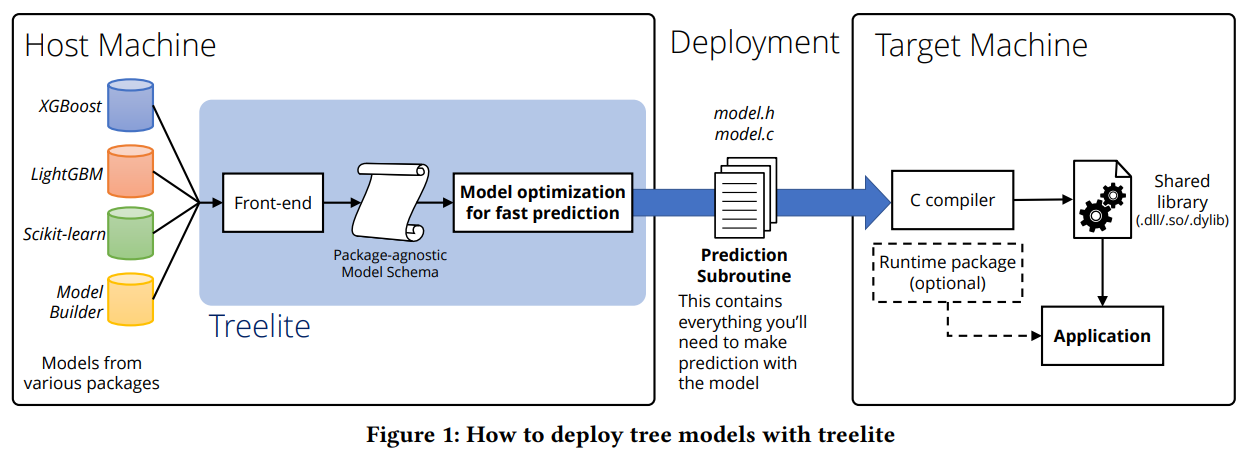
直接看结果: 代码: import re from collections import defaultdict import random import matplotlib.pyplot as plt import numpy as npimport pandas as pd import numpy as np import re from sklearn.feature_extraction.text import CountVectorizer from nltk.corpus import stopwords from nltk.tokenize import word_tokenize import matplotlib.pyplot as plt import seaborn as sns def STM(text):cleaned_text = re.sub(r'\W+', ' ', text)cleaned_text = re.sub(r'\d+', '', cleaned_text)tokens = cleaned_text.lower().split()stop_words = {'the', 'is', 'in', 'and', 'to', 'of', 'a', 'with&

 代码:
代码: