目录
一、Tomcat的相关知识
1)Tomcat的简介
2)Tomcat的组件构成
3)Tomcat的功能组件结构
4)Tomcat的请求过程
二、Tomcat服务的部署
步骤一:搭建Tomcat运行环境
(1)关闭防火墙和selinux,防止其对安装过程的干扰
(2)将准备好的软件包拖入/opt目录下,进行安装
(3)设置jdk的环境变量
(4)编写一个java 简易的源代码,进行环境测试
步骤二:安装启动tomcat
(1)安装Tomcat
(2)启动Tomcat
(3)开启tomcat服务,测试访问tomcat的默认首页
Tomcat服务使用拓展:优化启动速度
该方法的原理说明:
拓展: Linux中的熵
三、Tomcat的虚拟主机配置
1)实验目的
2)实验前准备
3)实验步骤
(1)创建 yang 和 wang 项目目录和文件
(2)修改 Tomcat 主配置文件 server.xml
(3)重启Tomcat服务
(4) 进行本地域名IP映射导入 ,测试访问
四、Tomcat的优化
1)内核优化
例如:
永久配置:
2)Tomcat配置文件参数优化
常用设置:
3)Tomcat 配置 JVM 参数
一、Tomcat的相关知识
1)Tomcat的简介
Tomcat 是 Java 语言开发的,Tomcat 服务器是一个免费的开放源代码的 Web 应用服务器,是 Apache 软件基金会的 Jakarta 项目中的一个核心项目,由 Apache、Sun 和其他一些公司及个人共同开发而成
Tomcat 属于轻量级应用服务器,在中小型系统和并发访问用户(据了解tomcat的并发量处理能力是nginx的六分之一)不是很多的场合下被普遍使用,是开发和调试 JSP 程序的首选。一般来说,Tomcat 虽然和 Apache 或者 Nginx 这些 Web 服务器一样,具有处理 HTML 页面的功能,然而由于其处理静态 HTML 的能力远不及 Apache 或者 Nginx,所以 Tomcat 通常是作为一个 Servlet 和 JSP 容器,单独运行在后端

2)Tomcat的组件构成
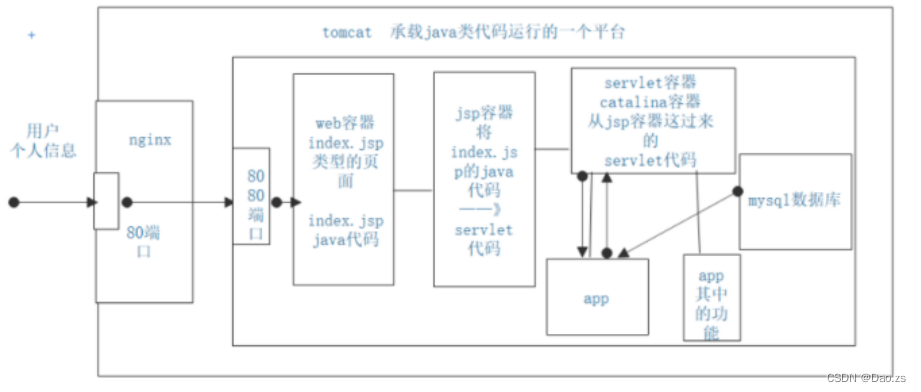
- Web 容器:完成 Web 服务器的功能
- Servlet 容器:名字为 catalina,用于处理 Servlet 代码
- JSP 容器:用于将 JSP 动态网页翻译成 Servlet 代码
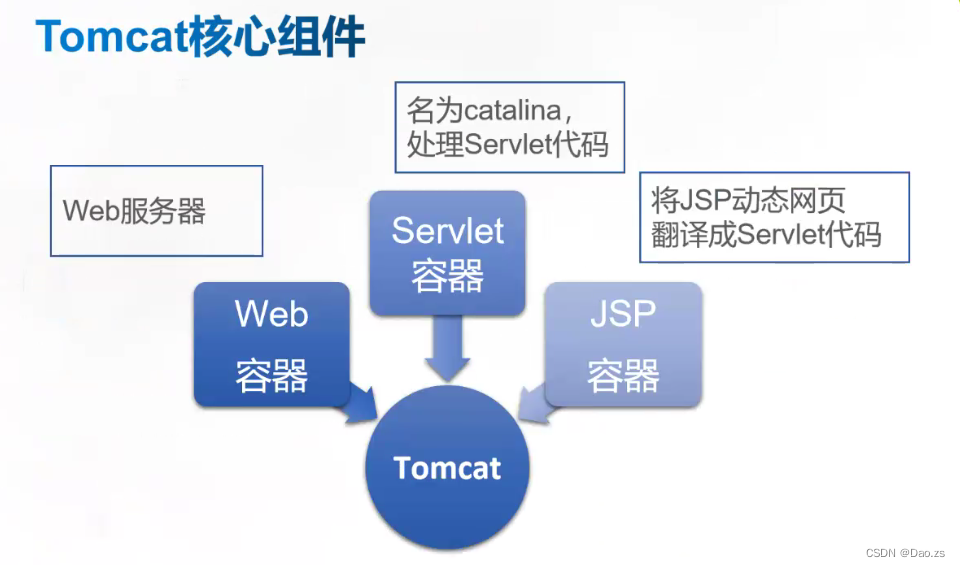
Tomcat 是 Web 应用服务器,也是一个 Servlet/JSP 容器。Tomcat 作为 Servlet 容器,负责处理客户的.jsp动态页面的请求,把请求传送给 Servlet,并将 Servlet 的响应传送回给客户
Servlet :是Java Servlet 的简称,可以理解为是一个服务连接器,是用 Java 编写的服务器端程序,具有独立于平台和协议的特性
简单的理解:servlet 就是一个中间件,包含了接口和方法,将客户端和数据库连接,从而实现动态网页的创建。
JSP: 全称 Java Server Pages,是一种动态网页开发技术。它使用 JSP 标签在HTML网页中插入 Java 代码。标签通常以 <% 开头,以 %> 结束。也是一种 Java servlet,主要用于实现 Java web 应用程序的用户界面部分。
JSP 通过网页表单获取用户输入数据、访问数据库及其他数据源,然后动态地创建网页
3)Tomcat的功能组件结构
Tomcat 的核心功能有两个,分别是负责接收和反馈外部请求的连接器 Connector,和负责处理请求的容器 Container。 其中连接器和容器相辅相成,一起构成了基本的 web 服务 Service。每个 Tomcat 服务器可以管理多个 Service

Service:对外提供的 Web 服务。主要包含 Connector 和 Container 两个核心组件,以及其他功能组件。Tomcat 可以管理多个 Service,且各 Service 之间相互独立
- Connector:负责对外接收和响应请求。它是Tomcat与外界的交通枢纽,监听端口接收外界请求,并将请求处理后传递给容器做业务处理,最后将容器处理后的结果响应给外界。
- Container:负责对内处理业务逻辑。其内部由 Engine、Host、Context和Wrapper 四个容器组成,用于管理和调用 Servlet 相关逻辑
Container 结构分析:
每个 Service 会包含一个 Container 容器。在 Container 内部包含了 4 个子容器,4个子容器的作用分别是:
- Engine:引擎,用来管理多个虚拟主机,一个 Service 最多只能有一个 Engine
- Host:代表一个虚拟主机,也可以叫站点,通过配置 Host 就可以添加站点
- Context:代表一个 Web 应用,包含多个 Servlet 封装器
- Wrapper:封装器,容器的最底层。每一 Wrapper 封装着一个 Servlet,负责对象实例的创建、执行和销毁功能

Engine、Host、Context 和 Wrapper,这四个容器之间属于层层递进的父子关系
容器 由一个引擎(Engine)可以管理多个虚拟主机(Host)。每个虚拟主机(Host)可以管理多个 Web 应用(Context)。每个 Web 应用会有多个 Servlet 封装器(Wrapper)
4)Tomcat的请求过程
- 用户在浏览器中输入网址,请求被发送到本机端口 8080,被在那里监听的 Connector 获得
- Connector 把该请求交给它所在的 Service 的 Engine(Container)来处理,并等待 Engine 的回应
- 请求在 Engine、Host、Context 和 Wrapper 这四个容器之间层层调用,最后在 Servlet 中执行对应的业务逻辑、数据存储等
- 执行完之后的请求响应在 Context、Host、Engine 容器之间层层返回,最后返回给 Connector,并通过 Connector 返回给客户端
二、Tomcat服务的部署
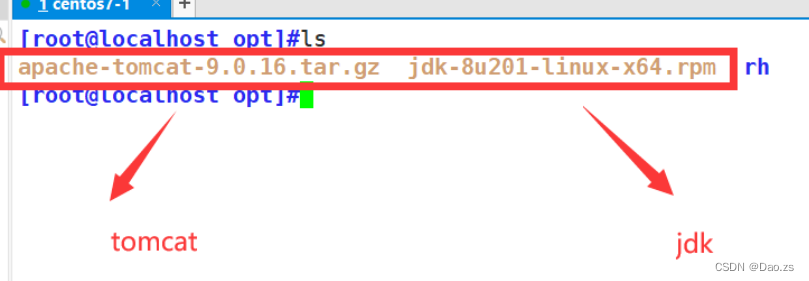
本次部署准备的版本安装包(版本根据需求):
jdk-8u201-linux-x64.rpm(jdk环境包,是tomcat的运行环境)
apache-tomcat-9.0.16.tar.gz(tomcat服务软件包)

步骤一:搭建Tomcat运行环境
(1)关闭防火墙和selinux,防止其对安装过程的干扰
systemctl stop firewalld
systemctl disable firewalld
setenforce 0(2)将准备好的软件包拖入/opt目录下,进行安装
#某rpm包尚未安装,我们可以通过该命令查询其说明信息、安装以后会生成的文件;
rpm -qpl jdk-8u201-linux-x64.rpm #安装并以#显示安装进度以及显示详细过程
rpm -ivh jdk-8u201-linux-x64.rpm #查看jdk环境
java -version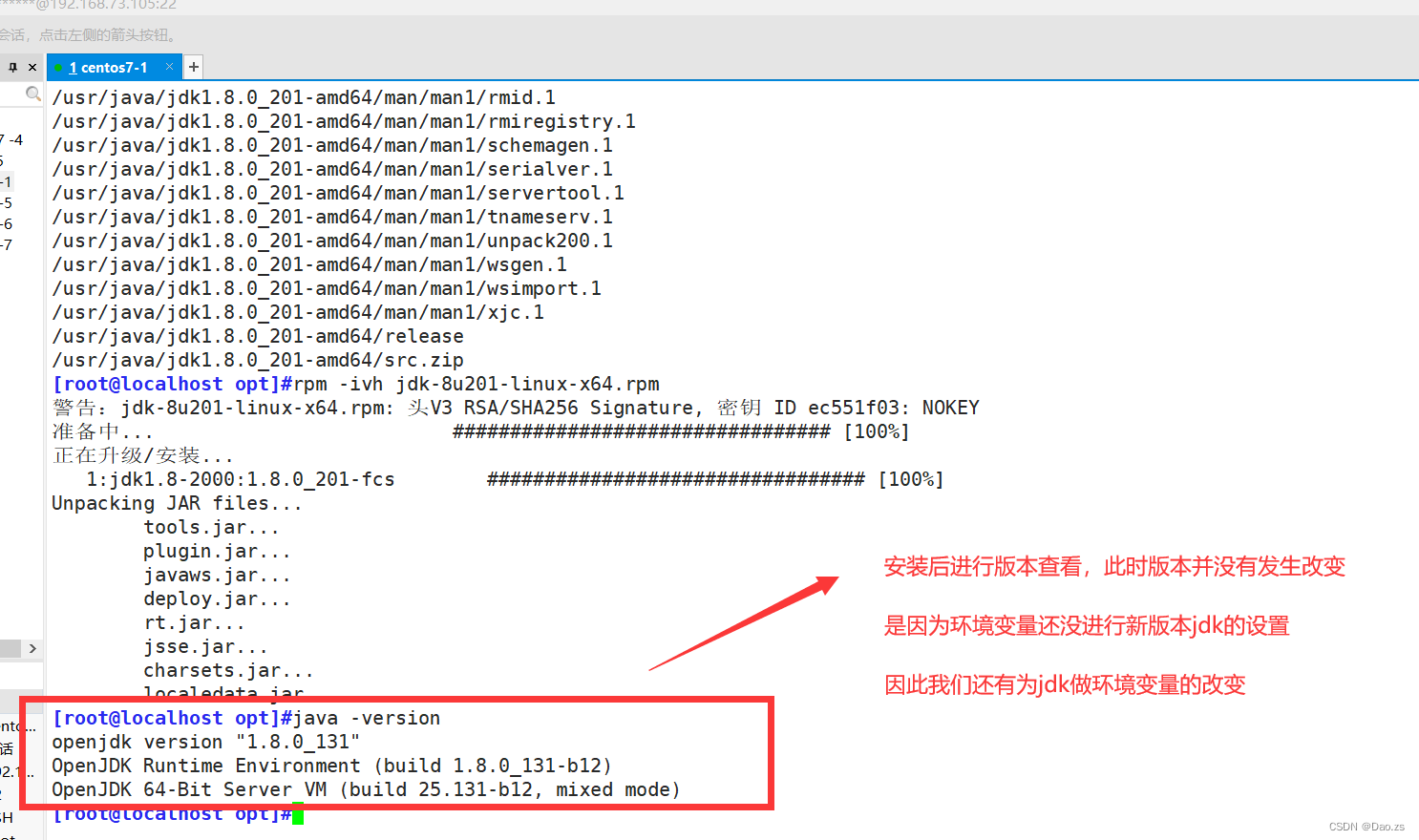
(3)设置jdk的环境变量
设置全局的环境变量,一般会有两种方式(本次部署采用第二种方式):
方式一:直接对 /etc/profile(全局变量配置文件进行改变)
方式二:在/etc/profile.d/ 目录下创建相关的 .sh 脚本,profile有默认调用的功能。(推荐使用,便于变量的管理)
vim /etc/profile.d/java.sh
export JAVA_HOME=/usr/java/jdk1.8.0_201-amd64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
拓展知识:
- CLASSPATH:编译、运行Java程序时,JRE会去该变量指定的路径中搜索所需的类(.class)文件
- JDK:java development kit (java开发工具)
- JRE:java runtime environment (java运行时环境)
- JVM:java virtuak machine (java虚拟机),使java程序可以在多种平台上运行class文件
source /etc/profile.d/java.sh
java -version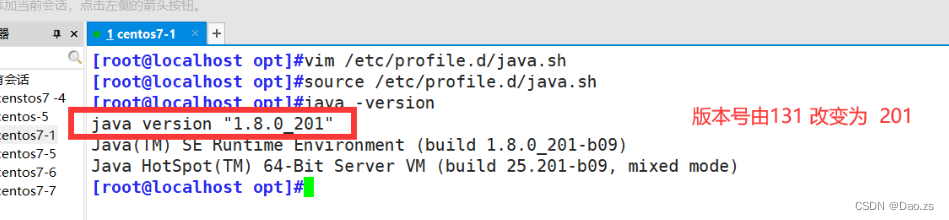
(4)编写一个java 简易的源代码,进行环境测试
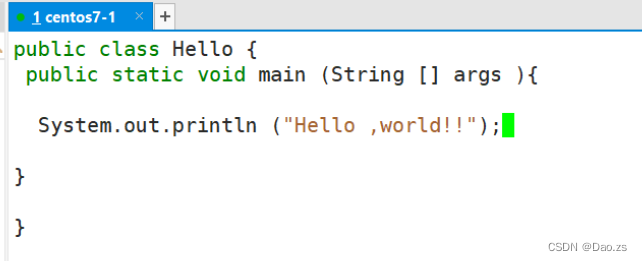
vim Hello.java
#类名、接口名命令:英文大小写字母、数字字符、$和_,不能使用关键字和数字开头;
一个单词命名时第一个单词的首字母要大写;多单词组成时,所有单词的首字母大写:XxxYyyZzz(大驼峰命名法)
public class Hello { public static void main(String[] args){System.out.println("Hello world!");}
}
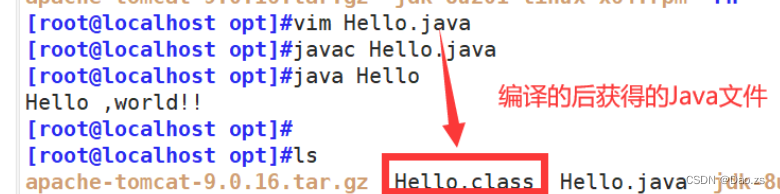
#编译源代码
javac Hello.java
#运行源代码
java Hello
步骤二:安装启动tomcat
(1)安装Tomcat
cd /opt
#解压tomcat软件包
tar zxvf apache-tomcat-9.0.16.tar.gz#移动至服务软件包统一管理目录中,并且简易其名称
mv apache-tomcat-9.0.16 /usr/local/tomcat
(2)启动Tomcat
注意:Tomcat服务启动时会占用8080端口
#后台启动
/usr/local/tomcat/bin/startup.sh
或
/usr/local/tomcat/bin/catalina.sh start 
#前台启动
/usr/local/tomcat/bin/catalina.sh run 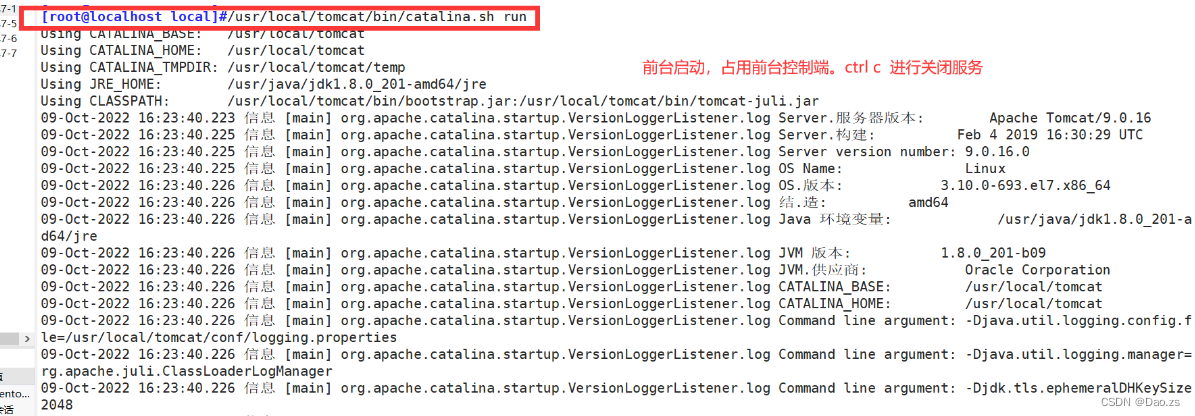
#关闭后台运行的tomcat
/usr/local/tomcat/bin/shutdown.sh vim /usr/lib/systemd/system/tomcat.service[Unit]
Description=tomcat server
Wants=network-online.target
After=network.target[Service]
Type=forking
Environment="JAVA_HOME=/usr/java/jdk1.8.0_201-amd64"
Environment="PATH=$JAVA_HOME/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin"
Environment="CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar"
ExecStart=/usr/local/tomcat/bin/startup.sh
ExecStop=/usr/local/tomcat/bin/shutdown.sh
Restart=on-failure[Install]
WantedBy=multi-user.targetsystemctl daemon-reload
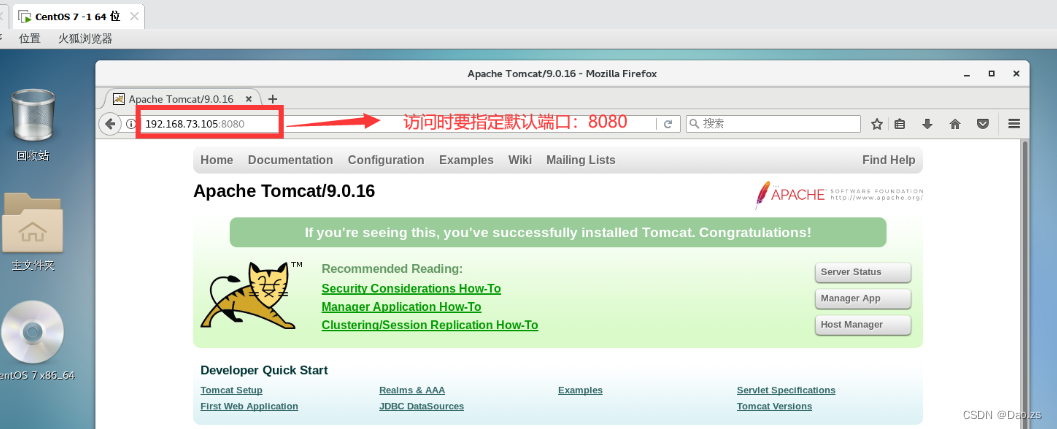
即可通过systemctl控制tomcat服务(3)开启tomcat服务,测试访问tomcat的默认首页
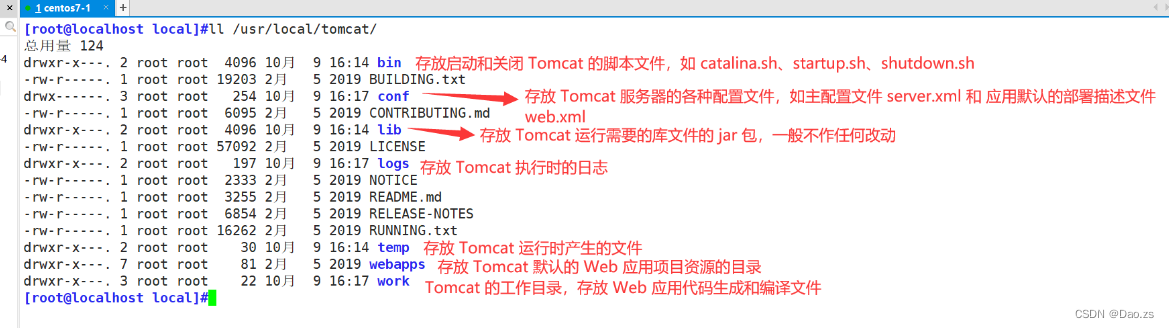
Tomcat的主要目录说明
- bin:存放启动和关闭 Tomcat 的脚本文件,如 catalina.sh、startup.sh、shutdown.sh
- conf:存放 Tomcat 服务器的各种配置文件,如主配置文件 server.xml 和 应用默认的部署描述文件 web.xml
- lib:存放 Tomcat 运行需要的库文件的 jar 包,一般不作任何改动
- logs:存放 Tomcat 执行时的日志
- temp:存放 Tomcat 运行时产生的文件
- webapps:存放 Tomcat 默认的 Web 应用项目资源的目录
- work:Tomcat 的工作目录,存放 Web 应用代码生成和编译文件
Tomcat服务使用拓展:优化启动速度
市场上依旧存在一些配置性能过低的服务器,第一次启动Tomcat时可能会发现 Tomcat 启动很慢,默认情况下可能会需要几十秒。遇到这种情况时,我们通过修改jdk参数来优化T欧美cat的启动速度
vim /usr/java/jdk1.8.0_201-amd64/jre/lib/security/java.security--117行--修改
securerandom.source=file:/dev/urandom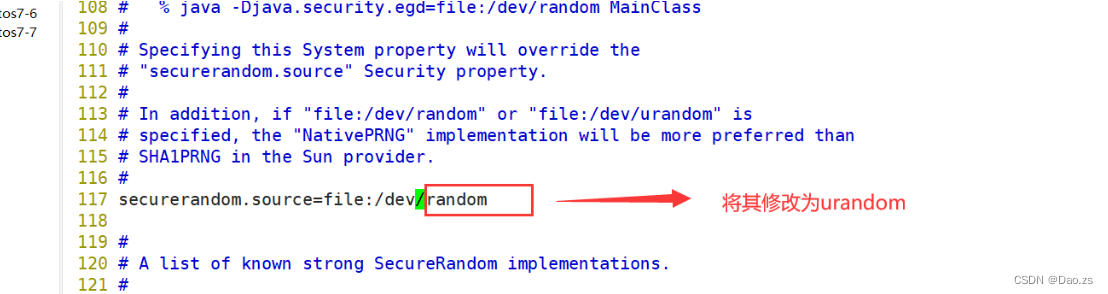
该方法的原理说明:
- tomcat 启动慢的原因是随机数(产生随机数的函数 random)产生遭到阻塞,遭到阻塞的原因是 熵池大小
- /dev/random:阻塞型,读取它就会产生随机数据,但该数据取决于熵池噪声,当熵池空了,对/dev/random 的读操作也将会被阻塞
- /dev/urandom:非阻塞的随机数产生器,它会重复使用熵池中的数据以产生伪随机数据。这表示对/dev/urandom的读取操作不会产生阻塞,但其输出的熵可能小于/dev/random的。它可以作为生成较低强度密码的伪随机数生成器,不建议用于生成高强度长期密码
拓展: Linux中的熵
Linux内核采用熵来描述数据的随机性。熵(entropy)是描述系统混乱无序程度的物理量,一个系统的熵越大则说明该系统的有序性越差,即不确定性越大。在信息学中,熵被用来表征一个符号或系统的不确定性,熵越大,表明系统所含有用信息量越少,不确定度越大。计算机本身是可预测的系统,因此,用计算机算法不可能产生真正的随机数。但是机器的环境中充满了各种各样的噪声,如硬件设备发生中断的时间,用户点击鼠标的时间间隔等是完全随机的,事先无法预测。Linux内核实现的随机数产生器正是利用系统中的这些随机噪声来产生高质量随机数序列。内核维护了一个熵池用来收集来自设备驱动程序和其它来源的环境噪音。理论上,熵池中的数据是完全随机的,可以实现产生真随机数序列。为跟踪熵池中数据的随机性,内核在将数据加入池的时候将估算数据的随机性,这个过程称作熵估算。熵估算值描述池中包含的随机数位数,其值越大表示池中数据的随机性越好
三、Tomcat的虚拟主机配置
真实生产环境会有多个项目需要运行,一般不会是在一台服务器上运行多个 Tomcat 服务,这样会消耗太多的系统资源。此时, 就需要使用到 Tomcat 虚拟主机。 Tomcat的虚拟主机最常用的设置也是基于域名。本次实验采用基于域名的虚拟主机
1)实验目的
现在新增两个域名 www.yang.com 和 www.wang.com, 希望通过这两个域名访问到不同的项目内容
2)实验前准备
搭建好相关的的jdk环境,并且保证tomcat的能够正常运行使用
3)实验步骤
(1)创建 yang 和 wang 项目目录和文件
mkdir /usr/local/tomcat/webapps/yang
mkdir /usr/local/tomcat/webapps/wang
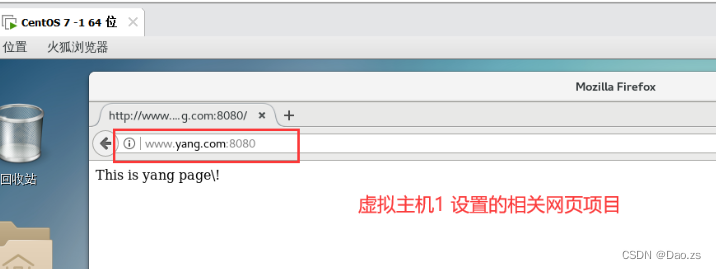
echo "This is yang page\!" > /usr/local/tomcat/webapps/yang/index.jsp
echo "This is wang page\!" > /usr/local/tomcat/webapps/wang/index.jsp
(2)修改 Tomcat 主配置文件 server.xml
vim /usr/local/tomcat/conf/server.xml
--165行前--插入
<Host name="www.yang.com" appBase="webapps" unpackWARs="true" autoDeploy="true" xmlValidation="false" xmlNamespaceAware="false"><Context docBase="/usr/local/tomcat/webapps/yang" path="" reloadable="true" />
</Host><Host name="www.wang.com" appBase="webapps" unpackWARs="true" autoDeploy="true" xmlValidation="false" xmlNamespaceAware="false"><Context docBase="/usr/local/tomcat/webapps/wang" path="" reloadable="true" />
</Host>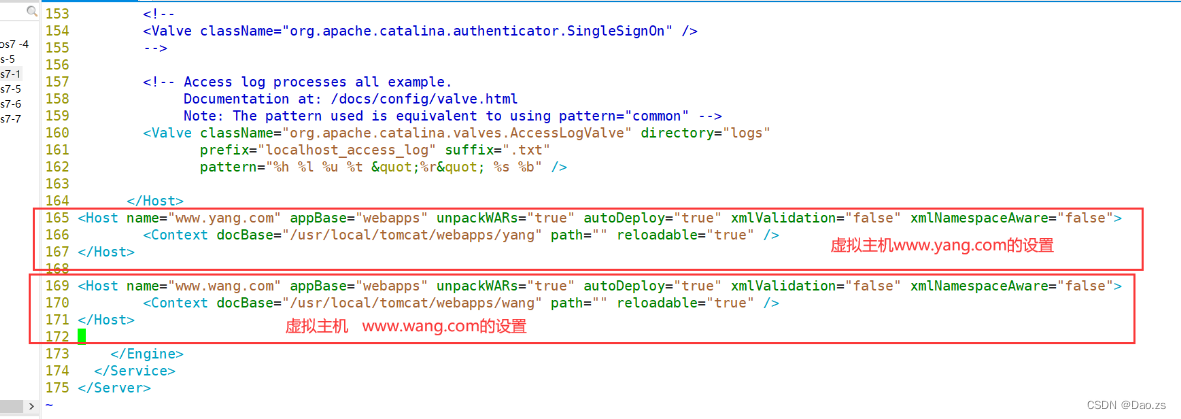
虚拟主机中的配置标签说明:
| <Host>标签中的配置项 | 作用 |
| name | 主机名 |
| appBase | Tomcat程序工作目录,即存放web应用程序的目录;相对路径为webapps,绝对路径为 /usr/local/tomcat/webapps |
| unpackWARs | 在启用此webapps时是否对WAR格式的归档文件先进行展开;默认为true |
| autoDeploy | 在Tomcat处于运行状态时放置于appBase目录中的应用程序文件是否自动进行deploy;默认为true |
| xmlValidation | 是否验证xml文件执行有效性检验的标志 |
| xmlNamespaceAware | 是否启用xml命名空间,设置该值与xmlValidation为true,表示对web.xml文件执行有效性检验 |
| <Context>标签中的配置项 | 作用 |
| docBase | 相应的Web应用程序的存放位置;也可以使用相对路径,起始路径为此Context所属Host中appBase定义的路径 |
| path | 相对于Web服务器根路径而言的URI;如果为空"",则表示为此webapp的根路径 / |
| reloadable | 是否允许重新加载此context相关的Web应用程序的类;默认为false |
HTTP 请求过程:
- Connector 连接器监听的端口是 8080。由于请求的端口和监听的端口一致,连接器接受了该请求
- 因为引擎的默认虚拟主机是 www.yang.com,并且虚拟主机的目录是webapps。所以请求找到了 tomcat/webapps 目录
- 访问的路径为根路径,URI 为空,即空是 Web 程序的应用名,也就是 context。此时请求找到 /usr/local/tomcat/webapps/yang 目录,解析 index.jsp 并返回
(3)重启Tomcat服务
#关闭Tomcat服务
/usr/local/tomcat/bin/shutdown.sh
#启动Tomcat服务
/usr/local/tomcat/bin/startup.sh(4) 进行本地域名IP映射导入 ,测试访问
echo "192.168.73.105 www.yang.com www.wang.com" >/etc/hosts

四、Tomcat的优化
Tomcat默认安装下的缺省配置并不适合生产环境,它可能会频繁出现假死现象需要重启,只有通过不断压测优化才能让它最高效率稳定的运行。(常用的网站压测工具: Apache-ab,webbench,Apache-Jemeter)
优化主要包括三方面,分别为操作系统优化(内核参数优化),Tomcat配置文件参数优化,Java虚拟机(JVM)调优
1)内核优化
Linux内核优化中主要针对两个配置文件 /etc/security/limits.conf 和/etc/sysctl.conf
通常是利用调用内核参数的程序sysctl -a 查询出最优内核参数,然后写入 /etc/sysctl.conf 文件内的
例如:
sysctl -a |grep fs.file-max
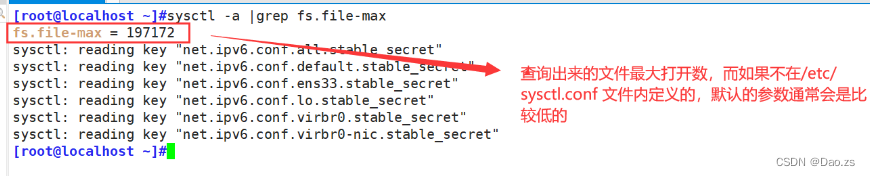
在得到该数据后我们可以将此 添加到 /etc/sysctl.conf 的配置文件中,从而改变最大的文件打开数。但是file-max 表示系统级别的能够打开的文件句柄的数量。是对整个系统的限制,并不是针对用户的
ulimit -n (临时设置)控制进程级别能够打开的文件句柄的数量。提供对shell及其启动的进程的可用文件句柄的控制。这是进程级别的。(通过 ulimit -a 可以查看到打开的文件句柄数量)
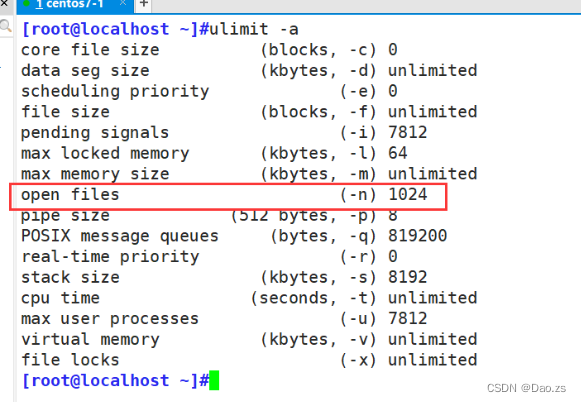
永久配置:
注意:设置保存后,需要重新ssh连接才会看到配置更改的变化
vim /etc/security/limits.conf
# 65535 为Linux系统最大打开文件数
* soft nproc 65535
* hard nproc 65535
* soft nofile 65535
* hard nofile 65535其他调试内核参数的查看:
sysctl -akernel.sysrq = 0
kernel.core_uses_pid = 1
kernel.msgmnb = 65536#默认为16384,调高
kernel.msgmax = 65536#默认为16384,调高
kernel.shmmax = 68719476736#以sctl -a实际查询出的为准
kernel.shmall = 4294967296#以sctl -a实际查询出的为准
net.ipv4.ip_forward = 0#0是关闭路由转发。VPN告别了,也是系统默认的值。所谓转发即当主机拥有多于一块的网卡时,其中一块收到数据包,根据数据包的目的ip地址将数据包发往本机另一块网卡,该网卡根据路由表继续发送数据包。这通常是路由器所要实现的功能,现在如果改成1,内核就可以做路由器的这个事了。
net.ipv4.conf.default.rp_filter = 0#和下面这一条一对的,开启网卡多播功能,0不是特别安全。
net.ipv4.conf.all.rp_filter = 0#reverse-path filtering,反向过滤技术,系统在接收到一个IP包后,检查该IP是否是合乎要求,不合要求的IP包会被系统丢弃。该技术就称为rp filter。0表示不启用该技术
net.ipv4.icmp_echo_ignore_all = 0 #忽略ICMP请求。出于安全考虑,建议开启此项(当前默认值为0,开启将值设为1)。但开启后会忽略所有接收到的icmp echo请求的包(会导致机器无法ping通),建议用户根据实际组网场景决定是否开启此项。也就是0可以被ping,1禁止被ping
net.ipv4.icmp_echo_ignore_broadcasts#和上一条一对的 系统忽略所有广播和多播地址的ICMP回显和时间戳记请求
net.ipv4.conf.default.accept_source_route = 0#
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_tw_buckets = 6000
net.ipv4.tcp_sack = 1#是否启用有选择的应答(Selective Acknowledgment),这可以通过有选择地应答乱序接收到的报文来提高性能(这样可以让发送者只发送丢失的报文段);(对于广域网通信来说)这个选项应该启用,但是这会增加对 CPU 的占用,一般是1,如果CPU扛不住那就0吧
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_rmem = 10240 87380 12582912#默认值的两倍TCP读取缓冲区,单位为字节,查看默认值
net.ipv4.tcp_wmem = 10240 87380 12582912#默认值的两倍发送缓冲区,和本机内存大小有关,谨慎修改
net.ipv4.tcp_mem = 94500000 915000000 927000000
net.core.wmem_default = 8388608#照着改
net.core.rmem_default = 8388608
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.netdev_max_backlog = 262144
net.core.somaxconn = 40960
net.ipv4.tcp_max_orphans = 3276800
net.ipv4.tcp_max_syn_backlog = 262144
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_synack_retries = 1 #可适当提高到2
net.ipv4.tcp_syn_retries = 1 #可适当提高到2
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 1
net.ipv4.tcp_keepalive_time = 30
net.ipv4.ip_local_port_range = 1024 65000#不默认也可以
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.netfilter.nf_conntrack_max = 6553500
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_established = 3600
net.nf_conntrack_max = 6553500
vm.overcommit_memory = 0#当linux发现内存不足时,会发生OOM killer(OOM=out-of-memory)。它会选择杀死一些进程(用户态进程,不是内核线程),以便释放内存。0是安全稳定,如果是1,表示即使内存耗尽也不杀死任何进程,如果是2,表示即使物理内存和swap都用完了,服务器也死战到底。
vm.swappiness = 0fs.file-max = 999999:这个参数表示进程(比如一个worker进程)可以同时打开的最大句柄数,这个参数直线限制最大并发连接数,需根据实际情况配置。net.ipv4.tcp_max_tw_buckets = 6000 #这个参数表示操作系统允许TIME_WAIT套接字数量的最大值,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息。该参数默认为180000,过多的TIME_WAIT套接字会使Web服务器变慢。注意:主动关闭连接的服务端会产生TIME_WAIT状态的连接net.ipv4.ip_local_port_range = 1024 65000 #允许系统打开的端口范围。net.ipv4.tcp_tw_recycle = 1 #启用timewait快速回收。和下面这个是一对net.ipv4.tcp_tw_reuse = 1 #开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接。这对于服务器来说很有意义,因为服务器上总会有大量TIME-WAIT状态的连接。net.ipv4.tcp_keepalive_time = 30:这个参数表示当keepalive启用时,TCP发送keepalive消息的频度。默认是2小时,若将其设置的小一些,可以更快地清理无效的连接(不是说的软件keepalive,是比如nginx的 keepalive参数)。net.ipv4.tcp_syncookies = 1 #开启SYN Cookies,当出现SYN等待队列溢出时,启用cookies来处理。net.core.somaxconn = 40960 #web 应用中 listen 函数的 backlog 默认会给我们内核参数的 net.core.somaxconn 限制到128,而nginx定义的NGX_LISTEN_BACKLOG 默认为511,所以有必要调整这个值。注:对于一个TCP连接,Server与Client需要通过三次握手来建立网络连接.当三次握手成功后,我们可以看到端口的状态由LISTEN转变为ESTABLISHED,接着这条链路上就可以开始传送数据了.每一个处于监听(Listen)状态的端口,都有自己的监听队列.监听队列的长度与如somaxconn参数和使用该端口的程序中listen()函数有关somaxconn参数:定义了系统中每一个端口最大的监听队列的长度,这是个全局的参数,默认值为128,对于一个经常处理新连接的高负载 web服务环境来说,默认的 128 太小了。大多数环境这个值建议增加到 1024 或者更多。大的侦听队列对防止拒绝服务 DoS 攻击也会有所帮助。net.core.netdev_max_backlog = 262144 #每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。net.ipv4.tcp_max_syn_backlog = 262144#这个参数标示TCP三次握手建立阶段接受SYN请求队列的最大长度,默认为1024,将其设置得大一些可以使出现Nginx繁忙来不及accept新连接的情况时,Linux不至于丢失客户端发起的连接请求。net.ipv4.tcp_rmem = 10240 87380 12582912#这个参数定义了TCP接受缓存(用于TCP接受滑动窗口)的最小值、默认值、最大值。
net.ipv4.tcp_wmem = 10240 87380 12582912:这个参数定义了TCP发送缓存(用于TCP发送滑动窗口)的最小值、默认值、最大值。
net.core.rmem_default = 6291456:这个参数表示内核套接字接受缓存区默认的大小。
net.core.wmem_default = 6291456:这个参数表示内核套接字发送缓存区默认的大小。
net.core.rmem_max = 12582912:这个参数表示内核套接字接受缓存区的最大大小。
net.core.wmem_max = 12582912:这个参数表示内核套接字发送缓存区的最大大小。
net.ipv4.tcp_syncookies = 1:该参数与性能无关,用于解决TCP的SYN攻击。查看线程的方法:
ps -aT2)Tomcat配置文件参数优化
常用设置:
vim /usr/local/tomcat/conf/server.xml
......
<Connector port="8080" protocol="HTTP/11.1"
connectionTimeout="20000"
redirectPort="8443"
--71行--插入
minSpareThreads="50"
enableLookups="false"
disableUploadTimeout="true"
acceptCount="300"
maxThreads="500"
processorCache="500"
URIEncoding="UTF-8"
maxKeepAliveRequests="100"
compression="on"
compressionMinSize="2048"
compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain,image/gif,image /jpg,image/png"/>常用的优化相关参数如下:
【redirectPort】如果某连接器支持的协议是HTTP,当接收客户端发来的HTTPS请求时,则转发至此属性定义的 8443 端口。【maxThreads】Tomcat使用线程来处理接收的每个请求,这个值表示Tomcat可创建的最大的线程数,即支持的最大并发连接数,默认值是 200。【minSpareThreads】最小空闲线程数,Tomcat 启动时的初始化的线程数,表示即使没有人使用也开这么多空线程等待,默认值是 10。【maxSpareThreads】最大备用线程数,一旦创建的线程超过这个值,Tomcat就会关闭不再需要的socket线程。默认值是-1(无限制)。一般不需要指定。【processorCache】进程缓冲器,可以提升并发请求。默认值是200,如果不做限制的话可以设置为-1,一般采用maxThreads的值或者-1。【URIEncoding】指定 Tomcat 容器的 URL 编码格式,网站一般采用UTF-8作为默认编码。【connnectionTimeout】网络连接超时,单位:毫秒,设置为 0 表示永不超时,这样设置有隐患的。通常默认 20000 毫秒就可以。【enableLookups】是否反查域名,以返回远程主机的主机名,取值为:true 或 false,如果设置为 false,则直接返回 IP 地址,为了提高处理能力,应设置为 false。【disableUploadTimeout】上传时是否使用超时机制。应设置为 true。【connectionUploadTimeout】上传超时时间,毕竟文件上传可能需要消耗更多的时间,这个根据你自己的业务需要自己调,以使Servlet有较长的时间来完成它的执行,需要与上一个参数一起配合使用才会生效。【acceptCount】指定当所有可以使用的处理请求的线程数都被使用时,可传入连接请求的最大队列长度,超过这个数的请求将不予处理,默认为 100 个。【maxKeepAliveRequests】指定一个长连接的最大请求数。默认长连接是打开的,设置为1时,代表关闭长连接;为-1时,代表请求数无限制【compression】是否对响应的数据进行GZIP压缩,off:表示禁止压缩;on:表示允许压缩(文本将被压缩)、force:表示所有情况下都进行压缩,默认值为 off,压缩数据后可以有效的减少页面的大小,一般可以减小 1/3 左右,节省带宽。【compressionMinSize】表示压缩响应的最小值,只有当响应报文大小大于这个值的时候才会对报文进行压缩,如果开启了压缩功能,默认值就是 2048。【compressableMimeType】压缩类型,指定对哪些类型的文件进行数据压缩。【noCompressionUserAgents="gozilla, traviata"】对于以下的浏览器,不启用压缩
#如果已经进行了动静分离处理,静态页面和图片等数据就不需做 Tomcat 处理,也就不要在 Tomcat 中配置压缩了。3)Tomcat 配置 JVM 参数
调优环境规格以 2C4G 为例:
#配置添加在 Tomcat 的 bin 目录下 catalina.sh 里vim /usr/local/tomcat/bin/catalina.sh ########添加至 cygwin=false 前#########JAVA_OPTS="$JAVA_OPTS -server -Xms2048m -Xmx2048m -Xmn768m -XX:ParallelGCThreads=2 -XX:PermSize=1024m -XX:MaxPermSize=1024m -Djava.awt.headless=true -XX:+DisableExplicitGC"
cygwin=false
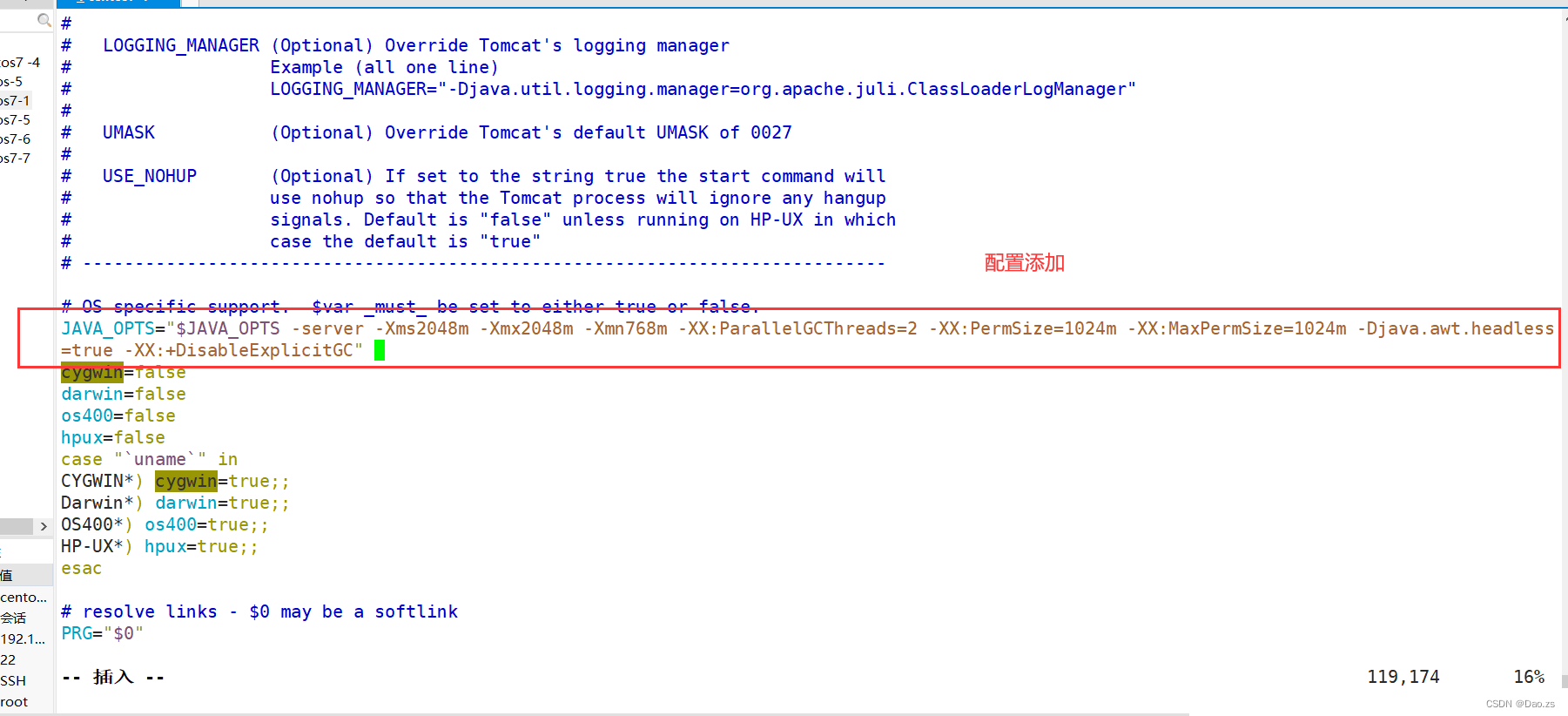
参数说明:
| 参数 | 使用说明 |
| -server | 一定要作为第一个参数,在多个CPU时性能佳 |
| -Xms | 初始Java初始化堆的大小,是分配JVM的最小内存,cpu性能高时此值应设的大一些 |
| -Xmx | 最大Java堆的大小,是分配JVM的最大内存,取决于硬件物理内存的大小,建议-Xms与-Xmx设成一样的值,均设为物理内存的一半。其目的是为了能够在java垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源 |
| -Xmn | 新生代的内存大小,官方推荐配置为整个堆的 3/8 |
其他配置参数说明:
----------------------------------------------------
●堆区进一步细化分为:新生代、中生代、老生代。
●java中每新new一个对象所占用的内存空间就是新生代的空间,当java垃圾回收机制对堆区进行资源回收后,那些新生代中没有被回收的资源将被转移到中生代,中生代的被转移到老生代。
●整个JVM堆大小 = 新生代大小 + 老生代大小 + 永久代大小
-----------------------------------------------------XX:ParallelGCThreads:配置并行收集器的线程数,即:同时有多少个线程一起进行垃圾回收,此值建议配置与 CPU 数目相等。-XX:PermSize:设置非堆内存初始值,即持久代内存大小,默认是物理内存的1/4-XX:MaxPermSize:最大非堆内存的大小,即最大持久代内存大小,默认是物理内存的1/4
----------------------------------------------------
●非堆区内存是不会被java垃圾回收机制进行处理的,且最大堆内存与最大非堆内存的和不能超出操作系统的可用内存。
●XMX和XMS设置一样大,MaxPermSize和MinPermSize设置一样大,这样可以减轻伸缩堆大小带来的压力。
-----------------------------------------------------Djava.awt.headless=true:免避在 Linux/Unix 环境下 Web 网页不能正常显示图片-XX:+DisableExplicitGC:禁止调用System.gc(),防止误调用gc方法导致系统的 JVM 大起大落而使系统响应时间严重降低。-XX:+UseParNewGC:对新生代采用多线程并行回收,缩短垃圾收集的时间-XX:+UseConcMarkSweepGC:并发标记清除收集器,它是老年代的收集算法,缩短垃圾收集的时间-XX:+CMSParallelRemarkEnabled:启用并行标记,降低标记停顿-XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0:这两个参数默认值就是这样的,表示触发FullGC时压缩堆,优化内存碎片-XX:CMSInitiatingOccupancyFraction=70:在应用程序使用70%完内存后开始CMS垃圾收集