论文
https://arxiv.org/pdf/1706.02216
abstract
大图中节点的低维embedding已经被证明在各种预测任务中非常有用,然而,大多数现有的方法要求在embedding训练期间图中的所有节点都存在;这些先前的方法属于直推式(transductive),不能自然地推广到看不见的节点。这里我们介绍GraphSAGE,一个通用的归纳式(inductive)框架,它利用节点特征信息(例如,文本属性)来有效地为以前未见过的数据生成节点embedding。
这里再整理一下之前提到的GCN和GAT,其中GCN是属于inductive还是transductive似乎都各有簇拥,这里可以参考这篇问答
How GCN can be an inductive method? - #2 by czkkkkkk - Questions - Deep Graph Library
引用这里的一个对话:
- we say GraphSAGE is inductive because it can use sampling methods to predict the label of unseen nodes. On the contrary, GCN is transductive because the graph structure is fixed.
- Okay I’m confused… Why is there many articles stating that GCN is an inductive learning framework ?
And, even two of you collaborators think it is inductive, check this post How to carry out the batch-wise training while using layer defined in DGL? - Questions - Deep Graph Library 5 (neo and mufeili).
You can also see on this website : Graph Neural Networks (snap-stanford.github.io) 9 which comes from Stanford university and where Jure Leskovec teaches this course, that GCN has an inductive capacity.From my point of view, I think we can use GCN as an inductive method because it does not change the shape of weight matrixes when we add a new node to the graph. We just need to do get the node’ neighbors times their features times the learned weight matrixes. In the wend we just have to pass GCN(A[new_nodes], X, W_learned), with A[new_nodes] the line allowing to get the node’ neighbors, X the feature matrix and W_learned all the matrixes learned during the training of the model.
I am really confused as you can see, beacause some say it is transductive, others say it is inductive. I know that originally it was tested in an transductive setting, but many sources accord to say it can be used inductively. Maybe it is because everyone does not have the same definition of transductive and inductive, yet they are straightforward definitions…
In the end, I just want to know if a GCN model can, from a node totally unseen (not masked, really unseen) during the training, generate an embedding for this unseen node ?
At the end of my GCN, I want to classify my node as 1 or 0, so I just put a linear layer with a sigmoid activation function.Thank you for your clarification.
- Thanks for your interest in such a discussion. My understand may not be totally correct since I am not a GNN algorithm expertise. Here are my thoughts. Full graph GCN is not inductive because it only is applied for the whole graph and makes predictions for nodes that can be seen during training. Sampling-based GraphSAGE is inductive because it is able to apply sampling on unseen nodes. So the difference is whether sampling is applied or not. If sampling is available, both GCN and SAGE models can conduct inductive learning.
neural network - What is the model architectural difference between transductive GCN and inductive GraphSAGE? - Data Science Stack Exchange
a
- The main novelty of GraphSAGE is a neighborhood sampling step (but this is independent of whether these models are used inductively or transductively). You can think of GraphSAGE as GCN with subsampled neighbors.
In practice, both can be used inductively and transductively.
The title of the GraphSAGE paper ("Inductive representation learning") is unfortunately a bit misleading in that regard. The main benefit of the sampling step of GraphSAGE is scalability (but at the cost of higher variance gradients).
- GraphSage provides a solution to address the problem DeepWalk embedding technique. As we know that DeepWalk embedding technique use transudative learning to extract features from a graph. If a node is added in the graph then we gain re-run the algorithm to get embedding of all node. So, DeepWalk besed GNN is not suitable for dynamic graphs where the nodes in the graphs are ever-changing. To address the above-mentioned issue, GraphSage is introduced to learn the node representation in inductive way. Specifically, each node is represented by the aggregation of its neighborhood. Thus, even if a new node unseen during training time appears in the graph, it can still be properly represented by its neighboring nodes.
You can learn more following blog: https://towardsdatascience.com/a-gentle-introduction-to-graph-neural-network-basics-deepwalk-and-graphsage-db5d540d50b3
为什么GCN是Transductive的? - 知乎
总结来说就是最原始的方法看起来就是transductive的,但是也可以某种程度上认为是inductivde的。
GAT就没什么疑问了,属于铁inductive了。


introduction
对于一个大图,低维的向量embedding用于特征输入已经被证明在大量的预测和图分析任务中非常有用了。这些在节点embedding方法背后的基本思想都是使用降维技术将节点图邻域的高维信息提取成密集的向量嵌入。然后,这些节点嵌入可以馈送到下游机器学习系统,并帮助完成节点分类、聚类和链接预测等任务。
然而,以前的工作主要集中在从单个固定图中嵌入节点,并且许多现实世界的应用需要为未见过的节点或全新的(子)图快速生成embedding。生成节点embedding的归纳方法也有助于具有相同特征形式的图的泛化:例如,可以在源自模式生物的蛋白质-蛋白质相互作用图上训练embedding生成器,然后使用训练好的模型轻松地为收集到的新生物数据生成节点嵌入。
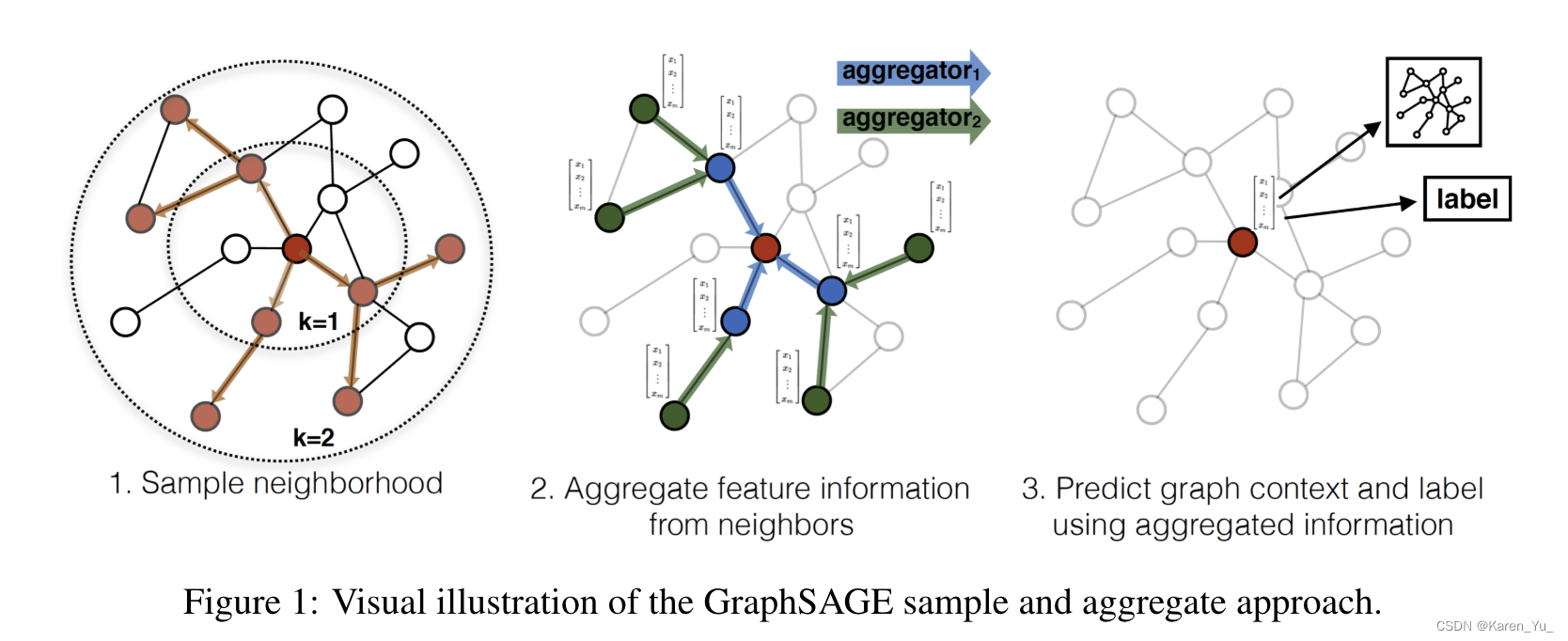
GraphSAGE (SAmple and aggreGatE),用于归纳节点嵌入。与基于矩阵分解的embedding方法不同,GraphSAGE利用节点特征(例如,文本属性、节点概要信息、节点度)来学习一个embedding函数,该函数可以推广到不可见的节点。通过在学习算法中加入节点特征,可以同时学习到每个节点邻域的拓扑结构以及节点特征在邻域中的分布。
GraphSAGE没有为每个节点训练一个不同的embedding向量,而是训练了一组聚合器函数,这些函数学习从节点的局部邻域聚合特征信息(图1)。每个聚合器函数从远离给定节点的不同跳数或搜索深度聚合信息。在测试或推理时,使用训练好的系统通过应用学习到的聚合函数来生成完全不可见节点的embedding。
原始的GCN算法是为transductive环境下的半监督学习而设计的,精确的算法要求在训练过程中知道完整的图拉普拉斯。GraphSAGE算法的一个简单变体可以看作是GCN框架到归纳设置的扩展。
proposed method: GraphSAGE
关键思想:如何从节点的邻居那里聚合信息(比如周围节点的度、文本属性)。
embedding generation(i.e., forward propagation) algorithm
假设我们已经训练好模型了,即假设我们已经学到K聚合函数(记作)的参数了,这里聚合的信息来源于节点的邻居,同样还学到了一系列权重矩阵(记作
),用于在模型的不同层或“搜索深度”之间传播信息。

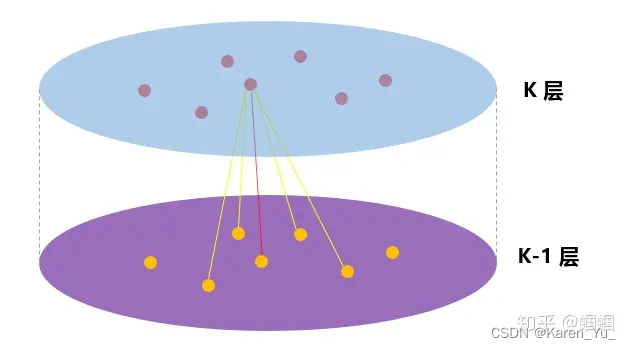
algorithm 1背后的直觉是,在每次迭代或搜索深度时,节点聚集来自其本地邻居的信息,并且随着该过程的迭代,节点逐渐从图的进一步到达处获得越来越多的信息。
algorithm 1描述的是当整张图()、所有节点的特征(
)被提供给输入时,产生embedding的过程。
关于邻居的定义:在这篇论文中,同一采样固定大小的邻域,而不是像algorithm 1 那样使用所有的邻居->这样就可以保证每个batch的计算量固定。->把定义成一个固定大小的、统一的集合
的采样,然后我们在每次迭代的时候,都抽取不同的统一的sample(个人理解这里的不同指的是节点不同,这里的统一指的是类似归一化之后的结果)
learning the parameters of GraphSAGE
为了在一个完全非监督的设置下学习有用的、可以预测的表示,对输出表示(应该就是指embedding)采用graph-based的损失函数,用来微调权重矩阵
,通过随机梯度下降调整聚合函数的参数。这一graph-based损失函数让相邻的节点能有类似的表示(这个好像还挺常见的,比较general的GNN似乎就是希望相邻的节点更相似),同时强制每个节点的表示是与众不同的。
这里是一个出现在节点
固定长度的random walk的附近的节点,
是sigmoid函数,
表示负样本分布,
表示负样本的个数。与之前的embedding方法不同,我们放到损失函数中的
表示是由节点的局部邻域中包含的特征生成的,而不是为每个节点训练唯一的embedding。
aggregator
节点的邻居没有自然的顺序;因此,algorithm 1中的聚合函数必须在一个无序的向量集合上操作。理想情况下,聚合器函数应该是对称的(即,其输入的不变操作),同时仍然是可训练的,并保持较高的表示能力。聚合函数的对称性保证了我们的神经网络模型可以训练并应用于任意有序的节点邻域特征集。
论文介绍了三种聚合器:mean aggregator,LSTM aggregator,pooling aggregator。
mean aggregator
取中向量的元素均值。mean聚合器几乎等同于在tranductive GCN框架中使用的卷积传播规则。可以通过用以下代码替换algorithm 1中的第4行和第5行,推导出GCN方法的归纳变体:
称这种改进的基于均值的聚合器为卷积,因为它是局部谱卷积的粗略线性逼近,这个卷积聚合器和我们提出的其他聚合器之间的一个重要区别是,它不执行算法第5行中的连接操作。->这种卷积聚合器连接了节点在前一层的表示以及聚合的邻居向量
。这种连接可以被看作是GraphSAGE在不同的“搜索深度(search depths)”或者“层(layers)”之间的一种简单的“skip-connection”
LSTM aggregator
基于LSTM架构的更复杂的聚合器。与均值聚合器相比,lstm具有更强的表达能力。然而,重要的是要注意lstm不是固有对称的(即,它们不是排列不变的),因为它们以顺序的方式处理它们的输入。通过简单地将lstm应用于节点邻居的随机排列,使得lstm能够在无序集合上运行
pooling aggregator
pooling 聚合器是对称的、可训练的在这种池化方法中,每个邻居的向量通过全连接神经网络独立馈送,在此转换之后,对跨邻居集的聚合信息应用元素最大池操作:
这里的max是元素层面上的求最大值,是非线性激活函数。原则上,在最大池化之前应用的函数可以是任意深度的多层感知器,但我们在这项工作中专注于简单的单层架构。通过对每个计算特征应用max-pooling算子,该模型有效地捕获了邻域集的不同方面。还要注意的是,原则上,任何对称向量函数都可以用来代替最大算子(例如:(元素的均值)。文章指出在实验中没有发现最大值和均值之间显著的区别,因此文章中采用的是最大值方法。
附录mini batch的伪代码。

下面是附录一些其他的博客中比较值得关注的内容
GraphSage 算法原理介绍与源码浅析_珍妮的算法之路-CSDN博客
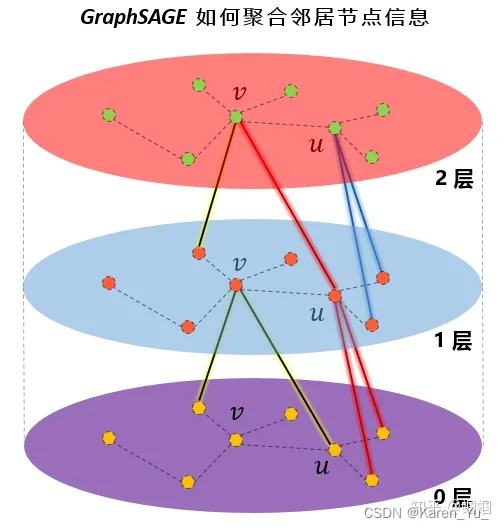
GraphSage 属于 Inductive learning 算法, 它学习一种聚合函数, 通过聚合节点邻居的特征信息来学习目标节点本身的 embedding 表达. 它的主要步骤就记录在它的名字中: Sample 与 Aggregate. 其中 Sample 阶段通过随机采样获取多跳邻居; Aggregate 阶段聚合邻居节点特征生成目标节点自身的 embedding. 以聚合 2 跳邻居为例, 它将首先聚合 2 跳邻居的特征生成 1 跳邻居的 embedding, 之后再聚合 1 跳邻居的 embedding 来生成节点本身的 embedding. 由于生成 1 跳邻居 embedding 时, 已经包含了 2 跳邻居的特征信息, 此时目标节点也将获得 2 跳邻居的特征信息. 论文中的图示形象地展示了这一过程:
官方开源代码:GitHub - williamleif/GraphSAGE: Representation learning on large graphs using stochastic graph convolutions.
采样:
采样时按照进行,聚合时按照
进行
这篇博客的作者在这里给了非常详细的图解,请直接移步原博客阅读。
图神经网络10-GraphSAGE论文全面解读 - 知乎
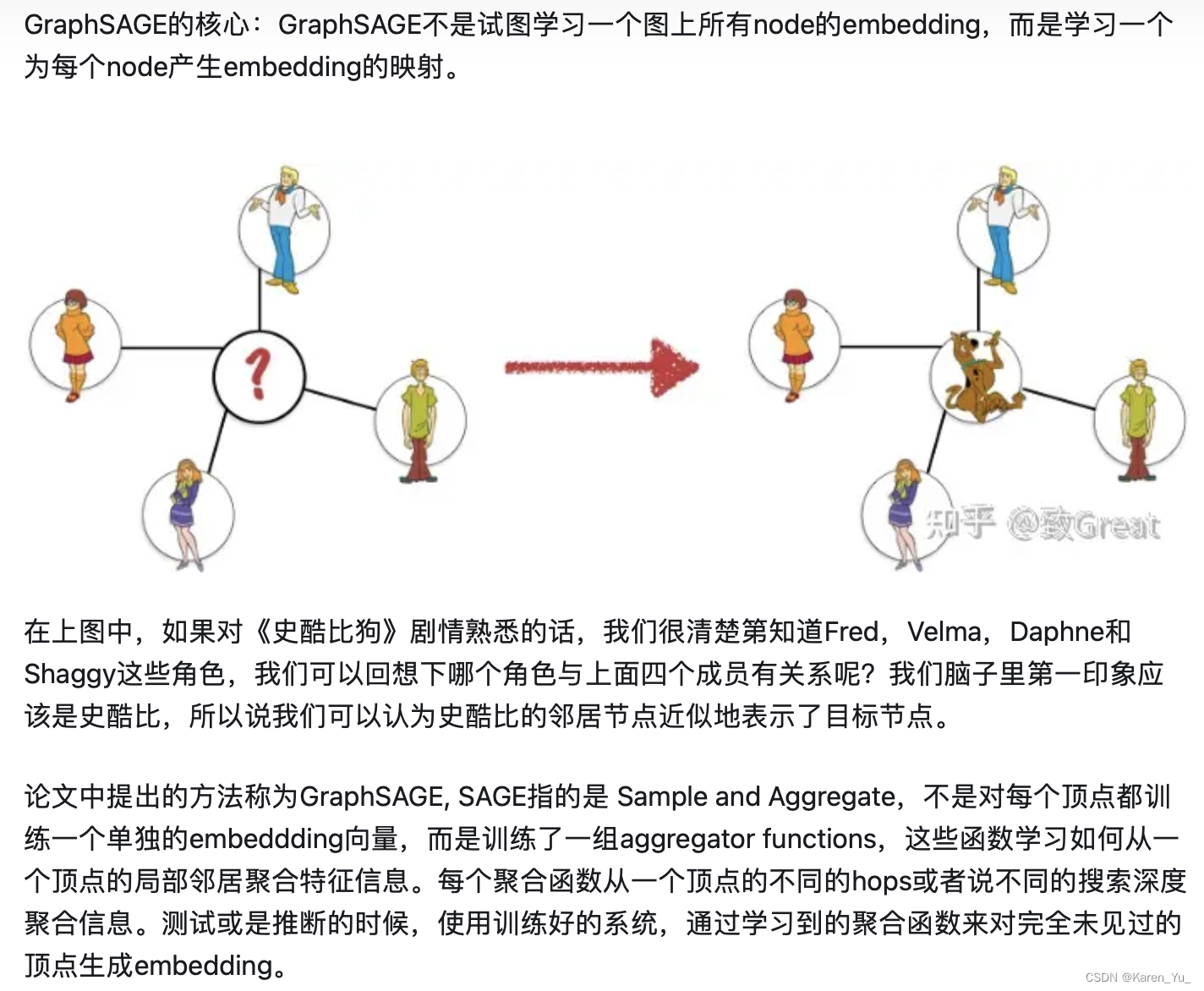
上面是为红色的目标节点生成embedding的过程。k表示距离目标节点的搜索深度,k=1就是目标节点的相邻节点,k=2表示目标节点相邻节点的相邻节点。 对于上图中的例子:
- 第一步是采样,k=1采样了3个节点,对k=2采用了5个节点;
- 第二步是聚合邻居节点的信息,获得目标节点的embedding;
- 第三步是使用聚合得到的信息,也就是目标节点的embedding,来预测图中想预测的信息;
GraphSAGE的目标是基于参数h的相邻节点的某种组合来学习每个节点的表示形式。

稍微回顾下,Graph中的每个节点都可以拥有自己的特征向量,该特征向量由X节点特征得到。现在让我们假设每个节点的所有特征向量都具有相同的大小。一层GraphSAGE可以运行k次迭代-因此,每k次迭代,每个节点都有一个节点表示h。
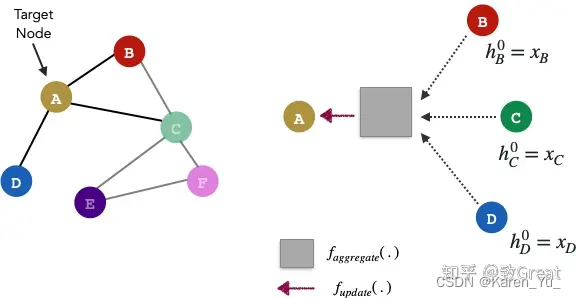
因为每个节点都可以由它们的邻居近似表示,所以节点的嵌入可以用其邻近节点嵌入向量的某种组合来表示。 通过一轮GraphSAGE算法,我们将获得节点A的新表示形式。原始图中的所有节点都遵循相同的过程。
步骤1 Aggregate

aggregator 的作用是把一个向量的集合转换成向量,也就是聚合。和其他机器学习任务中的数据(如图像,文本等)不同,图中的节点是没有顺序的(node’s neighbors have no natural ordering),aggregator function操作的是一个无序的向量集合。其中
代表了节点v的邻居节点集合。 这篇文章尝试了多种aggregator function:

- Mean aggregator:显然对向量集合,对应元素取均值是最直接的想法。
- LSTM aggregator:和mean aggregator相比,LSTM有更大的表达能力。但是LSTM不符合symmetric的性质,输入是有顺序的。所以把相邻节点的向量集合随机打乱顺序,然后作为LSTM的输入。
- Pooling aggregator:尝试了pooling做aggregator, 所有相邻节点的向量共享权重,先经过一个非线性全连接层,然后做max-pooling.
GraphSAGE算法遵循两步过程。由于它是迭代的,因此存在一个初始化步骤,该步骤将所有初始节点嵌入向量设置为其特征向量。(k从1…K开始迭代)

步骤2 Update
在基于节点v的邻居获得聚合表示后,请使用其先前表示和聚合表示的组合来更新当前节点v。该f_update功能为任何可微函数,可以再次,是一样简单的平均函数,或复杂如神经网络。
根据节点v的邻域聚合表示和节点v的先前表示,为节点v创建更新的表示:

(讲道理,读到这里觉得有一个问题,按照这么划分,那么应该是三个步骤,第一步不应该是做sample吗?然后又有了一个新问题,这里的sample是一旦指定就固定了还是每次迭代都要重新sample呢?我倾向于会随机sample,毕竟输入可能是没有顺序的。
源码中写的是“Assumes that adj lists are padded with random re-sampling”所以我也更倾向于自己的理解,求同存异吧)

GraphSAGE:我寻思GCN也没我牛逼 - 知乎
去学习一个节点的信息是怎么通过其邻居节点的特征聚合而来的。 学习到了这样的“聚合函数”,而我们本身就已知各个节点的特征和邻居关系,我们就可以很方便地得到一个新节点的表示了。
GCN等transductive的方法,学到的是每个节点的一个唯一确定的embedding; 而GraphSAGE方法学到的node embedding,是根据node的邻居关系的变化而变化的,也就是说,即使是旧的node,如果建立了一些新的link,那么其对应的embedding也会变化,而且也很方便地学到。
假设我们要聚合K次,则需要有K个聚合函数(aggregator),可以认为是N层。 每一次聚合,都是把上一层得到的各个node的特征聚合一次,在假设该node自己在上一层的特征,得到该层的特征。如此反复聚合K次,得到该node最后的特征。 最下面一层的node特征就是输入的node features。
(好图)
(好图*2)
设置一个定值,每次选择邻居的时候就是从周围的直接邻居(一阶邻居)中均匀地采样固定个数个邻居。虽然在聚合时仅仅聚合了一个节点邻居的信息,但该节点的邻居,也聚合了其邻居的信息,这样,在下一次聚合时,该节点就会接收到其邻居的邻居的信息,也就是聚合到了二阶邻居的信息了。
在GraphSAGE的实践中,作者发现,K不必取很大的值,当K=2时,效果就灰常好了,也就是只用扩展到2阶邻居即可。至于邻居的个数,文中提到S1×S2<=500,即两次扩展的邻居数之际小于500,大约每次只需要扩展20来个邻居即可。
(这篇文章的评论区也很值得看,请移步原文)
其他:
【Graph Neural Network】GraphSAGE: 算法原理,实现和应用 - 知乎
[论文笔记]:GraphSAGE:Inductive Representation Learning on Large Graphs 论文详解 NIPS 2017_graphsage: inductive graph representation learning-CSDN博客