在深度学习中不同的optimizer 通常会选择不同 优化策略 lr_sheduler 与之搭配;
1. SGD 与 Adam 优化器
Adam 与经典 SGD 的不同之处在于,
- Adam 执行局部参数更新(即在参数级别进行更改),而不是全局执行此操作的 SGD,
- 以及 它执行一些动量-类似的优化与经典 SGD 的无动量相反。
2. 学习率退火 annealing 方式
火,特别是在优化深度学习模型的背景下,是指在训练过程中逐渐降低学习率的技术。这个过程通常称为“学习率退火”或“学习率衰减”,对于帮助模型在训练结束时更有效地收敛至关重要。
“退火”一词源自冶金学,它描述了加热然后缓慢冷却以消除内应力并使材料增韧的过程。
通过逐渐降低学习率,您可以让模型对权重进行更小、更精确的调整。这增加了在损失情况中收敛到更好且可能更深的最小值的可能性。
在 PyTorch 中使用 StepLR 或 ExponentialLR 等学习率调度程序可以灵活有效地控制学习率随时间的变化,这对于有效训练深度神经网络至关重要。根据验证性能调整这些参数以获得最佳结果。
2.1 Step Decay: .
步骤衰减:每隔几个时期定期将学习率降低固定因子。这是一种简单且广泛使用的方法。
2.2 Exponential Decay
指数衰减:每个时期持续将学习率降低一个小因子,这会导致学习率随着时间的推移呈指数下降。
2.3 Linear or Polynomial Decay
线性或多项式衰减:随时间线性或根据多项式函数降低学习率。
2.4 Cosine Annealing
余弦退火:根据余弦函数调整学习率,在可能重新启动循环之前逐渐将其降低到最小值,这种技术称为热重启余弦退火。
2.5 各类学习率退火的 对比
步进与指数衰减:步进衰减降低了大的离散跳跃的学习率,这可以更容易配置并且行为更可预测。相比之下,指数衰减会逐渐且连续地改变学习率,这有助于保持更稳定的收敛,尤其是在训练的后期阶段。
线性/多项式与余弦退火:线性或多项式衰减提供了学习率的可预测、稳定的变化,可以调整为更积极或温和地降低。余弦退火以非线性方式降低学习率,这可以更好地探索损失景观并有可能避免局部最小值。
3. cycle 类型学习率退火算法
3.1 梯度型 学习率更新
先从 base_lr —> max_lr ----> base_lr ,
学习率先上升 —》 维持一定的epoch 数目 ----》 最后的阶段下降为 base_lr学习率;
下图中有错误, base_lr , max_lr 这两个学习率的位置应该互换。
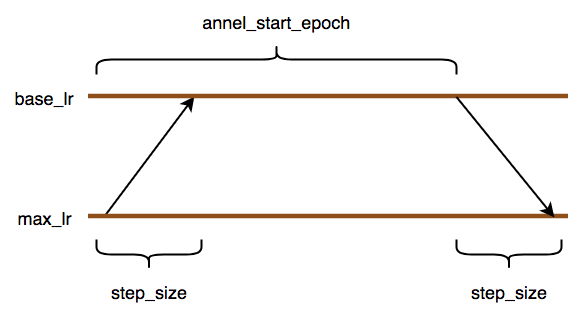
根据您提供的图像(该图像说明了梯形学习率计划),我将调整之前提供的 PyTorch 代码。该计划从基本学习率 ( base_lr ) 开始,在一定数量的 epoch ( step_size ) 内线性增加到最大学习率 ( max_lr ),保持一段时间内的最大学习率 ( anneal_start_epoch - 2 * step_size ),然后在相同数量的 epoch 内线性降低回基本学习率 ( step_size
下面是梯形学习率调度程序的调整后的 PyTorch 代码,考虑到了图表
import torch
from torch.optim.lr_scheduler import _LRSchedulerclass TrapezoidalLR(_LRScheduler):def __init__(self, optimizer, base_lr, max_lr, step_size, anneal_start_epoch, last_epoch=-1):self.base_lr = base_lrself.max_lr = max_lrself.step_size = step_sizeself.anneal_start_epoch = anneal_start_epochself.ramp_down_start_epoch = anneal_start_epoch + step_sizesuper(TrapezoidalLR, self).__init__(optimizer, last_epoch)def get_lr(self):if self.last_epoch < self.step_size:# Ramp up phaselr = [self.base_lr + (self.max_lr - self.base_lr) * (self.last_epoch / self.step_size) for base_lr in self.base_lrs]elif self.last_epoch < self.anneal_start_epoch:# Hold phaselr = [self.max_lr for _ in self.base_lrs]elif self.last_epoch < self.ramp_down_start_epoch:# Ramp down phaseprogress = (self.last_epoch - self.anneal_start_epoch) / self.step_sizelr = [self.max_lr - (self.max_lr - self.base_lr) * progress for base_lr in self.base_lrs]else:# After traininglr = [self.base_lr for _ in self.base_lrs]return lr# Example usage
model = ... # Define your model
optimizer = torch.optim.SGD(model.parameters(), lr=0.001) # Initial LR is overridden by scheduler# Define the total epochs based on your training plan
total_epochs = anneal_start_epoch + step_size
scheduler = TrapezoidalLR(optimizer, base_lr=0.001, max_lr=0.006, step_size=5, anneal_start_epoch=10)# Training loop
for epoch in range(total_epochs):scheduler.step(epoch)for input, target in train_loader:optimizer.zero_grad()output = model(input)loss = criterion(output, target)loss.backward()optimizer.step()print(f'Epoch: {epoch+1}, LR: {scheduler.get_lr()[0]}')确保正确定义模型和数据加载器,并在训练循环中设置正确的损失函数。根据您的特定用例的需要调整 base_lr 、 max_lr 、 step_size 和 anneal_start_epoch 。此代码假设时期总数将是 step_size 、 anneal_start_epoch 和另一个 step_size 的总和,以匹配如图所示的梯形时间表。
3.2 oneCycleLR
先上升后下降,
PyTorch 中的 OneCycleLR 调度器是学习率调度器 API 的一部分,它根据 1cycle 学习率策略调整学习率,该策略由 Leslie N. Smith 在题为“Super-Convergence: Very”的论文中提出使用大学习率快速训练神经网络”。 1cycle 策略是循环学习率 (CLR) 计划的一种形式,由两个主要阶段组成:
-
学习率从下限( base_lr 或 initial_lr )增加到上限( max_lr )的初始阶段。
-
第二阶段,学习率从上限( max_lr )下降到下限( base_lr 或 final_lr ),甚至进一步下降到非常小的值( base_lr 的 final_div_factor )。
此外, OneCycleLR 调度程序可以调整学习率的动量,这被认为有助于优化过程。
以下是 OneCycleLR 调度程序的工作原理及其关键参数:
Working Mechanism:
第 1 阶段 - 学习率退火(向上):学习率线性增加或使用自定义退火函数从 base_lr 到 max_lr 。此阶段允许优化器探索损失情况并对模型的权重进行重大更改。
第 2 阶段 - 学习率退火(向下):学习率随后降低,通常遵循余弦退火计划,从 max_lr 降低到非常小的值。此阶段有助于模型收敛到良好的解决方案。
动量调整(可选):如果使用动量,它通常会向与学习率相反的方向调整;
当学习率增加时减少,当学习率减少时增加。
Key Parameters:
- optimizer :调整学习率的优化器。
- max_lr :每个参数组循环中的学习率上限。
total_steps :循环中的总步数。请注意,如果您不指定此项,则必须指定 epochs 和 steps_per_epoch 。
epochs :训练的纪元数。如果未提供 total_steps ,则与 steps_per_epoch 一起使用来推断循环中的总步数。
steps_per_epoch :每个时期训练的步骤数(样本批次)。如果未提供 total_steps ,则与 epochs 一起使用来推断循环中的总步数。
pct_start :用于提高学习率的周期百分比(以总步数计)。
anneal_strategy :学习率和可选动量的退火策略。对于余弦退火方案,它可以是“cos”,对于线性方案,它可以是“线性”。
base_lr :初始学习率,是每个参数组循环的下限。
final_div_factor :通过 base_lr / final_div_factor 确定最小学习率。
div_factor :通过 max_lr / div_factor 确定初始学习率。
three_phase :如果为 True,它会在学习率从 base_lr / div_factor 到 base_lr / < 的末尾添加一个额外的步骤b4> 占总步数的一小部分。
import torch
import torch.optim as optim
from torch.optim.lr_scheduler import OneCycleLRmodel = ... # your model
optimizer = optim.SGD(model.parameters(), lr=0.1)
scheduler = OneCycleLR(optimizer, max_lr=1.0, steps_per_epoch=len(train_loader), epochs=num_epochs, anneal_strategy='cos')for epoch in range(num_epochs):for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# Step through the scheduler after each optimizer updatescheduler.step()
When using OneCycleLR, it's crucial to ensure that the scheduler is stepped after each batch rather than each epoch since the learning rate needs to adjust after each optimizer update. This technique is known for helping to train models quickly and efficiently, and for achieving better generalization.
使用 OneCycleLR 时,确保调度程序在每个批次而不是每个时期之后步进至关重要,因为学习率需要在每次优化器更新后进行调整。该技术因有助于快速有效地训练模型并实现更好的泛化而闻名。
reference
- https://github.com/bckenstler/CLR/issues/19;
- https://github.com/daisukelab/TrapezoidalLR






![[Linux][多线程][三][条件变量][生产者消费者模型][基于BlockingQueue的生产者消费者模型]详细讲解](https://img-blog.csdnimg.cn/direct/6946fbf64de24dbb919c3460ec3df87c.png)