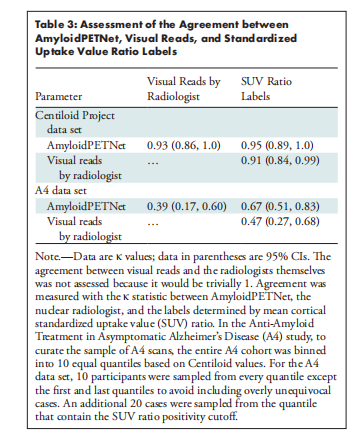
参考资料
- 正则表达式的先行断言(lookahead)和后行断言(lookbehind)
- 正则表达式中分组功能高级用法
- 前瞻断言与后瞻断言
- 初心者歓迎!手と目で覚える正規表現入門・その4(最終回)「中級者テクニックをマスターしよう」
目录
- 一. Positive Lookahead(正向先行断言)
- 1.1 语法
- 1.2 案例
- 二. Positive Lookbehind(正向后发断言)
- 2.1 语法
- 2.2 案例
- 2.2.1 步骤一:获取filename相关部分
- 2.2.2 步骤二:获取filename对应的值
- 三. Negative Lookahead(负向先行断言)
- 3.1 语法
- 3.2 案例
- 四. Negative Lookbehind(负向后发断言)
- 4.1 语法
- 4.2 案例
- 五. 综合案例
- 5.1 `(?<=content=)[^,]+`
- 5.2 `^(?!.*老师)[^,]+`
- 5.3 `(?<=content=)(?!.*老师)[^,]+`
- 5.4 `(?<=content=)(?!.*(老师|医生))[^,]+`
一. Positive Lookahead(正向先行断言)
1.1 语法
⏹语法:(?=...)
💦解释:匹配指定模式的前面的部分
1.2 案例
👇👇👇有如下所示的文本👇👇👇
John:guitar, George:guitar, Paul:bass, Ringo:drum
Freddie:vocal, Brian:guitar, John:bass, Roger:drum
⏹查找:bass之前的部分(匹配结果不包含:bass)
- 正则表达式:
\S+(?=:bass)

二. Positive Lookbehind(正向后发断言)
2.1 语法
⏹语法:(?<=...)
💦解释:匹配指定模式的后面的部分
2.2 案例
👇👇👇有如下所示的文本👇👇👇
type=zip; filename=users.zip; size=1024;
type=xml; filename=posts.xml; size=2048;
⏹查找filename,也就是要获取出users.zip和posts
2.2.1 步骤一:获取filename相关部分
⏹先通过如下正则表达式获取出filename部分
filename=[^;]+[^;]是一个字符集,用于匹配除了分号之外的任何单个字符。+是一个量词,表示匹配前面的字符集一个或多个次数。

2.2.2 步骤二:获取filename对应的值
⏹正则表达式:
(?<=filename=)[^;]+- 在一个字符串中,查找
filename=后面紧跟着的字符串,直到遇到分号;为止。 - 该正则表达式会匹配并提取这个字符串,而不包括
filename=和分号;。
- 在一个字符串中,查找

三. Negative Lookahead(负向先行断言)
3.1 语法
⏹语法:(?!...)
💦解释:匹配指定模式之外的前面的部分
3.2 案例
👇👇👇有如下所示的文本👇👇👇
I love apples; Test;
I love bananas; Test;
I love oranges; Test;
I love grapes; Test;
⏹正则表达式:
love\s(?!bananas).*?;love\s:匹配字面量的字符串 love,后跟一个空格字符(\s表示空白字符,包括空格、制表符等)。(?!bananas):负向先行断言,确保在当前位置后面不跟随 bananas。这意味着如果love后面是 bananas,匹配将会失败。.*?;:非贪婪模式匹配任意数量的任意字符(除了换行符),直到匹配到第一个;为止

love\s(?!bananas)[^;]+(?!bananas):负向先行断言,确保在当前位置后面不跟随 bananas。这意味着如果love后面是 bananas,匹配将会失败。[^;]+:匹配一个或多个不是分号;的字符。[^;]是一个字符集,表示除了分号以外的任意字符。+表示匹配前面的字符集一个或多个次数。

四. Negative Lookbehind(负向后发断言)
4.1 语法
⏹语法:(?<!...)
💦解释:匹配指定模式之外的后面的部分
4.2 案例
👇👇👇有如下所示的文本👇👇👇
- 日本只有东京都和京都,除了这两个都之外的所有都是不合理的,现在要求获取该数据。
東京都
千葉県
神奈川県
埼玉都
测试都
京都
⏹正则表达式:
^(?!東京|京).*都:^(?!東京|京):确保行的开始位置后不是東京或京.*都:匹配任意字符,直到遇到都

五. 综合案例
👇👇👇有如下所示的文本👇👇👇
content=张三老师,你好
content=张三医生,你好
content=李四医生,你好
content=李四老师,你好
content=张三司机,你好
content=王五工程师,你好
5.1 (?<=content=)[^,]+
⏹获取content=之后的部分,截止到,为止

5.2 ^(?!.*老师)[^,]+
⏹行内不能有 老师 ,并且截止到 , 部分

5.3 (?<=content=)(?!.*老师)[^,]+
⏹获取content=之后的部分,截止到,为止,并且匹配到的内容中不能有老师这两个字

5.4 (?<=content=)(?!.*(老师|医生))[^,]+
⏹获取 content= 之后的部分,截止到 , 为止,并且匹配到的内容中不能有老师或医生