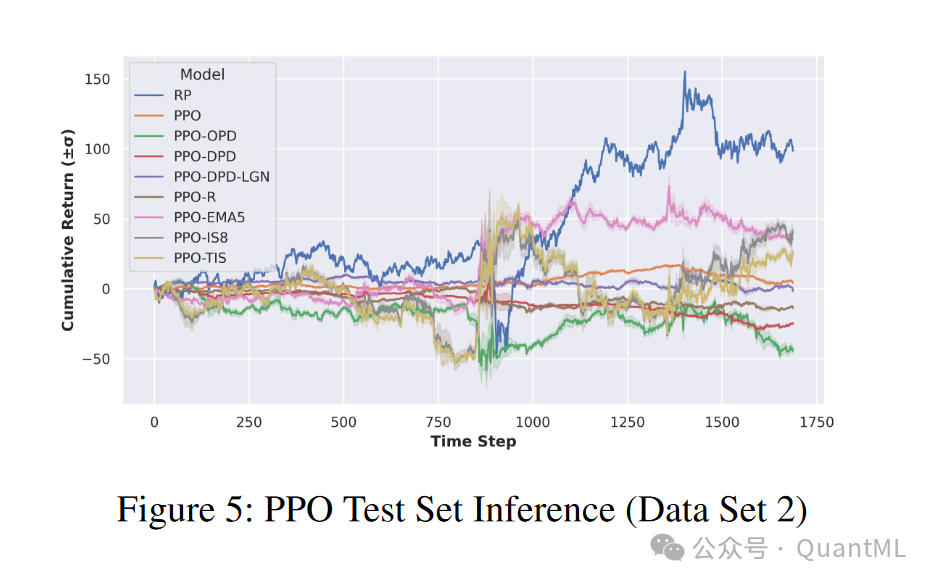
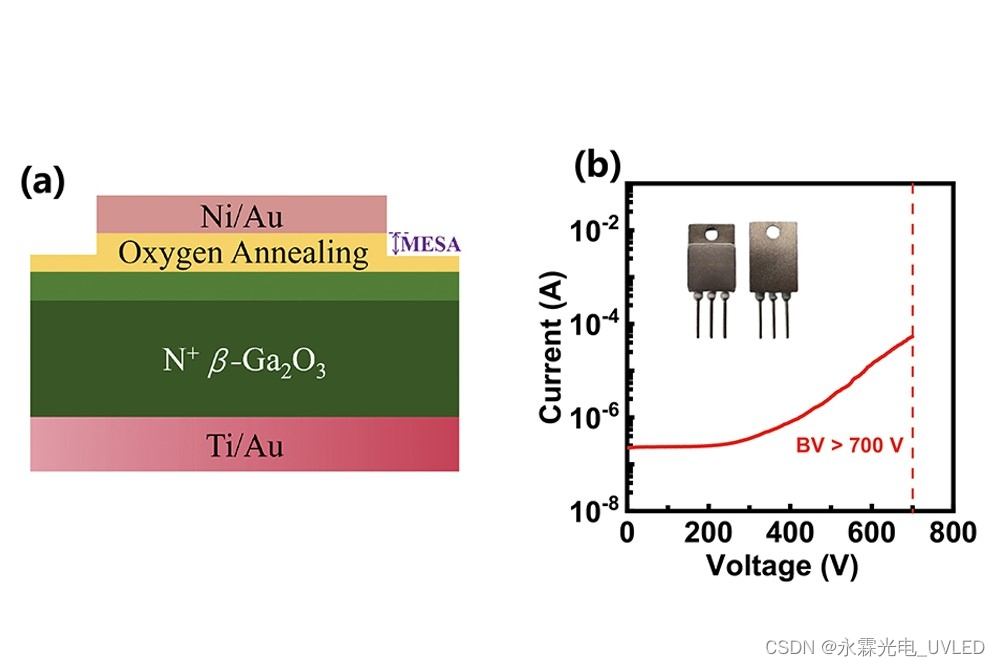
本文首发于公众号:机器感知
PTQ4SAM、Mamba-Attention、AniTalker、IceFormer、U-DiTs、CogDPM

PTQ4SAM: Post-Training Quantization for Segment Anything

Segment Anything Model (SAM) has achieved impressive performance in many computer vision tasks. However, as a large-scale model, the immense memory and computation costs hinder its practical deployment. In this paper, we propose a post-training quantization (PTQ) framework for Segment Anything Model, namely PTQ4SAM. First, we investigate the inherent bottleneck of SAM quantization attributed to the bimodal distribution in post-Key-Linear activations. We analyze its characteristics from both per-tensor and per-channel perspectives, and propose a Bimodal Integration strategy, which utilizes a mathematically equivalent sign operation to transform the bimodal distribution into a relatively easy-quantized normal distribution offline. Second, SAM encompasses diverse attention mechanisms (i.e., self-attention and two-way cross-attention), resulting in substantial variations in the post-Softmax distributions. Therefore, we introduce an Adaptive Granularity Quantization for Softmax th......
AniTalker: Animate Vivid and Diverse Talking Faces through Identity-Decoupled Facial Motion Encoding

The paper introduces AniTalker, an innovative framework designed to generate lifelike talking faces from a single portrait. Unlike existing models that primarily focus on verbal cues such as lip synchronization and fail to capture the complex dynamics of facial expressions and nonverbal cues, AniTalker employs a universal motion representation. This innovative representation effectively captures a wide range of facial dynamics, including subtle expressions and head movements. AniTalker enhances motion depiction through two self-supervised learning strategies: the first involves reconstructing target video frames from source frames within the same identity to learn subtle motion representations, and the second develops an identity encoder using metric learning while actively minimizing mutual information between the identity and motion encoders. This approach ensures that the motion representation is dynamic and devoid of identity-specific details, significantly reducing the n......
Matten: Video Generation with Mamba-Attention

In this paper, we introduce Matten, a cutting-edge latent diffusion model with Mamba-Attention architecture for video generation. With minimal computational cost, Matten employs spatial-temporal attention for local video content modeling and bidirectional Mamba for global video content modeling. Our comprehensive experimental evaluation demonstrates that Matten has competitive performance with the current Transformer-based and GAN-based models in benchmark performance, achieving superior FVD scores and efficiency. Additionally, we observe a direct positive correlation between the complexity of our designed model and the improvement in video quality, indicating the excellent scalability of Matten. ......
SMCD: High Realism Motion Style Transfer via Mamba-based Diffusion
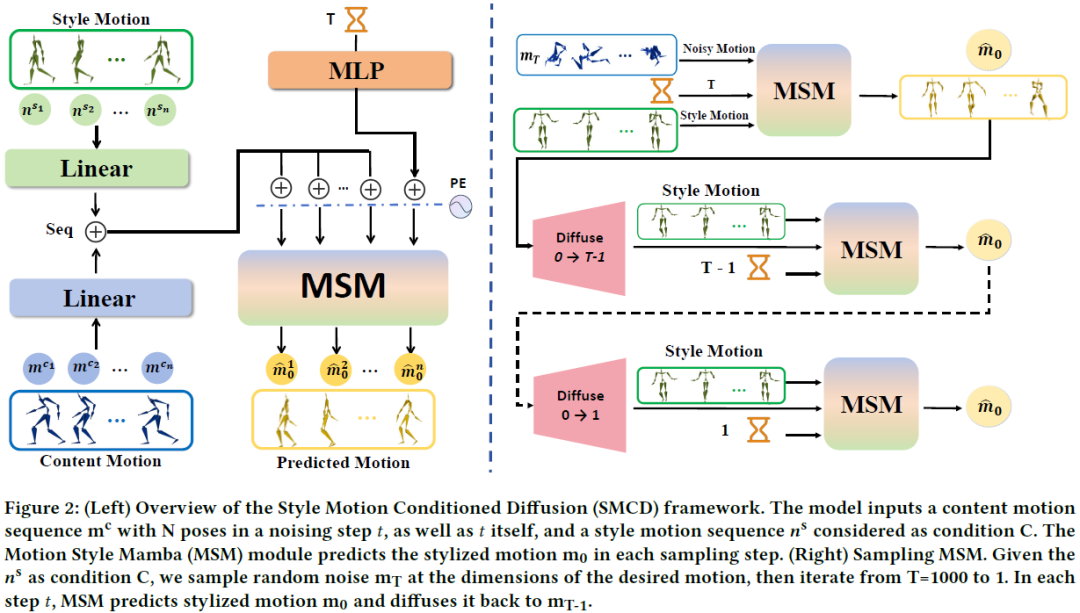
Motion style transfer is a significant research direction in multimedia applications. It enables the rapid switching of different styles of the same motion for virtual digital humans, thus vastly increasing the diversity and realism of movements. It is widely applied in multimedia scenarios such as movies, games, and the Metaverse. However, most of the current work in this field adopts the GAN, which may lead to instability and convergence issues, making the final generated motion sequence somewhat chaotic and unable to reflect a highly realistic and natural style. To address these problems, we consider style motion as a condition and propose the Style Motion Conditioned Diffusion (SMCD) framework for the first time, which can more comprehensively learn the style features of motion. Moreover, we apply Mamba model for the first time in the motion style transfer field, introducing the Motion Style Mamba (MSM) module to handle longer motion sequences. Thirdly, aiming at the SMCD......
IceFormer: Accelerated Inference with Long-Sequence Transformers on CPUs
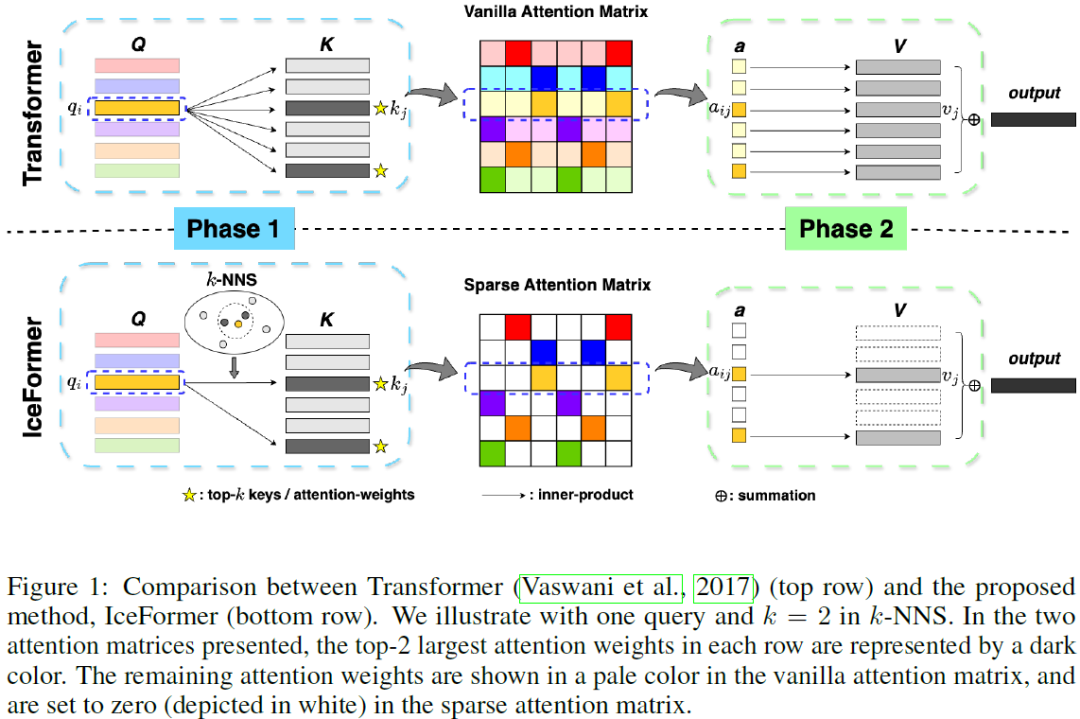
One limitation of existing Transformer-based models is that they cannot handle very long sequences as input since their self-attention operations exhibit quadratic time and space complexity. This problem becomes especially acute when Transformers are deployed on hardware platforms equipped only with CPUs. To address this issue, we propose a novel method for accelerating self-attention at inference time that works with pretrained Transformer models out-of-the-box without requiring retraining. We experiment using our method to accelerate various long-sequence Transformers, including a leading LLaMA 2-based LLM, on various benchmarks and demonstrate a greater speedup of 2.73x - 7.63x while retaining 98.6% - 99.6% of the accuracy of the original pretrained models. The code is available on our project website at https://yuzhenmao.github.io/IceFormer/. ......
Efficient Text-driven Motion Generation via Latent Consistency Training
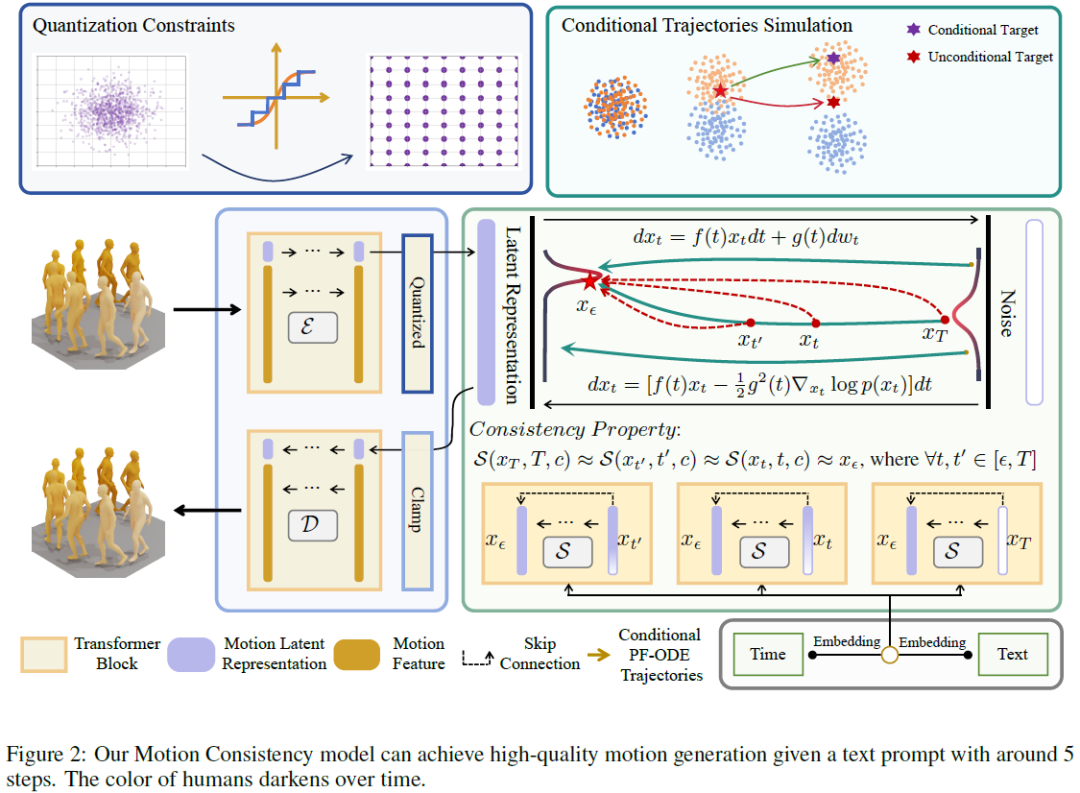
Motion diffusion models have recently proven successful for text-driven human motion generation. Despite their excellent generation performance, they are challenging to infer in real time due to the multi-step sampling mechanism that involves tens or hundreds of repeat function evaluation iterations. To this end, we investigate a motion latent consistency Training (MLCT) for motion generation to alleviate the computation and time consumption during iteration inference. It applies diffusion pipelines to low-dimensional motion latent spaces to mitigate the computational burden of each function evaluation. Explaining the diffusion process with probabilistic flow ordinary differential equation (PF-ODE) theory, the MLCT allows extremely few steps infer between the prior distribution to the motion latent representation distribution via maintaining consistency of the outputs over the trajectory of PF-ODE. Especially, we introduce a quantization constraint to optimize motion latent r......
U-DiTs: Downsample Tokens in U-Shaped Diffusion Transformers
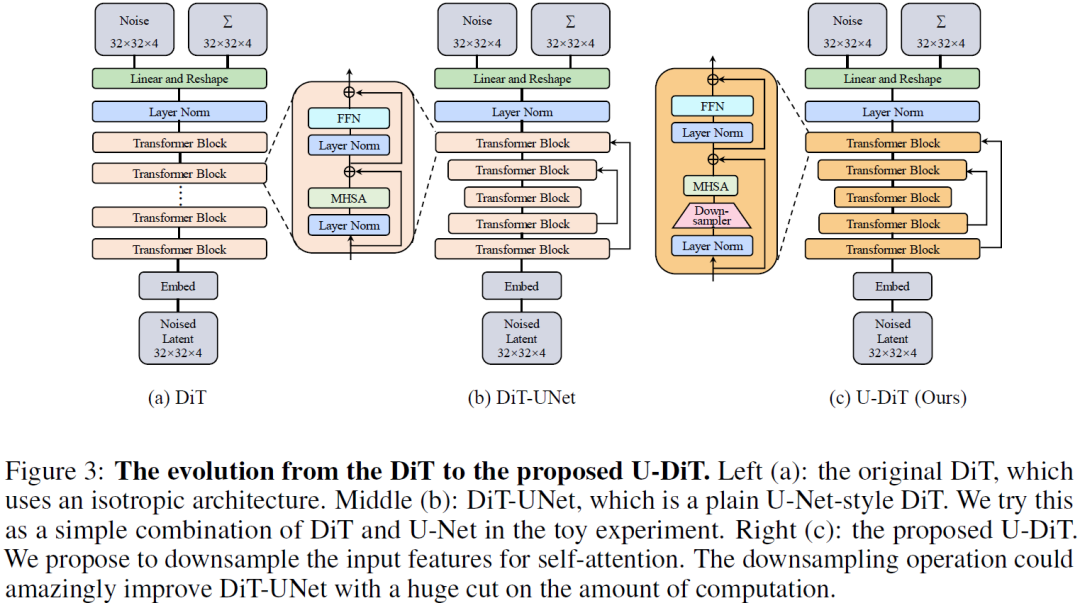
Diffusion Transformers (DiTs) introduce the transformer architecture to diffusion tasks for latent-space image generation. With an isotropic architecture that chains a series of transformer blocks, DiTs demonstrate competitive performance and good scalability; but meanwhile, the abandonment of U-Net by DiTs and their following improvements is worth rethinking. To this end, we conduct a simple toy experiment by comparing a U-Net architectured DiT with an isotropic one. It turns out that the U-Net architecture only gain a slight advantage amid the U-Net inductive bias, indicating potential redundancies within the U-Net-style DiT. Inspired by the discovery that U-Net backbone features are low-frequency-dominated, we perform token downsampling on the query-key-value tuple for self-attention and bring further improvements despite a considerable amount of reduction in computation. Based on self-attention with downsampled tokens, we propose a series of U-shaped DiTs (U-DiTs) in the ......
From Generalization Analysis to Optimization Designs for State Space Models
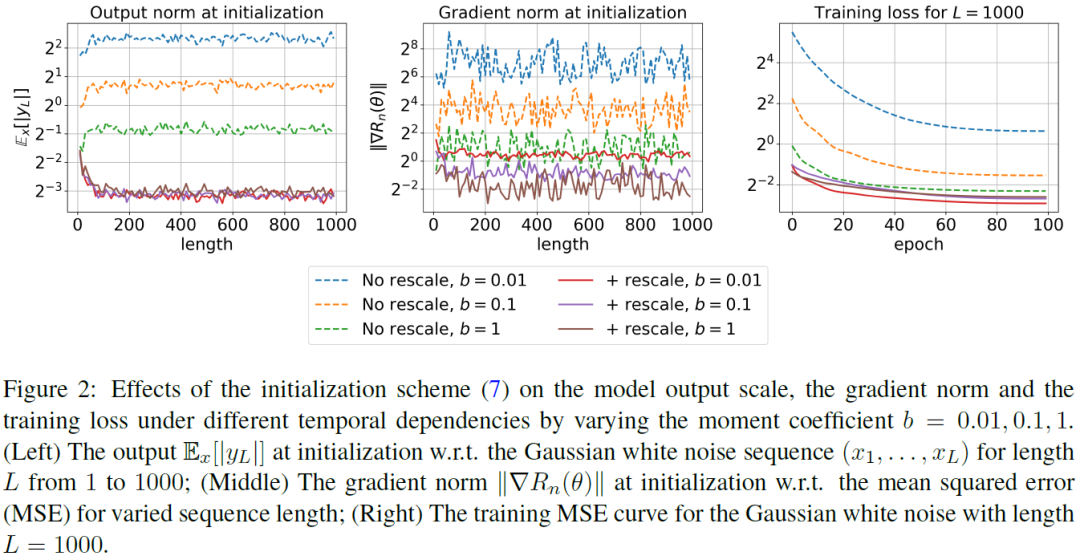
A State Space Model (SSM) is a foundation model in time series analysis, which has recently been shown as an alternative to transformers in sequence modeling. In this paper, we theoretically study the generalization of SSMs and propose improvements to training algorithms based on the generalization results. Specifically, we give a \textit{data-dependent} generalization bound for SSMs, showing an interplay between the SSM parameters and the temporal dependencies of the training sequences. Leveraging the generalization bound, we (1) set up a scaling rule for model initialization based on the proposed generalization measure, which significantly improves the robustness of the output value scales on SSMs to different temporal patterns in the sequence data; (2) introduce a new regularization method for training SSMs to enhance the generalization performance. Numerical results are conducted to validate our results. ......
CogDPM: Diffusion Probabilistic Models via Cognitive Predictive Coding
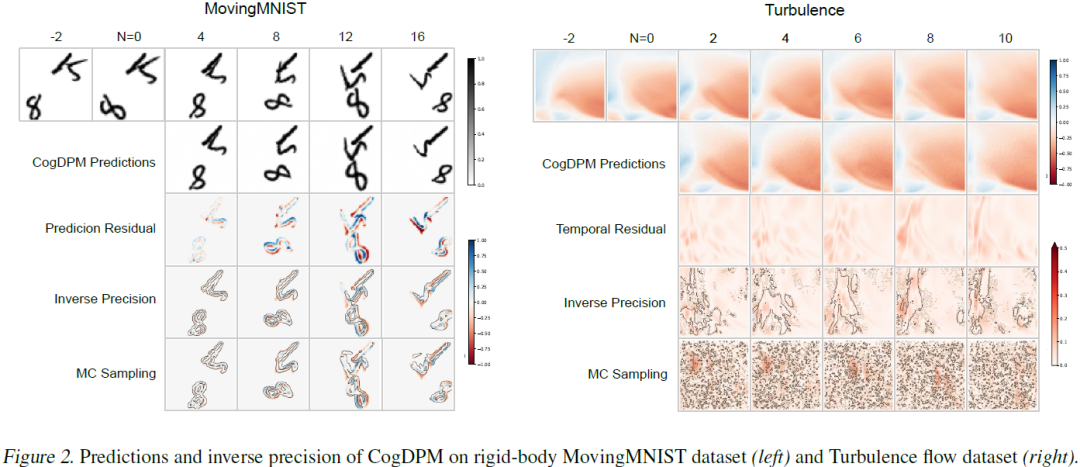
Predictive Coding (PC) is a theoretical framework in cognitive science suggesting that the human brain processes cognition through spatiotemporal prediction of the visual world. Existing studies have developed spatiotemporal prediction neural networks based on the PC theory, emulating its two core mechanisms: Correcting predictions from residuals and hierarchical learning. However, these models do not show the enhancement of prediction skills on real-world forecasting tasks and ignore the Precision Weighting mechanism of PC theory. The precision weighting mechanism posits that the brain allocates more attention to signals with lower precision, contributing to the cognitive ability of human brains. This work introduces the Cognitive Diffusion Probabilistic Models (CogDPM), which demonstrate the connection between diffusion probabilistic models and PC theory. CogDPM features a precision estimation method based on the hierarchical sampling capabilities of diffusion models and we......