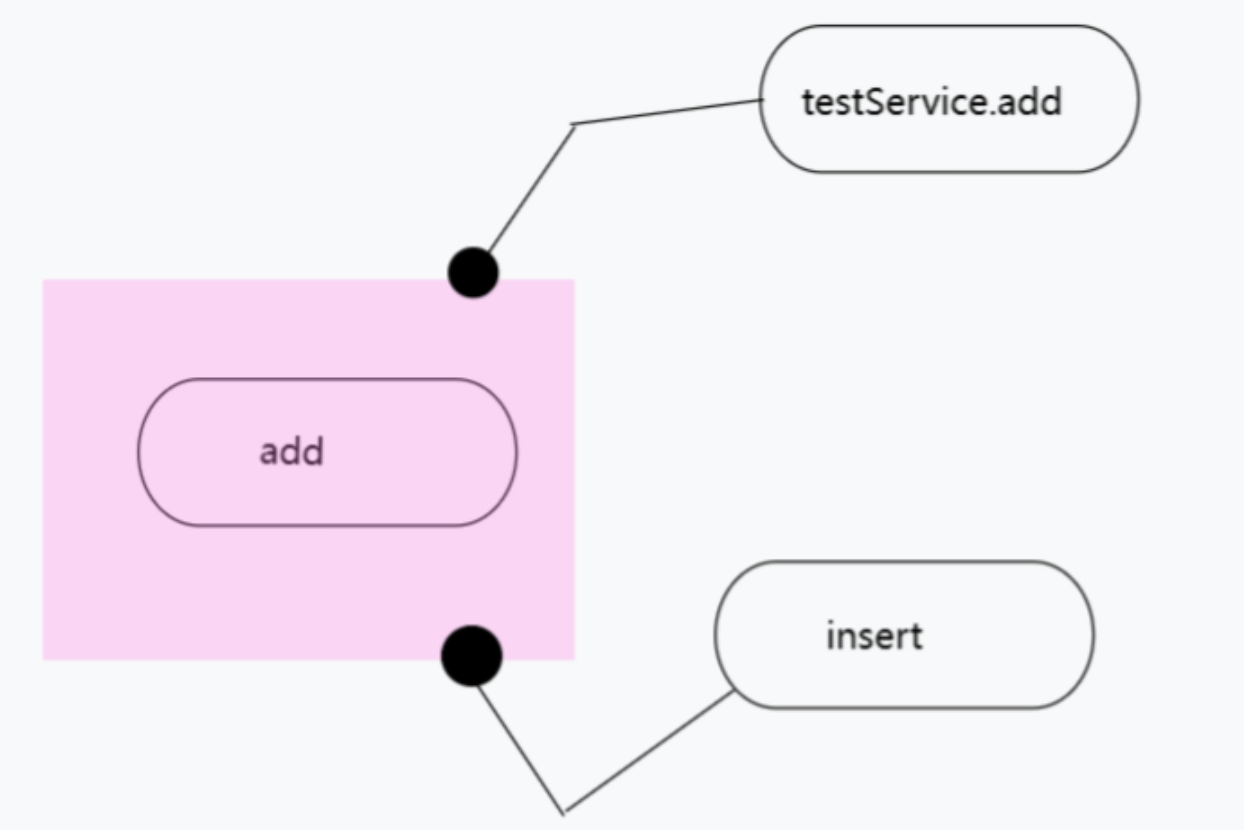
如上所示,我们可以使用 orders 这个别名来访问上图下面所示的所有索引。
建立 index
为了验证我们的 API,我们先建立一些数据:
PUT twitter/_doc/1
{"user" : "双榆树-张三","message" : "今儿天气不错啊,出去转转去","uid" : 2,"age" : 20,"city" : "北京","province" : "北京","country" : "中国","address" : "中国北京市海淀区","location" : {"lat" : "39.970718","lon" : "116.325747"}
}PUT twitter/_doc/2
{"user" : "东城区-老刘","message" : "出发,下一站云南!","uid" : 3,"age" : 30,"city" : "北京","province" : "北京","country" : "中国","address" : "中国北京市东城区台基厂三条3号","location" : {"lat" : "39.904313","lon" : "116.412754"}
}PUT twitter/_doc/3
{"user" : "虹桥-老吴","message" : "好友来了都今天我生日,好友来了,什么 birthday happy 就成!","uid" : 7,"age" : 90,"city" : "上海","province" : "上海","country" : "中国","address" : "中国上海市闵行区","location" : {"lat" : "31.175927","lon" : "121.383328"}
}这样,我们建立了三个文档的 twitter 索引。
管理别名
添加一个 index alias
一个 index 别名就是一个用来引用一个或多个已经存在的索引的另外一个名字,我们可以用如下的方法来创建
PUT /twitter/_alias/alias1请求的格式:
PUT /<index>/_alias/<alias>
POST /<index>/_alias/<alias>
PUT /<index>/_aliases/<alias>
POST /<index>/_aliases/<alias>路径参数:
<index> : 要添加到别名的索引名称的逗号分隔列表或通配符表达式。
要将群集中的所有索引添加到别名,请使用_all值。
<alias>: (必需,字符串)要创建或更新的索引别名的名称。
比如经过上面的 REST 请求,我们为 twitter 创建了另外一个别名 alias1。我们以后可以通过 alias1 来访问这个 index:
GET alias1/_search显示的结果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "twitter","_type" : "_doc","_id" : "4","_score" : 1.0,"_source" : {"user" : "朝阳区-老贾","message" : "123,gogogo","uid" : 5,"age" : 35,"city" : "北京","province" : "北京","country" : "中国","address" : "中国北京市朝阳区建国门","location" : {"lat" : "39.718256","lon" : "116.367910"}}},{"_index" : "twitter","_type" : "_doc","_id" : "5","_score" : 1.0,"_source" : {"user" : "朝阳区-老王","message" : "Happy BirthDay My Friend!","uid" : 6,"age" : 50,"city" : "北京","province" : "北京","country" : "中国","address" : "中国北京市朝阳区国贸","location" : {"lat" : "39.918256","lon" : "116.467910"}}},{"_index" : "twitter","_type" : "_doc","_id" : "6","_score" : 1.0,"_source" : {"user" : "虹桥-老吴","message" : "好友来了都今天我生日,好友来了,什么 birthday happy 就成!","uid" : 7,"age" : 90,"city" : "上海","province" : "上海","country" : "中国","address" : "中国上海市闵行区","location" : {"lat" : "31.175927","lon" : "121.383328"}}},...显然这样做的好处是非常明显的,我们可以把我们想要的进行搜索的 index 取一个和我们搜索方法里一样的别名就可以了,这样我们可以不修改我们的搜索方法,就可以分别对不同的 index 进行搜索。比如我们可以用同样的搜索方法对每天的 log 进行分析。只有把每天的 log 的 index 的名字都改成一样的 alias 就可以了。
创建一个基于城市的alias:
PUT twitter/_alias/city_beijing
{"filter": {"term": {"city": "北京"}}
}在这里,我们创建了一个名称为 city_beijing 的 alias。如果我们运行如下的搜索:
GET city_beijing/_search它将返回所有关于城市为北京的搜索结果:
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "twitter","_type" : "_doc","_id" : "4","_score" : 1.0,"_source" : {"user" : "朝阳区-老贾","message" : "123,gogogo","uid" : 5,"age" : 35,"city" : "北京","province" : "北京","country" : "中国","address" : "中国北京市朝阳区建国门","location" : {"lat" : "39.718256","lon" : "116.367910"}}},{"_index" : "twitter","_type" : "_doc","_id" : "5","_score" : 1.0,"_source" : {"user" : "朝阳区-老王","message" : "Happy BirthDay My Friend!","uid" : 6,"age" : 50,"city" : "北京","province" : "北京","country" : "中国","address" : "中国北京市朝阳区国贸","location" : {"lat" : "39.918256","lon" : "116.467910"}
...在上面,filter 甚至是可以多个查询,比如:
PUT twitter/_alias/city_beijing
{"filter": [{"term": {"city": "北京"}},{"range": {"age": {"lte": 25}}}]
}当我们做如下查询时:
GET city_beijing/_search显示的结果为:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "twitter","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"user" : "双榆树-张三","message" : "今儿天气不错啊,出去转转去","uid" : 2,"age" : 20,"city" : "北京","province" : "北京","country" : "中国","address" : "中国北京市海淀区","location" : {"lat" : "39.970718","lon" : "116.325747"}}}]}
}上面显示的结果是 city 为北京,同事 age 小于 25 岁。
alias 也可以在创建 index 时被创建,比如:
DELETE twitterPUT twitter
{"mappings" : {"properties" : {"address" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"age" : {"type" : "long"},"city" : {"type" : "keyword","copy_to" : ["region"]},"country" : {"type" : "keyword","copy_to" : ["region"]},"explain" : {"type" : "boolean"},"location" : {"type" : "geo_point"},"message" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"province" : {"type" : "keyword","copy_to" : ["region"]},"region" : {"type" : "text"},"uid" : {"type" : "long"},"user" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}},"aliases": {"city_beijing": {"filter": {"term": {"city": "北京"}}}}
}在这里,我们删除了 twitter 索引,同时我们重新定义 twitter 索引的 mapping,并同时定义了 city_beijing 你别名。重新 index 我们上面的三个文档,那么我们再次搜索我们的数据:
GET city_beijing/_search我们可以看到两个城市为北京的搜索结果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "twitter","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"user" : "双榆树-张三","message" : "今儿天气不错啊,出去转转去","uid" : 2,"age" : 20,"city" : "北京","province" : "北京","country" : "中国","address" : "中国北京市海淀区","location" : {"lat" : "39.970718","lon" : "116.325747"}}},{"_index" : "twitter","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"user" : "东城区-老刘","message" : "出发,下一站云南!","uid" : 3,"age" : 30,"city" : "北京","province" : "北京","country" : "中国","address" : "中国北京市东城区台基厂三条3号","location" : {"lat" : "39.904313","lon" : "116.412754"}}}]}
}我们还可以创建一个指向多个索引的别名,如下图图所示,包括使用通配符提供的索引。

以下代码显示了创建别名 (multi_cars_alias) 的代码。 它指向多个索引(cars1、cars2、cars3)。
PUT cars1,cars2,cars3/_alias/multi_cars_alias上面的索引名称是以逗号分开的列表。
同样,我们也可以使用通配符创建指向多个索引的别名,比如:
PUT cars*/_alias/wildcard_cars_alias一旦我们为一个索引创建了别名,我们可以直接通过如下的接口来获取它的别名,映射及设置:
GET twitter
获取 alias
我们可以通过如下的 API 来获取当前以及定义好的 alias:
GET /_alias
GET /_alias/<alias>
GET /<index>/_alias/<alias>比如:
GET /twitter/_alias/alias1这里获取在 twitter 下的名字叫做 alias1 的别名。针对我们的情况,我们使用如下的接口:
GET /twitter/_alias/city_beijing我们获取我们之前得到的city_beijing的alias。显示的结果如下:
{"twitter" : {"aliases" : {"city_beijing" : {"filter" : {"term" : {"city" : "北京"}}}}}
}你也可以通过如下的 wild card 方式来获取所有的 alias:
GET /twitter/_alias/*比如,我们新增加一个 alias1 的别名:
PUT /twitter/_alias/alias1上面的 wild card 方式返回来得结果为:
{"twitter" : {"aliases" : {"alias1" : { },"city_beijing" : {"filter" : {"term" : {"city" : "北京"}}}}}
}
显然这里有两个别名:alias1 及 city_beijing。
你可以通过如下的方式来搜寻你的alias:
GET /_alias/city_*它将显示名字以 city 开始的所有的 alias。
检查一个 alias 是否存在
我们可以通过如下的方式来检查一个alias是否存在:
HEAD /_alias/<alias>
HEAD /<index>/_alias/<alias>比如:
HEAD /_alias/alias1它显示的结果是:
200 - OK同样你也可通过wild card方式来查询:
HEAD /_alias/city*这个用来检查所有以 city 为开头的 alias。
更新 alias
我们这里所说的更新包括:添加及删除
接口为:
POST /_aliases比如:
POST /_aliases
{"actions" : [{ "add" : { "index" : "twitter", "alias" : "alias2" } }]
}在这里,我们为 twitter 索引添加了一个叫做 alias2 的别名。运行后,我们可以通过 alias2 来重新搜索我们的 twitter
GET /alias2/_search我们可以看到我们想要的结果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "twitter","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"user" : "双榆树-张三","message" : "今儿天气不错啊,出去转转去","uid" : 2,"age" : 20,"city" : "北京","province" : "北京","country" : "中国","address" : "中国北京市海淀区","location" : {"lat" : "39.970718","lon" : "116.325747"}}},...在 action 里,我们可以有如下的几种:
- add: 添加一个别名
- remove: 删除一个别名
- remove_index: 删除一个index或它的别名
比如我们可以通过如下的方法来删除一个 alias
POST /_aliases
{"actions" : [{ "remove": { "index" : "twitter", "alias" : "alias2" } }]
}一旦删除后,之前的定义的 alias2 就不可以用了。
重新命名一个 alias
重命名别名是一个简单的删除然后在同一 API 中添加操作。 此操作是原子操作,无需担心别名未指向索引的短时间段:
POST /_aliases
{"actions" : [{ "remove" : { "index" : "twitter", "alias" : "alias1" } },{ "add" : { "index" : "twitter", "alias" : "alias2" } }]
}
上面的操作,删除 alias1,同时创建一个新的叫做 alias2 的别名。
我们也可以把同一个 alias 在指向不同时期的 index,比如我们的 log index 滚动下一个月,我们可以修改我们的 alias 总是指向最新的index。
POST _aliases
{"actions": [{"add": {"index": "blogs_v2","alias": "blogs"}},{"remove": {"index": "blogs_v1","alias": "blogs"}}]
}经过上面的命令 blogs 是一个执行 blogs_v2 的别名。
为多个索引添加同样一个 alias
将别名与多个索引相关联只需几个添加操作:
POST /_aliases
{"actions" : [{ "add" : { "index" : "test1", "alias" : "alias1" } },{ "add" : { "index" : "test2", "alias" : "alias1" } }]
}你也可以通过如下的方式,通过一个add命令来完成:
POST /_aliases
{"actions" : [{ "add" : { "indices" : ["test1", "test2"], "alias" : "alias1" } }]
}甚至:
POST /_aliases
{"actions" : [{ "add" : { "index" : "test*", "alias" : "all_test_indices" } }]
}这样所有以 test* 为开头的索引都共同一个别名。
当我们 index 我们的文档时,对一个指向多个 index 的别名进行索引是错误的。
也可以在一个操作中使用别名交换索引:
PUT test
PUT test_2PUT test_2/_doc/1
{"text": "nice"
}POST /_aliases
{"actions" : [{ "add": { "index": "test_2", "alias": "test" } },{ "remove_index": { "index": "test" } } ]
}在上面的例子中,假如我们地添加了一个叫做 test 的 index。test 是我们对外的 API 接口需要而设置的索引名称。test_2 里的内容是我们想要的。我们直接可以通过上面的方法吧 test 中的数据交换到 test_2 中,并同时把 test 索引删除。这样当我们访问 test 的时候,其实它访问的是 test_2 里的内容。
GET test/_search上面对 test 的搜索将返回 test_2 中的数据。
Filtered alias
带有过滤器的别名提供了一种创建同一索引的不同“视图”的简便方法。 可以使用 Query DSL 定义过滤器,并使用此别名将其应用于所有“搜索”,“计数”,“按查询删除”和“更多此类操作”。
要创建过滤后的别名,首先我们需要确保映射中已存在这些字段:
PUT /test1
{"mappings": {"properties": {"user" : {"type": "keyword"}}}
}现在我们可以利用 filter 来创建一个alias,是基于 user 字段
POST /_aliases
{"actions" : [{"add" : {"index" : "test1","alias" : "alias2","filter" : { "term" : { "user" : "kimchy" } }}}]
}上面的 alias2 创建了一个 test1 索引上的一个 filter,包含所有的 user 为 kimchy 的文档。
Write index
可以将别名指向的索引关联为 write 索引。 指定后,针对指向多个索引的别名的所有索引和更新请求将尝试解析为 write 索引的一个索引。 每个别名只能将一个索引分配为一次 write 索引。 如果未指定 write 索引且别名引用了多个索引,则不允许写入。
可以使用别名API和索引创建API将与别名关联的索引指定为write索引。
POST /_aliases
{"actions" : [{"add" : {"index" : "test","alias" : "alias1","is_write_index" : true}},{"add" : {"index" : "test2","alias" : "alias1"}}]
}在这里,我们定义了 alias1 同时指向 test 及 test2 两个索引。其中 test 中,注明了 is_write_index,那么,如下的操作:
PUT /alias1/_doc/1
{"foo": "bar"
}相当于如下的操作:
PUT /test/_doc/1也就是写入到 test 索引中,而不会写入到 test2 中。
要交换哪个索引是别名的写入索引,可以利用别名 API 进行原子交换。 交换不依赖于操作的顺序。
POST /_aliases
{"actions" : [{"add" : {"index" : "test","alias" : "alias1","is_write_index" : false}}, {"add" : {"index" : "test2","alias" : "alias1","is_write_index" : true}}]
}在创建索引的时候创建 alias
在上面,我们看到使用 _alias 终点来创建 alias。在实际的使用中,我们甚至可以在创建一个索引的时候就同时把 alias 创建好。比如:
PUT products
{"aliases": {"prod": {"is_write_index": true},"prod1": { }}
}在上面,我们创建一个叫做 products 的索引,并且它是一个可以写入的索引。在创建这个 products 索引的同事,我们也创建了一个叫做 prod1 的 alias。我们导入第一个文档:
PUT products/_doc/1
{"color": "red","weight": 10
}我们可以使用如下的方法来对这个索引进行搜索:
GET prod/_search上面的搜索将返回 products 索引里的文档。我们也可以使用 prod1 这个 alias 来访问:
GET prod1/_search使用别名以零停机时间迁移数据
生产中索引的配置设置有时可能必须使用更新的属性进行更新,这可能是由于新的业务需求或技术增强(或修复错误)。新属性可能与该索引中存在的现有数据不兼容;在这种情况下,我们可以创建一个具有新设置的索引,并将数据从旧索引迁移到全新的索引中。
这听起来不错,但一个潜在的问题是针对旧索引编写的查询(例如,GET cars/_search { ..})需要更新,因为它们现在需要针对新索引运行(car_new)。如果这些查询在应用程序代码中是硬编码的,那么你可能需要将修补程序发布到生产环境中。
假设你有一个名为 vintage_cars 的索引,其中包含古代和老式汽车的所有信息,你现在需要更新索引。这是我们可以依靠别名的地方;我们可以在考虑别名的情况下制定策略。如果你执行以下步骤,迁移最有可能实现零停机时间。

- 创建一个名为 vintage_cars_alias 的别名来引用当前索引 vintage_cars。
- 由于新属性与现有索引不兼容,请创建一个新索引,例如使用新设置的 vintage_cars_new。
- 将旧索引 (vintage_cars) 中的数据复制(即重新索引 reindex)到新索引 (vintage_cars_new)。
- 重新创建指向旧索引的现有别名 (vintage_cars_alias) 以引用新索引。 因此,vintage_cars_alias 现在将指向 vintage_cars_new。
- 现在针对vintage_cars_alias 执行的所有查询都在新索引上执行。
对别名执行的查询现在将从新索引中获取数据,而不会退回应用程序。 因此,你实现了零停机时间。
参考:
【1】Update index alias API | Elasticsearch Guide [7.3] | Elastic
【2】Get index alias API | Elasticsearch Guide [7.3] | Elastic
【3】Add index alias API | Elasticsearch Guide [7.3] | Elastic













![[附源码]计算机毕业设计JAVA房屋中介管理系统](https://img-blog.csdnimg.cn/79abb5b060f94740866f08907c818b10.png)