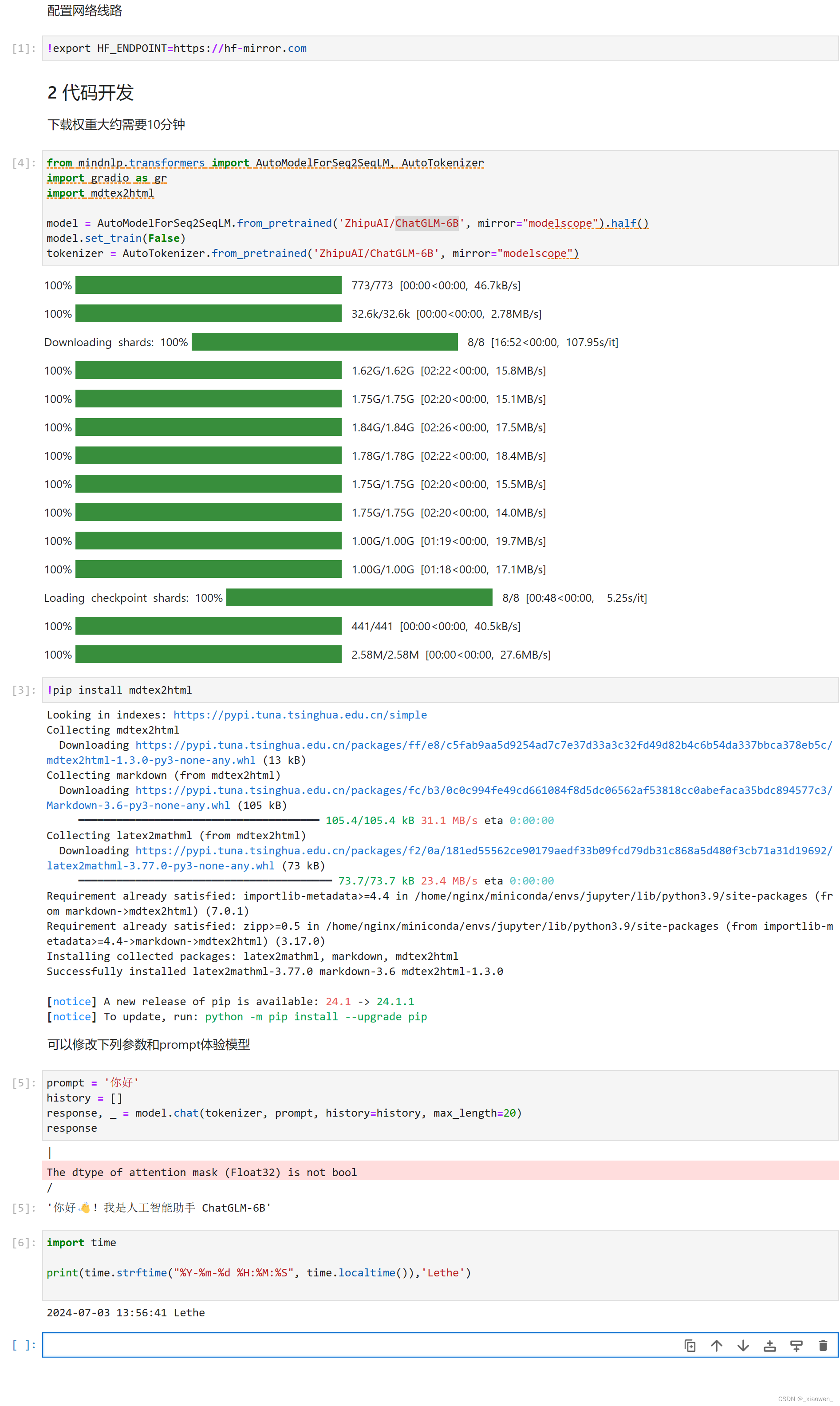
bean的创建顺序
在Spring Boot中,当一个配置类(使用@Configuration注解的类)中定义了多个bean时,这些bean的创建顺序并不完全由它们在类中的声明顺序决定。Spring框架在创建和管理bean时,遵循了复杂的依赖注入和生命周期管理规则,这些规则决定了bean的创建和初始化顺序。
以下是文心一言给出的一些影响bean创建顺序的主要因素(我直接复制过来):
- 依赖关系:Spring容器会根据bean之间的依赖关系来决定创建顺序。如果一个bean依赖于另一个bean,那么被依赖的bean会首先被创建。Spring通过构造函数、setter方法或字段注入等方式来识别这些依赖关系。
- @DependsOn注解:你可以使用@DependsOn注解来显式指定一个bean依赖于其他一个或多个bean。被@DependsOn注解指定的bean会在当前bean之前被创建。
- @Order或实现Ordered接口:虽然这些主要用于排序多个相同类型的bean(例如,多个实现了同一接口的bean),但它们在某些情况下也可能间接影响bean的创建顺序,尤其是当这些bean之间存在依赖关系时。
- @Bean的注册顺序:在配置类中,虽然bean的声明顺序不是决定性因素,但在没有其他依赖关系或显式排序的情况下,* Spring可能会按照它们在配置类中声明的顺序来创建bean。但是,这种顺序并不是严格保证的,特别是当存在复杂的依赖关系时。
- 初始化回调:Spring提供了几种初始化回调方法(如@PostConstruct注解的方法或实现了InitializingBean接口的afterPropertiesSet方法),这些方法在bean的所有必要属性被容器设置之后被调用。这些回调的执行顺序也受bean之间的依赖关系影响。
- 懒加载(Lazy Initialization):如果bean被标记为懒加载(通过@Lazy注解或全局配置),那么它只会在首次被请求时创建,这可能会影响bean的创建顺序。
- 总结来说,Spring Boot中配置类中多个bean的创建顺序主要由bean之间的依赖关系决定,而不仅仅是它们在配置类中的声明顺序。因此,在设计应用时,应该尽量避免对bean创建顺序的隐式依赖,而是通过显式的依赖关系或配置来管理bean的创建和初始化顺序。
bean注解的创建
首先这个注解在方法上使用,也可以在注解使用,这里只介绍在方法上使用的情况

在方法上使用很简单,只需要把它放在方法上就行
e.g
@Bean@ConfigurationProperties("spring.datasource.druid.master")public DataSource masterDataSource(DruidProperties druidProperties){DruidDataSource dataSource = DruidDataSourceBuilder.create().build();return druidProperties.dataSource(dataSource);}
- 这样如果在类中当做类属性使用,我们直接使用@Autowired注解注入就好了,
那如果是下面这样呢,这个
@Bean(name = "dynamicDataSource")@Primarypublic DynamicDataSource dataSource(DataSource dataSource){Map<Object, Object> targetDataSources = new HashMap<>();targetDataSources.put(DataSourceType.MASTER.name(), dataSource);setDataSource(targetDataSources, DataSourceType.SLAVE.name(), "slaveDataSource");return new DynamicDataSource(dataSource, targetDataSources);}
这样根据基于springboot的自动装配类型中的基于类型装配,可以找到我们上面创建的那个DataSource类型的bean
spring的依赖注入
实际上在Spring框架中,当你使用@Bean注解来声明一个bean的创建方法时,该方法中的参数并不是直接从某个地方“自动”获取的,而是根据Spring的依赖注入(DI)机制来解决的。Spring容器在创建bean时,会分析@Bean方法中的参数,并尝试通过以下几种方式来解决这些参数的依赖:
- 自动装配(Autowiring):
- 基于类型(byType):Spring会尝试在容器中查找与参数类型相匹配的bean。如果容器中只有一个bean匹配该类型,Spring会自动注入这个bean。如果有多个bean匹配,并且没有使用@Qualifier注解来指定具体的bean名称,那么Spring会抛出异常,因为它不知道应该注入哪一个bean。
- 基于名称(byName):如果你的@Bean方法参数名与容器中某个bean的名称相匹配,并且Spring的配置中启用了基于名称的自动装配(这通常是默认行为),那么Spring会尝试注入这个bean。不过,需要注意的是,在@Bean方法中使用基于名称的自动装配并不是非常直观,因为@Bean方法的参数名在编译后可能会被优化或更改,这取决于JVM和编译器的设置。因此,更推荐使用基于类型的自动装配。
- 通过方法参数中的注解:
- 如果@Bean方法的参数上使用了如@Qualifier、@Value等注解,Spring会根据这些注解来解析参数的值。例如,@Qualifier注解可以用来指定应该注入哪个bean(在有多个候选bean的情况下)。@Value注解则通常用于注入配置文件中的值(如属性文件中的值)。
- 通过构造函数或setter方法:
需要注意的是,虽然这里讨论的是@Bean方法中的参数,但通常我们不会在@Bean方法内部直接创建依赖对象(即参数所代表的bean)。相反,我们会让Spring通过构造函数或setter方法将这些依赖注入到我们的bean中。然而,对于@Bean方法本身,其参数是通过上述的依赖注入机制来解决的。 - Java配置和@Configuration类:
在@Configuration注解的类中,@Bean方法之间可以相互引用,因为Spring会确保在调用一个@Bean方法之前,它所依赖的所有bean都已经被创建和初始化。这种机制使得我们可以在@Bean方法中引用其他@Bean方法声明的bean。
总之,@Bean方法中的参数值是通过Spring的依赖注入机制来解决的,这通常涉及到基于类型或名称的自动装配,以及方法参数上的注解。
bean的名称
- 每个bean都有一个名称,那使用@Bean注解产生的bean在容器中的bean的名称什么,在下面有两个DataSource类型的bean
@Bean@ConfigurationProperties("spring.datasource.druid.master")public DataSource masterDataSource(DruidProperties druidProperties){DruidDataSource dataSource = DruidDataSourceBuilder.create().build();return druidProperties.dataSource(dataSource);}/*** 这里bean没有指定名称那这个bean在容器中的名称就 是方法名 "slaveDataSource"* @param druidProperties* @return*/@Bean@ConfigurationProperties("spring.datasource.druid.slave")@ConditionalOnProperty(prefix = "spring.datasource.druid.slave", name = "enabled", havingValue = "true")public DataSource slaveDataSource(DruidProperties druidProperties){DruidDataSource dataSource = DruidDataSourceBuilder.create().build();return druidProperties.dataSource(dataSource);}
在@bean注解中有个name参数,根据描述我们可以看出name值就是这个bean的名称,其中If left unspecified, the name of the bean is the name of the annotated method,表示如果没有指定,那这个bean的名称就是@Bean注解所注释的方法的名称,所以上面两个bean的名称分别是masterDataSource 和 slaveDataSource

- 如果指定了默认名称,那么这个bean在容器里就叫dynamicDataSource
@Bean(name = "dynamicDataSource")@Primarypublic DynamicDataSource dataSource(DataSource masterDataSource){Map<Object, Object> targetDataSources = new HashMap<>();targetDataSources.put(DataSourceType.MASTER.name(), masterDataSource);setDataSource(targetDataSources, DataSourceType.SLAVE.name(), "slaveDataSource");return new DynamicDataSource(masterDataSource, targetDataSources);}
那么参数中 public DynamicDataSource dataSource(DataSource masterDataSource)中的形参masterDataSource来自哪里呢,实际上它是spring从容器中找一个类型为DataSource,名为 masterDataSource的bean,如果把这里改成下面这样就会报错,因为容器中现在有两个DataSource类型的bean,masterDataSource 和 slaveDataSource,这里形参名叫做dataSource,spring根据名称找不到,根据类型能找到两个,不知道注入哪一个,就会报错
@Bean(name = "dynamicDataSource")@Primarypublic DynamicDataSource dataSource1(DataSource dataSource){Map<Object, Object> targetDataSources = new HashMap<>();targetDataSources.put(DataSourceType.MASTER.name(), dataSource);setDataSource(targetDataSources, DataSourceType.SLAVE.name(), "slaveDataSource");return new DynamicDataSource(dataSource, targetDataSources);}
这个时候@Qualifier注解就可以使用了,可以用@Qualifier注解指定bean,将masterDataSource的值 赋值到形参 dataSource
/**** 这里的形参 dataSource指的容器中DataSource类型的 名为dataSource 的 bean* 但是这里面容器里面没有这个bean,就可以用@Qualifier注解指定bean,将masterDataSource的值 赋值到形参 dataSource*/@Bean(name = "dynamicDataSource")@Primarypublic DynamicDataSource dataSource1(@Qualifier("masterDataSource") DataSource dataSource){Map<Object, Object> targetDataSources = new HashMap<>();targetDataSources.put(DataSourceType.MASTER.name(), dataSource);setDataSource(targetDataSources, DataSourceType.SLAVE.name(), "slaveDataSource");return new DynamicDataSource(dataSource, targetDataSources);}
这里实际上还有个@Primary注解,假如有多个相同类型的bean,可以使用@Primary来标明优先用那个bean,但是同一种类型的bean,只能有一个使用@Primary注解,实际上DynamicDataSource是DataSource的子类,所以实际上它们是同一种bean,所以只能有一个@Primary注解