本文字数:2631;估计阅读时间:7 分钟
作者:Bucky Schwarz
本文在公众号【ClickHouseInc】首发

我们最近发布了 Query Insights 的初步实现,为 ClickHouse Cloud 用户提供了一种便捷的方法来查看和解释查询日志。该功能对所有 ClickHouse Cloud 用户开放,本篇文章将讨论其功能和构建过程。
为什么要构建查询日志 UI?
ClickHouse 实例中的 system.query_log 表包含大量有价值的数据,可以帮助用户了解:
-
查询性能和异常;
-
错误及其相关信息(异常代码、消息、设置、配置文件事件等);
以及
-
时间序列查询指标(读取/写入吞吐量、数据量和延迟的变化)。
然而,收集这些信息也带来了挑战——system.query_log 目前包含超过 70 个字段(完整列表请见此处:https://clickhouse.com/docs/en/operations/system-tables/query_log),并且每个查询会生成两个或更多记录。因此,解释查询日志数据可能会很困难,特别是对于不太熟悉 ClickHouse 的用户来说。
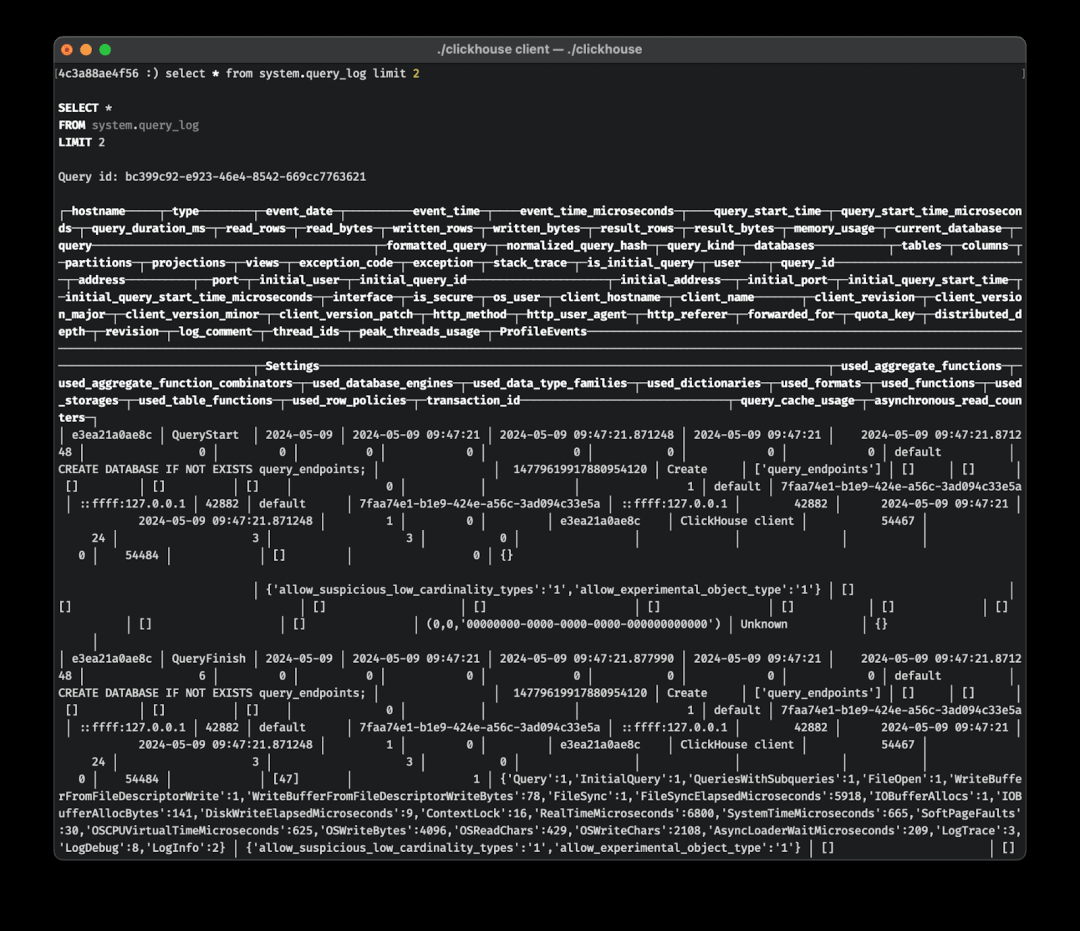
为了说明这一点,让我们来看一下在 CLI 中执行简单的 select * from system.query_log 的输出:
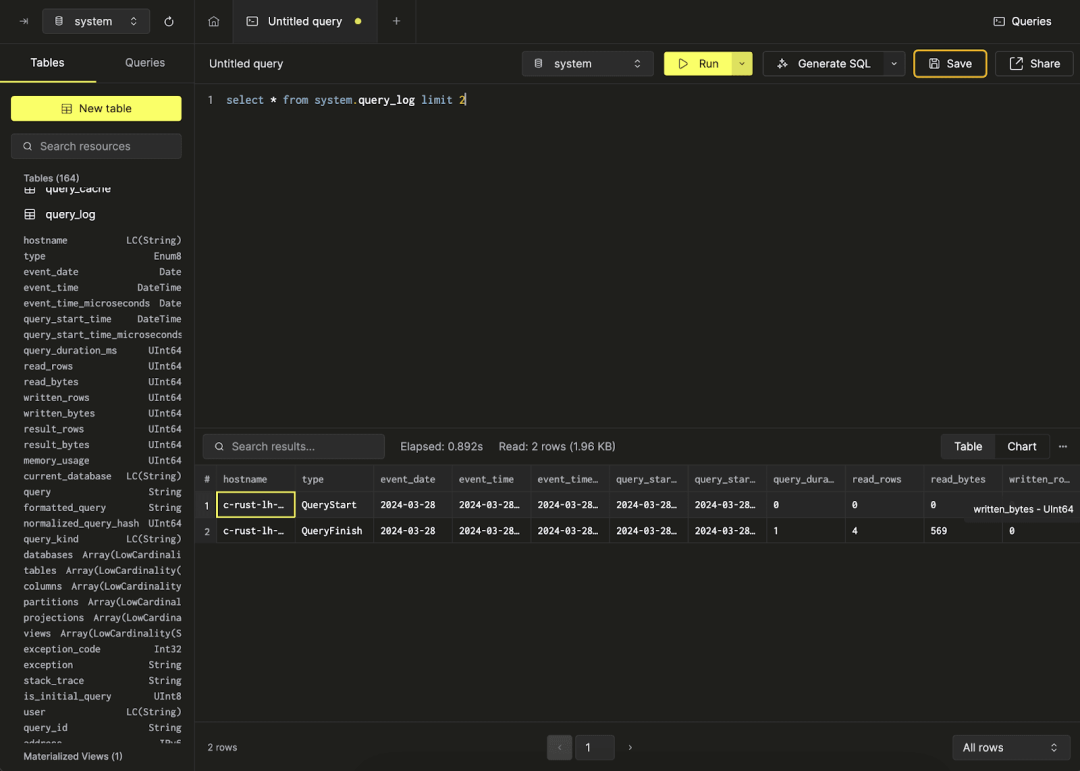
ClickHouse Cloud 中的 SQL 控制台在这方面有所改进(至少在视觉效果上),但如果您不清楚具体要查找的信息,使用体验仍然不是很直观:
增加一些复杂性,每个 ClickHouse Cloud 服务至少包含两个副本,每个副本都有自己的查询日志版本,这意味着简单地运行 select * from system.query_log 只会返回当前副本的结果。因此,每当 ClickHouse Cloud 用户(或任何运行多副本部署的 ClickHouse 用户)想要检查查询日志时,都需要使用 clusterAllReplicas() 函数,这对于经验较少的用户来说同样不直观。这引出了我们第一个(也是最明显的)查询日志 UI 的顶级目标:
-
目标 #1 — 使查询日志数据更易于解释和访问
如前所述,查询日志是查询优化、调试和监控整个集群健康状况和性能的关键信息来源。除了提高查询日志数据的可访问性之外,考虑到查询日志的用途和使用时机,我们还确定了这个新功能的其他顶级目标:
-
目标 #2 — 暴露重要的顶级查询指标
-
目标 #3 — 简化利用查询日志的查询调试和优化工作流
-
目标 #4 — 提供基于上下文的“智能”建议和洞察,进一步简化查询调试和优化
采用迭代方法
当我们开始规划这个功能时,我们确定前两个目标可以相对快速地实现,并能够解决用户的主要痛点。另一方面,后两个目标仍然比较模糊,需要进一步研究和深入理解不同的查询日志指标在何时和如何重要。因此,我们决定尽快发布一个初始版本,以实现目标 #1 和 #2,并为逐步改进目标 #3 和 #4 奠定基础。重要的是,未来的迭代工作将基于用户反馈。如果您正在阅读这篇文章,请尝试我们的新查询洞察 UI 并给我们反馈!
查询洞察 V1
选择服务后,左侧边栏的监控导航项会展开,显示一个新的“查询洞察”子项。点击此选项将打开新的查询洞察页面:
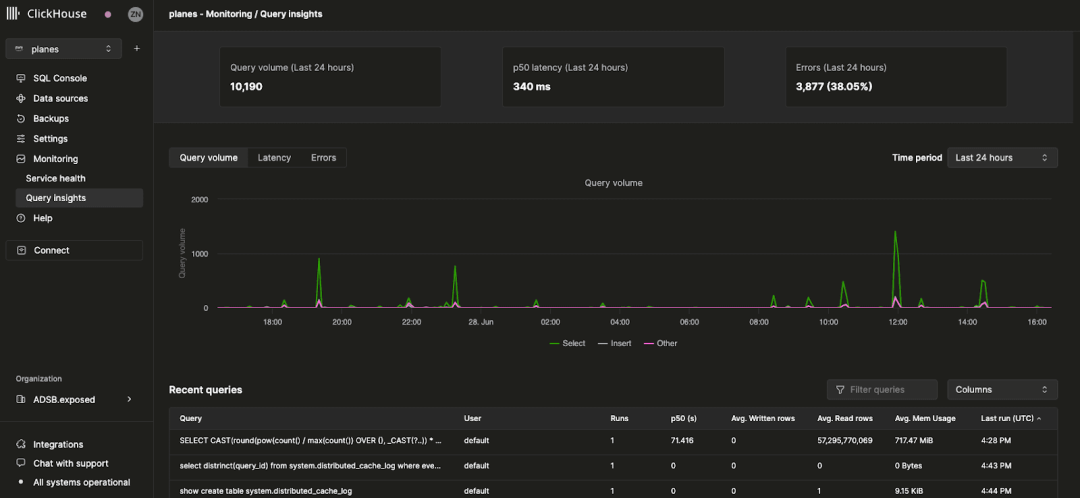
顶级指标
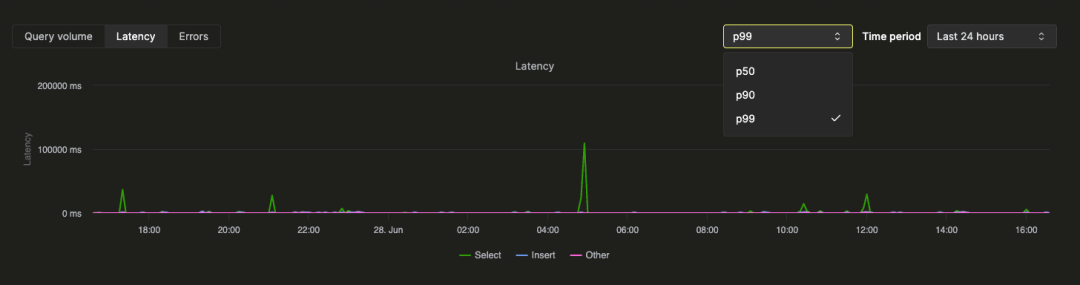
页面顶部的统计框显示了所选时间段内的一些基本查询指标。下面展示了三个时间序列图,分别代表查询量、延迟和错误率,这些图按查询类型(选择、插入、其他)在所选时间窗口内分解显示。延迟图可以进一步调整,以显示 p50、p90 和 p99 延迟:
最近的查询
在顶级指标下方,有一个表格显示了所选时间窗口内按标准化查询哈希和用户分组的查询日志条目:
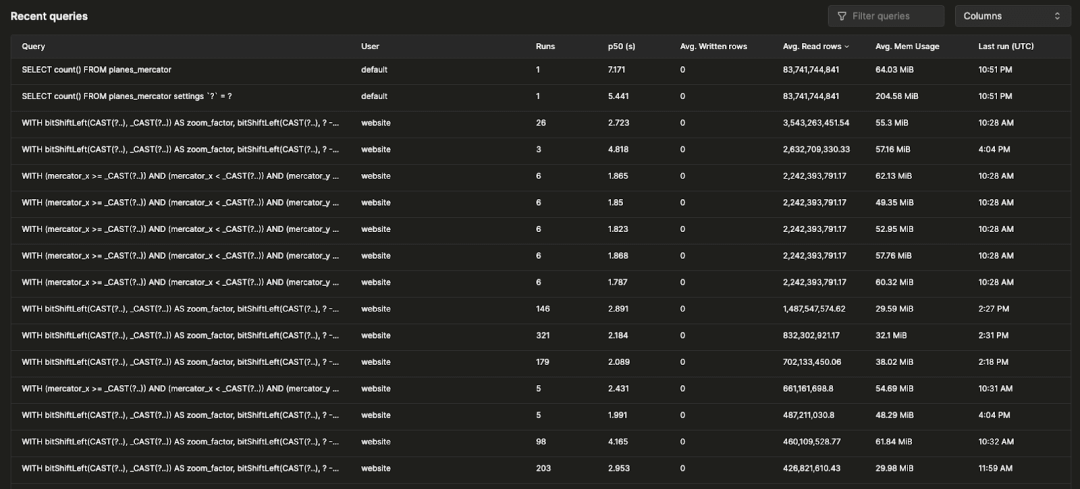
最近的查询可以按任何可用字段进行过滤和排序,表格也可以配置以显示或隐藏附加字段(如表格、p90 和 p99 延迟)。
查询详情
在最近的查询表格中选择一个查询,会打开一个包含该查询特定指标和信息的侧边栏:
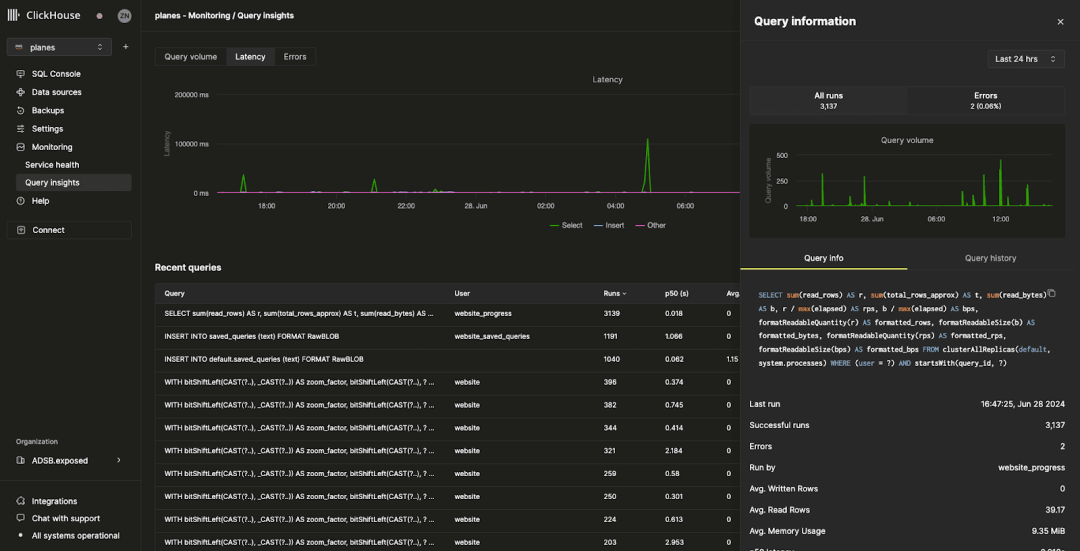
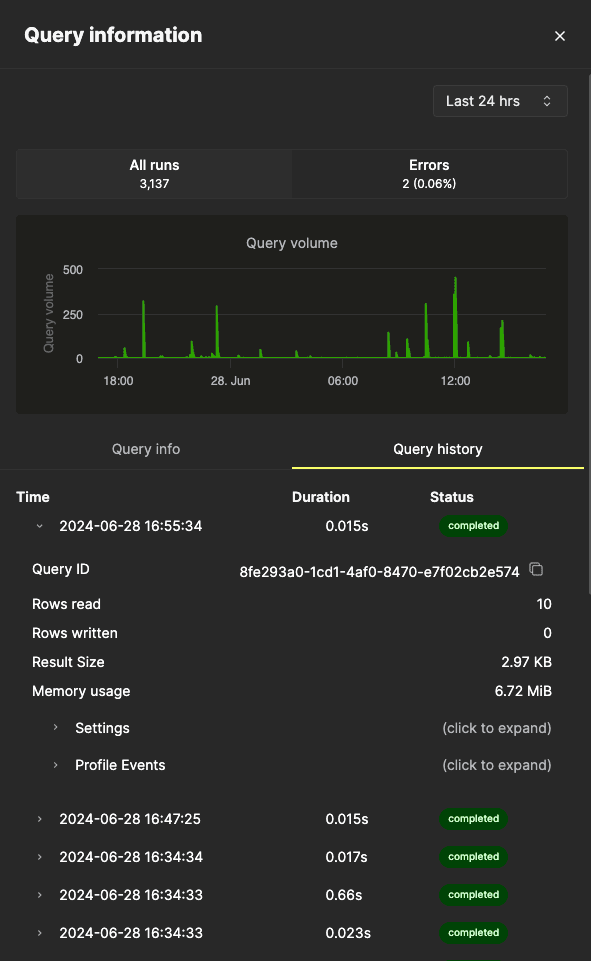
从侧边栏可以看到,这个特定查询在过去 24 小时内已运行超过 3000 次。“查询信息”选项卡显示的是汇总指标,但我们也可以通过选择“查询历史”选项卡查看单次运行的指标:
幕后揭秘
查询洞察是我在二月底加入 ClickHouse 后参与的第一个重要项目。在开始这个功能开发之前,我花了几周时间做一些小任务和修复错误,以熟悉代码库和工作流程。这反映了团队对我的信任和信心,以及我们招聘流程的高标准——高标准的招聘让我们确信被录用的人有能力完成工作,并能迅速上手。
这个功能的目标和设计已经相当明确,但细节和实施由我负责。我从一个 Figma 设计开始,该设计展示了一个通用的图表和显示不同类型数据(如所有查询、错误和慢查询)的功能。实现过程中,主要是将查询逻辑与可视化代码分离,并定义了清晰的接口。这些接口允许我们在不影响图表渲染代码的情况下,更改传递给查询的数据(例如时间范围以及查询的是延迟还是错误)。
在我的职业生涯中,我已经学到,功能的草拟与实际运行是两回事,并且我们对软件需求的理解会随着时间而变化。因此,我在接手这个项目时,尝试让初始版本范围尽可能狭窄(但仍可用),然后将功能展示给各种内部和外部用户——这是开发 Web 应用程序的标准方法。这样,任何未来的更改都可以相对容易地实施。我前面提到的慢查询,经过早期用户使用后,我们认为其概念不太合理,于是取消了它,并用 p99、p90 和 p50 延迟替代。我们还意识到,点击表格时显示的侧边栏效果不好,因此几乎完全重新设计了它。这些都不是大问题,因为我们在开发时预见到了可能的更改,并设置了相应的抽象和接口,以便轻松实现这些更改。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求