一、仿射变换图像结合正则项优化CAM生成
论文:Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation (CVPR,2020)
1.SEAM方法

-
孪生网络架构(Siamese Network Architecture):SEAM 方法采用了孪生网络结构,这种结构包含两个相似的网络分支,它们共享相同的权重和参数。每个分支都会处理输入图像,但是应用不同的变换(例如缩放、旋转等)。
-
等变正则化(Equivariant Regularization,简称 ER):这是 SEAM 方法的一个组成部分,目的是通过正则化技术确保网络输出的类激活图(CAM)在各种仿射变换下保持一致性。这意味着无论输入图像如何变换,网络都应该产生相同类别的激活响应。
-
像素相关性模块(Pixel Correlation Module,简称 PCM):这是 SEAM 方法的另一个组成部分,用于捕捉像素之间的上下文外观信息,并通过学习到的相似性来修正原始的 CAM,以提高 CAM 的精确度和一致性。
-
特别设计的损失函数(Specially Designed Losses):SEAM 方法使用了特定的损失函数来训练网络,这些损失函数不仅促进了 CAM 在仿射变换下的一致性,还确保了 CAM 能够很好地贴合目标对象的轮廓。
仿射变换(Affine Transformation):仿射变换是指对图像进行的一系列线性变换,包括旋转、缩放、平移等。每个样本都有一个仿射变换 A(·)。
等变性(Equivariance):等变性是指一个函数在输入经过某种变换后,其输出也会经过相同的变换。对于分割任务,作者指出分割函数(记为 Fws(·))应该保持等变性,即对输入图像 I 应用仿射变换 A(·) 后,分割函数的输出 A(Fws(I)) 应该等于先将 I 变换为 A(I) 后再应用分割函数 Fws(·) 的结果。
不变性(Invariance):与等变性相对的是不变性,即不管输入如何变换,输出都保持不变。分类任务更关注于不变性,因为类别标签不应随图像的旋转或缩放而改变。文中提到 Pool(Fwc(A(I))) = l,这里的 Pool 表示池化操作(pooling),Fwc(·) 是分类函数,l 是类别标签。这意味着即使输入图像经过了仿射变换,分类函数的输出(即类别标签)应该保持不变。
分类函数的不变性原因:文章指出,分类函数的不变性主要是由于池化操作导致的,而分类函数 Fwc(·) 本身并没有等变约束。
全监督与弱监督学习的差距:由于分类函数缺乏等变约束,使得在网络学习过程中很难达到分割函数的目标,即难以学习到能够精确描述对象形状和轮廓的特征。因此,文章提出需要集成额外的正则化项(regularizers),以缩小全监督学习和弱监督学习之间的监督差距。
- 分类损失(Classification Loss):使用全局平均池化层(global average pooling)和多标签软边界损失(multi-label soft margin loss)来训练网络。
- 等变正则化损失(Equivariant Regularization Loss):确保原始 CAM 在不同变换下的一致性。
- 等变交叉正则化损失(Equivariant Cross Regularization Loss):通过 PCM 进一步整合自监督学习,避免 CAM 在细化过程中退化。
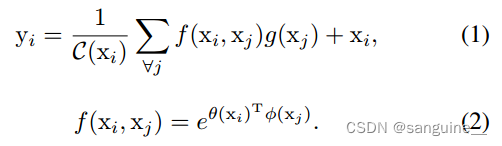
公式一:这个公式定义了自注意力机制中的一个输出信号 𝑦𝑖yi,它依赖于输入特征 𝑥x 在位置 𝑖i 上的表示。这里:
- yi 是位置 𝑖 的输出特征。
- xi 是输入特征在位置 𝑖的表示。
- C(xi) 是一个归一化因子,确保输出信号的幅度保持一致,通常是 ∑∀𝑗𝑓(𝑥𝑖,𝑥𝑗)的总和,这样可以使不同位置的 𝑦𝑖 具有相同的尺度。
- f(xi,xj) 是一个用于计算位置 𝑖和 𝑗之间相似度的函数,通常是一个嵌入空间中的点积,用于衡量两个位置的相关性。
- g(xj) 是一个用于转换输入信号 𝑥𝑗的函数,它可以是一个全连接层或1x1卷积层,用于为自注意力机制提供输入信号的不同表示。
公式二:这个公式定义了如何计算两个输入特征 𝑥𝑖和 𝑥𝑗之间的相似度 𝑓(𝑥𝑖,𝑥𝑗):
- θ(xi) 和 𝜙(𝑥𝑗)是嵌入函数,它们将输入特征 𝑥𝑖和 𝑥𝑗映射到一个嵌入空间中。这些函数通常由1x1卷积层实现,用于提取特征的高级表示。
- T 表示矩阵转置,确保 𝜃(𝑥𝑖)和 𝜙(𝑥𝑗)可以进行点积运算。
- e 表示向量,用于将 𝜃(𝑥𝑖) 转换为一个列向量,以便进行矩阵运算。
2.Equivariant Regularization(等变正则化)

-
网络表示:𝐹(⋅)表示的是整个网络模型,它接受输入并产生输出。
- 仿射变换:𝐴(⋅)表示任何空间仿射变换,如重新缩放(rescaling)、旋转(rotation)或翻转(flip)。这些变换可以改变图像的外观,但是不改变图像的语义内容。
-
正则化整合:为了在原始网络上整合正则化,网络被扩展为一个共享权重的孪生(siamese)结构。孪生网络结构包含两个相同的网络分支,它们共享相同的权重和参数。
-
变换应用:
- 一个分支在网络的输出上应用仿射变换,即对已经生成的CAM进行变换。
- 另一个分支在网络的前馈(feedforward)之前,对输入图像应用相同的仿射变换,然后通过网络生成CAM。
-
输出激活图的正则化:两个分支生成的输出激活图(即变换后的CAM和原始图像经过变换和网络处理后的CAM)通过正则化手段进行约束,以确保它们的一致性。这意味着无论图像如何变换,网络输出的CAM应该在语义上保持一致。
-
一致性保证:通过这种方式,正则化项确保了无论输入图像经过何种仿射变换,网络都能够生成一致的、与变换前图像对应的CAM。
3.Pixel Correlation Module
虽然等变正则化为网络学习提供了额外的监督,但仅使用经典卷积层很难达到理想的等变。自关注是捕获上下文信息和细化逐像素预测结果的有效模块。将Eq.(1)和Eq.(2)给出的经典自关注模块进行CAM细化,公式可以写成:
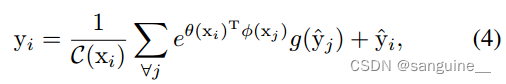
- 其中^y表示原始cam,y表示修改后的cam。
- 三个嵌入函数θ;φ;G可以通过单独的1 × 1卷积层来实现。
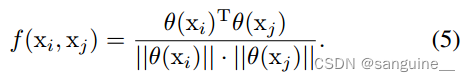
- 归一化特征空间的内积来计算当前像素i与其他像素之间的亲和力。
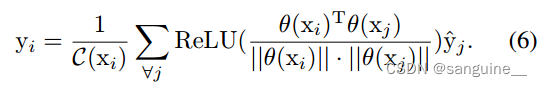
-
ReLU激活函数:在 PCM 中,使用 ReLU(Rectified Linear Unit)激活函数来处理像素之间的相似性得分。ReLU 函数的作用是将所有的负值置为零,而保持正值不变。这样做的目的是为了抑制(suppress)负的相似性得分,确保只保留正的、有意义的相似性信息。
- 相似性得分的归一化:在通过 ReLU 激活之后,相似性得分会被归一化(normalized)。归一化是一种数值处理方法,它可以确保相似性得分的总和为一个固定的值(如1),这样做有助于在不同的像素之间进行公平的比较。
-
加权求和生成最终 CAM:最终的 CAM 是通过将原始 CAM 与归一化后的相似性得分进行加权求和来生成的。这意味着每个像素在最终 CAM 中的值不仅取决于它在原始 CAM 中的值,还取决于它与图像中其他像素的相似性。
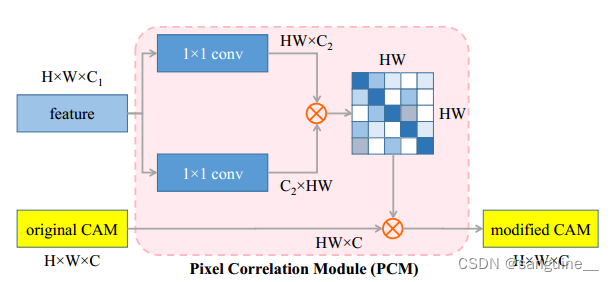
PCM 结构通过1×1卷积层处理原始 CAM,生成新的特征表示,然后利用这些特征表示来计算像素间的相似性,并将这些相似性信息整合回原始 CAM,从而生成修正后的 CAM。这个过程涉及到特征图的转换和融合,以及相似性计算,最终目的是生成一个更加精确的分割图。
4.Loss Design of SEAM
全局平均池化是一种池化操作,它将整个特征图的每个通道的数值取平均,生成一个单一的值作为该通道的池化结果。在生成预测向量z的过程中,全局平均池化层会对网络的输出特征图进行操作,将每个通道的数值取平均得到一个单一的值,然后将这些单一的值组合成一个向量z。
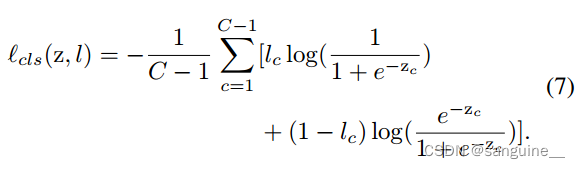
- 其中c表示前景对象的类别索引,C是总的类别数,l是真实标签向量,zc是预测向量z的第c个元素。
- 损失函数的目标是最小化预测向量z与真实标签l之间的差异。对于每个前景对象类别c,损失函数计算了预测值zc与真实标签lc之间的差异,并将这些差异进行汇总。如果预测值zc与真实标签lc一致,则损失函数趋近于0;否则,损失函数会增加,反映了预测值与真实标签之间的不一致性。
- lc:真实标签向量l中的元素,表示第c个前景对象类别的标签。如果lc为1,表示该类别存在;如果lc为0,表示该类别不存在。
- 预测向量zc经过sigmoid函数变换后的取值范围是(0,1)。

分类损失为目标定位提供了学习监督。为了保证输出的一致性,需要对原CAM进行等变正则化聚合。原始CAM的等变正则化(ER)损失可以简单地定义为:
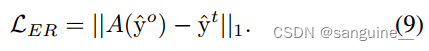
- ^yo:原始分支的网络输出的 CAM,即未经变换的 CAM。
- 𝑦^𝑡:变换分支的网络输出的 CAM,即经过相同仿射变换的 CAM。
- ∣∣⋅∣∣1:L1 范数,也称为曼哈顿距离,用于计算两个 CAM 之间的差异。L1 范数对每个元素的差异求和,对大的差异更加敏感。
- 等变正则化损失的目的是最小化原始分支和变换分支输出的 CAM 之间的差异。通过这种方式,网络学习到生成的 CAM 不仅在没有变换的情况下能够准确反映图像内容,而且在图像经过仿射变换后仍然保持一致性。
![]()
- 避免在PCM优化过程中CAM退化。
- 类激活图(CAMs)是通过前景对象的分类损失学习得到的。这意味着模型在训练过程中主要关注于识别和定位图像中的前景对象。
- 尽管模型专注于前景对象,但背景像素也不应该被忽视。在语义分割任务中,准确地识别和区分背景同样重要,因为它们提供了对前景对象的上下文信息。
- 在原始的 CAMs 中,背景像素的位置通常被赋予零向量(zero vectors),这意味着在这些位置的激活值为零。这样的表示方式无法产生梯度(gradients),从而无法通过梯度下降等优化算法推动背景像素的特征表示向更准确的方向更新。
- 为了解决上述问题,作者定义了一个背景分数(background score),用于改善背景像素的特征表示。这个分数是通过对原始 CAMs 进行修改得到的,确保背景像素也能产生有用的梯度,从而在网络训练过程中得到更好的优化。
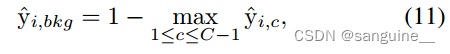
- 在深度学习中,梯度用于指导网络参数的更新。如果背景像素的激活值为零,那么它们在反向传播过程中不会产生梯度,导致这些像素的特征表示无法得到改进。通过定义背景分数,可以确保即使在背景区域,模型也能学习到区分不同背景上下文的特征。
- 通过引入背景分数,模型能够更好地学习到将背景像素的表示推向彼此更接近的方向,这有助于提高模型对背景的区分能力,从而在最终的分割任务中获得更准确的结果。
- 𝑦^𝑖,𝑐 表示原始 CAM 中,对于类别 𝑐在位置 𝑖的激活分数。这个分数反映了 CAM 在特定位置识别特定类别的置信度。
- 为了优化激活分数的表示,模型通过将前景(前景对象是指图像中用户感兴趣的对象,与背景相对)中非最大激活(non-maximum activations)置为零来归一化每个像素的激活向量。这意味着对于每个像素,只有最高激活分数的类别会被保留,其他类别的激活分数会被设置为零。
- 在归一化之后,模型会将一个额外的背景分数添加到每个像素的激活向量中。这个背景分数是独立的,并且与前景对象的激活分数不同。
- 在模型的推理阶段,即模型已经被训练完成并用于预测新图像的分割时,模型只保留前景对象的激活结果。这意味着只有那些对应于前景类别的最高激活分数会被用于最终的分割决策。
- 对于背景分数,推理阶段会将其设置为一个固定的阈值 𝛼。这里的 𝛼是一个硬阈值参数,用于确定背景像素的激活分数。通过这种方式,模型可以区分前景对象和背景,即使在训练阶段背景分数被用来改善像素间的关系。
- α 是一个预先设定的参数,用于在推理阶段确定背景像素的激活水平。如果一个像素的激活分数低于 𝛼,它可能被认为是背景的一部分。
![]()
- 分类损失(Classification Loss):用于大致定位(粗略定位)图像中的对象。通过图像级别的分类标签来引导网络学习,使得网络能够识别出图像中的主要类别。
- 等变正则化损失(Equivariant Regularization Loss,简称 ER Loss):作用:缩小像素级监督和图像级监督之间的差距。通过确保网络输出的CAM在不同的仿射变换下保持一致,ER Loss 强化了网络对图像变换的不变性,从而提高了分割的精度。
- 等变交叉正则化损失(Equivariant Cross Regularization Loss,简称 ECR Loss):整合PCM(像素相关性模块)与网络主体(trunk of the network),以在各种仿射变换下做出一致的预测。ECR Loss 通过正则化原始 CAM 和经过 PCM 修改后的 CAM 之间的差异,促进了网络对输入图像变化的适应性。
为什么用仿射变换??
仿射变换是一种常见的数据增强技术,可以通过缩放、旋转、翻转等方式改变图像的外观,但不改变其语义内容。这有助于提高模型对不同图像变换的泛化能力。
在全监督语义分割中,像素级标注会随着图像的变换而变换,因此模型学习到的特征图(如CAM)应该保持等变性。但在弱监督语义分割中,由于缺乏像素级标注,这种约束通常不存在。通过在训练过程中引入仿射变换,可以模拟这种约束,帮助模型学习到对变换不变的特征。
通过在训练过程中应用仿射变换,模型可以学习到即使在图像变换下也能保持一致性的分割特征。这提高了模型在面对真实世界中常见的视角变化和形变时的鲁棒性。
模拟真实世界条件:现实世界中的图像会因为各种因素(如相机移动、物体移动等)而发生变换。通过在训练集中引入仿射变换,可以更好地模拟这些条件,使模型更适应实际应用。
自监督学习:文章中提出的自监督等变注意力机制(SEAM)使用仿射变换作为一种自监督的手段。由于弱监督学习缺乏像素级标注,自监督学习通过设计不需要额外标注的任务(如预测图像变换)来提供额外的监督信号。
缩小监督差距:文章中提到,通过引入仿射变换,可以缩小全监督学习和弱监督学习之间的差距。这是因为全监督学习中的像素级标注隐含了等变性的约束,而弱监督学习通常缺乏这种约束。
改进分割质量:通过确保模型生成的CAM在仿射变换下保持一致,可以生成更精确的分割掩码,从而提高分割任务的性能。
5. Experiments
在训练阶段,为了避免像素相关性模块(PCM)和网络主体(trunk of the network)之间的相互干扰,作者选择在两者的连接点切断梯度的反向传播。这意味着PCM的权重不会通过梯度下降来更新,而是作为一个固定模块来使用。
尽管PCM的权重不通过梯度更新,但它仍然可以作为一个纯粹的上下文细化模块,与网络的主体同时进行训练。这允许PCM在训练过程中保持活跃,但不会对原始的CAM(类激活图)的学习过程产生负面影响。
由于梯度反向传播在PCM和网络主体之间被切断,原始CAM的学习过程不会受到PCM细化过程的影响。这样可以确保CAM能够专注于从图像级标注中学习到对象的分割。
在孪生网络中,两个分支之所以能够共享权重,是因为它们的参数(权重和偏置)是相同的。在训练阶段,两个分支都参与到梯度下降过程中,以学习等变性。但在推理阶段,由于模型已经训练完成,共享权重的一个分支就足以代表整个网络进行预测,因此没有必要激活另一个分支。
通过CAM进行分割的一般步骤和原理:
特征提取:使用深度学习模型(如卷积神经网络,CNN)从输入图像中提取特征。
生成原始CAM:基于提取的特征,网络生成原始的CAM。CAM是一种能够突出显示图像中与特定类别最相关的区域的热力图(heatmap)。
改进CAM:SEAM方法通过自监督学习和像素间的上下文信息来改进原始CAM。这包括:
- 等变正则化:确保经过仿射变换(如旋转、缩放等)的图像生成的CAM与原始图像的CAM在变换后保持一致。
- 像素相关性模块(PCM):利用像素间的相似性来细化CAM,使CAM更贴合目标对象的真实轮廓。
生成伪标签:通过改进后的CAM,可以为每个像素生成一个伪标签。这通常涉及到设置一个阈值,高于该阈值的像素被分配到特定的类别。
后处理:可能需要一些后处理步骤来优化分割结果,例如使用条件随机场(Conditional Random Fields, CRF)来进一步平滑分割边界,或者通过形态学操作来改善分割的连通性。
评估和优化:使用评估指标(如平均交并比,mIoU)来衡量伪标签的准确性,并根据需要调整模型参数或后处理步骤。
多尺度和翻转测试:在推理阶段,对不同尺度的图像和翻转后的图像进行测试,并将结果集成,以提高分割的鲁棒性和准确性。
通过上述步骤,SEAM方法能够在只有图像级标注的情况下,生成高质量的像素级分割结果。这对于弱监督语义分割任务特别有价值,因为它们通常缺乏详细的像素级标注信息。

OHEM代表在线难例挖掘(Online Hard Example Mining)。这是一种在训练深度学习模型时用于提高性能的技术,特别是在目标检测和语义分割等任务中。以下是OHEM的基本概念:
难例挖掘:在每次迭代或每个批次的训练中,模型会从训练数据中选择那些难以分类的样本。这些难例通常是模型当前状态下错误分类或者不太确定的样本。
在线:"在线"指的是难例挖掘是在模型训练过程中实时进行的,而不是预先在训练集上计算好。
损失函数聚焦:OHEM技术通过修改损失函数的计算方式,使得损失函数更多地聚焦在难例上。这意味着在反向传播过程中,模型参数的更新将主要由这些难例驱动。
提高鲁棒性:通过专注于难例,OHEM有助于模型学习到更加鲁棒的特征表示,从而提高模型对于新样本的泛化能力。
减少计算量:在每个训练批次中只关注难例,而不是整个训练集,可以减少不必要的计算量,使得训练过程更加高效。
在语义分割的上下文中,OHEM通常用于优化像素级别的分类损失,如交叉熵损失。在每个训练批次中,模型会计算所有像素的损失,然后选择损失最高的前一定比例的像素(这些像素是当前模型最难正确分类的)。然后,只有这些像素的损失会被用来进行反向传播和参数更新。
总的来说,OHEM是一种有效的训练策略,它通过专注于难例来提高模型的性能,尤其在标注数据稀缺或不平衡的情况下。在SEAM方法的消融研究中,OHEM被用来进一步提升模型生成的伪标签的质量,从而提高最终的分割性能。

- 从表2给出的评价结果可以看出,GradCAM和GradCAM++都不能缩小完全监督和弱监督语义分割任务之间的监督差距,因为最好的mIoU结果并没有提高。我们认为改进后的定位机制只是为了表示对象相关的部分,没有底层信息的约束,不适合分割任务。由这些改进的定位方法生成的cam与地面真相掩模的匹配程度并没有提高。

图4:cam的可视化。(a)原始图像。(b)地面真值分割。(c)基线cam。(d) SEAM生产的cam。SEAM不仅可以抑制过度激活,还可以将CAMs扩展到完整的对象激活范围。

图5:前景和背景亲缘性注意图的可视化。红色和绿色的叉表示选择的像素,用蓝色表示相似的特征。
- 所选择的前景和背景像素在空间上非常接近,而它们的亲和注意图却有很大的不同。证明了PCM可以通过自监督学习边界敏感特征
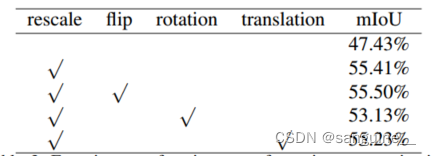
表3: 等变正则化的各种变换实验。简单地聚合不同的仿射变换并不能带来显著的改进。
- 简单地合并不同的转换并不是很有效。当缩放变换分别与翻转、旋转、平移相结合时,只有翻转有微小的改进。在我们看来,这是因为翻转、旋转和平移之间的激活映射过于相似,无法产生足够的监督。

表4:扩大缩放范围的实验。这里SEAM的重缩放率被设置为0.5。
- 单纯增加重尺度范围并不能提高生成伪标签的精度,这证明了性能的提高来自于PCM和等变正则化的结合,而不是数据增强
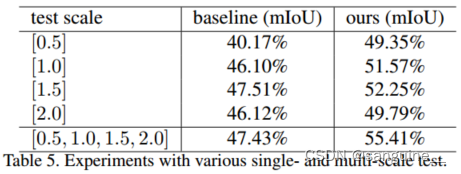
- 为了验证我们提出的SEAM的有效性,我们评估了单尺度和多尺度测试产生的cam。表5表明,我们提出的模型在单尺度和多尺度测试中都以更高的峰值性能优于基线。
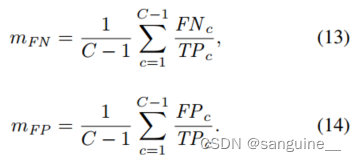
- 其中TPc表示c类真阳性预测的像素数,FPc和FN c分别表示假阳性和假阴性。这两个指标排除了背景类别,因为背景的预测与前景相反。具体来说,当cam没有完全激活覆盖时,如果假阴性区域较多,则mFN值较大。相对而言,较大的mFP意味着有更多的假阳性区域,这意味着CAMs被过度激活

图6:过激活和欠激活曲线。mFN曲线越低表示欠激活区域越少,mFP越低表示过激活区域越少。
- 该曲线显示了基线和我们的方法之间的巨大差距。SEAM实现了较低的mFN和mFP,这意味着我们的方法生成的cam具有更完整的激活覆盖和更少的过度激活像素。因此SEAM的预测图更符合地面真值分割的形状。在不同的图像尺度上,SEAM的曲线比基线模型更一致,证明了等方差正则化在网络学习过程中是有效的,有助于改进CAM。
6.Comparison with State-of-the-arts
为了进一步提高伪像素级注释的准确性,我们遵循[2]的工作,在我们修订的CAM基础上训练AffinityNet。最终合成的伪标签在PASCAL VOC 2012训练集上达到63.61% mIoU。然后在这些伪标签的完全监督下,用ResNet38主干训练经典分割模型DeepLab[5],得到最终的分割结果

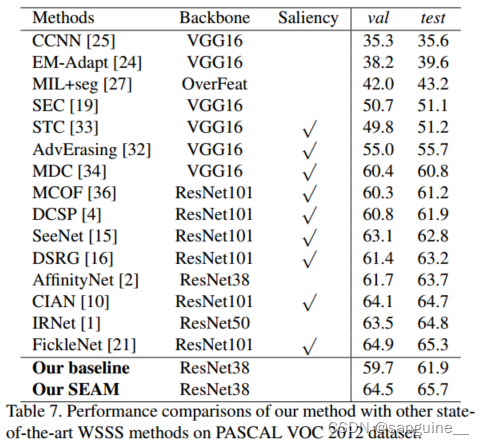
表6给出了各类在val集合上的mIoU,表7给出了前人方法的更多实验结果。与基线方法相比,我们的SEAM在具有相同训练设置的val和test集上显著提高了性能。此外,我们的方法仅使用PASCAL VOC 2012测试集上的图像级标签就能呈现出最先进的性能。

我们的性能提升既不是来自更大的网络结构,也不是来自改进的显著性检测器。性能的提高主要来自于额外的自我监督和PCM的合作,它为分割任务产生了更好的cam。图7显示了一些定性结果,验证了我们的方法在大对象和小对象上都能很好地工作。
7.conclusion
在本文中,我们提出了一种自监督等变注意机制(SEAM),通过引入额外的自我监督来缩小完全监督和弱监督语义分割之间的监督差距。SEAM通过利用等变正则化将自我监督嵌入到弱监督学习框架中,这迫使从各种转换图像预测的cam保持一致。为了进一步提高网络生成一致性图像的能力,设计了像素相关模块(PCM),该模块通过学习像素间相似度对原始图像进行细化。我们的SEAM是由一个具有有效正则化损失的连体网络结构实现的。生成的凸轮不仅在不同的变换输入上保持一致,而且更符合地面真值掩模的形状。我们合成的像素级伪标签重新训练的分割网络在PASCAL VOC 2012数据集上达到了最先进的性能,证明了SEAM的有效性