文章链接:https://arxiv.org/pdf/2406.09402
项目地址:https://immortalco.github.io/Instruct-4D-to-4D/
今天和大家一起学习的是Instruct 4D-to-4D,可以通过2D扩散模型实现4D感知和时空一致性,以生成高质量的指令引导的动态场景编辑结果。
传统的2D扩散模型在动态场景编辑中的应用通常会导致不一致,主要原因在于其固有的逐帧编辑方法。为了解决将指令引导的编辑扩展到4D的复杂性,本文的关键洞察是将4D场景视为伪3D场景,解耦为两个子问题:在视频编辑中实现时间一致性,并将这些编辑应用于伪3D场景。基于此,本文首先通过引入anchor感知注意模块来增强Instruct-Pix2Pix (IP2P)模型,以实现批处理和一致性编辑。
此外,本文还在滑动窗口模式下集成了光流引导的外观传播,以实现更精确的逐帧编辑,并结合基于深度的投影来管理伪3D场景的大量数据,随后通过迭代编辑实现收敛。本文在各种场景和编辑指令中对文中的方法进行了广泛评估,结果表明其在空间和时间上一致性方面表现出色,并且在细节和清晰度上显著提升。值得注意的是,Instruct 4D-to-4D具有通用性,适用于单目和具有挑战性的多摄像头场景。
介绍
通过渲染合成逼真的新视角图像,神经辐射场(NeRF)及其变体已经成为3D甚至4D动态场景的主要神经表示方法。除了仅仅表示现有场景之外,越来越多的人对通过场景编辑从原始场景创建新的、多样化的场景产生了兴趣。对于用户来说,最方便和直接的方式来传达场景编辑操作是通过自然语言——这一任务被称为指令引导的编辑。
在2D图像任务中,已经通过2D扩散模型,即 Instruct-Pix2Pix (IP2P)取得了成功。然而,将这一能力扩展到以NeRF表示的3D或4D场景却面临显著挑战。困难在于NeRF表示的隐式特性,缺乏直接修改参数以实现目标方向的方式,同时在新维度中出现的复杂性也大大增加。最近,在指令引导的3D场景编辑方面取得了显著进展,例如Instruct-NeRF2NeRF (IN2N)。IN2N通过从2D扩散模型(如IP2P)蒸馏来实现3D编辑,即生成经过IP2P编辑的多视图图像,并将它们拟合到NeRF表示的场景中。由于扩散模型生成结果的高度多样性,IP2P可能会产生多视图不一致的图像,同一对象在不同视图中的外观可能会不同。因此,IN2N通过在NeRF上进行训练来整合结果,使其收敛到“平均”编辑结果,这在理论上是合理的,但在实践中往往会遇到挑战。
将编辑任务从3D进一步扩展到4D,引入了基本的困难。在超出3D场景的额外时间维度中,不仅需要每帧3D场景切片的3D空间一致性,还需要不同帧之间的时间一致性。值得注意的是,由于最近的4D NeRF模型对场景中每个绝对3D位置的特性进行建模,而不是单个对象的运动,因此不同帧中的同一对象并非由相同的参数建模。这种偏差阻碍了NeRF通过拟合不一致的多视图图像实现空间一致性,使得IN2N流程无法有效地在4D场景上执行编辑。
本文引入了Instruct 4D-to-4D,是在指令引导的4D场景编辑中首次尝试,克服了上述问题。本文的关键洞察是将4D场景视为伪3D场景,其中每个伪视图是一个视频,包含了同一视角的所有帧。随后,对伪3D场景的任务可以以类似于真实3D场景的方式进行处理,分解为两个子问题:1)为每个伪视图实现时间一致的编辑,2)使用第(1)步中的方法编辑伪3D场景。然后,我们可以用视频编辑方法解决(1),并利用蒸馏引导的3D场景编辑方法解决(2)。
本文特别利用了一种anchor感知注意力模块来增强IP2P模型。在本文的模块中,“anchor”是一对图像及其编辑结果,作为IP2P生成的参考。增强后的IP2P现在支持批量输入多个图像,并且IP2Ppipeline中的自注意力模块被替换为针对本批次anchor图像的交叉注意力机制。因此,IP2P基于当前图像与anchor图像之间的相关性生成编辑结果,确保在该批次内进行一致的编辑。然而,注意力模块可能无法始终正确关联不同视图中的对象,从而引入潜在的不一致性。
为此,本文进一步提出了一种光流引导的滑动窗口方法来促进视频编辑。利用RAFT为每帧预测光流,以建立相邻帧之间的像素对应关系。这使能够将一个帧的编辑结果传播到下一个帧,类似于一种扭曲效果。结合增强的IP2P和光流技术,本文可以按时间顺序编辑视频,通过分段处理帧并在每个段落应用编辑,同时将编辑效果传播到下一个段落。这个过程涉及利用光流来初始化基于前几帧的编辑,然后使用增强的IP2P,其中前一个段落的最后一帧作为anchor。
在处理包含大量视角的4D场景时,每个视角的计算成本很高。 为了解决这个问题,本文采用了受ViCA-NeRF 启发的策略,基于关键视角来编辑伪3D场景。首先随机选择关键伪视角,并使用前面提到的方法进行编辑。然后对于每一帧,采用基于深度的投影将关键视角的结果扭曲到其他视角,并利用加权平均来聚合外观信息,从而获得所有帧的编辑结果。鉴于4D场景的复杂性,本文应用IN2N的迭代编辑过程,以逐步生成编辑后的帧并在编辑后的帧上拟合NeRF,直到场景收敛为止。
本文进行了广泛的实验,涵盖单目和多摄像头动态场景,验证了文中方法的有效性。评估结果显示,本文的方法在实现更锐利的渲染结果和显著增强的细节方面具有显著能力,并且在4D编辑中保证了空间-时间一致性(见下图1)。

本文的贡献主要体现在三个方面:
-
引入了Instruct 4D-to-4D,这是一个简单而有效的框架,通过从2D扩散模型的蒸馏来将4D场景作为伪3D场景进行指导编辑;
-
提出了基于anchor感知的IP2P和光流引导的滑动窗口方法,实现了对任意长度的长视频或伪视角的高效和一致的编辑;
-
借助所提出的方法,开发了一个pipeline来迭代生成完整和一致编辑的数据集,在各种任务中实现了高质量的4D场景编辑。本文的工作是首次探索和解决通用指导4D场景编辑的任务,为这一有前景的领域奠定了基础。
方法
本文提出了Instruct 4D-to-4D,这是一个新颖的pipeline,通过从Instruct-Pix2Pix (IP2P) 中提炼来编辑4D场景,IP2P是一种强大的2D扩散模型,支持指导图像编辑。本文方法的基本思想源于ViCA-NeRF,这是一种基于关键视角的编辑方法。将4D场景视为伪3D场景,其中每个伪视角是多帧视频,本文应用基于关键视角的编辑方法,分为两个步骤:关键伪视角编辑和从关键伪视角传播到其他视角,如下图2所示。本文提出了几个关键组件,在这些步骤中强化和实现空间和时间一致性,生成4D一致的编辑结果。

基于anchor的IP2P用于一致的批量生成
批量生成与伪3D卷积。将伪视图的编辑过程视为编辑视频。因此,在编辑每帧时,需要强制实现时间上的一致性。受到之前视频编辑工作的启发,本文在IP2P中一起编辑一批图像,并增强IP2P中的UNet,使其在生成时考虑整个批次。本文将其 的2D卷积层升级为 的3D卷积层,通过重复使用原始的卷积核参数。
基于anchor感知的注意力模块。受限于GPU内存,本文无法一次性编辑伪视图的所有帧,需要将生成过程分成多个批次。因此,保持批次之间的一致性至关重要。借鉴于Tune-a-Video 的思路,本文不是从头开始生成新批次的编辑结果,而是允许模型参考一个在所有生成批次中共享的anchor帧,及其原始和编辑后的版本,以将编辑风格从anchor帧“传播”到新的编辑批次。通过将IP2P中的自注意力模块替换为针对anchor帧的交叉注意力模型,能够在当前图像和anchor图像之间建立连接,通过模仿anchor的风格生成新的编辑图像,从而延续anchor的一致编辑风格。值得注意的是,本文使用anchor注意力IP2P与Tune-a-Video有所不同,后者在当前帧和上一帧之间查询交叉注意力而非anchor帧。我们的设计还进一步促进了下面章节的修复过程,该过程也需要集中关注当前帧的现有部分。
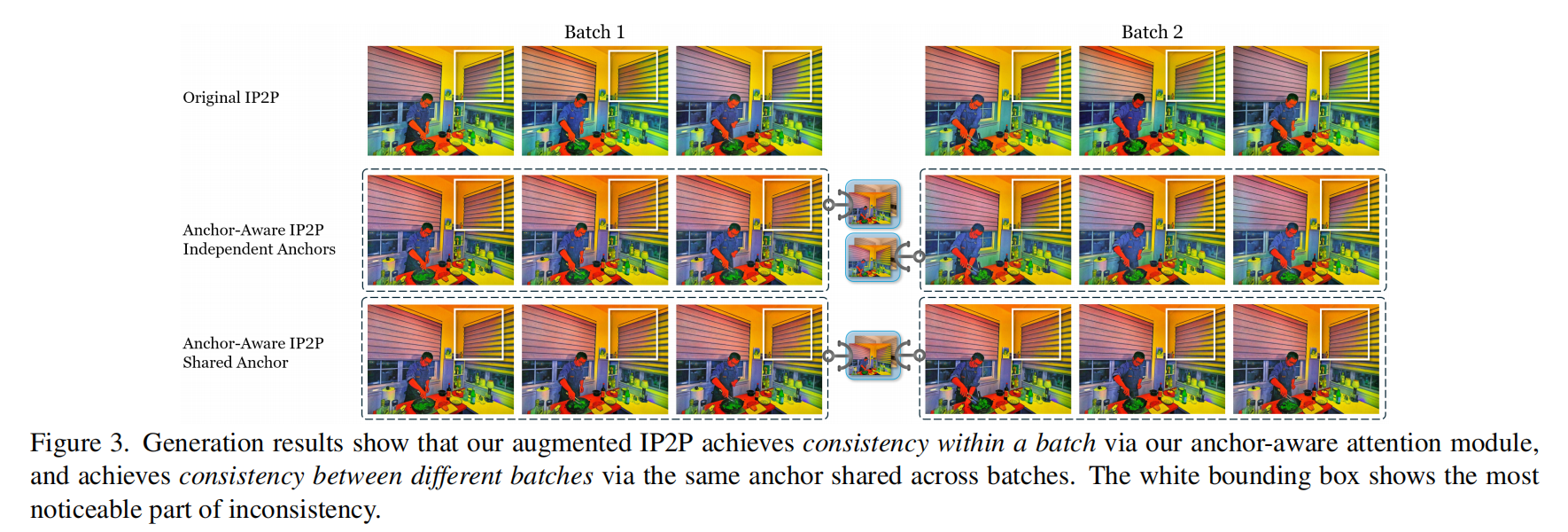
有效性。下图3展示了不同版本的IP2P生成结果。原始的IP2P编辑所有图像时存在不一致性,即使是同一个批次中的图像也有不同的颜色分布。通过引入anchor感知注意力层,IP2P能够将整个批次作为一个整体生成,因此在同一个批次内生成一致的编辑结果。然而,它仍然无法在不同批次之间生成一致的图像。采用相同anchor图像跨批次参考的全面anchor感知IP2P能够为所有6个图像在2个批次中生成一致的编辑结果,这表明即使没有额外训练,anchor感知IP2P也能够实现一致的编辑结果。
光流引导滑动窗口方法用于伪视图编辑
光流作为4D Warping。为了确保伪视图的时间一致性,本文需要在不同帧之间找到像素的对应关系。传统的3D场景编辑方法(如ViCA-NeRF、RAFT)利用基于深度的Warping来找到不同视角之间的对应关系,使用NeRF预测的深度和相机参数进行确定性Warping。然而,在4D中,没有这样明确的方法。因此,本文使用光流估计网络RAFT来预测光流,其格式为每个像素的2D运动向量,可以推导出另一帧中的对应像素。利用RAFT,本文能够在相邻帧之间进行像素的Warping,就像在3D中一样。由于每个伪视图都是在固定的摄像机位置拍摄的,光流能够很好地完成这项任务。
滑动窗口方法。本文借鉴了视频编辑方法的思想来编辑伪视图。然而,这些方法主要专注于短视频,并通过在单个批次中编辑所有帧来进行视频编辑,因此无法处理长视频。因此,本文提出了一种新颖的滑动窗口(宽度为 ,即最大允许的批处理大小)方法,利用了基于anchor的IP2P和光流。如上图2(a)所示,对于当前包含 个图像的窗口,例如帧 、、、,我们首先通过4D Warping逐一将帧 的编辑结果传播到所有这些 个图像上。对于未匹配的像素,即对应于帧 中遮挡部分的像素,本文将它们的值设置为其原始值,从而获得原始和Warping后编辑图像的融合图像。
接着,类似于ViCA-NeRF中的思路,本文使用IP2P对滑动窗口中每个视角的融合图像进行修补和再绘制,通过向融合图像添加噪声,并使用IP2P进行去噪,使生成的编辑图像在Warping结果上遵循相似的模式,同时重新绘制整个图像使其看起来自然合理。为了确保整个伪视图的风格一致,本文使用第一帧作为所有窗口共享的anchor,这样模型将以类似第一个视角的一致风格生成图像。由于一个伪视图的摄像机位置固定,不同帧之间有许多共同的物体,因此这种方法非常有效,能够为窗口中的帧生成一致的编辑结果。
完成当前窗口的编辑后,本文将窗口向前移动 帧。因此,对于总共 帧的伪视图,本文的Instruct 4D-to-4D只需要调用 IP2P 次。通过缓存同一视角相邻帧之间的光流预测,本文可以高效实现时间一致的伪视图编辑。
基于Warping的伪视图传播
生成第一帧图像。由于本文需要将编辑后的伪视图传播到所有其他视图并确保空间一致性,因此在所有关键伪视图中以一种空间一致的方式编辑第一帧非常重要 - 它们不仅用于启动当前伪视图的编辑,还用作所有后续生成的anchor或参考。因此,本文首先在任意一个关键伪视图中编辑一帧作为第一帧,然后使用本文的anchor感知IP2P与其一起作为anchor来生成其他第一帧。通过这种方式,所有第一帧都以一致的风格进行编辑,这对于编辑关键伪视图是一个良好的起点。
从关键视图传播到其他视图。在编辑关键伪视图之后,类似于ViCA-NeRF 的方法,本文将它们的编辑结果传播到所有其他关键视图。ViCA-NeRF使用基于深度的空间Warping来从同一时间步的另一个视图Warping图像,而本文还提出了基于光流的时间Warping,从同一视图的前一帧进行Warping。通过这两种类型的Warping,本文可以从多个来源Warping编辑后的图像。
本文按时间顺序逐步传播每个时间步骤。在时间步骤 进行传播时,对于每个视图 上的帧 ,本文将其编辑版本作为两个来源Warping结果的加权平均值:(1) 使用时间Warping从同一视图的前一帧 的编辑结果;以及 (2) 使用空间Warping从一个关键视图中当前帧的编辑结果。通过对所有时间步骤进行帧的传播,本文得到一个包含所有编辑帧的一致性编辑数据集。本文使用这样的数据集来训练NeRF朝向编辑结果。 通过这种传播方法,本文能够在 个耗时的 IP2P 生成中高效地生成一整套一致编辑的帧数据集,其中 为所有 个伪视图中的关键伪视图数,在本文的实验中 n = 5,而 V 可能超过20。这种高效性使得本文能够部署一个迭代的pipeline来更新数据集。
整体编辑 pipeline
迭代式数据集更新。借鉴 IN2N 的思想,本文在基准方法上应用迭代式数据集替换,使用文中的方法重复生成完整的数据集,并在其上适配本文的NeRF。在每次迭代中,本文首先随机选择几个伪视图作为这次生成中的关键视图。本文使用文中的方法为所有这些关键伪视图的第一帧生成空间一致的编辑结果,然后使用滑动窗口方法来传播这些编辑结果到所有伪视图。在获得所有编辑的关键伪视图后,本文再次使用文中的方法为所有其他伪视图生成空间和时间上一致的编辑结果,最终得到一个一致的编辑数据集。本文用这个编辑过的数据集替换原始的4D数据集,并在其上适配NeRF模型。
通过并行化和退火策略提高效率。在本文的pipeline中,NeRF只需要在数据集上进行训练并提供当前的渲染结果,而IP2P只需要根据NeRF的渲染结果生成新的数据集 - IP2P和NeRF之间几乎没有依赖和交互。因此,本文通过在两个GPU上异步运行这两部分来并行化pipeline。在第一个GPU上,持续训练NeRF并在渲染缓冲区中缓存NeRF的渲染结果;而在第二个GPU上,应用本文的迭代数据集生成pipeline来生成新的数据集,使用来自渲染缓冲区的图像,并更新用于训练NeRF的数据集。通过最小化交互,最大化了并行化,从而显著减少了训练时间。
另一方面,为了改善生成结果和收敛速度,本文采用了来自HiFA 的退火技巧来对NeRF进行精细编辑。高层次的思路是使用噪声水平来控制渲染结果与IP2P编辑结果的相似性。本文在高噪声水平下生成数据集,以生成充分编辑的结果,然后逐渐退火噪声水平,使其与NeRF正在收敛到的编辑结果保持一致,并进一步细化这些结果。与IN2N总是在随机噪声水平下生成不同,本文的Instruct 4D-to-4D 能够快速收敛到高质量的编辑结果。
通过这两种技术,本文的Instruct 4D-to-4D能够在几个小时内编辑一个包含20个视图和数百帧的大规模4D场景。
实验
编辑任务和NeRF主干。本文用于评估的4D场景是通过单手持相机和多相机阵列捕捉的,包括:(I) DyCheck 和 HyperNeRF 中的单目场景,这些是简单的、以物体为中心的场景,使用单个移动相机;(II) DyNeRF/N3DV 中的多相机场景,包括具有面向前方视角和人类运动结构的室内场景。对于单目场景,本文将所有帧视为单个伪视图进行编辑。本文使用NeRFPlayer 作为NeRF主干,以生成高质量的4D场景渲染结果。
基线方法。Instruct 4D-to-4D是首个致力于指导式4D场景编辑的工作。以前没有研究专注于相同的任务,而唯一类似的工作Control4D 尚未发布其代码。因此,无法与现有方法进行基线比较。为了展示本文的Instruct 4D-to-4D的有效性,本文构建了一个基线方法IN2N-4D,将IN2N 平稳地扩展到4D,它会迭代地生成一个编辑过的帧并将其添加到数据集中。本文定性和定量地比较Instruct 4D-to-4D与IN2N-4D的结果。为了量化结果,由于本文的pipeline的模型都在使用生成的图像训练NeRF,本文使用传统的NeRF 指标来评估结果,即在IP2P生成的图像(从纯噪声生成,因此不会依赖于NeRF的渲染图像)与NeRF的渲染结果之间的PSNR、SSIM和LPIPS。本文在补充材料中进行了Instruct 4D-to-4D各个变体的消融研究。
定性结果。本文的定性结果显示在图下6、下图5和下图4中。与基线方法IN2N-4D的定性比较如下图5和下图6所示。如下图5所示,在将单目场景中的猫变成狐狸的任务中,IN2N-4D生成模糊的结果,并出现多个人工痕迹:多个耳朵、多个鼻子和嘴巴等。而本文的Instruct 4D-to-4D生成了逼真的结果,狐狸的形状与原始场景中的猫非常吻合,毛发上有清晰的纹理,没有任何痕迹。
这些结果表明,本文的anchor-aware IP2P、基于光流的Warping和滑动窗口方法用于伪视图编辑,能够产生伪视图的时间一致性编辑结果。相比之下,IN2N-4D中原始的IP2P生成了每帧不一致的编辑图像,最终导致了4D NeRF上的奇怪结果。下图6展示了多摄像头场景上的风格转移结果。本文并行化的Instruct 4D-to-4D在短短两小时内实现了一致的风格转移结果,而IN2N-4D则需要比本文的Instruct 4D-to-4D长24倍的时间,仍无法使4D NeRF收敛到指定的风格。这表明,4D场景编辑具有极高的难度,而本文 Instruct 4D-to-4D通过迭代生成完整的编辑数据集的策略,实现了高效的编辑。所有这些结果共同显示,本文设计的Instruct 4D-to-4D是合理且有效的,能够以非常高效的方式生成高质量的编辑结果。

上图5的实验展示了单目场景mochi-high-five在不同指令下的表现,包括对猫的局部编辑,以及整个场景的风格转移指令。本文的Instruct 4D-to-4D在Fox和Tiger指令下实现了逼真的局部编辑结果,如虎纹的清晰和一致。在风格转移指令下,编辑后的场景忠实地反映了指定的风格。这些结果展示了Instruct 4D-to-4D在各种指令下编辑单目场景的出色能力。

上图4的实验展示了其他风格转移结果,包括HyperNeRF和DyCheck中的单目场景,以及DyNeRF中的多摄像头场景。Instruct 4D-to-4D始终以高保真度展现各种风格的风格转移结果,颜色明亮,外观清晰。

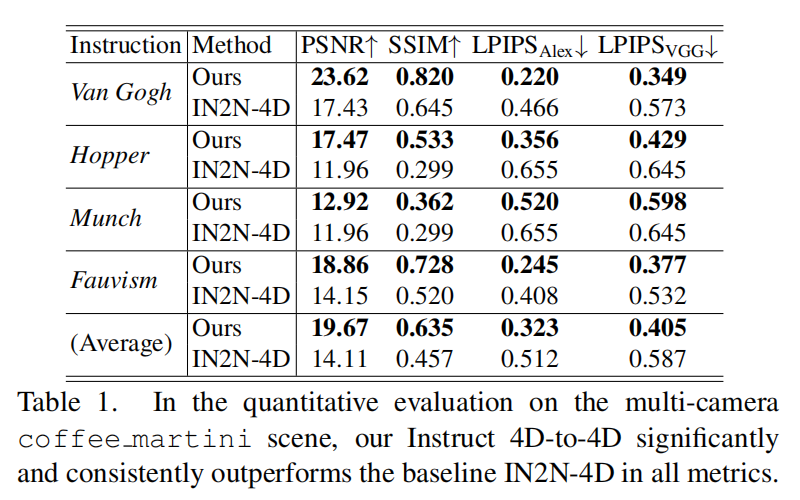
定量比较。本文在多摄像头咖啡马提尼场景上对文中的Instruct 4D-to-4D和基线方法IN2N-4D进行了量化比较,结果见下表1。与定性比较结果一致,本文的Instruct 4D-to-4D显著且一致地优于基线方法IN2N-4D。这表明,由Instruct 4D-to-4D训练的NeRF比基线方法更好地适应了IP2P生成的编辑结果,进一步验证了本文Instruct 4D-to-4D的有效性。
消融研究:变量与设置。 本文通过与以下几种变体的比较来验证本文的设计选择:
-
视频编辑。这个变体作为本文Instruct 4D-to-4D的最基本实现,使用任何视频编辑方法编辑每个伪视图帧,并使用3D Warping将编辑结果传播到其他帧。本文使用了一个零损耗文本驱动的视频编辑模型,FateZero,通过预训练的稳定扩散模型。本文遵循Fatezero官方实现中的风格编辑和属性编辑设置。由于它们只能处理8个视频帧的批处理,本文采用逐批次的伪视图编辑策略。
-
不使用光流的anchor感知IP2P。在这个变体中,本文在没有光流引导的情况下进行视频编辑,即anchor感知IP2P直接使用相同的扩散模型设置编辑所有训练图像。
-
单次伪视图传播。在这个变体中,本文仅进行一次伪视图传播,即所有剩余的伪视图从4个随机选择的关键伪视图中进行Warping,然后在这些编辑图像上训练NeRF直至收敛。
消融研究的任务是在DyNeRF数据集的咖啡马提尼上应用“如果由梵高绘制”的操作。由于“视频编辑”变体不使用主文中的扩散模型IP2P来编辑视频,因此本文无法使用主文中的度量标准。因此,与IN2N 一致,本文使用CLIP 相似度来评估编辑操作的成功程度。
消融研究:结果。定性结果显示在下图7和演示视频中。大多数变体未能对场景进行足够的编辑,呈现出阴沉的外观,并且缺乏梵高典型的色彩。这表明本文Instruct 4D-to-4D的设计选择是有效的且至关重要,可以实现高质量的编辑。

量化比较结果显示在下表2中。本文完整的Instruct 4D-to-4D在消融任务中实现了显著更高的CLIP相似度,表明本文的设计是有效的。此外,观察到视频编辑策略甚至无法比IN2N-4D获得更好的指标,这表明即使将其转换为伪3D场景,编辑4D场景仍然是一个非常困难的任务。

结论
Instruct 4D-to-4D,这是第一个通过将4D场景视为伪3D场景,并采用迭代策略利用2D扩散模型编辑伪3D场景的指导性4D场景编辑框架。定性实验结果显示,Instruct 4D-to-4D在包括单目和多摄像头场景在内的多种任务中实现了高质量的编辑结果。Instruct 4D-to-4D还显著优于基线方法,即将现有最先进的3D编辑方法简单扩展到4D场景,显示了这一任务的难度和复杂性,以及本文方法的成功。希望本文的工作能够激发更多关于4D场景编辑的未来研究。
参考文献
[1] Instruct 4D-to-4D: Editing 4D Scenes as Pseudo-3D Scenes Using 2D Diffusion