参考资料:活用pandas库
1、创建数据
(1)创建Series
在pandas中,series是一维容器,seires中的数据类型(dtype)必须相同。创建series最简单的方法是传入一个python列表。如果传入的是混合类型的列表,将会使用最常见的类型object。
# 导入库
import pandas as pd
s=pd.Series(['banana',42])
print(s)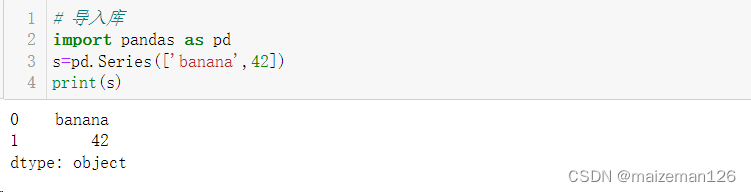
请注意上图中的输出结果,左边显示的“行号”实际是Series的索引。当然也可以指定series的索引,如下:
# 通过传入一个python列表,手动为Series指定索引值
s=pd.Series(["wes mckinney","creator of pandas"],index=["Person","Who"])
print(s)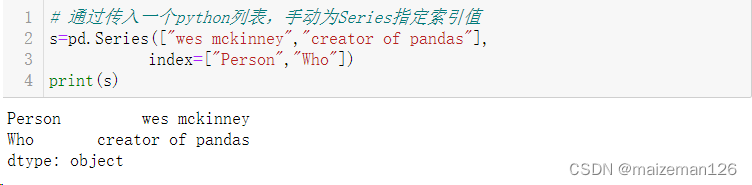
(2)创建DataFrame
字典是创建DataFrame最常见的方法,键代表列名,值是列的内容。
scientists=pd.DataFrame({"Name":["Rosaline Franklin","William Gosset"],"Occupation":["Chemist","Statistician"],"Born":["1920-07-25","1876-06-13"],"Died":["1958-04-16","1937-10-16"],"Age":[37,61]
})
print(scientists)
DataFrame可以使用columns参数指定列的顺序。如果想把那么列作为行索引,可以使用index参数。
scientists=pd.DataFrame({"Occupation":["Chemist","Statistician"],"Born":["1920-07-25","1876-06-13"],"Died":["1958-04-16","1937-10-16"],"Age":[37,61]},index=["Rosaline Franklin","William Gosset"],columns=["Occupation","Born","Died","Age"]
)
print(scientists)
2、Seires
首先创建一个DataFrame
# 创建名为scients的DataFrame
# 其带有行索引标签
scientists=pd.DataFrame({"Occupation":["Chemist","Statistician"],"Born":["1920-07-25","1876-06-13"],"Died":["1958-04-16","1937-10-16"],"Age":[37,61]},index=["Rosaline Franklin","William Gosset"],columns=["Occupation","Born","Died","Age"]
)
print(scientists)# 使用行索引标签选择一位科学家
first_row=scientists.loc['William Gosset']
print(type(first_row))
print(first_row)
我们看输出的结果,第一“列”输出索引,第二“列”输出值。我们可以查看此Seires的索引和值,分别是index属性和values属性,当然我们可以用keys函数来获取索引。如下:
print(first_row.index)
print("-"*20)
print(first_row.keys())
print("-"*20)
print(first_row.values)

(1)类似于ndarray的Series
Series是pandas的一种数据结构,与numpy.ndarray非常相似,ndarray的许多方法和函数也适用于Series。
numpy是一个科学计算库,常用于处理数字向量。可以吧Series看作numpy.ndarray的扩展,它们的属性和方法有重叠。针对数字向量,可以进行一些常见的计算,如描述统计。
ages=scientists["Age"]
print(ages)
print("-"*20)
print("均值:",ages.mean())
print("-"*20)
print("最大值:",ages.max())
print("-"*20)
print("最小值:",ages.min())
print("-"*20)
print("标准差:",ages.std(ddof=1))

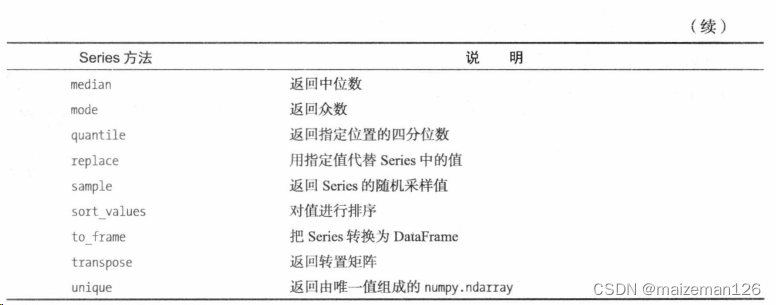
(2)布尔子集:Series
# 读取数据集
df=pd.read_csv(r"C:\王池池\学习\python\活用pandas库\data\scientists.csv")
# 获取ages数据列作为Series
ages=df["Age"]
print(ages)
# 调用describe方法获取多项描述统计数据
print(ages.describe())
# 调用mean方法获取所有年龄均值
print(ages.mean())
# 获取大于平均值的年龄
print(ages[ages>ages.mean()])
# 查看ages>ages.mean()的返回值
print(ages>ages.mean())最后一个print函数的输出结果如下,是一个dtype为bool型的Series。

(3)操作自动对齐和向量化(广播)
许多Series方法(以及DataFrame方法)都是向量化的,即这些方法会同时处理整个向量。这种方式让代码更易读,并且通常可以通过优化来加速计算。
①如果两个长度相同的向量之间执行计算,所得向量的每个元素是两个向量对应元素的计算结果。

②当向量和标量进行运算时,标量会与向量的每个元素逐一进行计算。

③处理不同长度的向量时,处理方式决定于向量的类型。对于Series,对向量的操作会根据索引进行。结果限量的其余元素会被填充为“缺失”值,用NaN表示,指“not a number”即“非数值”。
这种处理方式称为“广播”(broadcasting),pandas的“广播”是指不同shape的数组之间的运算方式。
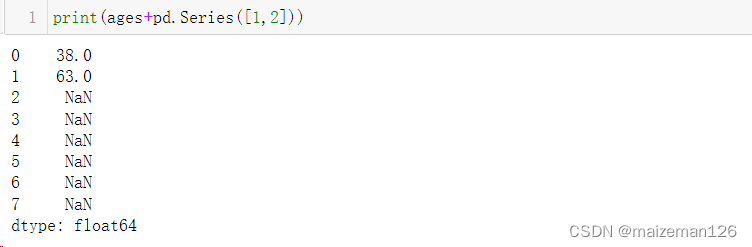
④pandas基本会自动对齐数据。执行操作时,数据会尽可能依据索引标签进行对齐。
# 依据年龄在数据中的原有顺序输出
print(ages)
# 将年龄按索引标签倒序排列
rev_ages=ages.sort_index(ascending=False)
print(rev_ages)
# 参考输出,显示索引标签对齐
print(ages+ages)
# 请注意在向量相反的情况下如何获取相同值
print(ages+rev_ages)![[ES] ElasticSearch节点加入集群失败经历分析主节点选举、ES网络配置 [publish_address不是当前机器ip]](https://img-blog.csdnimg.cn/img_convert/a04ad7cd77d6d958e9cf7a87ce41e99f.png)