【新智元导读】紧跟着Meta的重磅发布,Mistral Large 2也带着权重一起上新了,而且参数量仅为Llama 3.1 405B的三分之一。不仅在编码、数学和多语言等专业领域可与SOTA模型直接竞争,还支持单节点部署。
昨天正式发布的Llama 3.1模型,让AI社区着实为之兴奋。
但是仔细一想就能发现——405B的参数规模,基本是没法让个人开发者在本地运行了。
比如昨天刚发布,就有一位勇敢的推特网友亲测,用一张英伟达4090运行Llama 3.1。

结果可想而知,等了30分钟模型才开始回应,缓缓吐出一个「The」。

最后结果是,Llama给出完整回应,整整用了20个小时。

根据Artificial Analysis的估算,你需要部署含2张8×H100的DGX超算才能在本地运行405B。
看来,小扎对Llama 3.1成为开源AI界Linux的期待,可能和现实有不少的差距。目前的硬件能力,很难支持405B模型的大范围全量运行。
此时,又一位开源巨头Mistral精准踩点,发布了他们的最新旗舰模型Mistral Large 2。

Mistral Large 2在代码生成、数学和推理等方面的能力明显增强,可以与GPT-4o和Llama 3.1一较高下。
而且,模型参数量仅有123B,不到Llama 3.1 405B的三分之一,完全可以在单个节点上以大吞吐量运行。
成本效率、速度和性能的「三角形战士」,Mistral Large当之无愧——
和GPT-4o比,它开源;和Llama 3.1 450B比,它参数少;和Llama 3 70B比,它性能好。
推特网友惊呼,「开源AI就这么卷起来了吗!」
短短一周时间内,GPT-4o mini、Llama 3.1、Mistral Large 2相继发布,有些让人应接不暇。
「我躺了,你们先卷着。」
但躺平阵营中绝对不包含ollama。前脚Mistral刚官宣,这边就火速更新。

果然,参数量砍去一大半之后,本地部署难度就大大下降了。
同样从ollama上下载模型,用96GB内存还是可以顺利运行起来的。
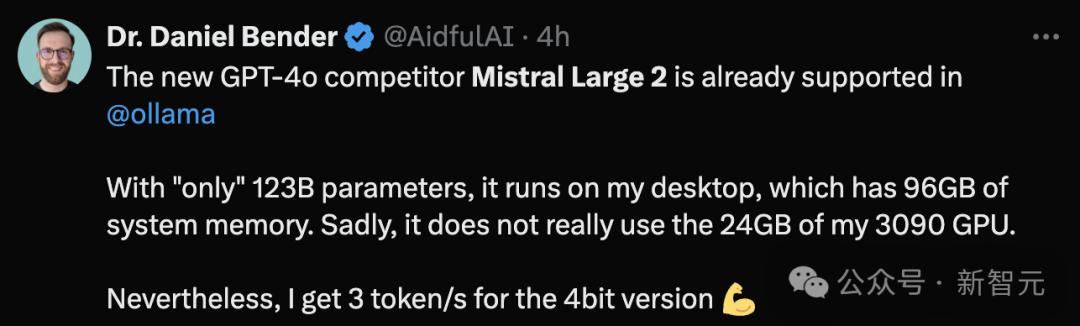
虽然3 token/s的生成速度慢了点,但比起用20个小时等模型响应,已经是质的飞跃了。
用前段时间击穿GPT-4o的「9.11 vs. 9.9」问题测试Large 2,没想到它竟然答对了。
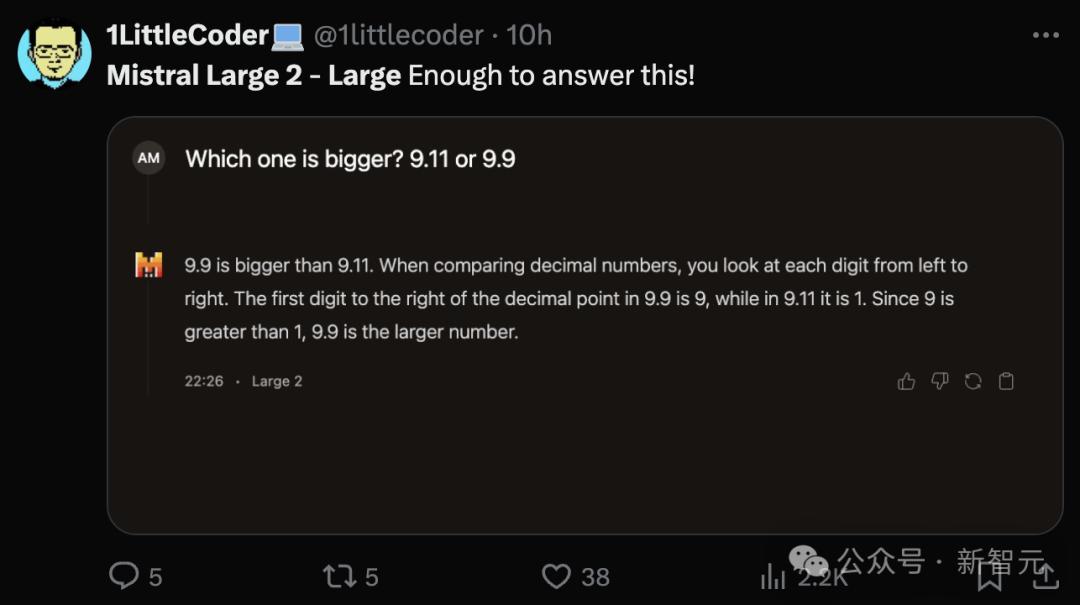
值得一提的是,Mistral Large首代发布还不到半年(2024年2月),但并没有开源,用户只能通过官方API或Azure访问。
刚发布的Mistral Large 2则已经将模型权重托管到了HuggingFace仓库中,向研究和非商业用途开放,但商业用途的部署仍需要直接联系Mistral以取得许可。

HuggingFace地址:https://huggingface.co/mistralai/Mistral-Large-Instruct-2407
不仅上下文窗口从上一代的32k增长到了128k(同Llama 3.1),而且有强大的多语言能力,支持数十种自然语言以及80多种编程语言。
令人印象深刻的是,Mistral Large的预训练版本在MMLU上的准确率可以达到84%。
这个成绩已经超过了340B参数的Nemotron,而且与GPT-4(85.1%)和Llama 3.1(87.3%)基本处于同一水平,可以说是将模型性能/成本的Pareto最优边界又向前推进了一步。
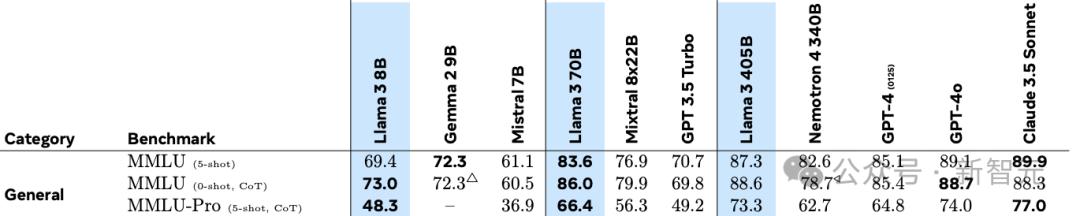
出自Llama 3.1论文
代码与推理
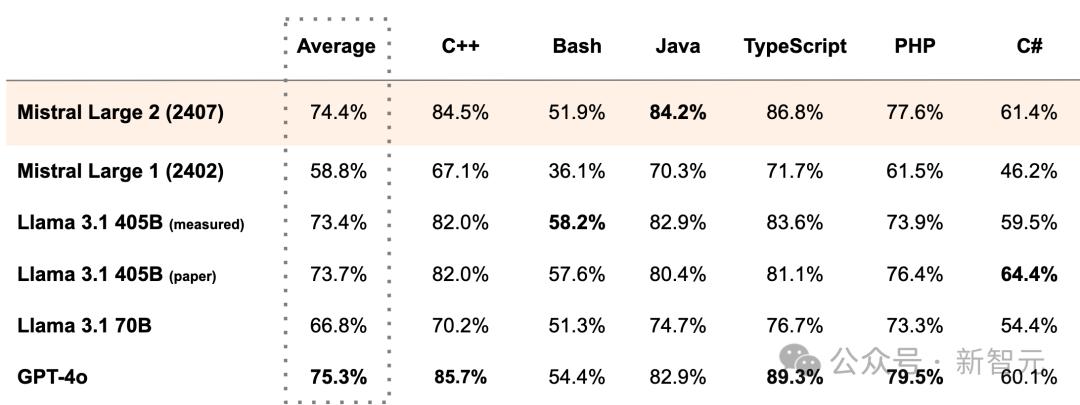
基于Mistral之前训练的经验,研究团队对Mistral Large 2也进行了大量代码训练,支持包括Python、Java、C、C++、JavaScript 和Bash在内的80多种语言。
在代码生成方面,Mistral Large 2远远优于Llama 3.1 70B和之前的Mistral Large,与Llama 3.1 405B不相上下。

团队在提高模型的推理能力方面也投入了大量精力。在训练过程中,特别关注减少模型的「幻觉」。
实现方法就是通过微调,让模型的响应更加谨慎而敏锐,确保它提供可靠、准确的输出。
此外,经过训练的Mistral Large 2还被赋予了一个品质:承认自己并非无所不知。
在无法找到解决方案,或没有足够信息支撑有效回答时,模型会直接承认而非「不懂装懂」。
Mistral Large 2这种对答案准确性的「责任感」,提升了在数学基准上的表现,展现了更强的推理和解决问题的能力。
在用于代码生成的HumanEval和HumanEval Plus基准测试中,它的表现优于Claude 3.5 Sonnet和Llama 3.1,仅次于GPT-4o。

代码生成基准测试
在MultiPL-E基准上,Mistral Large 2的平均生成准确率领先Llama 3.1将近1个百分点,而且可以媲美GPT-4o。
纵向比较也可以看出,Codestral系列的经验对Mistral Large 2有不少助益。仅仅过了5个月,Mistral Large系列的生成准确率就从58.8%飙升至74.4%。
而且,在以数学为重点的基准测试中(GSM8K和MATH),它的表现也可圈可点。
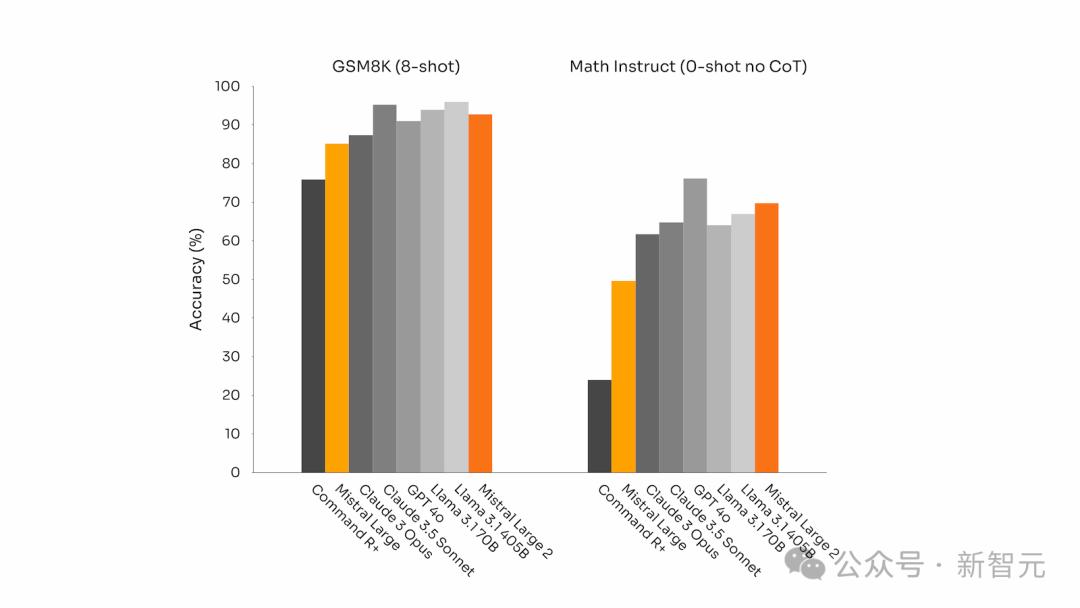
GSM8K(8-shot)和MATH(0-shot,无CoT)基准测试
指令执行与对齐
Mistral Large 2的指令执行和对话能力也得到了显著提升,在执行精确指令和处理长时间多轮对话方面表现尤为出色。
以下是其在Wild Bench和Arena Hard基准测试上的表现:

通用对齐基准测试
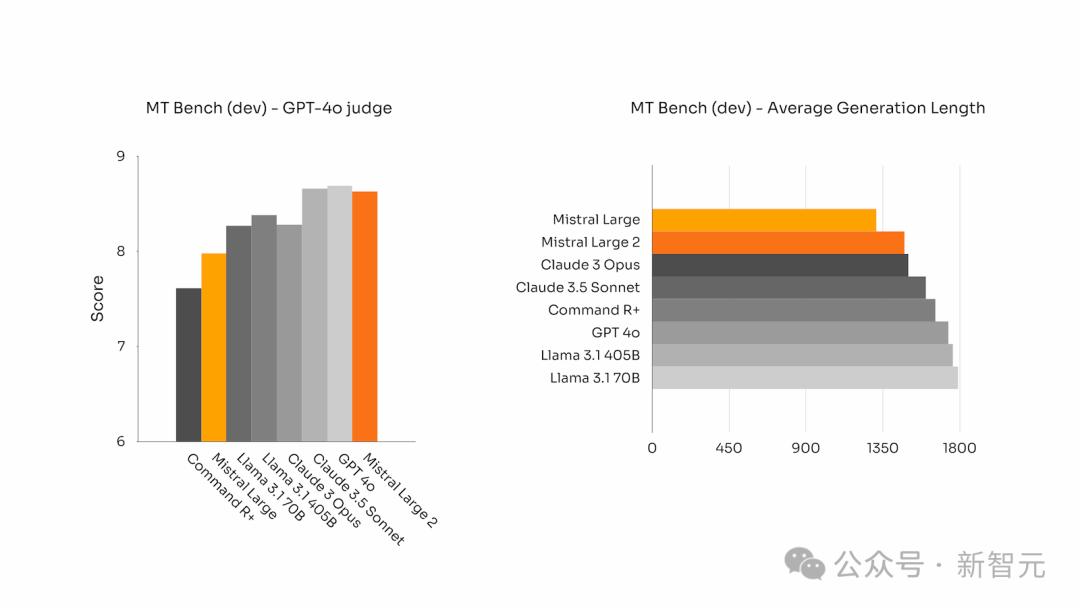
在一些基准测试中,生成较长的回答通常会提高得分。
然而,在许多商业应用中,答案的简洁至关重要——简短的模型响应可以促进更快速的交互,让推理过程更加高效且降低成本。
Mistral声称Large 2可以比领先的人工智能模型产生更简洁的响应,因为后者倾向于喋喋不休。
下图展示了不同模型在MT Bench基准测试中问题的平均生成长度:
语言多样性
如今,许多商业应用涉及处理多语言文档。
尽管大多数模型以英语为中心,但Mistral Large 2在大量多语言数据上进行了训练。
比如,在法语、德语、西班牙语、意大利语、葡萄牙语、荷兰语、俄语、中文、日语、韩语、阿拉伯语和印地语等多种语言上,Mistral Large 2都有出色的性能。
以下是Mistral Large 2在多语言MMLU基准测试中的表现结果,并与之前的Mistral Large、Llama 3.1模型以及Cohere的Command R+进行了比较:

在下图的8种语言上,Mistral Large 2的性能可以媲美Llama 3.1 405。但值得注意的是,所有模型似乎都在中文MMLU上取得了最低分。

工具使用与函数调用
Mistral Large 2具备了更强的函数调用和检索能力,能够熟练执行并行和顺序的函数调用,准确率甚至超过了GPT-4o。
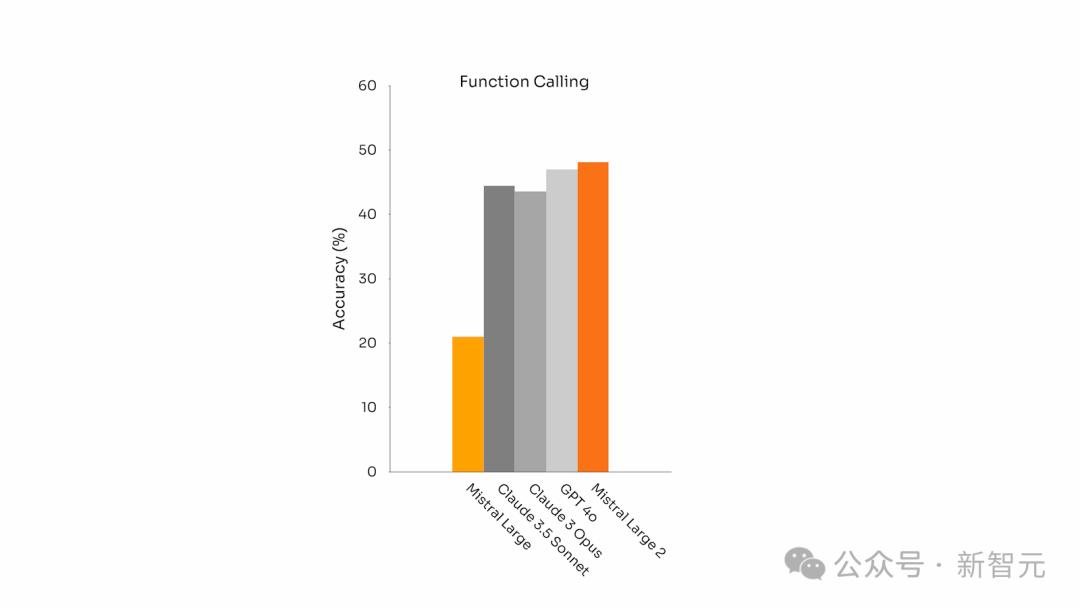
这意味着,Mistral Large 2可以成为复杂商业应用的核心引擎。
除了直接从HuggingFace上下载权重,用户可以通过官方API平台la Plateforme访问或微调模型,免费聊天机器人le chat也已经部署了Mistral Large 2。
Vertex AI、Azure Studio等第三方云平台也托管了Mistral Large 2的API。

参考资料:
https://mistral.ai/news/mistral-large-2407/
https://techcrunch.com/2024/07/24/mistral-releases-large-2-meta-openai-ai-models/
https://venturebeat.com/ai/mistral-shocks-with-new-open-model-mistral-large-2-taking-on-llama-3-1/
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享]👈

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的所有 ⚡️ 大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
全套 《LLM大模型入门+进阶学习资源包》↓↓↓ 获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享👈