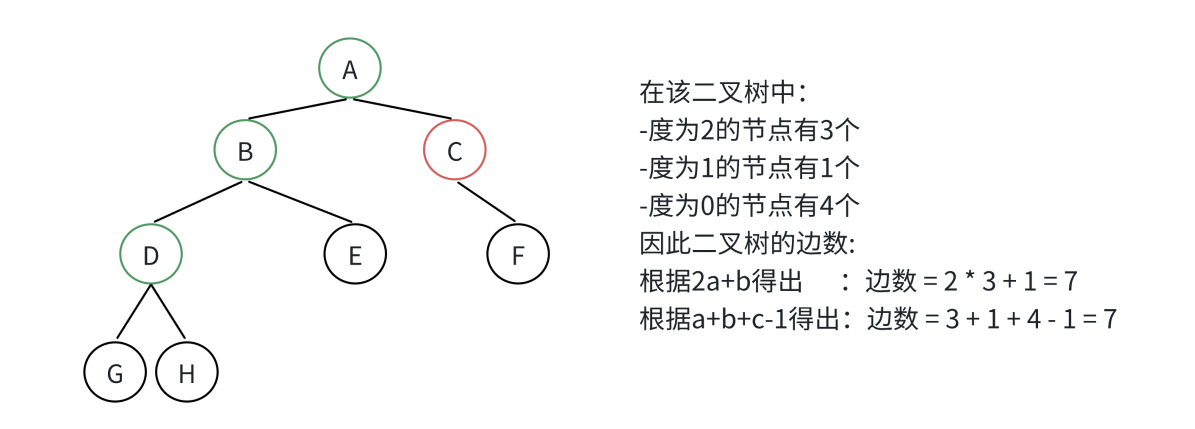
前言:
在上篇文章【数据结构】二叉树——顺序结构——堆及其实现中,实现了二叉树的顺序结构,使用堆来实现了二叉树这样一个数据结构;现在就来实现而二叉树的链式结构。
一、链式结构
链式结构,使用链表来表示一颗二叉树,即用链来指示二叉树中元素的逻辑关系。通常的就是链表中每个节点右三个域组成,数据域和左右指针域,左右指针分别指向该节点的左孩子节点和右孩子节点的存储地址。
链式结构分为二叉链和三叉链(三叉链比而二叉链多一个指向父节点的指针域)。

这里使用二叉链来实现。
二、二叉树链式结构实现相关功能
在实现之前,先来看一下,具体要实现哪些功能?
首先就是二叉树的结构,我们使用链表来实现,链表的每一个节点都由数值域和左右指针域组成。
二叉树链式结构的节点
typedef int TreeDataType;
typedef struct TreeNode
{TreeDataType data;struct TreeNode* left;struct TreeNode* right;
}TreeNode;
二叉树链式结构如上,接下来再来看一下二叉树链式结构实现的相关功能:
//二叉树的前序排序
int PreOrder(TreeNode* root);
//二叉树的中序排序
int InOrder(TreeNode* root);
//二叉树的后序遍历
int AfterOrter(TreeNode* root);
//二叉树节点个数
int BinaryTreeSize(TreeNode* root);
//二叉树叶子节点个数
int BinaryTreeLeafSize(TreeNode* root);
//二叉树第k层节点个数
int BinaryTreeLevelKSize(TreeNode* root, int k);
//二叉树的深度
int BinaryTreeDepth(TreeNode* root);
//查找二叉树值为x的节点
TreeNode* BinaryTreeFind(TreeNode* root, TreeDataType x);
//层序遍历
void LevelOrder(BTNode* root)
//判断是否为满二叉树
bool BinaryTreeComplete(BTNode* root)
//二叉树的销毁
void TreeDesTroy(TreeNode** root);2.1、二叉树前、中、后序遍历
这里,前序、中序和后序遍历什么意思呢,

说白了,这三种遍历其实就是以对二叉树访问的顺序,来遍历二叉树
这里以前序遍历为例,遍历二叉树

现在有一个这样的二叉树,用前序遍历来访问这颗二叉树(这里访问并输出访问到的数据)

首先访问根节点,输出访问到的数据 1 ;再访问左子树

再访问其左子树的根节点,输出访问到的数据 2 ;再接着访问左子树

再访问其左子树的根节点,输出访问到的数据 4 ;再接着访问左子树

此时访问到了空节点,就直接回退,回退到其父节点的函数栈帧,访问父节点的右子树

访问4这个节点的右子树,也为空,此时节4这个点为根节点的左子树已经访问 结束了,回退到其父节点的函数栈帧,访问其父节点的右子树

访问2这个节点的右子树,先输出右子树的根节点数据 5 ;再访问根节点5的左子树

这里节点5的左右节点都为空,这里省略一些过程;此时5这个节点访问结束,回退到2这个节点,而2这个节点右子树访问结束,也已经访问结束了;此时再回退到根节点,访问根节点的右子树。

此时访问根节点的右子树的根节点,输出访问到的数据 3 ;再接着访问3这个节点的左子树

这里,3这个节点的左右节点都为空,访问就直接返回,回退到根节点,就说明根节点的右子树访问已经结束,此时二叉树已经变了结束。
这里前序遍历的输出结果为 1 2 4 5 3
这三个前、中、后序遍历本质上没啥差别,这里直接看实现代码
//二叉树的前序排序
void PreOrder(TreeNode* root)
{if (root == NULL){return;}//输出数据printf("%d ", root->data);//遍历左子树PreOrder(root->left);//遍历右子树PreOrder(root->right);
}
//二叉树的中序排序
void InOrder(TreeNode* root)
{if (root == NULL){return;}//遍历左子树InOrder(root->left);//输出数据printf("%d ", root->data);//遍历右子树InOrder(root->right);
}
//二叉树的后序遍历
void AfterOrter(TreeNode* root)
{if (root == NULL){return;}//遍历左子树AfterOrter(root->left);//遍历右子树AfterOrter(root->right);//输出数据printf("%d ", root->data);
}这里我们来测试代码对不对,我们先创建一个二叉树,然后看输出结果是否正确、
TreeNode* BuyNode(TreeDataType x)
{TreeNode* newnode = (TreeNode*)malloc(sizeof(TreeNode));if (newnode == NULL){perror("malloc");exit(1);}newnode->data = x;newnode->left = newnode->right = NULL;return newnode;
}void test()
{TreeNode* node1 = BuyNode(1);TreeNode* node2 = BuyNode(2);TreeNode* node3 = BuyNode(3);TreeNode* node4 = BuyNode(4);TreeNode* node5 = BuyNode(5);node1->left = node2;node1->right = node3;node2->left = node4;node2->right = node5;//前序遍历PreOrder(node1);printf("\n");//中序遍历InOrder(node1);printf("\n");//后序遍历AfterOrter(node1);printf("\n");
}
int main()
{test();return 0;
}
这里代码没有问题。
2.2、二叉树节点个数
这里,二叉树的链式结构我们是使用递归来实现的,那我们该如何去计算二叉树的节点个数呢?
思路:
遍历二叉树,遍历到空节点就返回0,不是空节点就返回其左子树和右子树节点个数之和再加一
代码如下:
//二叉树节点个数
int BinaryTreeSize(TreeNode* root)
{if (root == NULL){return 0;}return BinaryTreeSize(root->left) + BinaryTreeSize(root->right) + 1;
}2.3、二叉树叶子结点个数
所谓叶子节点:就是左右子节点都为空的节点,我们就利用这个特点来判断
思路:
遍历二叉树,遍历到空节点就返回空;遍历到节点的左右节点都为空,返回1;否则就返回节点的左子树和右子树的叶子结点之和。
代码如下:
//二叉树叶子节点个数
int BinaryTreeLeafSize(TreeNode* root)
{if (root == NULL){return 0;}if (root->left == NULL && root->right == NULL){return 1;}return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right);
}2.4、二叉树第k层节点个数
求二叉树第k层节点的个数,我们先来看这样的一个图

通过图我们可以看到,每次向下遍历一层,k-1;当k=1时,正好是第k层
思路:
遍历二叉树,遍历到空节点就返回 0 ;遍历到k=1时,就返回1;否则就返回该节点左子树和右子树中第k - 1层的节点个数。
这里需要注意,要在判断k=1之前判断节点是否为空。
代码如下:
//二叉树第k层节点个数
int BinaryTreeLevelKSize(TreeNode* root, int k)
{if (root == NULL){return 0;}if (k == 1){return 1;}return BinaryTreeLevelKSize(root->left, k - 1) + BinaryTreeLevelKSize(root->right, k - 1);
}2.5、二叉树的深度
求二叉树的深度,我们这里是将二叉树的左子树和右子树分开依次遍历的,显然我们不能像上面一样,返回遍历左子树和右子树的和;这里就返回其中最大的。
思路:
遍历二叉树,遍历到空节点就返回空;定义两个值,记录其节点左子树和右子树的深度再加一;返回其中最大的即可。
理解:这里定义两个值记录其左右子树的深度加一(加一就是记录当前这一层)。
代码如下:
//二叉树的深度
int BinaryTreeDepth(TreeNode* root)
{if (root == NULL){return 0;}int depth_left = BinaryTreeDepth(root->left) + 1;int depth_right = BinaryTreeDepth(root->right) + 1;return (depth_left > depth_right) ? depth_left : depth_right;
}2.6、查找二叉树中值为 x 的节点
查找相对来说就比较简单了,遍历二叉树,为空就返回NULL,值为x就返回该节点的地址,如果遍历过程中函数返回值不为NULL,就证明找到了,直接返回即可。
思路:
遍历二叉树,遍历到空节点就返回NULL;判断节点的值是否为x,是就返回该节点的地址;不是。就创建指针变量接受其左右子树遍历的结果,如果不为NULL就直接返回该返回值。为空则继续遍历。
代码如下:
//查找二叉树值为x的节点
TreeNode* BinaryTreeFind(TreeNode* root, TreeDataType x)
{if (root == NULL){return NULL;}if (root->data == x){return root;}TreeNode* pleft = BinaryTreeFind(root->left, x);if (pleft)return pleft;TreeNode* pright = BinaryTreeFind(root->right, x);if (pright)return pright;return NULL;
}到这里,来看一下这些代码是否正确

 对于这样的一个二叉树,代码输出结果都正确。
对于这样的一个二叉树,代码输出结果都正确。
2.7、层序遍历
这里层序遍历,我们需要借用队列这样一个数据结构(前面有详细讲解),
大致思路如此:

将根节点数据放入队列中;然后出队列,并且把该节点的左右子节点插入到队列当中。

将1这个节点出队列,再把左右子节点插入到队列当中

再出队头节点,将其左右子节点插入队列当中

依次类推,当队头数据左右子节点为空,就不进插入队列这一操作。

代码如下:
这里用到了对列相关代码,详细代码在上篇
//层序遍历
//借助数据结构---队列
void LevelOrder(BTNode* root)
{Queue q;QueueInit(&q);QueuePush(&q, root);while (!QueueEmpty(&q)){//取队头,打印BTNode* front = QueueFront(&q);printf("%d ", front->data);QueuePop(&q);//队头节点的左右孩子入队列if (front->left)QueuePush(&q, front->left);if (front->right)QueuePush(&q, front->right);}//队列为空QueueDestroy(&q);
}2.8、判断二叉树是否为满二叉树
判断二叉树是否为满二叉树,还是借用队列这样的数据结构,和层序遍历有相似之处;与层序遍历不同的是,这里,即便左右子节点为空,有进行入队列操作;当队头数据为空,就判断队列剩余数据是否都为空,如果都为空,就证明二叉树为满二叉树;否则就不是满二叉树。
代码如下:
//判断二叉树是否为完全二叉树
//---队列
bool BinaryTreeComplete(BTNode* root)
{Queue q;QueueInit(&q);QueuePush(&q, root);while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);if (front == NULL){break;}QueuePush(&q, front->left);QueuePush(&q, front->right);}//队列不一定为空while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);if (front != NULL){QueueDestroy(&q);return false;}}QueueDestroy(&q);return true;
}2.9、二叉树的销毁
这里为了测试这些代码,就手动创建了一个二叉树,这些都是动态开辟的空间,养成好习惯,手动释放动态开辟的空间。
这里需要注意的是:使用后序遍历,先是否底层的节点,
代码如下:
// 二叉树销毁
void BinaryTreeDesTroy(TreeNode** root)
{if (*root == NULL){return;}BinaryTreeDesTroy(&((*root)->left));BinaryTreeDesTroy(&((*root)->right));free(*root);*root = NULL;
}感谢各位大佬支持并指出问题,
如果本篇内容对你有帮助,可以一键三连支持以下,感谢支持!!!