【短小精悍】仅需6GB显存,你就可以跑起来清华智谱的ChatGLM-6B-Int4大模型
- 版本环境
- 一、序
- 二、ChatGLM-6B-Int4大模型
- 2.1 简介
- 2.2 模型
- 三、运行环境
- 3.1 下载模型
- 3.2 下载环境
- 3.3 下载代码
- 四、运行
- 4.1 运行代码
- 4.2 运行结果
- 4.3 GPU使用情况
- 五、相关问题
- 5.1 windows环境问题
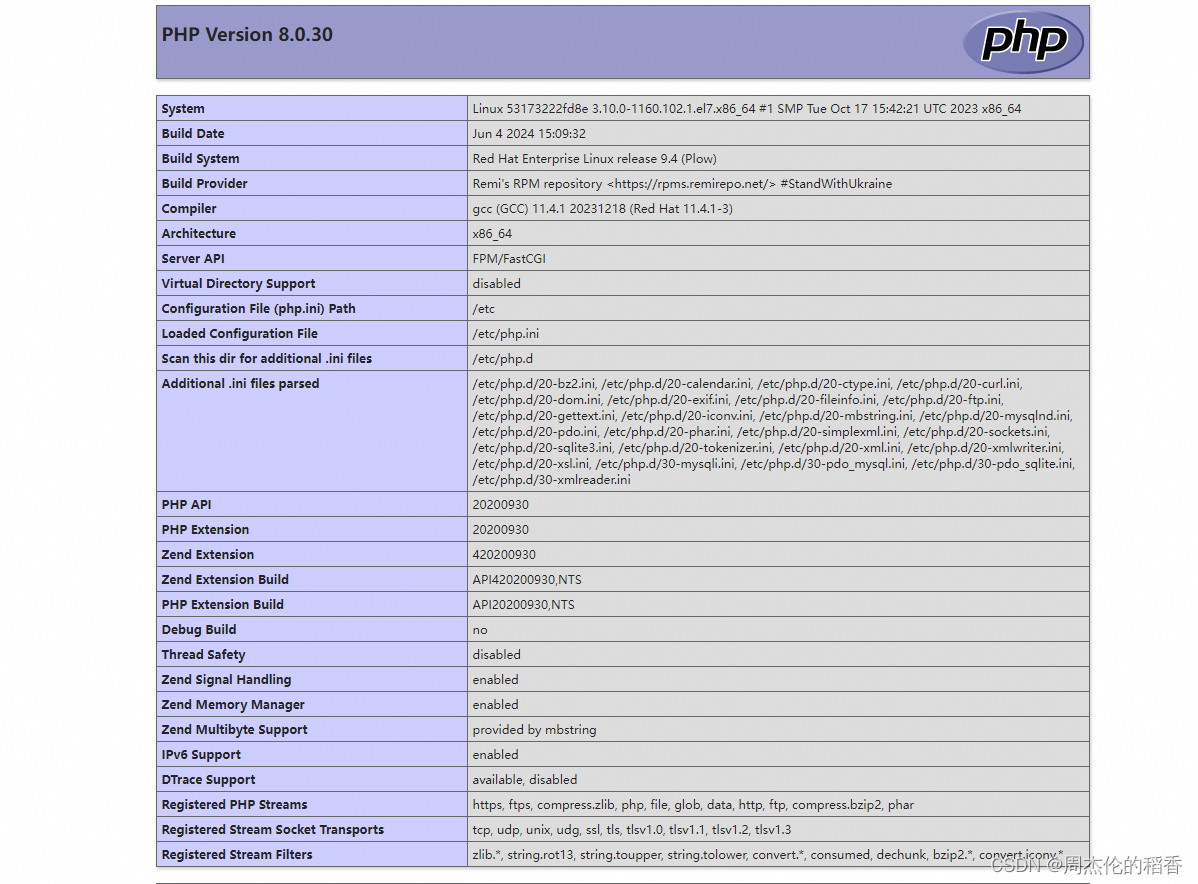
版本环境
- 操作系统 Windows 10
- python v3.10.12
- conda 24.1.2
- NVIDIA-SMI 552.22 Driver Version: 552.22 CUDA Version: 12.4
- CUDA Toolkit 12.1
- torch 2.3.0+cu121
- torchaudio 2.3.0+cu121
- torchvision 0.18.0+cu121
一、序
问:大模型跑起来分几步?

答:分三步。
问:哪三步?
答:第一步下模型;第二步下环境;第三步下代码。
二、ChatGLM-6B-Int4大模型
2.1 简介
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存,实际测试时候5GB也行)。ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
ChatGLM-6B-INT4 是 ChatGLM-6B 量化后的模型权重。具体的,ChatGLM-6B-INT4 对 ChatGLM-6B 中的 28 个 GLM Block 进行了 INT4 量化,没有对 Embedding 和 LM Head 进行量化。量化后的模型理论上 6G 显存(使用 CPU 即内存)即可推理,具有在嵌入式设备(如树莓派)上运行的可能。
在 CPU 上运行时,会根据硬件自动编译 CPU Kernel ,请确保已安装 GCC 和 OpenMP (Linux一般已安装,对于Windows则需手动安装),以获得最佳并行计算能力。
2.2 模型
图中标红的是主模型文件。

三、运行环境
3.1 下载模型
可以通过网页下载魔搭社区下载。
也可以通过命令行下载。
git clone https://www.modelscope.cn/ZhipuAI/ChatGLM-6B-Int4.gitgit lfs pull
下载完成后,文件目录如图所示。

3.2 下载环境
使用conda多python环境。
版本是3.10.12

安装pytorch相关依赖,注意根据GPU型号、CUDA版本下载对应的torch。笔者前期就下载了仅CPU类型的依赖,导致GPU算力没用上。
3.3 下载代码
git clone https://github.com/THUDM/ChatGLM2-6B

四、运行
以下代码是笔者根据魔搭社区中的代码范例进行改写。

4.1 运行代码
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
from modelscope.models import Model
import time# 指定本地模型文件路径,替换成你自己的
local_model_path = 'F:\\glm-2-model\\ChatGLM-6B-Int4'
# 加载本地模型
model = Model.from_pretrained(local_model_path)
pipe = pipeline(task=Tasks.chat, model=model)# 定义一个函数来处理用户输入和模型回复,并计时
def chat_with_model():while True:# 获取用户输入query = input("\n用户:")if query.strip() == "退出":break# 开始计时start_time = time.time()# 发送输入到模型inputs = {'text': query, 'history': []}result = pipe(inputs)# 停止计时end_time = time.time()# 计算用时elapsed_time = end_time - start_time# 打印用时print(f"\n用时:{elapsed_time:.2f}秒")# 逐字打印模型回复内容if 'response' in result and result['response']:for char in result['response']:print(char, end='', flush=True)print() # 打印换行符,以便于下一次输入else:print("\nChatGLM:这道题我不会,请尝试其他问题。")# 启动聊天
chat_with_model()4.2 运行结果

红色框中的提示无关紧要,笔者进行一次提问,用时8秒回答出来了。
笔者再次提问,这个回答就很牛逼了。通义千问是什么?

4.3 GPU使用情况

可以看到GPU内存使用了5GB。
五、相关问题
5.1 windows环境问题
缺少相关的依赖就按照提示进行安装即可。有的依赖针对Windows环境进行设计的,如pyreadline3等。









![[Spring] SpringBoot基本配置与快速上手](https://i-blog.csdnimg.cn/direct/67d39e1f5d9c4dfb82c994965f006534.png)