前言
首届YashanDB「迁移体验官」开放后,陆续收到「体验官」们的投稿,小崖在此把优秀的投稿文章分享给大家~今天分享的用户文章是《使用崖山YMP 迁移 Oracle/MySQL 至YashanDB 23.2 验证测试》(作者:尚雷),满满干货,不要错过!
📣号外!新的征文活动已开启,点击此处即可跳转活动链接,最高可获千元大奖!🤩
 ](https://mp.weixin.qq.com/s/sLGLwmSDdKh5xISbj7IxwA)
](https://mp.weixin.qq.com/s/sLGLwmSDdKh5xISbj7IxwA)
说一下我和崖山数据库的结缘,大概在去年吧,因为我经常在墨天轮写文章,看到崖山数据库推出了一崖山体验官的活动,我就报名参加了。第一次体验了崖山数据库,也测试了我司数据库到崖山数据库的兼容性,发现崖山数据库的兼容性真的很不错的,尤其是对Oracle的兼容性做的真的挺不错。而且崖山数据库的一些命令和Oracle很兼容,对一些Oracle DBA来说上手特别容易,甚至可以说是无缝衔接。
最近受崖山数据库邀请作为【YashanDB迁移体验官】,体验了一把YMP的迁移,我也搭建了测试环境,并验证了我司一些Oracle和MySQL到崖山数据库的迁移,并参与了崖山的直播和大家分享了YMP的迁移感受。
在验证测试中也发现了一些YMP的问题,也将这些问题反馈了崖山官方技术人员,他们的响应速度也是非常快,对于反馈的一些问题有些已经提交研发进行修复,给他们点个大大的赞。
下面我将为大家附上我本次迁移测试的全过程,以及对YMP的迁移感受。不足之处还望大家多多指正。
也希望大家多多支持崖山,多多支持国产数据库,只有大家齐心协力,国产数据库的将来才会越来越好。
01 产品介绍
根据崖山官网介绍,崖山迁移平台(Yashan Migration Platform),简称YMP,是YashanDB提供的数据库迁移产品,支持异构RDBMS与YashanDB之间进行迁移评估、离线迁移、数据校验的功能。另外,YMP提供页面可视化服务,使用者只需通过一些简单的界面操作,即可完成从评估到迁移到数据一致性评估整个流程的执行与监控,整个操作过程门槛比较低,操作比较流畅。
YMP安装后,会集成一个YashanDB内置库,该内置库的作用是用于YMP进行校验评估是需要的,不能作为业务目标库使用,建议在做数据迁移时,单独部署一套YashanDB(目标端业务库)。
内置库是用于ymp在迁移评估阶段待迁移元数据的兼容度评估,不能作为业务目标库使用,做数据同步测试,部署一套YashanDB(目标端业务库)和YMP自嵌的内置库是很规范的。
当前YMP支持(Oracle、MySQL、DM)等异构库到YashanDB的迁移,也支持YashanDB到YashanDB的同构迁移。
YMP整个迁移过程包括如下六个主要阶段:
-
创建任务
-
迁移评估
-
迁移配置
-
离线迁移
-
校验初始化
-
一致性校验
1.1 产品架构
在崖山官网,有如下一幅图介绍YMP的总体架构,如下所示:
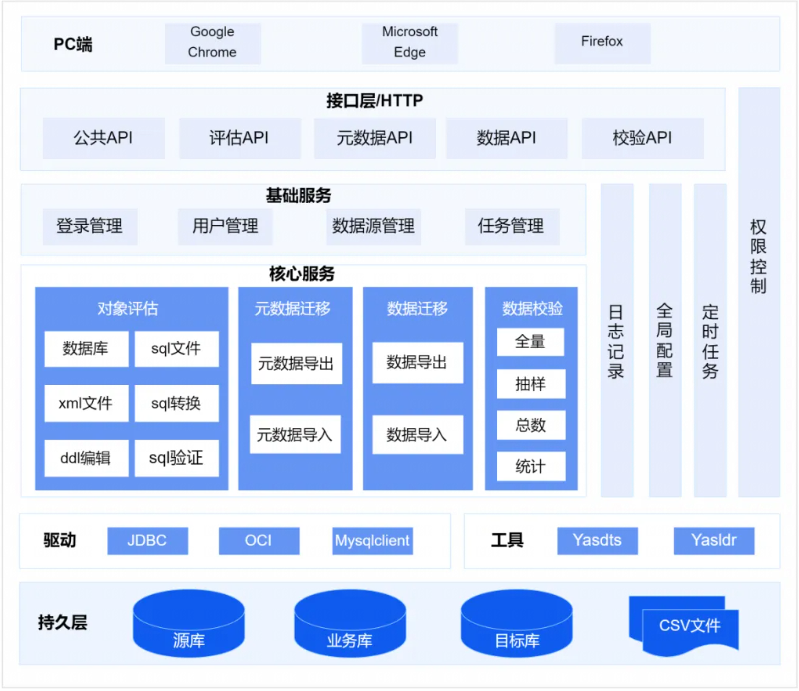
根据上面产品架构显示,主要包括了(对象评估、元数据迁移、数据迁移、数据校验)等几个核心服务。
1.2 数据库版本支持
根据官网资料介绍,当前最新版YMP版本为YMP 23.2,其对异构和同构数据库有一定的版本限制,详见如下:

另外在官网(链接:https://doc.yashandb.com/ymp/23.2/zh/产品简介/产品规格)页面中,也有对异构RDBMS库相应数据类型的支持。
02 外置库部署
部署外置库的目的是为将迁移评估后源端数据迁移到YashanDB后的目标端库,为保证迁移顺利,外置库存放数据目录一定要有足够存储空间。
建议将外置库和YMP内置库分开部署,推荐是将内置库和外置库部署在不同服务器上,若部署在同一台服务器,使用不同用户部署外置库和内置库。
因为条件限制,我本次选择在同一台物理测试服务器上部署外置库和YMP,两者分别部署在不同用户下,外置库选择部署在yashan用户下,内置库部署在ymp用户下。
对于外置库的安装部署,在官方文档里有详细的介绍,本次就不再做过多赘述,只是简单描述整个安装部署过程。(链接:https://doc.yashandb.com/yashandb/23.2/zh/产品描述/产品简介.html)
1) 软件下载:
截止到2024-04-25日,当前YashanDB最新版本为23.2,可在官网主页【https://www.yashandb.com/】,点击【免费下载】根据操作系统类型下载YashanDB 个人版,当前可供下载的类型包括X86和ARM两种类型。
2)环境准备:
环境准备包括服务器系统及网络规划、系统参数调整、目录及用户规划等,服务器和操作系统的配置要满足官网服务器配置需求。
3)软件安装:
崖山数据库的安装方式有命令行安装和可视化安装两种类型,数据库安装类型有(单机主备部署、分布式部署、共享集群部署)这三种部署形态,可以按照自己的业务需求选择相应的部署方式。
4)初始化环境:
数据库安装部署后,需要设置环境变量、初始数据库。如在安装过程中未对监听端口进行调整,默认监听端口为1688。可根据需要设置是否开机启动,实例如下。
[yashan@dsmart install]$ ./bin/yasboot package se gen --cluster yashandb -u yashan -p yashan --ip 10.110.8.42 --port 22 --install-path /data/yashan/yasdb_home --data-path /data/yashan/yasdb_data --begin-port 1688hostid | group | node_type | node_name | listen_addr | replication_addr | data_path
----------------------------------------------------------------------------------------------------------host0001 | dbg1 | db | 1-1 | 10.110.8.42:1688 | 10.110.8.42:1689 | /data/yashan/yasdb_data
----------+-------+-----------+-----------+------------------+------------------+-------------------------Generate config success
补充:安装YashanDB时,可通过指定-d, --child参数,展示任务以及子任务信息,以便了解部署进度。如下所示:
[yashan@dsmart install]$ ./bin/yasboot cluster deploy -t yashandb.toml -d --childtype | uuid | name | hostid | index | status | return_code | progress | cost
------------------------------------------------------------------------------------------------------------------------task | 274c34dbc58b9cbd | DeployYasdbCluster | - | yashandb | SUCCESS | 0 | 100 | 9
-------+------------------+--------------------+----------+-------------------+---------+-------------+----------+------child | 9d1fafb987ad2b56 | DeployDBPrimary | host0001 | yashandb.1-1 | SUCCESS | 0 | 100 | 6 +------------------+--------------------+----------+-------------------+---------+-------------+----------+------| 12f5e1c9e1bfd015 | SyncNodeConfig | - | yashandb | SUCCESS | 0 | 100 | 1 +------------------+--------------------+----------+-------------------+---------+-------------+----------+------| cba90435323b808c | MonitReload | host0001 | yashandb-host0001 | SUCCESS | 0 | 100 | 1
-------+------------------+--------------------+----------+-------------------+---------+-------------+----------+------
task completed, status: SUCCESS
# 返回 task completed, status: SUCCESS 表示安装成功
03 YMP部署
在官网有详细对YMP的安装部署介绍,这里根据官网文档做简要介绍。
(链接:https://doc.yashandb.com/ymp/23.2/zh/产品简介/产品概述.html)
3.1 安装前准备
服务器配置:安装YMP的服务器要满足官网配置要求,详见如下:

操作系统参数调整:需确保操作系统max user processes最大用户线程数不小于65535。
# 查看最大用户线程数
# ulimit -u# 执行如下命令使最大用户线程数临时生效,重启后无效
# ulimit -u 65536# 执行执行如下命令将最大用户线程数写入/etc/security/limits.conf文件,重启后参数永久生效
echo " * soft nproc 65536 * hard nproc 65536 " >> /etc/security/limits.conf
用户准备:创建一个用户用于安装YMP,以YMP为例,在用户创建和授权后,后续所有安装步骤均在该用户下操作。
# 新建YMP用户
# useradd -d /home/ymp -m ymp
# passwd ymp
开放端口:如未进行调整,YMP将采用如下端口。

如无特殊需求,建议关闭服务器防火墙:
# 关闭防火墙
# systemctl stop firewalld#关闭开机自启
#systemctl disable firewalld
JDK环境准备:YMP仅支持在JDK8或JDK11的环境下安装。
通过Java官方路径下载上述版本的JDK并安装成功后,还需配置如下环境变量:
# 以JDK安装路径为/usr/tools/jdk8为例
# vi /etc/profile# 在文件结尾添加如下
# export JAVA_HOME=/usr/tools/jdk8
# export PATH=$JAVA_HOME/bin:$PATH
# export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar # 重新载入配置文件
# source /etc/profile# 安装成功后查看JDK版本信息
# java -version
libaio环境准备:YMP运行需要libaio动态库。
# 查看是否已安装libaio动态库
# rpm -qa | grep libaio# 若未有版本信息打印,安装libaio
# yum install -y libaio
OCI环境准备(可选):若用YMP迁移Oracle到YashanDB数据库,需要安装OCI环境。
到Oracle官网下载OCI 客户端软件。
(链接:https://www.oracle.com/database/technologies/instant-client/linux-x86-64-downloads.html#license-lightbox)
YMP当前仅支持 OCI Version 19.19.0.0.0及以上版本。
上传安装包至YMP用户/home/ymp/路径。
# 修改安装包所属用户及用户组为ymp用户
# chown ymp:ymp instantclient-xxx# 从root用户切换至ymp用户
# su - ymp# 切换至安装路径
$ cd /home/ymp# 解压OCI安装包
$ unzip instantclient-xxx
软件包准备:请根据自己操作系统选择对应YMP软件安装包,当前YMP有Linux X86和Linux ARM两个版本,最新版为 Yashan Migration Platform 23.2.1版本。
将下载的YMP软件包上传到服务器/home/ymp用户。
# 修改安装包所属用户及用户组为ymp用户
# chown ymp:ymp yashan-migrate-platform-v23.2.1.0-linux-x86-64.zip # 从root用户切换至ymp用户
# su - ymp# 切换至安装路径
$ cd /home/ymp
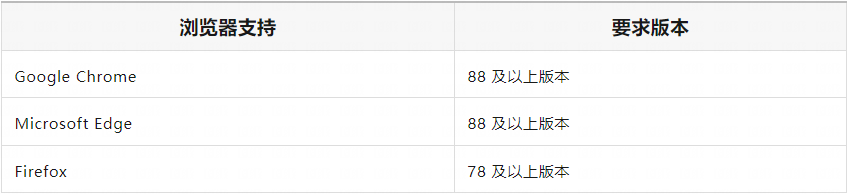
客户端浏览器: YMP的操作需要浏览器支持,YMP支持当前主流浏览器,参照如下:
YMP支持浏览器Google Chrome、Microsoft Edge和Firefox,建议使用当前较新的版本。
3.2 安装YMP
1)解压YMP安装包:使用ymp用户解压YMP安装包,操作如下:
# 切换至YMP安装目录
# su - ymp
$ cd /home/ymp/
$ unzip yashan-migrate-platform-v23.2.1.0-linux-x86-64.zip
2)安装参数调整:可依据实际需要对默认内置库安装端口、启动参数、密码登进行设置,其中有两个文件非常重要,如下所示:
# 文件所在目录 /home/ymp/yashan-migrate-platform/conf
db.properties: 默认内置库安装配置文件,里面包含内置库sys默认密码,默认端口号,默认字符集(UTF8),详细内容如下:
YASDB_PASSWORD=ymppw602.
YASDB_PORT=8091
YASDB_CHARACTER_SET=UTF8
## character_set optional: UTF8, ASCII, ISO88591, GBKapplication.properties: YMP配置文件,该文件包含内容较多,详细内容如下
# YMP服务端口
server.port=8090# 用户登录后空闲过期时间,单位秒(s),默认15分钟
shiro.session.timeout=900
# YMP使用的最大堆内存,单位: GB
ymp_memory=4
# YMP使用的堆外内存,单位: GB
ymp_direct_memory=2# ========================================YMP业务数据库=============================================
# YMP业务数据库连接信息
spring.datasource.url=jdbc:yasdb://127.0.0.1:8091/yashan
spring.datasource.username=YMP_DEFAULT
spring.datasource.password=ymppw602
spring.datasource.largePoolSize=64M
spring.datasource.cursorPoolSize=64M
# 默认内置库表类型,默认HEAP,可选HEAP,TAC,LSC
spring.datasource.defaultTableType=HEAP
spring.datasource.openCursors=3000
spring.datasource.sharePoolSize=2G
spring.datasource.dateFormat=yyyy-mm-dd hh24:mi:ss
spring.datasource.ddlLockTimeout=2# ========================================评估=============================================# YMP的最大并行任务数
task.parallel.max-num=500
# 预计数据迁移速度,KB/s。修改会影响评估结果预计迁移时间的大小
commons.dataMigrateSpeed=51200
# 预计对象迁移速度,number/s。修改会影响评估结果预计迁移时间的大小
commons.objMigrateSpeed=200
# 评估任务单个会话获取DDL的数量,如果Oracle性能较差,则需要降低该值
assessment.ddlCount=50
# 评估任务最多同时拥有的会话数,如果Oracle性能较差,则需要降低该值
assessment.maxThreadCount=20
# 内置库表类型是否为LSC,默认为false
isLscTable=false
# 拦截的Oracle数据源db/schema黑名单
schemaBlackList.oracle=ANONYMOUS,APEX_030200,APEX_PUBLIC_USER,APPQOSSYS,BI,CTXSYS,DBSNMP,DIP,EXFSYS,FLOWS_FILES,HR,IX,MDDATA,MDSYS,MGMT_VIEW,OE,OLAPSYS,ORACLE_OCM,ORDDATA,ORDPLUGINS,ORDSYS,OUTLN,OWBSYS,OWBSYS_AUDIT,PM,SCOTT,SH,SI_INFORMTN_SCHEMA,SPATIAL_CSW_ADMIN_USR,SPATIAL_WFS_ADMIN_USR,SYS,SYSMAN,SYSTEM,WMSYS,XDB,XS$NULL
# 拦截的MySQL数据源db/schema黑名单
schemaBlackList.mysql=information_schema,mysql,performance_schema,sys
# 拦截的dm数据源db/schema黑名单
schemaBlackList.dm=SYS,SYSDBA,SYSSSO,SYSAUDITOR,CTISYS# ========================================迁移=============================================# 元数据迁移过程中源端、目标端查询视图连接数。在元数据迁移过程中会有分批量的查询的动作, 需要开启多个查询连接并行查询。该参数配置元数据迁移的源端、目标端查询的并行线程数,决定了对数据库的查询最大连接数,不设置默认20
migration.parallel.query=20
# 元数据迁移过程中目标端执行创建连接数。在元数据迁移过程中会并行把对象在目标端的执行,以提升迁移效率。该参数配置元数据迁移的目标端DDL执行的并行线程数,决定了连接数据库的执行最大连接数,不设置默认20。migration.parallel.query和migration.parallel.execute的连接总和,是最终迁移过程中所有的目标端数据库连接数。
migration.parallel.execute=20
# 创建索引是否使用并行参数,true/TRUE:使用,false/FALSE:不使用
migration.parallel.createIndexUseParallel=true
# 索引创建的并行度,需要考虑migration.parallel.execute。例:migration.parallel.execute:10,migration.parallel.index: 5,表示,同时10个连接在并行建索引,每个索引的并行度是5(CREATE INDEX XXX PARALLEL 5)。不填默认CPU核数。
migration.parallel.index=5
# 数据迁移前是否将表设为nologging,默认为false
setNoLogging=false
# 导出oracle时使用的导出方式,支持 [dts, jdbc] 两种方式
export.oracle.tool=dts
# 导出时每个csv文件的行数
export.csv.exportRowsEveryFile=2000000
# 迁移成功时候是否删除csv文件
export.csv.isRemoveCsvFileInSuccess=true
# csv文件存储路径包含对schema和table的拼接,schema名或table名中包含以上字符时,将会被替换,以避免被操作系统识别错误导致迁移失败;不过这可能会使某些表(比如AA$与AA.)在替换后使用的csv文件存储路径相同,导致迁移失败(No such file or directory),可以通过重新迁移失败表来解决
export.csv.path.replacement.from=\ /'."*$
# 发生csv文件存储路径字符替换时(详见export.csv.path.replacement.from),指定替换的目标字符或字符串
export.csv.path.replacement.to=_
# 导出时大表拆分的个数
export.table.splitCount=5
# 导出时触发大表拆分的行数
export.table.splitConditionCount=10000000
# 导出时触发大表拆分的表大小(G)
export.table.splitConditionSize=5
# 导出时带lob字段大表拆分的个数
export.lobTable.splitCount=5
# 导出时触发带lob字段大表拆分的行数
export.lobTable.splitConditionCount=1000000
# 导出时触发带lob字段大表拆分的表大小(G)
export.lobTable.splitConditionSize=5
# 使用jdbc导出时每个csv文件的最大行数
export.jdbc.thresholdForSplittingFileLines=5000000
# 使用jdbc导出时每个csv文件的最大大小(M)
export.jdbc.thresholdForSplittingFileSize=3072
# #yasldr More References: http://doc.yashandb.com/yashandb/22.2/zh/%E5%B7%A5%E5%85%B7%E6%89%8B%E5%86%8C/yasldr/yasldr%E4%BD%BF%E7%94%A8%E6%8C%87%E5%AF%BC.html
# yasldr导入时的并行度
import.degree_of_parallelism=16
# yasldr导入时每批次的CSV数据行数
import.batch_size=2048
# yasldr导入方式,包括BASIC方式和BATCH方式
import.mode=BATCH
import.SENDERS=7
import.CSV_CHUNK_SIZE=128
# ========================================校验=============================================
# 校验任务限制每个数据源支持的最大连接数
checkTask.datasource.max-connection=500
# 校验任务获取连接超时时间,单位:ms
checkTask.datasource.connection-timeout=10000
# 校验任务获取的连接池中维持的最小连接数
checkTask.datasource.minimum-idle=0
# 校验任务的最大并行任务数
checkTask.task.parallel.max-num=20
# 校验任务的子任务的最大并行任务数,即一个任务多少个表在同时校验
checkTask.subTask.parallel.max-num=200
# 校验任务的全量校验对FLOAT数据类型的校验精度
checkTask.checkFloatPrecision=6
# 校验任务的数据类型映射有一边是char数据类型就移除数据右侧空格进行对比
checkTask.isRemoveCharBlank=true
以上两个文件参数都可以依据需要进行调整,调整后重启YMP生效。
3)YMP安装
YMP安装时按默认方式自行安装YashanDB作为内置库。
默认内置库相关信息:
-
部署形态:单机
-
集群名称:ymp
-
安装目录:/home/ymp/yashan-migrate-platform/db
YMP安装内置库有两种方式:
方式一:安装内置库并启动YMP
# 进入安装目录执行安装命令
$ cd /home/ymp/yashan-migrate-platform/
$ sh bin/ymp.sh install --db /home/ymp/yashandb-23.2.1.0-linux-x86_64.tar.gz
方式二:安装内置库和OCI客户端并启动YMP
# 进入安装目录执行安装命令
$ cd /home/ymp/yashan-migrate-platform/
$ sh bin/ymp.sh install --db /home/ymp/yashandb-personal-23.2.1.100-linux-x86_64.tar.gz --path /home/ymp/instantclient_19_19
上述两种方式的安装都需要借助YashanDB软件安装压缩文件。
4)查看运行状态:通过如下方式可查看YMP运行状态
[ymp@dsmart ~]$ cd yashan-migrate-platform/
[ymp@dsmart yashan-migrate-platform]$ sh bin/ymp.sh status
YMP is running, pid is 9512.
Built-in database is used, pid is 9382.# 还可以通过如下方式查看YMP版本
[ymp@dsmart yashan-migrate-platform]$ sh bin/ymp.sh -v
Yashan-migrate-platform version: Release v23.2.1.0
YashanDB SQL Personal Edition Release 23.2.1.100 x86_64
YashanDB Loader Personal Edition Release 23.2.1.100 x86_64 2d13f1d
04 访问YMP(崖山数据迁移平台)
4.1 设置初始密码
YMP部署后,YMP提供了账号和密码同为admin的账户,使用该账户初次登录会提示需修改初始密码,并且初始密码的设置要符合密码规范要求。
修改初始密码后,使用新密码登录YMP,主界面如下:
如希望重新设置admin密码,可通过主界面右上角【个人中心】进行设置。
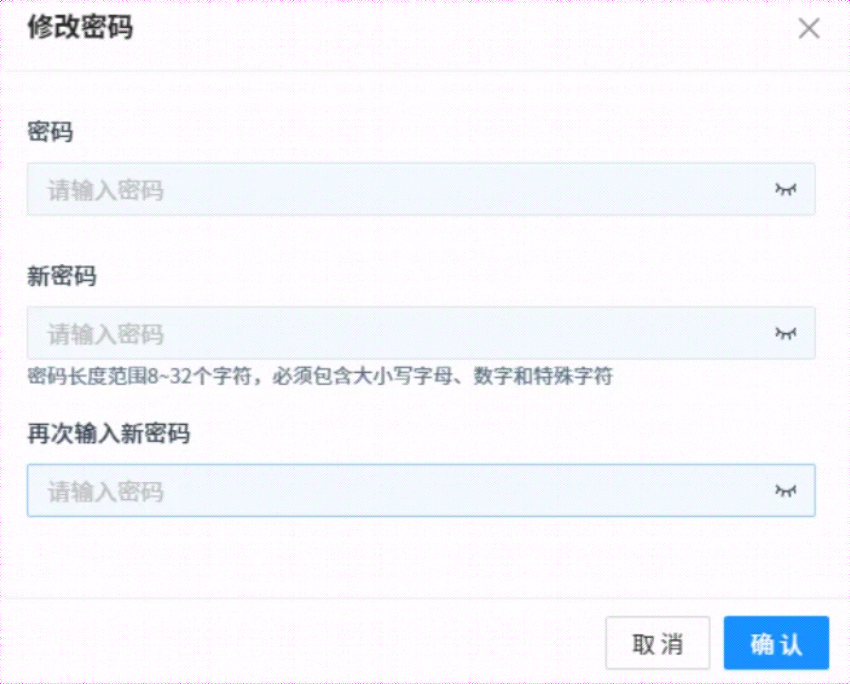
点击【个人中心】进入如下页面:

点击上图红色箭头处,可修改admin密码,如下所示:
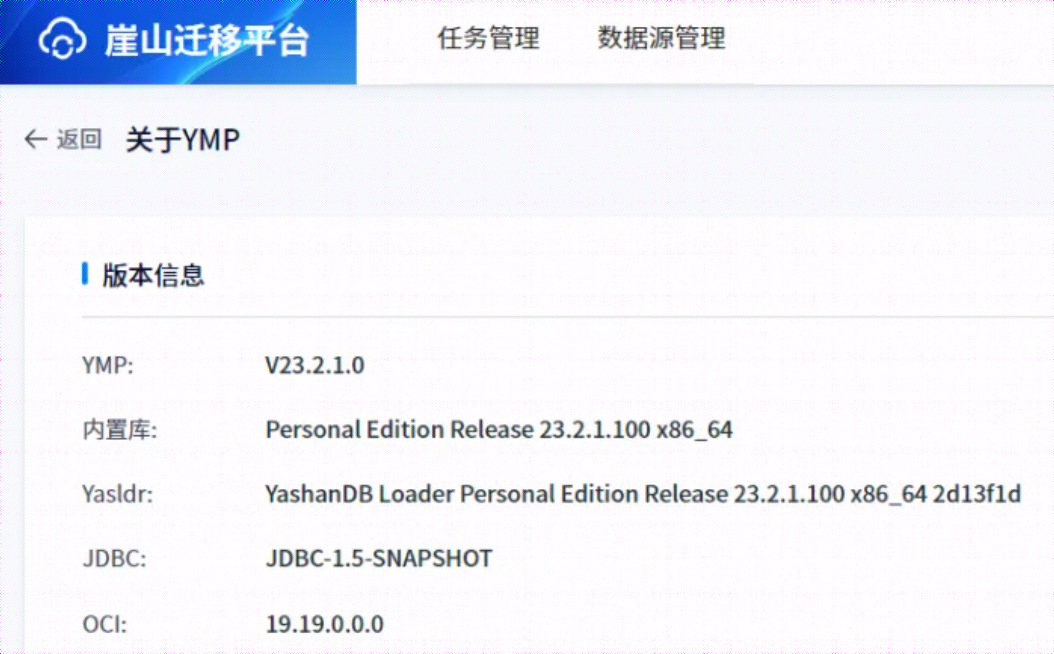
4.2 查看YMP版本信息
在【个人中心】处也能查看到当前YMP版本、内置库版本、JDBC及OCI等版本信息,如下所示:
05 数据源管理
5.1 创建用户并授权
这一步操作目的主要是为连接源端数据源,评估源端对象兼容性做准备。
此处有三种迁移平台所需权限,分别如下:
-
跨用户评估迁移权限
-
仅本连接用户元数据评估迁移所需权限
-
跳过评估所需权限
注:
跨用户评估迁移权限:指的是迁移平台使用的用户和需要迁移的用户不是同一个的场景
仅本连接用户元数据评估迁移所需权限:指的是迁移平台使用的用户和需要迁移的用户是同一个的场景
本次选择使用跨用户评估迁移权限,源端执行如下操作:
CREATE USER orauser IDENTIFIED BY XXXX;
GRANT CREATE SESSION TO orauser;
GRANT SELECT_CATALOG_ROLE TO orauser;
GRANT SELECT ANY TABLE TO orauser;
GRANT SELECT ANY SEQUENCE TO orauser;
5.2 添加数据源
在YMP主界面点击【数据源管理】,如下所示

5.2.1 添加源端
点击上图箭头处【添加数据源】
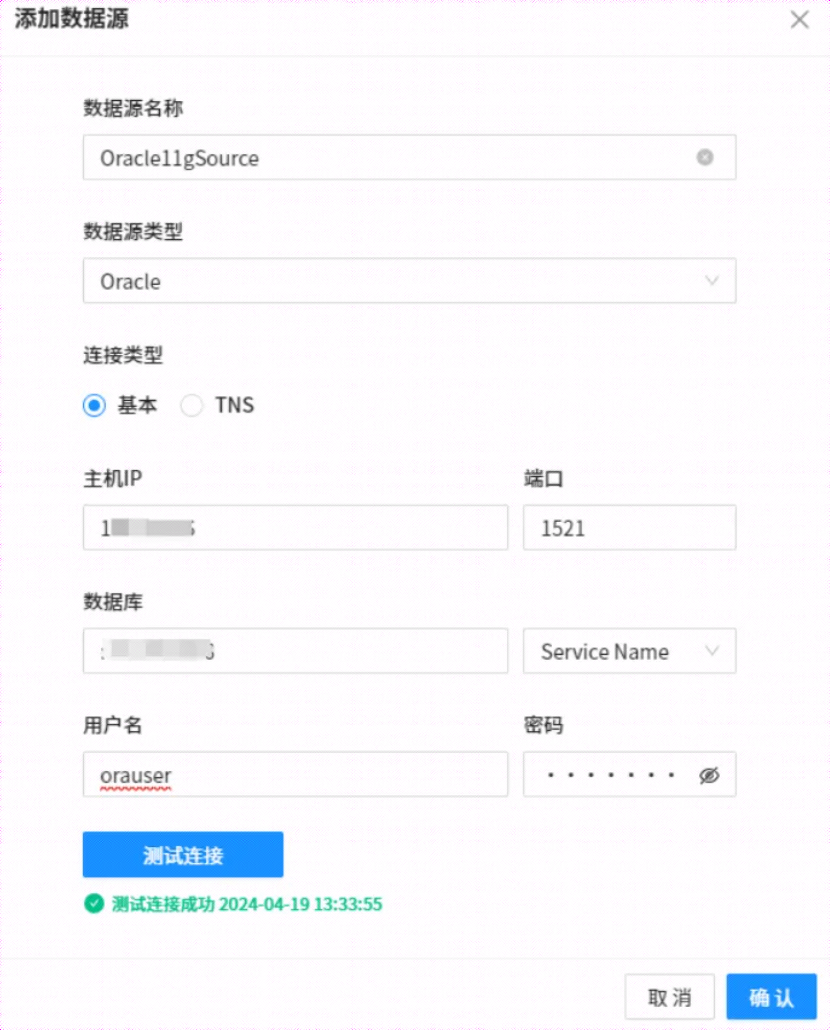
参照上图信息,填写数据源名称、数据源类型、选择连接类型、源端IP和端口、数据库可以选择ServiceName或者SID,填写用户名和密码。
然后点击测试连接,成功连接会有返回提示,然后点击确认,源端数据源添加后,如下所示:

并可以对上述创建的数据源进行相应信息修改和删除数据源。
5.2.2 添加目标端
参照添加源端,设置目标端,本次我选择使用sys系统用户,如下所示:
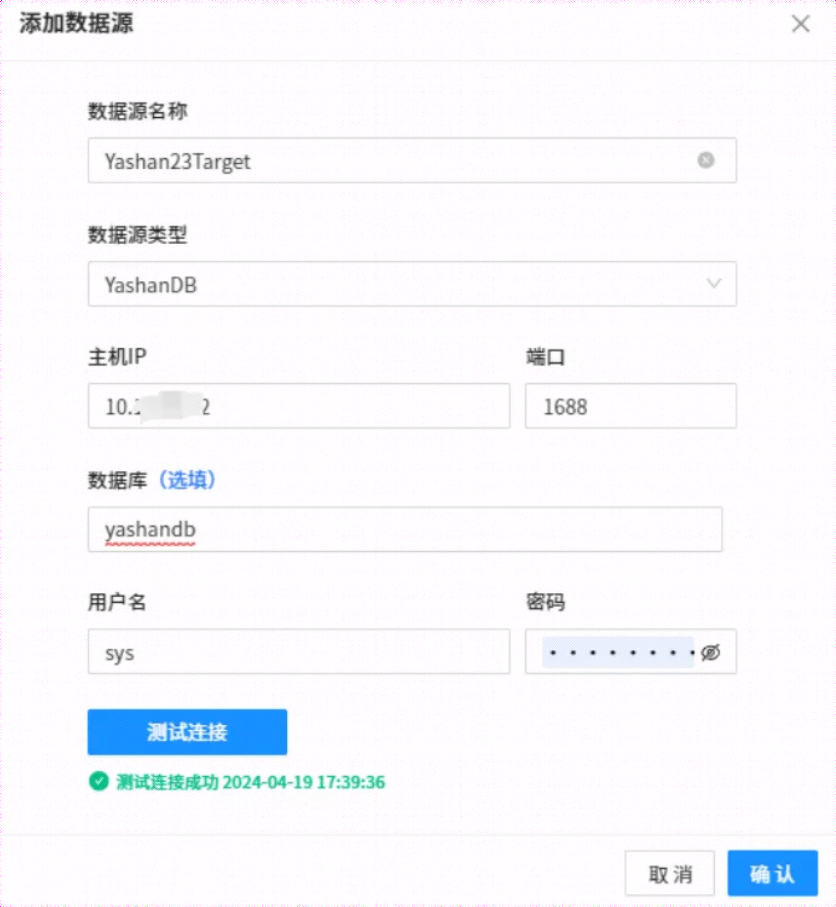
数据源类型选择 YashanDB,端口本次采用默认端口,然后点击测试连接,成功连接会有返回提示,然后点击确认,目标端数据源添加后,如下所示:

06 任务管理
上述数据源创建后,方可进行任务管理。
6.1 创建任务
创建任务是进行数据库迁移评估的起点,首先要先创建一个迁移评估任务。点击【任务管理】,进入任务管理界面。
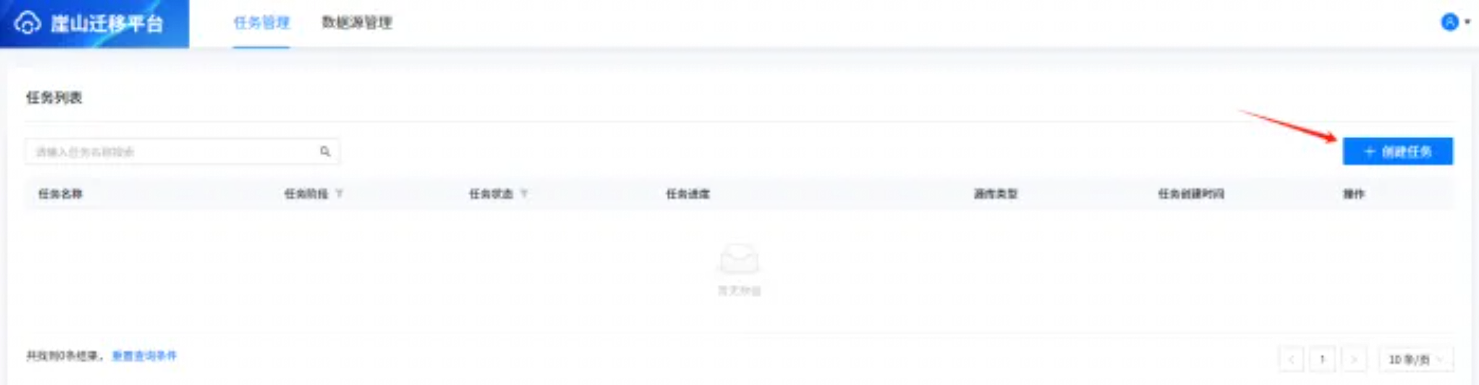
如上图所示,点击右上角【创建任务】按钮创建任务,如下所示:
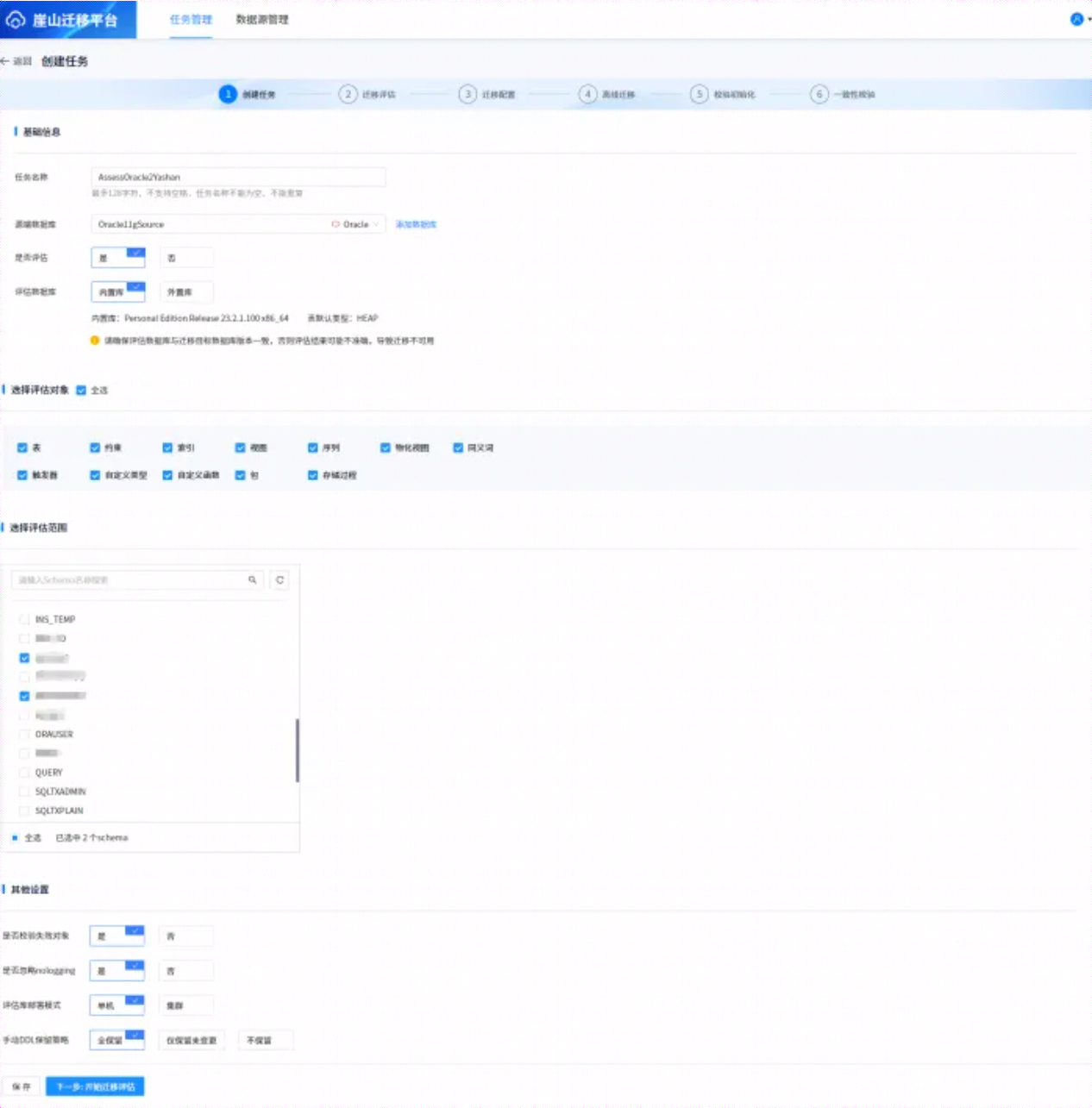
创建任务有四个主要选项,分别是:
-
基础信息 包含[任务名称、源端数据库、是否评估、评估数据库(若选择外置库,需设置外置库信息)]
-
选择评估对象 包含如表、约束、索引、视图等相关信息
-
选择评估范围 可根据需要选择待评估的对象用户
-
其他设置 包含[是否校验失效对象、是否忽略nologging、评估部署模式、手动DDL保留策略]
在官网这部分有对上述几个主要选项的详细描述,限于篇幅,本次不做赘述。
(链接 :https://doc.yashandb.com/ymp/23.2/zh/用户指南/任务管理/创建任务.html )
上述信息填写后,可点击【保存】,会暂存填写的任务信息,此时任务状态为评估编辑中。若希望进行评估,可点击【下一步:开始迁移评估】进入迁移评估阶段,如下所示:
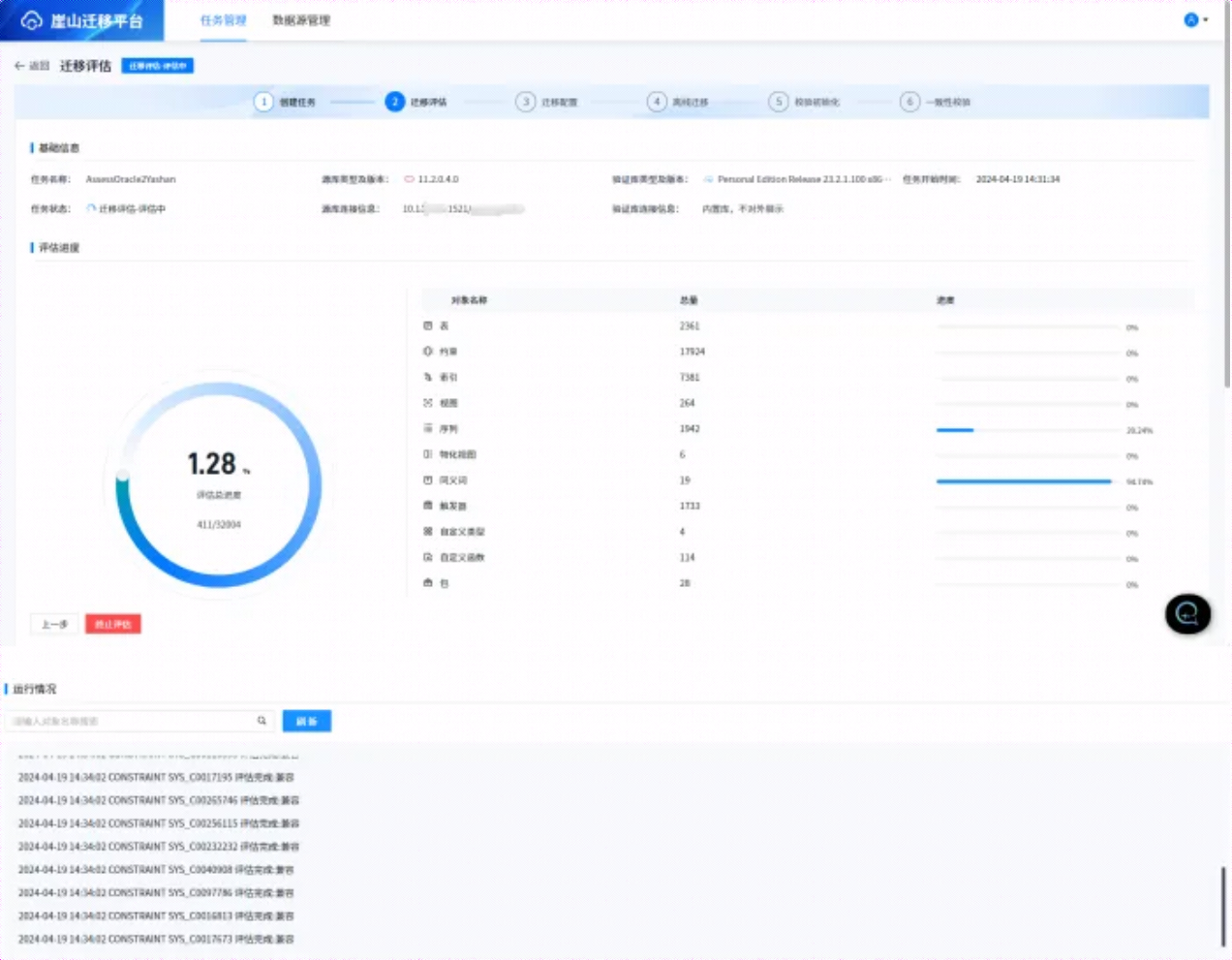
迁移评估结束后,会给出评估结果,如下所示:
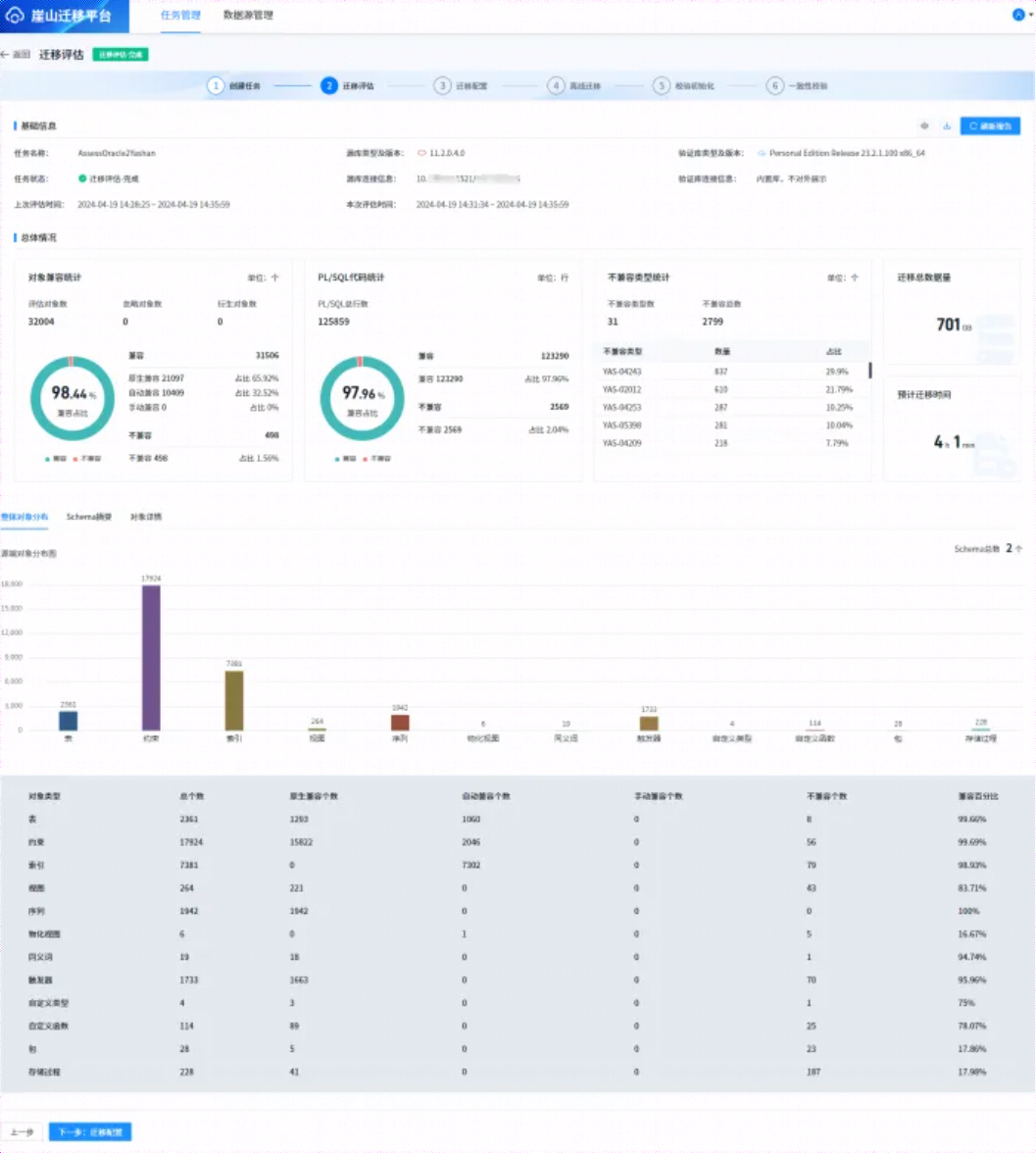
本次仅为测试验证,如上图所示,在【对象详情】界面,勾选【不兼容】,然后点击【确定】按钮,如下所示:

然后勾选 【全选所有】,再点击又上角【批量设置是否忽略】,选择【忽略】,如下所示:
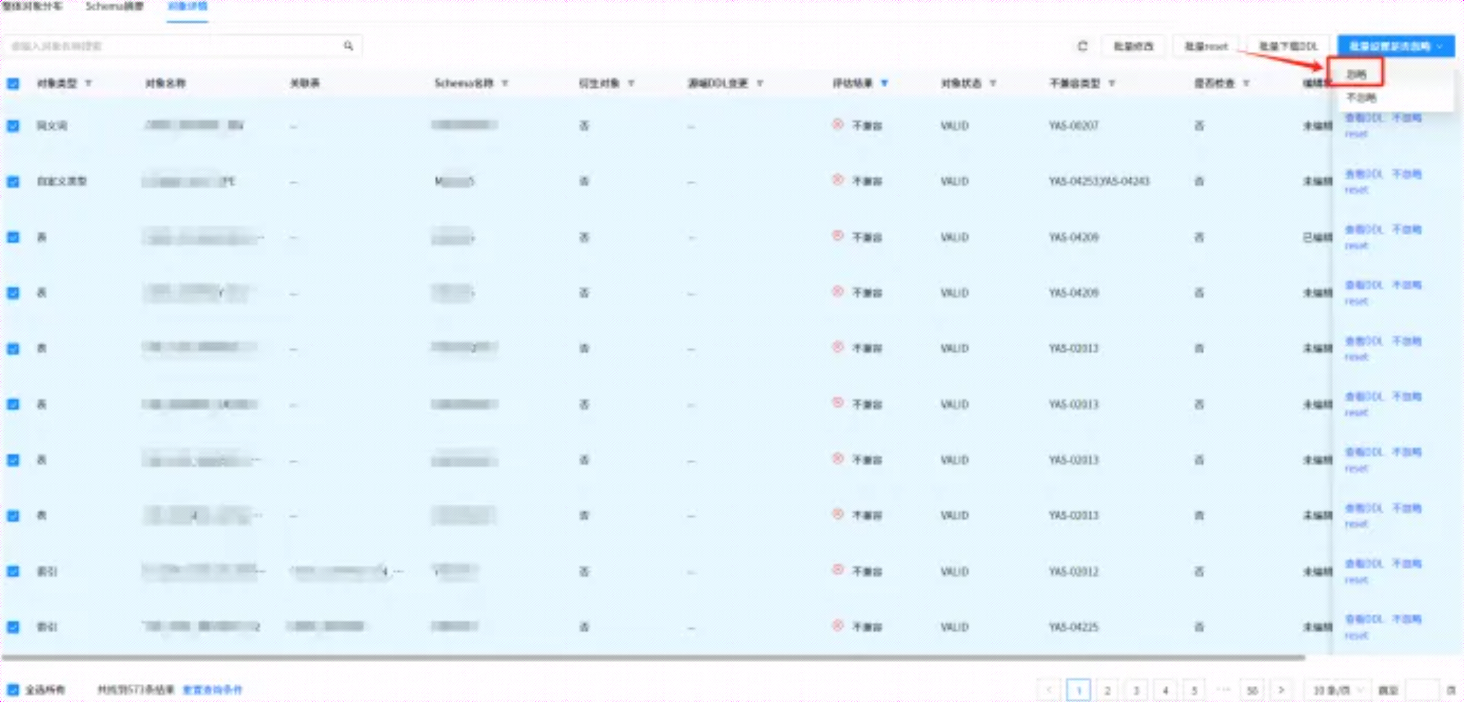
此时,会有如下提示,提示需要重新刷新报告,如下所示:

然后点击 【刷新报告】,待报告刷新后,点击【下一步:迁移配置】,如下所示:
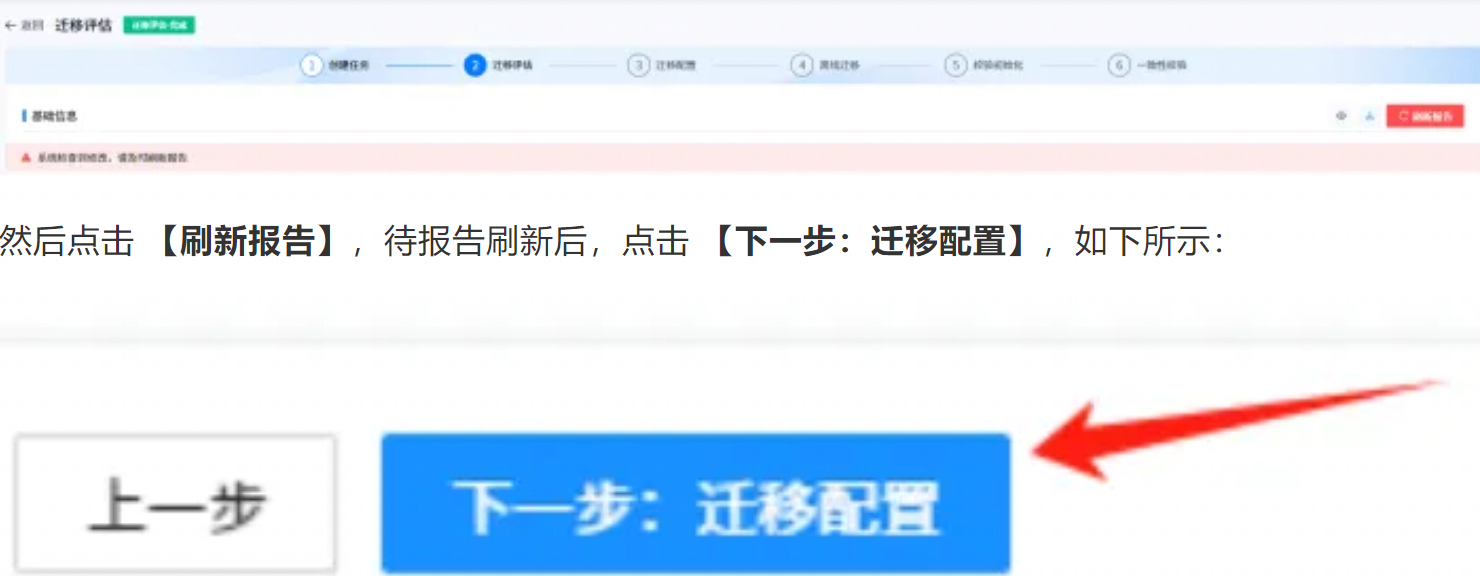
选择批量忽略不兼容对象,然后点击【迁移配置】
6.2 迁移配置
上面点击【下一步:迁移配置】进入如下界面,如下所示:
注:可根据需要进行配置,本次仅为测试,绝大多数配置选择默认。
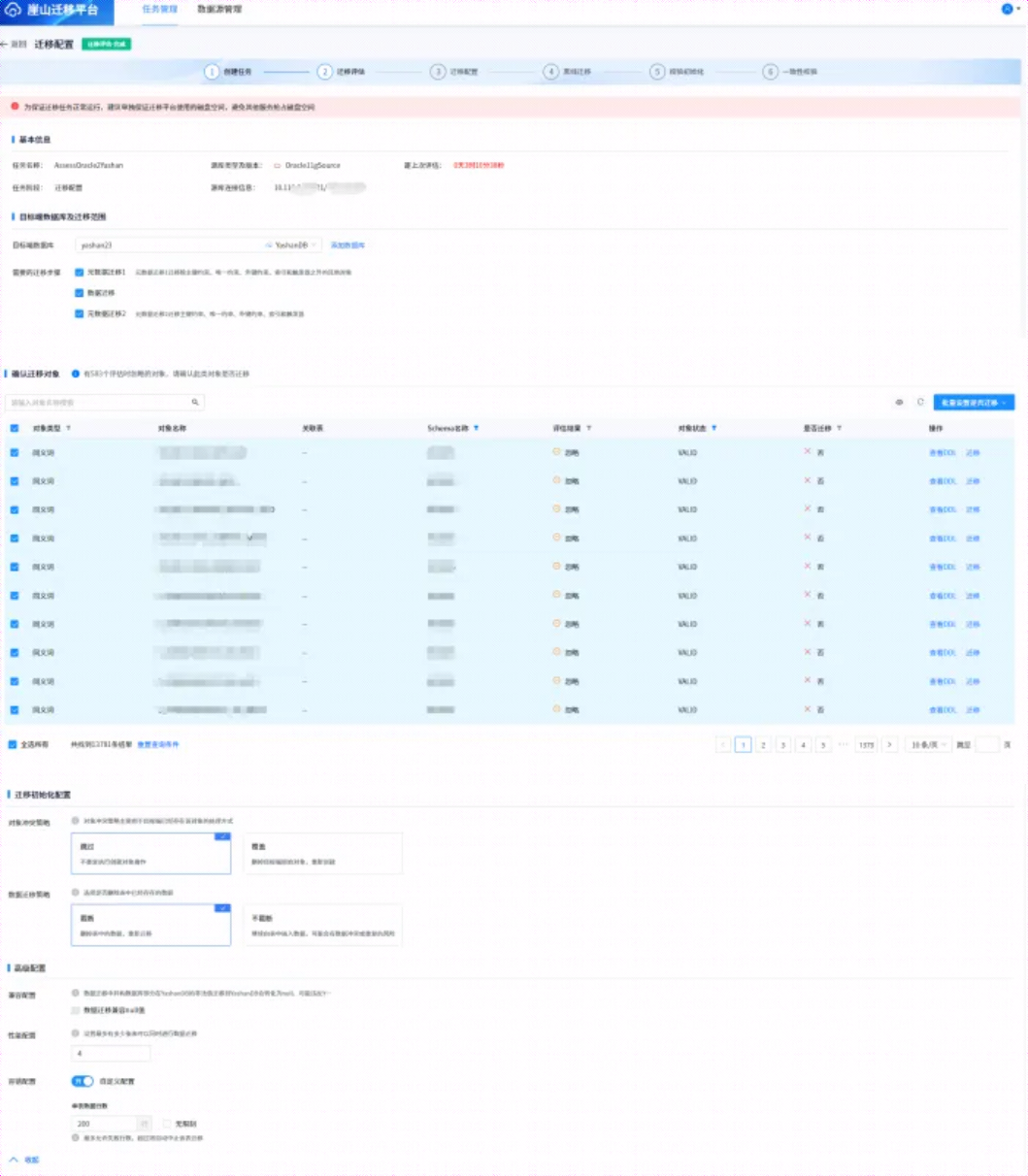
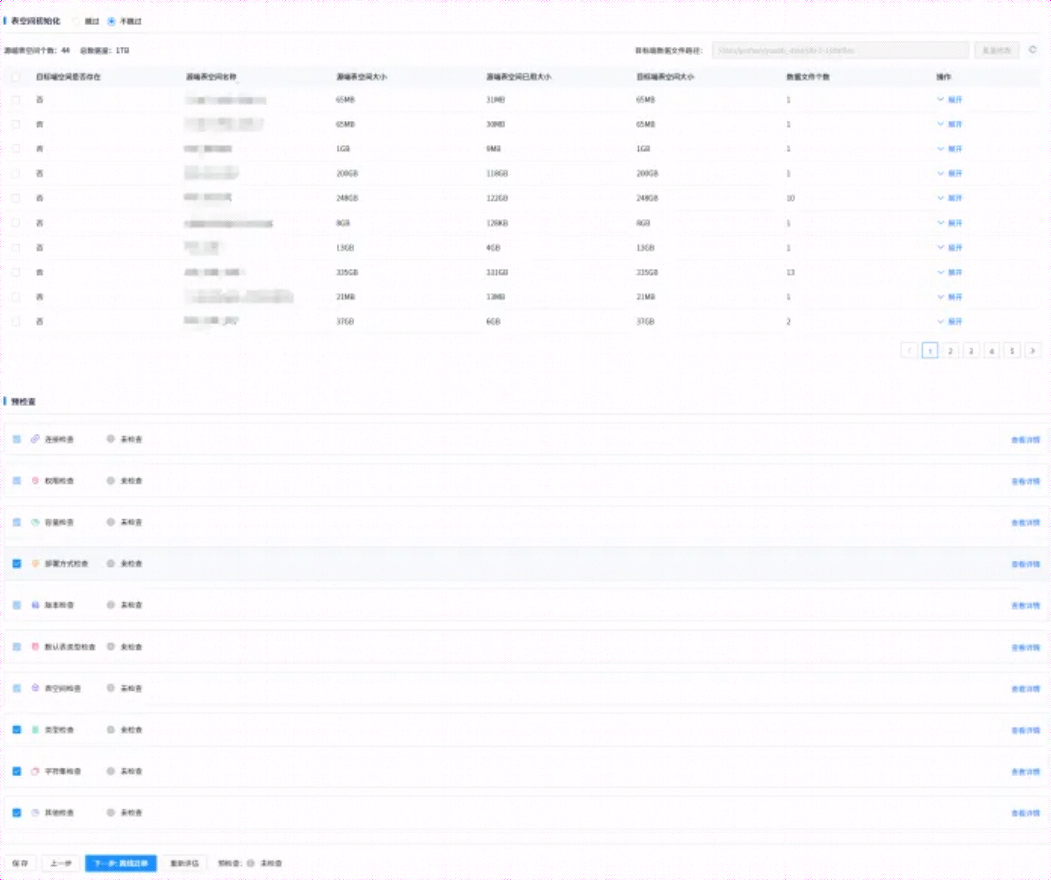
点击 【下一步:离线迁移】
6.3 离线迁移
在上面点击离线迁移后,进入如下界面,如下所示:
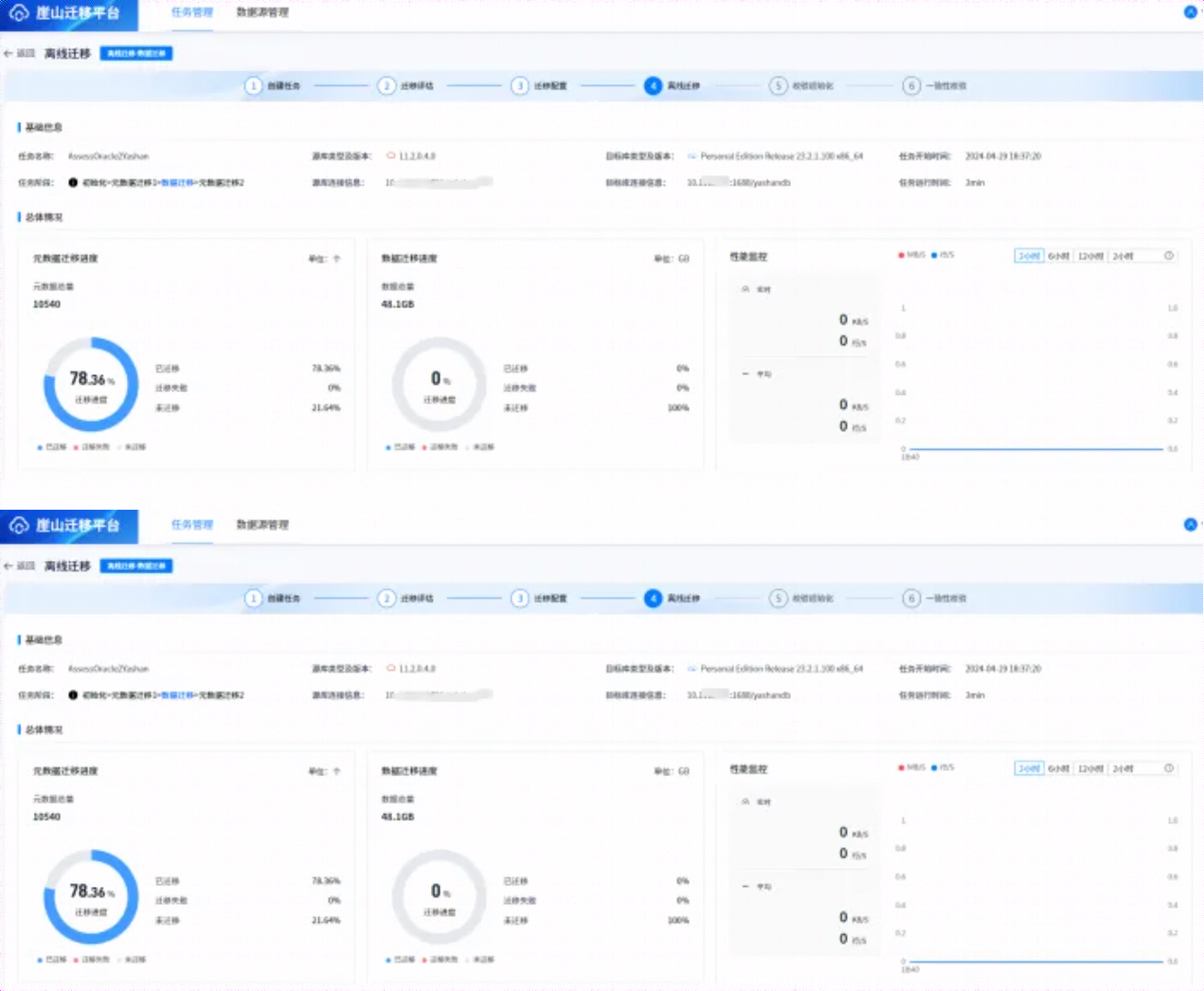
待一段时间后,迁移结束,信息如下所示:
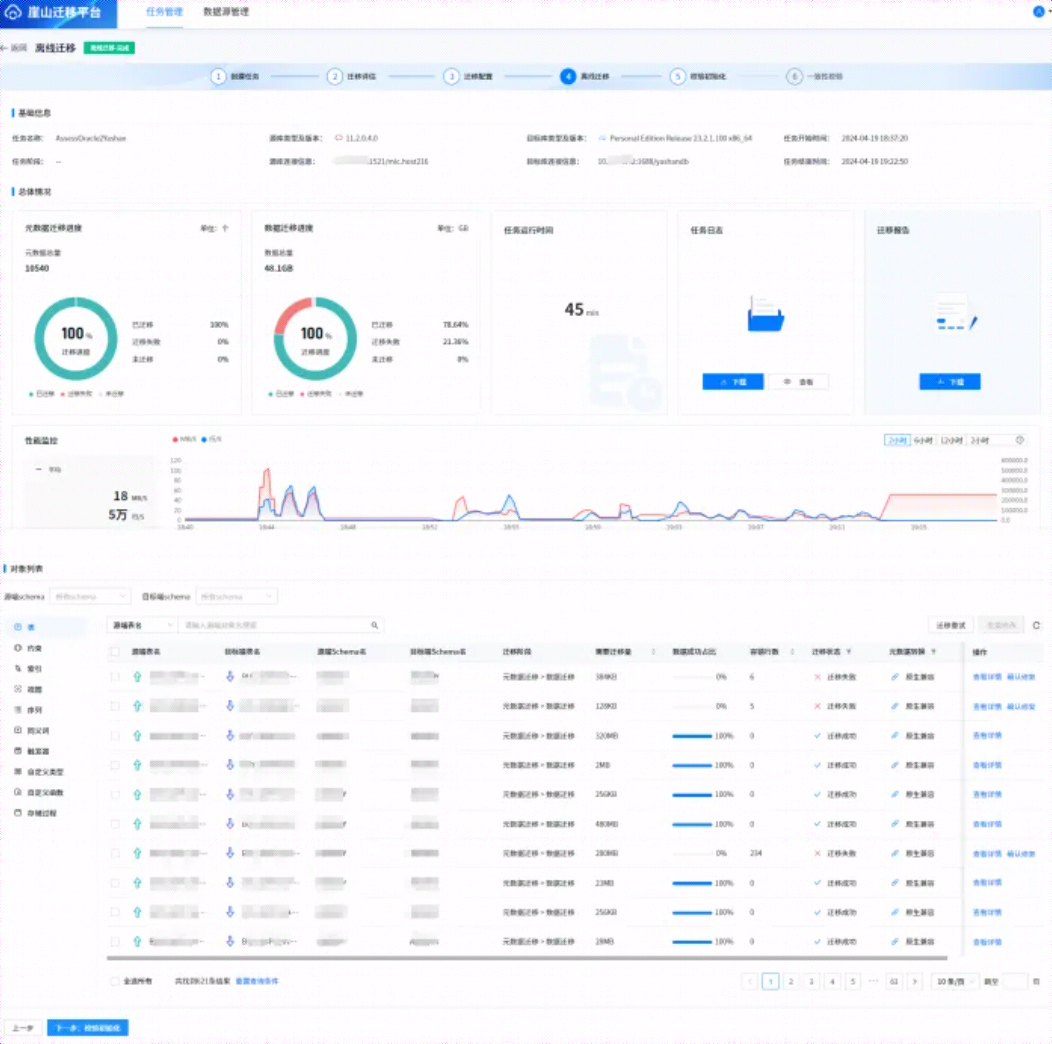
6.4 校验初始化
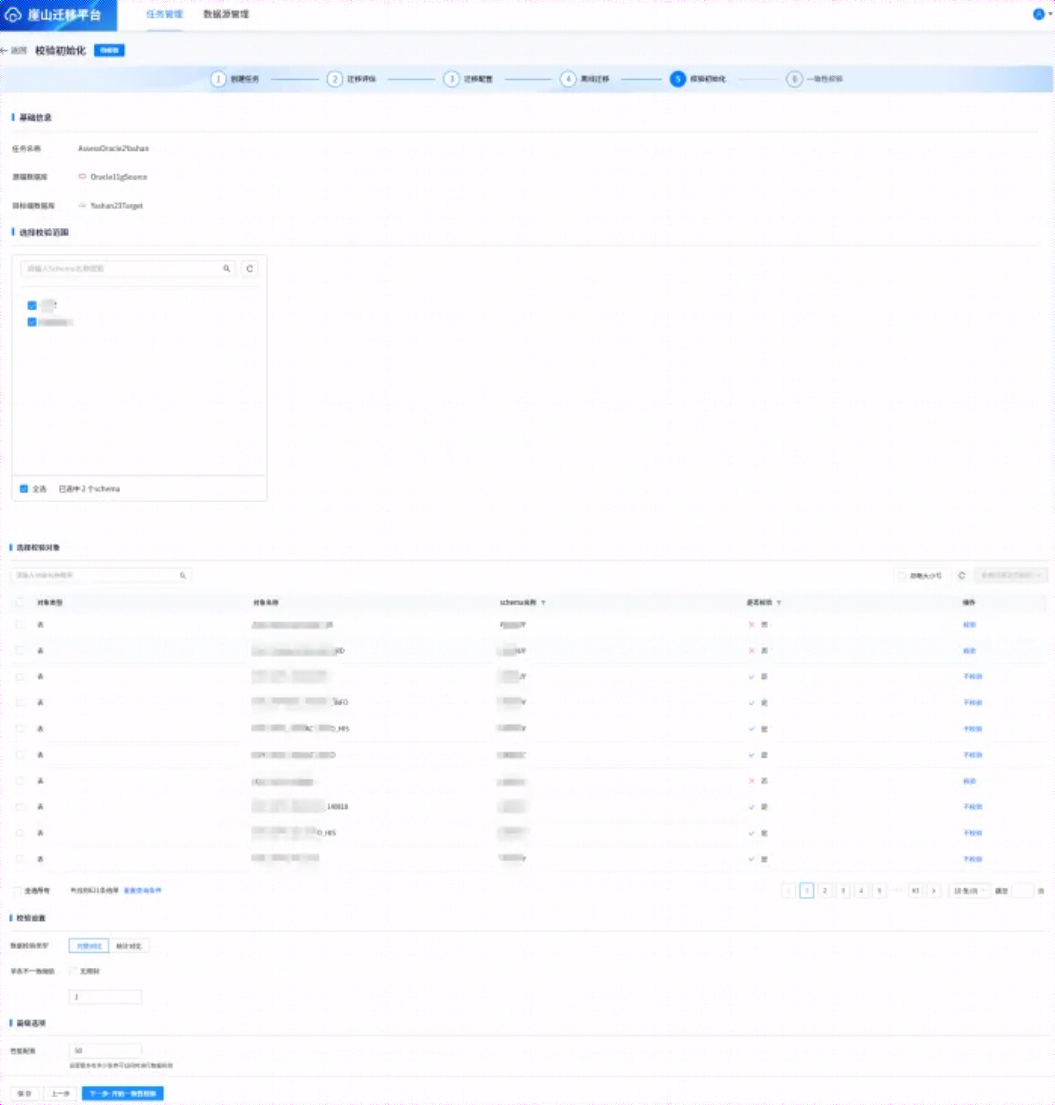
点击上图【下一步:校验初始化】,进入如下页面,如下所示:
6.5 一致性校验
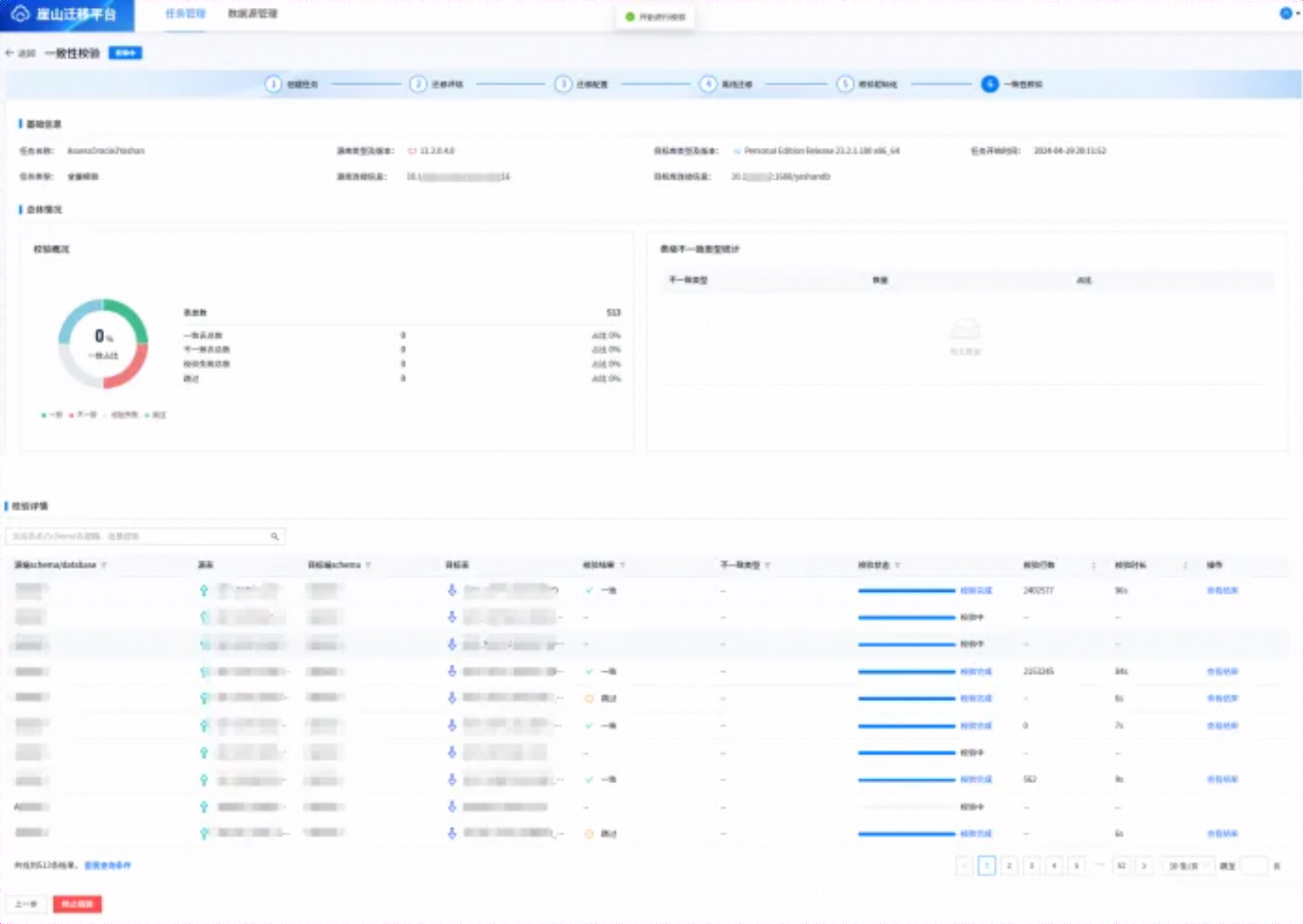
如上图所示,点击【下一步:开始一致性校验】,如下所示:
6.6 MySQL 迁移
上面我们主要是测试了Oracle到崖山的数据迁移,接下来我们将演示下MySQL到崖山数据库的迁移。
本次选择的MySQL库版本是 5.6,通过YMP将其迁移到yashanDB库。
6.6.1 添加数据源
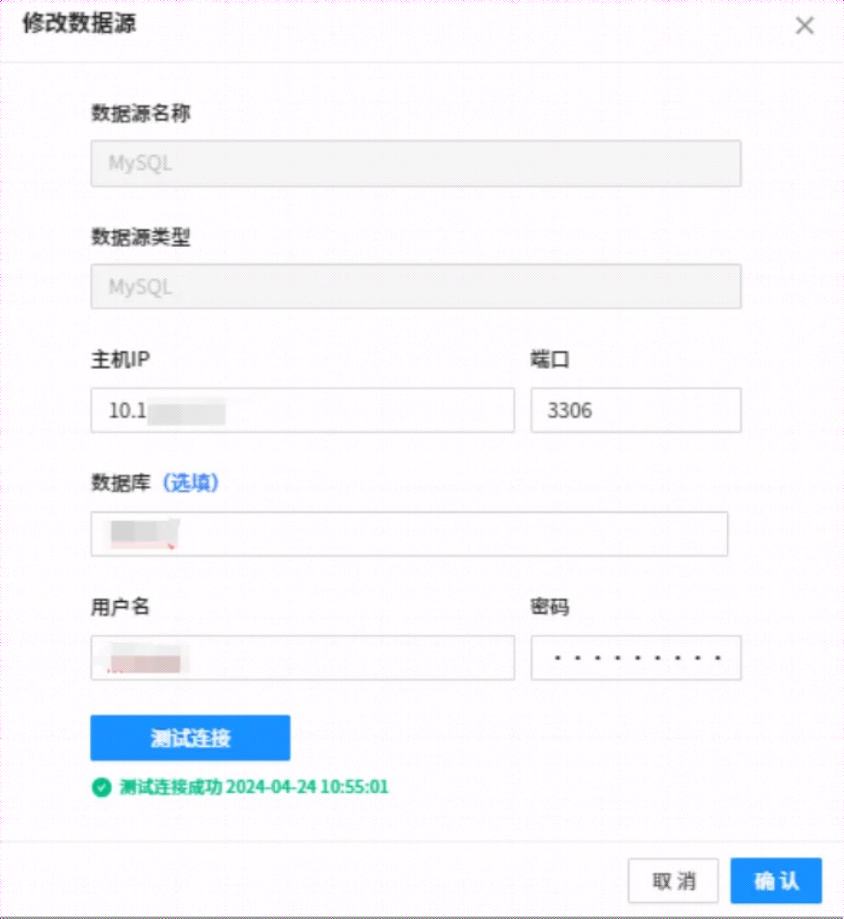
参照上述Oracle迁移,在【数据源管理】界面,添加数据源名称、选择数据源类型为MySQL,根据MySQL环境设置数据库IP和端口号、用户名和密码,【测试连接】通过,点击【确认】保存。
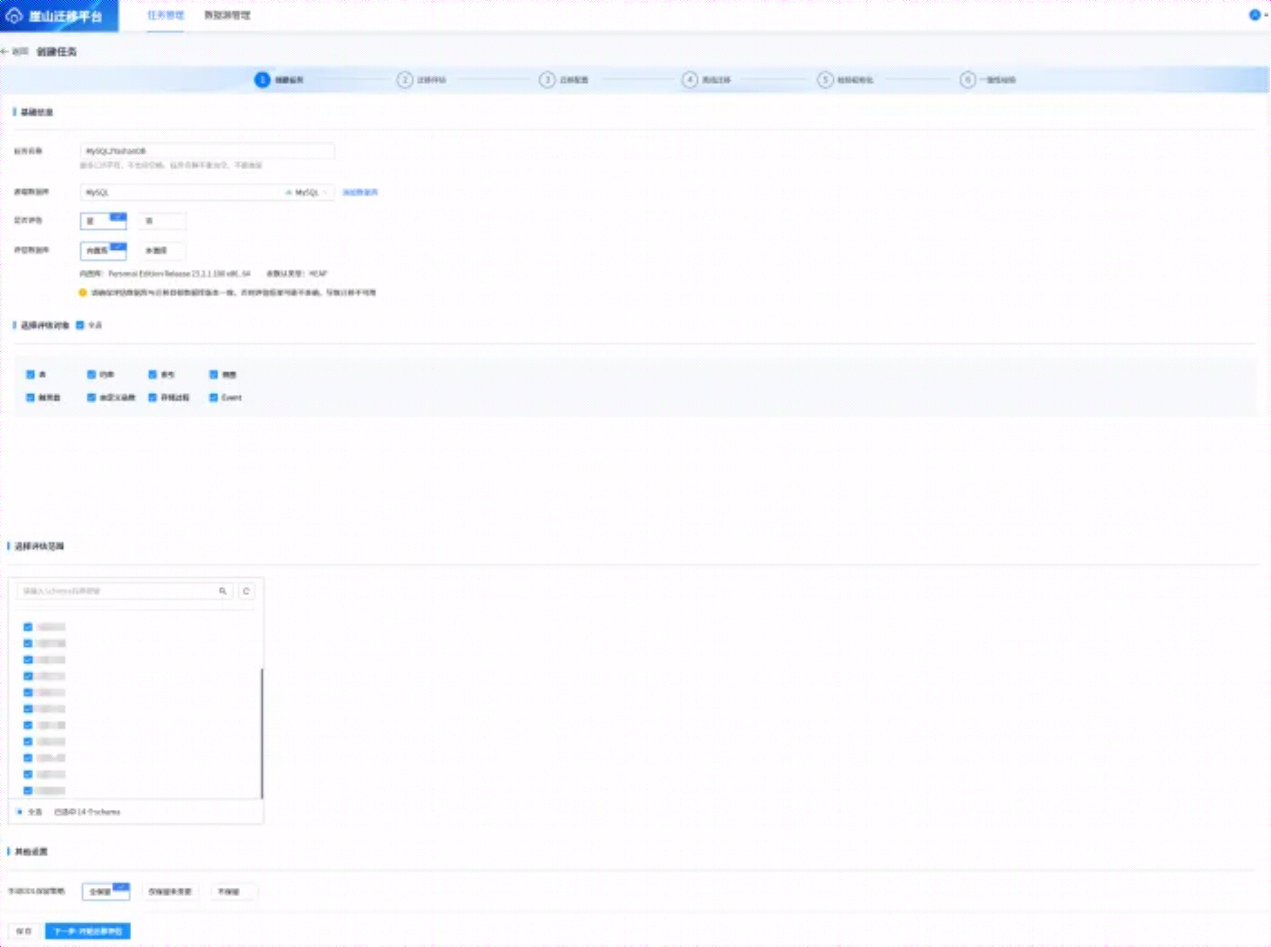
6.6.2 创建任务
在【任务管理】界面,创建任务,如下所示:
6.6.3 迁移评估
根据上面提示设置后,点击【下一步:开始迁移评估】,进入迁移评估阶段,如下所示,会对MySQL迁移到yashanDB的对象进行兼容性评估,如下所示。
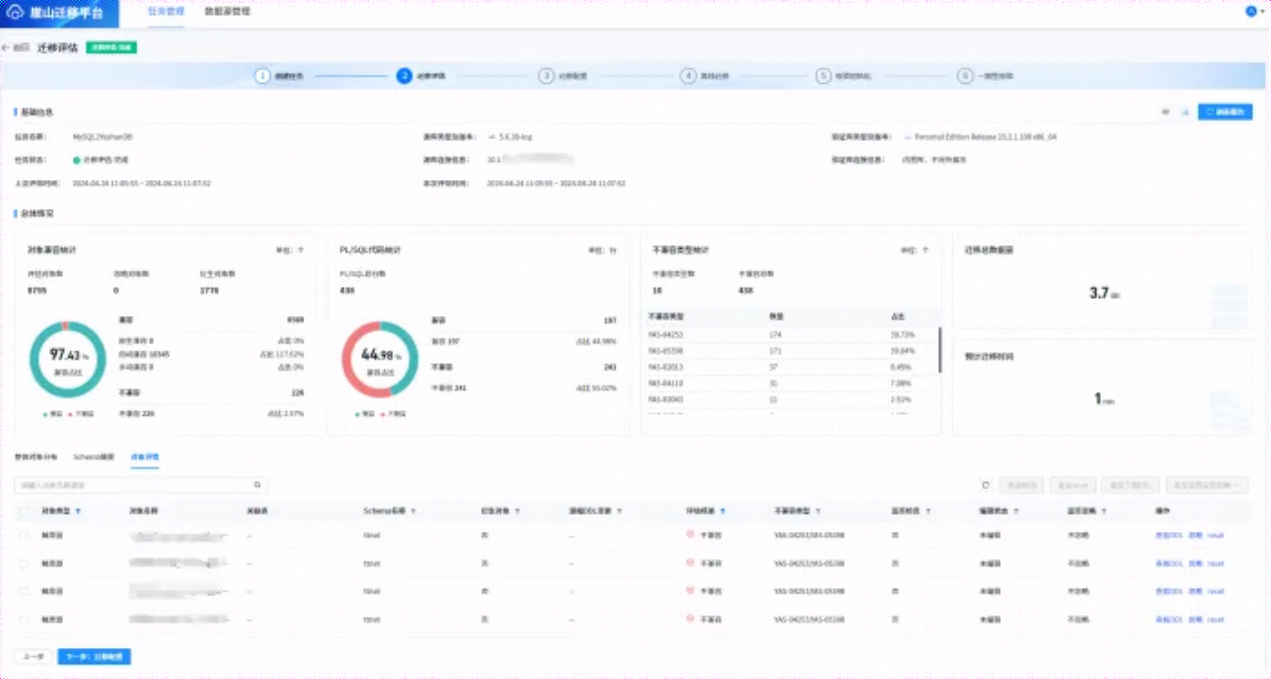
根据上面的评估结果,可以查看哪些对象不兼容,选择“不兼容”在【对象详情】菜单,选择【评估结果】项,勾选“不兼容”选项,如下所示:

如果是生产迁移,一定要对不兼容对象进行兼容处理。
本次作为测试,对于不兼容类型,选择忽略,首先勾选【全选所有】,然后再【批量设置是否忽略】选项,勾选【忽略】,如下所示:
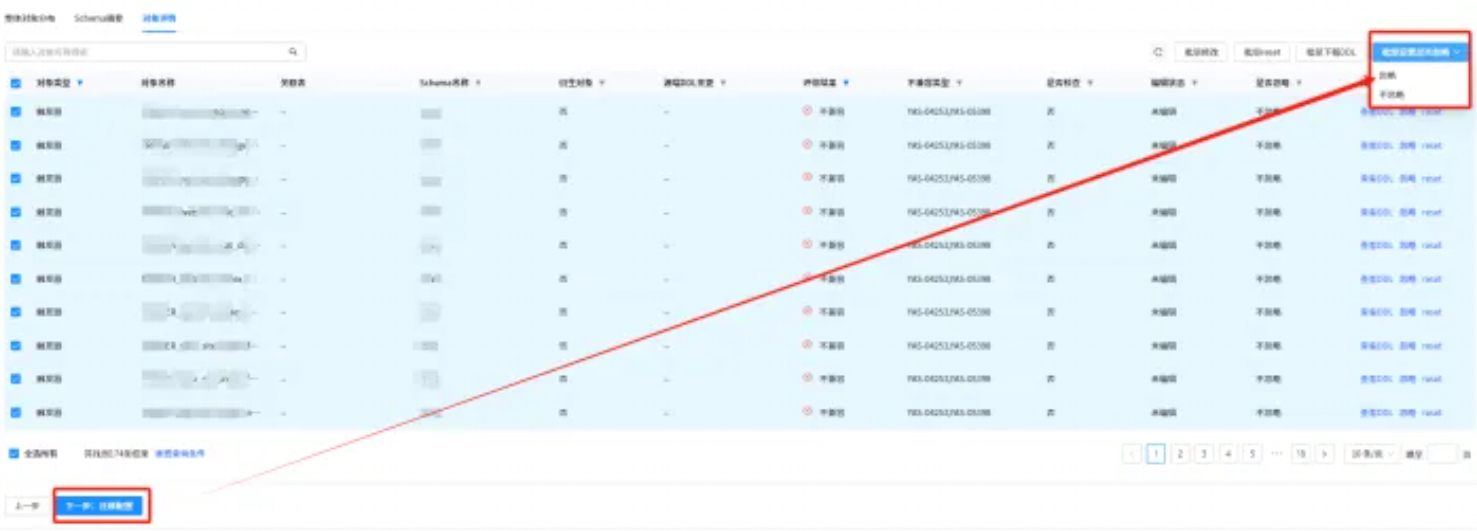
忽略全部不兼容对象后,需要重新刷新报告,如下所示:

重新刷新报告,重新评估后,结果如下所示:

只有兼容占比达到100%,才可以选择迁移配置。
6.6.4 迁移配置
上述迁移评估完成后,点击【下一步:迁移配置】,进入迁移配置界面,如下所示:
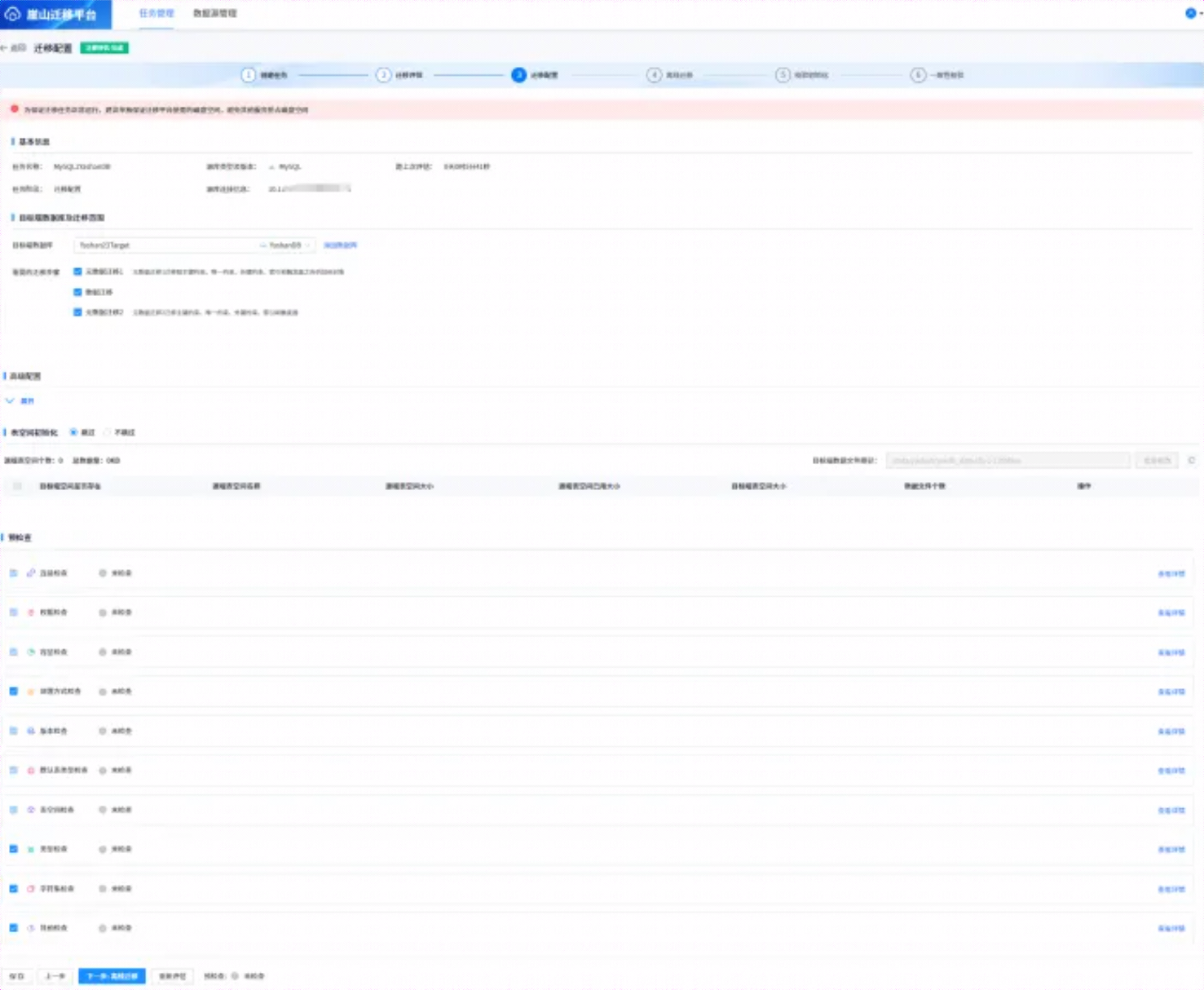
如上所示,在【目标端数据库及迁移范围】选择yashanDB外智库,在【迁移初始化配置】处,如果是首次迁移,可以选择默认,如果外置库已有之前迁移的对象而未删除,再次迁移可以选择【覆盖】,【表空间初始化】选择默认“跳过”。
6.6.5 离线迁移
上述操作完成后,点击【下一步:离线迁移】进入离线迁移界面,在迁移过程中,会显示迁移进度,迁移结束后,如下所示:
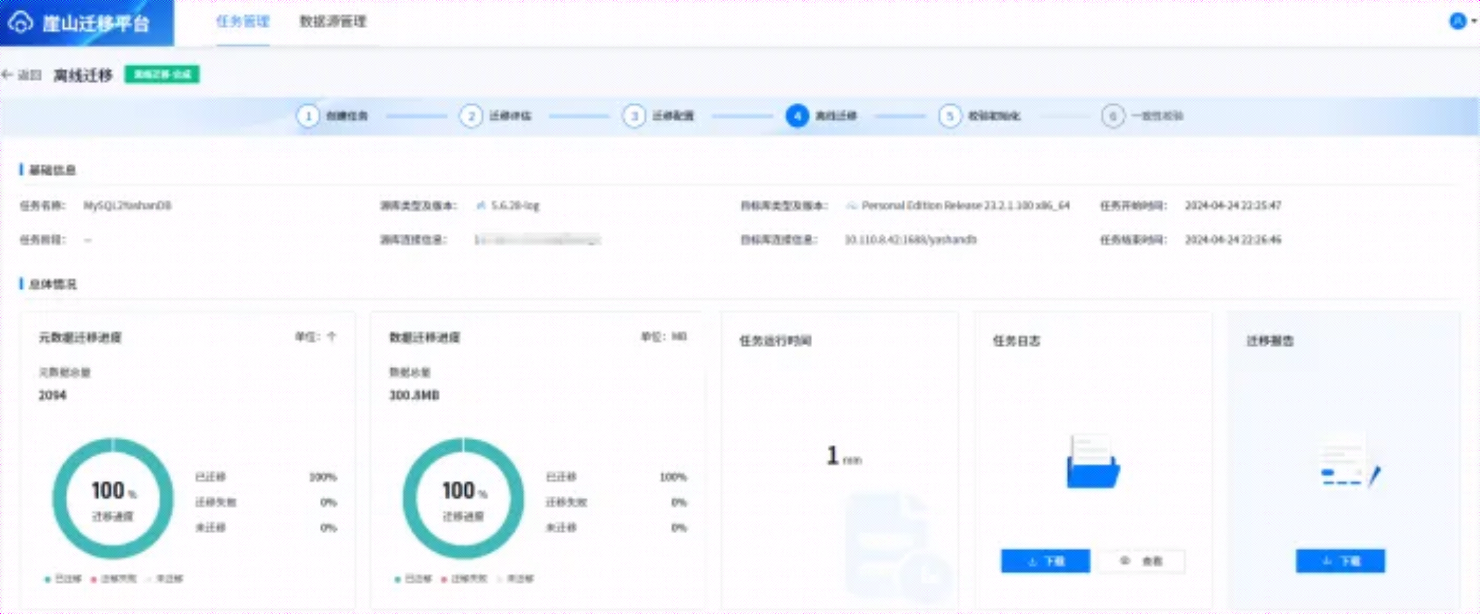
6.6.6 校验初始化
上述离线迁移完成后,点击【下一步:校验初始化】,进入如下所示页面:
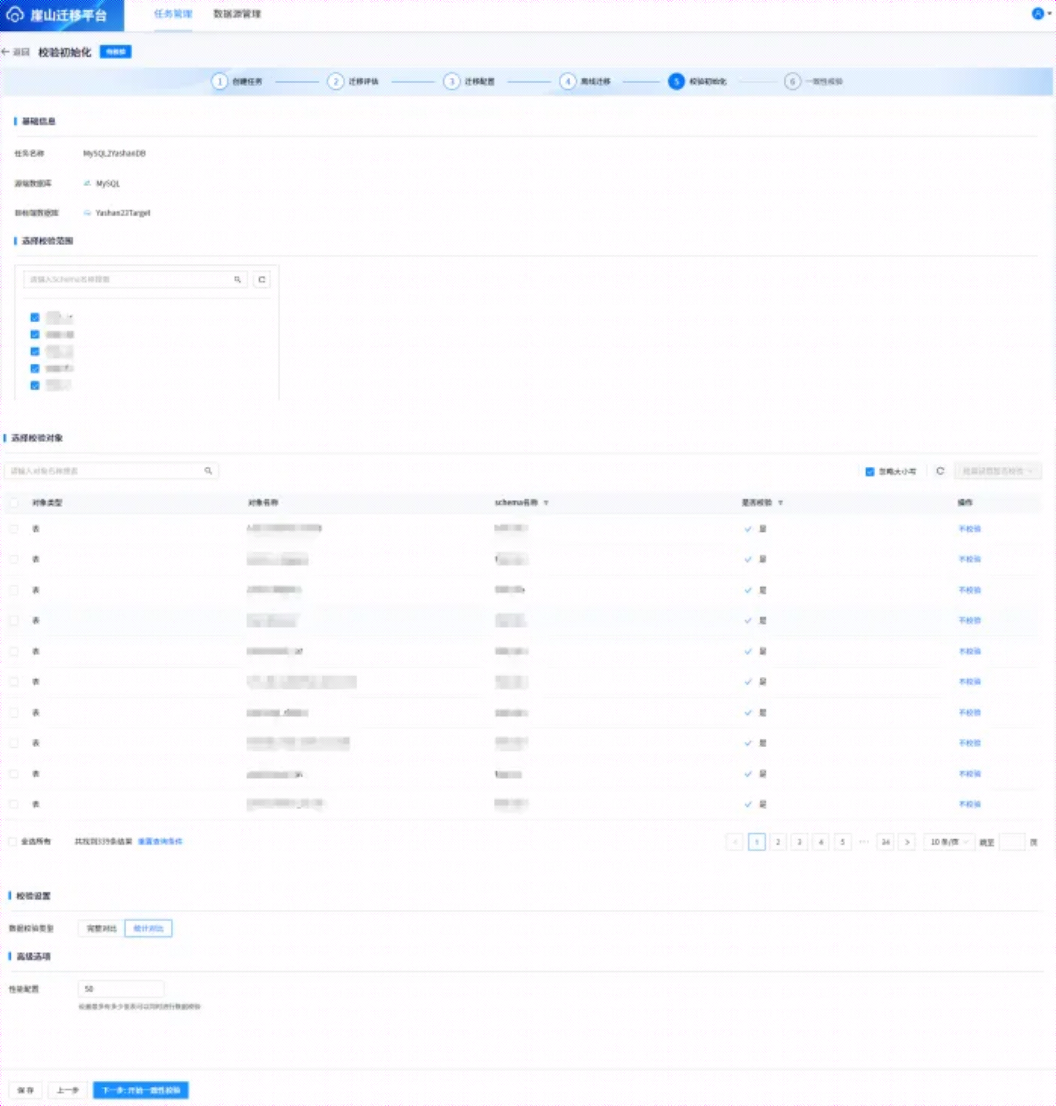
如上图所示,在校验初始化页面,在【选择校验范围】选择校验的用户,在【校验设置】可以选择“完整对比”或者“统计对比”,两者的相关含义如下所示:
-
统计对比:一致性校验页面显示统计校验。
-
完整对比:新增单表不一致阈值,可选无限制或自定义阈值,达到阈值后停止校验,一致性校验页面显示全量校验。
在【高级选项】中,性能配置表示支持最大可同时进行表校验的数目,每一对表的校验会使用一个线程,同时源端与目标端各占用一个连接数,默认范围[1,200]。
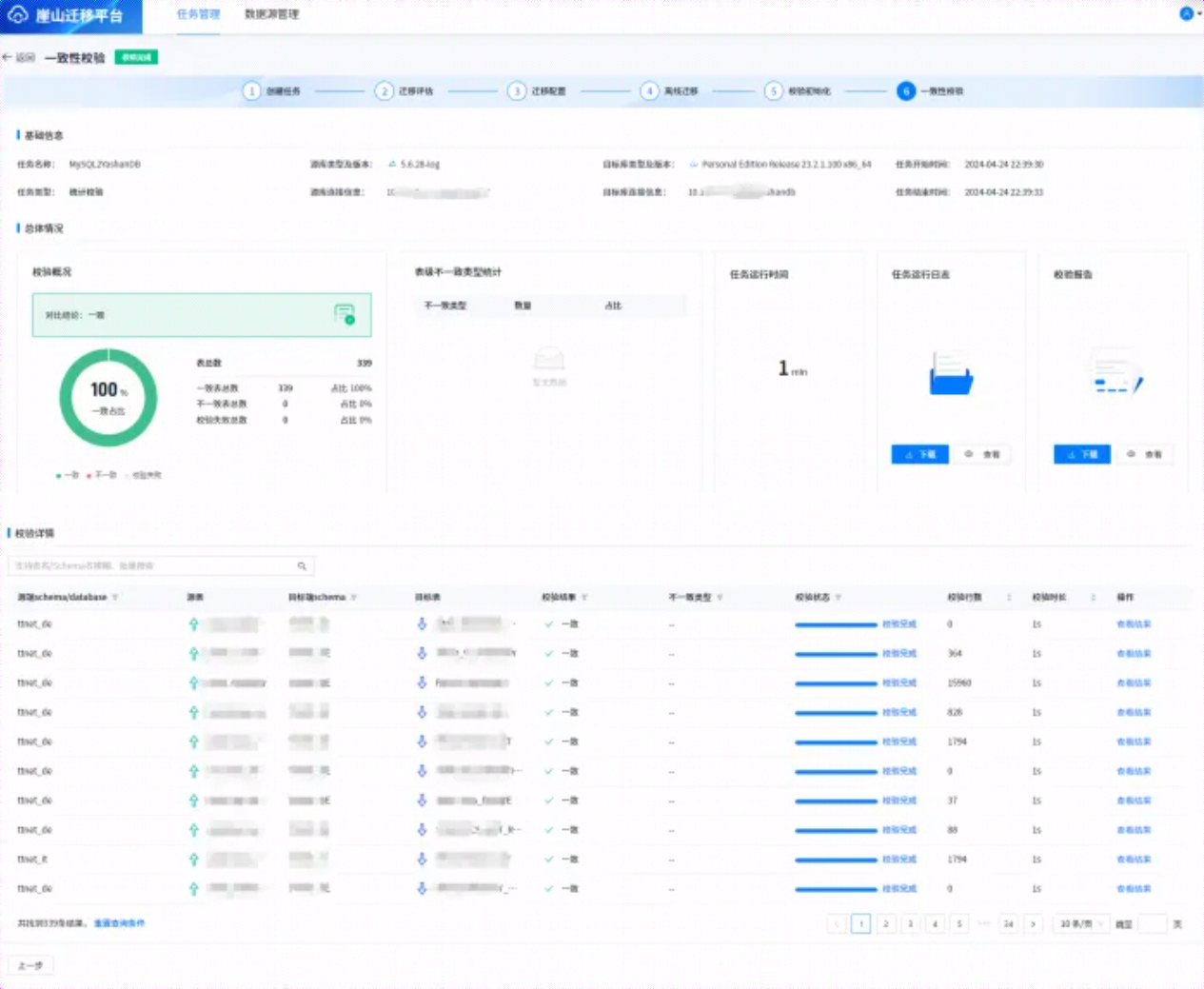
6.6.7 一致性校验
参照5.6.6 章节,在设置了相关参数后,点击【下一步:开始一致性校验】进行数据校验,校验过程中,会显示校验进度,校验结束后,结果如下所示: