目录
一、单因素ANOVA
分析
过程
结果及分析
二、双因素ANOVA
案例及分析
过程
结果及分析
一、单因素ANOVA
单因素方差分析是两个样本平均数比较的引伸,它是用来检验多个平均数之间的差异,从而确定一种因素对试验结果有无显著性影响的统计方法。
分析:
研究者想分析不同group间的Index得分差异,可以采用单因素方差分析。
单因素方差分析适用于2种类型的研究设计:
1)判断3个及以上独立的组间均数是否存在差异(也可以是2组,此时等同于独立样本t检验);
2)判断前后变化的差值是否存在差异。
使用单因素方差分析时,需要考虑6个假设。
假设1:因变量为连续变量;
假设2:有一个包含3个及以上分类、且组别间相互独立的自变量;
假设3:各组间和组内的观测值相互独立;
假设4:各组内没有明显异常值;
假设5:各组内因变量符合正态分布;
假设6:各组间的方差齐。
建立检验假设,确定检验水准:
H0:三个总体均值相等,即【情况】相同
H1:三个总体均值不全相等,即【情况】不全相同
α=0.05
由于多个总体均值中两两均值之间的差别,需要利用多个均值间的两两比较方法进一步分析,以下方法都必须在满足方差齐性的前提条件时才可以应用
| 事先已计划好的,不管方差分析结果如何,均进行比较(LSD、Bonferroni) |


格式:这是一个计划/非计划的多重比较,由于【各组样本含量不同】,因此在多重比较对话框中选择【】
过程:
数据-拆分文件(记得合并)
分析-比较平均值-单因素ANOVA分析


结果及分析:
方差齐,方差分析显示组间差异有统计学意义,并进行了两两比较。
- 经箱线图判断,数据无异常值;
- 峰度、偏度值,P-P图、Q-Q图,S-W检验,P=【】,按α=0.05的检验水准,P>0.05,不拒绝H0,认为各组数据服从正态分布
- Levene's方差齐性检验,结果显示F=【】,P=【】,按α=0.05的检验水准,P>0.05,不拒绝H0,认为三总体方差齐,满足方差分析时方差齐性这一前提条件,可以进行完全随机设计的方差分析。
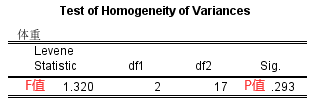
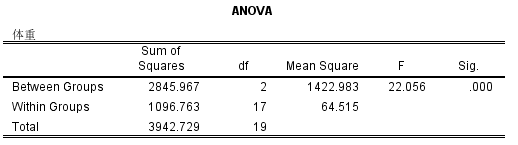
- 方差分析,结果显示F=【】,P=【】,按α=0.05的检验水准,P<0.05,拒绝H0,认为三个总体间均数存在差异,用事后比较。数据以均数±标准差的形式表示,体重分别为:高中及以下组(67.23±4.46)、本科生组(75.44±6.75)、硕士研究生组(80.81±3.23)、博士研究生组(89.60±6.15)。

- (1)【】检验是三组样本之间互相两两比较,结果显示三组互相两两之间进行比较P值均小于0.05,差别均有统计学意义。
Tukey检验结果表明,从高中及以下组到本科生组,Index平均得分增加8.22(95%CI:0.79~15.65),差异具有统计学意义(P=0.026);从高中及以下组到硕士研究生组,Index平均得分增加13.58(95%CI:5.95~21.21),差异具有统计学意义(P <0.001),其他组比较解释同上。

(2)邓妮特检验是【】组分别与【】组对照组相比,【】组与【】组对照组对应P值<0.05,差别有统计学意义,剩余【】组与【】组对照组P值均>0.05,差别没有统计学意义。

二、双因素ANOVA
案例及分析
需要先满足6项假设:
假设1:因变量是连续变量。
假设2:存在两个自变量,且都是分类变量。
假设3:具有相互独立的观测值。
假设4:任一分类中不存在显著异常值。
假设5:任一分类中残差近似正态分布。
假设6:任一分类都具有等方差性。
建立检验假设,确定检验水准:
对行/列因素提出的假设:
H0:【】个总体均数全相等,【行/列因素】【因变量】相同
H1:【】个总体均数不全相等,【行/列因素】【因变量】不全相同
检验水准α=0.05
过程:
分析-一般线性模型-单变量
可以得到双因素方差分析的结果,并生成3个新变量:预测值(PRE_1),残差(RES_1)和学生化残差(SRE_1)。



数据-拆分文件 拆分数据(即将数据根据性别和饮食人群分成6类)

分析-描述统计-探索 检验假设:任一分类中不存在显著异常值、残差近似正态分布
结果及分析:
自变量之间不存在交互作用,采用主效应和两两比较分析。
1、经箱线图判断,数据无异常值;
2、峰度、偏度值,P-P图、Q-Q图,S-W检验,P=【】,按α=0.05的检验水准,P>0.05,不拒绝H0,认为各组数据残差服从正态分布
3、Levene's方差齐性检验,结果显示F=【】,P=【】,按α=0.05的检验水准,P>0.05,不拒绝H0,认为三总体方差齐,满足方差分析时方差齐性这一前提条件,可以进行完全随机设计的方差分析。

4、结果显示,F性别*饮食人群=【】,P=【】,按α=0.05的检验水准,
(1)P<0.05,拒绝假设H0,认为性别和饮食人群在对【】的影响上存在交互作用。当存在交互作用时,单独分析主效应的意义不大,需要逐一分析各因素的单独效应,分析两者的交互特点,因素A中因素B对因变量的影响是否有差异【要用代码操作,就没学】;

(2)如果P>0.05,说明交互项没有统计学意义,两个自变量之间不存在交互作用。
当不存在交互作用时,说明两因素的作用效果相互独立,逐一分析各因素的主效应即可。看【因素A】和【因素B】的主效应所对应的P值,【因素A】P值<0.05,【因素B】P值>0.05,【因素A】对【】有影响,【因素B】对【】没有影响,对类别数超过2的自变量因素进行多重比较。
5、 接4(2),主效应分析过程
如果是平衡设计,采用SPSS输出Univariate: Post Hoc-Multiple Comparisons for Observed Means分析结果;
如果是非平衡设计,且计算加权边际均值,采用Descriptive Statistics和Multiple Comparisons结果;
如果是非平衡设计,且计算非加权边际均值,采用Estimates和Pairwise Comparisons结果。


采用两两比较分析受教育程度的主效应结果。
受教育程度为高中及以下、大学本科和研究生及以上学历的研究对象的幸福指数评分的非加权边际均值分别为64.48、68.63和86.25分【针对非平衡设计,也没学】。
- 【】检验是三组样本之间互相两两比较,结果显示三组互相两两之间进行比较P值均小于0.05,差别均有统计学意义。
Tukey检验结果表明,从高中及以下组到本科生组,Index平均得分增加8.22(95%CI:0.79~15.65),差异具有统计学意义(P=0.026);从高中及以下组到硕士研究生组,Index平均得分增加13.58(95%CI:5.95~21.21),差异具有统计学意义(P <0.001),其他组比较解释同上。
- 邓妮特检验是【】组分别与【】组对照组相比,【】组与【】组对照组对应P值<0.05,差别有统计学意义,剩余【】组与【】组对照组P值均>0.05,差别没有统计学意义。