日志文件是Linux系统中极为重要的一部分,它们记录了系统和应用程序的各种活动信息。通过日志文件,系统管理员可以监控系统的运行状态、发现潜在的问题,并进行故障排除。
一. 常见的日志文件
在介绍具体的日志分析命令之前,首先了解一下Linux系统中常见的日志文件。它们通常位于/var/log目录下,包括:
-
/var/log/syslog:记录系统的通用日志信息,适用于大多数Linux发行版。 -
/var/log/messages:记录系统的通用日志信息,通常在Red Hat系的发行版中使用。 -
/var/log/auth.log:记录身份验证相关的日志信息,如登录尝试、sudo命令使用等。 -
/var/log/kern.log:记录内核相关的日志信息。 -
/var/log/dmesg:记录系统启动时的内核消息。 -
/var/log/boot.log:记录系统启动过程中的消息。 -
/var/log/cron.log:记录定时任务相关的日志信息。 -
/var/log/mail.log:记录邮件系统相关的日志信息。 -
/var/log/apache2/access.log和/var/log/apache2/error.log:记录Apache服务器的访问日志和错误日志。 -
/var/log/nginx/access.log和/var/log/nginx/error.log:记录Nginx服务器的访问日志和错误日志。
二. 查看日志文件的命令
1. cat
cat命令用于查看文件的内容,适用于查看较短的日志文件。
示例:
cat /var/log/syslog2. less
less命令用于分页查看文件内容,可以方便地向上或向下滚动,适用于查看较长的日志文件。
示例:
less /var/log/syslog3. tail
tail命令用于查看文件的末尾部分,默认显示最后10行。常用选项包括-n指定行数和-f用于实时跟踪日志文件的更新。
示例:
tail -n 20 /var/log/syslog
tail -f /var/log/syslog4. head
head命令用于查看文件的开头部分,默认显示前10行。
示例:
head -n 20 /var/log/syslog5. grep
grep命令用于在文件中搜索匹配特定模式的行,适用于从日志文件中提取特定信息。
示例:
grep "error" /var/log/syslog
grep -i "fail" /var/log/auth.log选项-i表示忽略大小写。
6. awk
awk是一种强大的文本处理工具,适用于从日志文件中提取和处理结构化信息。
示例:
awk '{print $1, $2, $3}' /var/log/syslog上述命令提取并显示日志文件的前三列。
7.sed
sed是一种流编辑器,适用于对日志文件进行搜索、替换和过滤。
示例:
sed -n '/error/p' /var/log/syslog上述命令显示包含“error”的行。
三、分析日志文件的工具
1.logrotate
logrotate命令用于管理和轮转日志文件,防止日志文件过大。配置文件通常位于/etc/logrotate.conf和/etc/logrotate.d/目录下。
示例配置:
/var/log/syslog {dailyrotate 7compressmissingoknotifempty
}上述配置表示对/var/log/syslog进行每日轮转,保留7个历史日志文件,并进行压缩。
2. journalctl
journalctl命令用于查看和分析systemd的日志信息。
示例:
journalctl -xe
journalctl -u nginx.service选项-xe用于显示最近的日志并详细解释错误,-u用于查看特定服务的日志。
下面详细介绍了journalctl工具的用法和应用场景。作为一名系统管理员或开发人员,掌握journalctl的使用技巧对于有效管理和分析系统日志至关重要。
从下面的示例不难看出,journalctl是一个功能强大且灵活的命令行工具,它提供了多种过滤和排序选项,能够快速定位和解决问题。我们学习了如何按时间、进程和日志级别等方式过滤日志,并提到了使用正则表达式过滤日志、相关身份验证模块的介绍和使用、以及汇总统计日志字段的用法,我们还介绍了journalctl的实用功能,包括实时监视、高级搜索和过滤。通过使用日志标识符和元数据,我们能够更精确地定位特定事件,并深入分析应用程序的活动,每个场景拿来用于生产环境都是没有任何问题的。
掌握journalctl带来了许多价值和效益。它不仅能够帮助我们快速诊断故障和进行性能优化,还能用于安全审计和系统稳定性的维护。通过减少故障排除时间,提高工作效率,我们可以提升整个系统的可靠性和可用性。
1.基于boot引导筛选日志
首先可通过--list-boots参数列出当前系统所有的boot引导:
journalctl --list-boots
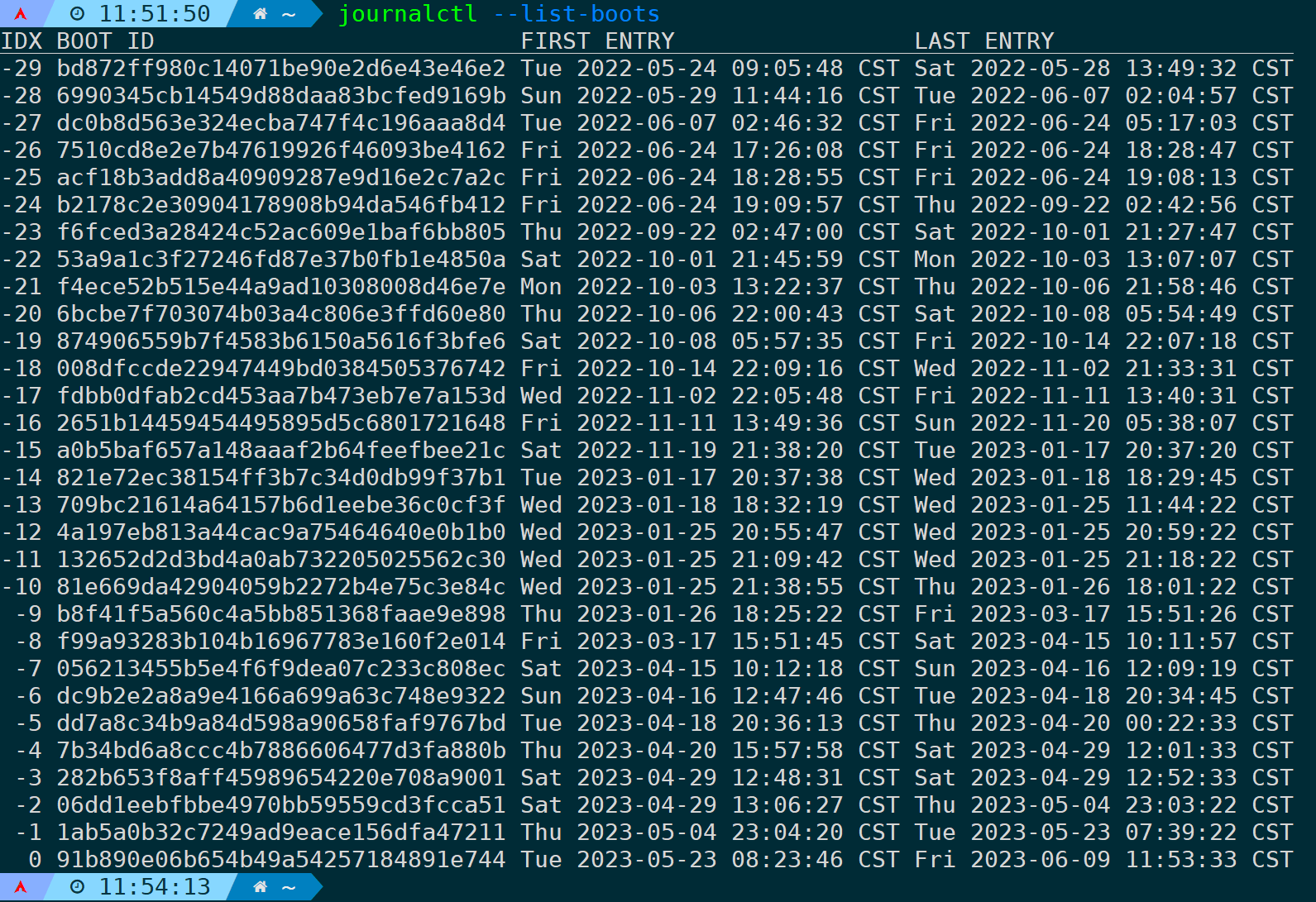
最左边的IDX列为序列号,0表示当前BOOT引导ID,-1表示上一次引导ID,以此类推,右边两列则为每个BOOT引导的时间范围,每次重启系统后都会生成一个新的BOOT ID。
明白此概念后,比如想筛选上一次引导所产生的错误日志,可以是:
journalctl -b -1 -g "fail|error"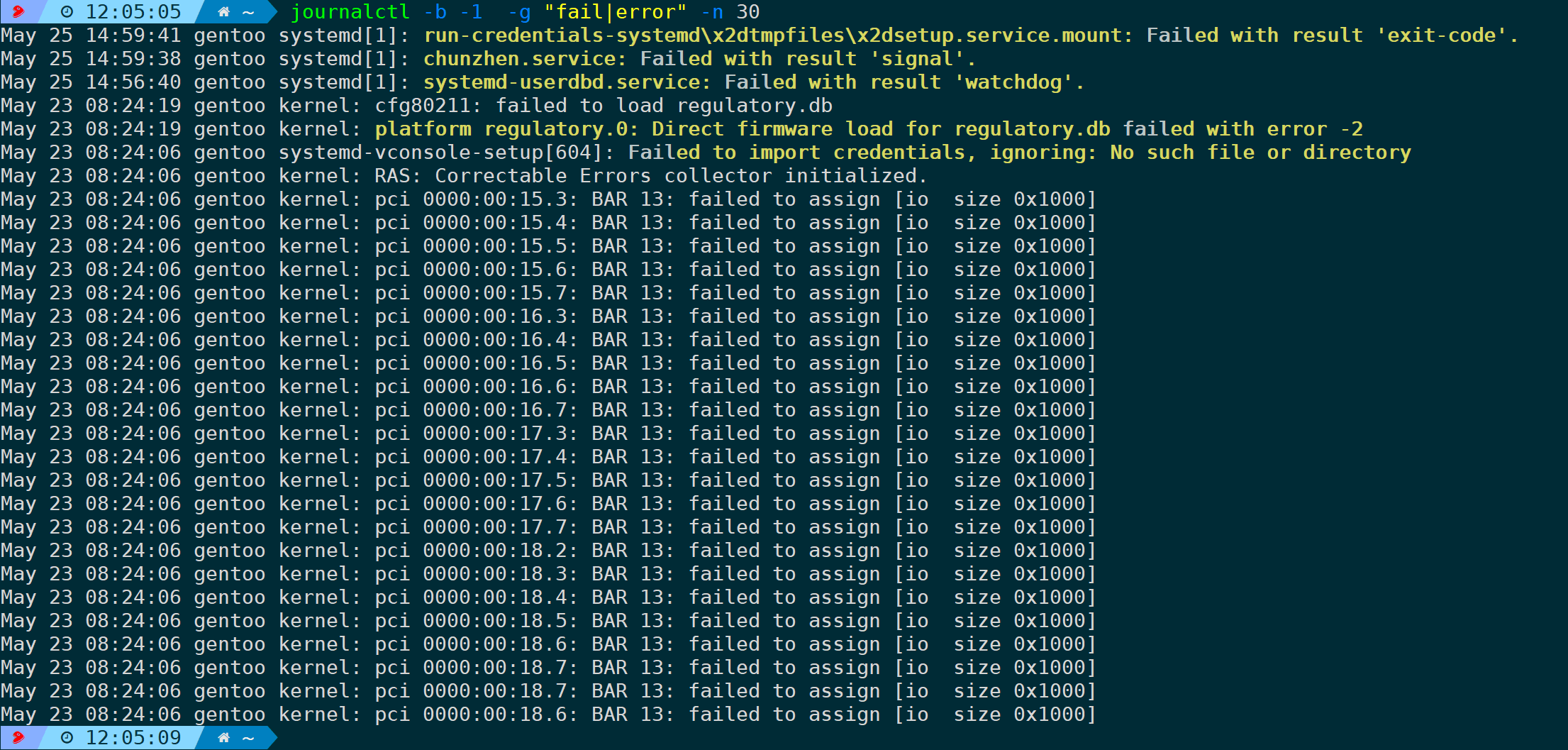
-n 30 显示最近30条日志,不加则显示全部。
或者通过日志定义的优先级来筛选上一次启动期间0-3级(emerge、alert、crit、error)的错误日志:
journalctl -b -1 -p 0..3
2.指定时间范围筛选特定服务的日志
筛选特定systemd服务,使用-u参数,比如-u "sshd"筛选sshd服务的日志。
指定时间范围,则通过--since(-S)和--until(-U)参数实现。
时间格式为标准的年月日时分秒(YYYY-MM-DD HH:MM:SS):“2023-06-09 18:00:00”,当然你也可以简写为"yesterday"、"today"、"tomorrow"。
筛选从昨天开始到现在的sshd服务日志:
journalctl -u sshd --since yesterday
当缺省"--unitl(-U)"时,则表示当前时间。
筛选2023年5月1号到5月31号的sshd服务日志并显示最近20条记录:
journalctl -u sshd --since "2023-05-01" --until "2023-5-31" -n 20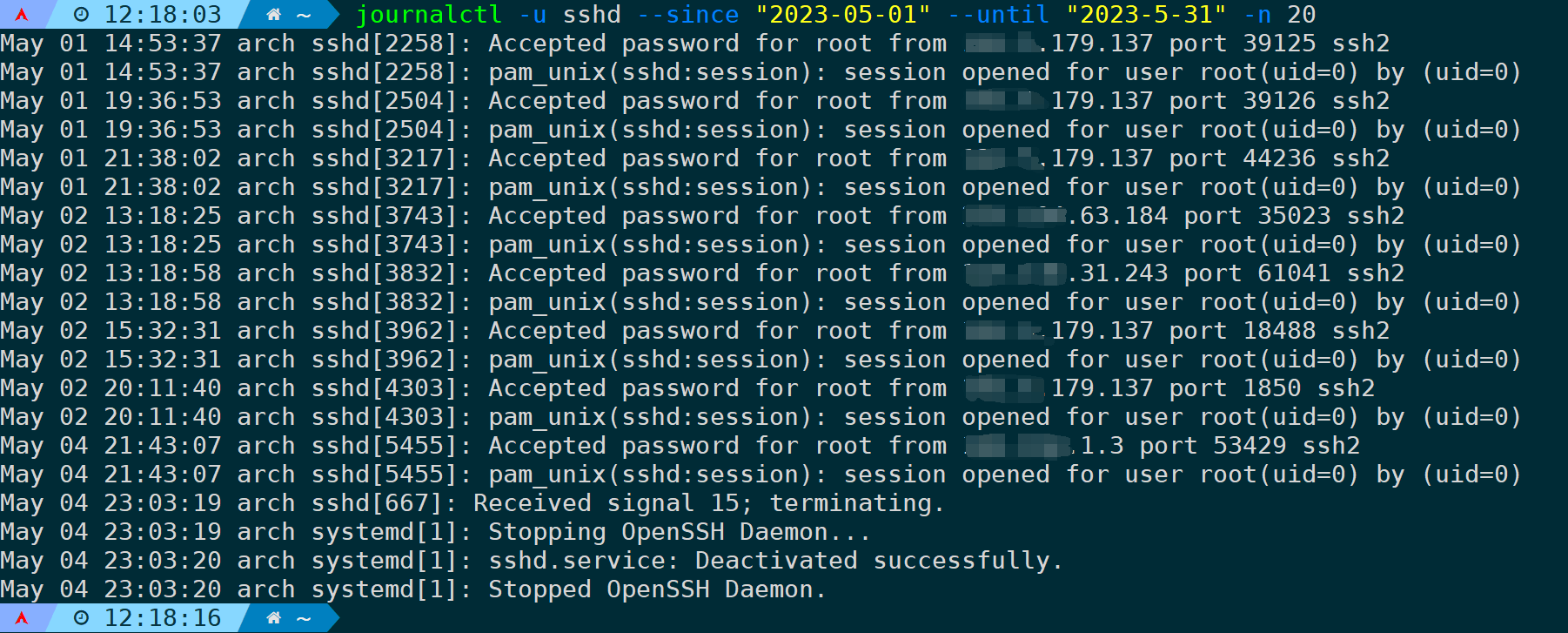
3.使用正则表达式过滤特定日志
当日志数量庞大时,我们只想过滤特定符合条件内容的日志,此时--grep(-g)参数就派上了用场;journalctl的日志由很多字段组成,其中日志信息内容会记录到MESSAGE字段,-g参数的作用域也是这个字段,并支持Perl正则写法,具体语法可以通过man pcre2pattern来查看。
同时需要注意,如果写的表达式都是小写,那就不区分大小写,如果包含大写就会区分大小写,如果不想区分大小写可以使用--case-sensitive=false参数来生效,比如下面的几种情况:
- --grep "abc",是不区分大小写的;
- --grep "Abc",区分大小写,只过滤匹配Abc的日志;
- --grep "Abc" --case-sensitive=false,仍然不区分大小写。
筛选sshd服务登录失败的日志并显示最近30条:
journalctl -u sshd --grep "Failed" -n 30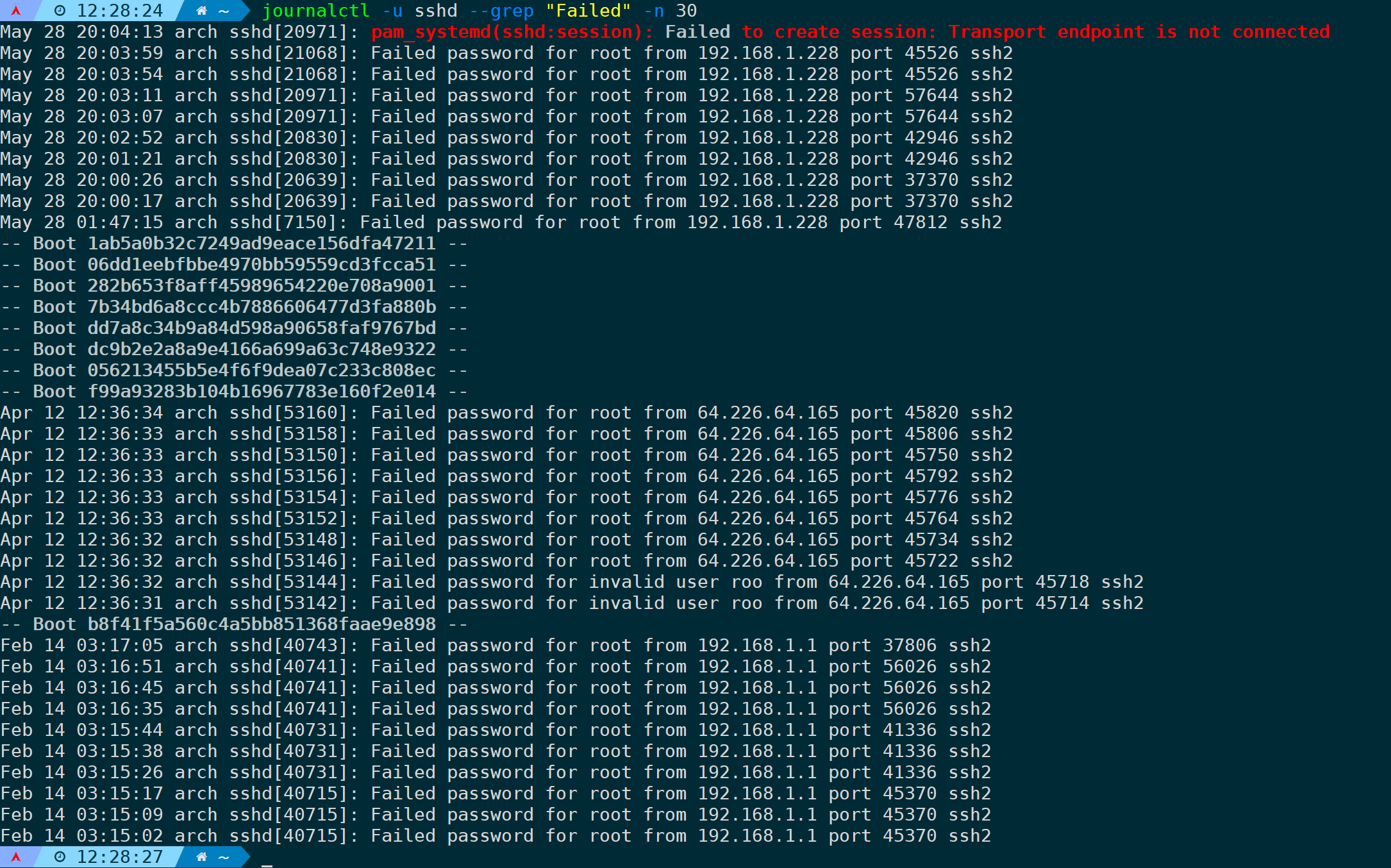
从上图可以观察到,如果日志跨了BOOT ID,会把对应的BOOT ID也展示出来。
筛选prometheus服务的master节点最近五行的错误日志,且不允许分页:
journalctl -u prometheus -g '(?i)Web master node.*error' -n 5 --no-pager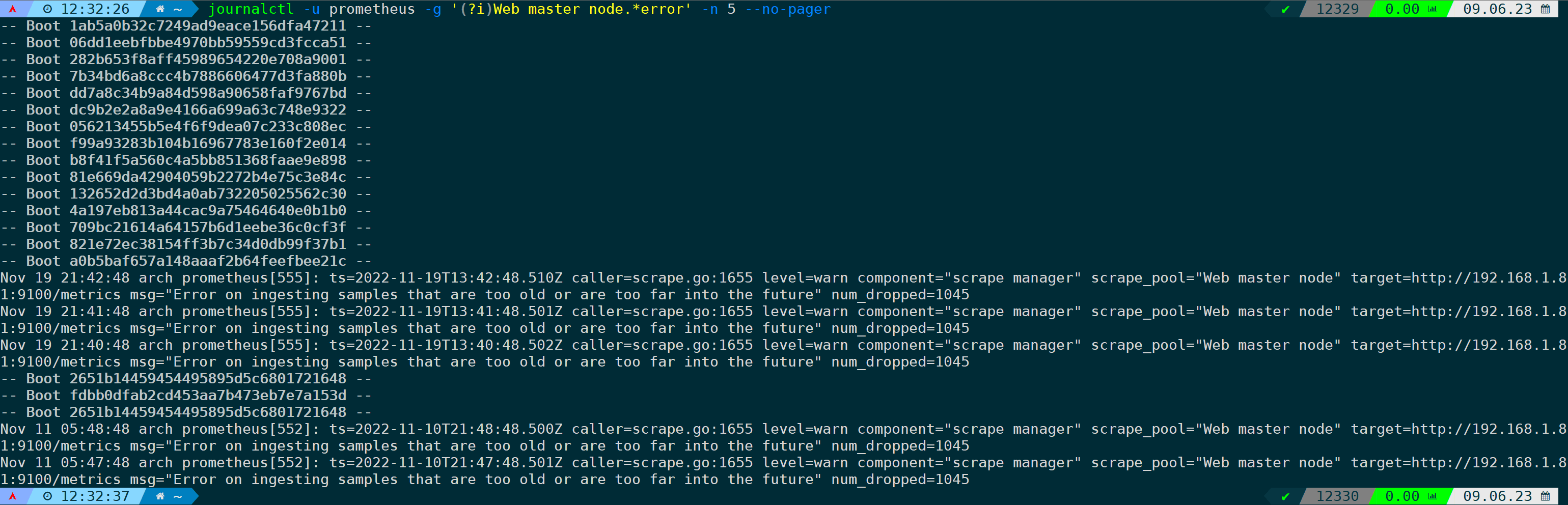
4.实时跟踪特定服务的日志
journalctl提供了-f(--follow)参数来追踪日志,可实时输出所产生的日志。
跟踪sshd服务从现在开始所产生的日志:
journalctl -u sshd -S now -f
跟踪grafana服务产生的日志,并显示最近10行已经存储的日志:
journalctl -u grafana -f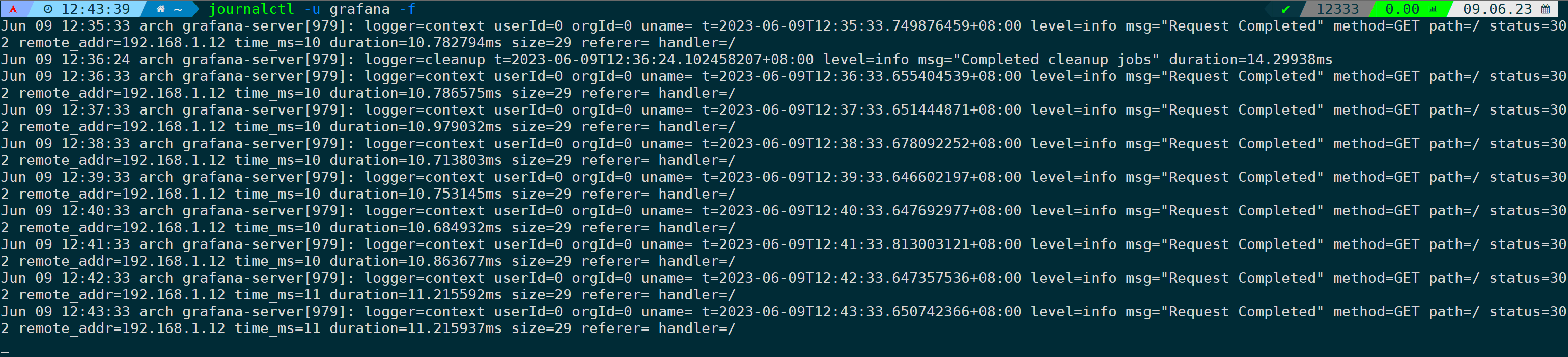
当不加-S now参数时,默认会把最近已产生的10行日志输出出来再进行实时跟踪,如果你想打印已经存储的所有行日志再进行追踪,加上--no-tail参数即可:
journalctl -u grafana -f --no-tail5.筛选与内核相关的错误日志
--demgs或者-k参数j将会打印内核相关日志:
journalctl -k
而只想看到有没有错误日志,可以通过-p来指定日志优先级,比如输出错误级别为0-3级(emerge、alert、crit、error)的日志:
jouornalctl -k -p 0..3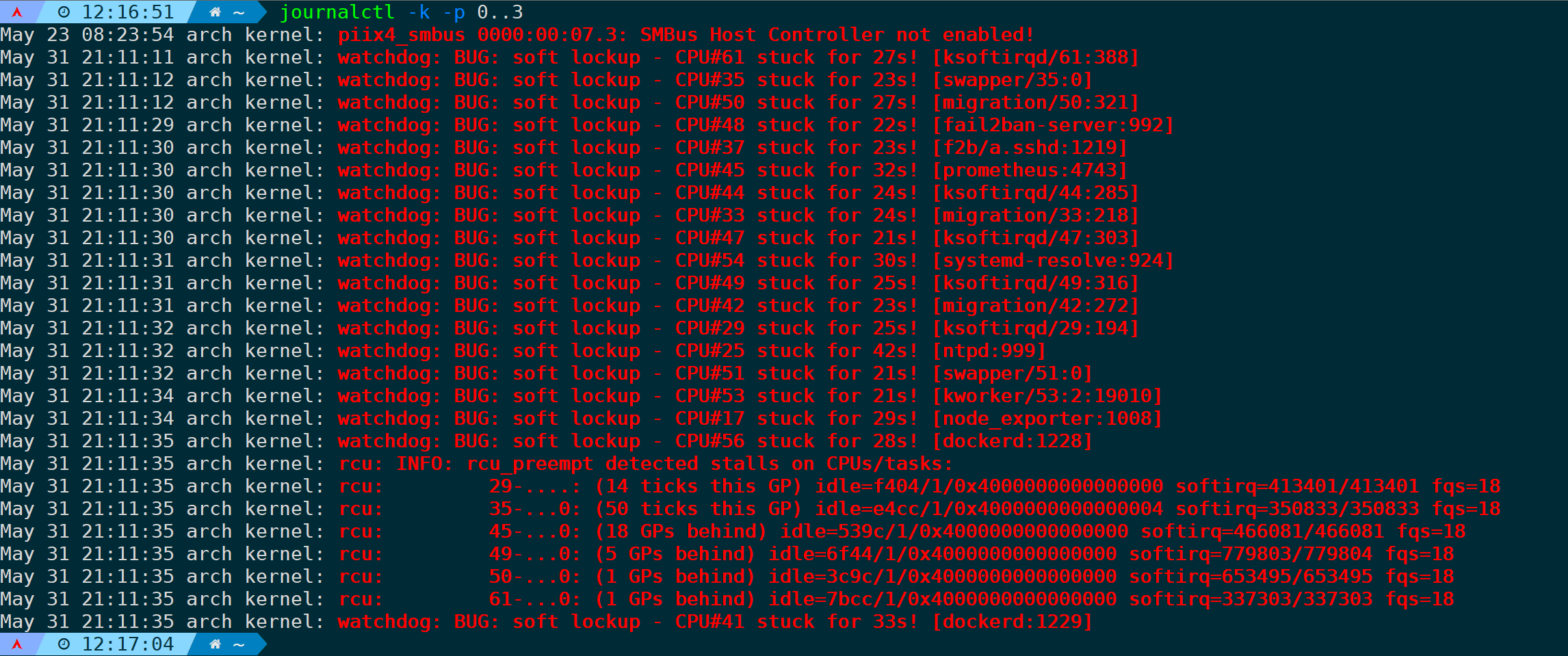
默认只会显示本次系统从启动到现在所产生的内核日志,如果想看到上一次的内核日志,则可以加上-b -1参数,比如想要查看上一次从开机到关机(boot为-1)所产生的内核日志,且级别为0-4级(emerge、alert、crit、erro、warning):
journalctl -k -p 0..4 -b -1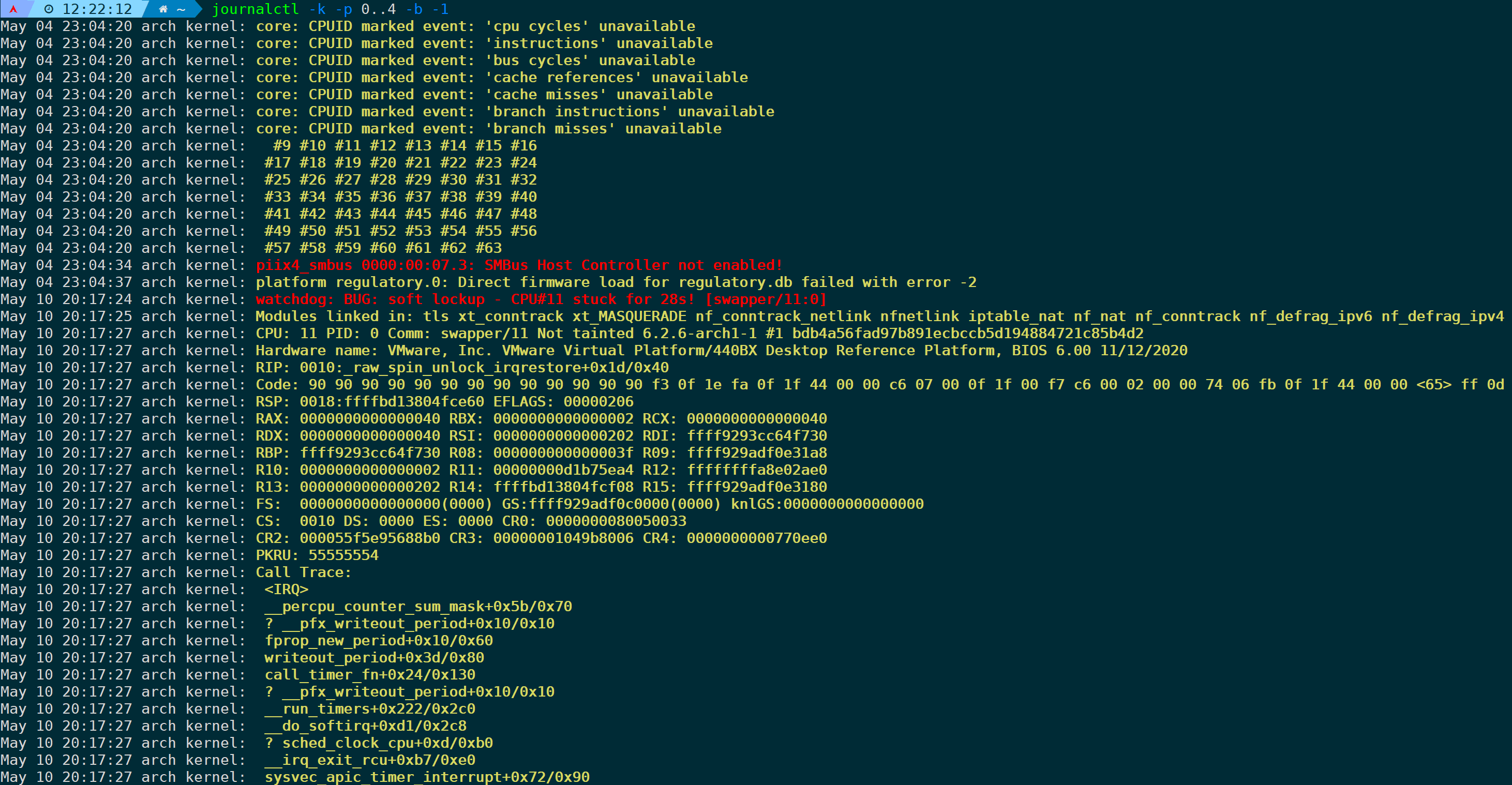
或者我想通过MESSAGE字段的内容来匹配满足我需要的内核日志:
journalctl -k -g "fail|error|bug|out of memory" -b -1 -n -r
-n(--lines)不指定数字默认只显示最近10行,-r(--reverse)反向显示,从近到远。
6.筛选与身份验证相关的日志
systemd-journald会按照不同设备对日志分门别类,最常见的设备有:
- kernel:内核产生的日志消息。
- user:与用户操作和登录相关的日志消息。
- mail:与邮件系统相关的日志消息。
- auth:与身份验证和授权相关的日志消息。
- syslog:由 syslog 守护程序生成的日志消息。
- lpr:与打印系统相关的日志消息。
- news:与新闻服务器相关的日志消息。
- uucp:与 UUCP(Unix to Unix Copy)系统相关的日志消息。
- cron:与定时任务(cron)相关的日志消息。
- authpriv:与身份验证和授权的私有信息相关的日志消息。
- ftp:与文件传输协议(FTP)服务器相关的日志消息。
- ntp:与网络时间协议(NTP)服务器相关的日志消息。
然后通过--facility参数来指定设备模块所产生的日志,比如想筛选与身份验证相关的日志最近30行:
journalctl --facility=auth -n 30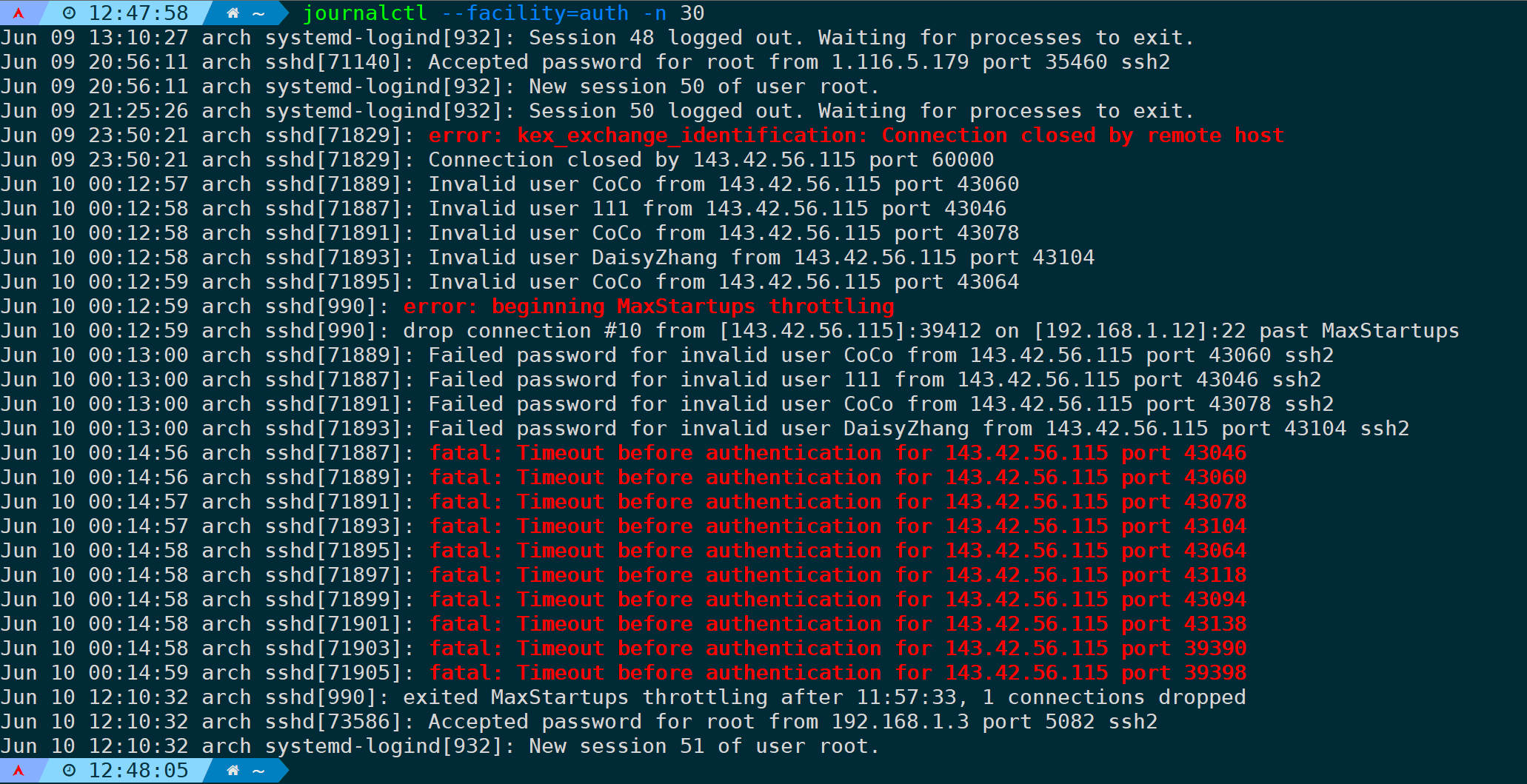
筛选与身份验证和授权的私有信息相关的日志最近20行:
journalctl --facility=authpriv -n 20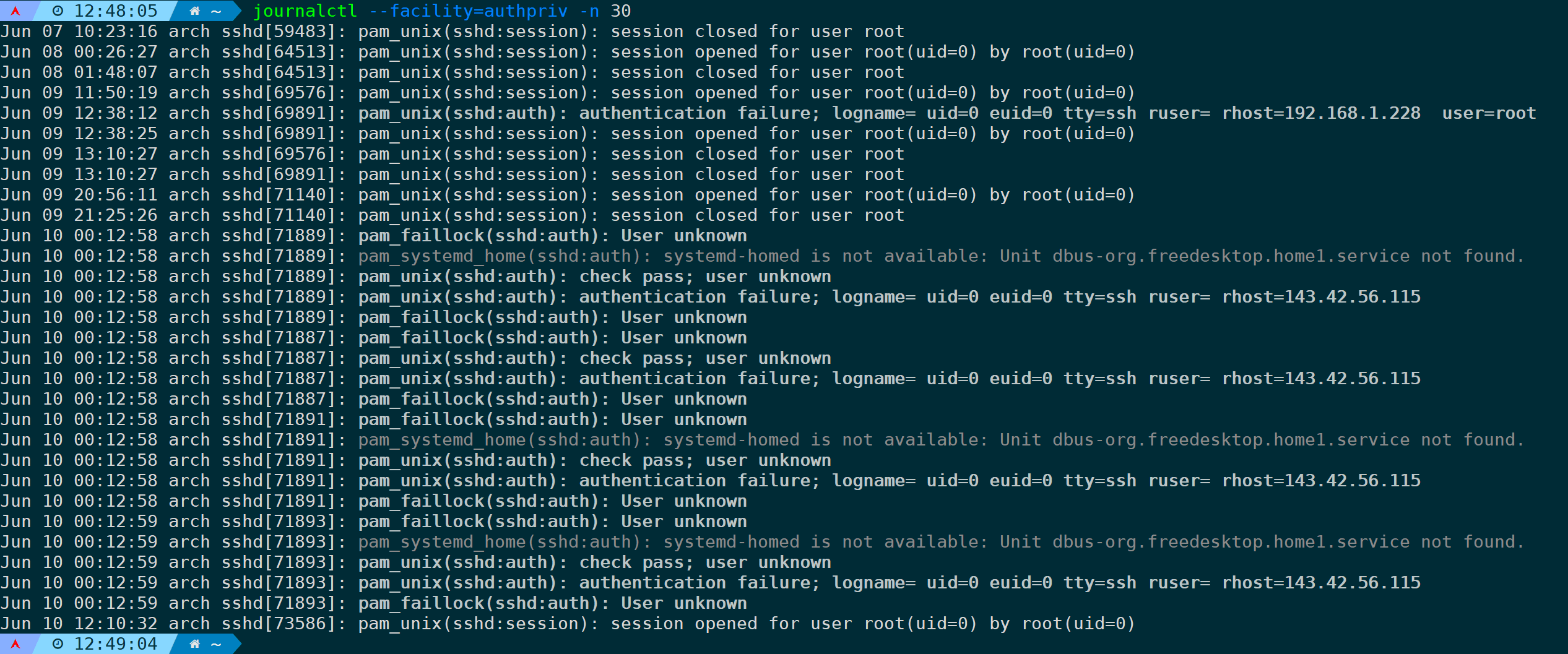
这里能详细打印出pam模块的验证过程。
筛选auth模块并且指定sshd标识符,且关键词为fail|invalid|error|timeout的日志最近30行:
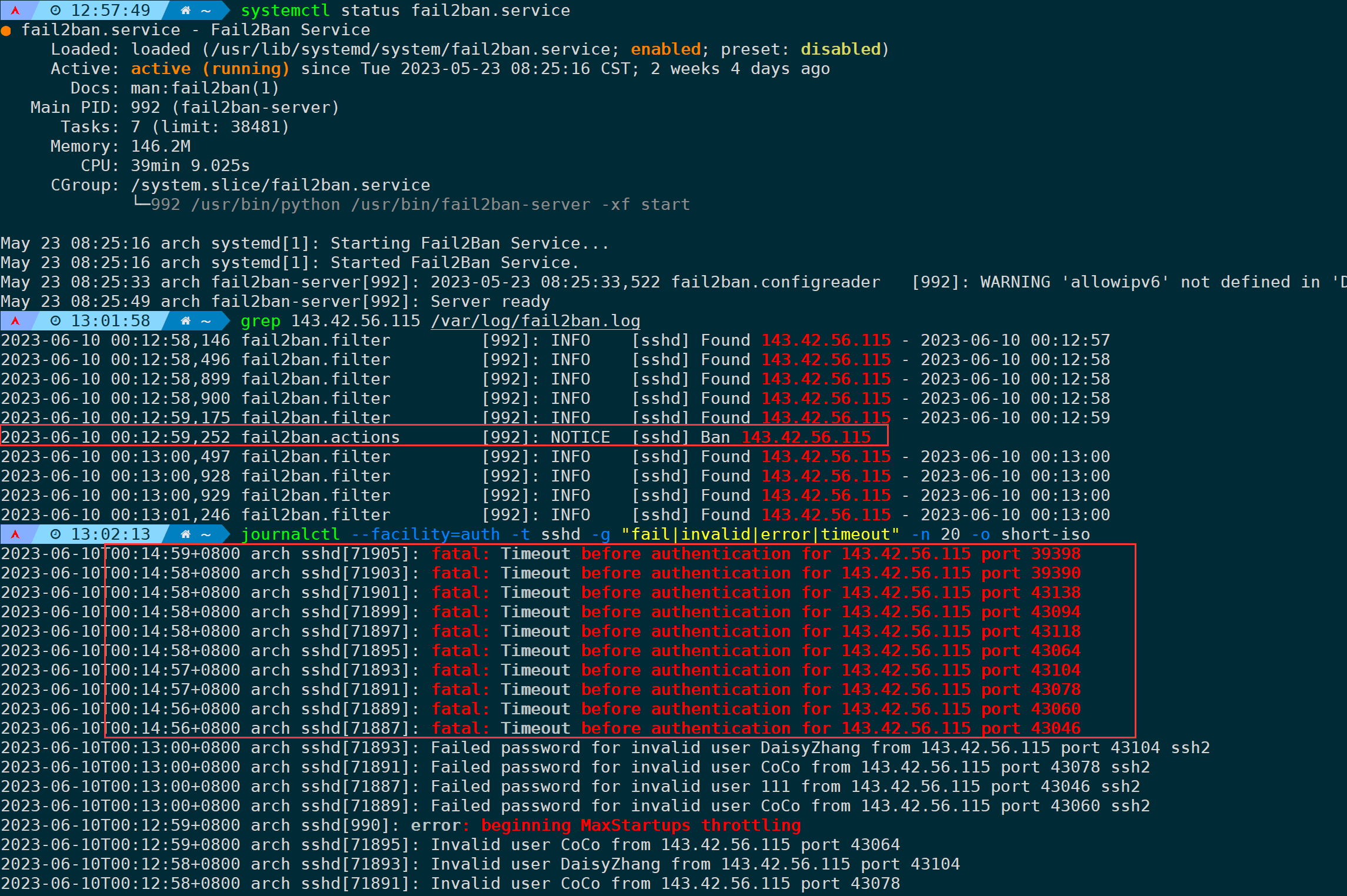
journalctl --facility=auth -t sshd -g "fail|invalid|error|timeout" -n 30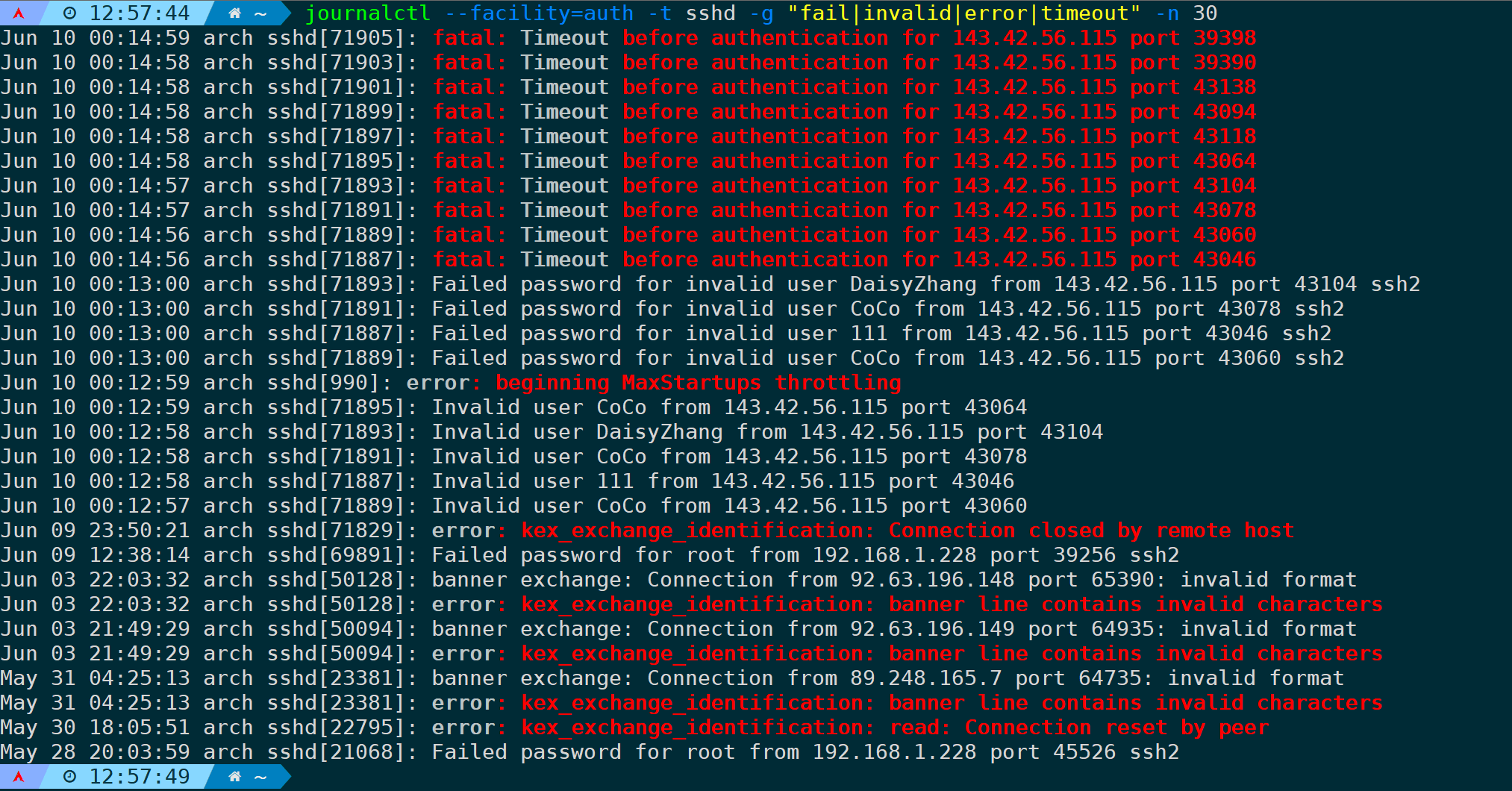
从日志可以看出,攻击者IP:143.42.56.115 在尝试多次登录服务器并用户名密码错误后,00:14:56开始的所有登录请求全部超时,因为00:12:59这个时间点已经被fail2ban给屏蔽了:
如果你对fail2ban比较感兴趣,可以参照我写的这篇。
7.以json格式输出日志
journalctl提供了格式化输出选项,除了json还支持short、verbose等,如果你想了解更多的输出格式,可以参照我这篇。
通过-o(--output)参数来指定输出格式,还是拿上一条举例,筛选auth模块并且指定sshd标识符,且关键词为fail|invalid|error|timeout的日志最近20行,但是以json格式输出:
journalctl --facility=auth -t sshd -g "fail|invalid|error|timeout" -n 20 -o json
这么看不太直观,通过json-pretty参数可有优化输出:
journalctl --facility=auth -t sshd -g "fail|invalid|error|timeout" -n 1 -o json-pretty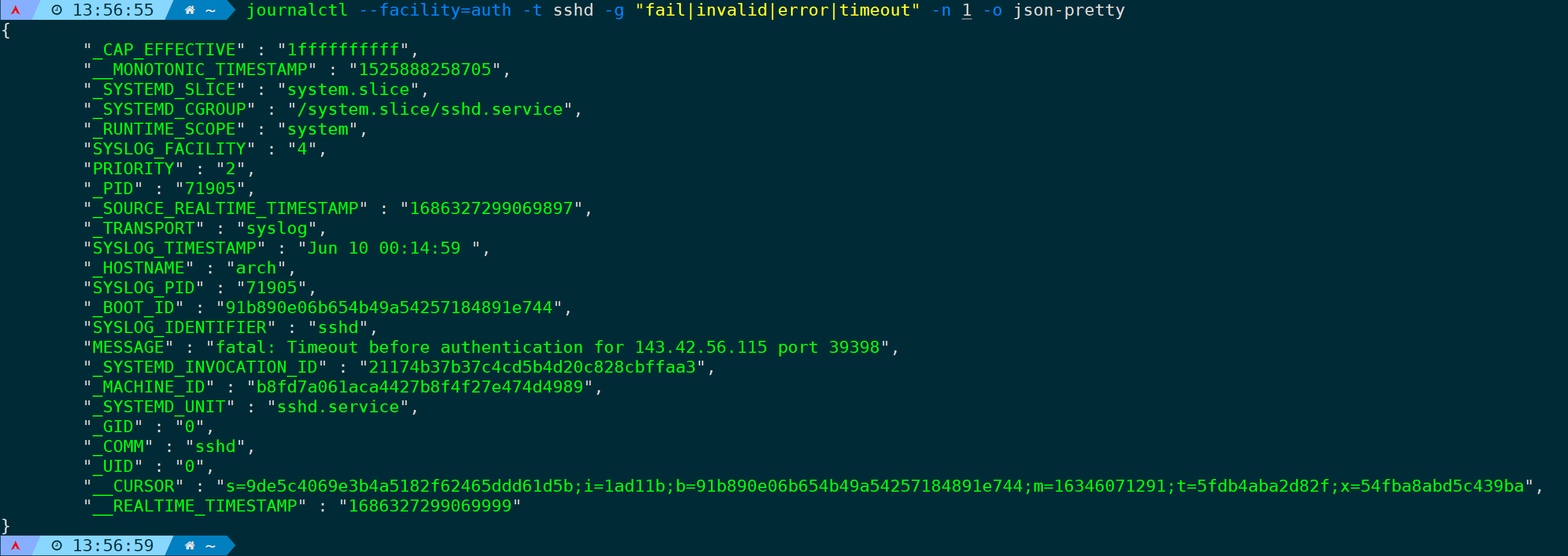
8.根据进程PID过滤日志
当某个服务报错时,我们想通过进程PID来过滤出相关错误日志:
journalctl -n _PID=<PID> -b 0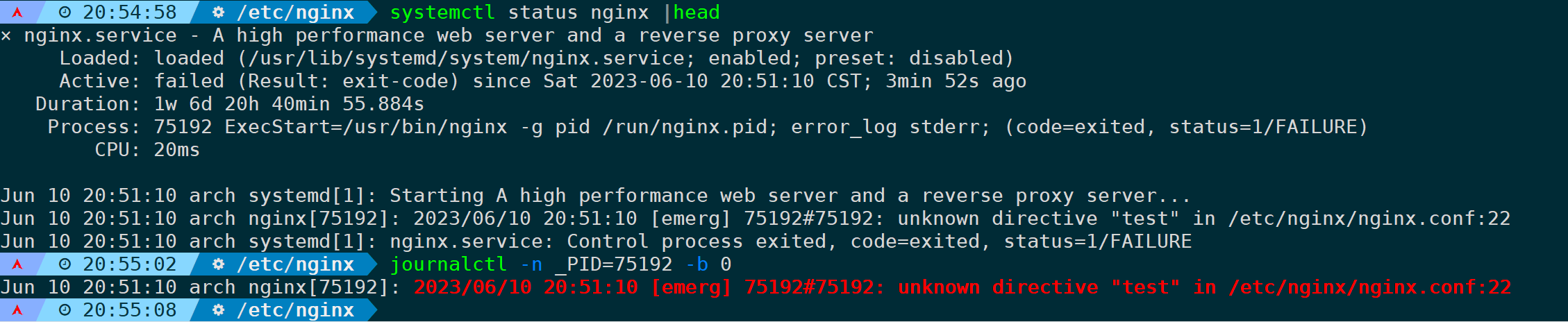
-n只显示最近10行,-b 0只显示本次系统启动到目前为止的日志。
通过systemctl查看服务状态,可以看到失败时的PID,即使这个服务并没有运行成功,systemd-journald也会将记录存储到_PID字段,因此当服务并没有正常运行时,你通过lsof、netstat、pidof、ps诸如此类的命令是查不到PID的,不要觉得奇怪,因为它们只能查当前正在运行的进程PID,而systemd会记录进程的PID,不管服务是否正常。
我们不妨通过verbose或json格式来输出,这样你应该能清晰认识到为什么能够通过_PID字段来过滤日志:
journalctl -n _PID=75192 -b 0 -o verbose
journalctl -n _PID=75192 -b 0 -o json-pretty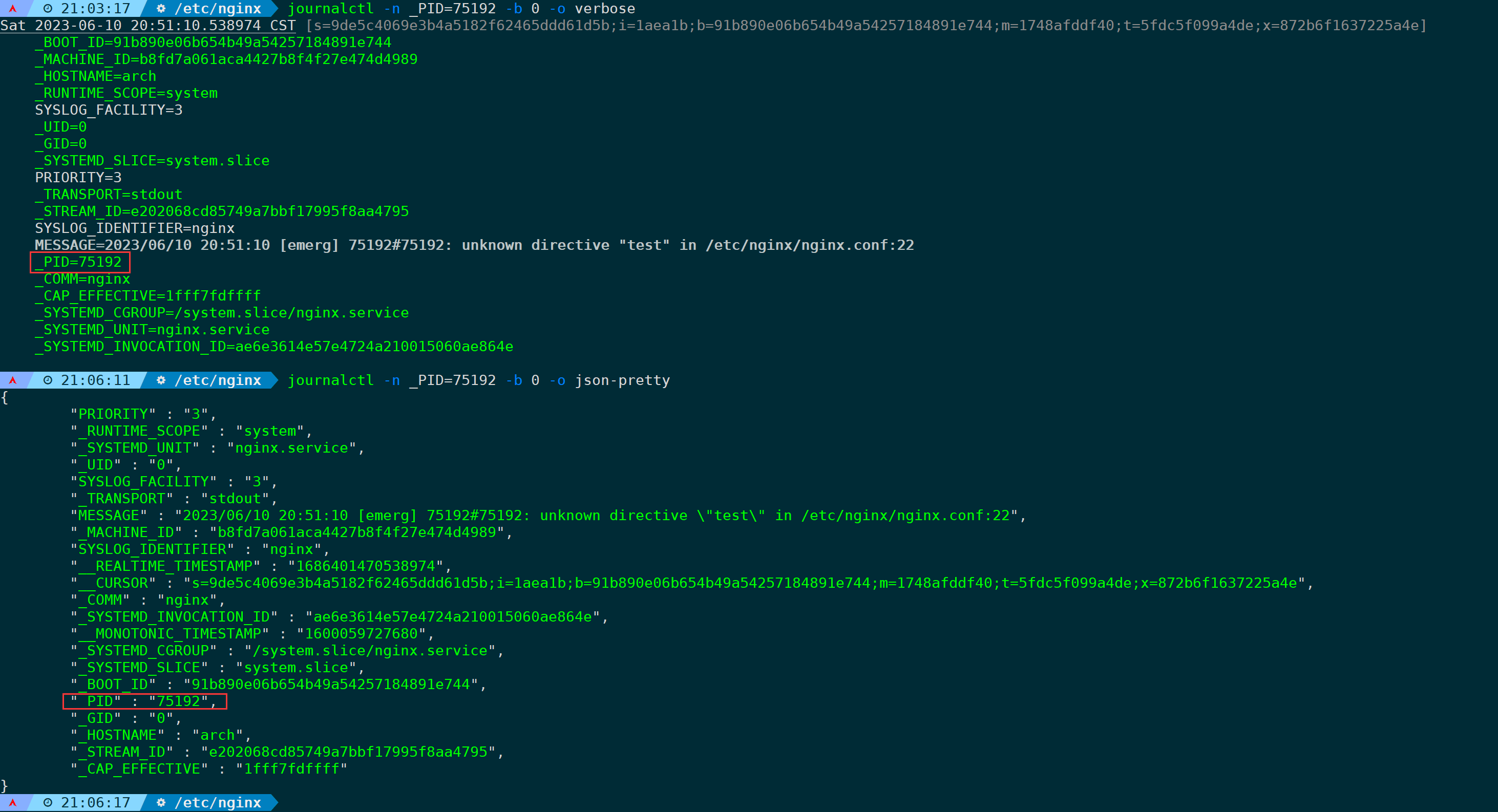
很明显,完整的日志会存储到不同的字段,每个字段分工明确。不用怀疑,上面的字段你都可以拿来单独作为过滤条件或者组合使用都是没问题的。
比如指定_PID的情况下同时指定_SYSTEMD_UNIT字段:
journalctl -n _PID=75192 _SYSTEMD_UNIT=nginx.service -o verbose
journalctl -n _PID=75192 _SYSTEMD_UNIT=nginx.service -o json-pretty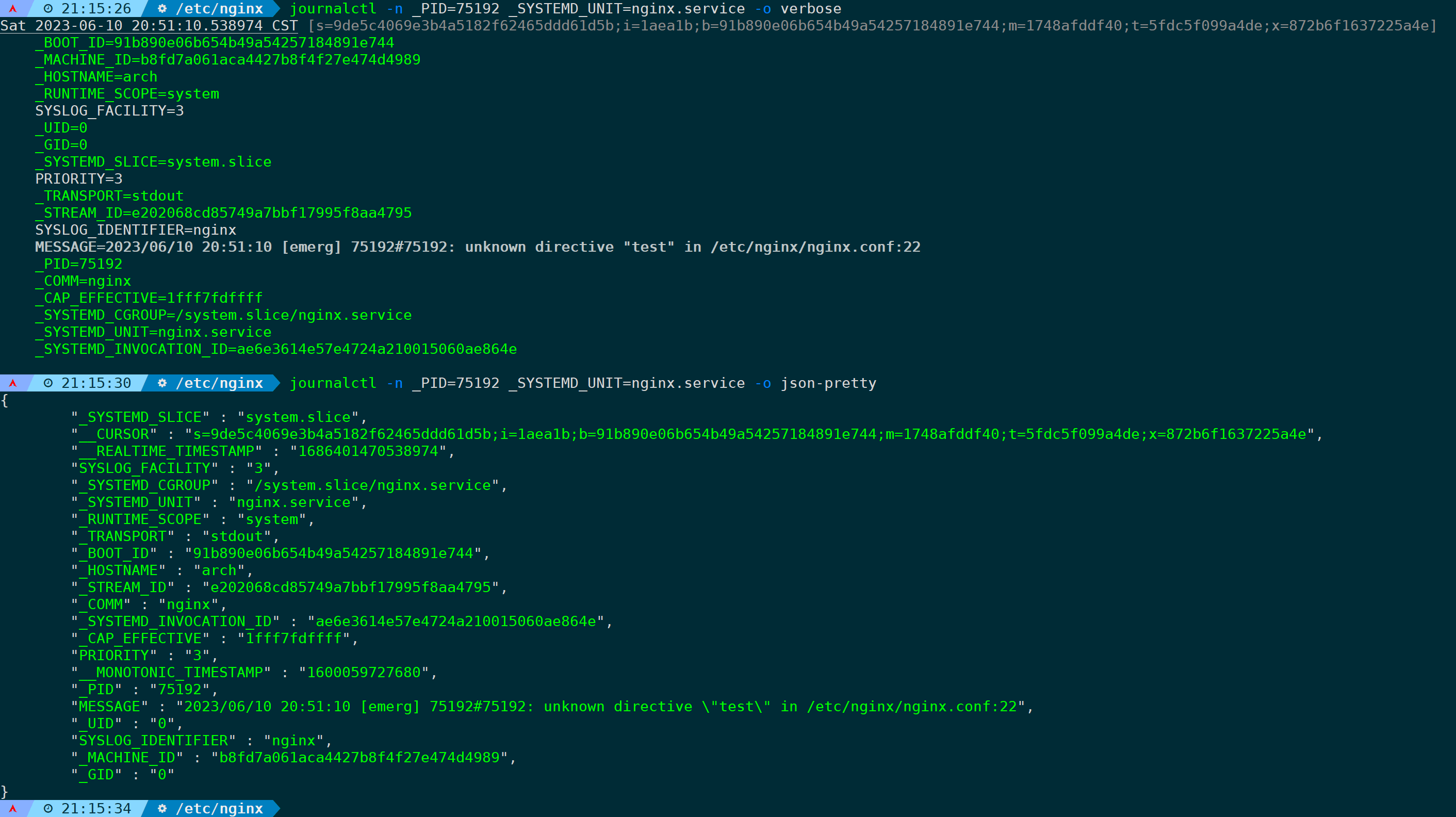
过滤条件越多日志越精准越具备唯一性。
当然你也可以通过-u参数来跟踪特定服务的日志:
journalctl -u nginx.service -n
9.禁止截断输出和截断输出
默认情况下,当日志过长,journalctl会截断输出,比如以下这条命令,显示身份验证模块的日志最近10行:
journalctl --facility=auth -t audit -g SER_AUTH -n
可以看到每一行末尾都用">"字符截断了,看不到完整内容,此时我们加上--no-pager参数即可:
journalctl --facility=auth -t audit -g SER_AUTH -n --no-pager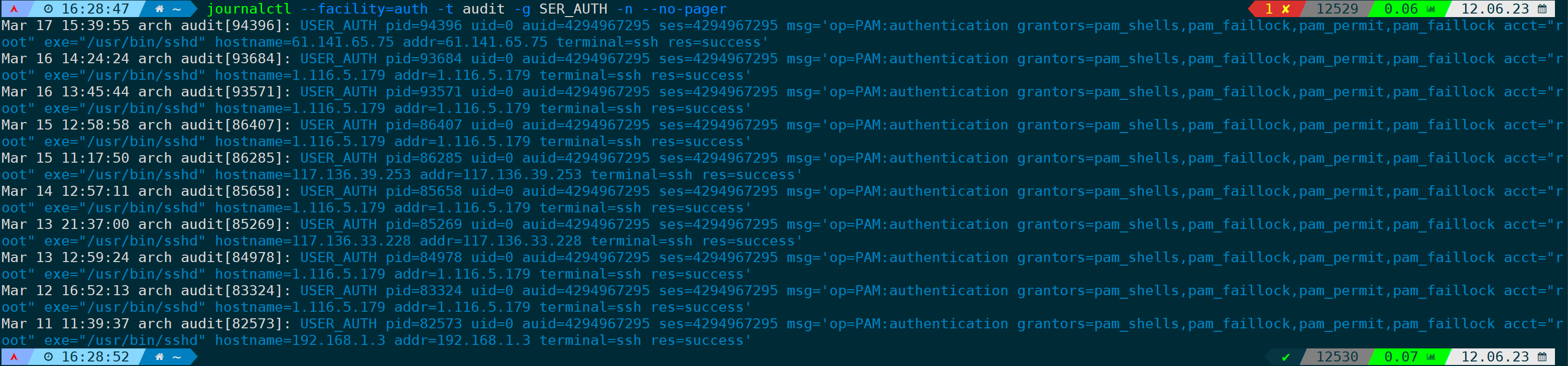
当然,如果你想省略中间内容,不需要完全显示,可以使用--no-full参数,journalctl会用"…"省略这部分内容:

--no-full的意思是如果日志信息太长,需要另起一行,则不显示所有,截断输出中间部分。
10.汇总统计日志字段出现次数
当使用一些组合命令时,可以轻松统计我们想要的字段出现的次数。
比如统计今天的错误日志(MESSAGE字段包含:fail|error|fatal的日志),汇总输出为对应的二进制命令的次数:
journalctl --no-pager --since today -g 'fail|error|fatal' -o json | jq '._EXE' | sort | uniq -c | sort -nr -k 1把时间限定去掉:
journalctl --no-pager -g 'fail|error|fatal' -o json | jq '._EXE' | sort | uniq -c | sort -nr -k 1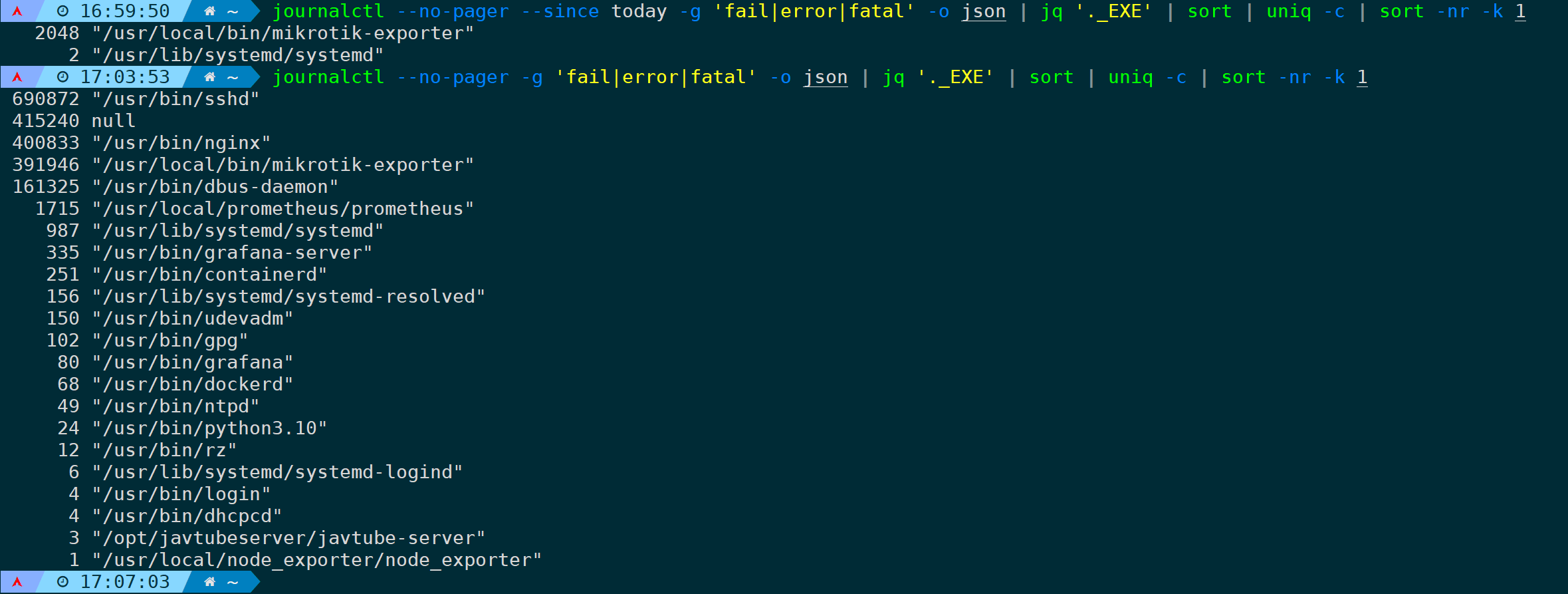
可以看到其中第二行为null,情况有以下几种:
- 系统日志记录的事件没有与特定的可执行文件关联;
- 可执行文件的信息不可用(比如该文件已被删除或信息丢失);
- 内核本身产生的日志,不需要与任何可执行文件关联。
上面是根据_EXE字段来统计汇总,那么其它字段也是同理,比如统计错误日志出现次数,并按照服务字段(_SYSTEMD_UNIT)汇总次数,取TOP 25行:
journalctl --no-pager -g 'fail|error|fatal' -o json | jq '._SYSTEMD_UNIT' | sort | uniq -c | sort -nr -k 1 |head -n 25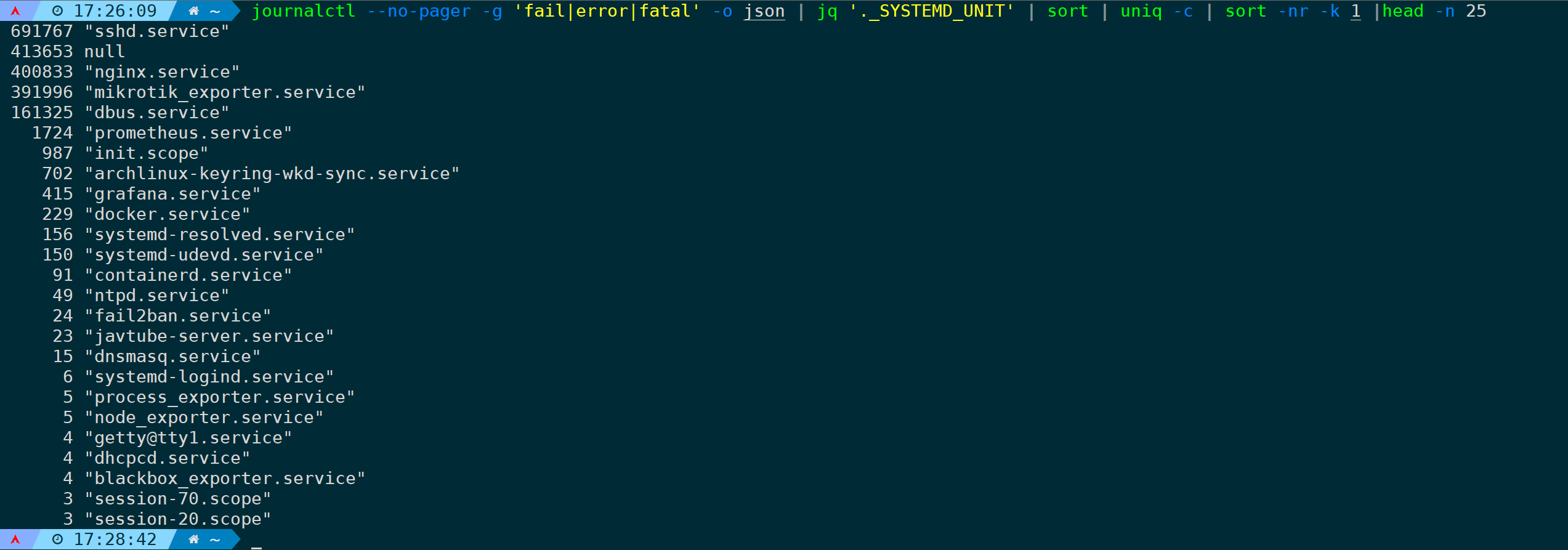
各个字段含义可通过 man 7 systemd.journal-fields 获取。
又或者,按照系统日志消息存储的类别(_TRANSPORT)来统计:
journalctl --no-pager -o json | jq '._TRANSPORT' | sort | uniq -c | sort -nr -k 1 # 统计范围为所有。
journalctl --no-pager -g 'fail|error|fatal' -o json | jq '._TRANSPORT' | sort | uniq -c | sort -nr -k 1 # 统计范围为匹配fail|error|fatal的日志。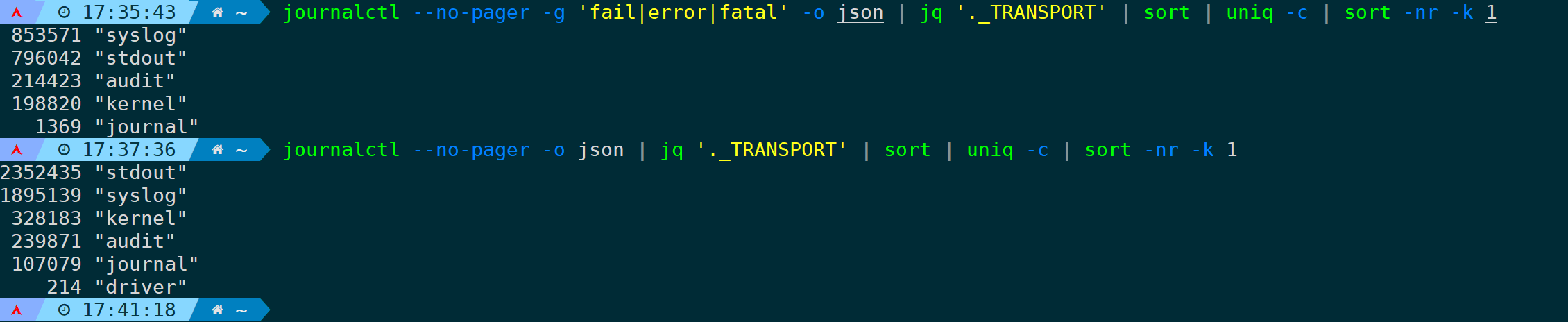
stdout:表示消息通过标准输出(stdout)传输,通常是由应用程序直接打印到控制台或输出到文件中。journal:表示消息通过本地套接字传输,由systemd-journald接收和处理。这是默认的传输方式,系统日志消息被写入到系统日志文件(通常位于/var/log/journal/目录下)。syslog:表示消息通过syslog协议传输,由rsyslog或其他类似的日志服务接收和处理。这种传输方式允许将日志消息发送到远程服务器或进行其他配置和处理。journal+console:表示消息同时通过本地套接字和标准输出传输,消息会同时被写入到系统日志和控制台。journal+syslog:表示消息同时通过本地套接字和syslog协议传输,消息会同时被写入到系统日志和syslog。
3. logwatch
logwatch是一款日志分析工具,可以生成易读的日志报告。
Logwatch,顾名思义,是一款专门监测 Linux log 文件(日志文件)的软件。安装以后只要稍微配置一下,就能每天将主机的 log 分析文件发送至指定的邮箱。为什么要这么做? 因为这样能节省一个个手动查看日志的繁琐,为管理员节省时间,节省精力。并且每天(甚至更频繁)都能准确地接收到日志。从而对服务器的安全情况有所掌握。
安装并使用示例:
sudo apt-get install logwatch
sudo logwatch --detail High --mailto admin@example.com --service all --range today--detail < level>: 报告的详细度,可选项: High, Med, Low , 数字 0-10
--logfile < name>: 指日志文件名
--service < name>: 服务名,有对应的解析脚本,可以在 /usr/share/logwatch/scripts/services中找到
--print: 打印打标准输出
--mailto < addr>: 收件人地址
--archives: 以归档格式发送。使用压缩的文件, 轮转的文件, 例如 messages.1、messages.1.gz
--save < filename>: 保存到文件
--range < range>: 日期范围, Yesterday, Today, All
--debug < level>: 调试级别: High, Med, Low
--splithosts: 为每个主机创建一份报告
--multiemail: 将报告发送给多个邮件地址,没有使用--splithosts参数时,这个选项自动忽略
--output: 配置指令定义了一份 logwatch 报告的格式。有mail邮箱格式和html格式上述命令生成详细的日志报告,并通过邮件发送给管理员。

4. goaccess
goaccess是一款实时的Web日志分析工具,适用于分析Apache和Nginx日志。
GoAccess 是一个基于终端的实时 Web 日志分析仪。用 C 语言编写,它是快速,互动的,并以优雅而直观的方式显示日志。它提供了各种 Web 日志文件的支持,包括 Apache,Nginx,Caddy,Amazon S3 和 CloudFront,仅提及几个。它可以以 HTML 格式,JSON 渲染结果,还可以生成 CSV 报告。
安装并使用示例:
sudo apt-get install goaccess
goaccess /var/log/nginx/access.log -o report.html --log-format=COMBINED上述命令生成一份HTML格式的访问日志报告。
GoAccess特性
-
使用 C 语言编写,快速、实时,毫秒 / 秒级的更新
-
只使用 ncurses 作为依赖
-
支持几乎所有的 Web 日志格式(Apache,Nginx,Amazon S3,Elastic Load Balancing,CloudFront 等)
- 轻松设置日志格式
-
美观的的终端和 dashboard
-
通过了 Valgrind 测试
监视Apache日志
执行以下命令,监控Apache日志,其中
-f 选项允许在命令行上实时查看日志,
goaccess -f /var/log/apache2/access.log --log-format=COMBINED
通过web仪表板查看日志
我们还可以通过重定向来将 web 服务器日志以优雅而直观的方式呈现在一个仪表板上。我们可以将输出文件指定为linux_web.html。
当然,还可以将生成的html文件,放到指定的nginx或者apache目录,就可以远程通过浏览器访问(视情况而定要不要配置)。
goaccess -f /var/log/apache2/access.log --log-format=COMBINED > linux_web.html 在终端查看生成的linux_web.html文件
浏览器打开日志文件
将生成的linux_web.html文件导出到本地,使用本地浏览器打开。