一、简述
本文的目标是了解自然语言处理 (NLP) 的历史,包括 Transformer 体系结构如何彻底改变该领域并帮助我们创建大型语言模型 (LLM)。
基础模型(如 GPT-4)是最先进的自然语言处理模型,旨在理解、生成人类语言并与之交互。 要理解基础模型的重要性,有必要探索它们的起源,它们源于人工智能和自然语言处理领域的进步。
自然语言处理 (NLP) 是一种专注于理解、解释和生成人类语言的 AI。 一些常见 NLP 用例包括:

语音转文本和文本转语音的转换。 例如,生成视频字幕。
机器翻译。 例如,将文本从英语翻译为日语。
文本分类。 例如,将电子邮件标记为垃圾邮件或非垃圾邮件。
实体提取。 例如,从文档中提取关键字或名称。
问题解答。 例如,提供“法国的首都是哪里?”等问题的答案
文本摘要。 例如,根据多页文档生成一个简短的单段摘要。
从历史上看,NLP 一直具有挑战性,因为我们的语言很复杂,计算机很难理解文本。
二、用于NLP的统计技术
过去几十年,自然语言处理 (NLP) 领域取得了多项技术成果,实现了大型语言模型 (LLM)。为了了解 LLM,我们先来了解过去一段时间内为当前技术做出贡献的 NLP 统计技术。
由于 NLP 侧重于理解和生成文本,因此实现 NLP 时的大多数首次尝试都基于语言固有的规则和结构。 特别是在机器学习技术流行之前,采用的主要方法是结构化模型和形式化语法。
这些方法依赖于语言规则和语法模式的显式编程来处理和生成文本。 尽管这些模型可以合理地处理某些特定语言任务,但在面对自然语言的巨大复杂性和可变性时,它们面临着重大挑战。
20 世纪 90 年代,研究人员开始利用统计和概率模型直接从数据中学习模式和表示形式,而不是硬编码规则。
1、了解分词
如你所料,计算机很难破译文本,因为它们主要依赖于数字。 因此,为了读取文本,我们需要将呈现的文本转换为数字。
使计算机能够更轻松地处理文本的一个重要技术发展是词汇切分。 标记是具有已知含义的字符串,通常表示一个字词。 词汇切分将字词转换为标记,然后再转换为数字。 词汇切分的统计方法是使用管道:

首先选择要标记的文本。 根据规则拆分文本中的字词。 例如,拆分含空格的字词。 词干分解。 通过删除字词的末尾来合并类似字词。 停止字词删除。 删除没有意义的干扰词(如 the 和 a)。 提供了这些字词的字典,以在结构上将它们从文本中删除。 为每个唯一标记分配一个数字。 允许标记文本的词汇切分。 因此,统计技术可用于让计算机在数据中查找模式,而不是应用基于规则的模型。
2、NLP 统计技术
实现 NLP 的两大重要进展都使用了统计技术:Naïve Bayes 和词频–逆向文档频率 (TF-IDF)。
了解 Naïve Bayes
Naïve Bayes 是一项统计技术,最初用于电子邮件筛选。 为了了解垃圾邮件和非垃圾邮件之间的区别,将两个文档进行比较。 Naïve Bayes 分类器标识哪些标记与标记为垃圾邮件的电子邮件相关联。 换句话说,该技术会找出哪组字词仅出现在一种类型的文档中,但未出现在另一种类型的文档中。 字词组通常称为词袋功能。
例如,与常规电子邮件相比,有关可疑健康产品的垃圾邮件中 miracle cure、lose weight fast 和 anti-aging 的出现频率可能更高。
虽然现已证实 Naïve Bayes 比简单的基于规则的文本分类模型更有效,但它仍然相对简单,因为只考虑了字词或标记是否存在,但没有考虑位置。
了解 TF-IDF
词频–逆向文档频率 (TF-IDF) 技术具有类似的方法,即将一个文档中字词出现的频率与整个文档语料库中字词出现的频率进行比较。 通过了解字词的使用上下文,可以基于某些主题对文档进行分类。 TF-IDF 通常用于信息检索,以帮助了解要搜索的相关字词或标记。
例如,字词 flour 通常出现在包含烘焙食谱的文档中。 如果搜索含 flour 的文档,也可以检索到包含 baking 的文档,因为这些字词经常在文本中一起使用。
事实证明,TF-IDF 对于搜索引擎了解文档与某人的搜索查询的相关性非常有用。 但是,TF-IDF 技术不考虑字词之间的语义关系。 不会检测同义词或具有类似含义的字词。
尽管统计技术是 NLP 领域中宝贵的技术成果,但深度学习技术取得了必要的创新,从而实现了当前拥有的 NLP 水平。
三、用于NLP的深度学习技术
统计技术在文本分类等自然语言处理 (NLP) 任务中表现相对较好。 对于翻译等任务,仍有很大的改进空间。
最近,深度学习技术推动了自然语言处理 (NLP) 领域在翻译等任务方面的发展。
当你要翻译文本时,不应只将每个字词翻译为另一种语言。 你可能还记得多年前的翻译服务,它们翻译的句子过于直白,常常导致有趣的结果。 相反,你希望语言模型能够理解文本的含义(或语义),并使用该信息在目标语言中创建语法正确的句子。
1、了解字词嵌入
将深度学习技术应用于 NLP 时引入的一个关键概念是字词嵌入。 字词嵌入解决了无法定义字词之间的语义关系的问题。
在字词嵌入之前,NLP 的一个普遍挑战是检测字词之间的语义关系。 字词嵌入会表示矢量空间中的字词,以便可以轻松描述和计算字词之间的关系。
字词嵌入是在自我监督学习期间创建的。 在训练过程中,模型会分析句子中字词的共现模式,并学习将它们表示为矢量。 矢量可在多维空间中用坐标表示字词。 然后,可以通过确定相对矢量之间的距离来计算字词之间的距离,并描述字词之间的语义关系。
假设你要使用大量文本数据集训练一个模型。 在训练过程中,该模型发现字词“bike”和“car”通常用于相同的字词模式中。 除了在相同的文本中发现“bike”和“car”之外,你还可以发现它们都用于描述类似的事物。 例如,有人可能会驾驶“bike”或“car”,或者在商店购买“bike”或“car”。
模型了解到,这两个字词通常位于类似的上下文中,于是它会在矢量空间中将 bike 和 car 的字词向量绘制得靠近彼此。
假设我们有一个三维矢量空间,其中每个维度对应一个语义特征。 在本例中,假设维度表示车辆类型、运输方式、活动等因素。 然后,我们可以根据字词的语义关系将假设的矢量分配给字词:

Boat[2, 1, 4] 靠近“drive”和“shop”,表示你可以驾驶船只和游览水域附近的商店。Car[7, 5, 1] 离“bike”比“boat”更近,因为汽车和自行车都用于陆地而不是水上。Bike[6, 8, 0] 在活动维度中更靠近“drive”,在车辆类型维度中靠近“car”。Drive[8, 4, 3] 靠近“boat”、“car”、“bike”,但远离“shop”,因为它描述的是不同类型的活动。Shop[1, 3, 5] 离“bike”最近,因为这些字词最常一起使用。
尽管字词嵌入是检测字词之间的语义关系的一种很好的方法,但它仍然存在问题。 例如,具有不同意向的字词(如 love 和 hate)通常会显示为相关,因为它们用于类似的上下文中。 另一个问题是,模型对每个字词只使用一个条目,导致具有不同含义的字词(例如 bank)会在语义上与大量字词相关。
2、将记忆添加到 NLP 模型
理解文本不仅仅是理解单独呈现的单个字词。 字词的含义可能有所不同,具体取决于它们所处的上下文。 换句话说,字词周围的句子会影响字词的含义。
使用 RNN 包含字词的上下文
在深度学习之前,包含字词的上下文是一项过于复杂且成本高昂的任务。 在包含上下文方面的第一个突破是循环神经网络 (RNN)。
RNN 由多个连续步骤组成。 每个步骤可接受一个输入和一个隐藏状态。 假设每个步骤中的输入是一个新字词。 每个步骤还会生成一个输出。 隐藏状态可用作网络的记忆,用于存储上一步的输出并将其作为输入传递给下一步。
假设有一个句子是这样的:
Vincent Van Gogh was a painter most known for creating stunning and emotionally expressive artworks, including ...
要知道下一个词是什么,你需要记住画家的名字。 该句子需要补全,因为最后一个词是缺失的。 NLP 任务中缺失或掩盖的字词通常用 [MASK] 表示。 通过在句子中使用特殊的 [MASK] 标记,可以让语言模型知道它需要预测缺失的标记或值是什么。
简化示例句子后,可以为 RNN 提供以下输入:Vincent was a painter known for [MASK]:

RNN 将每个标记作为输入,对其进行处理,并使用该标记的记忆更新隐藏状态。 将下一个标记作为新输入进行处理时,将更新上一步中的隐藏状态。
最终,最后一个标记作为输入传递给模型,即 [MASK] 标记。 指示缺少信息,并且模型需要预测其值。 然后,RNN 会使用隐藏状态来预测出输出应类似于 Starry Night

在示例中,隐藏状态包含信息 Vincent、is、painter、know。 使用 RNN 时,每个标记在隐藏状态下都同等重要,因此在预测输出时它们会得到同等的考量。
RNN 使得在解读字词相对于完整句子的含义时能够包含上下文。 但是,随着 RNN 的隐藏状态随每个标记而更新,实际的相关信息(或信号)可能会丢失。
在提供的示例中,文森特·梵高的名字在句子的开头,而掩码在末尾。 在最后一步,当掩码作为输入传递时,隐藏状态可能包含大量与预测掩码的输出无关的信息。 由于隐藏状态的大小有限,相关信息甚至可能会被删除,以便为新的和更近期的信息腾出空间。
当我们读到这句话时,我们知道只有某些字词对于预测最后一个字词是必不可少的。 但是,RNN 会包含处于隐藏状态的所有(相关和不相关的)信息。 因此,相关信息可能会在隐藏状态下成为弱信号,这意味着它可能会被忽略,因为有太多其他无关的信息在影响着模型。
通过长短期记忆改进 RNN
针对 RNN 的弱信号问题的一个解决方案是一种更新型的 RNN:长短期记忆 (LSTM)。 LSTM 能够通过维护在每步中更新的隐藏状态来处理序列数据。 使用 LSTM 时,模型可以决定要记住的内容和要忘记的内容。 这样一来,可以跳过不相关或不提供重要信息的上下文,并且可以将重要信号保存更长时间。
四、用于NLP的Transformer结构
自然语言处理 (NLP) 的突破归功于 Transformer 体系结构的开发。 Transformer 是在 2017 年 Vaswani 等人撰写的《Attention is all you need》(注意力是你所需要的一切)论文中引入的。 Transformer 体系结构提供了递归神经网络 (RNNS) 执行 NLP 的替代方法。 RNN 按顺序处理字词,因此是计算密集型的,而 Transformer 不按顺序处理字词,而是使用注意力 (attention) 独立地并行处理每个字词。 字词的位置和在句子中的顺序对于理解文本含义来说很重要。 为了包含此信息而不必按顺序处理文本,Transformer 使用了位置编码。
1、了解位置编码
在 Transformer 推出之前,语言模型使用词嵌入来将文本编码为向量。 在 Transformer 体系结构中,使用了位置编码来将文本编码为向量。 位置编码是词嵌入向量和位置向量之和。 通过这样做,编码后的文本包含有关字词的含义及其在句子中的位置的信息。
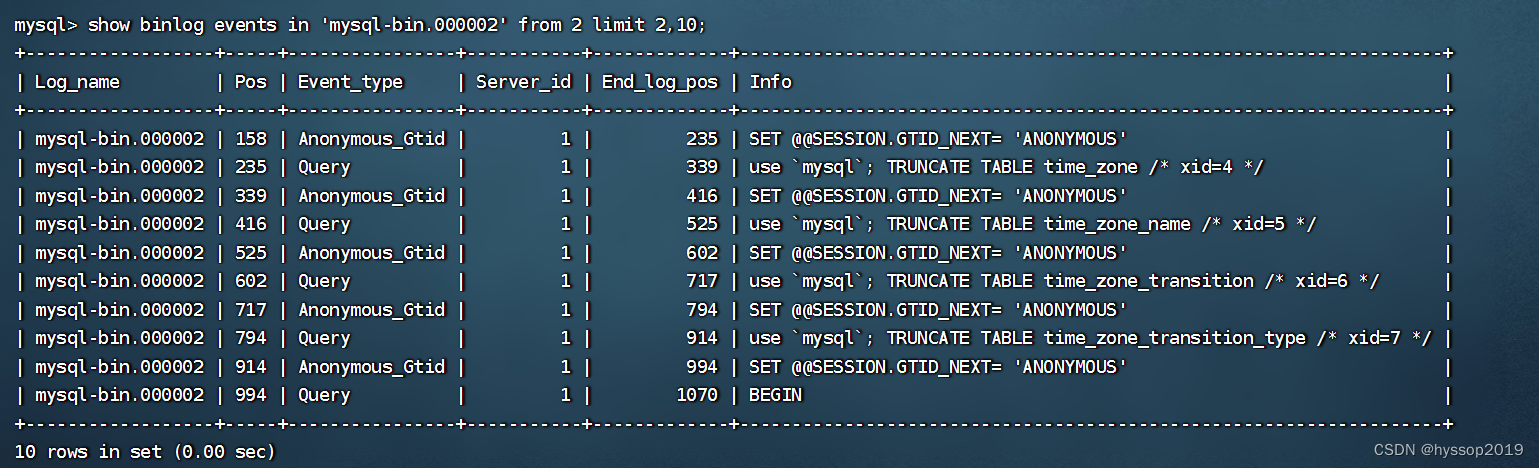
若要对字词在句子中的位置进行编码,可使用单个数字来表示索引值。 例如:
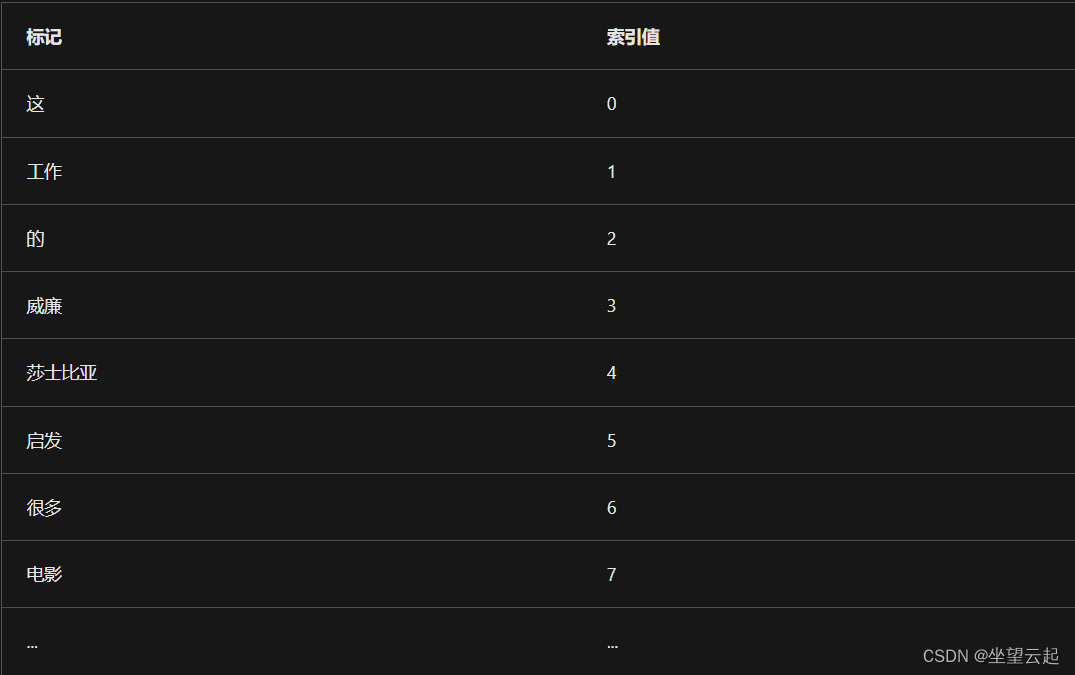
文本或序列越长,索引值可能就越大。 虽然对文本中的每个位置使用唯一值是一种简单的方法,但值没有任何含义,并且在模型训练期间,值的增大可能会导致不稳定。 《Attention is all you need》论文中提出的解决方案是使用正弦和余弦函数,其中 pos 表示位置,i 表示维度:
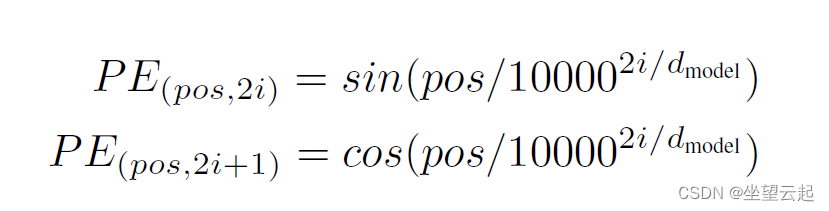
结合使用这些周期函数进行创建时,可以为每个位置创建唯一的向量。 这样的话,值在一个范围内,并且当编码较大的文本时,索引不会变大。 此外,这些位置向量使模型能够更轻松地计算和比较句子中不同字词的位置。
2、了解多头注意力
Transformer 用于处理文本的最重要技术是使用注意力而不是递归。 注意力也称为自注意力或内部注意力,这种机制用于将新信息映射到已学习的信息,以了解新信息需要什么。
Transformer 使用注意力函数,其中新字词使用位置编码进行了编码,并表示为查询。 已编码的字词的输出是具有关联值的键。 为了说明注意力函数使用的三个变量(查询、键和值),让我们来看看一个简化的示例。 假设对句子 Vincent van Gogh is a painter, known for his stunning and emotionally expressive artworks. 进行编码。对查询 Vincent van Gogh 进行编码时,输出可能将 Vincent van Gogh 用作键,将 painter 用作关联值。 该体系结构将键和值存储在表中,将来解码时可使用该表:
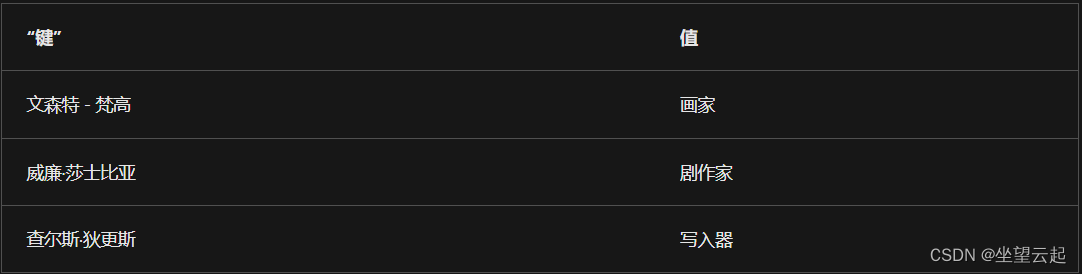
每次显示新句子时,例如 Shakespeare's work has influenced many movies, mostly thanks to his work as a ..., 模型都可将 Shakespeare 作为查询,并在键值表中查找此内容来补全句子。 Shakespeare 查询最接近 William Shakespeare 键,因此关联值 playwright 显示为输出。
3、使用缩放点积来计算注意力函数
为了计算注意力函数,查询、键和值都编码为向量。 然后,注意力函数计算查询向量和键向量之间的缩放点积。
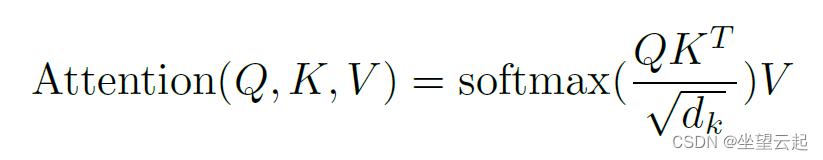
点积计算表示标记的向量之间的角度,当向量对齐程度更高时,积越大。 softmax 函数在注意力函数中对向量的缩放点积使用,来创建具有可能结果的概率分布。 换句话说,softmax 函数的输出中显示了哪些键最接近查询。 然后选择概率最高的键,关联值是注意力函数的输出。
Transformer 体系结构使用多头注意力,这意味着标记由注意力函数多次并行处理。 这样做,可通过各种方式处理处理字词或句子,以便从句子中提取不同类型的信息。
4、Transformer 体系结构
在《Attention is all you need》论文中,推荐的 Transformer 体系结构建模如下:
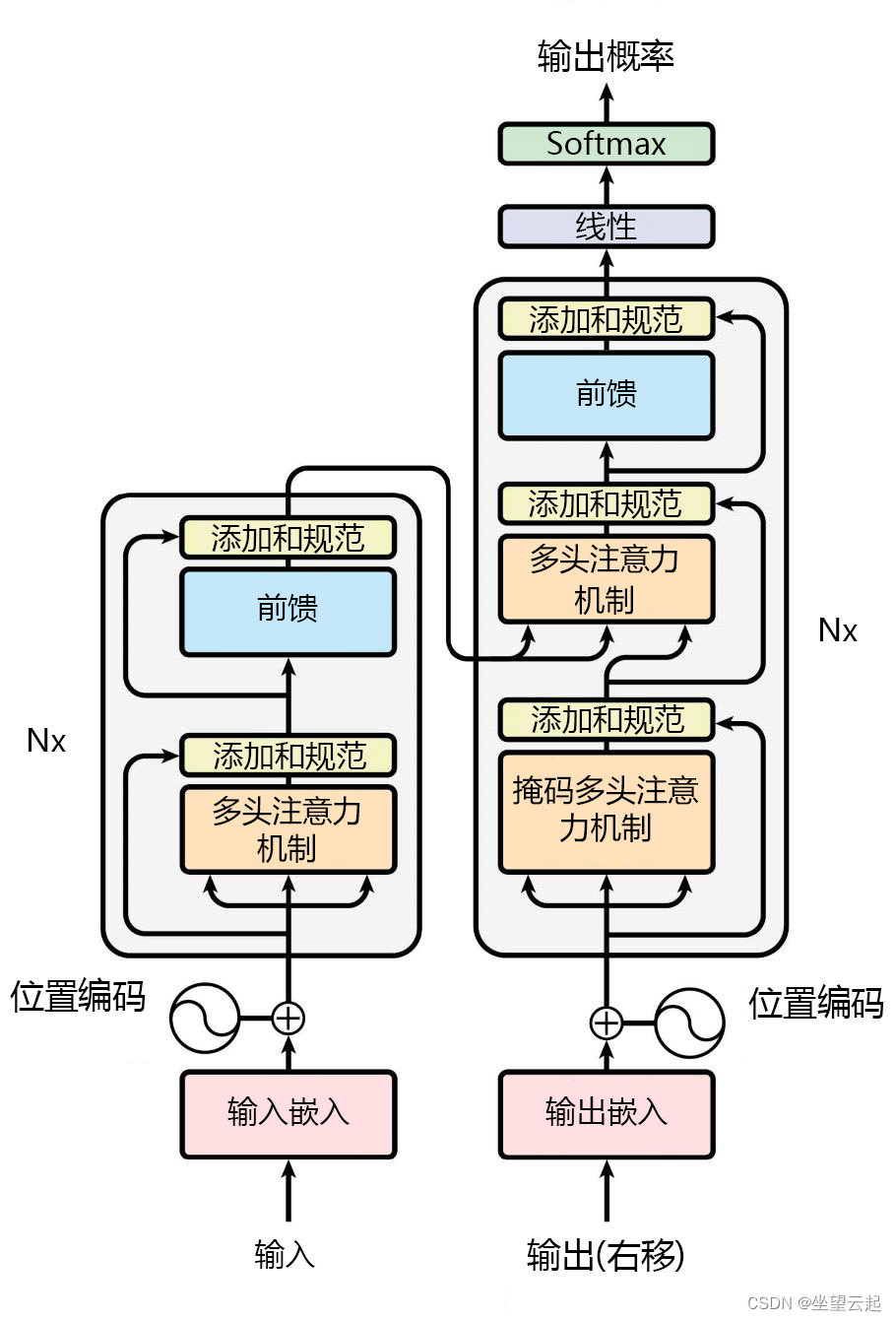
原始 Transformer 体系结构中主要有两个组件:
编码器:负责处理输入序列,并创建捕获每个标记的上下文的表示形式。
解码器:通过关注编码器的表示形式并预测序列中的下一个标记,生成输出序列。
在 Transformer 体系结构中,最重要的创新是位置编码和多头注意力。 侧重于这两个组件的体系结构的简化表示形式可能如下所示:
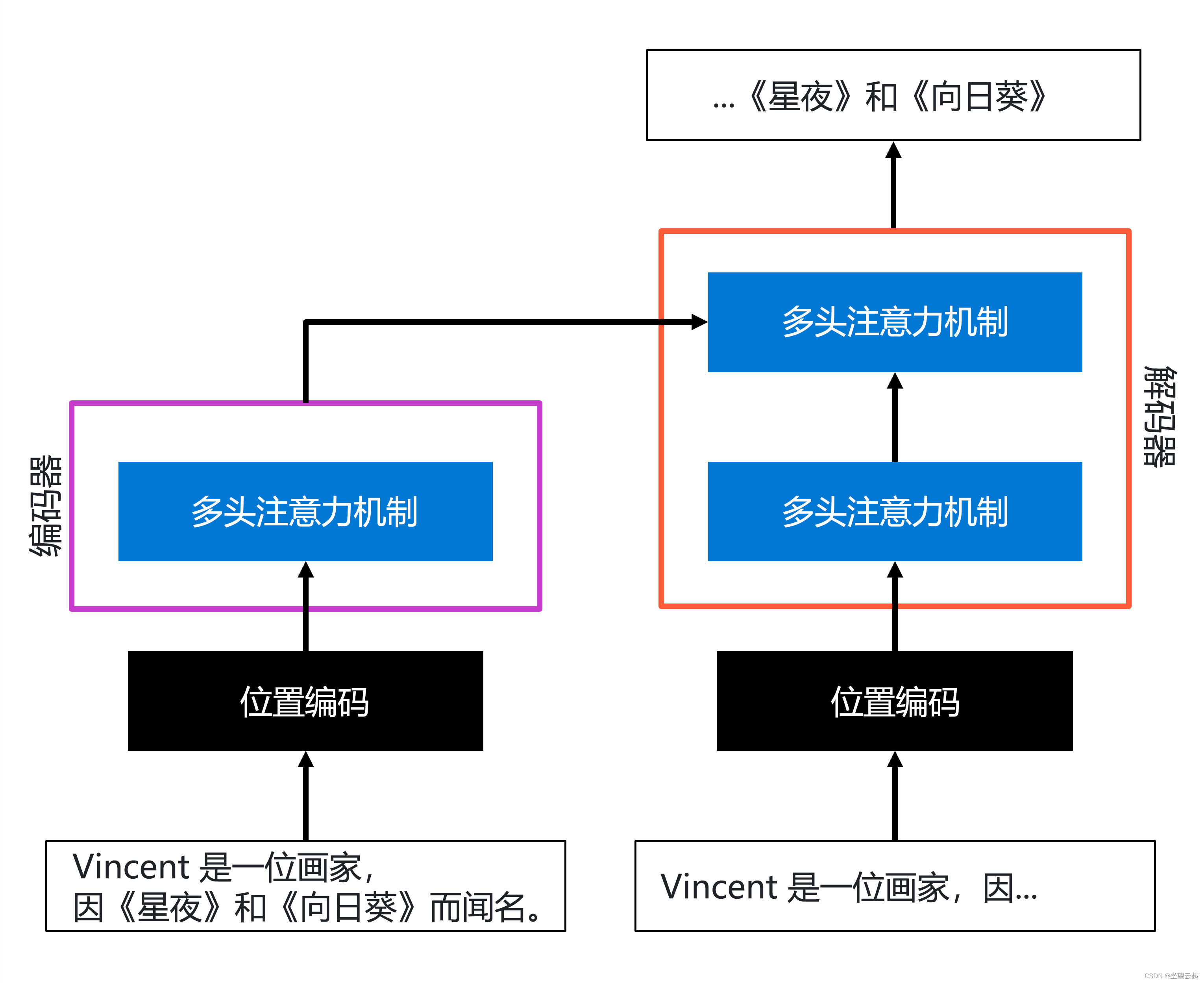
在编码器层中,输入序列使用位置编码进行编码,之后使用多头注意力来创建文本的表示形式。
在解码器层中,(不完整的)输出序列以类似的方式进行编码,方法是先使用位置编码,然后使用多头注意力。 然后,在解码器中再次使用多头注意力机制,来合并编码器的输出和已编码的输出序列的输出(该序列的输出作为输入传递到编码器部分)。 这样,就可以生成输出。
Transformer 体系结构引入的概念极大地提高了模型理解和生成文本的能力。 已经采用了 Transformer 体系结构来训练不同的模型,以便针对特定 NLP 任务进行优化。
Transformer 体系结构让我们可以更高效地为自然语言处理 (NLP) 训练模型。 注意力机制不处理句子或序列中的每个标记,而是使模型以各种方式并行处理标记。
若要使用 Transformer 体系结构训练模型,需要使用大量文本数据作为输入。不同的模型被训练出来,这些模型主要的不同点在于训练使用的数据或它们在体系结构中实现注意力机制的方式。 由于模型是通过大型数据集训练的,并且模型本身的大小很大,因此它们通常被称为大型语言模型 (LLM)。
许多 LLM 都是开源的,可通过 Hugging Face 等社区公开获取。很多云服务商还提供了最常用的 LLM 作为基础模型。基础模型是通过大型文本预先训练的,可以通过相对较小的数据集针对特定任务进行微调。


![[论文笔记] EcomGPT:COT扩充数据的电商大模型](https://img-blog.csdnimg.cn/direct/83033b9b062b42af9649618027df68fa.png)