传送门:原论文连接
一、论文简介
本论文是Google在2013的SIGCOMM上发表的一篇关于其成功部署的基于SDN的B4系统的论文。其中介绍了B4的设计,以及在实际运行过程中的一些经验。本论文的参考价值在于,它是第一篇对于成功部署全球性的SDN系统的总结,对我们理解和实际的SDN部署有很好的指导作用。
二、B4特性
1)大量的带宽需求部署到少量的站点。
2)弹性流量要求寻求最大化平均带宽。
3)对边缘服务器和网络进行全面控制,实现边缘速率限制和需求测量。
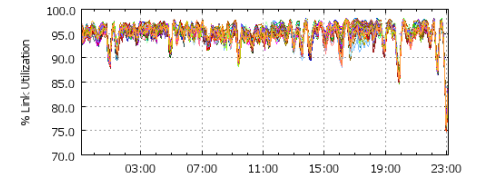
4)中心化的流量控制使得链路的利用率可以接近100%。
5) 同时支持标准的路由协议和中心化的流量控制。
6)高可应用扩展性,支持快速部署和迭代,并支持与终端应用程序紧密集成,以适应故障或通信模式变化的自适应。
7) 基于商业化的交换机硬件。
三、关键设计
1.设计思想
1)把传输失败作为寻常事件,并将影响报告给端的应用程序。
2)硬件交换机有简单的接口来编程实现中央控制下的转发表。
3)在架构上实现两个独立的广域网,面向用户的和连接数据中心的。
4)将硬件和软件进行隔离,使得软硬件发展解耦。
2.Traffic Engineering (TE)的作用
1)通过控制边缘网络来裁定竞争性请求,谁将获得有限的资源。
2)根据优先级,使用多路径的隧道来充分利用链路的带宽。
3)当连接失效或者应用需求改变时,动态重新分配带宽。
3.运行在B4上的应用类型
1)用户数据复制
2)分布式存储和运算
3)大量数据同步
4.SDN/openflow带来的好处
1) SDN基于软件的定制化控制面板,能够在普通服务器上运行,能够很好的协调计划中网络变化和意外网络改变。
2)SDN使得我们可以充分发挥高性能硬件的能力。
3)基于网线而不是路由的中心化结构。
5.B4的架构

图中的几个缩写:
1)NCS:Network Control Servers, 网络控制服务器。
2)OFC:OpenFlow controllers, OpenFlow 控制器。
3)OFA:OpenFlow Agent, OpenFlow 代理。
4)iBGP:internal Border Gateway Protocol,内部边界网关协议。
5)eBGP:external Border Gateway Protocol,外部边界网关协议。
6)TE:Traffic Engineering, 流量工程。
7)RAP:Routing Application Proxy, 应用路由代理。
8)NCAs: Network Control Applications ,网络控制应用程序。
各层之间的联系:
1)B4服务的对象是一些站点,每一个站点由若干服务器集群组成。
2)站点中交换机只做流量转发,复杂的路由控制由站点控制器完成。
3)站点控制层由网络控制器组成,包括OFC和NCAs。
4)全局控制层包含逻辑上中心化的应用,通过站点层的NCAs来实现。
5)每一个服务器站点在逻辑上都是一个自治系统,拥有一个IP前缀;每个cluster包含一个BGP路由器与B4交换机配对。
6)建立了一个集成化的中心服务,既包括路由,又包括流量工程。
7)每一个B4站点包含多路的交换线路,每个端口都连上远方的端点,所有的站点都需要被均匀的分配流量,B4通过等价路由hash来实现必须的负载均衡。
架构特性:
1)分布式路由和中心化流量工程
6.交换机设计
1)通过控制传输速率来避免使用大缓存和包丢失。
2)使用自己定制的交换机用来实现,可以使得软件和硬件相互分离,同时因为没有现成的平台支持SDN部署。
3)用16个16*10G的普通交换机实现一个128*10G的 B4交换机。
4)在交换机上直接运行路由协议。
5)用户层使用OFA来实现硬件层面的管道,OFA连接远处的OFC。
6)OFA是用来在翻译OF信息,相当于一个中间层。
7.网络控制功能
1)B4的大部分功能运行在站点控制层的NCS中。
2)帕克索斯通过单调递增的ID来标记Leader,并将其传递给客户端。
3)使用修改后的Onix来进行openflow的控制。
8.集成路由的架构

1)一些缩写
ISIS:intermedia system to intermediate system, 中间系统到中间系统。
RIP:routing information protocal,路由信息协议,一种内部网关协议。
ECMP:equal-cost multipath routing,等价路由。
NIB:network information base,个网络信息库,包括目前网络的所有状态,被Onix用来作为控制层的决策。
2)路由设计
[1]RAP是作为一个SDN应用,用来连接Quagga和底层的硬件switch,在功能上主要实现BGP/ISIS的路由信息的更新,switch和Quagga之间的路由包,接口更新。
[2]OFA用来和OFC进行通信,相当于连接了数据层和控制层。
3)RAP
[1]RAP本质上就是路由的具体实现。
[2]RAP可以将每个RIB条目翻译成两个openflow的流表。
9.流量工程

1)中心化的流量架构的组成
网络拓扑图,TE可以集成主干线路来计算点到点的边,这可以降低输入的复杂度
流集合,TE不能再应用粒度上进行操控,因此我们将FG定义为一个{源站,目站,QoS}的三元组。
隧道,所谓的隧道是一种逻辑连接。
隧道集群,把FG映射成隧道和对应的权值问题。
2)带宽函数
[1]为了捕获相对优先级,将bandwidth函数和每一个应用相互关联,具体说来就是就是根据流的优先级,维度的规模来分配带宽。
[2]bandwidth函数是根据管理员指定的权值自动推导的。
3)优化算法
[1]用线性规划的方法进行分配的代价很高,因此设计一个近似算法取得99%的效果,却在效率上提升了25倍
(4)生成隧道集群
[1]通过不断迭代来寻找瓶颈边,优先的隧道是不包含瓶颈边的,并且瓶颈边也不再参与TG的生成。
[2]算法终止条件是,每条边都满足分配或者我们不能再找到一条更好的隧道。
(5)tunnel集群的量化
[1]进行粒度分割在本质上是一个整数规划问题,由于复杂性问题,在处理时,采用的是一种启发式的方法。
10.TE 协议和Openflow
1)目标:如何在分布式,错误发生情况下实现隧道集群,隧道和流集群到openflow的转换
2)B4交换机可以扮演的角色:分流,运输,解析
外部IP是一个tunnel-ID而不是一个真正的网络IP,TE提前定义了一张表,用来进行相互的转换。
3)案例分析:

[1]根据包的头部进行分流,通过一个资源IP和母的IP,在图中就是sip,和dip
[2]整个传输过程分为两段,在B4的传输和在B4之外的传输,在B4之外的传输使用的最长前缀匹配原则。
4)TE和路由的组成
[1]TE支持最短路径路由和TE,这样当TE失效时仍然可以使用。
[2]根据openflow流表条目的优先级和硬件的容量,我们把不同的流映射成不同的硬件表。
[3]最终我们根据访问控制列表(ACL)来设置转发行为。
[4]多路径表和隧道解析表可以进行map,同样的端口由于tunnel不一样,可能最终的映射结果不一样。
5)在站点之间协调TE的状态
[1]每个控制器TDB来设置必须的关于个体的转发表,这个抽象过程将TE从硬件表中独立出来。
[2]TED以键值对的方式存储全局的隧道,隧道集群和集群。
[3]OFC将TE选项变为流编程指令。
6)依赖和失败
[1]一个条目不能被删除,除非所有引用它的都被删除了。这和数据库中依赖性是一回事。
[2]在TE和OFC之间自动同步TED的内容,首先会计算普通TED视图和TE主节点和OFC之间的差异。基于关系和进程号生成独一无二的标识。
[3]顺序问题。编号,并拒绝小号,接收大号。
[4]一个TE操作可能失败,应为远程调用可能失败,或者是OFC拒绝。标记失败的,并且定时清理。


![[转]天龙八部服务器端-共享内存的设计](http://272.img.pp.sohu.com.cn/images/msnimg/2010/12/8/9/50/1291773027606_s.jpg)