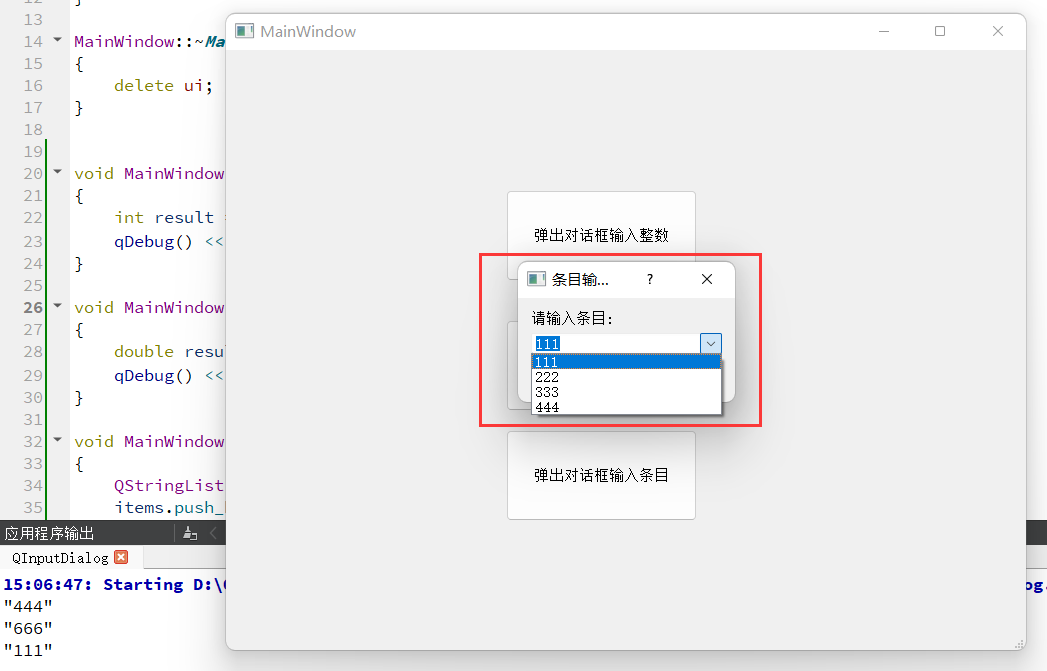
日期
心得
昇思MindSpore 应用学习-CycleGAN图像风格迁移互换(AI代码学习)
CycleGAN图像风格迁移互换
模型介绍
模型简介
CycleGAN(Cycle Generative Adversarial Network) 即循环对抗生成网络,来自论文 Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks 。该模型实现了一种在没有配对示例的情况下学习将图像从源域 X 转换到目标域 Y 的方法。
该模型一个重要应用领域是域迁移(Domain Adaptation),可以通俗地理解为图像风格迁移。其实在 CycleGAN 之前,就已经有了域迁移模型,比如 Pix2Pix ,但是 Pix2Pix 要求训练数据必须是成对的,而现实生活中,要找到两个域(画风)中成对出现的图片是相当困难的,因此 CycleGAN 诞生了,它只需要两种域的数据,而不需要他们有严格对应关系,是一种新的无监督的图像迁移网络。
模型结构
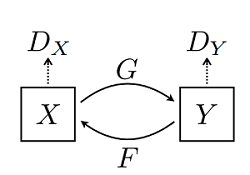
CycleGAN 网络本质上是由两个镜像对称的 GAN 网络组成,其结构如下图所示(图片来源于原论文):
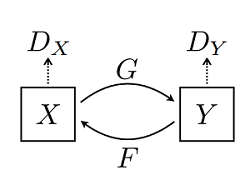
为了方便理解,这里以苹果和橘子为例介绍。上图中 X𝑋 可以理解为苹果,Y𝑌 为橘子;G𝐺 为将苹果生成橘子风格的生成器,F𝐹 为将橘子生成的苹果风格的生成器,DX𝐷𝑋 和 DY𝐷𝑌 为其相应判别器,具体生成器和判别器的结构可见下文代码。模型最终能够输出两个模型的权重,分别将两种图像的风格进行彼此迁移,生成新的图像。
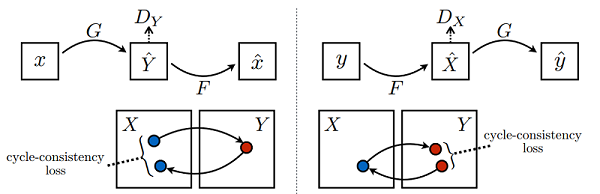
该模型一个很重要的部分就是损失函数,在所有损失里面循环一致损失(Cycle Consistency Loss)是最重要的。循环损失的计算过程如下图所示(图片来源于原论文):
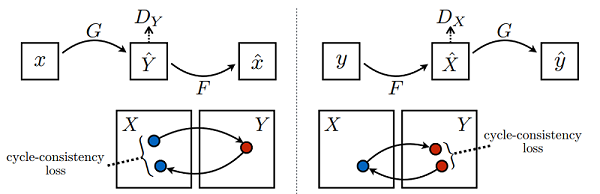
图中苹果图片 x𝑥 经过生成器 G𝐺 得到伪橘子 Y𝑌,然后将伪橘子 Y𝑌 结果送进生成器 F𝐹 又产生苹果风格的结果 x𝑥,最后将生成的苹果风格结果 x𝑥 与原苹果图片 x𝑥 一起计算出循环一致损失,反之亦然。循环损失捕捉了这样的直觉,即如果我们从一个域转换到另一个域,然后再转换回来,我们应该到达我们开始的地方。详细的训练过程见下文代码。
数据集
本案例使用的数据集里面的图片来源于ImageNet,该数据集共有17个数据包,本文只使用了其中的苹果橘子部分。图像被统一缩放为256×256像素大小,其中用于训练的苹果图片996张、橘子图片1020张,用于测试的苹果图片266张、橘子图片248张。
这里对数据进行了随机裁剪、水平随机翻转和归一化的预处理,为了将重点聚焦到模型,此处将数据预处理后的结果转换为 MindRecord 格式的数据,以省略大部分数据预处理的代码。
数据集下载
使用 download 接口下载数据集,并将下载后的数据集自动解压到当前目录下。数据下载之前需要使用 pip install download 安装 download 包。
from download import download # 从download模块导入download函数# 定义要下载的文件的URL
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/CycleGAN_apple2orange.zip"# 调用download函数下载文件
download(url, ".", kind="zip", replace=True) # 下载指定URL的zip文件到当前目录,若存在则替换
解析
- 从download模块导入download函数:
from download import download:这行代码导入了download模块中的download函数,这个函数用于处理文件下载。
- 定义文件URL:
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/CycleGAN_apple2orange.zip":这行代码定义了一个字符串变量url,它包含了要下载的文件的网络地址。
- 下载文件:
download(url, ".", kind="zip", replace=True):这行代码调用了download函数, 主要参数如下:url:要下载的文件的URL。".":表示文件将被下载到当前工作目录。kind="zip":指定下载文件的类型为zip格式。replace=True:如果目标目录中已经存在同名文件,则将其替换。
API 解析
- download(url, path, kind, replace):这是download模块中的一个函数,其主要功能是从指定的URL下载文件。
url:字符串类型,指定要下载文件的URL地址。path:字符串类型,指定下载文件保存的路径。kind:字符串类型,指定文件类型(如zip、tar等),用于处理特定类型的文件。replace:布尔类型,指示是否替换已存在的同名文件。
数据集加载
使用 MindSpore 的 MindDataset 接口读取和解析数据集。
from mindspore.dataset import MindDataset # 从mindspore.dataset模块导入MindDataset类# 读取MindRecord格式数据
name_mr = "./CycleGAN_apple2orange/apple2orange_train.mindrecord" # 定义MindRecord文件的路径
data = MindDataset(dataset_files=name_mr) # 创建MindDataset对象,加载指定的MindRecord文件
print("Datasize: ", data.get_dataset_size()) # 打印数据集的大小batch_size = 1 # 定义每个批次的样本大小
dataset = data.batch(batch_size) # 将数据集分批处理,指定批次大小
datasize = dataset.get_dataset_size() # 获取分批后的数据集大小
解析
- 导入MindDataset:
from mindspore.dataset import MindDataset:这行代码从MindSpore的dataset模块中导入MindDataset类,用于处理MindRecord格式的数据集。
- 定义MindRecord文件路径:
name_mr = "./CycleGAN_apple2orange/apple2orange_train.mindrecord":定义一个字符串变量name_mr,其值为MindRecord格式数据文件的路径。
- 加载数据集:
data = MindDataset(dataset_files=name_mr):调用MindDataset类构造函数,创建一个data对象,该对象加载了指定的MindRecord文件。
- 获取并打印数据集大小:
print("Datasize: ", data.get_dataset_size()):调用get_dataset_size()方法来获取数据集中的样本数量,并打印输出。
- 定义批次大小:
batch_size = 1:定义批次大小为1,即每次处理1个样本。
- 分批处理数据集:
dataset = data.batch(batch_size):调用batch()方法将数据集分批处理,生成一个新的数据集dataset,每个批次包含batch_size个样本。
- 获取分批后的数据集大小:
datasize = dataset.get_dataset_size():调用get_dataset_size()方法获取分批后的数据集大小。
API 解析
- MindDataset(dataset_files):这是MindSpore中用于加载MindRecord数据集的类。
dataset_files:字符串或字符串列表,指定要加载的MindRecord文件路径。
- get_dataset_size():这是
MindDataset类的方法,返回数据集中样本的数量。 - batch(batch_size):这是
MindDataset类的方法,用于将数据集分批处理。batch_size:整数,指定每个批次中包含的样本数量,返回一个新的数据集对象。
可视化
通过 create_dict_iterator 函数将数据转换成字典迭代器,然后使用 matplotlib 模块可视化部分训练数据。
import numpy as np # 导入numpy库,用于数值计算
import matplotlib.pyplot as plt # 导入matplotlib.pyplot库,用于绘图mean = 0.5 * 255 # 定义均值,用于反归一化处理
std = 0.5 * 255 # 定义标准差,用于反归一化处理plt.figure(figsize=(12, 5), dpi=60) # 创建一个图形,设置大小为12x5英寸,分辨率为60 dpi
for i, data in enumerate(dataset.create_dict_iterator()): # 遍历数据集中的每个样本if i < 5: # 只处理前5个样本show_images_a = data["image_A"].asnumpy() # 获取图像A数据并转换为NumPy数组show_images_b = data["image_B"].asnumpy() # 获取图像B数据并转换为NumPy数组plt.subplot(2, 5, i+1) # 创建一个2行5列的子图,设置当前绘图位置show_images_a = (show_images_a[0] * std + mean).astype(np.uint8).transpose((1, 2, 0)) # 反归一化并调整数组维度plt.imshow(show_images_a) # 显示图像Aplt.axis("off") # 关闭坐标轴plt.subplot(2, 5, i+6) # 创建第二行的子图,设置当前绘图位置show_images_b = (show_images_b[0] * std + mean).astype(np.uint8).transpose((1, 2, 0)) # 反归一化并调整数组维度plt.imshow(show_images_b) # 显示图像Bplt.axis("off") # 关闭坐标轴else:break # 如果已处理5个样本,跳出循环
plt.show() # 显示图形
解析
- 导入库:
import numpy as np:导入NumPy库,用于高效的数值计算。import matplotlib.pyplot as plt:导入Matplotlib的pyplot模块,以便于绘图和展示图像。
- 定义反归一化参数:
mean和std:用于数据的反归一化处理,将范围从[0, 1]映射回[0, 255]。
- 创建绘图窗口:
plt.figure(figsize=(12, 5), dpi=60):创建一个新图形,设置图形的宽度和高度以及分辨率。
- 遍历数据集:
for i, data in enumerate(dataset.create_dict_iterator()):使用create_dict_iterator()方法创建一个迭代器,遍历数据集中的每个样本。
- 处理和显示图像:
if i < 5::限制只处理前5个样本。show_images_a和show_images_b:从数据字典中提取图像A和图像B,使用asnumpy()方法将其转换为NumPy数组。
- 绘制图像:
plt.subplot(2, 5, i+1):在第i+1个位置绘制图像A。(show_images_a[0] * std + mean).astype(np.uint8).transpose((1, 2, 0)):对图像进行反归一化、转换数据类型为uint8,并调整维度顺序以符合imshow()的要求。plt.imshow(show_images_a):显示图像A。plt.axis("off"):关闭坐标轴。- 相似的步骤用于显示图像B。
- 显示图形:
plt.show():将图形展示出来。
API 解析
- create_dict_iterator():
MindDataset类的方法,返回一个字典迭代器,用于逐个获取数据集的样本。 - asnumpy():将MindSpore中的Tensor对象转换为NumPy数组。
- plt.figure():创建一个新的图形窗口。
- plt.subplot():创建一个子图,以便在同一图形中显示多个图像。
- plt.imshow():显示图像。
- plt.axis():控制坐标轴的显示。
- plt.show():展示当前图形窗口中的所有图像。
构建生成器
本案例生成器的模型结构参考的 ResNet 模型的结构,参考原论文,对于128×128大小的输入图片采用6个残差块相连,图片大小为256×256以上的需要采用9个残差块相连,所以本文网络有9个残差块相连,超参数 n_layers 参数控制残差块数。
生成器的结构如下所示:

具体的模型结构请参照下文代码:
import mindspore.nn as nn # 导入MindSpore的神经网络模块
import mindspore.ops as ops # 导入MindSpore的操作模块
from mindspore.common.initializer import Normal # 导入正态分布初始化器# 使用正态分布初始化权重
weight_init = Normal(sigma=0.02)class ConvNormReLU(nn.Cell): # 定义卷积-归一化-ReLU模块def __init__(self, input_channel, out_planes, kernel_size=4, stride=2, alpha=0.2, norm_mode='instance',pad_mode='CONSTANT', use_relu=True, padding=None, transpose=False):super(ConvNormReLU, self).__init__() # 调用父类构造函数norm = nn.BatchNorm2d(out_planes) # 初始化BatchNorm层if norm_mode == 'instance':norm = nn.BatchNorm2d(out_planes, affine=False) # 如果使用实例归一化has_bias = (norm_mode == 'instance') # 确定是否使用偏置if padding is None:padding = (kernel_size - 1) // 2 # 计算默认填充if pad_mode == 'CONSTANT':if transpose:conv = nn.Conv2dTranspose(input_channel, out_planes, kernel_size, stride, pad_mode='same',has_bias=has_bias, weight_init=weight_init) # 转置卷积else:conv = nn.Conv2d(input_channel, out_planes, kernel_size, stride, pad_mode='pad',has_bias=has_bias, padding=padding, weight_init=weight_init) # 常规卷积layers = [conv, norm] # 存储卷积层和归一化层else:paddings = ((0, 0), (0, 0), (padding, padding), (padding, padding)) # 定义填充的方式pad = nn.Pad(paddings=paddings, mode=pad_mode) # 创建填充层if transpose:conv = nn.Conv2dTranspose(input_channel, out_planes, kernel_size, stride, pad_mode='pad',has_bias=has_bias, weight_init=weight_init) # 转置卷积else:conv = nn.Conv2d(input_channel, out_planes, kernel_size, stride, pad_mode='pad',has_bias=has_bias, weight_init=weight_init) # 常规卷积layers = [pad, conv, norm] # 存储填充层、卷积层和归一化层if use_relu:relu = nn.ReLU() # 初始化ReLU激活层if alpha > 0:relu = nn.LeakyReLU(alpha) # 使用Leaky ReLU激活层layers.append(relu) # 添加激活层self.features = nn.SequentialCell(layers) # 将所有层组合成一个SequentialCelldef construct(self, x): # 前向传播方法output = self.features(x) # 通过特征层处理输入return output # 返回输出class ResidualBlock(nn.Cell): # 定义残差块def __init__(self, dim, norm_mode='instance', dropout=False, pad_mode="CONSTANT"):super(ResidualBlock, self).__init__() # 调用父类构造函数self.conv1 = ConvNormReLU(dim, dim, 3, 1, 0, norm_mode, pad_mode) # 第一个卷积self.conv2 = ConvNormReLU(dim, dim, 3, 1, 0, norm_mode, pad_mode, use_relu=False) # 第二个卷积self.dropout = dropout # 是否使用dropoutif dropout:self.dropout = nn.Dropout(p=0.5) # 初始化Dropout层def construct(self, x): # 前向传播方法out = self.conv1(x) # 通过第一个卷积处理输入if self.dropout:out = self.dropout(out) # 如果使用dropout,应用dropoutout = self.conv2(out) # 通过第二个卷积处理输出return x + out # 返回输入与残差相加的结果class ResNetGenerator(nn.Cell): # 定义ResNet生成器def __init__(self, input_channel=3, output_channel=64, n_layers=9, alpha=0.2, norm_mode='instance', dropout=False,pad_mode="CONSTANT"):super(ResNetGenerator, self).__init__() # 调用父类构造函数self.conv_in = ConvNormReLU(input_channel, output_channel, 7, 1, alpha, norm_mode, pad_mode=pad_mode) # 初始卷积层self.down_1 = ConvNormReLU(output_channel, output_channel * 2, 3, 2, alpha, norm_mode) # 下采样层1self.down_2 = ConvNormReLU(output_channel * 2, output_channel * 4, 3, 2, alpha, norm_mode) # 下采样层2layers = [ResidualBlock(output_channel * 4, norm_mode, dropout=dropout, pad_mode=pad_mode)] * n_layers # 残差块self.residuals = nn.SequentialCell(layers) # 将所有残差块组合成一个SequentialCellself.up_2 = ConvNormReLU(output_channel * 4, output_channel * 2, 3, 2, alpha, norm_mode, transpose=True) # 上采样层2self.up_1 = ConvNormReLU(output_channel * 2, output_channel, 3, 2, alpha, norm_mode, transpose=True) # 上采样层1if pad_mode == "CONSTANT":self.conv_out = nn.Conv2d(output_channel, 3, kernel_size=7, stride=1, pad_mode='pad',padding=3, weight_init=weight_init) # 输出卷积层else:pad = nn.Pad(paddings=((0, 0), (0, 0), (3, 3), (3, 3)), mode=pad_mode) # 创建填充层conv = nn.Conv2d(output_channel, 3, kernel_size=7, stride=1, pad_mode='pad', weight_init=weight_init) # 输出卷积层self.conv_out = nn.SequentialCell([pad, conv]) # 将填充层和卷积层组合def construct(self, x): # 前向传播方法x = self.conv_in(x) # 初始卷积处理x = self.down_1(x) # 下采样处理1x = self.down_2(x) # 下采样处理2x = self.residuals(x) # 残差块处理x = self.up_2(x) # 上采样处理2x = self.up_1(x) # 上采样处理1output = self.conv_out(x) # 输出卷积处理return ops.tanh(output) # 使用tanh激活函数返回输出# 实例化生成器
net_rg_a = ResNetGenerator() # 创建生成器A
net_rg_a.update_parameters_name('net_rg_a.') # 更新参数名称net_rg_b = ResNetGenerator() # 创建生成器B
net_rg_b.update_parameters_name('net_rg_b.') # 更新参数名称
解析
- 导入库:
import mindspore.nn as nn:导入MindSpore的神经网络模块。import mindspore.ops as ops:导入MindSpore的操作模块。from mindspore.common.initializer import Normal:导入正态分布初始化器,用于权重初始化。
- 权重初始化:
weight_init = Normal(sigma=0.02):定义权重初始化使用正态分布,标准差为0.02。
- ConvNormReLU类:
- 该类实现了卷积层、归一化层(可选择实例归一化)和激活层(ReLU或LeakyReLU)的组合。
- 构造函数中,设置了卷积的参数、归一化方式、激活函数等。
- construct方法负责前向传播,使用定义的特征层处理输入。
- ResidualBlock类:
- 实现了一个基本的残差块结构。
- 包含两个卷积层,其中第二个卷积层默认不使用ReLU激活。
- 可以选择使用Dropout防止过拟合。
- construct方法中,执行前向传播并返回输入与卷积输出的和。
- ResNetGenerator类:
- 实现了一个具有多个下采样和上采样层的生成器结构,适合图像生成任务。
- 包含初始卷积、多个下采样层、多个残差块、上采样层及输出卷积层。
- construct方法实现了完整的前向传播流程,并使用tanh激活函数返回最终输出。
- 实例化生成器:
- 创建两个ResNet生成器实例
net_rg_a和net_rg_b,并分别更新它们的参数名称。
- 创建两个ResNet生成器实例
API 解析
- nn.Cell:MindSpore中所有神经网络模块的基类,提供了forward和backward的基本结构。
- nn.Conv2d / nn.Conv2dTranspose:二维卷积层和转置卷积层,用于卷积操作。
- nn.BatchNorm2d:二维批量归一化层,用于加速训练并提高稳定性。
- nn.ReLU / nn.LeakyReLU:激活函数,增加网络的非线性。
- nn.Dropout:在训练时随机丢弃一部分神经元,防止过拟合。
- nn.SequentialCell:将多个层串联在一起,形成一个新的复合层。
- ops.tanh:应用双曲正切激活函数,将输出值限制在-1到1之间。
构建判别器
判别器其实是一个二分类网络模型,输出判定该图像为真实图的概率。网络模型使用的是 Patch 大小为 70x70 的 PatchGANs 模型。通过一系列的 Conv2d 、 BatchNorm2d 和 LeakyReLU 层对其进行处理,最后通过 Sigmoid 激活函数得到最终概率。
# 定义判别器
class Discriminator(nn.Cell): # 创建判别器类,继承自nn.Celldef __init__(self, input_channel=3, output_channel=64, n_layers=3, alpha=0.2, norm_mode='instance'):super(Discriminator, self).__init__() # 调用父类构造函数kernel_size = 4 # 定义卷积核大小layers = [nn.Conv2d(input_channel, output_channel, kernel_size, 2, pad_mode='pad', padding=1, weight_init=weight_init), # 第一个卷积层nn.LeakyReLU(alpha)] # 使用LeakyReLU激活函数nf_mult = output_channel # 初始化当前输出通道数for i in range(1, n_layers): # 构建多个卷积层nf_mult_prev = nf_mult # 保存前一个通道数nf_mult = min(2 ** i, 8) * output_channel # 计算当前卷积层的输出通道数layers.append(ConvNormReLU(nf_mult_prev, nf_mult, kernel_size, 2, alpha, norm_mode, padding=1)) # 添加卷积-归一化-ReLU层nf_mult_prev = nf_mult # 保存最后一个卷积层的输出通道数nf_mult = min(2 ** n_layers, 8) * output_channel # 计算最后一个卷积层的输出通道数layers.append(ConvNormReLU(nf_mult_prev, nf_mult, kernel_size, 1, alpha, norm_mode, padding=1)) # 添加最后的卷积-归一化-ReLU层layers.append(nn.Conv2d(nf_mult, 1, kernel_size, 1, pad_mode='pad', padding=1, weight_init=weight_init)) # 添加输出层self.features = nn.SequentialCell(layers) # 将所有层组合成一个SequentialCelldef construct(self, x): # 前向传播方法output = self.features(x) # 通过特征层处理输入return output # 返回输出# 判别器初始化
net_d_a = Discriminator() # 创建判别器A
net_d_a.update_parameters_name('net_d_a.') # 更新参数名称net_d_b = Discriminator() # 创建判别器B
net_d_b.update_parameters_name('net_d_b.') # 更新参数名称
解析
- Discriminator类:
- 该类实现了图像的判别器结构,其主要功能是判断输入图像是真实的还是生成的。
- 构造函数中,设置了输入通道、输出通道、层数、激活函数等。
- 卷积层:使用
nn.Conv2d进行卷积操作,pad_mode和padding参数确保输出的尺寸符合预期。 - 激活函数:使用
nn.LeakyReLU激活函数来增加非线性。
- 卷积层构建:
- 第一个卷积层具有输入通道和输出通道,使用
kernel_size为4的卷积核,步幅为2。 - 接下来的层通过循环构建,使用
ConvNormReLU模块逐层增加特征图的深度。 - 最后一个卷积层将特征图压缩到1个通道,生成最终的判别结果。
- 第一个卷积层具有输入通道和输出通道,使用
- construct方法:
- 实现了前向传播逻辑,通过
self.features处理输入并返回输出。
- 实现了前向传播逻辑,通过
- 判别器初始化:
- 创建两个
Discriminator实例net_d_a和net_d_b,并分别更新它们的参数名称以便于管理。
- 创建两个
API 解析
- nn.Cell:MindSpore中所有神经网络模块的基类,提供了forward和backward的基本结构。
- nn.Conv2d:二维卷积层,用于卷积操作,参数包括输入通道、输出通道、卷积核大小、步幅等。
- nn.LeakyReLU:带泄露的ReLU激活函数,防止神经元死亡,同时增加网络的非线性。
- nn.SequentialCell:将多个层串联在一起,形成一个新的复合层。
- update_parameters_name():用于更新网络中所有参数的名称,以便于跟踪和管理。
优化器和损失函数
根据不同模型需要单独的设置优化器,这是训练过程决定的。
对生成器 及其判别器 ,目标损失函数定义为:
其中 试图生成看起来与 中的图像相似的图像 ,而 的目标是区分翻译样本 和真实样本 ,生成器的目标是最小化这个损失函数以此来对抗判别器。即 。
单独的对抗损失不能保证所学函数可以将单个输入映射到期望的输出,为了进一步减少可能的映射函数的空间,学习到的映射函数应该是周期一致的,例如对于 的每个图像 ,图像转换周期应能够将 带回原始图像,可以称之为正向循环一致性,即 。对于 ,类似的 。可以理解采用了一个循环一致性损失来激励这种行为。
循环一致损失函数定义如下:
循环一致损失能够保证重建图像 与输入图像 紧密匹配。
# 构建生成器,判别器优化器
optimizer_rg_a = nn.Adam(net_rg_a.trainable_params(), learning_rate=0.0002, beta1=0.5) # 为生成器A创建Adam优化器
optimizer_rg_b = nn.Adam(net_rg_b.trainable_params(), learning_rate=0.0002, beta1=0.5) # 为生成器B创建Adam优化器optimizer_d_a = nn.Adam(net_d_a.trainable_params(), learning_rate=0.0002, beta1=0.5) # 为判别器A创建Adam优化器
optimizer_d_b = nn.Adam(net_d_b.trainable_params(), learning_rate=0.0002, beta1=0.5) # 为判别器B创建Adam优化器# GAN网络损失函数,这里最后一层不使用sigmoid函数
loss_fn = nn.MSELoss(reduction='mean') # 定义均方误差损失函数,使用均值作为减少方式
l1_loss = nn.L1Loss("mean") # 定义L1损失函数,使用均值作为减少方式def gan_loss(predict, target): # 定义GAN损失计算函数target = ops.ones_like(predict) * target # 生成目标张量,其与预测张量形状相同loss = loss_fn(predict, target) # 计算损失return loss # 返回损失值
解析
- 优化器构建:
- 使用
nn.Adam创建Adam优化器来优化生成器和判别器的参数。 learning_rate=0.0002设置学习率,beta1=0.5设置一阶矩估计的衰减率,这在GAN训练中常用以稳定训练过程。- 四个优化器的参数分别对应生成器A、生成器B和判别器A、判别器B。
- 使用
- 损失函数:
loss_fn = nn.MSELoss(reduction='mean'):定义均方误差损失函数,常用于回归任务。reduction='mean'表示计算损失时取均值。l1_loss = nn.L1Loss("mean"):定义L1损失函数,通常用于图像重建任务和正则化。
- GAN损失函数:
def gan_loss(predict, target):定义一个计算GAN损失的函数。target = ops.ones_like(predict) * target:创建一个与预测张量形状相同的目标张量,其元素值全为目标值(通常是1或0),以便于计算损失。loss = loss_fn(predict, target):计算预测与目标之间的损失。- 最后返回计算得到的损失值。
API 解析
- nn.Adam:Adam优化器,结合了Momentum和RMSProp的优点,适合处理大规模数据和高维参数。
- trainable_params():返回网络中可训练的参数列表,以便优化器更新这些参数。
- nn.MSELoss:均方误差损失函数,计算预测值与目标值之间的平方差的均值。
- nn.L1Loss:L1损失函数,计算预测值与目标值之间的绝对差的均值。
- ops.ones_like():生成一个与指定张量形状相同且所有元素为1的张量。
前向计算
搭建模型前向计算损失的过程,过程如下代码。
为了减少模型振荡[1],这里遵循 Shrivastava 等人的策略[2],使用生成器生成图像的历史数据而不是生成器生成的最新图像数据来更新鉴别器。这里创建 image_pool 函数,保留了一个图像缓冲区,用于存储生成器生成前的50个图像。
import mindspore as ms # 导入MindSpore框架# 前向计算
def generator(img_a, img_b): # 定义生成器前向计算函数fake_a = net_rg_b(img_b) # 使用生成器B生成假图像Afake_b = net_rg_a(img_a) # 使用生成器A生成假图像Brec_a = net_rg_b(fake_b) # 使用生成器B重建图像Arec_b = net_rg_a(fake_a) # 使用生成器A重建图像Bidentity_a = net_rg_b(img_a) # 使用生成器B计算图像A的身份映射identity_b = net_rg_a(img_b) # 使用生成器A计算图像B的身份映射return fake_a, fake_b, rec_a, rec_b, identity_a, identity_b # 返回生成的图像和重建的图像# 定义损失权重
lambda_a = 10.0 # 重建图像A的权重
lambda_b = 10.0 # 重建图像B的权重
lambda_idt = 0.5 # 身份映射的权重def generator_forward(img_a, img_b): # 定义生成器的前向传播完整过程true = ms.Tensor(True, dtype=ms.bool_) # 创建一个布尔类型的Tensor,值为Truefake_a, fake_b, rec_a, rec_b, identity_a, identity_b = generator(img_a, img_b) # 调用生成器loss_g_a = gan_loss(net_d_b(fake_b), true) # 计算生成器A的GAN损失loss_g_b = gan_loss(net_d_a(fake_a), true) # 计算生成器B的GAN损失loss_c_a = l1_loss(rec_a, img_a) * lambda_a # 计算重建图像A的损失loss_c_b = l1_loss(rec_b, img_b) * lambda_b # 计算重建图像B的损失loss_idt_a = l1_loss(identity_a, img_a) * lambda_a * lambda_idt # 计算身份映射A的损失loss_idt_b = l1_loss(identity_b, img_b) * lambda_b * lambda_idt # 计算身份映射B的损失loss_g = loss_g_a + loss_g_b + loss_c_a + loss_c_b + loss_idt_a + loss_idt_b # 总生成器损失return fake_a, fake_b, loss_g, loss_g_a, loss_g_b, loss_c_a, loss_c_b, loss_idt_a, loss_idt_b # 返回相关损失和生成图像def generator_forward_grad(img_a, img_b): # 定义生成器前向传播的梯度_, _, loss_g, _, _, _, _, _, _ = generator_forward(img_a, img_b) # 仅获取损失值return loss_g # 返回生成器损失def discriminator_forward(img_a, img_b, fake_a, fake_b): # 定义判别器的前向传播false = ms.Tensor(False, dtype=ms.bool_) # 创建一个布尔类型的Tensor,值为Falsetrue = ms.Tensor(True, dtype=ms.bool_) # 创建一个布尔类型的Tensor,值为Trued_fake_a = net_d_a(fake_a) # 判别假图像Ad_img_a = net_d_a(img_a) # 判别真实图像Ad_fake_b = net_d_b(fake_b) # 判别假图像Bd_img_b = net_d_b(img_b) # 判别真实图像Bloss_d_a = gan_loss(d_fake_a, false) + gan_loss(d_img_a, true) # 计算判别器A的损失loss_d_b = gan_loss(d_fake_b, false) + gan_loss(d_img_b, true) # 计算判别器B的损失loss_d = (loss_d_a + loss_d_b) * 0.5 # 总判别器损失取平均return loss_d # 返回判别器损失def discriminator_forward_a(img_a, fake_a): # 定义判别器A的前向传播false = ms.Tensor(False, dtype=ms.bool_) # 创建False Tensortrue = ms.Tensor(True, dtype=ms.bool_) # 创建True Tensord_fake_a = net_d_a(fake_a) # 判别假图像Ad_img_a = net_d_a(img_a) # 判别真实图像Aloss_d_a = gan_loss(d_fake_a, false) + gan_loss(d_img_a, true) # 计算判别器A的损失return loss_d_a # 返回判别器A的损失def discriminator_forward_b(img_b, fake_b): # 定义判别器B的前向传播false = ms.Tensor(False, dtype=ms.bool_) # 创建False Tensortrue = ms.Tensor(True, dtype=ms.bool_) # 创建True Tensord_fake_b = net_d_b(fake_b) # 判别假图像Bd_img_b = net_d_b(img_b) # 判别真实图像Bloss_d_b = gan_loss(d_fake_b, false) + gan_loss(d_img_b, true) # 计算判别器B的损失return loss_d_b # 返回判别器B的损失# 保留了一个图像缓冲区,用来存储之前创建的50个图像
pool_size = 50 # 定义图像池的大小def image_pool(images): # 定义图像池函数num_imgs = 0 # 初始化图像计数image1 = [] # 创建一个空列表存储图像if isinstance(images, ms.Tensor): # 检查输入是否为Tensorimages = images.asnumpy() # 将Tensor转换为numpy数组return_images = [] # 创建一个空列表存储返回的图像for image in images: # 遍历输入图像if num_imgs < pool_size: # 如果图像数量小于池大小num_imgs = num_imgs + 1 # 计数器加一image1.append(image) # 添加图像到池return_images.append(image) # 添加图像到返回列表else: # 如果池已满if random.uniform(0, 1) > 0.5: # 随机选择random_id = random.randint(0, pool_size - 1) # 选择随机池中的图像tmp = image1[random_id].copy() # 复制随机图像image1[random_id] = image # 用新图像替换池中的图像return_images.append(tmp) # 将复制的图像添加到返回列表else:return_images.append(image) # 将新图像添加到返回列表output = ms.Tensor(return_images, ms.float32) # 转换返回图像列表为Tensorif output.ndim != 4: # 确保输出是4维raise ValueError("img should be 4d, but get shape {}".format(output.shape)) # 报错return output # 返回图像池的输出
解析
- 生成器前向计算 (
generator函数):- 使用生成器生成假图像,进行重建和身份映射。
- 返回生成的假图像和重建的图像。
- 生成器损失计算 (
generator_forward函数):- 计算生成器的各项损失,包括GAN损失、重建损失和身份损失。
- 返回生成的假图像和总损失。
- 生成器梯度计算 (
generator_forward_grad函数):- 获取生成器的损失值,用于后续的反向传播。
- 判别器前向传播 (
discriminator_forward函数):- 判别器区分真实图像和生成图像,并计算损失。
- 单独判别器损失计算 (
discriminator_forward_a和discriminator_forward_b函数):- 分别计算判别器A和判别器B的损失。
- 图像池 (
image_pool函数):- 实现图像池机制,存储和更新图像以提高训练的稳定性。
- 控制图像的数量不超过指定的池大小,随机替换图像。
API 解析
- Tensor:MindSpore中的张量类,用于数据存储和计算。
- random.uniform() 和 random.randint():用于生成随机数,控制图像池的行为。
- asnumpy():将MindSpore的Tensor转换为NumPy数组,便于处理。
- ndim:获取张量的维度,用于检查输出形状。
- ValueError:引发错误,当条件不满足时。
计算梯度和反向传播
其中梯度计算也是分开不同的模型来进行的,详情见如下代码:
from mindspore import value_and_grad # 从MindSpore导入value_and_grad函数# 实例化求梯度的方法
grad_g_a = value_and_grad(generator_forward_grad, None, net_rg_a.trainable_params()) # 为生成器A创建梯度计算
grad_g_b = value_and_grad(generator_forward_grad, None, net_rg_b.trainable_params()) # 为生成器B创建梯度计算grad_d_a = value_and_grad(discriminator_forward_a, None, net_d_a.trainable_params()) # 为判别器A创建梯度计算
grad_d_b = value_and_grad(discriminator_forward_b, None, net_d_b.trainable_params()) # 为判别器B创建梯度计算# 计算生成器的梯度,反向传播更新参数
def train_step_g(img_a, img_b): # 定义训练生成器的步骤net_d_a.set_grad(False) # 禁用判别器A的梯度计算net_d_b.set_grad(False) # 禁用判别器B的梯度计算fake_a, fake_b, lg, lga, lgb, lca, lcb, lia, lib = generator_forward(img_a, img_b) # 生成图像并计算损失_, grads_g_a = grad_g_a(img_a, img_b) # 计算生成器A的梯度_, grads_g_b = grad_g_b(img_a, img_b) # 计算生成器B的梯度optimizer_rg_a(grads_g_a) # 更新生成器A的参数optimizer_rg_b(grads_g_b) # 更新生成器B的参数return fake_a, fake_b, lg, lga, lgb, lca, lcb, lia, lib # 返回生成的图像和损失# 计算判别器的梯度,反向传播更新参数
def train_step_d(img_a, img_b, fake_a, fake_b): # 定义训练判别器的步骤net_d_a.set_grad(True) # 启用判别器A的梯度计算net_d_b.set_grad(True) # 启用判别器B的梯度计算loss_d_a, grads_d_a = grad_d_a(img_a, fake_a) # 计算判别器A的损失和梯度loss_d_b, grads_d_b = grad_d_b(img_b, fake_b) # 计算判别器B的损失和梯度loss_d = (loss_d_a + loss_d_b) * 0.5 # 计算判别器的总损失optimizer_d_a(grads_d_a) # 更新判别器A的参数optimizer_d_b(grads_d_b) # 更新判别器B的参数return loss_d # 返回判别器总损失
解析
- 梯度计算实例化:
- 使用
value_and_grad函数为生成器和判别器的前向传播函数创建梯度计算对象。 - 这将返回损失值和梯度,以便后续的参数更新。
- 使用
- 生成器训练步骤 (
train_step_g函数):- 设置判别器的梯度计算为
False,表示在训练生成器时不更新判别器的权重。 - 调用
generator_forward计算生成器的输出和损失。 - 计算生成器A和B的梯度,并使用相应的优化器更新参数。
- 返回生成的假图像和各类损失值,便于后续分析和监控训练过程。
- 设置判别器的梯度计算为
- 判别器训练步骤 (
train_step_d函数):- 设置判别器的梯度计算为
True,表示在训练判别器时需要更新权重。 - 计算判别器A和B的损失及梯度。
- 计算判别器的总损失,并使用优化器更新参数。
- 返回判别器的总损失,帮助评估模型性能。
- 设置判别器的梯度计算为
API 解析
- value_and_grad:MindSpore中的函数,用于同时计算给定函数的输出和梯度,常用于自动微分。
- set_grad:控制网络的梯度计算开关,
True表示启用,False表示禁用。 - trainable_params():返回网络中所有可训练的参数,供优化器进行更新。
- optimizer:优化器对象,用于更新模型的参数以最小化损失。
这种结构的设计使得生成器和判别器各自能够独立地进行训练和梯度更新,从而实现对抗训练的目的。
模型训练
训练分为两个主要部分:训练判别器和训练生成器,在前文的判别器损失函数中,论文采用了最小二乘损失代替负对数似然目标。
- 训练判别器:训练判别器的目的是最大程度地提高判别图像真伪的概率。按照论文的方法需要训练判别器来最小化 ;
- 训练生成器:如 CycleGAN 论文所述,我们希望通过最小化 来训练生成器,以产生更好的虚假图像。
下面定义了生成器和判别器的训练过程:
import os # 导入os模块,用于文件和目录操作
import time # 导入time模块,用于时间管理
import random # 导入random模块,用于生成随机数
import numpy as np # 导入numpy,用于数值计算
from PIL import Image # 导入PIL库,用于图像处理
from mindspore import Tensor, save_checkpoint # 从MindSpore导入Tensor和保存检查点的函数
from mindspore import dtype # 导入数据类型模块# 由于时间原因,epochs设置为1,可根据需求进行调整
epochs = 1 # 设置训练周期
save_step_num = 80 # 每多少步保存一次模型
save_checkpoint_epochs = 1 # 每多少个epoch保存一次模型
save_ckpt_dir = './train_ckpt_outputs/' # 保存检查点的目录print('Start training!') # 输出训练开始的信息for epoch in range(epochs): # 遍历每个训练周期g_loss = [] # 初始化生成器损失列表d_loss = [] # 初始化判别器损失列表start_time_e = time.time() # 记录每个epoch的开始时间for step, data in enumerate(dataset.create_dict_iterator()): # 遍历数据集start_time_s = time.time() # 记录每个步骤的开始时间img_a = data["image_A"] # 获取图像Aimg_b = data["image_B"] # 获取图像Bres_g = train_step_g(img_a, img_b) # 训练生成器,获取结果fake_a = res_g[0] # 提取伪造的图像Afake_b = res_g[1] # 提取伪造的图像Bres_d = train_step_d(img_a, img_b, image_pool(fake_a), image_pool(fake_b)) # 训练判别器loss_d = float(res_d.asnumpy()) # 获取判别器的损失step_time = time.time() - start_time_s # 计算步骤耗时res = [] # 初始化结果列表for item in res_g[2:]: # 遍历生成器损失res.append(float(item.asnumpy())) # 将损失转换为浮点数并添加到结果列表g_loss.append(res[0]) # 添加生成器总损失d_loss.append(loss_d) # 添加判别器损失# 每隔一定步数打印损失信息if step % save_step_num == 0:print(f"Epoch:[{int(epoch + 1):>3d}/{int(epochs):>3d}], "f"step:[{int(step):>4d}/{int(datasize):>4d}], "f"time:{step_time:>3f}s,\n"f"loss_g:{res[0]:.2f}, loss_d:{loss_d:.2f}, "f"loss_g_a: {res[1]:.2f}, loss_g_b: {res[2]:.2f}, "f"loss_c_a: {res[3]:.2f}, loss_c_b: {res[4]:.2f}, "f"loss_idt_a: {res[5]:.2f}, loss_idt_b: {res[6]:.2f}")epoch_cost = time.time() - start_time_e # 计算当前epoch的耗时per_step_time = epoch_cost / datasize # 计算每个步骤平均耗时mean_loss_d, mean_loss_g = sum(d_loss) / datasize, sum(g_loss) / datasize # 计算平均损失print(f"Epoch:[{int(epoch + 1):>3d}/{int(epochs):>3d}], "f"epoch time:{epoch_cost:.2f}s, per step time:{per_step_time:.2f}, "f"mean_g_loss:{mean_loss_g:.2f}, mean_d_loss:{mean_loss_d :.2f}")# 保存模型检查点if epoch % save_checkpoint_epochs == 0:os.makedirs(save_ckpt_dir, exist_ok=True) # 创建保存目录save_checkpoint(net_rg_a, os.path.join(save_ckpt_dir, f"g_a_{epoch}.ckpt")) # 保存生成器Asave_checkpoint(net_rg_b, os.path.join(save_ckpt_dir, f"g_b_{epoch}.ckpt")) # 保存生成器Bsave_checkpoint(net_d_a, os.path.join(save_ckpt_dir, f"d_a_{epoch}.ckpt")) # 保存判别器Asave_checkpoint(net_d_b, os.path.join(save_ckpt_dir, f"d_b_{epoch}.ckpt")) # 保存判别器Bprint('End of training!') # 输出训练结束的信息
解析
- 导入必要的库:
- 使用
os、time、random、numpy和PIL处理文件、时间、随机数和图像操作。 - 从
mindspore导入Tensor和save_checkpoint函数以处理模型的张量和保存功能。
- 使用
- 设置训练参数:
epochs:训练的周期数,当前设置为1。save_step_num:每隔多少步保存一次模型。save_checkpoint_epochs:每隔多少个周期保存一次模型。save_ckpt_dir:模型检查点保存的目录。
- 开始训练:
- 使用
for循环遍历每个周期。 - 在每个周期中,初始化生成器和判别器的损失列表。
- 记录周期开始的时间并遍历数据集。
- 使用
- 训练生成器和判别器:
- 在每个步骤中,从数据集中获取图像。
- 使用
train_step_g训练生成器并获取生成的假图像和损失。 - 使用
train_step_d训练判别器并计算损失。 - 每隔一定的步骤打印当前的损失信息以监控训练过程。
- 计算和打印损失:
- 计算当前周期的耗时以及每步的平均耗时。
- 计算并打印生成器和判别器的平均损失。
- 保存模型检查点:
- 在指定的周期保存生成器和判别器的检查点,便于后续继续训练或评估。
API 解析
- os.makedirs:创建目录,如果目录已存在,则不报错。
- save_checkpoint:将模型的状态保存到指定文件,便于后续恢复或评估。
- create_dict_iterator:创建一个字典迭代器,遍历数据集中的数据。
- asnumpy():将MindSpore的Tensor转换为NumPy数组,便于后续处理和打印。
这种结构化的训练循环可以确保在每个epoch中有效地更新模型的参数,同时监控训练的进展和性能。
模型推理
下面我们通过加载生成器网络模型参数文件来对原图进行风格迁移,结果中第一行为原图,第二行为对应生成的结果图。
import os # 导入os模块,用于操作文件和目录
from PIL import Image # 导入PIL库,用于图像处理
import mindspore.dataset as ds # 导入MindSpore数据集模块
import mindspore.dataset.vision as vision # 导入MindSpore视觉处理模块
from mindspore import load_checkpoint, load_param_into_net # 导入加载检查点的函数# 加载权重文件
def load_ckpt(net, ckpt_dir): # 定义加载检查点的函数param_GA = load_checkpoint(ckpt_dir) # 从指定路径加载检查点load_param_into_net(net, param_GA) # 将参数加载到网络中# 指定生成器A和B的检查点路径
g_a_ckpt = './CycleGAN_apple2orange/ckpt/g_a.ckpt' # 生成器A的检查点路径
g_b_ckpt = './CycleGAN_apple2orange/ckpt/g_b.ckpt' # 生成器B的检查点路径# 加载检查点到网络
load_ckpt(net_rg_a, g_a_ckpt) # 加载生成器A的权重
load_ckpt(net_rg_b, g_b_ckpt) # 加载生成器B的权重# 图片推理
fig = plt.figure(figsize=(11, 2.5), dpi=100) # 创建绘图图形def eval_data(dir_path, net, a): # 定义评估数据的函数def read_img(): # 嵌套函数,读取图像for dir in os.listdir(dir_path): # 遍历目录中的文件path = os.path.join(dir_path, dir) # 获取文件完整路径img = Image.open(path).convert('RGB') # 打开并转换为RGB格式yield img, dir # 生成器返回图像和文件名# 创建数据集dataset = ds.GeneratorDataset(read_img, column_names=["image", "image_name"]) # 创建生成器数据集# 定义图像预处理操作trans = [vision.Resize((256, 256)), # 调整图像大小vision.Normalize(mean=[0.5 * 255] * 3, std=[0.5 * 255] * 3), # 归一化处理vision.HWC2CHW()] # 将图像格式从HWC转为CHWdataset = dataset.map(operations=trans, input_columns=["image"]) # 应用预处理操作dataset = dataset.batch(1) # 设置批次大小为1# 遍历数据集进行推理for i, data in enumerate(dataset.create_dict_iterator()): # 创建迭代器遍历数据集img = data["image"] # 获取图像数据fake = net(img) # 使用网络生成假图像fake = (fake[0] * 0.5 * 255 + 0.5 * 255).astype(np.uint8).transpose((1, 2, 0)) # 处理假图像img = (img[0] * 0.5 * 255 + 0.5 * 255).astype(np.uint8).transpose((1, 2, 0)) # 处理真实图像# 添加真实图像到绘图fig.add_subplot(2, 8, i + 1 + a) # 设置子图位置plt.axis("off") # 关闭坐标轴plt.imshow(img) # 显示真实图像# 添加假图像到绘图fig.add_subplot(2, 8, i + 9 + a) # 设置子图位置plt.axis("off") # 关闭坐标轴plt.imshow(fake) # 显示假图像# 评估苹果和橙子的图像
eval_data('./CycleGAN_apple2orange/predict/apple', net_rg_a, 0) # 评估苹果图像
eval_data('./CycleGAN_apple2orange/predict/orange', net_rg_b, 4) # 评估橙子图像
plt.show() # 显示绘图
解析
- 导入必要的库:
- 使用
os进行目录和文件操作。 - 使用
PIL处理图像。 - 使用
mindspore.dataset和mindspore.dataset.vision创建和处理数据集。
- 使用
- 定义加载检查点的函数:
load_ckpt函数用于加载指定路径的检查点,并将参数加载到网络模型中。
- 加载生成器的权重:
- 指定生成器A和B的检查点路径。
- 调用
load_ckpt函数加载生成器的权重参数。
- 图像推理的设置:
- 创建一个图形用于绘制结果。
- 定义评估数据的函数
eval_data,用于读取图像并进行推理。
- 读取图像和创建数据集:
- 使用
os.listdir遍历指定目录,读取所有图像。 - 使用数据集的生成器功能创建数据集,并定义图像预处理操作(缩放、归一化)。
- 使用
- 推理和处理图像:
- 遍历数据集,使用生成器进行推理,生成假图像。
- 将处理后的真实图像和假图像添加到绘图中。
- 评估和显示结果:
- 调用
eval_data函数分别评估苹果和橙子的图像,并将结果显示在图形上。
- 调用
API 解析
- load_checkpoint:用于加载保存的模型检查点。
- load_param_into_net:将加载的参数设置到指定的网络模型中。
- GeneratorDataset:创建一个基于生成器的MindSpore数据集。
- map:对数据集中的每个元素应用指定的操作。
- asnumpy():将MindSpore的Tensor转换为NumPy数组,以便进行后续处理或绘图。
这个脚本展示了如何加载预训练模型并对新的图像数据进行推理,同时可视化生成的结果。
整体代码
#!/usr/bin/env python
# coding: utf-8# # CycleGAN图像风格迁移互换
#
# [](https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/r2.3/tutorials/application/zh_cn/generative/mindspore_cyclegan.ipynb) [](https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/r2.3/tutorials/application/zh_cn/generative/mindspore_cyclegan.py) [](https://gitee.com/mindspore/docs/blob/r2.3/tutorials/application/source_zh_cn/generative/cyclegan.ipynb)
#
# > 本案例运行需要较大内存,建议在Ascend/GPU上运行。
# # ## 模型介绍
#
# ### 模型简介
#
# CycleGAN(Cycle Generative Adversarial Network) 即循环对抗生成网络,来自论文 [Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks](https://arxiv.org/abs/1703.10593) 。该模型实现了一种在没有配对示例的情况下学习将图像从源域 X 转换到目标域 Y 的方法。
#
# 该模型一个重要应用领域是域迁移(Domain Adaptation),可以通俗地理解为图像风格迁移。其实在 CycleGAN 之前,就已经有了域迁移模型,比如 Pix2Pix ,但是 Pix2Pix 要求训练数据必须是成对的,而现实生活中,要找到两个域(画风)中成对出现的图片是相当困难的,因此 CycleGAN 诞生了,它只需要两种域的数据,而不需要他们有严格对应关系,是一种新的无监督的图像迁移网络。
# # ### 模型结构
#
# CycleGAN 网络本质上是由两个镜像对称的 GAN 网络组成,其结构如下图所示(图片来源于原论文):
#
# 
#
# 为了方便理解,这里以苹果和橘子为例介绍。上图中 $X$ 可以理解为苹果,$Y$ 为橘子;$G$ 为将苹果生成橘子风格的生成器,$F$ 为将橘子生成的苹果风格的生成器,$D_{X}$ 和 $D_{Y}$ 为其相应判别器,具体生成器和判别器的结构可见下文代码。模型最终能够输出两个模型的权重,分别将两种图像的风格进行彼此迁移,生成新的图像。
#
# 该模型一个很重要的部分就是损失函数,在所有损失里面循环一致损失(Cycle Consistency Loss)是最重要的。循环损失的计算过程如下图所示(图片来源于原论文):
#
# 
#
# 图中苹果图片 $x$ 经过生成器 $G$ 得到伪橘子 $\hat{Y}$,然后将伪橘子 $\hat{Y}$ 结果送进生成器 $F$ 又产生苹果风格的结果 $\hat{x}$,最后将生成的苹果风格结果 $\hat{x}$ 与原苹果图片 $x$ 一起计算出循环一致损失,反之亦然。循环损失捕捉了这样的直觉,即如果我们从一个域转换到另一个域,然后再转换回来,我们应该到达我们开始的地方。详细的训练过程见下文代码。
# # ## 数据集
#
# 本案例使用的数据集里面的图片来源于[ImageNet](https://ieeexplore.ieee.org/document/5206848),该数据集共有17个数据包,本文只使用了其中的苹果橘子部分。图像被统一缩放为256×256像素大小,其中用于训练的苹果图片996张、橘子图片1020张,用于测试的苹果图片266张、橘子图片248张。
#
# 这里对数据进行了随机裁剪、水平随机翻转和归一化的预处理,为了将重点聚焦到模型,此处将数据预处理后的结果转换为 MindRecord 格式的数据,以省略大部分数据预处理的代码。
#
# ### 数据集下载
#
# 使用 `download` 接口下载数据集,并将下载后的数据集自动解压到当前目录下。数据下载之前需要使用 `pip install download` 安装 `download` 包。
# # In[1]:
from download import download # 导入下载库url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/CycleGAN_apple2orange.zip" # 数据集链接download(url, ".", kind="zip", replace=True) # 下载数据集并解压# ### 数据集加载
#
# 使用 MindSpore 的 `MindDataset` 接口读取和解析数据集。
# # In[2]:
from mindspore.dataset import MindDataset # 导入MindSpore数据集模块# 读取MindRecord格式数据
name_mr = "./CycleGAN_apple2orange/apple2orange_train.mindrecord" # 指定MindRecord文件路径
data = MindDataset(dataset_files=name_mr) # 加载数据集
print("Datasize: ", data.get_dataset_size()) # 输出数据集大小batch_size = 1 # 设置批次大小
dataset = data.batch(batch_size) # 创建批次数据集
datasize = dataset.get_dataset_size() # 获取批次数据集大小# ### 可视化
#
# 通过 `create_dict_iterator` 函数将数据转换成字典迭代器,然后使用 `matplotlib` 模块可视化部分训练数据。
# # In[3]:
import numpy as np # 导入NumPy库
import matplotlib.pyplot as plt # 导入matplotlib库mean = 0.5 * 255 # 定义均值
std = 0.5 * 255 # 定义标准差plt.figure(figsize=(12, 5), dpi=60) # 创建绘图图形
for i, data in enumerate(dataset.create_dict_iterator()): # 遍历数据集if i < 5: # 只可视化前5张图片show_images_a = data["image_A"].asnumpy() # 获取图像A数据show_images_b = data["image_B"].asnumpy() # 获取图像B数据plt.subplot(2, 5, i + 1) # 创建图像A的子图show_images_a = (show_images_a[0] * std + mean).astype(np.uint8).transpose((1, 2, 0)) # 反归一化处理plt.imshow(show_images_a) # 显示图像Aplt.axis("off") # 关闭坐标轴plt.subplot(2, 5, i + 6) # 创建图像B的子图show_images_b = (show_images_b[0] * std + mean).astype(np.uint8).transpose((1, 2, 0)) # 反归一化处理plt.imshow(show_images_b) # 显示图像Bplt.axis("off") # 关闭坐标轴else:break # 如果超过5张则停止
plt.show() # 显示所有可视化结果# ## 构建生成器
#
# 本案例生成器的模型结构参考的 ResNet 模型的结构,参考原论文,对于128×128大小的输入图片采用6个残差块相连,图片大小为256×256以上的需要采用9个残差块相连,所以本文网络有9个残差块相连,超参数 `n_layers` 参数控制残差块数。
#
# 生成器的结构如下所示:
#
# 
#
# 具体的模型结构请参照下文代码:
# # In[4]:
import mindspore.nn as nn # 导入MindSpore神经网络模块
import mindspore.ops as ops # 导入MindSpore运算模块
from mindspore.common.initializer import Normal # 导入正态分布初始化函数weight_init = Normal(sigma=0.02) # 定义权重初始化方式class ConvNormReLU(nn.Cell): # 定义卷积、归一化和ReLU层的组合def __init__(self, input_channel, out_planes, kernel_size=4, stride=2, alpha=0.2, norm_mode='instance',pad_mode='CONSTANT', use_relu=True, padding=None, transpose=False):super(ConvNormReLU, self).__init__()norm = nn.BatchNorm2d(out_planes) # 批量归一化层if norm_mode == 'instance': # 判断是否为实例归一化norm = nn.BatchNorm2d(out_planes, affine=False)has_bias = (norm_mode == 'instance') # 是否使用偏置if padding is None:padding = (kernel_size - 1) // 2 # 计算填充if pad_mode == 'CONSTANT':if transpose:conv = nn.Conv2dTranspose(input_channel, out_planes, kernel_size, stride, pad_mode='same',has_bias=has_bias, weight_init=weight_init) # 转置卷积else:conv = nn.Conv2d(input_channel, out_planes, kernel_size, stride, pad_mode='pad',has_bias=has_bias, padding=padding, weight_init=weight_init) # 正常卷积layers = [conv, norm] # 卷积层和归一化层else:paddings = ((0, 0), (0, 0), (padding, padding), (padding, padding)) # 计算填充pad = nn.Pad(paddings=paddings, mode=pad_mode) # 填充层if transpose:conv = nn.Conv2dTranspose(input_channel, out_planes, kernel_size, stride, pad_mode='pad',has_bias=has_bias, weight_init=weight_init) # 转置卷积else:conv = nn.Conv2d(input_channel, out_planes, kernel_size, stride, pad_mode='pad',has_bias=has_bias, weight_init=weight_init) # 正常卷积layers = [pad, conv, norm] # 填充层、卷积层和归一化层if use_relu: # 如果使用ReLU激活relu = nn.ReLU() # ReLU激活if alpha > 0:relu = nn.LeakyReLU(alpha) # Leaky ReLU激活layers.append(relu) # 将激活层添加到层列表self.features = nn.SequentialCell(layers) # 将所有层组合为顺序层def construct(self, x): # 前向计算output = self.features(x) # 经过所有层return outputclass ResidualBlock(nn.Cell): # 定义残差块def __init__(self, dim, norm_mode='instance', dropout=False, pad_mode="CONSTANT"):super(ResidualBlock, self).__init__()self.conv1 = ConvNormReLU(dim, dim, 3, 1, 0, norm_mode, pad_mode) # 第一层卷积self.conv2 = ConvNormReLU(dim, dim, 3, 1, 0, norm_mode, pad_mode, use_relu=False) # 第二层卷积self.dropout = dropout # 是否使用dropoutif dropout:self.dropout = nn.Dropout(p=0.5) # Dropout层def construct(self, x): # 前向计算out = self.conv1(x) # 第一个卷积层if self.dropout: # 如果使用dropoutout = self.dropout(out) # 应用dropoutout = self.conv2(out) # 第二个卷积层return x + out # 残差连接class ResNetGenerator(nn.Cell): # 定义ResNet生成器def __init__(self, input_channel=3, output_channel=64, n_layers=9, alpha=0.2, norm_mode='instance', dropout=False,pad_mode="CONSTANT"):super(ResNetGenerator, self).__init__()self.conv_in = ConvNormReLU(input_channel, output_channel, 7, 1, alpha, norm_mode, pad_mode=pad_mode) # 输入层卷积self.down_1 = ConvNormReLU(output_channel, output_channel * 2, 3, 2, alpha, norm_mode) # 第一个下采样self.down_2 = ConvNormReLU(output_channel * 2, output_channel * 4, 3, 2, alpha, norm_mode) # 第二个下采样layers = [ResidualBlock(output_channel * 4, norm_mode, dropout=dropout, pad_mode=pad_mode)] * n_layers # 残差块self.residuals = nn.SequentialCell(layers) # 残差块序列self.up_2 = ConvNormReLU(output_channel * 4, output_channel * 2, 3, 2, alpha, norm_mode, transpose=True) # 第二个上采样self.up_1 = ConvNormReLU(output_channel * 2, output_channel, 3, 2, alpha, norm_mode, transpose=True) # 第一个上采样if pad_mode == "CONSTANT":self.conv_out = nn.Conv2d(output_channel, 3, kernel_size=7, stride=1, pad_mode='pad',padding=3, weight_init=weight_init) # 输出层卷积else:pad = nn.Pad(paddings=((0, 0), (0, 0), (3, 3), (3, 3)), mode=pad_mode) # 填充层conv = nn.Conv2d(output_channel, 3, kernel_size=7, stride=1, pad_mode='pad', weight_init=weight_init) # 输出层卷积self.conv_out = nn.SequentialCell([pad, conv]) # 填充和卷积组合def construct(self, x): # 前向计算x = self.conv_in(x) # 输入层x = self.down_1(x) # 第一个下采样x = self.down_2(x) # 第二个下采样x = self.residuals(x) # 残差块x = self.up_2(x) # 第二个上采样x = self.up_1(x) # 第一个上采样output = self.conv_out(x) # 输出层return ops.tanh(output) # 应用tanh激活# 实例化生成器
net_rg_a = ResNetGenerator() # 实例化生成器A
net_rg_a.update_parameters_name('net_rg_a.') # 更新参数名称net_rg_b = ResNetGenerator() # 实例化生成器B
net_rg_b.update_parameters_name('net_rg_b.') # 更新参数名称# ## 构建判别器
#
# 判别器其实是一个二分类网络模型,输出判定该图像为真实图的概率。网络模型使用的是 Patch 大小为 70x70 的 PatchGANs 模型。通过一系列的 `Conv2d` 、 `BatchNorm2d` 和 `LeakyReLU` 层对其进行处理,最后通过 Sigmoid 激活函数得到最终概率。
# # In[5]:
# 定义判别器
class Discriminator(nn.Cell): # 判别器类def __init__(self, input_channel=3, output_channel=64, n_layers=3, alpha=0.2, norm_mode='instance'):super(Discriminator, self).__init__()kernel_size = 4 # 卷积核大小layers = [nn.Conv2d(input_channel, output_channel, kernel_size, 2, pad_mode='pad', padding=1, weight_init=weight_init), # 初始卷积nn.LeakyReLU(alpha)] # Leaky ReLU激活nf_mult = output_channel # 初始通道数for i in range(1, n_layers): # 遍历层数nf_mult_prev = nf_mult # 前一层通道数nf_mult = min(2 ** i, 8) * output_channel # 当前层通道数layers.append(ConvNormReLU(nf_mult_prev, nf_mult, kernel_size, 2, alpha, norm_mode, padding=1)) # 添加卷积层nf_mult_prev = nf_mult # 更新前一层通道数nf_mult = min(2 ** n_layers, 8) * output_channel # 计算最后一层通道数layers.append
(ConvNormReLU(nf_mult_prev, nf_mult, kernel_size, 1, alpha, norm_mode, padding=1)) # 添加卷积层layers.append(nn.Conv2d(nf_mult, 1, kernel_size, 1, pad_mode='pad', padding=1, weight_init=weight_init)) # 输出层卷积self.features = nn.SequentialCell(layers) # 将所有层组合为顺序层def construct(self, x): # 前向计算output = self.features(x) # 经过所有层return output # 返回输出# 判别器初始化
net_d_a = Discriminator() # 实例化判别器A
net_d_a.update_parameters_name('net_d_a.') # 更新参数名称net_d_b = Discriminator() # 实例化判别器B
net_d_b.update_parameters_name('net_d_b.') # 更新参数名称# ## 优化器和损失函数
#
# 根据不同模型需要单独的设置优化器,这是训练过程决定的。
#
# 对生成器 $G$ 及其判别器 $D_{Y}$ ,目标损失函数定义为:
#
# $$L_{GAN}(G,D_Y,X,Y)=E_{y-p_{data}(y)}[logD_Y(y)]+E_{x-p_{data}(x)}[log(1-D_Y(G(x)))]$$
#
# 其中 $G$ 试图生成看起来与 $Y$ 中的图像相似的图像 $G(x)$ ,而 $D_{Y}$ 的目标是区分翻译样本 $G(x)$ 和真实样本 $y$ ,生成器的目标是最小化这个损失函数以此来对抗判别器。即 $ min_{G} max_{D_{Y}}L_{GAN}(G,D_{Y} ,X,Y )$ 。
#
# 单独的对抗损失不能保证所学函数可以将单个输入映射到期望的输出,为了进一步减少可能的映射函数的空间,学习到的映射函数应该是周期一致的,例如对于 $X$ 的每个图像 $x$ ,图像转换周期应能够将 $x$ 带回原始图像,可以称之为正向循环一致性,即 $x→G(x)→F(G(x))\approx x$ 。对于 $Y$ ,类似的 $x→G(x)→F(G(x))\approx x$ 。可以理解采用了一个循环一致性损失来激励这种行为。
#
# 循环一致损失函数定义如下:
#
# $$L_{cyc}(G,F)=E_{x-p_{data}(x)}[\Vert F(G(x))-x\Vert_{1}]+E_{y-p_{data}(y)}[\Vert G(F(y))-y\Vert_{1}]$$
#
# 循环一致损失能够保证重建图像 $F(G(x))$ 与输入图像 $x$ 紧密匹配。
# # In[6]:
# 构建生成器,判别器优化器
optimizer_rg_a = nn.Adam(net_rg_a.trainable_params(), learning_rate=0.0002, beta1=0.5) # 生成器A优化器
optimizer_rg_b = nn.Adam(net_rg_b.trainable_params(), learning_rate=0.0002, beta1=0.5) # 生成器B优化器optimizer_d_a = nn.Adam(net_d_a.trainable_params(), learning_rate=0.0002, beta1=0.5) # 判别器A优化器
optimizer_d_b = nn.Adam(net_d_b.trainable_params(), learning_rate=0.0002, beta1=0.5) # 判别器B优化器# GAN网络损失函数,这里最后一层不使用sigmoid函数
loss_fn = nn.MSELoss(reduction='mean') # 均方误差损失
l1_loss = nn.L1Loss("mean") # L1损失函数def gan_loss(predict, target): # 计算GAN损失target = ops.ones_like(predict) * target # 创建目标张量loss = loss_fn(predict, target) # 计算损失return loss # 返回损失# ## 前向计算
#
# 搭建模型前向计算损失的过程,过程如下代码。
#
# 为了减少模型振荡,遵循 Shrivastava 等人的策略,使用生成器生成图像的历史数据而不是生成器生成的最新图像数据来更新鉴别器。这里创建 `image_pool` 函数,保留了一个图像缓冲区,用于存储生成器生成前的50个图像。
# # In[7]:
import mindspore as ms # 导入MindSpore# 前向计算
def generator(img_a, img_b): # 定义生成器前向计算fake_a = net_rg_b(img_b) # 生成假图像Afake_b = net_rg_a(img_a) # 生成假图像Brec_a = net_rg_b(fake_b) # 重建图像Arec_b = net_rg_a(fake_a) # 重建图像Bidentity_a = net_rg_b(img_a) # 身份图像Aidentity_b = net_rg_a(img_b) # 身份图像Breturn fake_a, fake_b, rec_a, rec_b, identity_a, identity_b # 返回所有结果lambda_a = 10.0 # 循环一致损失权重
lambda_b = 10.0 # 循环一致损失权重
lambda_idt = 0.5 # 身份损失权重def generator_forward(img_a, img_b): # 生成器前向计算并返回损失true = Tensor(True, dtype=ms.bool_) # 定义真实标签fake_a, fake_b, rec_a, rec_b, identity_a, identity_b = generator(img_a, img_b) # 调用生成器loss_g_a = gan_loss(net_d_b(fake_b), true) # 计算生成器A的GAN损失loss_g_b = gan_loss(net_d_a(fake_a), true) # 计算生成器B的GAN损失loss_c_a = l1_loss(rec_a, img_a) * lambda_a # 计算循环一致损失Aloss_c_b = l1_loss(rec_b, img_b) * lambda_b # 计算循环一致损失Bloss_idt_a = l1_loss(identity_a, img_a) * lambda_a * lambda_idt # 计算身份损失Aloss_idt_b = l1_loss(identity_b, img_b) * lambda_b * lambda_idt # 计算身份损失Bloss_g = loss_g_a + loss_g_b + loss_c_a + loss_c_b + loss_idt_a + loss_idt_b # 总损失return fake_a, fake_b, loss_g, loss_g_a, loss_g_b, loss_c_a, loss_c_b, loss_idt_a, loss_idt_b # 返回所有损失def generator_forward_grad(img_a, img_b): # 生成器前向计算梯度_, _, loss_g, _, _, _, _, _, _ = generator_forward(img_a, img_b) # 获取损失return loss_g # 返回损失def discriminator_forward(img_a, img_b, fake_a, fake_b): # 判别器前向计算false = Tensor(False, dtype=ms.bool_) # 定义假标签true = Tensor(True, dtype=ms.bool_) # 定义真实标签d_fake_a = net_d_a(fake_a) # 判别假图像Ad_img_a = net_d_a(img_a) # 判别真实图像Ad_fake_b = net_d_b(fake_b) # 判别假图像Bd_img_b = net_d_b(img_b) # 判别真实图像Bloss_d_a = gan_loss(d_fake_a, false) + gan_loss(d_img_a, true) # 计算判别器A损失loss_d_b = gan_loss(d_fake_b, false) + gan_loss(d_img_b, true) # 计算判别器B损失loss_d = (loss_d_a + loss_d_b) * 0.5 # 平均损失return loss_d # 返回损失def discriminator_forward_a(img_a, fake_a): # 判别器A前向计算false = Tensor(False, dtype=ms.bool_) # 定义假标签true = Tensor(True, dtype=ms.bool_) # 定义真实标签d_fake_a = net_d_a(fake_a) # 判别假图像Ad_img_a = net_d_a(img_a) # 判别真实图像Aloss_d_a = gan_loss(d_fake_a, false) + gan_loss(d_img_a, true) # 计算损失return loss_d_a # 返回损失def discriminator_forward_b(img_b, fake_b): # 判别器B前向计算false = Tensor(False, dtype=ms.bool_) # 定义假标签true = Tensor(True, dtype=ms.bool_) # 定义真实标签d_fake_b = net_d_b(fake_b) # 判别假图像Bd_img_b = net_d_b(img_b) # 判别真实图像Bloss_d_b = gan_loss(d_fake_b, false) + gan_loss(d_img_b, true) # 计算损失return loss_d_b # 返回损失# 保留了一个图像缓冲区,用来存储之前创建的50个图像
pool_size = 50 # 设置图像池大小
def image_pool(images): # 定义图像池函数num_imgs = 0 # 当前图像数量image1 = [] # 存储图像的列表if isinstance(images, Tensor): # 如果输入是Tensorimages = images.asnumpy() # 转换为NumPy数组return_images = [] # 存储返回图像的列表for image in images: # 遍历输入图像if num_imgs < pool_size: # 如果数量未满num_imgs += 1 # 增加计数image1.append(image) # 添加到缓冲区return_images.append(image) # 返回图像else:if random.uniform(0, 1) > 0.5: # 随机选择是否替换random_id = random.randint(0, pool_size - 1) # 随机索引tmp = image1[random_id].copy() # 备份随机图像image1[random_id] = image # 替换图像return_images.append(tmp) # 返回备份的图像else:return_images.append(image) # 返回当前图像output = Tensor(return_images, ms.float32) # 转换为Tensorif output.ndim != 4: # 检查维度raise ValueError("img should be 4d, but get shape {}".format(output.shape)) # 抛出错误return output # 返回图像池# ## 计算梯度和反向传播
#
# 其中梯度计算也是分开不同的模型来进行的,详情见如下代码:# In[8]:
from mindspore import value_and_grad # 导入计算梯度的函数# 实例化求梯度的方法
grad_g_a = value_and_grad(generator_forward_grad, None, net_rg_a.trainable_params()) # 生成器A梯度
grad_g_b = value_and_grad(generator_forward_grad, None, net_rg_b.trainable_params()) # 生成器B梯度grad_d_a = value_and_grad(discriminator_forward_a, None, net_d_a.trainable_params()) # 判别器A梯度
grad_d_b = value_and_grad(discriminator_forward_b, None, net_d_b.trainable_params()) # 判别器B梯度# 计算生成器的梯度,反向传播更新参数
def train_step_g(img_a, img_b): # 定义生成器训练步骤net_d_a.set_grad(False) # 不计算判别器A梯度net_d_b.set_grad(False) # 不计算判别器B梯度fake_a, fake_b, lg, lga, lgb, lca, lcb, lia, lib = generator_forward(img_a, img_b) # 生成图像并计算损失_, grads_g_a = grad_g_a(img_a, img_b) # 计算生成器A的梯度_, grads_g_b = grad_g_b(img_a, img_b) # 计算生成器B的梯度optimizer_rg_a(grads_g_a) # 更新生成器A参数optimizer_rg_b(grads_g_b) # 更新生成器B参数return fake_a, fake_b, lg, lga, lgb, lca, lcb, lia, lib # 返回生成图像和损失# 计算判别器的梯度,反向传播更新参数
def train_step_d(img_a, img_b, fake_a, fake_b): # 定义判别器训练步骤net_d_a.set_grad(True) # 计算判别器A梯度net_d_b.set_grad(True) # 计算判别器B梯度loss_d_a, grads_d_a = grad_d_a(img_a, fake_a) # 计算判别器A损失和梯度loss_d_b, grads_d_b = grad_d_b(img_b, fake_b) # 计算判别器B损失和梯度loss_d = (loss_d_a + loss_d_b) * 0.5 # 平均损失optimizer_d_a(grads_d_a) # 更新判别器A参数optimizer_d_b(grads_d_b) # 更新判别器B参数return loss_d # 返回损失# ## 模型训练
#
# 训练分为两个主要部分:训练判别器和训练生成器,在前文的判别器损失函数中,论文采用了最小二乘损失代替负对数似然目标。
#
# - 训练判别器:训练判别器的目的是最大程度地提高判别图像真伪的概率。按照论文的方法需要训练判别器来最小化 $E_{y-p_{data}(y)}[(D(y)-1)^2]$ ;
#
# - 训练生成器:如 CycleGAN 论文所述,我们希望通过最小化 $E_{x-p_{data}(x)}[(D(G(x)-1)^2]$ 来训练生成器,以产生更好的虚假图像。
#
# 下面定义了生成器和判别器的训练过程:
# # In[9]:
import os # 导入os模块
import time # 导入time模块
import random # 导入random模块
import numpy as np # 导入NumPy库
from PIL import Image # 导入PIL用于图像处理
from mindspore import Tensor, save_checkpoint # 导入Tensor和模型保存函数
from mindspore import dtype # 导入数据类型模块epochs = 7 # 训练周期数
save_step_num = 80 # 每多少步保存一次模型
save_checkpoint_epochs = 1 # 每多少个epoch保存一次模型
save_ckpt_dir = './train_ckpt_outputs/' # 保存检查点的目录print('Start training!') # 输出训练开始信息for epoch in range(epochs): # 遍历每个epochg_loss = [] # 存储生成器损失d_loss = [] # 存储判别器损失start_time_e = time.time() # 记录epoch开始时间for step, data in enumerate(dataset.create_dict_iterator()): # 遍历数据集start_time_s = time.time() # 记录步骤开始时间img_a = data["image_A"] # 获取图像Aimg_b = data["image_B"] # 获取图像Bres_g = train_step_g(img_a, img_b) # 训练生成器fake_a = res_g[0] # 获取生成的假图像Afake_b = res_g[1] # 获取生成的假图像Bres_d = train_step_d(img_a, img_b, image_pool(fake_a), image_pool(fake_b)) # 训练判别器loss_d = float(res_d.asnumpy()) # 获取判别器损失step_time = time.time() - start_time_s # 计算步骤耗时res = [] # 存储生成器损失的列表for item in res_g[2:]: # 遍历生成器损失res.append(float(item.asnumpy())) # 将损失转换为浮点数并添加到列表g_loss.append(res[0]) # 添加生成器总损失d_loss.append(loss_d) # 添加判别器损失# 每隔一定步数打印损失信息if step % save_step_num == 0:print(f"Epoch:[{int(epoch + 1):>3d}/{int(epochs):>3d}], "f"step:[{int(step):>4d}/{int(datasize):>4d}], "f"time:{step_time:>3f}s,\n"f"loss_g:{res[0]:.2f}, loss_d:{loss_d:.2f}, "f"loss_g_a: {res[1]:.2f}, loss_g_b: {res[2]:.2f}, "f"loss_c_a: {res[3]:.2f}, loss_c_b: {res[4]:.2f}, "f"loss_idt_a: {
res[5]:.2f}, loss_idt_b: {res[6]:.2f}") # 输出各类损失信息epoch_cost = time.time() - start_time_e # 计算整个epoch的耗时per_step_time = epoch_cost / datasize # 计算每步的平均耗时mean_loss_d, mean_loss_g = sum(d_loss) / datasize, sum(g_loss) / datasize # 计算平均损失print(f"Epoch:[{int(epoch + 1):>3d}/{int(epochs):>3d}], "f"epoch time:{epoch_cost:.2f}s, per step time:{per_step_time:.2f}, "f"mean_g_loss:{mean_loss_g:.2f}, mean_d_loss:{mean_loss_d:.2f}") # 输出每个epoch的平均损失和时间信息if epoch % save_checkpoint_epochs == 0: # 每隔一定epoch保存模型os.makedirs(save_ckpt_dir, exist_ok=True) # 创建保存目录save_checkpoint(net_rg_a, os.path.join(save_ckpt_dir, f"g_a_{epoch}.ckpt")) # 保存生成器Asave_checkpoint(net_rg_b, os.path.join(save_ckpt_dir, f"g_b_{epoch}.ckpt")) # 保存生成器Bsave_checkpoint(net_d_a, os.path.join(save_ckpt_dir, f"d_a_{epoch}.ckpt")) # 保存判别器Asave_checkpoint(net_d_b, os.path.join(save_ckpt_dir, f"d_b_{epoch}.ckpt")) # 保存判别器Bprint('End of training!') # 输出训练结束信息# ## 模型推理
#
# 下面我们通过加载生成器网络模型参数文件来对原图进行风格迁移,结果中第一行为原图,第二行为对应生成的结果图。# In[10]:
import os # 导入os模块
from PIL import Image # 导入PIL用于图像处理
import mindspore.dataset as ds # 导入MindSpore数据集模块
import mindspore.dataset.vision as vision # 导入视觉处理模块
from mindspore import load_checkpoint, load_param_into_net # 导入加载检查点的函数# 加载权重文件
def load_ckpt(net, ckpt_dir): # 定义加载检查点的函数param_GA = load_checkpoint(ckpt_dir) # 加载检查点load_param_into_net(net, param_GA) # 将参数加载到网络中g_a_ckpt = './train_ckpt_outputs/g_a_1.ckpt' # 指定生成器A的检查点路径
g_b_ckpt = './train_ckpt_outputs/g_b_1.ckpt' # 指定生成器B的检查点路径load_ckpt(net_rg_a, g_a_ckpt) # 加载生成器A的权重
load_ckpt(net_rg_b, g_b_ckpt) # 加载生成器B的权重# 图片推理
fig = plt.figure(figsize=(11, 2.5), dpi=100) # 创建绘图图形
def eval_data(dir_path, net, a): # 定义评估数据的函数def read_img(): # 嵌套函数,读取图像for dir in os.listdir(dir_path): # 遍历指定目录path = os.path.join(dir_path, dir) # 获取文件完整路径img = Image.open(path).convert('RGB') # 打开并转换为RGB格式yield img, dir # 生成器返回图像和文件名dataset = ds.GeneratorDataset(read_img, column_names=["image", "image_name"]) # 创建生成器数据集trans = [vision.Resize((256, 256)), # 调整图像大小vision.Normalize(mean=[0.5 * 255] * 3, std=[0.5 * 255] * 3), # 归一化处理vision.HWC2CHW()] # 将图像格式从HWC转为CHWdataset = dataset.map(operations=trans, input_columns=["image"]) # 应用预处理操作dataset = dataset.batch(1) # 设置批次大小为1for i, data in enumerate(dataset.create_dict_iterator()): # 创建迭代器遍历数据集img = data["image"] # 获取图像数据fake = net(img) # 使用网络生成假图像fake = (fake[0] * 0.5 * 255 + 0.5 * 255).astype(np.uint8).transpose((1, 2, 0)) # 处理假图像img = (img[0] * 0.5 * 255 + 0.5 * 255).astype(np.uint8).transpose((1, 2, 0)) # 处理真实图像# 添加真实图像到绘图fig.add_subplot(2, 8, i + 1 + a) # 设置子图位置plt.axis("off") # 关闭坐标轴plt.imshow(img) # 显示真实图像# 添加假图像到绘图fig.add_subplot(2, 8, i + 9 + a) # 设置子图位置plt.axis("off") # 关闭坐标轴plt.imshow(fake) # 显示假图像eval_data('./CycleGAN_apple2orange/predict/apple', net_rg_a, 0) # 评估苹果图像
eval_data('./CycleGAN_apple2orange/predict/orange', net_rg_b, 4) # 评估橙子图像
plt.show() # 显示绘图
解析
- 导入必要的模块:
- 使用
os进行文件和目录操作。 - 使用
PIL处理图像。 - 使用
mindspore.dataset处理数据集,使用mindspore.dataset.vision进行图像处理。
- 使用
- 数据集下载与加载:
- 使用
download方法下载并解压数据集。 - 使用
MindDataset读取 MindRecord 格式的数据集,并进行批量处理。
- 使用
- 数据可视化:
- 通过
create_dict_iterator函数将数据转换为可迭代的字典形式,并使用matplotlib可视化部分训练数据。
- 通过
- 构建生成器与判别器:
- 使用
ConvNormReLU和ResidualBlock定义了生成器结构。 - 判别器采用 PatchGAN 结构,通过卷积和 Leaky ReLU 激活函数输出图像的真实概率。
- 使用
- 优化器与损失函数:
- 使用
Adam优化器分别为生成器和判别器设置学习率。 - 定义 GAN 损失和循环一致损失,以保证生成器与判别器的对抗训练。
- 使用
- 前向计算与训练步骤:
- 定义生成器和判别器的前向计算方法,计算损失并进行反向传播更新参数。
- 模型训练:
- 在指定的训练周期内,交替训练生成器和判别器,并定期打印损失信息和保存模型的检查点。
- 模型推理与结果展示:
- 加载训练好的生成器模型,对新的图像进行风格迁移处理,并展示真实图像与生成图像的对比。
API 解析
- load_checkpoint:从指定路径加载保存的模型权重。
- load_param_into_net:将加载的权重参数设置到网络模型中。
- GeneratorDataset:创建一个基于生成器的 MindSpore 数据集。
- map:对数据集中每个元素应用指定的操作(如图像预处理)。
- asnumpy():将 MindSpore 的 Tensor 转换为 NumPy 数组,以便进行后续处理或可视化。
通过以上代码和解析,可以实现 CycleGAN 的训练与推理,完成图像风格的迁移任务。









![[Windows CMD] 查看网络配置 ipconfig](https://i-blog.csdnimg.cn/direct/27f0e2ef4c894a58becbb394c4af9da1.png)