题目:Dual Aggregation Transformer(双聚合Transformer) for Image Super-Resolution(图像超分辨)
论文(ICCV):Chen_Dual_Aggregation_Transformer_for_Image_Super-Resolution_ICCV_2023_paper.pdf (thecvf.com)
源码:zhengchen1999/DAT: PyTorch code for our ICCV 2023 paper "Dual Aggregation Transformer for Image Super-Resolution" (github.com)
Super Resolution:超分辨率(Super-Resolution),简称超分(SR)。是指利用光学及其相关光学知识,根据已知图像信息恢复图像细节和其他数据信息的过程,简单来说就是增大图像的分辨率,防止其图像质量下降。
一、摘要
研究背景:Transformer最近在低级视觉任务中获得了相当大的流行,包括图像超分辨率(SR)。这些网络沿着不同的维度、空间或通道利用自注意力,并取得了令人印象深刻的性能。这激励我们将 Transformer 中的两个维度结合起来,以获得更强大的表示能力。
主要工作:基于上述思想,本文提出了一种新的 Transformer 模型,双聚合 Transformer(DAT),用于 SR 图像。该 DAT 以 模块间 和 模块内 双重方式聚合了 跨空间 和 跨通道维度 的特征。
- 1. 交替地在连续的 Transformer 块中应用 空间 和 通道自注意力。该策略使 DAT 能够捕获全局上下文并实现 模块间特征聚合 。
- 2. 提出了自适应交互模块(AIM)和空间门前馈网络(SGFN)来实现 模块内特征聚合 。AIM 从相应维度补充了两种自注意力机制。
- 3. 同时,SGFN 在前馈网络中引入了额外的非线性空间信息。
实验效果:大量实验表明,DAT方法优于现有方法。
二、引言
图像超分辨任务的背景、挑战以及基于CNN网络的方法的不足(在全局依赖上)—> transformer简介 + 在超分辨方向上transformer相关的研究工作(主要为自注意力方向,两个方面:空间层面和通道层面)+ 概括 Spatial window self-attention(SW-SA)和 Channel-wise self-attention (CW-SA) 的作用(对超分辨)—> DAT网络、AIM模块和SGFN模块的设计动机(为了解决哪些问题)、设计思路(如何实现,网络具体实现是怎么做的)、功能和作用 —> 贡献:
- 1. 设计了一种新的图像SR模型--双聚合transformer(DAT)。DAT以块间和块内双重方式聚合空间和通道特征,以获得强大的表示能力。(主要工作概述)
- 2. 交替采用空间和通道自关注,实现块间空间和通道特征聚合。此外,还提出了AIM和SGFN来实现块内特征聚合。(新模块概述)
- 3. 进行了大量的实验,以证明DAT优于最先进的方法,同时保持了较低的复杂性和模型大小。(实验效果概述)
三、方法
3.1 架构概述
Dual Aggregation Transformer (DAT) 的网络体系结构如下图所示。双空间transformer模块 (DSTB)和双通道transformer模块 (DCTB)是两个连续的双聚合transformer模块 (DATB)。(DSTB和DCTB只在注意力有所不同,因此将他们都看作DATB模块)
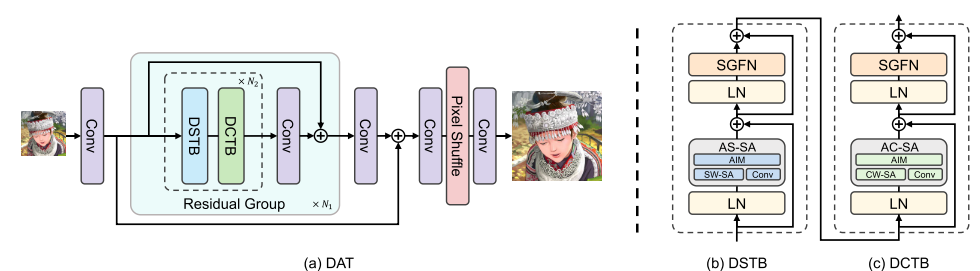
整个网络包括三个模块:浅层特征提取、深层特征提取和图像重建。
浅层特征提取(浅层卷积):首先,给定一幅低分辨率(LR)输入图像 ,使用卷积层对其进行处理并生成浅层特征
。
深层特征提取(DSTB + DCTB + 2× Conv):浅层特征 在深特征提取模块内进行处理,以获得深层特征
。该模块由N1个残差组(RG)堆叠。每个RG包含n2对双聚合transformer模块(DATB)。每个DATB对包含两个transformer模块,分别利用空间和通道自注意力。在RG的末尾引入一个卷积层来细化从变压器块中提取的特征。此外,对于每个RG,使用残差连接。
图像重建(conv + pixel shuffle + conv):在该模块中,通过 pixel shuffle 方法对深度特征 进行上采样。并在上采样操作之前和之后使用卷积层聚集特征。
Q:pixel shuffle 方法是什么?
3.2 Dual Aggregation Transformer Block(双聚合transformer模块)
DATB有两种类型:双空间transformer模块 (DSTB)和双通道transformer模块 (DCTB)。
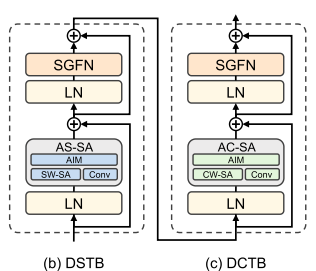
DSTB 和 DCTB 分别基于 Spatial Window Self-Attention(空间窗口自注意力) 和 Channel-Wise Self-Attention(逐通道自注意力)。通过交替应用 DSTB 和 DCTB ,DAT可以实现空间维度和通道维度之间的块间特征聚合。此外,还提出了自适应交互模块(AIM)和空间门前馈网络(SGFN)来实现模块内特征聚合。
1)Spatial Window Self-Attention(空间窗口自注意力)
如图所示,空间窗口自注意力(SW-SA)计算窗口内的注意。
过程:
1. 给定输入 ,通过线性投影生成查询Q、键K和值V矩阵。该过程被定义为:
![]()
其中,是省略偏差的线性投影。
2. 随后,将Q、K和V划分为不重叠的窗口,并展平每个包含 个像素的窗口。将重塑的投影矩阵表示为
。然后,将
分成 h 个头:
,
,且
。每个头的维度为
。第 i 个头的输出
定义为:
![]()
其中,D表示相对位置编码。(自注意力计算)
3. 最后,通过对所有 的重塑和拼接,得到特征
。 这一过程的公式如下:
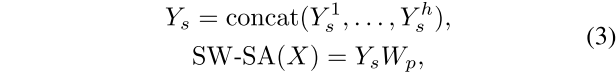
其中, 是融合所有特征的线性投影。(这里提到默认使用Swin transformer中的移位窗口操作来捕捉更多的空间信息)
代码实现:
def img2windows(img, H_sp, W_sp): # 划分窗口"""Input: Image (B, C, H, W)Output: Window Partition (B', N, C)"""B, C, H, W = img.shapeimg_reshape = img.view(B, C, H // H_sp, H_sp, W // W_sp, W_sp)img_perm = img_reshape.permute(0, 2, 4, 3, 5, 1).contiguous().reshape(-1, H_sp* W_sp, C)return img_permclass Spatial_Attention(nn.Module):""" Spatial Window Self-Attention.It supports rectangle window (containing square window).Args:dim (int): Number of input channels.idx (int): The indentix of window. (0/1)split_size (tuple(int)): Height and Width of spatial window.dim_out (int | None): The dimension of the attention output. Default: Nonenum_heads (int): Number of attention heads. Default: 6attn_drop (float): Dropout ratio of attention weight. Default: 0.0proj_drop (float): Dropout ratio of output. Default: 0.0qk_scale (float | None): Override default qk scale of head_dim ** -0.5 if setposition_bias (bool): The dynamic relative position bias. Default: True"""def __init__(self, dim, idx, split_size=[8,8], dim_out=None, num_heads=6, attn_drop=0., proj_drop=0., qk_scale=None, position_bias=True):super().__init__()self.dim = dimself.dim_out = dim_out or dimself.split_size = split_sizeself.num_heads = num_headsself.idx = idxself.position_bias = position_biashead_dim = dim // num_heads # 每个头的维度self.scale = qk_scale or head_dim ** -0.5if idx == 0:H_sp, W_sp = self.split_size[0], self.split_size[1]elif idx == 1:W_sp, H_sp = self.split_size[0], self.split_size[1]else:print ("ERROR MODE", idx)exit(0)self.H_sp = H_spself.W_sp = W_spif self.position_bias:self.pos = DynamicPosBias(self.dim // 4, self.num_heads, residual=False)# generate mother-setposition_bias_h = torch.arange(1 - self.H_sp, self.H_sp)position_bias_w = torch.arange(1 - self.W_sp, self.W_sp)biases = torch.stack(torch.meshgrid([position_bias_h, position_bias_w]))biases = biases.flatten(1).transpose(0, 1).contiguous().float()self.register_buffer('rpe_biases', biases)# get pair-wise relative position index for each token inside the windowcoords_h = torch.arange(self.H_sp)coords_w = torch.arange(self.W_sp)coords = torch.stack(torch.meshgrid([coords_h, coords_w]))coords_flatten = torch.flatten(coords, 1)relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]relative_coords = relative_coords.permute(1, 2, 0).contiguous()relative_coords[:, :, 0] += self.H_sp - 1relative_coords[:, :, 1] += self.W_sp - 1relative_coords[:, :, 0] *= 2 * self.W_sp - 1relative_position_index = relative_coords.sum(-1)self.register_buffer('relative_position_index', relative_position_index)self.attn_drop = nn.Dropout(attn_drop)def im2win(self, x, H, W): # 将Q、K和V划分为不重叠的窗口, (B N C) --> (num_win num_heads H_sp* W_sp C//num_heads)B, N, C = x.shapex = x.transpose(-2,-1).contiguous().view(B, C, H, W)x = img2windows(x, self.H_sp, self.W_sp)x = x.reshape(-1, self.H_sp* self.W_sp, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3).contiguous()return xdef forward(self, qkv, H, W, mask=None):"""Input: qkv: (B, 3*L, C), H, W, mask: (B, N, N), N is the window sizeOutput: x (B, H, W, C)"""q,k,v = qkv[0], qkv[1], qkv[2]B, L, C = q.shapeassert L == H * W, "flatten img_tokens has wrong size"# partition the q,k,v, image to windowq = self.im2win(q, H, W)k = self.im2win(k, H, W)v = self.im2win(v, H, W)q = q * self.scaleattn = (q @ k.transpose(-2, -1)) # B head N C @ B head C N --> B head N N# calculate drpeif self.position_bias:pos = self.pos(self.rpe_biases)# select position biasrelative_position_bias = pos[self.relative_position_index.view(-1)].view(self.H_sp * self.W_sp, self.H_sp * self.W_sp, -1)relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()attn = attn + relative_position_bias.unsqueeze(0)N = attn.shape[3]# use mask for shift windowif mask is not None:nW = mask.shape[0]attn = attn.view(B, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)attn = attn.view(-1, self.num_heads, N, N)attn = nn.functional.softmax(attn, dim=-1, dtype=attn.dtype)attn = self.attn_drop(attn)x = (attn @ v)x = x.transpose(1, 2).reshape(-1, self.H_sp* self.W_sp, C) # B head N N @ B head N C# merge the window, window to imagex = windows2img(x, self.H_sp, self.W_sp, H, W) # B H' W' Creturn x2)Channel-Wise Self-Attention(逐通道自注意力)
通道自注意力(channel-wise self-attention, CW-SA)中的自注意力机制是沿着通道维度进行的。
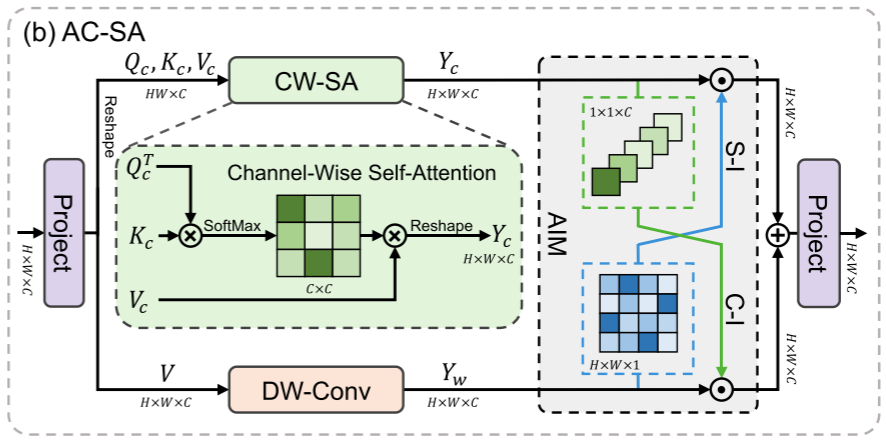
方法:按通道划分为头部,并分别对每个头部进行注意力计算。
过程:给定输入X,应用线性投影来生成查询、键和值矩阵,并将它们重塑为 大小。用
,
和
表示重构矩阵。与SW-SA中的操作相同,将投影向量分成 h 个头。则第 i 头的通道自注意力过程可计算为:
![]()
其中, 是第 i 个头的输出,α 是可学习的参数,用于在softmax函数之前调整内积。最后,通过对所有
进行重塑和拼接(这里与空间窗口自注意力操作相同),得到注意力特征
。
class Adaptive_Channel_Attention(nn.Module):# The implementation builds on XCiT code https://github.com/facebookresearch/xcit""" Adaptive Channel Self-AttentionArgs:dim (int): Number of input channels.num_heads (int): Number of attention heads. Default: 6qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float | None): Override default qk scale of head_dim ** -0.5 if set.attn_drop (float): Attention dropout rate. Default: 0.0drop_path (float): Stochastic depth rate. Default: 0.0"""def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):super().__init__()self.num_heads = num_headsself.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)self.dwconv = nn.Sequential(nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1,groups=dim),nn.BatchNorm2d(dim),nn.GELU())self.channel_interaction = nn.Sequential(nn.AdaptiveAvgPool2d(1),nn.Conv2d(dim, dim // 8, kernel_size=1),nn.BatchNorm2d(dim // 8),nn.GELU(),nn.Conv2d(dim // 8, dim, kernel_size=1),)self.spatial_interaction = nn.Sequential(nn.Conv2d(dim, dim // 16, kernel_size=1),nn.BatchNorm2d(dim // 16),nn.GELU(),nn.Conv2d(dim // 16, 1, kernel_size=1))def forward(self, x, H, W):"""Input: x: (B, H*W, C), H, WOutput: x: (B, H*W, C)"""B, N, C = x.shapeqkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads) # 按通道划分头部qkv = qkv.permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2]q = q.transpose(-2, -1)k = k.transpose(-2, -1)v = v.transpose(-2, -1)v_ = v.reshape(B, C, N).contiguous().view(B, C, H, W)q = torch.nn.functional.normalize(q, dim=-1)k = torch.nn.functional.normalize(k, dim=-1)attn = (q @ k.transpose(-2, -1)) * self.temperatureattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)# attention outputattened_x = (attn @ v).permute(0, 3, 1, 2).reshape(B, N, C)# convolution outputconv_x = self.dwconv(v_)# Adaptive Interaction Module (AIM)# C-Map (before sigmoid)attention_reshape = attened_x.transpose(-2,-1).contiguous().view(B, C, H, W)channel_map = self.channel_interaction(attention_reshape)# S-Map (before sigmoid)spatial_map = self.spatial_interaction(conv_x).permute(0, 2, 3, 1).contiguous().view(B, N, 1)# S-Iattened_x = attened_x * torch.sigmoid(spatial_map)# C-Iconv_x = conv_x * torch.sigmoid(channel_map)conv_x = conv_x.permute(0, 2, 3, 1).contiguous().view(B, N, C)x = attened_x + conv_xx = self.proj(x)x = self.proj_drop(x)return x
3)Adaptive Interaction Module(自适应交互模块)
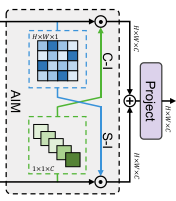


下分支:由于自注意力专注于捕捉全局特征,纳入了一个平行于自注意力模块的卷积分支(DW-Conv),将局部性引入Transformer。
问题:
- 1. 简单地添加卷积分支不能有效地融合全局和局部特征。
- 2. 尽管SW-SA和CW-SA交替执行可以同时捕获空间和通道特征,但不同维度的信息仍然不能在单个自注意力中有效利用。
目的:为克服这些问题,本文提出了自适应交互模块(AIM),根据自注意力机制的类型,从空间或通道维度自适应地重新加权两个分支的特征。
过程:首先,对 V 进行并行深度卷积(DW-Conv),以建立自注意力和卷积之间的直接联系。卷积输出为 。然后引入AIM,对两个特征进行自适应调整。具体而言,AIM包括两个交互操作:空间交互(S-I) 和 通道交互(C-I)。给定两个输入特征,
和
,空间交互计算一个输入的空间注意力图( 记为S-Map,大小为
)。通道交互计算通道注意力图( 记为C-Map,大小为
)。以 B 为例,公式表达如下:
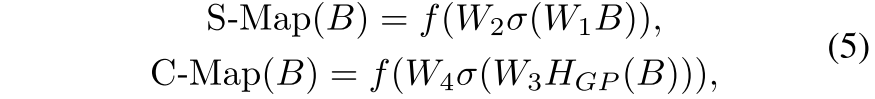
其中 表示全局平均池,
表示Sigmoid函数,
表示GELU函数。
表示用于缩小或放大通道维度的逐点卷积的权重。W1和W2的缩放比率分别为 r1,C/r1。W3的缩放比率为r2,并且W4膨胀比率为 r2。
随后,相互将注意力图应用于另一个输入,从而实现交互。这一过程的公式如下:
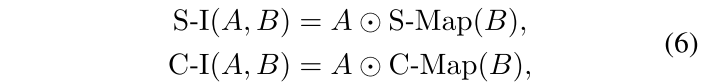
其中,⊙表示逐元素乘法。
最后,基于AIM,在SW-SA和CW-SA的基础上,设计了两种新的自注意力机制AS-SA和AC-SA。对于SW-SA,我们引入了两个分支之间的通道-空间相互作用。对于CW-SA,我们采用空间-信道交互。给定输入 ,过程定义为:
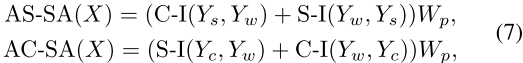
其中,、
和
是上面定义的SW-SA、CW-SA和DW-Conv的输出。
4)Spatial-Gate Feed-Forward Network(空间门前馈网络)

问题:
- 1. 前馈网络(FFN)难以捕获空间信息。
- 2. 此外,通道中的冗余信息阻碍了特征表达能力。
解决方法:提出了空间门前馈网络(SGFN),将空间门(SG)引入到FFN中。
结构:SG模块是一个简单的门机制,由深度卷积和逐元素乘法组成。沿着通道维度,将特征映射分为卷积支路和乘法支路两部分。总体而言,给定输入 ,SGFN计算公式如下:
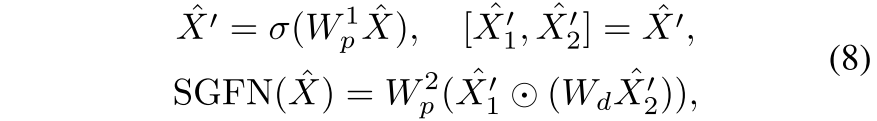
其中, 和
表示线性投影,σ 表示Gelu函数,
表示深度卷积的可学习参数。
和
空间中,其中 C' 表示SGFN中的隐维度。
四、实验
训练设置:本文训练了 patch 大小为64×64,批次大小为32的模型。训练迭代次数为500K。通过ADAM优化器( β1=0.9和β2=0.99 ),通过最小化 L1 损失来优化模型。将学习速率设置为2×10−4,并以[250K,400K,450K,475K]为标记减半。此外,在训练期间,随机使用90◦、180◦和270◦的旋转和水平翻转来增强数据。本文的模型是基于4个A100图形处理器的PyTorch实现的。
数据集:DIV2K 和 Flickr2K用于训练,以及五个基准数据集:Set5、Set14、B100、Urban100和Manga109用于测试。分别在×2、×3、×4三种尺度下进行了实验。
评估指标:PSNR 和 SSIM,这两个度量是在YCbCR空间的Y通道( 即,亮度 )上计算的。
4.1 消融实验
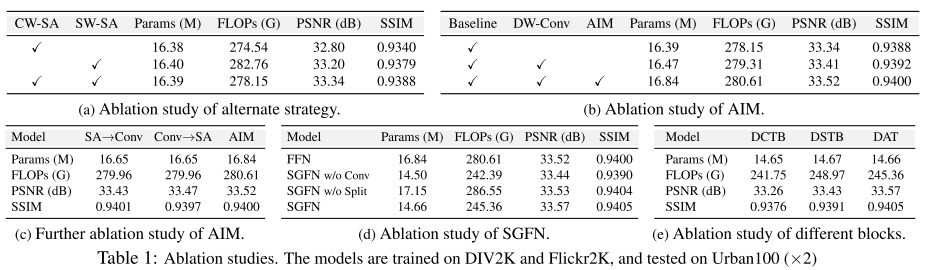
为了调查交替使用SW-SA和CW-SA的策略的效果,本文进行了几个实验:
- 1. 表的第一行和第二行表示用 CW-SA 或 SW-SA 替换 DAT 中的所有注意模块,其中SW-SA采用8x8窗口大小。(单一模块)
- 2. 第三行表示在 DAT 中的连续transformer模块中交替应用两个SA。此外,在SA中,所有模型都采用规则的FFN,而不采用AIM。(本文方法)
比较这三种模型,可以观察到,使用SW-SA的模型的性能优于使用CW-SA的模型。此外,交替应用两个SA可以获得33.34dB的最佳性能。这表明,同时利用通道信息和空间信息是精确图像恢复的关键。
4.2 与最先进的方法进行比较
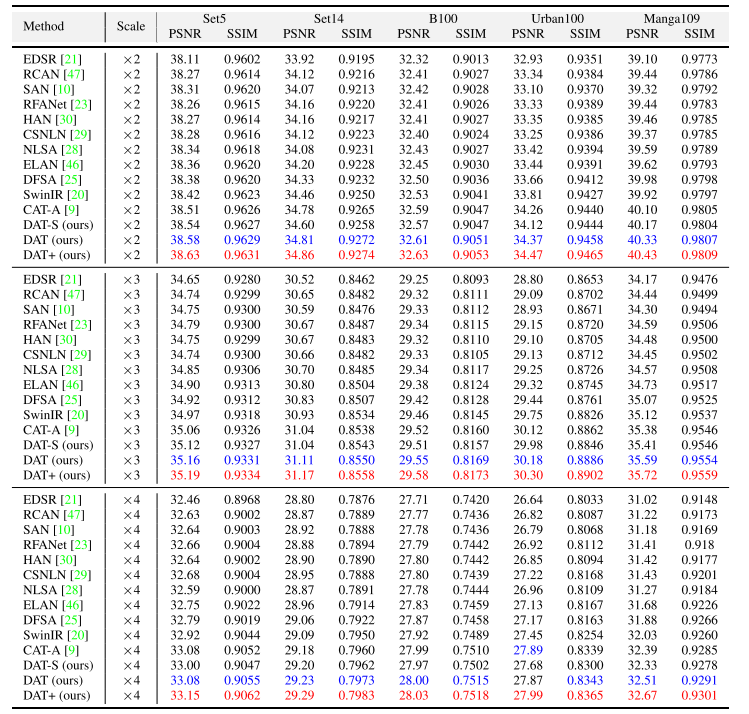
定量比较:同时,除了在Urban100数据集(×4)上的PSNR值与CAT-A相比外,DAT的性能要好于以前的方法。具体地说,与SwinIR和CAT-A相比(比较对象),DAT在Manga109数据集(×2)上(数据集)获得了显著的增益,分别获得了0.41db和0.23db的改进(提升比例)。此外,小视觉模型DAT-S也取得了与以往方法相当或更好的性能。所有这些定量结果表明,聚合块间和块内的空间和通道信息可以有效地提高图像重建质量(结论)。
定性比较:在一些具有挑战性的场景中,以前的方法可能会遇到模糊伪影、扭曲或不准确的纹理恢复(对比方法定性描述)。与之形成鲜明对比的是,本文的方法有效地减少了伪影,保留了更多的结构和更精细的细节(本文方法定性描述)。这主要是因为本文的方法通过从不同维度提取复杂特征,具有更强的表示能力(结论)。
五、结论
主要工作:本文提出了一种新的图像SR变换模型--双聚集变换(DAT)。DAT以块间和块内双重方式聚合空间和信道特征,以获得强大的表示能力(概述,方法 + 作用)。
- 1. 具体地说,连续的transformer模块交替地应用空间窗口和通道方式的自注意力。DAT可以通过这种替代策略对全局依赖关系进行建模,并实现空间维度和通道维度之间的块间特征聚合。
- 2. 此外,还提出了自适应交互模块(AIM)和空间门前馈网络(SGFN)来增强每个块并实现两维之间的块内特征聚合。目的从相应维度强化两种自我注意机制的建模能力。(逐模块细化概述,方法 + 作用)
- 3. 同时,SGFN利用非线性空间信息对前馈网络进行补充。
实验结果:大量的实验表明,DAT的性能优于以往的方法。