好久不写爬虫。。。忘了个锤子。于是借着学java的机会用java写个爬虫
爬取静态页面 迅雷会员账号和密码。时时获取最新的~
先上我暑假写的python版~
:
# -*- coding: utf-8 -*-
import urllib
import re
import os
url1 = 'http://xlfans.com/'
regex = r'迅雷会员(.+?)密码(.*)<'
regex1 = r'class="item"><a href="(.+?)">'
ml = 'c:/xunlei.txt'
def get_html(url):html1 = urllib.urlopen(url)html = html1.read()html1.close()return html
def get_re(html):xunlei = re.findall(regex,html)for a in xunlei:with open(ml,'a') as f:b = a[0]+' '+a[1]f.write(b+'\n')
def get_new(html):new = re.findall(regex1,html)return new[0]html= get_html(url1)
url = get_new(html)
new_html = get_html(url)
if os.path.exists(ml):os.remove(ml)
get_re(new_html)
print 'please look c:/xunlei.txt thankyou!'
print 'newurl= '+url附一个暑假写的获取代理ip的小python代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import re
import urllib2
url1 ='http://www.kuaidaili.com/'#<td data-title="IP">123.182.216.241</td>
html1 = urllib2.urlopen(url1)
html = html1.read()
html1.close()
regexip = r'data-title="IP">(\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3})'
regexport = r'data-title="PORT">(\d{1,4})'
poxyip = re.findall(regexip,html)
poxyport = re.findall(regexport,html)
for x in range(10):print poxyip[x]+':'+poxyport[x]然后~
java版
:
package com.Recar;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.*;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class pacdemo1 {public static void main(String[] args) throws IOException {System.out.println("程序开始....");String str =newURL();String url1 =str.replace("class=\"item\"><a href=\"", " ");String url = url1.replace("\">", " ");System.out.println(url);http(url);}//抽出来单独写个方法返回html的public static String html(String url1) throws IOException{URL url = new URL(url1);URLConnection connection = url.openConnection();connection.connect();BufferedReader in = null;in = new BufferedReader(new InputStreamReader(connection.getInputStream(),"UTF-8"));String result = null;String line;while((line=in.readLine())!=null){result+=line; }//whileSystem.out.println("获取到html....");return result;}///////////////////////////////////////////////////////////////////获取最新的迅雷会员网址public static String newURL() throws IOException{String newURL = null;String result;result= html("http://xlfans.com");//result是返回的网页String regex ="class=\"item\"><a href=\"(.+?)\">";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(result);System.out.println("开始查找最新迅雷会员网址.....");if(matcher.find()){newURL = matcher.group(0);}else{System.out.println("sorry,没有找到,请更新正则"); }return newURL;}///////////////////////////////////////////////////////////////////////////获取网页,并匹配正则public static void http(String newurl)throws IOException{try {//URLURL url = new URL(newurl);String result;result = html(url.toString());//result是返回的网页//那么做正则 迅雷会员(.+?)密码(.*)String regex ="<br />迅雷会员号(.+?)密码(.*)<br />";Pattern pattern = Pattern.compile(regex);Matcher matcher = pattern.matcher(result);String xunlei = null ; String xunlei2= null ; if(matcher.find()){xunlei = matcher.group(0);xunlei2= xunlei.replace("<br />", "\n");System.out.println(xunlei2);}else{System.out.println("sorry,没有找到,请更新正则"); }} catch (MalformedURLException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}
java版还有问题,总是还有一块一起匹配出来了。我是个萌新,忘大佬指点啊。java写爬虫真心烦啊。Python大法好。
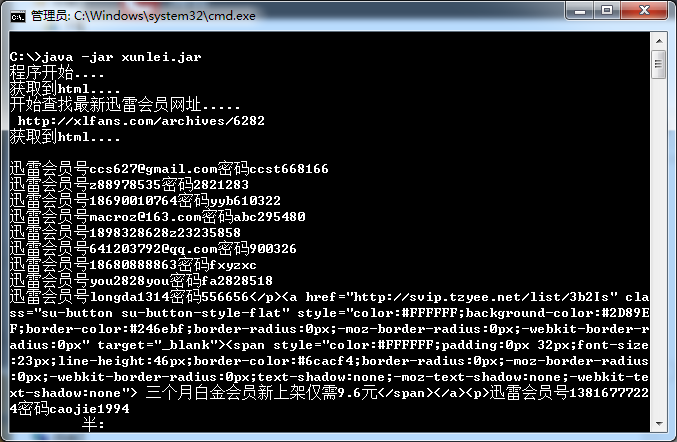
导出jar 要注意是导出 可执行版的。不是单纯的jar文件。
小总结:
java的爬虫是先用定义URL
URL url = new URL("www.baidu.com");然后打开网址
URLConnection connection = url.openConnection();connection.connect();用流来接收html
BufferedReader in = null;in = new BufferedReader(new InputStreamReader(connection.getInputStream(),"UTF-8"));String result = null;String line;while((line=in.readLine())!=null){result+=line; }//while然后用正则匹配,当然还有其他更好的方法~
java写的像C。。。以后要改。要学习。有空写动态网页的爬虫。