#AI夏令营 #Datawhale #夏令营
Task1文章链接:
电力需求预测挑战赛笔记 Taks1 跑通baseline-CSDN博客文章浏览阅读577次,点赞5次,收藏9次。电力需求预测挑战赛;【训练时序预测模型助力电力需求预测】https://blog.csdn.net/qq_23311271/article/details/140356873
进阶lightgbm,开始特征工程
导入模块
!pip install lightgbmimport numpy as np
import pandas as pd
import lightgbm as lgb
from sklearn.metrics import mean_squared_log_error, mean_absolute_error
import tqdm
import sys
import os
import gc
import argparse
import warnings
warnings.filterwarnings('ignore')读取数据
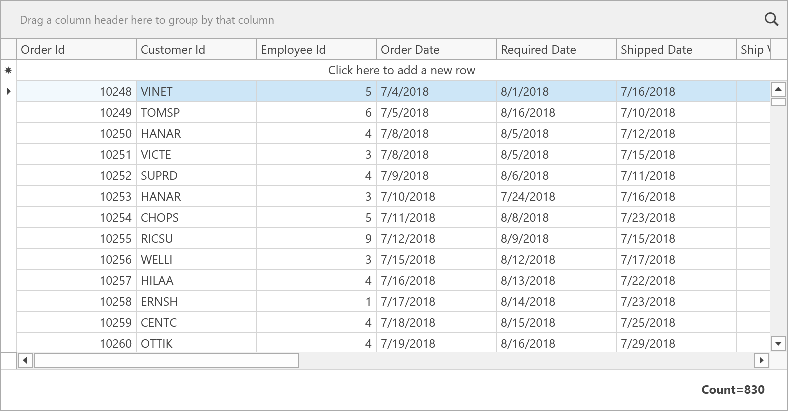
train = pd.read_csv('data/data283931/train.csv')
test = pd.read_csv('data/data283931/test.csv')查看数据情况
赛题数据由训练集和测试集组成,为了保证比赛的公平性,将每日日期进行脱敏,用 1-N 进行标识,即 1 为数据集最近一天,其中 1-10 为测试集数据。
数据集由字段 id(房屋 id)、 dt(日标识)、type(房屋类型)、target(实际电力消耗)组成。
| 特征字段 | 字段描述 |
|---|---|
| id | 房屋 id |
| dt | 日标识 |
| type | 房屋类型 |
| target | 实际电力消耗,预测目标 |
查看训练集数据
train输出如下:
| id | dt | type | target | |
|---|---|---|---|---|
| 0 | 00037f39cf | 11 | 2 | 44.050 |
| 1 | 00037f39cf | 12 | 2 | 50.672 |
| 2 | 00037f39cf | 13 | 2 | 39.042 |
| 3 | 00037f39cf | 14 | 2 | 35.900 |
| 4 | 00037f39cf | 15 | 2 | 53.888 |
| ... | ... | ... | ... | ... |
| 2877300 | fff81139a7 | 502 | 5 | 28.552 |
| 2877301 | fff81139a7 | 503 | 5 | 22.818 |
| 2877302 | fff81139a7 | 504 | 5 | 21.282 |
| 2877303 | fff81139a7 | 505 | 5 | 22.021 |
| 2877304 | fff81139a7 | 506 | 5 | 18.145 |
2877305 rows × 4 columns
分析不同id对于target的影响
import matplotlib.pyplot as plt
import pandas as pd# 使用groupby函数按'id'列对训练数据进行分组,并计算'target'列的平均值
# reset_index()函数将分组后的结果转换为DataFrame,方便后续绘图使用
type_target_df = train.groupby('id')['target'].mean().reset_index()# 设置图形的大小为8x4英寸
plt.figure(figsize=(8, 4))# 由于'id'列是类别型数据,不适合直接作为柱状图的x轴
# 实际上,如果'id'的数量很多,应该选择一个子集或者使用其他可视化方法
# 这里为了示例,我们假设只有两个'id':'blue_id'和'green_id'
# 对应的颜色分别为蓝色和绿色
ids = type_target_df['id'].head(10) # 假设只选择前10个'id'
colors = ['blue', 'green']
plt.bar(ids, type_target_df[type_target_df['id'].isin(ids)]['target'], color=colors)# 设置x轴的标签为'id'
plt.xlabel('id')# 设置y轴的标签为'Average Target Value'
plt.ylabel('Average Target Value')# 设置图表的标题为'Bar Chart of Target by id'
plt.title('Bar Chart of Target by id')# 显示图表
plt.show()

import matplotlib.pyplot as plt
# 不同id类型对应target的柱状图
type_target_df = train.groupby('id')['target'].mean().reset_index()
plt.figure(figsize=(8, 4))
plt.bar(type_target_df['id'], type_target_df['target'], color=['blue', 'green'])
plt.xlabel('id')
plt.ylabel('Average Target Value')
plt.title('Bar Chart of Target by id')
plt.show()
根据id分组target值的平均值的分布
import matplotlib.pyplot as plt
import pandas as pd# 使用groupby函数按'id'列对训练数据进行分组,并计算'target'列的平均值
# reset_index()函数将分组后的结果转换为DataFrame,方便后续绘图使用
type_target_df = train.groupby('id')['target'].mean().reset_index()# 定义target值的区间
bins = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
labels = [f'{bins[i]}-{bins[i+1]}' for i in range(len(bins)-1)]# 将target值分配到对应的区间
type_target_df['target_range'] = pd.cut(type_target_df['target'], bins=bins, labels=labels, right=False)# 对区间进行分组,并计算每个区间的id数量
range_counts = type_target_df.groupby('target_range')['id'].count().reset_index()# 设置图形的大小为8x4英寸
plt.figure(figsize=(8, 4))# 绘制柱状图,'range_counts['target_range']'表示x轴的类别,'range_counts['id']'表示y轴的数值
# color参数设置柱状图的颜色,这里使用蓝色
plt.bar(range_counts['target_range'], range_counts['id'], color='blue')# 设置x轴的标签为'Target Range'
plt.xlabel('Target Range')# 设置y轴的标签为'Number of ids'
plt.ylabel('Number of ids')# 设置图表的标题为'Bar Chart of Number of ids by Target Range'
plt.title('Bar Chart of Number of ids by Target Range')# 显示图表
plt.show()

分析不同type对于target的影响
首先对训练数据按type列进行分组,并计算每个组target列的平均值。然后,使用matplotlib库绘制了一个柱状图,展示了不同type对应的target平均值
import matplotlib.pyplot as plt# 使用groupby函数按'type'列对训练数据进行分组,并计算'target'列的平均值 CSDN@优雅的造轮狮
# reset_index()函数将分组后的结果转换为DataFrame,方便后续绘图使用
type_target_df = train.groupby('type')['target'].mean().reset_index()# 设置图形的大小为8x4英寸
plt.figure(figsize=(8, 4))# 绘制柱状图,'type_target_df['type']'表示x轴的类别,'type_target_df['target']'表示y轴的数值
# color参数设置柱状图的颜色,这里分别为蓝色和绿色
plt.bar(type_target_df['type'], type_target_df['target'], color=['blue', 'green'])# 设置x轴的标签为'Type'
plt.xlabel('Type')# 设置y轴的标签为'Average Target Value'
plt.ylabel('Average Target Value')# 设置图表的标题为'Bar Chart of Target by Type'
plt.title('Bar Chart of Target by Type')# 显示图表
plt.show()
输出结果:
# 从训练数据中筛选出'id'等于'fff81139a7'的行
specific_id_df = train[train['id'] == 'fff81139a7']
#specific_id_df = train[train['id'] == '00037f39cf']
# 设置图形的大小为10x5英寸
plt.figure(figsize=(10, 5))# 绘制线图,'specific_id_df['dt']'表示x轴的时间戳,'specific_id_df['target']'表示y轴的目标值
# marker参数设置数据点的标记样式为圆形,linestyle参数设置线条样式为实线 CSDN@优雅的造轮狮
plt.plot(specific_id_df['dt'], specific_id_df['target'], marker='o', linestyle='-')# 设置x轴的标签为'DateTime'
plt.xlabel('DateTime')# 设置y轴的标签为'Target Value'
plt.ylabel('Target Value')# 设置图表的标题为"Line Chart of Target for ID 'fff81139a7'"
plt.title("Line Chart of Target for ID 'fff81139a7'")# 显示图表
plt.show()


target值的分布情况
import matplotlib.pyplot as plt
import pandas as pd# 使用value_counts函数统计'target'列的每个唯一值的数量
target_counts = train['target'].value_counts().reset_index()
target_counts.columns = ['Target Value', 'Count']# 设置图形的大小为8x4英寸
plt.figure(figsize=(8, 4))# 绘制柱状图,'target_counts['Target Value']'表示x轴的类别,'target_counts['Count']'表示y轴的数值
# color参数设置柱状图的颜色,这里使用蓝色
plt.bar(target_counts['Target Value'], target_counts['Count'], color='blue')# 设置x轴的标签为'Target Value'
plt.xlabel('Target Value')# 设置y轴的标签为'Count'
plt.ylabel('Count')# 设置图表的标题为'Bar Chart of Target Value Counts'
plt.title('Bar Chart of Target Value Counts')# 显示图表
plt.show()

特征工程
进行历史平移特征和窗口统计特征(即最后三个历史平移目标的平均值)
import pandas as pd# 将测试数据和训练数据合并
# 并沿着行的方向(axis=0)合并
# 忽略原有的索引(ignore_index=True)
# 这样可以创建一个包含测试数据和训练数据的单一DataFrame
data = pd.concat([test, train], axis=0, ignore_index=True)# 按照'id'和'dt'列进行降序排序,并重置索引(reset_index(drop=True))
# 这样可以确保数据按照特定的顺序排列,方便后续处理 CSDN@优雅的造轮狮
data = data.sort_values(['id', 'dt'], ascending=False).reset_index(drop=True)# 创建历史平移特征
# 对于每个i值从10到29,创建一个新的列,该列包含每个'id'组中'target'值的i步滞后
for i in range(10, 30):data[f'last{i}_target'] = data.groupby(['id'])['target'].shift(i)# 创建窗口统计特征
# 计算最后三个历史平移目标的平均值,并存储在新的列'win3_mean_target'中
data[f'win3_mean_target'] = (data['last10_target'] + data['last11_target'] + data['last12_target']) / 3# 切分数据为训练集和测试集
# 选择'target'列非空的数据作为训练集,并重置索引
train = data[data.target.notnull()].reset_index(drop=True)
# 选择'target'列空的数据作为测试集,并重置索引
test = data[data.target.isnull()].reset_index(drop=True)# 确定输入特征
# 选择除了'id'和'target'之外的所有列作为训练特征
train_cols = [f for f in data.columns if f not in ['id', 'target']]
训练模型
使用lgbm训练模型
from lightgbm.callback import log_evaluationdef time_model(lgb, train_df, test_df, cols):# 训练集和验证集切分trn_x, trn_y = train_df[train_df.dt>=31][cols], train_df[train_df.dt>=31]['target']val_x, val_y = train_df[train_df.dt<=30][cols], train_df[train_df.dt<=30]['target']# 构建模型输入数据train_matrix = lgb.Dataset(trn_x, label=trn_y)valid_matrix = lgb.Dataset(val_x, label=val_y)# lightgbm参数lgb_params = {'boosting_type': 'gbdt','objective': 'regression','metric': 'mse','min_child_weight': 5,'num_leaves': 2 ** 5,'lambda_l2': 10,'feature_fraction': 0.8,'bagging_fraction': 0.8,'bagging_freq': 4,'learning_rate': 0.05,'seed': 2024,'nthread' : 16,'verbose' : -1,}# 训练模型model = lgb.train(lgb_params, train_matrix, 50000, valid_sets=[train_matrix, valid_matrix],callbacks=[log_evaluation(period=100)])# model = lgb.train(lgb_params, train_matrix, 50000, valid_sets=[train_matrix, valid_matrix], # categorical_feature=[])# callbacks=[early_stopping.early_stopping(500), log_evaluation.log_evaluation(period=50)]# 验证集和测试集结果预测 CSDN@优雅的造轮狮val_pred = model.predict(val_x, num_iteration=model.best_iteration)test_pred = model.predict(test_df[cols], num_iteration=model.best_iteration)# 离线分数评估score = mean_squared_error(val_pred, val_y)print(score)return val_pred, test_predlgb_oof, lgb_test = time_model(lgb, train, test, train_cols)# 保存结果文件到本地
test['target'] = lgb_test
test[['id','dt','target']].to_csv('submit.csv', index=None)经过数据进行历史平移特征和窗口统计特征(即最后三个历史平移目标的平均值)后分数有了明显提升
TIPS:

MSE是均方误差(Mean Squared Error)的缩写,是用于衡量模型预测值与真实值之间差异的指标。它计算了预测值与真实值之间差异的平方,并对所有样本求平均。 MSE越小,表示模型的预测结果与真实值之间的差异越小。它常用于回归问题中,一般情况下取值范围为0到正无穷。
| 1 | 返回分数 | 261.3418 | 2024-07-16_20-42-09.csv | 1gszwJaV | 2024-07-16 20:44:13 |