文章目录
- CharTextCNN
- 一、文件目录
- 二、语料集下载地址(本文选择AG)
- 三、数据处理(data_loader.py)
- 四、模型(chartextcnn.py)
- 五、训练和测试
- 实验结果
CharTextCNN

一、文件目录

二、语料集下载地址(本文选择AG)
AG News: https://s3.amazonaws.com/fast-ai-nlp/ag_news_csv.tgz
DBPedia: https://s3.amazonaws.com/fast-ai-nlp/dbpedia_csv.tgz
Sogou news: https://s3.amazonaws.com/fast-ai-nlp/sogou_news_csv.tgz
Yelp Review Polarity: https://s3.amazonaws.com/fast-ai-nlp/yelp_review_polarity_csv.tgz
Yelp Review Full: https://s3.amazonaws.com/fast-ai-nlp/yelp_review_full_csv.tgz
Yahoo! Answers: https://s3.amazonaws.com/fast-ai-nlp/yahoo_answers_csv.tgz
Amazon Review Full: https://s3.amazonaws.com/fast-ai-nlp/amazon_review_full_csv.tgz
Amazon Review Polarity: https://s3.amazonaws.com/fast-ai-nlp/amazon_review_polarity_csv.tgz
三、数据处理(data_loader.py)
1.数据集加载
2.读取标签和数据
3.读取所有的字符
4.将句子ont-hot表示
import os
import torch
import json
import csv
import numpy as np
from torch.utils import dataclass AG_Data(data.DataLoader):def __init__(self,data_path,l0=1014):self.path = os.path.abspath('.')if "data" not in self.path:self.path +="/data"self.data_path = data_pathself.l0 = l0self.load_Alphabet()self.load(self.data_path)# 读取所有字符def load_Alphabet(self):with open(self.path+"/alphabet.json") as f:self.alphabet = "".join(json.load(f))# 下载数据,读取标签和数据def load(self, data_path,lowercase=True):self.label = []self.data = []# 数据集加载with open(self.path+data_path,"r") as f:# 默认读写用逗号做分隔符(delimiter),双引号作引用符(quotechar)datas = list(csv.reader(f, delimiter=',', quotechar='"'))for row in datas:self.label.append(int(row[0]) - 1)txt = " ".join(row[1:])if lowercase:txt = txt.lower()self.data.append(txt)self.y = self.label# 句子one-hot表示,X:batch_size*字符one-hot表示(feature)*句子中字符个数(length=1014),Y:标签def __getitem__(self, idx):X = self.oneHotEncode(idx)y = self.y[idx]return X, ydef oneHotEncode(self, idx):X = np.zeros([len(self.alphabet),self.l0])for index_char, char in enumerate(self.data[idx][::-1]):if self.char2Index(char) != -1:X[self.char2Index(char)][index_char] = 1.0return X# 返回字符的下标,字符存在输出下标,不存在输出-1.def char2Index(self,char):return self.alphabet.find(char)# 读取标签长度def __len__(self):return len(self.label)
四、模型(chartextcnn.py)

每层前都进行归一化:

import torch
import torch.nn as nn
import numpy as np
class CharTextCNN(nn.Module):def __init__(self,config):super(CharTextCNN,self).__init__()in_features = [config.char_num] + config.features[0:-1]out_features = config.featureskernel_sizes = config.kernel_sizesself.convs = []# bs*70*1014self.conv1 = nn.Sequential(nn.Conv1d(in_features[0], out_features[0], kernel_size=kernel_sizes[0], stride=1), # 一维卷积nn.BatchNorm1d(out_features[0]), # bn层nn.ReLU(), # relu激活函数层nn.MaxPool1d(kernel_size=3, stride=3) #一维池化层) # 卷积+bn+relu+pooling模块self.conv2 = nn.Sequential(nn.Conv1d(in_features[1], out_features[1], kernel_size=kernel_sizes[1], stride=1),nn.BatchNorm1d(out_features[1]),nn.ReLU(),nn.MaxPool1d(kernel_size=3, stride=3))self.conv3 = nn.Sequential(nn.Conv1d(in_features[2], out_features[2], kernel_size=kernel_sizes[2], stride=1),nn.BatchNorm1d(out_features[2]),nn.ReLU())self.conv4 = nn.Sequential(nn.Conv1d(in_features[3], out_features[3], kernel_size=kernel_sizes[3], stride=1),nn.BatchNorm1d(out_features[3]),nn.ReLU())self.conv5 = nn.Sequential(nn.Conv1d(in_features[4], out_features[4], kernel_size=kernel_sizes[4], stride=1),nn.BatchNorm1d(out_features[4]),nn.ReLU())self.conv6 = nn.Sequential(nn.Conv1d(in_features[5], out_features[5], kernel_size=kernel_sizes[5], stride=1),nn.BatchNorm1d(out_features[5]),nn.ReLU(),nn.MaxPool1d(kernel_size=3, stride=3))self.fc1 = nn.Sequential(nn.Linear(8704, 1024), # 全连接层 #((l0-96)/27)*256nn.ReLU(),nn.Dropout(p=config.dropout) # dropout层) # 全连接+relu+dropout模块self.fc2 = nn.Sequential(nn.Linear(1024, 1024),nn.ReLU(),nn.Dropout(p=config.dropout))self.fc3 = nn.Linear(1024, config.num_classes)def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = self.conv4(x)x = self.conv5(x)x = self.conv6(x)x = x.view(x.size(0), -1) # 变成二维送进全连接层x = self.fc1(x)x = self.fc2(x)x = self.fc3(x)return x
五、训练和测试
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.optim as optim
from model import CharTextCNN
from data import AG_Data
from tqdm import tqdm
import numpy as np
import config as argumentparser
config = argumentparser.ArgumentParser() # 读入参数设置
config.features = list(map(int,config.features.split(","))) # 将features用,分割,并且转成int
config.kernel_sizes = list(map(int,config.kernel_sizes.split(","))) # kernel_sizes,分割,并且转成int
config.pooling = list(map(int,config.pooling.split(",")))if config.gpu and torch.cuda.is_available(): # 是否使用gputorch.cuda.set_device(config.gpu)
# 导入训练集
training_set = AG_Data(data_path="/AG/train.csv",l0=config.l0)
training_iter = torch.utils.data.DataLoader(dataset=training_set,batch_size=config.batch_size,shuffle=True,num_workers=0)
# 导入测试集
test_set = AG_Data(data_path="/AG/test.csv",l0=config.l0)test_iter = torch.utils.data.DataLoader(dataset=test_set,batch_size=config.batch_size,shuffle=False,num_workers=0)
model = CharTextCNN(config) # 初始化模型
if config.cuda and torch.cuda.is_available(): # 如果使用gpu,将模型送进gpumodel.cuda()
criterion = nn.CrossEntropyLoss() # 构建loss结构
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate) #构建优化器
loss = -1
def get_test_result(data_iter,data_set):# 生成测试结果model.eval()data_loss = 0true_sample_num = 0for data, label in data_iter:if config.cuda and torch.cuda.is_available():data = data.cuda()label = label.cuda()else:data = torch.autograd.Variable(data).float()out = model(data)true_sample_num += np.sum((torch.argmax(out, 1) == label).cpu().numpy()) # 得到一个batch的预测正确的样本个数acc = true_sample_num / data_set.__len__()return data_loss,accfor epoch in range(config.epoch):model.train()process_bar = tqdm(training_iter)for data, label in process_bar:if config.cuda and torch.cuda.is_available():data = data.cuda() # 如果使用gpu,将数据送进goulabel = label.cuda()else:data = torch.autograd.Variable(data).float()label = torch.autograd.Variable(label).squeeze()out = model(data)loss_now = criterion(out, autograd.Variable(label.long()))if loss == -1:loss = loss_now.data.item()else:loss = 0.95 * loss + 0.05 * loss_now.data.item() # 平滑操作process_bar.set_postfix(loss=loss_now.data.item()) # 输出loss,实时监测loss的大小process_bar.update()optimizer.zero_grad() # 梯度更新loss_now.backward()optimizer.step()test_loss, test_acc = get_test_result(test_iter, test_set)print("The test acc is: %.5f" % test_acc)
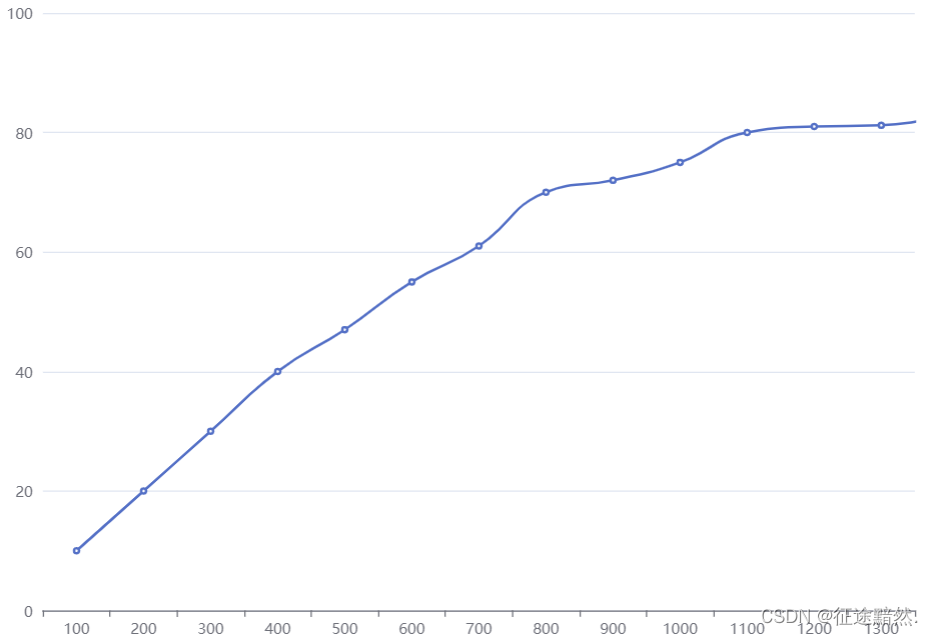
实验结果
输出测试集准确率:

![[NOI2009] 描边](https://img-blog.csdnimg.cn/img_convert/bea20425d2d855aa931211e2cee53f33.png)