简介
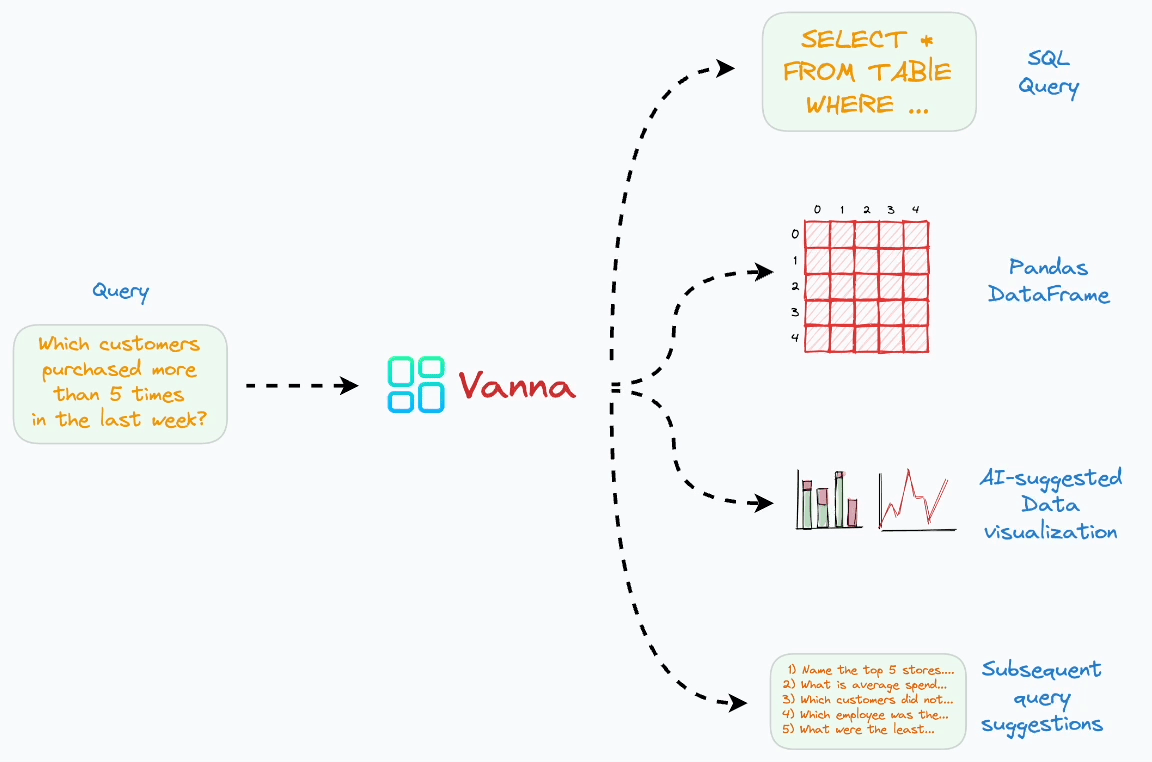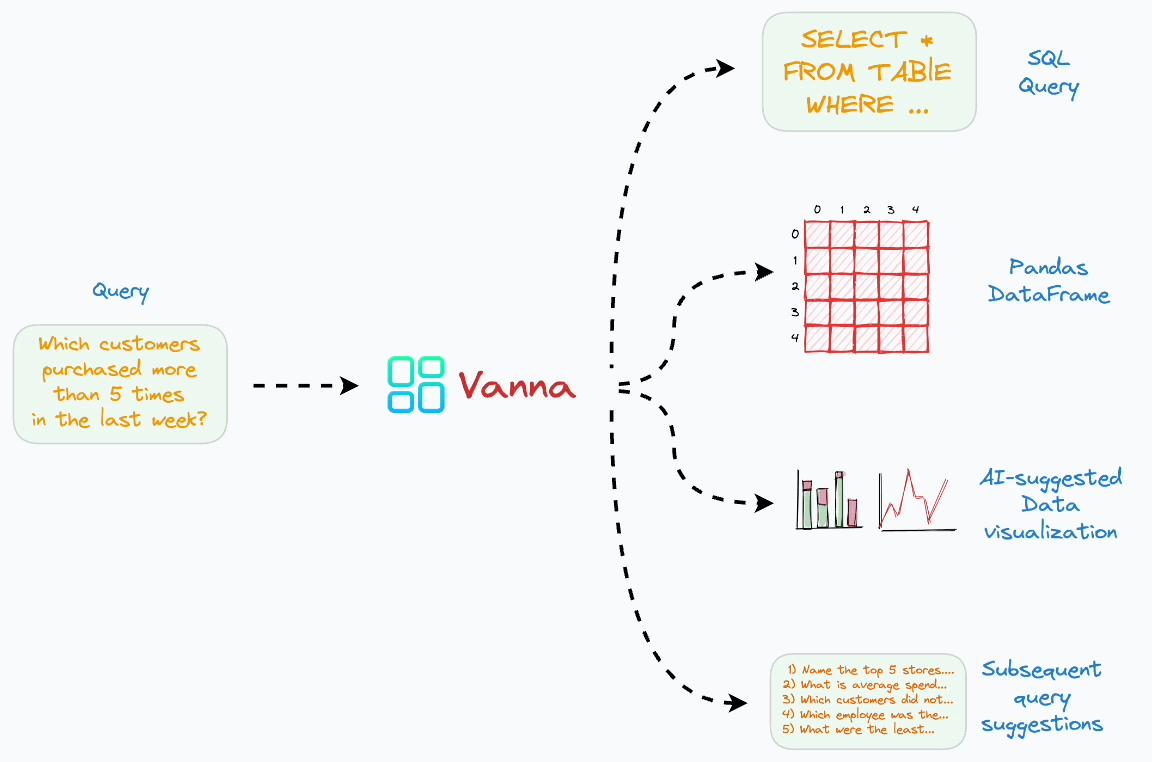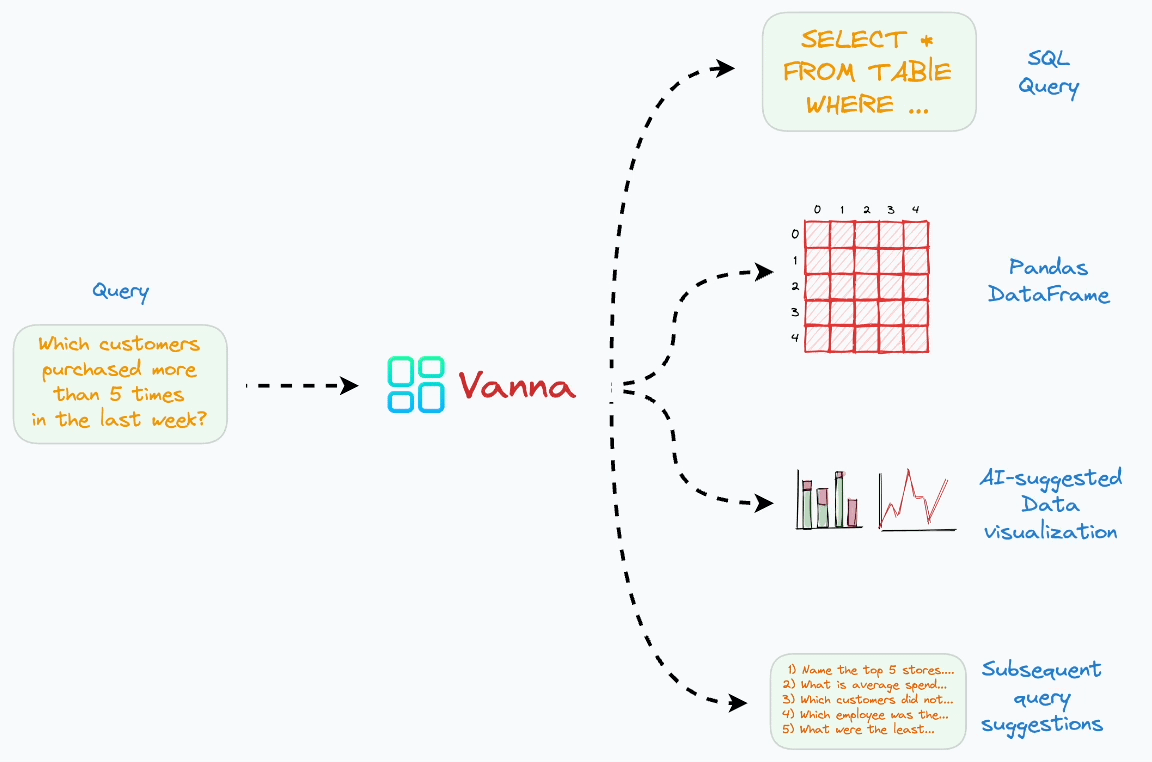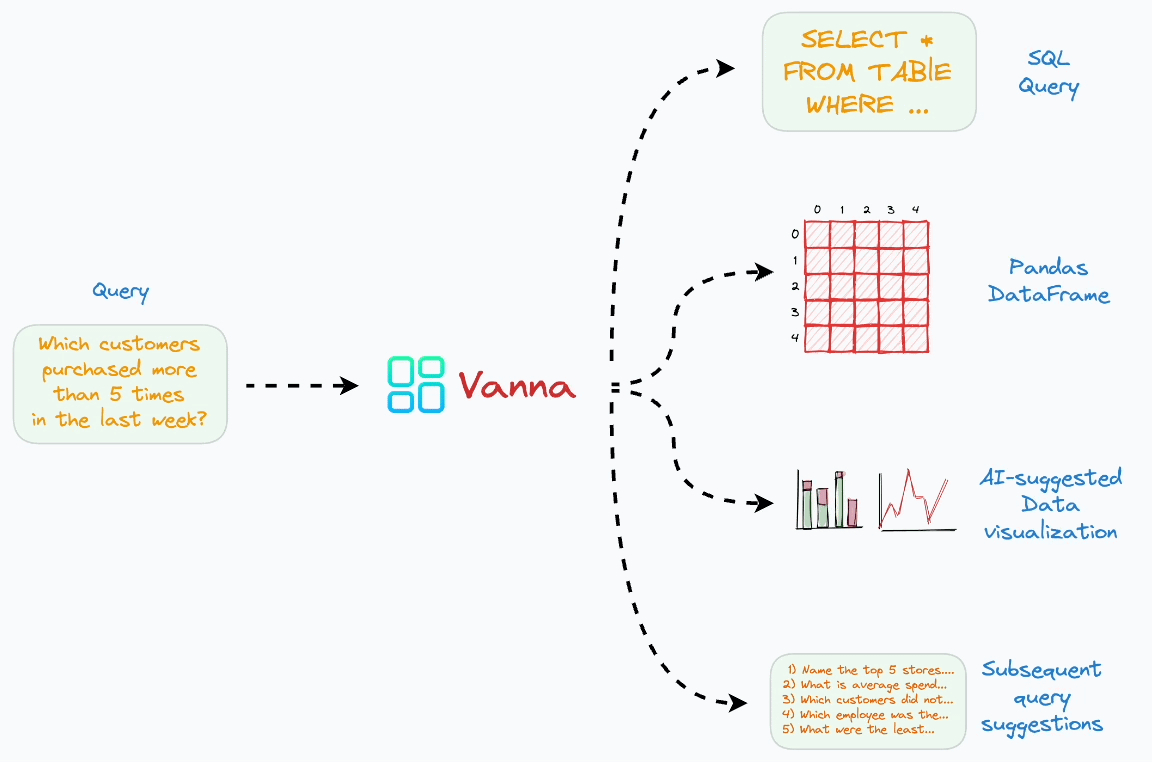
Vanna是基于检索增强(RAG)的sql生成框架
Vanna 使用一种称为 LLM(大型语言模型)的生成式人工智能。简而言之,这些模型是在大量数据(包括一堆在线可用的 SQL 查询)上进行训练的,并通过预测响应提示中最有可能的下一个单词或“标记”来工作。Vanna 优化了提示(通过向量数据库使用嵌入搜索)并微调 LLM 模型以生成更好的 SQL。Vanna 可以使用和试验许多不同的LLM,以获得最准确的结果。
Vanna借助了相对简单也更易理解的RAG方法,通过检索增强来构建Prompt,以提高SQL生成的准确率。从本质上讲,Vanna 是一个 Python 包,它使用检索增强来帮助您使用 LLM 为数据库生成准确的 SQL 查询。

事先用向量数据库将待查询数据库的建表语句、文档、常用SQL及其自然语言查询问题存储起来。在用户发起查询请求时,会先从向量数据库中检索出相关的建表语句、文档、SQL问答对放入到prompt里(DDL和文档作为上下文、SQL问答对作为few-shot样例),LLM根据prompt生成查询SQL并执行,框架会进一步将查询结果使用plotly可视化出来或用LLM生成后续问题。如果用户反馈LLM生成的结果是正确的,可以将这一问答对存储到向量数据库,可以使得以后的生成结果更准确。
优势
-
易用性:Vanna 允许非技术用户通过自然语言与数据库交互,无需编写复杂的 SQL 查询。
-
灵活性:它可以处理多种类型的数据库和查询,适用于不同的应用场景。
-
准确性:Vanna 的能力与你提供的训练数据相关,更多的训练数据意味着在大型和复杂的数据集上有更好的准确性。
-
安全性:你的数据库内容不会直接发送给 LLM,SQL 执行发生在你的本地环境中。
-
自我学习:你可以选择在成功执行的查询上“自动训练”,或让界面提示用户对结果提供反馈,使未来的结果更加准确。
劣势
-
准确性:生成的 SQL 查询可能不完全准确,可能需要人工干预来修正。
-
性能:对于大型数据库,生成 SQL 查询可能会有些缓慢。
-
依赖数据库结构:Vanna 需要事先知道数据库的结构信息,包括表名、字段名等。这意味着我们需要先将数据库结构信息导入到 Vanna 中,才能正确地生成 SQL 查询语句。
-
复杂查询生成能力有限:对于一些非常复杂的查询语句,如果自然语言描述不够明确或存在歧义,可能导致 Vanna 无法正确生成 SQL 语句。
Vanna的关键原理
借助数据库的DDL语句、元数据(数据库内关于自身数据的描述信息)、相关文档说明、参考样例SQL等训练一个RAG的“模型”(embedding+向量库);
并在收到用户自然语言描述的问题时,从RAG模型中通过语义检索出相关的内容,进而组装进入Prompt,然后交给LLM生成SQL。
Vanna 的工作过程分为两个简单步骤 :
-
在给定的数据上训练 RAG“模型”-本质上是基于文档(建表语句、相关sql查询、表或者字段的comment)作为资料,进行Embedding后存入向量库。
-
然后提出问题,基于这些问题去向量库检索相关信息,这些问题传给大模型返回 SQL 查询,这些查询可以设置为在您的数据库上自动运行。

具体步骤包括:
训练:根据您的数据训练 RAG“模型”,或者说根据数据结构构建向量库。用户可以使用 DDL 语句、文档或样例 SQL 查询对 Vanna 进行训练,让它掌握数据库的结构、业务术语和查询模式。Vanna 会将训练数据转化为向量嵌入,存储在向量数据库中,并建立元数据索引,以便于后续检索。
问问题:问Vanna关于数据的各种问题,如"上个月销量最大的5个商品"
检索:Vanna对问题的处理与其他RAG系统一样,检索对应的DDL 语句、文档或样例 SQL。
生成 SQL: Vanna 利用LLM(例如 GPT-4),结合上下文信息,将自然语言问题转化为精准的 SQL 查询语句。
执行 & 展示:数据库收到 Vanna 生成的 SQL 查询后,就会执行查询。Vanna 会将查询结果整理成易于理解的格式,例如表格或图表,呈现给用户。
训练
Vanna的RAG模型训练,支持以下几种方式:
1. DDL语句
DDL有助于Vanna了解你的数据库表结构信息。
vn.train(ddl="""CREATE TABLE IF NOT EXISTS my-table (id INT PRIMARY KEY,name VARCHAR(100),age INT)
""")2. 文档内容
可以是你的企业、应用、数据库相关的任何文档内容,只要有助于Vanna正确生成SQL即可,比如对你行业特有名词的解释、特殊指标的计算方式等。
vn.train(documentation="Our business defines XYZ as ABC")3. SQL或者SQL问答对
即SQL的样例,这显然有助于大模型学习针对您数据库的知识,特别是有助于理解提出问题的上下文,可以大大提高sql生成正确性。
vn.train(question="What is the average age of our customers?",sql="SELECT AVG(age) FROM customers")4. 训练计划(plan)
这是vanna提供的一种针对大型数据库自动训练的简易方法。借助RDBMS本身的数据库内元数据信息来训练RAG model,从而了解到库内的表结构、列名、关系、备注等有用信息。
df_information_schema=vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS")
plan=vn.get_training_plan_generic(df_information_schema)
vn.train(plan=plan)提问
vn.ask("What are the top 10 customers by sales?")你会得到 SQL
SELECT c.c_name as customer_name, sum(l.l_extendedprice * (1 - l.l_discount)) as total_sales
FROM snowflake_sample_data.tpch_sf1.lineitem l join snowflake_sample_data.tpch_sf1.orders o ON l.l_orderkey = o.o_orderkey join snowflake_sample_data.tpch_sf1.customer c ON o.o_custkey = c.c_custkey
GROUP BY customer_name
ORDER BY total_sales desc limit 10;如果已连接到数据库,将获得类似以下内容的查询结果:

也可以通过Plotly chart进行绘图:

Vanna三个主要基础设施
-
Database,即需要进行查询的关系型数据库
-
VectorDB,即需要存放RAG“模型”的向量库
-
LLM,即需要使用的大语言模型,用来执行
Text2SQL任务

配置LLM和向量数据库
默认情况下,Vanna支持使用其在线LLM服务(对接OpenAI)与向量库,可以无需对这两个进行任何设置,即可使用。因此使用Vanna最简单的原型只需要五行代码:
import vanna from vanna.remote
import VannaDefault
vn = VannaDefault(model='model_name', api_key='api_key')
vn.connect_to_sqlite('https://vanna.ai/Chinook.sqlite')
vn.ask("What are the top 10 albums by sales?")这里的OpenAI_Chat和ChromaDB_VectorStore是Vanna已经内置支持的LLM和VectorDB。
如果你需要支持非内置支持的LLM和vectorDB,则需要首先扩展出自己的LLM类与VectorDB类,
实现必要的方法(具体可参考官方文档),然后再扩展出自己的Vanna对象。

参考文献
[1] How accurate can AI generate SQL? (vanna.ai)
[2] https://github.com/vanna-ai/vanna
[3] https://vanna.ai/docs
[3] Vanna-ai: 本地部署OpenAI兼容大模型及向量数据库
[4] Vanna-ai :基于RAG的TextToSql实现方案
[5] Vanna 用 RAG的方法做Text2SQL系统