一 过滤器
1.1相关概念
1.过滤器可以根据列族、列、版本等更多的条件来对数据进行过滤,
基于 HBase 本身提供的三维有序(行键,列,版本有序),这些过滤器可以高效地完成查询过滤的任务,带有过滤器条件的 RPC 查询请求会把过滤器分发到各个 RegionServer(这是一个服务端过滤器),这样也可以降低网络传输的压力。
2.使用过滤器至少需要两类参数:
一类是抽象的操作符,另一类是比较器
3.过滤器的作用是在服务端判断数据是否满足条件,然后只将满足条件的数据返回给客户端
4.过滤器的类型很多,但是可以分为三大类:
-
比较过滤器:可应用于rowkey、列簇、列、列值过滤器
-
专用过滤器:只能适用于特定的过滤器
-
包装过滤器:包装过滤器就是通过包装其他过滤器以实现某些拓展的功能
1.2 CompareOperator 比较运算符
比较运算符
-
LESS <
-
LESS_OR_EQUAL <=
-
EQUAL =
-
NOT_EQUAL <>
-
GREATER_OR_EQUAL >=
-
GREATER >
-
NO_OP 排除所有
1.3 常见的六大比较器
BinaryComparator
按字节索引顺序比较指定字节数组,采用Bytes.compareTo(byte[])
BinaryPrefixComparator
通BinaryComparator,只是比较左端前缀的数据是否相同
NullComparator
判断给定的是否为空
BitComparator
按位比较
RegexStringComparator
提供一个正则的比较器,仅支持 EQUAL 和非EQUAL
SubstringComparator
判断提供的子串是否出现在中
二 常用的过滤器
2.1 行键过滤器
1.先将表名封装成一个TableName的对象
TableName tn = TableName.valueOf("表名");
2.获取表对象 使用数据库连接对象conn中的getTable获取表对象,参数是TableName的对象
Table table = conn.getTable(tn);
3.创建sacn对象
Scan scan = new Scan();
4.创建什么比较器,传入的值是不同的
这里是行键比较器,比较的是在这个行键的大小,所以用BinaryComparator,传入的是行键
BinaryComparator binaryComparator = new BinaryComparator(Bytes.toBytes("行键"));
5.创建一个行键过滤器对象
里面传入的是操作符,跟比较器对象
RowFilter rowFilter = new RowFilter(CompareOperator.LESS, binaryComparator);
6.设置过滤器
使用的是scan里面的setFilter方法,里面传入的是过滤器对象
scan.setFilter(rowFilter);
7.创建结果对象
使用的是表对象中的getScanner方法,传入的是scan对象
ResultScanner resultScanner = table.getScanner(scan);
8.遍历结果对象
/*** 需求:通过RowFilter与BinaryComparator过滤比rowKey 1500100010小的所有值出来* 配合等值比较器BinaryComparator*/@Testpublic void scanDataWithRowFilterAndBinaryComparator() throws Exception{try {//先将表名封装成一个TableName的对象TableName st = TableName.valueOf("students");//获取表对象Table table = conn.getTable(st);//scanScan scan = new Scan();//创建一个BinaryComparator比较器对象,里面传入的是行键BinaryComparator binaryComparator = new BinaryComparator(Bytes.toBytes("1500100010"));//创建一个行键过滤器对象RowFilter rowFilter = new RowFilter(CompareOperator.LESS, binaryComparator);//设置过滤器//public Scan setFilter(Filter filter)scan.setFilter(rowFilter);//创建结果对象ResultScanner resultScanner = table.getScanner(scan);for (Result result : resultScanner) {HBaseUtils.printResult(result);}}catch (Exception e){e.printStackTrace();}}2.2 列簇过滤器
1.先将表名封装成一个TableName的对象
TableName tn = TableName.valueOf("表名");
2.获取表对象 使用数据库连接对象conn中的getTable获取表对象,参数是TableName的对象
Table table = conn.getTable(tn);
3.创建sacn对象
Scan scan = new Scan();
4.创建什么比较器,传入的值是不同的
这里是列簇比较器,比较的是列簇是是否包含,所以使用SubstringComparator比较器,传入的是字符串
5.创建一个什么的过滤器对象
这里是列簇过滤器 FamilyFilter
里面传入的是操作符,跟比较器对象
FamilyFilter familyFilter = new FamilyFilter(CompareOperator.EQUAL, substringComparator);
6.设置过滤器
使用的是scan里面的setFilter方法,里面传入的是过滤器对象
scan.setFilter(rowFilter);
7.创建结果对象
使用的是表对象中的getScanner方法,传入的是scan对象
ResultScanner resultScanner = table.getScanner(scan);
8.遍历结果对象
/*** 列簇过滤器:FamilyFilter* 需求:过滤出列簇名中包含“a”的列簇中所有数据配合包含比较器SubstringComparator*/@Testpublic void scanDataWithFamilyFilterAndSubstringComparator() {try {//先将表名封装成一个TableName的对象TableName st = TableName.valueOf("users");//获取表对象Table table = conn.getTable(st);//scanScan scan = new Scan();//创建一个SubstringComparator包含比较器对象,里面传入是字符SubstringComparator substringComparator = new SubstringComparator("f");//创建一个列簇过滤器对象FamilyFilter familyFilter = new FamilyFilter(CompareOperator.EQUAL, substringComparator);//设置过滤器//public Scan setFilter(Filter filter)scan.setFilter(familyFilter);//创建结果对象ResultScanner resultScanner = table.getScanner(scan);for (Result result : resultScanner) {HBaseUtils.printResult(result);}}catch (Exception e){e.printStackTrace();}}2.3 列名过滤器
1.先将表名封装成一个TableName的对象
TableName tn = TableName.valueOf("表名");
2.获取表对象 使用数据库连接对象conn中的getTable获取表对象,参数是TableName的对象
Table table = conn.getTable(tn);
3.创建sacn对象
Scan scan = new Scan();
4.创建什么比较器,传入的值是不同的
这里是列名比较器,比较的是列簇是是否包含,所以使用SubstringComparator比较器,传入的是字符串
5.创建一个什么的过滤器对象
这里是列簇过滤器QualifierFilter
里面传入的是操作符,跟比较器对象
QualifierFilter qualifierFilter = new QualifierFilter(CompareOperator.EQUAL, substringComparator);
6.设置过滤器
使用的是scan里面的setFilter方法,里面传入的是过滤器对象
scan.setFilter(rowFilter);
7.创建结果对象
使用的是表对象中的getScanner方法,传入的是scan对象
ResultScanner resultScanner = table.getScanner(scan);
8.遍历结果对象
/*** 列名过滤器:QualifierFilter* 通过QualifierFilter与SubstringComparator查询列名包含 m 的列的值*/@Testpublic void scanDataWithQualifierFilterAndSubstringComparator() {try {//先将表名封装成一个TableName的对象TableName st = TableName.valueOf("users");//获取表对象Table table = conn.getTable(st);//scanScan scan = new Scan();//创建一个SubstringComparator包含比较器对象,里面传入是字符SubstringComparator substringComparator = new SubstringComparator("m");//创建一个列名过滤器对象QualifierFilter qualifierFilter = new QualifierFilter(CompareOperator.EQUAL, substringComparator);//设置过滤器//public Scan setFilter(Filter filter)scan.setFilter(qualifierFilter);//创建结果对象ResultScanner resultScanner = table.getScanner(scan);for (Result result : resultScanner) {HBaseUtils.printResult(result);}} catch (Exception e) {e.printStackTrace();}}2.4 列值过滤器
列值过滤器只能过滤出当前符合条件的列,至于与该列属于同一行的其他列并不会返回
1.先将表名封装成一个TableName的对象
TableName tn = TableName.valueOf("表名");
2.获取表对象 使用数据库连接对象conn中的getTable获取表对象,参数是TableName的对象
Table table = conn.getTable(tn);
3.创建sacn对象
Scan scan = new Scan();
4.创建什么比较器,传入的值是不同的
这里是列值比较器,比较的是列值前面是否以啥开头,所以使用BinaryPrefixComparator比较器,传入的是字符串
BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator(Bytes.toBytes("从"));
5.创建一个什么的过滤器对象
这里是列值过滤器valueFilter
里面传入的是操作符,跟比较器对象
ValueFilter valueFilter = new ValueFilter(CompareOperator.EQUAL, binaryPrefixComparator);
6.设置过滤器
使用的是scan里面的setFilter方法,里面传入的是过滤器对象
scan.setFilter(valueFilter );
7.创建结果对象
使用的是表对象中的getScanner方法,传入的是scan对象
ResultScanner resultScanner = table.getScanner(scan);
8.遍历结果对象
/*** 列值过滤器(属于比较过滤器)* 通过ValueFilter与BinaryPrefixComparator过滤出所有的cell中值以 "从" 开头的学生* 注意:列值过滤器只能过滤出当前符合条件的列,至于与该列属于同一行的其他列并不会返回*/@Testpublic void scanDataWithValueFilterAndBinaryPrefixComparator(){try {//先将表名封装成一个TableName的对象TableName st = TableName.valueOf("students");//获取表对象Table table = conn.getTable(st);//scanScan scan = new Scan();//创建一个BinaryPrefixComparator只是比较左端前缀的数据是否相同比较器对象,里面传入是字节数组BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator(Bytes.toBytes("从"));//创建一个列值过滤器对象ValueFilter valueFilter = new ValueFilter(CompareOperator.EQUAL, binaryPrefixComparator);//设置过滤器//public Scan setFilter(Filter filter)scan.setFilter(valueFilter);//创建结果对象ResultScanner resultScanner = table.getScanner(scan);for (Result result : resultScanner) {HBaseUtils.printResult(result);}}catch (Exception e){e.printStackTrace();}}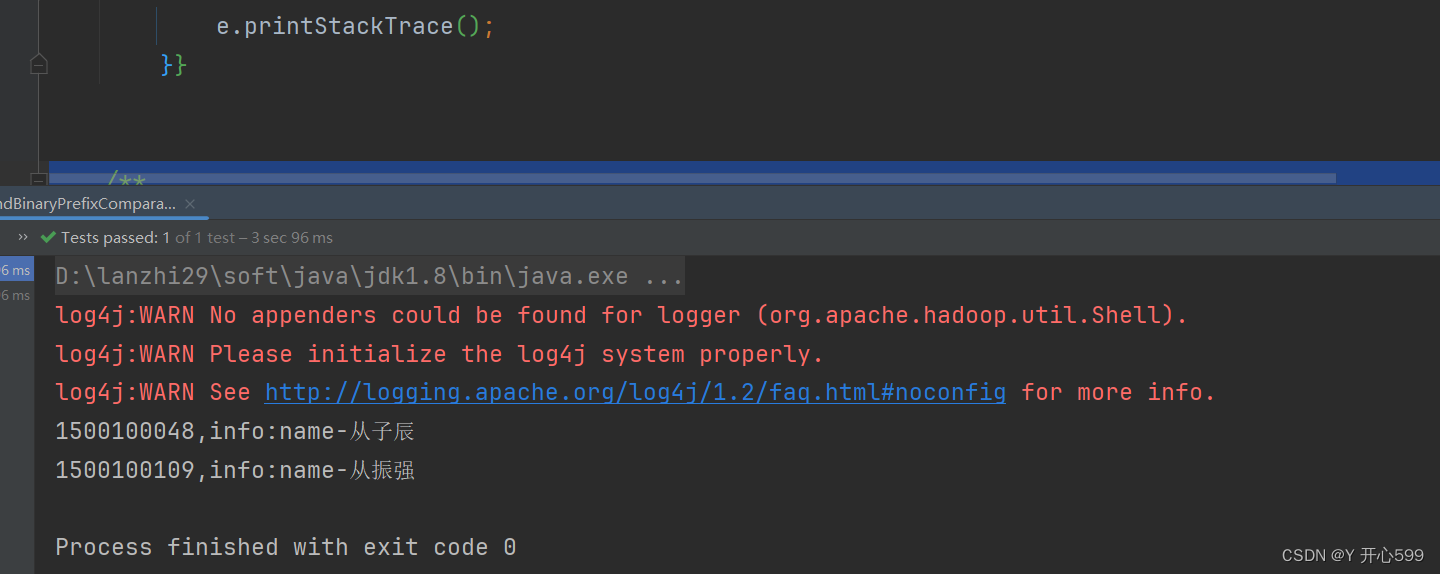
2.5 专用过滤器
2.5.1单列值过滤器
SingleColumnValueFilter会返回满足条件的cell所在行的所有cell的值(即会返回一行数据)
1.创建过滤器不一样
//创建单列值过滤器
//public SingleColumnValueFilter(final byte [] family, final byte [] qualifier,
// final CompareOperator op,
// final org.apache.hadoop.hbase.filter.ByteArrayComparable comparator)
传入的是行键,列名(全是字节数组形式),操作符,比较器对象
/*** 单列值过滤器(专用过滤器)* 需求:通过SingleColumnValueFilter与BinaryPrefixComparator过滤出所有的cell中值以 "从" 开头的学生*/@Testpublic void scanDataWithSingleColumnValueFilterAndBinaryPrefixComparator(){try {//先将表名封装成一个TableName的对象TableName tn = TableName.valueOf("students");//获取表对象Table table = conn.getTable(tn);//scanScan scan = new Scan();//创建一个BinaryPrefixComparator只是比较左端前缀的数据是否相同比较器对象,里面传入是字节数组BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator(Bytes.toBytes("从"));//创建一个单列值过滤器对象//public SingleColumnValueFilter(byte[] family, byte[] qualifier, CompareOperator op, ByteArrayComparable comparator)SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("name"), CompareOperator.EQUAL, binaryPrefixComparator);//设置过滤器//public Scan setFilter(Filter filter)scan.setFilter(singleColumnValueFilter);//创建结果对象ResultScanner resultScanner = table.getScanner(scan);for (Result result : resultScanner) {HBaseUtils.printResult(result);}}catch (Exception e){e.printStackTrace();}}2.得到的结果跟列值比较器有所不同,它可以把这行所有数据全都展示出来
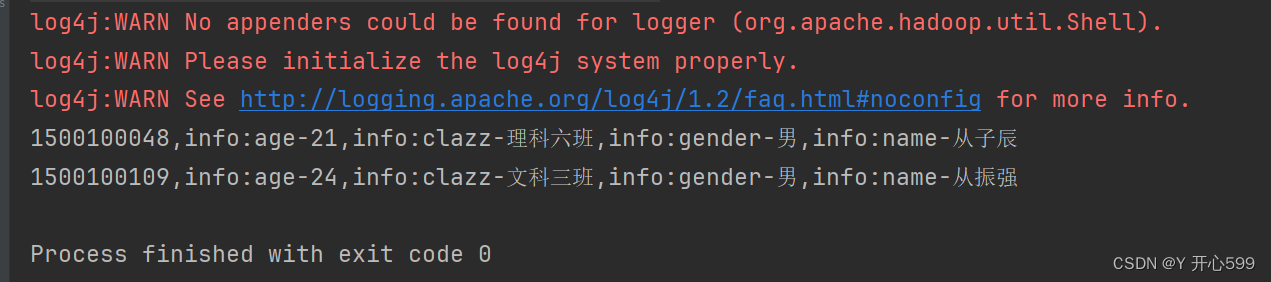
2.5.2列值排除过滤器
SingleColumnValueExcludeFilter 会返回满足条件的cell所在行的所有cell的值(即会返回一行数据)
1.创建过滤器不一样
//创建列值排除过滤器
//public SingleColumnValueExcludeFilter(byte[] family, byte[] qualifier,
// CompareOperator op, ByteArrayComparable comparator)
传入的是行键,列名(全是字节数组形式),操作符,比较器对象
/*** 列值排除过滤器* SingleColumnValueExcludeFilter* 通过SingleColumnValueExcludeFilter与BinaryComparator查询文科一班所有学生信息,最终不返回clazz列*/@Testpublic void scanDataWithSingleColumnValueExcludeFilterAndBinaryComparator(){try {//先将表名封装成一个TableName的对象TableName tn = TableName.valueOf("students");//获取表对象Table table = conn.getTable(tn);//scanScan scan = new Scan();//创建一个BinaryPrefixComparator只是比较左端前缀的数据是否相同比较器对象,里面传入是字节数组BinaryComparator binaryComparator = new BinaryComparator(Bytes.toBytes("文科一班"));//创建一个列值排除过滤器对象//public SingleColumnValueExcludeFilter(byte[] family, byte[] qualifier, CompareOperator op, ByteArrayComparable comparator)SingleColumnValueExcludeFilter singleColumnValueExcludeFilter = new SingleColumnValueExcludeFilter(Bytes.toBytes("info"), Bytes.toBytes("clazz"), CompareOperator.EQUAL, binaryComparator);//设置过滤器//public Scan setFilter(Filter filter)scan.setFilter(singleColumnValueExcludeFilter);//创建结果对象ResultScanner resultScanner = table.getScanner(scan);for (Result result : resultScanner) {HBaseUtils.printResult(result);}}catch (Exception e){e.printStackTrace();}2.结果是 除了我们输入的列,其他全部输出
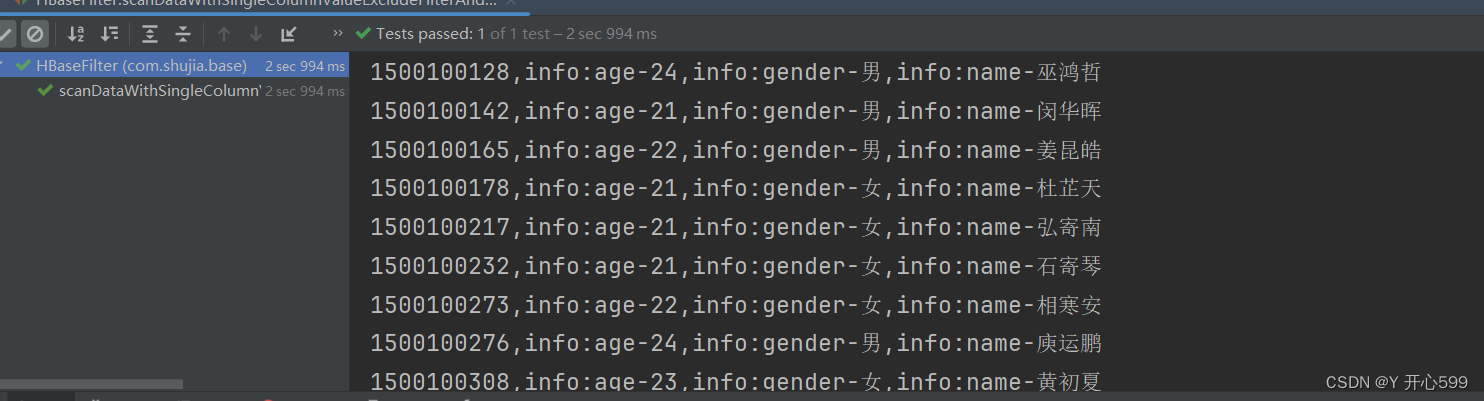
2.5.3 rowkey前缀过滤器:
PrefixFilter
1.不需要设置比较器
2.设置的过滤器不同
//PrefixFilter(final byte [] prefix)
里面直接传入行键的字节数组
/*** 行键前缀过滤器 PrefixFilter* 通过PrefixFilter查询以15001001开头的所有前缀的rowkey*/@Testpublic void scanDataWithPrefixFilter(){try {//先将表名封装成一个TableName的对象TableName tn = TableName.valueOf("students");//获取表对象Table table = conn.getTable(tn);//scanScan scan = new Scan();//创建一个行键前缀过滤器对象//public PrefixFilter(byte[] prefix)PrefixFilter prefixFilter = new PrefixFilter(Bytes.toBytes("15001001"));//设置过滤器//public Scan setFilter(Filter filter)scan.setFilter(prefixFilter);//创建结果对象ResultScanner resultScanner = table.getScanner(scan);for (Result result : resultScanner) {HBaseUtils.printResult(result);}}catch (Exception e){e.printStackTrace();}}2.结果
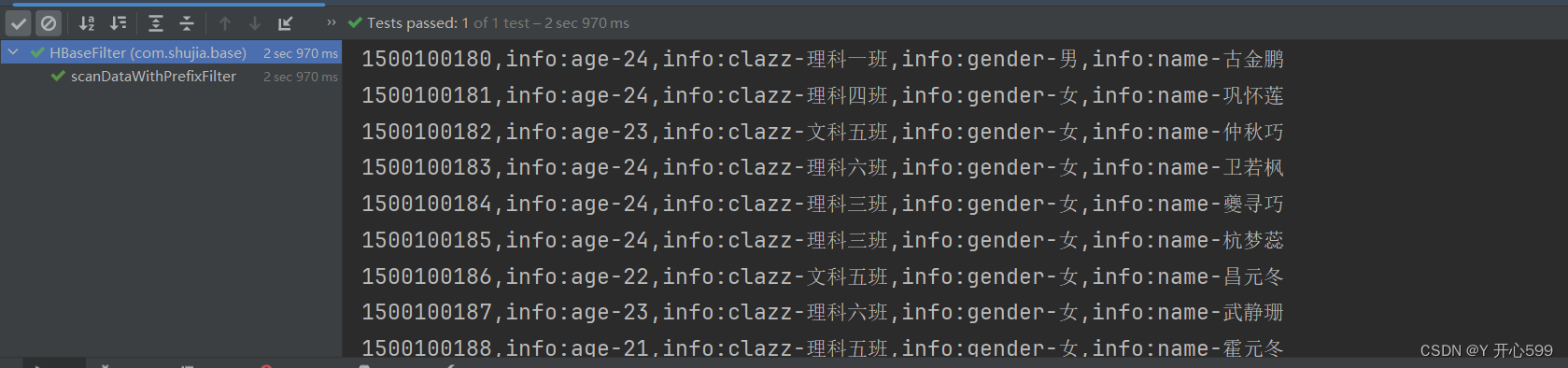
2.5.4 分页过滤器
PageFilter
1.需要设置分页的张数,查询的数量,起始行
2.设置过滤器
PageFilter pageFilter = new PageFilter(pageNumData);
3.遍历要for 循环遍历,因为设置了页数
4.前一页的末尾是下页的起始行
/*** 分页过滤器* PageFilter* 通过PageFilter查询三页的数据,每页10条*/@Testpublic void scanDataWithPageFilter() {try {//先将表名封装成一个TableName的对象TableName tn = TableName.valueOf("students");//获取表对象Table table = conn.getTable(tn);//设置要查询的页数int pageNum=3;//设置每一行查询的数量int pageNumData=10;//设置起始行String statKey="";//创建分页对象PageFilter pageFilter = new PageFilter(pageNumData);//创建scan对象Scan scan = new Scan();//设置scan对象scan.setFilter(pageFilter);for (int i=1;i<=pageNum;i++){System.out.println("======================="+i+"页=========");ResultScanner resultScanner = table.getScanner(scan);for (Result result : resultScanner) {statKey = Bytes.toString(result.getRow()) + 0;//设置下一行的开始scan.withStartRow(Bytes.toBytes(statKey));HBaseUtils.printResult(result);}}}catch (Exception e){e.printStackTrace();}}2.6 包装过滤器
2.6.1 跳过过滤器
SkipFilter
1.//创建跳过过滤器
SkipFilter skipFilter = new SkipFilter(valueFilter);
里面传入的是过滤器
2.他只能跳过列值,不能跳过行键
3.看看区别
a.这里设置过滤器用的是列值过滤器
结果只是将含有理科的没有查询,但是其他的都查询了
b.设置的是跳过过滤器
结果是将所有含理科的全部不查询
 2.6.2 停止过滤器
2.6.2 停止过滤器
WhileMatchFilter
1.设置过滤器
WhileMatchFilter whileMatchFilter = new WhileMatchFilter(valueFilter);
传入的是过滤器对象
2.只能跳过列值
3.区别
a.这里设置过滤器用的是列值过滤器
结果只是将含有理科的没有查询,但是其他的都查询了
b.停止过滤器
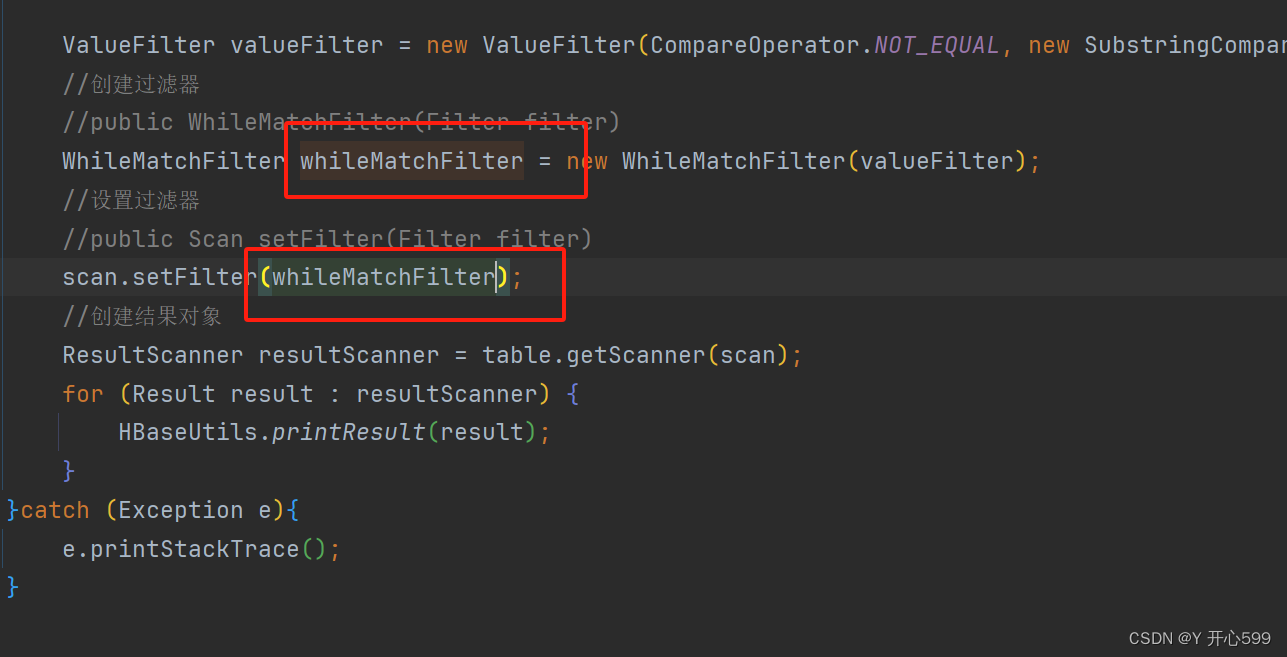
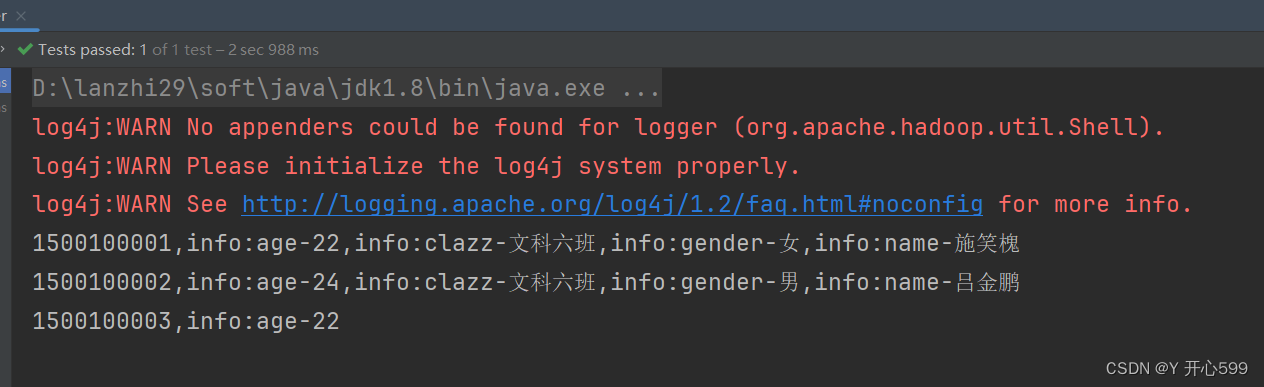
他是查到有理科出现,立马停止
2.7 多过滤器
1.过滤条件可以设置多个比较器与过滤器
2.创建过滤器集合
将过滤器添加到集合中
3.创建FilterList对象
FilterList filterList = new FilterList();
//public void addFilter(List<Filter> filters)
filterList.addFilter(filters);
/*** 组合过滤器* 需求:通过运用4种比较器过滤出姓于,年纪大于22岁,性别为女,且是理科的学生。*/@Testpublic void scanDataWithGroupFilter(){try {//先将表名封装成一个TableName的对象TableName tn = TableName.valueOf("students");//获取表对象Table table = conn.getTable(tn);//scanScan scan = new Scan();//创建比较器,判断姓名是否以于开头BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator(Bytes.toBytes("于"));//创建比较器 判断年龄是否大于22BinaryComparator binaryComparator = new BinaryComparator(Bytes.toBytes("22"));//创建比较器 判断性别是否为女BinaryComparator binaryComparator1 = new BinaryComparator(Bytes.toBytes("女"));//创建比较器 判断班级是否为理科SubstringComparator substringComparator = new SubstringComparator("理科");//创建单列值过滤器,判断姓名是否以于开头SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(Bytes.toBytes("info"),Bytes.toBytes("name"), CompareOperator.EQUAL, binaryPrefixComparator);//创建单列值过滤器,判断年龄是否大于22SingleColumnValueFilter singleColumnValueFilter1 = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("age"), CompareOperator.GREATER, binaryComparator);//创建单列值过滤器,判断年龄是否大于22SingleColumnValueFilter singleColumnValueFilter2 = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("gender"), CompareOperator.EQUAL, binaryComparator1);//创建单列值过滤器,判断班级是否含有理科SingleColumnValueFilter singleColumnValueFilter3 = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("clazz"), CompareOperator.EQUAL, substringComparator);//创建过滤器集合ArrayList<Filter> filters = new ArrayList<>();filters.add(singleColumnValueFilter);filters.add(singleColumnValueFilter1);filters.add(singleColumnValueFilter2);filters.add(singleColumnValueFilter3);//创建创建FilterList对象对象FilterList filterList = new FilterList();filterList.addFilter(filters);//设置过滤器//public Scan setFilter(Filter filter)scan.setFilter(filterList);//创建结果对象ResultScanner resultScanner = table.getScanner(scan);for (Result result : resultScanner) {HBaseUtils.printResult(result);}}catch (Exception e){e.printStackTrace();}}综合案例
查询文科一班学生总分排名前10的学生(输出:学号,姓名,班级,总分)结果写到hbase
1、先将成绩表创建出来
2.将成绩表与学生表关联起来
3.设置合适的rowKey
4.重新创建一张表,设置合适的rowKey
package com.shujia.base;import com.shujia.utils.HBaseUtils;
import org.apache.hadoop.hbase.CompareOperator;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.PrefixFilter;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.util.Bytes;import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.util.Arrays;
import java.util.HashMap;public class HBasePractice {public static void main(String[] args) throws Exception {//获取数据库连接对象Connection conn = HBaseUtils.CONNECTION;Admin admin = HBaseUtils.ADMIN;//创建一张表
// HBaseUtils.createOneTable("scores","info");/*** 1500100001,1000001,98* 1500100001,1000002,5* 1500100001,1000003,137* 1500100001,1000004,29* 1500100001,1000005,85* 1500100001,1000006,52* 1500100002,1000001,139*** 所以我们这样设置rowkey*1500100001-1000001,98*1500100001-1000002,5*1500100001-1000003,137*1500100001-1000004,29*1500100001-1000005,85*1500100001-1000006,52*1500100002-1000001,139* 查询文科一班学生总分排名前10的学生(输出:学号,姓名,班级,总分)结果写到hbase*///读文件
// BufferedReader br = new BufferedReader(new FileReader("hbase/data/score.txt"));
// String line = null;
// while ((line=br.readLine())!=null){
// String[] split = line.split(",");
// String id = split[0];
// String sid = split[1];
// String sc = split[2];
// HBaseUtils.putOneDataToTable("scores",id+"-"+sid,"info","score",sc);
// }//先将表名封装成一个TableName的对象TableName tn = TableName.valueOf("students");TableName tn1 = TableName.valueOf("scores");//获取表对象Table students = conn.getTable(tn);Table scores = conn.getTable(tn1);//scanScan scan = new Scan();//设置比较器BinaryComparator binaryComparator = new BinaryComparator(Bytes.toBytes("文科一班"));//设置过滤器SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("clazz"), CompareOperator.EQUAL, binaryComparator);//设置过滤器scan.setFilter(singleColumnValueFilter);//创建结果对象ResultScanner resultScanner = students.getScanner(scan);//创建map集合HashMap<String, Integer> yiBanWenKe = new HashMap<>();for (Result result : resultScanner) {String id = Bytes.toString(result.getRow());//创建rowkey前缀过滤器PrefixFilter prefixFilter = new PrefixFilter(Bytes.toBytes(id));//scanScan scan1 = new Scan();//设置过滤器scan1.setFilter(prefixFilter);//创建结果对象ResultScanner resultScanner1 = scores.getScanner(scan1);int sumScore=0;for (Result result1 : resultScanner1) {int score = Integer.parseInt(Bytes.toString(result1.getValue(Bytes.toBytes("info"), Bytes.toBytes("score"))));sumScore+=score;}String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));String clazz = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("clazz")));yiBanWenKe.put(id+"-"+name+"-"+clazz,sumScore);}
// yiBanWenKe.forEach((k,v)->{
// String[] split = k.split("-");
// System.out.println("学号:"+split[0]+"\t姓名:"+split[1]+"\t班级:"+split[2]+"\t总分:"+v);
// });/*** 因为要降序排序,而hbase中,使用limit不能做到,这个时候只能重新设置rowKey* 1500100946 秋海白 文科一班 353* 1500100308 黄初夏 文科一班 628** 353-1500100946 秋海白 文科一班* 628-1500100308 黄初夏 文科一班* 再使用比较大的数减去分数,这样比较高的分数就就可以再上面* (1000-353)-1500100946 秋海白 文科一班* (1000-628)-1500100308 黄初夏 文科一班*///创建结果表
// HBaseUtils.dropOneTable("clazzWenOne");
// HBaseUtils.createOneTable("clazzWenOne","info");yiBanWenKe.forEach((k,v)->{String[] split = k.split("-");String id = split[0];String name = split[1];String clazz = split[2];int new_score=1000-v;System.out.println("学号:"+split[0]+"\t姓名:"+split[1]+"\t班级:"+split[2]+"\t总分:"+v);
// System.out.println("键:"+new_score+"-"+id+"\t姓名:"+name+"\t班级:"+clazz+"\t总分:"+v);HBaseUtils.putOneDataToTable("clazzWenOne",new_score+"-"+id,"info","name",name);HBaseUtils.putOneDataToTable("clazzWenOne",new_score+"-"+id,"info","clazz",clazz);});
// HBaseUtils.scanData("clazzWenOne",10);//释放资源HBaseUtils.closeSource();}
}
2.8 布隆过滤器
1.本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
2.在HBase中,布隆过滤器(Bloom Filter)的主要作用是提高随机读(get)的性能。HBase通过布隆过滤器来避免大量的读文件操作,特别是在过滤指定的rowkey是否在目标文件时,有助于减少不必要的扫描多个文件。
3.创建表的时候,可以在设置列簇描述器对象时候设置
使用的是ColumnFamilyDescriptorBuilder里面的newBuilder方法,传入的是列簇的字节数组
然后继续使用设置布隆过滤器的方法setBloomFilterType,里面传入的是设置的控制行还是列
ColumnFamilyDescriptor columnFamilyDescriptor = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily))
.setBloomFilterType(BloomType.ROW).build();
public static void createOneTable(String tableName, String columnFamily) {try {//先将表名封装成一个TableName的对象TableName tn = TableName.valueOf(tableName);if (!ADMIN.tableExists(tn)){TableDescriptorBuilder table = TableDescriptorBuilder.newBuilder(tn);//创建列簇描述器对象
// ColumnFamilyDescriptor info = ColumnFamilyDescriptorBuilder.of("info");//使用另一种方法创建列簇描述器对象,并设置布隆过滤器ColumnFamilyDescriptor info = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily)).setBloomFilterType(BloomType.ROW).build();//将列簇与表进行关联table.setColumnFamily(info);//调用方法,创建表ADMIN.createTable(table.build());System.out.println(tn + "表创建成功!!!");}else {System.out.println(tn + "表已经存在!");}} catch (Exception e) {System.out.println("表创建失败!!");e.printStackTrace();}}


![[负债学习]支线Python4.21](https://img-blog.csdnimg.cn/d1a542ef5ac0416f8b806649dcb9c082.jpeg)
![【YOLOv8改进[Neck]】使用BiFPN助力V8更优秀](https://img-blog.csdnimg.cn/direct/7462a827f58b4462b2a2c1196c550107.png)