1.遵守法律法规
爬虫在获取网页数据时,需要遵守以下几点,以确保不违反法律法规:
-
不得侵犯网站的知识产权:爬虫不得未经授权,获取和复制网站的内容,这包括文本、图片、音频、视频等。
-
不得违反网站的使用条款:爬虫在获取网页数据时,需要仔细阅读网站的使用条款和隐私政策,确保不违反其中的规定。
-
不得干扰网站的正常运行:爬虫不得对网站的服务器、网络带宽等资源造成过大的负荷,以免影响网站的正常运行。
-
不得抓取敏感信息:爬虫不得抓取涉及政治、宗教、色情等敏感话题的内容,以免触犯相关法律法规。
-
建立反爬虫机制:网站可以采取反爬虫措施,如设置防爬虫规则、验证码等,爬虫需要根据这些规则进行调整,以确保不被网站封禁。
总之,爬虫需要遵守相关法律法规和网站的使用条款,合理抓取数据,避免侵犯网站的知识产权和干扰网站的正常运行,以确保爬虫的合法性和可持续性。
2.爬虫的概念
爬虫是一种自动地获取网页数据并存储到本地的程序。它的主要作用是获取网站上的数据,这些数据可以用于分析、研究、开发等多种目的。爬虫可以帮助我们获取网站上的数据,而不需要人工浏览和抓取。爬虫的分类主要有通用爬虫和聚焦爬虫。通用爬虫是指搜索引擎和大型web服务提供商的爬虫,它们抓取的是一整张页面数据。聚焦爬虫是针对特定网站的爬虫,它们定向的获取某方面数据的爬虫。
3.爬虫应用场景
爬虫的应用场景非常广泛,主要包括以下几个方面:
- 数据分析和研究:爬虫可以获取网站上的数据,然后进行分析和研究,从而获取有价值的信息。
- 新闻聚合:爬虫可以抓取多个网站上的新闻内容,并将其整合到一个地方,方便用户查看。
- 电子商务:爬虫可以抓取网站上的商品信息,并将其整理成报表,方便商家分析和决策。
- 数据挖掘:爬虫可以抓取网站上的数据,并将其转换成机器可以理解的格式,从而进行数据挖掘和分析。
4.爬虫的工作原理和流程
- 确定爬虫的目标网站和需要抓取的数据。
- 编写爬虫的代码,包括爬虫的起始地址、结束地址、请求头、爬取的数据类型等。
- 运行爬虫程序,将爬虫代码发送到目标网站。
- 目标网站返回响应数据,爬虫程序将其存储到本地。
- 爬虫程序对存储的数据进行处理和分析,得到需要的数据。
- 爬虫程序重复以上步骤,直到爬虫的目标数据被抓取完毕。
举例来说,我们可以使用Python编写一个爬虫程序,用于抓取一个电子商务网站上的商品信息。我们可以使用requests库发送HTTP请求,使用BeautifulSoup库解析HTML响应,然后将抓取的数据存储到本地。这个爬虫程序可以定期运行,从而获取该网站上的商品信息。这些商品信息可以用于分析和研究,从而帮助商家做出更好的决策。
5.爬取网页
想要爬取网页的内容,首先我们需要审查页面元素。以我的博客 陆理手记 为例,如果想要抓取Python教程分类下所有的文章标题,我们可以先进入分类页进行审查页面元素。

判断网页可抓取后,可以使用之前教程 Python基础教程:requests模块发送http请求 | 陆理手记) 提到过的requests模块进行网页请求,请求到网页内容后,再对内容进行解析,提取我们所需要的数据,这里用到的就是BeautifulSoup模块。
6.BeautifulSoup模块应用
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库,它能够通过你喜欢的转换器实现惯用的文档导,可以通过标签名、属性或文本内容搜索和修改网页内容,使用 BeautifulSoup,可以轻松地从复杂的 HTML 或 XML 文档中提取信息,并将其用于 Python 程序中。

下面我们举个简单的例子,以抓取我的博客 陆理手记 中Python分类的文章标题为例
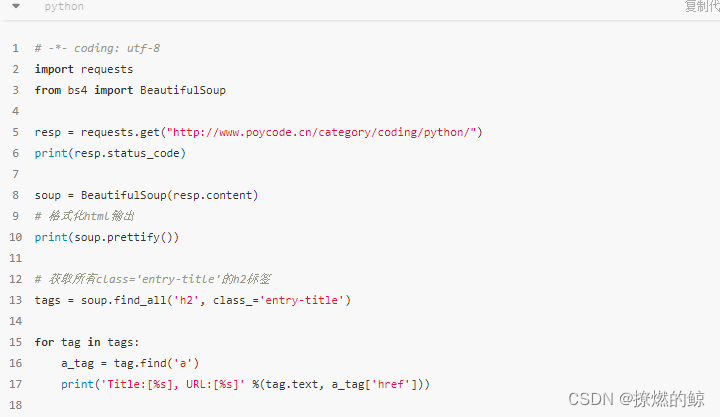
输出结果:

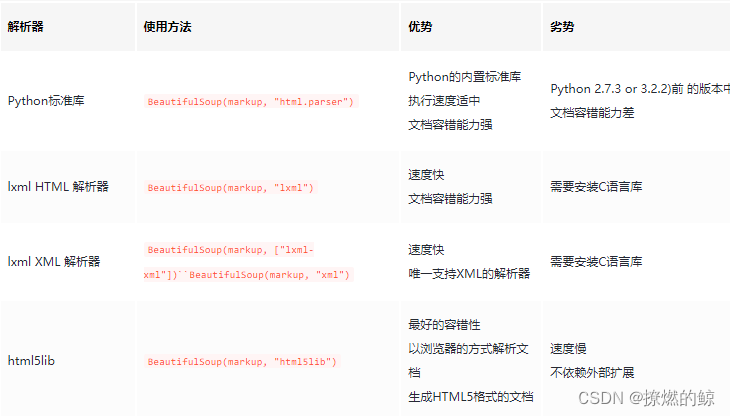
上述代码中,首先通过requests库请求python教程的分类页面,获取到整个html文档。然后我们使用BeautifulSoup(html, features='html.parser')解析该html文档,便能获取到一个BeautifulSoup对象。features是解析器,有如下几种,这里我们使用Python内置的标准库。
soup_html.find_all('h2', class_='entry-title')是查找html文档中所有的 class='entry-title' 的 h2 标签,BeautifulSoup提供了许多方便快捷强大的标签搜索功能,这里就不一一介绍,原因是我认为:Beautiful Soup 中文文档 已经写的非常详细,如果你需要进行爬虫相关的编程,查阅也是非常方便的。
7.总结
本文简单介绍了爬虫的基础知识以及需要用的库和方法,并做了非常简单的示例。总地来说,爬虫就是模拟网络请求,并解析、提取出我们想要的数据。爬虫可以帮助我们更快地获取网站上的数据,为工作和生活带来诸多便利。当然,也希望在学习 python 爬虫的过程中,大家能够更好的理解和应用 python的语法。