文章目录
- 浏览器输入URL后发生了什么?
- Linux 系统是如何收发网络包的?
- Linux 网络协议栈
- Linux 接收网络包的流程
- Linux 发送网络包的流程
浏览器输入URL后发生了什么?
- URL解析
- 当在浏览器中输入URL后,浏览器首先对拿到的URL进行识别,抽取出域名字段。
- DNS查询
- 1.查询浏览器缓存(浏览器会缓存之前拿到的DNS 2-30分钟时间),如果没有找到,那么->
- 2.检查系统缓存,检査hosts文件,这个文件保存了一些以前访问过的网站的域名和IP的数据。它就像是一个本地的数据库。如果找到就可以直接获取目标主机的IP地址了。没有找到的话,那么->
- 3.检查路由器缓存,路由器有自己的DNS缓存,可能就包括了这在査询的内容;如果没有,那么->
- 4.查询ISP DNS 缓存: ISP服务商DNS缓存(本地服务器缓存)那里可能有相关的内容,如果还不行的话,那么->
- 5.递归查询:从根域名服务器到顶级域名服务器再到权威域名服务器依次搜索对应目标域名的IP.
- 通过以上的查找,就可以获取到域名对应的IP了。接下来就是向该IP地址定位的HTTP服务器发起TCP连接。
- TCP连接
- 三次握手,四次挥手
- 请求和传输数据
- 发起HTTP请求:建立TCP连接后,浏览器会向服务器发送HTTP请求。这个请求包括请求方法(如GET、POST)、请求头(包含一些额外的信息,如用户代理、Cookie等)以及可能的请求体(对于POST请求)。
- 服务器处理请求:服务器接收到浏览器发送的请求后,根据请求的路径和其他信息,处理请求并生成响应。
- 接收响应:浏览器接收到服务器发送的响应,响应包括状态码(表示请求成功、失败或其他状态)、响应头(包含一些元数据,如内容类型、缓存控制等)和响应体(实际的响应数据)。
- 渲染页面:如果响应的内容是HTML,浏览器会解析HTML、构建DOM树和CSSOM树,然后将它们合并为渲染树,最终绘制到屏幕上。
- 关闭连接:页面渲染完成后,浏览器会关闭与服务器的TCP连接,释放资源。
Linux 系统是如何收发网络包的?
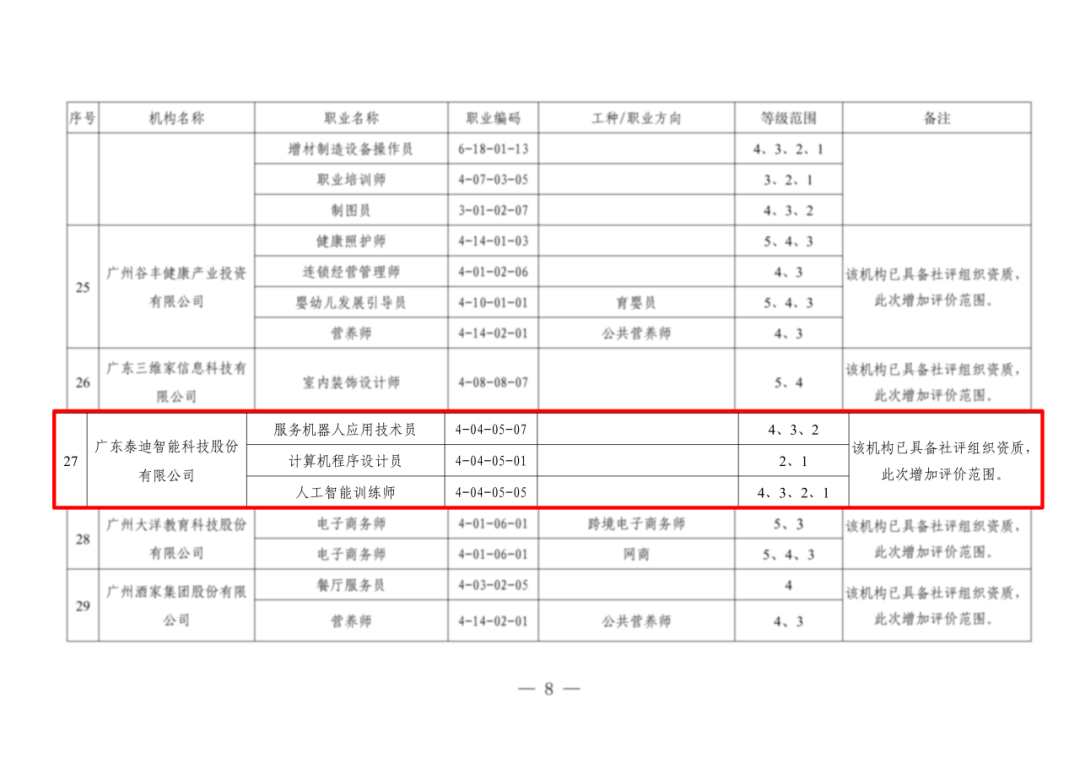
Linux 网络协议栈
Linux 网络协议栈的样子,其实就类似于 TCP/IP 的四层结构:
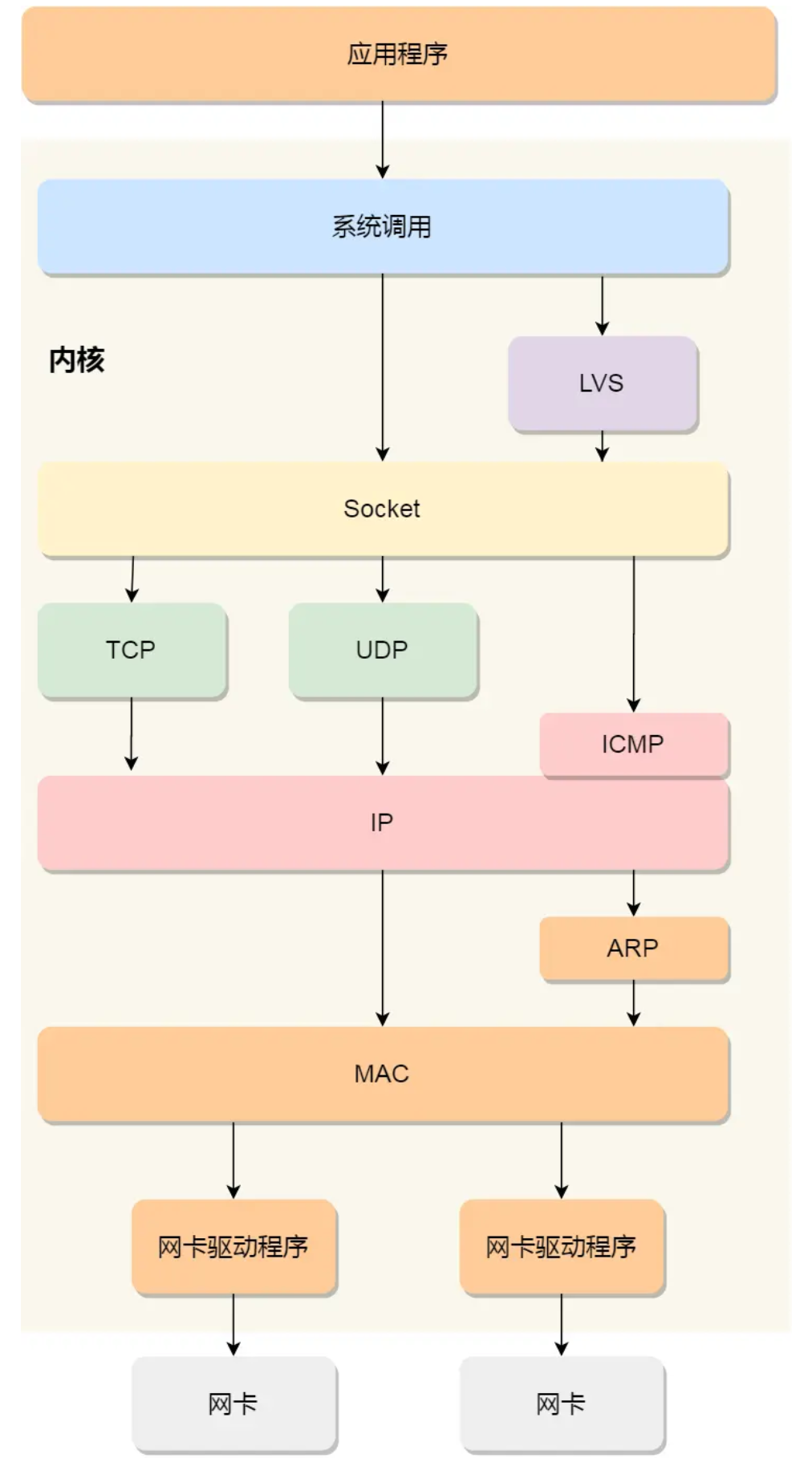
Linux 接收网络包的流程
网卡是计算机里的一个硬件,专门负责接收和发送网络包,当网卡接收到一个网络包后,会通过 DMA 技术,将网络包写入到指定的内存地址,也就是写入到 Ring Buffer ,这个是一个环形缓冲区,接着就会告诉操作系统这个网络包已经到达。
那应该怎么告诉操作系统这个网络包已经到达了呢?
最简单的一种方式就是触发中断,也就是每当网卡收到一个网络包,就触发一个中断告诉操作系统。
但是,这存在一个问题,在高性能网络场景下,网络包的数量会非常多,那么就会触发非常多的中断,要知道当 CPU 收到了中断,就会停下手里的事情,而去处理这些网络包,处理完毕后,才会回去继续其他事情,那么频繁地触发中断,则会导致 CPU 一直没完没了的处理中断,而导致其他任务可能无法继续前进,从而影响系统的整体效率。
所以为了解决频繁中断带来的性能开销,Linux 内核在 2.6 版本中引入了 NAPI 机制,它是混合「中断和轮询」的方式来接收网络包,它的核心概念就是不采用中断的方式读取数据,而是首先采用中断唤醒数据接收的服务程序,然后 poll 的方法来轮询数据。
因此,当有网络包到达时,会通过 DMA 技术,将网络包写入到指定的内存地址,接着网卡向 CPU 发起硬件中断,当 CPU 收到硬件中断请求后,根据中断表,调用已经注册的中断处理函数。
硬件中断处理函数会做如下的事情:
- 需要先**「暂时屏蔽中断」**,表示已经知道内存中有数据了,告诉网卡下次再收到数据包直接写内存就可以了,不要再通知 CPU 了,这样可以提高效率,避免 CPU 不停的被中断。
- 接着,发起**「软中断」**,然后恢复刚才屏蔽的中断。
至此,硬件中断处理函数的工作就已经完成。
硬件中断处理函数做的事情很少,主要耗时的工作都交给软中断处理函数了。
:::info
软中断的处理
:::
内核中的 ksoftirqd 线程专门负责软中断的处理,当 ksoftirqd 内核线程收到软中断后,就会来轮询处理数据。
ksoftirqd 线程会从** Ring Buffer** 中获取一个数据帧,用 sk_buff 表示,从而可以作为一个网络包交给网络协议栈进行逐层处理。
:::info
网络协议栈
:::
首先,会先进入到网络接口层,在这一层会检查报文的合法性,如果不合法则丢弃,合法则会找出该网络包的上层协议的类型,比如是 IPv4,还是 IPv6,接着再去掉帧头和帧尾,然后交给网络层。
到了网络层,则取出 IP 包,判断网络包下一步的走向,比如是交给上层处理还是转发出去。当确认这个网络包要发送给本机后,就会从 IP 头里看看上一层协议的类型是 TCP 还是 UDP,接着去掉 IP 头,然后交给传输层。
传输层取出 TCP 头或 UDP 头,根据四元组「源 IP、源端口、目的 IP、目的端口」 作为标识,找出对应的 Socket,并把数据放到 Socket 的接收缓冲区。
最后,应用层程序调用 Socket 接口,将内核的 Socket 接收缓冲区的数据「拷贝」到应用层的缓冲区,然后唤醒用户进程。
至此,一个网络包的接收过程就已经结束了,你也可以从下图左边部分看到网络包接收的流程,右边部分刚好反过来,它是网络包发送的流程。
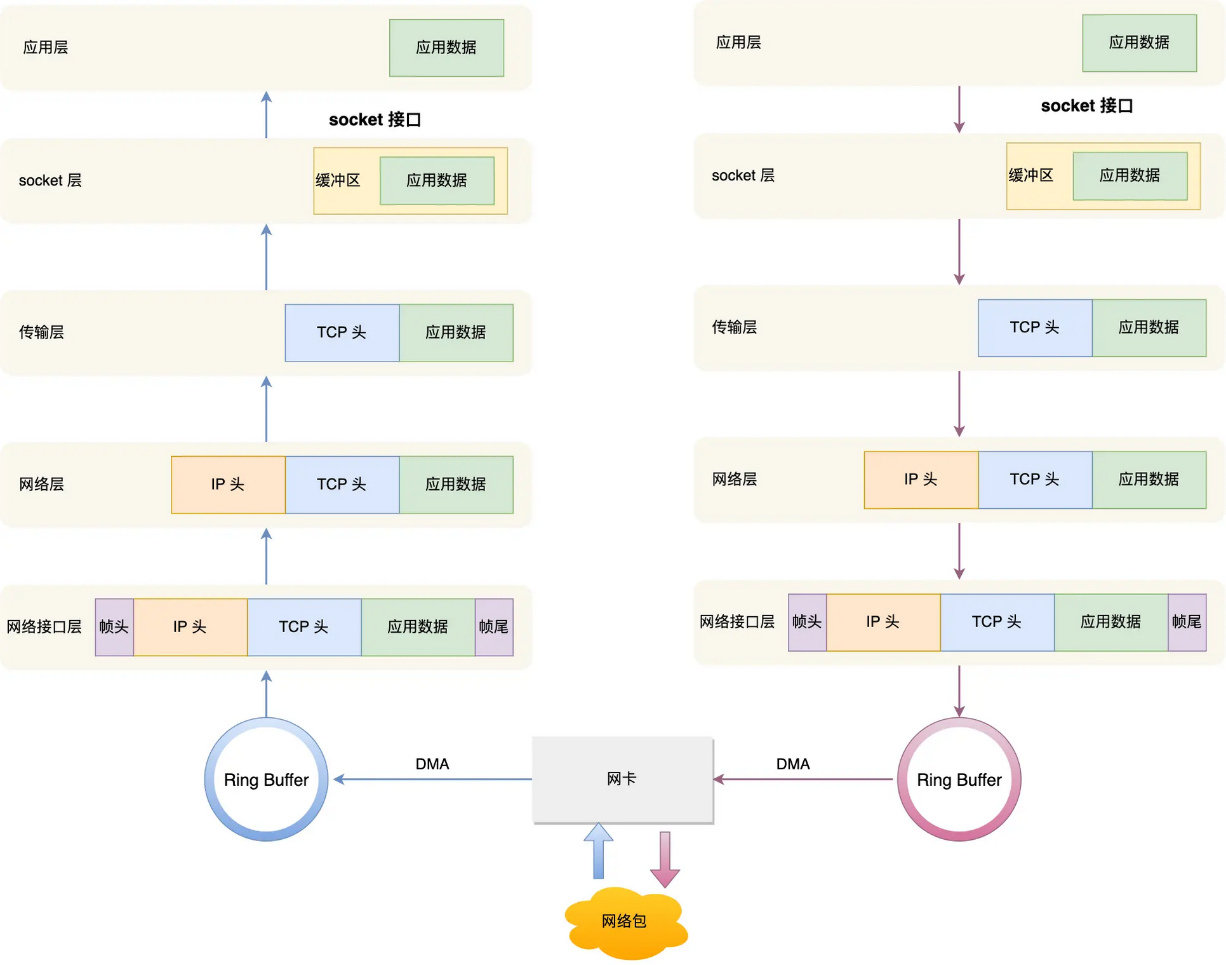
Linux 发送网络包的流程
如上图的右半部分,发送网络包的流程正好和接收流程相反。
首先,应用程序会调用 Socket 发送数据包的接口,由于这个是系统调用,所以会从用户态陷入到内核态中的 Socket 层,内核会申请一个内核态的 sk_buff 内存,将用户待发送的数据拷贝到 sk_buff 内存,并将其加入到发送缓冲区。
接下来,网络协议栈从 Socket 发送缓冲区中取出 sk_buff,并按照 TCP/IP 协议栈从上到下逐层处理。
如果使用的是 TCP 传输协议发送数据,那么先拷贝一个新的 sk_buff 副本 ,这是因为 sk_buff 后续在调用网络层,最后到达网卡发送完成的时候,这个 sk_buff 会被释放掉。而** TCP 协议是支持丢失重传的,在收到对方的 ACK 之前,这个 sk_buff 不能被删除。所以内核的做法就是每次调用网卡发送的时候,实际上传递出去的是 sk_buff 的一个拷贝,等收到 ACK 再真正删除。**
接着,对 sk_buff 填充 TCP 头。这里提一下,sk_buff 可以表示各个层的数据包,在应用层数据包叫 data,在 TCP 层我们称为 segment,在 IP 层我们叫 packet,在数据链路层称为 frame。
你可能会好奇,为什么全部数据包只用一个结构体来描述呢?协议栈采用的是分层结构,上层向下层传递数据时需要增加包头,下层向上层数据时又需要去掉包头,如果每一层都用一个结构体,那在层之间传递数据的时候,就要发生多次拷贝,这将大大降低 CPU 效率。
于是,为了在层级之间传递数据时,不发生拷贝,只用 sk_buff 一个结构体来描述所有的网络包,那它是如何做到的呢?是通过调整 sk_buff 中 data 的指针,比如:
- 当接收报文时,从网卡驱动开始,通过协议栈层层往上传送数据报,通过增加 skb->data 的值,来逐步剥离协议首部。
- 当要发送报文时,创建 sk_buff 结构体,数据缓存区的头部预留足够的空间,用来填充各层首部,在经过各下层协议时,通过减少 skb->data 的值来增加协议首部。
你可以从下面这张图看到,当发送报文时,data 指针的移动过程。
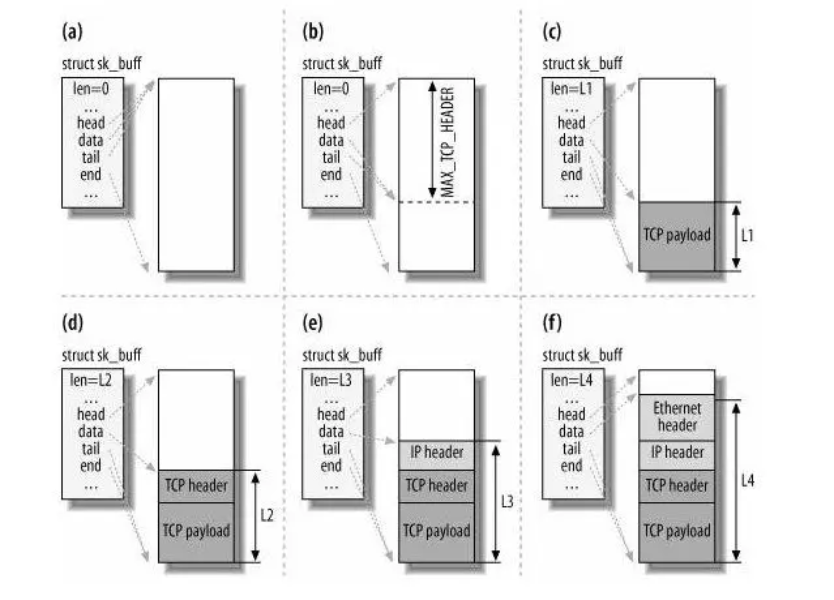
至此,传输层的工作也就都完成了。
然后交给网络层,在网络层里会做这些工作:选取路由(确认下一跳的 IP)、填充 IP 头、netfilter 过滤、对超过 MTU 大小的数据包进行分片。处理完这些工作后会交给网络接口层处理。
网络接口层会通过** ARP 协议获得下一跳的 MAC 地址**,然后对 sk_buff 填充帧头和帧尾,接着将 sk_buff 放到网卡的发送队列中。
这一些工作准备好后**,会触发「软中断」告诉网卡驱动程序,这里有新的网络包需要发送**,驱动程序会从发送队列中读取 sk_buff,将这个 sk_buff 挂到 RingBuffer 中,接着将 sk_buff 数据(RingBuffer)映射到网卡可访问的内存 DMA 区域,最后触发真实的发送。
当数据发送完成以后,其实工作并没有结束,因为内存还没有清理。当发送完成的时候,网卡设备会触发一个硬中断来释放内存,主要是释放 sk_buff 内存和清理 RingBuffer 内存。
最后,当收到这个 TCP 报文的 ACK 应答时,传输层就会释放原始的 sk_buff 。
发送网络数据的时候,涉及几次内存拷贝操作?
第一次,调用发送数据的系统调用的时候,内核会申请一个内核态的 sk_buff 内存,将用户待发送的数据拷贝到 sk_buff 内存,并将其加入到发送缓冲区。
第二次,在使用 TCP 传输协议的情况下,从传输层进入网络层的时候,每一个 sk_buff 都会被克隆一个新的副本出来。副本 sk_buff 会被送往网络层,等它发送完的时候就会释放掉,然后原始的 sk_buff 还保留在传输层,目的是为了实现 TCP 的可靠传输,等收到这个数据包的 ACK 时,才会释放原始的 sk_buff 。
第三次,当 IP 层发现 sk_buff 大于 MTU 时才需要进行。会再申请额外的 sk_buff,并将原来的 sk_buff 拷贝为多个小的 sk_buff。

![[Linux安全运维] iptables包过滤](https://i-blog.csdnimg.cn/direct/3d65f55951b64654a0f41d565adfff4c.png#pic_center)