所有的网络应用都是基于相同的基本编程模型(客户端-服务器编程模型),有着相似的整体逻辑结构,并且依赖相同的编程接口。
客户端-服务器编程模型
每个网络应用都是基于客户端-服务器模型的。采用这个模型,一个应用是由一个服务器进程和一个或者多个客户端进程组成。服务器管理某种资源,并且通过操作这种资源来为它的客户端提供某种服务。例如,一个Web服务器管理着一组磁盘文件,它会代表客户端进行检索和执行。
客户端-服务器模型中的基本操作是事务(transaction)。一个客户端-服务器事务由以下四步组成。
- 当一个客户端需要服务时,它向服务器发送一个请求,发起一个事务。例如,当Web浏览器需要一个文件时,它就发送一个请求给Web服务器。
- 服务器收到请求后,解释它,并以适当的方式操作它的资源。例如,Web服务器收到浏览器发出的请求后,它就读一个磁盘文件。
- 服务器给客户端发送一个响应,并等待下一个请求。例如,Web服务器将文件发送回客户端。
- 客户端收到响应并处理它。例如,当Web浏览器收到来自服务器的一页后,就在屏幕上显示此页。
客户端和服务器是进程,而不是常提到的机器或者主机。
客户端-服务器事务不是数据库事务,没有数据库事务的任何特性,例如原子性。在我们的上下文中,事务仅仅是客户端和服务器执行的一系列步骤。
网络
客户端和服务器通常运行在不同的主机上,并且通过计算机网络的硬件和软件资源来通信。
对主机而言,网络只是右一种I/O设备,是数据源和数据接收方。
物理上而言,网络是一个按照地理远近组成的层次系统。最底层是LAN(Local Area Network,局域网)。
以太网
迄今为止,最流行的局域网技术就是以太网(Ethernet),它是由施乐公司帕洛阿尔托研究中心(Xerox PARC)在20世纪70年代中期提出来的。
一个以太网段(Ethernet segment)包括一些电缆(通常是双绞线)和一个叫做集线器的小盒子。
每根电缆都有相同的最大位带宽,通常是100Mb/s或者1Gb/s。电缆的一端连接到主机的适配器,而另一端则连接到集线器的一个端口上。
集线器不加分辨的将从一个端口上收到的每个位复制到其他所有的端口上。因此,每台主机都能看到每个位。
每个以太网适配器都有一个全球唯一的48位地址,它存储在这个适配器的非易失性存储器上。
一台主机可以发送一段位(称为帧(frame))到这个网段内的其他任何主机。每个帧包括一些固定数量的头部(header)位,用来标识此帧的源和目的地址以及此帧的长度,此后紧随的就是数据位的有效荷载(payload)。每个主机适配器都能看到这个帧,但是只有目的主机实际读取它。

桥接以太网
使用一些电缆和叫做网桥(bridge)的小盒子,多个以太网段可以连接成较大的局域网,称为桥接以太网(bridged Ethernet),如图11-4所示。
在一个桥接以太网里,一些电缆连接网桥与网桥,而另外一些连接网桥和集线器。这些电缆的带宽可以是不同的。
网桥比集线器更充分的利用了电缆带宽。利用一种聪明的分配算法,它们随着时间自动学习哪个主机可以通过哪个端口可达,然后只在有必要时,有选择的将帧从一个端口复制到另一个端口。例如,如果主机A发送一个帧到同网段上的主机B,当该帧到达网桥X的输入端口时,X就将丢弃此帧,因而节省了其它网段上的带宽。然而,如果主机A发送一个帧到一个不同网段上的主机C,那么网桥X只会把此帧复制到和网桥Y相连的端口上,网桥Y会只把此帧复制到与主机C的网段连接的端口。

互联网
在层次的更高级别中,多个不兼容的局域网可以通过叫做路由器(router)的特殊计算机连接起来,组成一个internet(互联网络)。
互联网络至关重要的特性是,它能由采用完全不同和不兼容技术的各种局域网和广域网组成。
解决互联网络某台源主机跨过所有这些不兼容的网络发送数据位到另一台目的主机的方法就是一层运行在每台主机和路由器上的协议软件,它消除了不同网络之间的差异。这个软件实现一种协议,这种协议控制主机和路由器如何协同工作来实现数据传输。这种协议必须提供两种基本能力:
- 命名机制。不同的局域网技术有不同和不兼容的方式来为主机分配地址。互联网络协议通过定义一种一致的主机地址格式消除了这些差异。每台主机会被分配至少一个这种互联网络地址(Internet address),这个地址唯一的标识了这台主机。
- 传送机制。在电缆上编码位和将这些位封装成帧方面,不同的联网技术有不同的和不兼容的方式。互联网络协议通过定义一种把数据位捆扎成不连续的片(称为包)的统一方式,从而消除了这些差异。一个包是由包头和有效载荷组成的,其中包头包括包的大小以及源主机和目的主机的地址,有效载荷包括从源主机发出的数据位。
全球IP因特网
全球IP因特网是最著名和最成功的互联网络实现。
因特网客户端-服务器应用程序的基本硬件和软件组织:

每台因特网主机都运行实现TCP/IP协议(Transmission Control Protocol/Internet Protocol,传输控制协议/互联网络协议)的软件,几乎每个现代计算机系统都支持这个协议。
因特网的客户端和服务器混合使用套接字接口函数和Unix I/O函数来进行通信。通常将套接字函数实现为系统调用,,这些系统调用会陷入内核,并调用各种内核模式的TCP/IP函数。
网路协议详见:计算机网络:网络协议。
因特网详见:计算机网络:Internet。
套接字接口
套接字接口(socket interface)是一组函数,它们和Unix I/O函数结合起来,用以创建网络应用。
下图给出了一个典型的客户端-服务器事务的上下文中套接字接口概述:
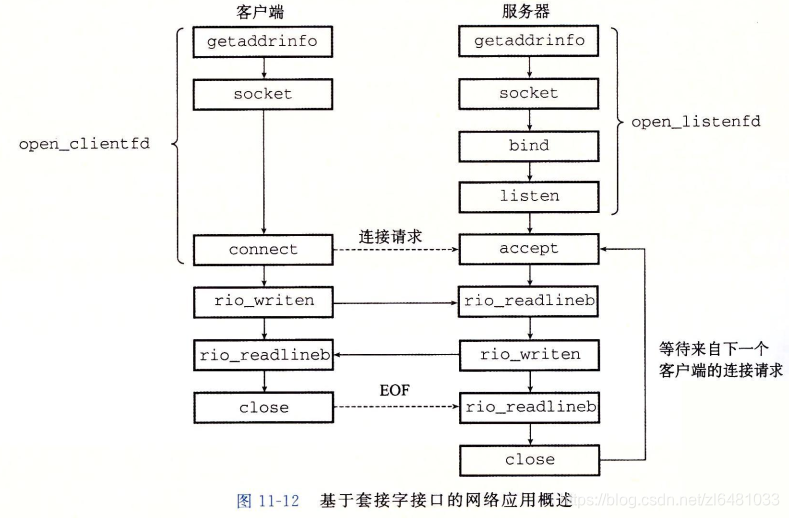
套接字地址结构
从Linux内核的角度看,一个套接字就是通信的一个端口。
从Linux程序的角度来看,套接字就是一个有相应描述符的打开文件。
套接字地址结构:
/* IP socket address structure */
struct sockaddr_in {uint16_t sin_family; /* Protocol family (always AF_INET) 成员是AF_INET */uint16_t sin_port; /* Port numer in network byte order 成员是16位的端口号 */struct in_addr sin_addr; /* IP address in network byte order 成员是一个32位的IP地址 */unsigned char sin_zero[8]; /* Pad to sizeof(struct sockaddr) */
};/* Generic socket address structure (for connect, bind, and accept) */
struct sockaddr {uint16_t sa_family; /* Protocol family */char sa_data[14]; /* Address data */
};connect、bind和accept函数要求一个指向与协议相关的套接字地址结构的指针。套接字接口的设计者面临的问题是,如何定义这些函数,使之能接受各种类型的套接字地址结构。今天我们可以使用通用的void*指针,但是那时在C中并不存在这种类型的指针。解决办法是定义套接字函数要求一个指向通用sockaddr结构的指针,然后要求应用程序将与协议特定的结构的指针强制转换成这个通用结构。
然后无论何时需要将sockaddr_in结构强制转换成通用的sockaddr结构时,我们都使用这个类型。
socket函数
客户端和服务器使用socket函数来创建一个套接字描述符(socket descriptor)。
#include <sys/types.h>
#include <sys/socket.h>int socket(int domain, int type, int protocol);//返回:若成功则为非负描述符,若出错则为-1。如果想要使用套接字成为连接的一个端点,就用如下硬编码的参数来调用socket函数:
clientfd = Socket(AF_INET, SOCK_STREAM, 0);其中,AF_INET表明我们正在使用32位IP地址,而SOCK_STREAM表示这个套接字是连接的一个端点。不过最好的方法是用getaddrinfo函数来自动生成这些参数,这样代码就与协议无关了。
socket返回的clientfd描述符仅是部分打开的,还不能用于读写。如何完成打开套接字的工作,取决于我们是客户端还是服务器。
connect函数
客户端通过调用connect函数来建立和服务器的连接。
#include <sys/socket.h>int connect(int clientfd, const struct sockaddr *addr, socklen_t addrlen);//返回:若成功则为0,若出错则为-1。connect函数试图与套接字地址为addr的服务器建立一个因特网连接,其中addrlen是sizeof(sockaddr_in)。connect函数会阻塞,一直到连接成功建立或是发生错误。如果成功,clientfd描述符现在就准备好可以读写了,并且得到的连接是由套接字对(x:y, addr.sin_addr:addr.sin_port)刻画的,其中x表示客户端的IP地址,而y表示临时端口,它唯一的确定了客户端主机上的客户端进程。对于socket,最好的方法是用getaddrinfo来为connect提供参数。
bind函数
剩下的套接字函数——bind、listen和accept,服务器用它们来和客户端建立连接。
#include <sys/socket.h>int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);//返回:若成功则为0,若出错则为-1。bind函数告诉内核将addr中的服务器套接字地址和套接字描述符sockfd联系起来。参数addrlen就是sizeof(sockaddr_in)。对于socket和connect,最好的方法是用getaddrinfo来为bind提供参数。
listen函数
客户端是发起连接请求的主动实体。服务器是等待来自客户端的连接请求的被动实体。默认情况下,内核会认为socket函数创建的描述符对应于主动套接字(active socket),它存在于一个连接的客户端。服务器调用listen函数告诉内核,描述符是被服务器而不是客户端使用的。
#include <sys/socket.h>int listen(int sockfd, int backlog);//返回:若成功则为0,若出错则为-1。listen函数将sockfd从一个主动套接字转化为一个监听套接字(listening socket),该套接字可以接受来自客户端的连接请求。backlog参数暗示了内核在开始拒绝连接请求之前,队列中要排队的未完成的连接请求的数量。backlog参数的确切含义要求对TCP/IP协议的理解,这超出了我们讨论的范围。通常我们会把它设置为一个较大的值,比如1024。
accept函数
服务器通过调用accept函数来等待来自客户端的连接请求。
#include <sys/socket.h>int accept(int listenfd, struct sockaddr *addr, int *adddrlen);//返回:若成功则为非负连接描述符,若出错则为-1。accept函数等待来自客户端的请求到达侦听描述符listenfd,然后在addr中填写客户端的套接字地址,并返回一个已连接描述符,这个描述符可被利用Unix IO 函数与客户端通信。
监听描述符与已连接描述符之间的区别是很多人感到迷惑,监听描述符是作为客户端连接请求的一个端点,它通常被创建一次,并存在于服务器整个生命周期,已连接描述符是客户端于服务器之间已经建立起来的连接的端点,服务器每次接受连接请求时都会创建一次,它只存在于服务器为一个客户端服务的过程中。
下图描绘了监听描述符和已连接描述符的角色,在第一步,服务器调用accept,等待连接请求到达监听描述符,设为3。第二步中客户端调用connect函数,发送一个连接请求到listenfd,第三步,accept函数打开一个新的已连接描述符connfd(设为4),在clientfd和connfd之间建立连接,并随后返回connfd给应用程序,客户端也从connect返回,在这一点后,客户端和服务器就可以分别读和写clientfd和connfd来回传数据了。

监听描述符和已连接描述符之间的区别:这两者的区分是很有用的,它可以使我们建立并发服务器,能够同时处理许多客户端连接,例如,每一次一个连接请求到达监听描述符时,我们可以派生fork一个新的进程,它通过已连接描述符与客户端通信。
主机和服务的转换
linux 提供了一些强大的函数(getaddrinfo和getnameinfo)实现二进制套接字地址结构和主机名、主机地址、服务名和端口号的字符串表示之间的相互转化。当和套接字接口一起使用时,这些函数能够使我们编写独立于任何版本的IP协议的网络程序。
(1)getaddrinfo函数
getaddrinfo函数将主机名、主机地址、服务名和端口号的字符串转化为套接字地址结构。
#include <sys/types.h>
#include <sys/socket.h>
#include <netdb.h>int getaddrinfo(const char *node, const char *service,const struct addrinfo *hints,struct addrinfo **res);void freeaddrinfo(struct addrinfo *res);const char *gai_strerror(int errcode);struct addrinfo {int ai_flags;int ai_family;int ai_socktype;int ai_protocol;socklen_t ai_addrlen;struct sockaddr *ai_addr;char *ai_canonname;struct addrinfo *ai_next;};给定host和service(套接字地址的两个组成部分),getaddrinfo函数返回result,result是一个指向addrinfo结构的链表,其中每个结构都指向一个对应于host和service的套接字地址结构。
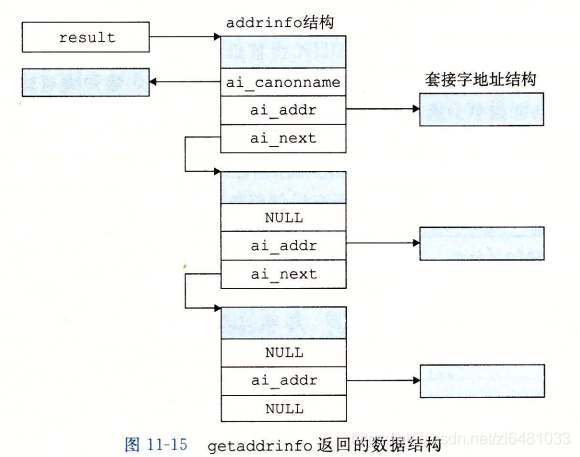
在客户端调用了getaddrinfo之后,会遍历整个列表,依次尝试每个套接字地址,直到调用socket和connect成功,建立连接。类似的,服务器会尝试遍历列表中每个套接字地址,直到调用socket和bind成功,描述符会被绑定到一个合法的套接字地址,为了避免内存泄漏,应用程序必须在最后调用freeaddrinfo,释放该链表。如果getaddrinfo返回非0的错误代码,应用程序可以调用gai_streeror,将该代码转换成消息字符串。
getaddrinfo的host参数可以是域名,也可以使数字地址,service可以是服务名(如http)也可以是十进制端口号,如果不想把主机名转换成地址可以把host参数设为NULL,service也一样,但必须指定两者中至少一个。
可选参数hints是一个addrinfo结构,它提供对getaddrinfo返回的套接字地址列表更好的控制,如果要传递hints参数,只需要设置下列字段,ai_family、ai_socktype、ai_protocol和ai_flags字段,其他字段必须设置为0或NULL。实际中,使用memset将整个结构清零,然后有选择地设置一些字段。
*getaddrinfo 默认返回IPv4和IPv6套接字地址,ai_famliy设置为AF_INET会将列表限制为IPv4地址,设置为AF_INET6会限制为IPv6地址。
*对于host关联地每个地址,getaddrinfo函数最多返回三个addrinfo结构。
*ai_flags字段是一个位掩码,可以进一步修改默认行为。
当getaddrinfo创建输出列表中地addrinfo结构时,会填写每个字段,除了ai_flags。ai_addr字段指向一个套接字地址结构,ai_addrlen字段给出这个套接字地址结构的大小,而ai_next字段指向列表中下一个addrinfo结构,其他字段描述这个套接字地址的各种属性。
getaddrinfo一个好的方面就是addrinfo结构中的字段是不透明的,也就是他们可以直接传递给套接字接口中的函数,应用程序代码无需再做任何处理,例如ai_family、ai_socktype和ai_protocl可以直接传递给socket。ai_addr和ai_addrlen可以直接传递给connect和bind。这个属性可以使我们编写客户端和服务器能够独立于某个特殊版本的IP协议。
(2)getnameinfo函数
getnameinfo函数和getaddrinfo是相反的,将一个套接字地址结构转换成相应的主机和服务名字符串。
#include <sys/socket.h>
#include <netdb.h>int getnameinfo(const struct sockaddr *sa, socklen_t salen,char *host, socklen_t hostlen,char *serv, socklen_t servlen, int flags);/*
**The flags argument modifies the behavior of getnameinfo() as follows:** NI_NAMEREQD
** If set, then an error is returned if the hostname cannot be determined.
**
** NI_DGRAM
** If set, then the service is datagram (UDP) based rather than stream (TCP) **based. This is required for the few ports (512-514) that
** have different services for UDP and TCP.** NI_NOFQDN
** If set, return only the hostname part of the fully qualified domain name **for local hosts.** NI_NUMERICHOST
** If set, then the numeric form of the hostname is returned. (When not **set, this will still happen in case the node's name cannot be
** determined.)** NI_NUMERICSERV
** If set, then the numeric form of the service address is returned. (When **not set, this will still happen in case the service's name
** cannot be determined.)
*/参数sa指向大小为salen字节的套接字结构,host指向大小为hostlen字节的缓冲区,serv 指向大小为servlen字节的缓冲区。getnameinfo函数将套接字地址结构sa转换成对应的主机和服务名字符串,并将它们复制到host和service缓冲区。如果getnameinfo返回非零的错误代码,应用程序可以调用gai_strerror把它转换成字符串。
如果不想要主机名,可以把host设置为NULL,hostlen设置为0。对服务字段来说也是一样,不过两者最少设置一个。
参数flag是一个位掩码,能够修改默认的行为,可以把各种值用OR组合起来得到该掩码。
*NI_NUMERICHOST 。getnameinfo默认试图返回host中的域名,设置该标志会使该函数返回一个数字地址字符串。
*NI_NUMERICSERV。getnameinfo默认会检查/etc/service,如果可能会返回服务名而不是端口号,设置该标志会使该函数跳过查找,简单返回端口号。更多参数可以查看上图。
套接字接口的辅助函数
一开始可能觉得getnameinfo函数和套接字接口看上去比较麻烦,可以用一些辅助函数包装一下会方便很多。称为open_clientfd和open_listenfd,客户端和服务器相互通信时可以使用这些函数。
(1)open_clientfd函数
客户端调用open_clientfd建立于服务器的连接。
//成功返回描述符,出错返回-1
int open_clientfd(char *hostname, char *port) {int clientfd;struct addrinfo hints, *listp, *p;// Get a list of potential server addressmemset(&hints, 0, sizeof(struct addrinfo));hints.ai_socktype = SOCK_STREAM; // Open a connectionhints.ai_flags = AI_NUMERICSERV; // using numeric port argumentshints.ai_flags |= AI_ADDRCONFIG; // Recommended for connectionsgetaddrinfo(hostname, port, &hints, &listp);// Walk the list for one that we can successfully connect to// 如果全部都失败,才最终返回失败(可能有多个地址)for (p = listp; p; p = p->ai_next) {// Create a socket descriptor// 这里使用从 getaddrinfo 中得到的参数,实现协议无关if ((clientfd = socket(p->ai_family, p->ai_socktype,p->ai_protocol)) < 0)continue; // Socket failed, try the next// Connect to the server// 这里使用从 getaddrinfo 中得到的参数,实现协议无关if (connect(clientfd, p->ai_addr, p->ai_addrlen) != -1)break; // Successclose(clientfd); // Connect failed, try another}// Clean upfreeaddrinfo(listp);if (!p) // All connections failedreturn -1;else // The last connect succeededreturn clientfd;
}open_clientfd函数建立与服务器的连接,该服务器运行在主机hostname上,并在端口号port监听连接请求,返回一个打开的套接字描述符,该描述符准备好了就可以用Unix IO函数作为输入和输出。上图是源码,调用getaddrinfo,返回一个addrinfo的结构列表,每个结构指向一个套接字地址结构,可以用于建立与服务器的连接,该服务器运行在hostname上并监听port端口,然后遍历该列表,依次尝试列表中的每个条目,直到调用socket和connect成功,如果connect失败,再尝试下一个条目之前要关闭套接字描述符。如果connect成功,会释放列表内存,并把套接字描述符返回给客户端,客户端可以立即开始用Unix IO与服务器通信。
(2)open_listenfd 函数
调用open_listenfd函数,服务器创建一个监听描述符,准备好连接请求。
int open_listenfd(char *port){struct addrinfo hints, *listp, *p;int listenfd, optval=1;// Get a list of potential server addressesmemset(&hints, 0, sizeof(struct addrinfo));hints.ai_socktype = SOCK_STREAM; // Accept connectionhints.ai_flags = AI_PASSIVE | AI_ADDRCONFIG; // on any IP addresshints.ai_flags |= AI_NUMERICSERV; // using port number// 因为服务器不需要连接,所以原来填写地址的地方直接是 NULLgetaddrinfo(NULL, port, &hints, &listp); // Walk the list for one that we can successfully connect to// 如果全部都失败,才最终返回失败(可能有多个地址)for (p = listp; p; p = p->ai_next) {// Create a socket descriptor// 这里使用从 getaddrinfo 中得到的参数,实现协议无关if ((listenfd = socket(p->ai_family, p->ai_socktype,p->ai_protocol)) < 0)continue; // Socket failed, try the next// Eliminates "Address already in use" error from bindsetsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR), (const void *)&optval, sizeof(int));// Bind the descriptor to the addressif (bind(listenfd, p->ai_addr, p->ai_addrlen) == 0)break; // Successclose(listenfd); // Bind failed, try another}// Clean upfreeaddrinfo(listp);if (!p) // No address workedreturn -1;// Make it a listening socket ready to accept connection requestsif (listen(listenfd, LISTENQ) < 0) {close(listenfd);return -1;}return listenfd;
}open_listenfd函数打开和返回一个监听描述符,这个描述符准备好在端口port上,接受连接请求。和open_clientfd很像,也是调用getaddrinfo,然后遍历结果列表,直到调用socket和bind成功。在上面的程序中,使用了setsockopt函数配置服务器,使得服务器能够被终止、重启和立即开始接受连接请求。一个重启的服务器默认在大约30s内拒绝客户端的连接请求。在调用getaddrinfo时使用AI_PASSIVE标志,将host参数设置为NULL,每个套接字地址结构中的地址字段会被设置为通配符地址,告诉内核这个服务器会接收发送到本主机的所有IP地址的请求。
Web服务器
Web基础
Web客户端和服务器中之间的交互作用是一个基于文本的应用级协议,叫做HTTP协议(超文本传输协议)。HTTP是一个简单的协议,一个Web客户端(也就是浏览器)打开一个到服务器的因特网连接,并请求这些内容。服务器响应所请求的内容,然后关闭连接,浏览器读取这些内容,并把它显示在屏幕上。
Web服务和常规的文件检索服务(例如FTP)的主要区别是:Web内容可以用一种叫做HTML(超文本标记语言)来编写,一个HTML程序(页)包含指令(标记)他们告诉浏览器如何显示这页中的各种文本和图形对象。例如
<b> Make me bold! </b>告诉浏览器用粗体字型输出<b>和</b>标记之间的文本,然而,HTML真正强大的地方再一个页面可以包含指针(超链接)这些指针可以指向存放在任何因特网主机上的内容,例如,一个格式如下的HTML行
<a href="http://www.cmu.edu/index.html">Carnegie Mwllon</a>告诉浏览器高亮显示文本对象Carnegie Mwllon并创建一个超链接,指向存放CMU Web服务器叫做index.html的HTML文件。如果用户单击了这个高亮文本对象,浏览器会从CMU服务器中请求相应的HTML文件并显示。
Web内容
对于Web客户端和服务器而言,内容是与一个MIME(多用途的忘记邮件扩充协议)类型相关的字节序列,下图是一些常用的MIME类型。

Web服务器以两种不同的方式向客户端提供内容:
- 取一个磁盘文件,并将它的内容返回客户端,磁盘文件成为静态内容,而返回文件给客户端的过程称为服务静态内容。
- 运行一个可执行文件,并将它的输出返回客户端,运行时可执行文件的输出称为动态内容,而运行程序并返回他的输出到客户端的过程称为服务动态内容。而运行程序并返回他的输出到客户端的过程被称为服务动态内容。
每条由Web服务器返回的内容都是和它管理的某个文件相关联的,这些文件中的每一个都有一个唯一的名字,叫做URL(通用资源定位符),例如
http://www.google.coim:80/index.html表示因特网主机www.goole.com上有一个称为/index.html的HTML的文件,是由一个监听端口80的Web服务器管理的,端口号是可选的,默认为知名的HTTP端口80,可执行文件的URL可以在文件名后包括程序参数。“?”字符分割文件名和参数,并且每个参数都用“&”字符分隔开。例如
http://bludfish.ics.cs.cmu.edu:8000/cgi-bin/addr?15000&213上面这个URL标识了一个叫做/cgi-bin/addr 的可执行文件,会带有两个参数字符串,15000和213来调用它,在事务过程中客户端和服务器使用的是URL的不同部分,例如,客户端使用前缀:http://www.google.com:80来决定与哪类服务器联系,服务器在哪以及监听的端口号是多少,服务器使用后缀/index.html来发现它文件系统中的文件,并确定请求的是静态内容还是动态内容。
关于服务器如何解释一个URL的后缀,有几点需要理解:
- 确定一个URL指向的是静态内容还是动态内容没有标准的规则。每个服务器对它所管理的文件都有自己的规则。一种经典的(老式的)方法是,确定一组目录,例如,cgi-bin,所有的可执行性文件都必须存放在这些目录中。
- 后缀中的最开始的那个“/”不表示Linux的根目录。相反,它表示的是被请求内容类型的主目录。
- 最小的URL后缀是“/”字符,所有服务器将其扩展为某个默认的主页。
HTTP事务
资料《深入理解计算机系统》