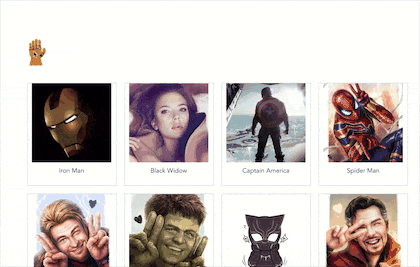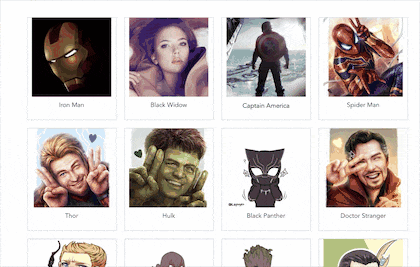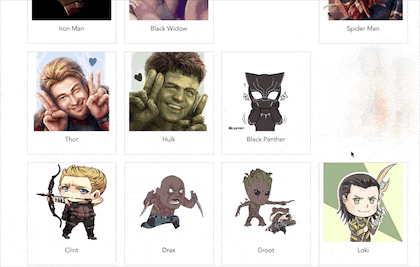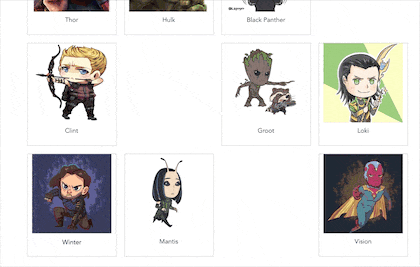
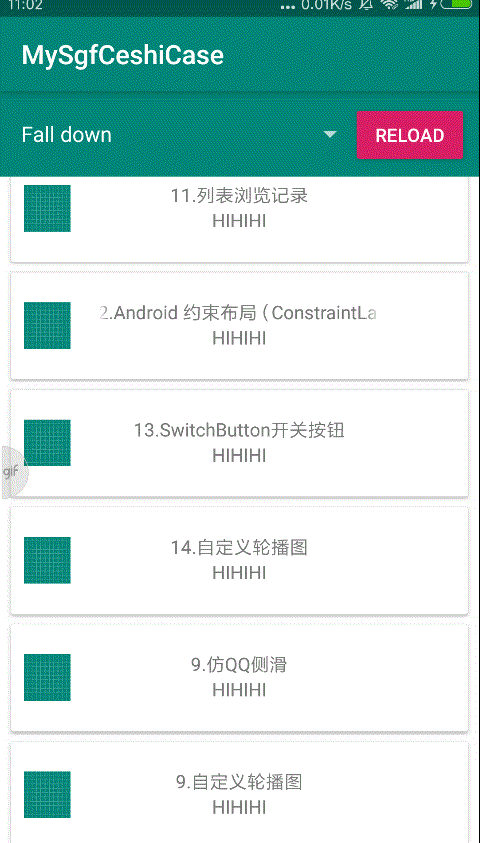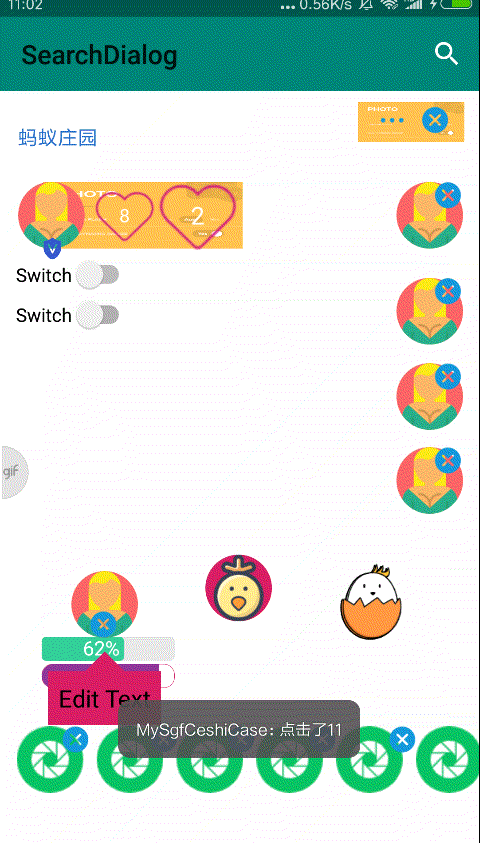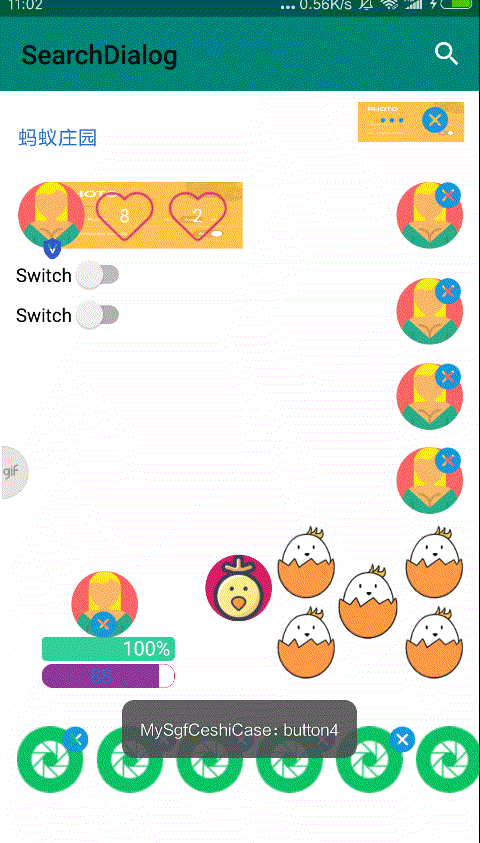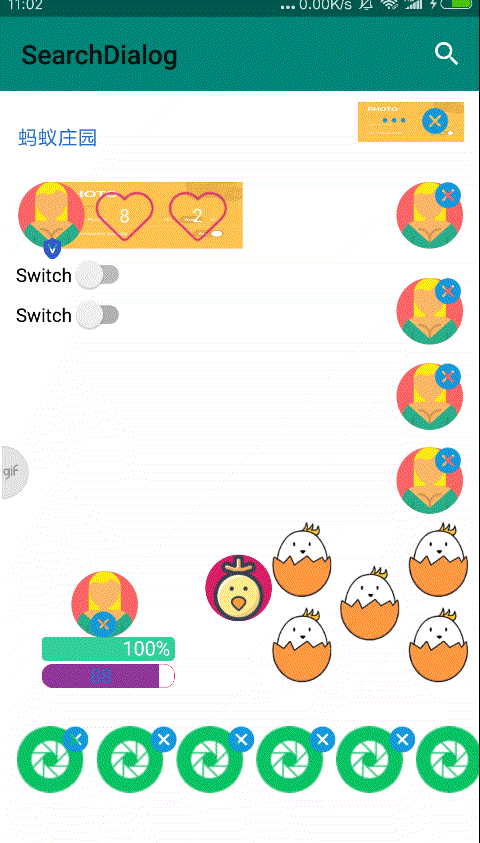
大家好,我是初冬,一直想研究一下人工智能,但是一直再观望,上一期我写来一篇《一篇前端图像处理秘籍》,想着趁热打铁,于是卯足干劲,就有了前端换脸的想法,那就写一个换脸的 Demo 吧,因此就有以下图片中的 DEMO。

今天我们就以这个 DEMO 来看看,如何利用 tfjs + canvas 实现前端换脸。
技术分析
前端换脸(易容术)前提就是获取到人脸的范围,但是目前也就只有 AI 能够起到关键性的作用,因为关键在于人脸的识别以及计算五官的位置和大小,从而可以满足我们天马行空的需求,怎么样才能让它跟灭霸打响指一样简单呢?
首先,我们需要精准的获取到图像(图片或视频)中是否有人脸,另外就是人脸的边界以及五官的位置。比如:检测人脸特征点,我们称之为人脸的“神经网络”。

其次,作为主刀医生的我们,在拿到五官位置的报告之后,跟客户的沟通明确需求之后,再次进行仔细慎密分析,最终我们就才放心大胆的动“刀子”了。
别忘了打麻药,我好几次都忘了,客户疼晕过去也就省去了麻药的费用。我真是勤俭持家的好大夫。
我们除了要拿到五官的位置以外,我们还需要知道五官的大小,说实话这有点难,不是所有人的眼睛都跟杜海涛和李荣浩那样精密(显微镜好测),也不是所有人的嘴都像姚晨和舒淇那般气吞山河。
我相信有些伙伴已经陷入焦虑之中,不用焦虑了朋友,反正被动刀的人不是你🤪,方法总比困难多,对吧,动起来再说。
技术选型
要想获取到五官的位置,首先得识别人脸,然后才是获取人脸五官的范围及其五官位置。这里我们不得不借助一些 AI 智能的力量了,关于智能人脸检测的库初步调研下来大概有face-api.js、tracking.js、clmtrackr.js、tfjs。
同时我也一步步,满怀这初为主刀医生的信心,满怀期待的从 face-api 开始,一个一个的往下试,屡试屡败,屡败屡试,差点就从入门到放弃了,想到我一代神医难道要从此没落?突然我从自我怀疑的废墟之中站起来了,再确认过准备工作和工作流程之后,我发现这个仓库是 3年前的,也可能是是自我的问题,我还是毅然决然的放弃 face-api.js、tracking.js、clmtrackr.js 这些提案,将寄托的颜色投向 tfjs。
很快我在 tfjs 的官网 找到一些已经训练好的模型 ,其中就包含我们需要的人脸检测的模型 ,巧了吗不是,为我们开启了易容术的大门,谷歌果然没有让我失望😄。
通过漫长又愉快的测试,我发现 Blazface 库可以帮助我们检测到:
- 人脸范围的开始和结束坐标
- 左眼睛和右眼睛的位置
- 左耳朵和右耳朵的位置
- 鼻子的位置
- 嘴巴的位置
一图胜千言,眼见为实以下。

技术实现
技术分享如果只讲理论那岂不是太聒噪了,不符合我的 Style,关于如何从技术上实现,我们可以从一个简单的 DEMO 开始,给眼睛添加上 💗。
先敬上一张效果图。

整个实现流程可分为以下几个步骤:
- 引入 tfjs 并加载 AI 模型(人脸识别)
- 获取图像中所有人脸的信息
- 计算每个人眼睛的大小
- canvas 绘制图片并在眼睛上方添加 💗
这里我们使用的是贴图,而不是改变图像的数据(ImageData)。当然我们也可以直接更改 ImageData,但是罗翔老师表示不推荐,如果直接更改图像的数据,不仅计算量很大,导致绘制卡顿,甚至会导致浏览器卡死;另外模型目前无法保证精度,从而导致图像失真。毕竟我们现在依靠的是 AI 模型分析提供的坐标,期待以后模型更加完善和精准吧。
第一步:引入 Blazface detector 库 并加载 AI 模型
Blazface detector 库依赖 tfjs,因此我们需要先加载 tfjs.
两种引入方式
npm 导入
const blazeface = require('@tensorflow-models/blazeface');
script 标签
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/blazeface"></script>
加载 AI 模型
⚠️ 需要科学上网,因为 model 需要从 TFHUB 上加载,未来有望可以自己选择从哪加载模型(先已接受提案)。
async function main() {// 加载模型const model = await blazeface.load();// TODO...}main();
第二步:获取图像中所有人脸的信息
在确保模型加载完成之后,我们可以使用 estimateFaces 方法来检测到图像中所有的人脸信息,该方法将返回一个数组,数组的数量为检测到的人脸的数量,每一个人脸信息都是一个对象,该对象包含以下信息:
- topLeft
人脸↖️角边界的坐标 - bottomRight
人脸↘️角边界的坐标。可以结合topLeft计算出,人脸的宽、高大小。 - probability
准确率。 - landmarks
包含五官的位置的数组。按顺序分别表示右眼睛、左眼睛、鼻子、嘴巴、右耳朵、左耳朵。
estimateFaces 方法接收 2 个参数,分别为:
- input
DOM 节点活着 DOM 对象。可以是video活着image。 - returnTensors
布尔类型,返回数据类型。如果是false返回的具体数值,x, y 坐标等。如果为true,返回的是一个对象。
示例:
// 我们将 video 或 image 对象(或节点)传递给模型
const input = document.querySelector("img");
// 该方法将返回一个包含人脸边界框、五官坐标的数组,数组的每一个 item 都对应一个人脸。
const predictions = await model.estimateFaces(input, false);
/*
`predictions` is an array of objects describing each detected face, for example:
[{topLeft: [232.28, 145.26],bottomRight: [449.75, 308.36],probability: [0.998],landmarks: [[295.13, 177.64], // 右眼睛的坐标[382.32, 175.56], // 左眼睛的坐标[341.18, 205.03], // 鼻子的坐标[345.12, 250.61], // 嘴巴的坐标[252.76, 211.37], // 右耳朵的坐标[431.20, 204.93] // 左耳朵的坐标]}
]
*/
第三步: 计算每个人眼睛的大小
在第二步中,我们已经获取了每个人眼睛的坐标位置。接下来我们需要计算眼睛的大小,仔细的小伙伴可能已经发现,模型分析的数据中,并没有提供眼睛大小的属性,那么我们如何判断眼睛的大小呢?
上文的图3中,我们可以看出眼睛的坐标均是下眼皮,鼻子坐标是鼻尖、嘴巴的位置是中心点,而且都存在一定偏移,仔细观察我们发现,角度也会影响眼睛的大小,但是有个共同的现象就是,边界到眼睛的高度,在往下偏移这个高度的一半,大概就是眼睛的位置。因此眼睛的大小 = 眼睛的 Y 坐标 - 上边界的 Y 坐标。
for (let i = 0; i < predictions.length; i++) {const start = predictions[i].topLeft;const end = predictions[i].bottomRight;const size = [end[0] - start[0], end[1] - start[1]];const rightEyeP = predictions[i].landmarks[0];const leftEyeP = predictions[i].landmarks[1];// 眼睛的大小const fontSize = rightEyeP[1] - start[1];context.font = `${fontSize}px/${fontSize}px serif`;
}
第四步:canvas 中绘制图像以及 💗
由于这里我们使用的是贴图的方式,因此我们需要先绘制原始图像,然后在眼睛的位置,通过 CanvasRenderingContext2D.fillText() 的方式,将我们的 💗 绘制上去,这里我们也可以使用图片的方式,看大家喜欢,我觉得文本更快,因为图片需要加载 😛。
// 此处省略绘制原图的步骤,详情查看源码
// ...
// 遍历人脸信息数组
for (let i = 0; i < predictions.length; i++) {const start = predictions[i].topLeft;const end = predictions[i].bottomRight;const size = [end[0] - start[0], end[1] - start[1]];const rightEyeP = predictions[i].landmarks[0];const leftEyeP = predictions[i].landmarks[1];// 看见爱情const fontSize = rightEyeP[1] - start[1];context.font = `${fontSize}px/${fontSize}px serif`;context.fillStyle = 'red';context.fillText('❤️', rightEyeP[0] - fontSize / 2, rightEyeP[1]);context.fillText('❤️', leftEyeP[0] - fontSize / 2, leftEyeP[1]);
}
源码双手奉上,是不是迫不及待试一试呢?不用急,下面我还提供了一些其他有趣的 DEMO,别忘了点赞、收藏哦。
进阶
本文只是讲解一些入门的图像处理技术,高度的图像处理,远比我们想象的负责的多,同时也有需要相关的算法,感兴趣的小伙伴,可以去查阅相关的资料文档。比如,可以百度一些 图像跟踪算法、图像处理算法、二值化、265色转灰色等等。
此外我想通过分享几个 DMEO,以及实现分享,从点到面帮助大家巩固一下。
防疫达人
疫情来势汹汹,却迟迟不走,炎炎夏日想必大家戴口罩都被闷坏了吧,不如我来给你们加一个无形的口罩。是干就干,找一个没有背景颜色的口罩 PNG,下面就可以开始我们的表演了。
步骤:
- 通过模型获取嘴巴的位置
- 计算嘴巴的宽度
- canvas 中绘制图像以及口罩
分析:
- 口罩是一张图片,需要通过 CanvasRenderingContext2D.drawImage() 方法绘制
- 口罩的中心点约等于嘴巴中心点
for (let i = 0; i < predictions.length; i++) {const start = predictions[i].topLeft;const end = predictions[i].bottomRight;const size = [end[0] - start[0], end[1] - start[1]];const rightEyeP = predictions[i].landmarks[0];const leftEyeP = predictions[i].landmarks[1];const noseP = predictions[i].landmarks[2];const mouseP = predictions[i].landmarks[3];const rightEarP = predictions[i].landmarks[4];const leftEarP = predictions[i].landmarks[5];// 防疫达人const image = new Image();image.src = "./assets/images/mouthMask.png";image.onload = function() {const top = noseP[1] - start[1];const left = start[0];// 嘴巴为中心点,一半上面一半下面context.drawImage(image, mouseP[0] - size[0] / 2, mouseP[1] - size[1] / 2, size[0], size[1]);}
}
源码
烈焰红唇
步骤:
- 通过模型获取嘴巴的位置
- 计算嘴巴的宽度
- canvas 中绘制图像以及 👄
分析:
同样,模型并没有返回嘴巴大小,而且每个人嘴巴大小都不一样,举一反三,冷静分析,试图找到突破口:
- 鼻子和嘴巴可能在同一条Y轴
- 耳朵的宽度不可能是嘴巴的高度
- 眼睛的宽度?嘴巴的高度?
[灵光一闪],对,眼睛的宽度貌似跟嘴巴的宽度差不多,于是,我将好奇的目光投向了我的同事,我从左手边的柜子中,拿出来一筒没开封的可比克薯片,经过观察我发现:只要不张嘴,他们的嘴巴约等于眼睛之间的宽度,当然也有个别特例,不过不影响我断定,这应该就是黄金比例吧。
于是乎,有了以下的代码:
for (let i = 0; i < predictions.length; i++) {const start = predictions[i].topLeft;const end = predictions[i].bottomRight;const size = [end[0] - start[0], end[1] - start[1]];const rightEyeP = predictions[i].landmarks[0];const leftEyeP = predictions[i].landmarks[1];// 加个烈焰红唇// 嘴巴大概是眼睛之前的宽度const fontSize = Math.abs(rightEyeP[0] - leftEyeP[0]);context.font = `${fontSize}px/${fontSize}px serif`;context.fillStyle = 'red';context.fillText('👄', mouseP[0] - fontSize / 2, mouseP[1] + fontSize / 2);
}
源码
视频处理
之前都是介绍图片的处理方式,其实视频的处理方式是一样的,不同的是,图片只要绘制一次,但是视频,我们需要将视频的每一帧(图片)都绘制出来,然后再进行二次处理。
分析:
- canvas 的大小等于视频的大小,视频的大小需要
onload之后才能获取 - 我们需要对视频的每一帧进行处理,由于是循环处理,所有我们可能需要使用到
setTimeout、setInterval或者requestAnimationFrame来实现,明显 setInterval 不适合,另外,如果数据量庞大,setTimeout可能会影响响应速度,因此我们需要选用requestAnimationFrame来循环处理。
步骤:
- 加载视频
- 视频加载成功,初始化 canvas
- 初始化完成,加载 AI 模型
- 处理视频的每一帧
源码
技术知识总结
TensorFlow.js 是 Google 开源机器学习平台针对 JavaScript 开发的库,简称 tfjs。
我们使用了 tfjs 提供的人脸检测模型 Blazeface detector。
Blazeface detector 提供了两个方法,均返回 Promise 对象:
- load 方法,用于加载模型
需要从 tensor flow hub 获取到最新的模型,因此需要安全上网,不能安全上网的小伙伴,开源找一找是否有镜像地址,通过改变本地 host 来映射到镜像地址 - estimateFaces 用于检测人脸信息
检测所有人脸的信息,返回一个数组,数组中每一个元素都代表一个人的人脸信息,包含人脸边界信息、五官位置。
另外,我们还运用到 canvas 的一些基础常识,CanvasRenderingContext2D.fillText() 、CanvasRenderingContext2D.drawImage() 。
课后作业
朋友们,给自己戴一副 🕶️怎么样?
下面小伙伴们可以把自己的作品发送给我邮箱 也可以 github 上发起 Pull requests,审核通过将会收录至我的 Demo 中哦。
如果觉得我的文章有意思,请评论留言,告诉我你的想法和意见吧。
问题收集
- DEMO 没有效果?
- ⚠️ 需要科学上网,因为 model 需要从 TFHUB 上加载,未来有望可以自己选择从哪加载模型(先已接受提案)。
- 本地使用 nginx 、python、node-server 起一个本地服务,防止资源跨域(有些资源需要从本地获取)
- 如果是采集 detect-video 或者 camera 请先检查是否有本地摄像头,如果没有,请使用项目提供的 MP4 进行测试。
- 其他问题
- 等你来提
相关链接
- 一篇前端图像处理秘籍
- TensorFlow JavaScript 模型
- Blazeface detector