前言:本篇主要讲解搭建所需环境,以及基于pytorch框架在stm32cubeide上部署神经网络,部署神经网络到STM32单片机,本篇实现初步部署模型,没有加入训练集与验证集,将在第二篇加入。篇二详细讲解STM32CubeIDE上部署神经网络之指纹识别(Pytorch)的数据准备和模型训练过程等,进行实战,第二篇在本专栏查阅。
目录
1. 环境安装和配置
2. AI神经网络模型搭建
2.1 数据集介绍
2.2 网络模型
2.3 训练
3. STM32CubeIDE上进行模型转换与模型部署到单片机
4. STM32 CubeUDE上进行模型验证
5. 结果统计与分析
1. 环境安装和配置
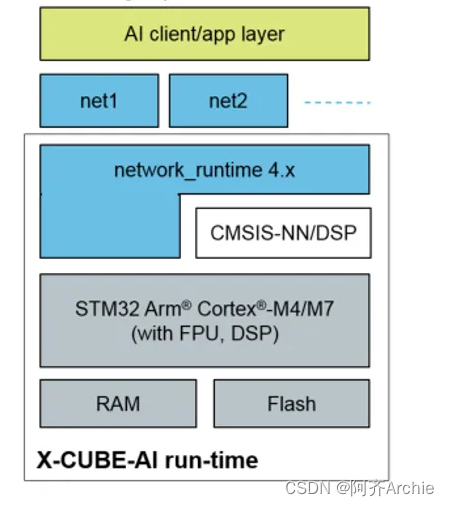
本文介绍在STM32cubeIDE上部署AI模型,开发板型号STM32F429IGT6。
与AI加速器不同,ST支持神经网络计算是因为之前的芯片已经内置了DSP处理器,可以执行高精度浮点运算,正好可以拿来做神经网络计算。如何判断自己准备购买的板子适不适合做AI计算,最好也按以下步骤在CUBE-AI上模拟部署一遍,若模拟成功,所选开发板就是可以的。
STM32cubeIDE可直接在ST官网下载,下载链接
https://www.st.com/zh/development-tools/stm32cubeide.html
默认安装即可,不懂可自行上网查教程。
2. AI神经网络模型搭建
2.1 数据集介绍
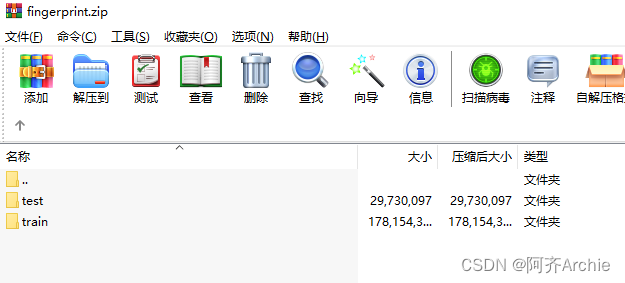
针对tinyML开发了自己的指纹识别数据集,数据集和完整代码见文末下载链接。指纹识别数据集包含100个类别,大小为260*260,训练集30张,测试集5张。在测试时使用128*128与64*64的分辨率。
数据集在如下文件夹中


生成测试集的方法:
import os
import numpy as np
from PIL import Image
import torchvision.transforms as transformsnormalize = transforms.Normalize(mean=[0.5],std=[0.5])
test_transforms = transforms.Compose([# transforms.RandomResizedCrop(224),transforms.Resize(128),transforms.ToTensor(),normalize])def prepare_eval_data(data_file, transform=None):datas = os.listdir(data_file)imgs=[]labels=[]for img_path in datas:data = Image.open(data_file + '/' + img_path) # 260*260*1label, _ = img_path.split('_')label = int(label) - 1label_ohot=np.zeros(100)label_ohot[label]=1# print(data.shape, label)data1 = transform(data)data2 = transform(data)data3 = transform(data)data = np.concatenate([data1, data2, data3], 0)labels.append(label_ohot)imgs.append(data)imgs = np.array(imgs)labels = np.array(labels)print(imgs.shape,labels.shape)return imgs,labelsif __name__ == '__main__':data_path = '/disks/disk2/dataset/fingerprint/'testx,testy=prepare_eval_data(data_path+'test',test_transforms )print(testx.shape,testy.shape)print(testy[0])np.save('fpr100*5_testx_128.npy', testx)np.save('fpr100*5_testy_128.npy', testy)2.2 网络模型
测试了多个轻量化神经网络模型,如压缩后的MobileNet v2:
class MobileNetV2Slim(nn.Module):def __init__(self, num_classes=1000):super(MobileNetV2Slim,self).__init__()self.first_conv = Conv3x3BNReLU(3,4,2,groups=1)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)# self.layer1 = self.make_layer(in_channels=8, out_channels=4, stride=1, block_num=1)self.layer2 = self.make_layer(in_channels=4, out_channels=6, stride=1, block_num=1)self.layer3 = self.make_layer(in_channels=6, out_channels=8, stride=2, block_num=2)self.layer4 = self.make_layer(in_channels=8, out_channels=16, stride=2, block_num=3)self.layer5 = self.make_layer(in_channels=16, out_channels=24, stride=1, block_num=3)self.layer6 = self.make_layer(in_channels=24, out_channels=32, stride=2, block_num=3)self.layer7 = self.make_layer(in_channels=32, out_channels=64, stride=1, block_num=1)self.last_conv = Conv1x1BNReLU(64,128)self.avgpool = nn.AvgPool2d(kernel_size=2,stride=1)self.dropout = nn.Dropout(p=0.2)self.linear = nn.Linear(in_features=128,out_features=num_classes)def make_layer(self, in_channels, out_channels, stride, block_num):layers = []layers.append(InvertedResidual(in_channels, out_channels, stride))for i in range(1, block_num):layers.append(InvertedResidual(out_channels,out_channels,1))return nn.Sequential(*layers)def init_params(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight)nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear) or isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)def forward(self, x):x = self.first_conv(x)x=self.maxpool(x)# x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.layer5(x)x = self.layer6(x)x = self.layer7(x)x = self.last_conv(x)# print(x.size())x = self.avgpool(x)# x = x.view(x.size(0),-1)x=x.reshape(int(x.size(0)), -1)x = self.dropout(x)out = self.linear(x)return out2.3 训练
基于pytorch搭建模型进行训练,核心代码如下:
'''***********- trainer -*************'''
class trainer:def __init__(self, loss_f,loss_dv,loss_fn, model, optimizer, scheduler, config):self.loss_f = loss_fself.loss_dv = loss_dvself.loss_fn = loss_fnself.model = modelself.optimizer = optimizerself.scheduler = schedulerself.config = configdef batch_train(self, batch_imgs, batch_labels, epoch):predicted = self.model(batch_imgs)loss = self.myloss(predicted, batch_labels)predicted = softmax(predicted, dim=-1)del batch_imgs, batch_labelsreturn loss, predicteddef train_epoch(self, loader,epoch):self.model.train()tqdm_loader = tqdm(loader)# acc = Accuracy_score()losses = AverageMeter()top1 = AverageMeter()top5 = AverageMeter()print("\n************Training*************")for batch_idx, (imgs, labels) in enumerate(tqdm_loader):#print("data",imgs.size(), labels.size())#[128, 3, 32, 32]) torch.Size([128]imgs, labels=imgs.cuda(), labels.cuda()#permute(0,3,1,2).# print(self.optimizer.param_groups[0]['lr'])loss, predicted = self.batch_train(imgs, labels, epoch)losses.update(loss.item(), imgs.size(0))# print(predicted.size(),labels.size())self.optimizer.zero_grad()loss.backward()self.optimizer.step()# self.scheduler.step()err1, err5 = accuracy(predicted.data, labels, topk=(1, 5))top1.update(err1.item(), imgs.size(0))top5.update(err5.item(), imgs.size(0))tqdm_loader.set_description('Training: loss:{:.4}/{:.4} lr:{:.4} err1:{:.4} err5:{:.4}'.format(loss, losses.avg, self.optimizer.param_groups[0]['lr'],top1.avg, top5.avg))# if batch_idx%1==0:# breakreturn 100-top1.avg, losses.avgdef valid_epoch(self, loader, epoch):self.model.eval()# acc = Accuracy_score()# tqdm_loader = tqdm(loader)losses = AverageMeter()top1 = AverageMeter()print("\n************Evaluation*************")for batch_idx, (imgs, labels) in enumerate(loader):with torch.no_grad():batch_imgs = imgs.cuda()#permute(0,3,1,2).batch_labels = labels.cuda()predicted= self.model(batch_imgs)loss = self.myloss(predicted, batch_labels).detach().cpu().numpy()loss = loss.mean()predicted = softmax(predicted, dim=-1)losses.update(loss.item(), imgs.size(0))err1, err5 = accuracy(predicted.data, batch_labels, topk=(1, 5))top1.update(err1.item(), imgs.size(0))return 100-top1.avg, losses.avgdef myloss(self,predicted,labels):#print(predicted.size(),labels.size())#[128, 10]) torch.Size([128])loss = self.loss_f(predicted,labels,)# loss = loss1+loss2return lossdef run(self, train_loder, val_loder,model_path):best_acc = 0start_epoch=0# model, optimizer, start_epoch=load_checkpoint(self.model,self.optimizer,model_path)for e in range(self.config.epochs):e=e+start_epoch+1print("------model:{}----Epoch: {}--------".format(self.config.model_name,e))self.scheduler.step(e)# torch.cuda.empty_cache()train_acc, train_loss = self.train_epoch(train_loder,e)val_acc, val_loss=self.valid_epoch(val_loder,e)#print("\nval_loss:{:.4f} | val_acc:{:.4f} | train_acc:{:.4f}".format(val_loss, val_acc,train_acc))if val_acc > best_acc:best_acc = val_accprint('Current Best (top-1 acc):',val_acc)#new_model = quant_dorefa.prepare(self.model, inplace=False, a_bits=8, w_bits=8)x = torch.rand(1, 3,data_config.input_size, data_config.input_size).float().cuda()save_path=data_config.MODEL_PATH+data_config.model_name+'_epoch{}_params.onnx'.format(e)torch.onnx.export(self.model, x, save_path, export_params=True, verbose=False,opset_version=10)# 支持Opset 7, 8, 9 and 10 of ONNX 1.6 is supported.print("saving model sucessful !",save_path)print('\nbest score:{}'.format(data_config.model_name))print("best accuracy:{:.4f} ".format(best_acc))模型训练后得到***.onnx模型、训练和测试数据,这是我们后续步骤要用到的。
3. STM32CubeIDE上进行模型转换与模型部署到单片机
步骤2得到了torch神经网络框架训练好的“***.onnx”模型文件,下一步需要把该AI模型转换成C程序代码,并嵌入到整个项目工程中。整个项目工程包括硬件代码可以直接通过 STM32CubeIDE工具生成。
具体步骤如下:
打开安装好的STM32CubeIDE软件。

新建,stm32 project。
搜索,选择目标开发板型号STM32F429IGT6,点击next。

填写项目名,点击finish。
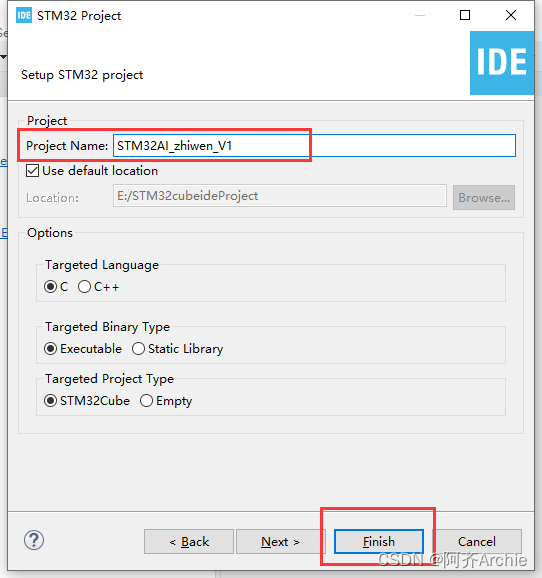
点击Yes 。

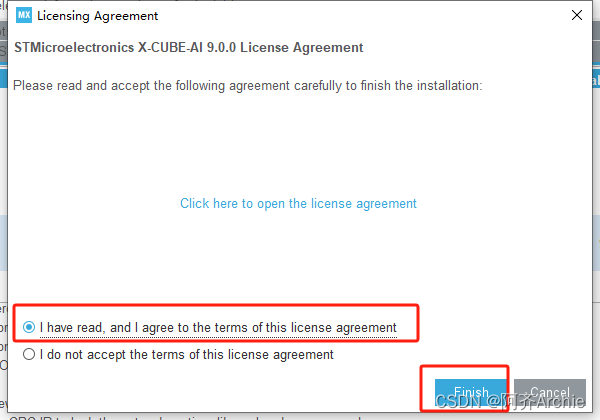
点击I hava read .... ;然后点击Finish。

等待初始化完成,左边是IDE编译器中是自动生成的底板代码,右边是CUBEMX软件界面,可对开发板硬件资源进行配置。
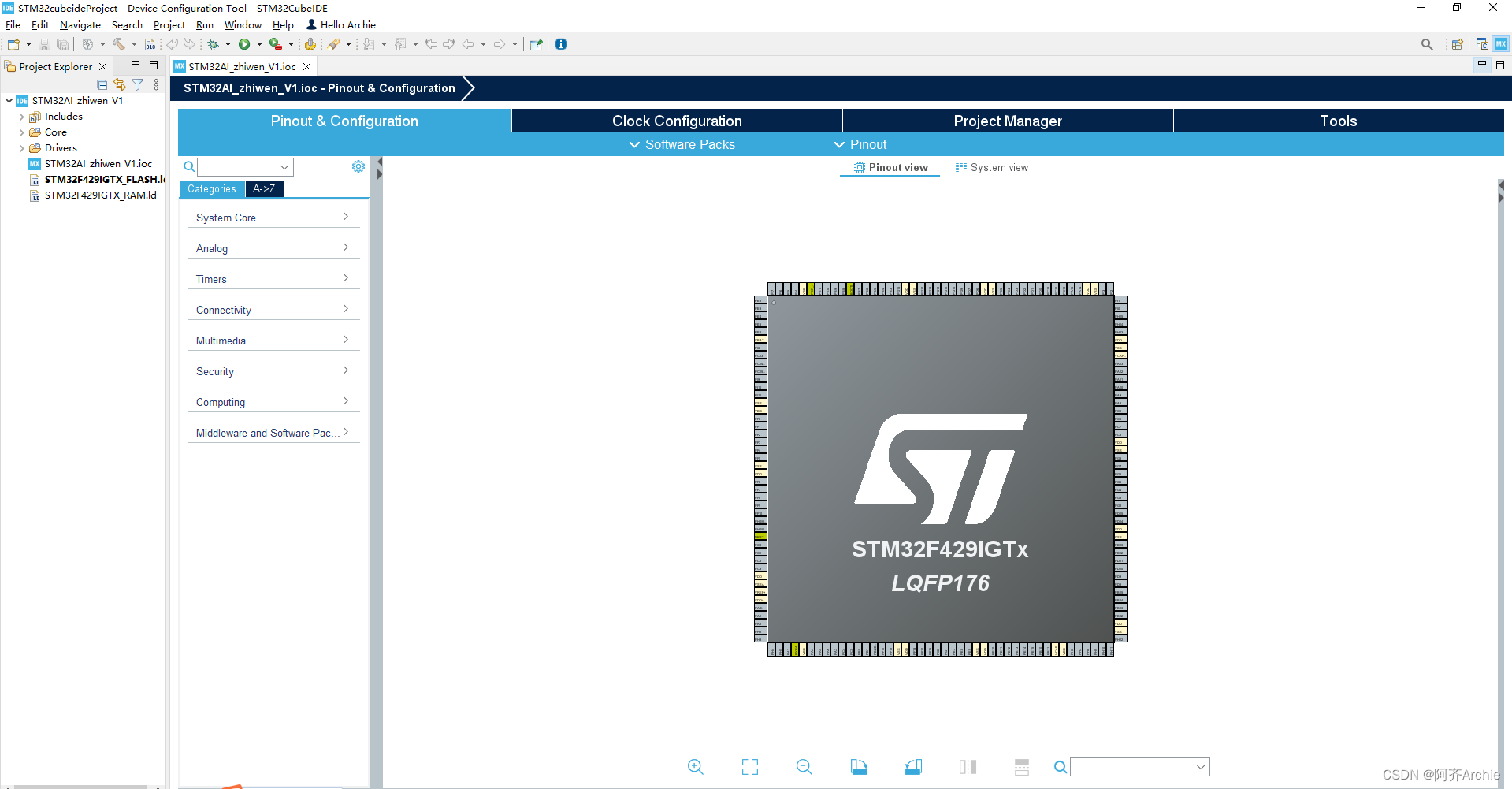
下载X-CUBE-AI,需在software packs点manage software packs找到X-CUBE-AI下载。


选取ai开发需要支持的软件包cue-ai,在software packs点select components。

在X-CUBE-AI行下core勾选,application选validation,双核开发板建议选M7系列,点OK完成

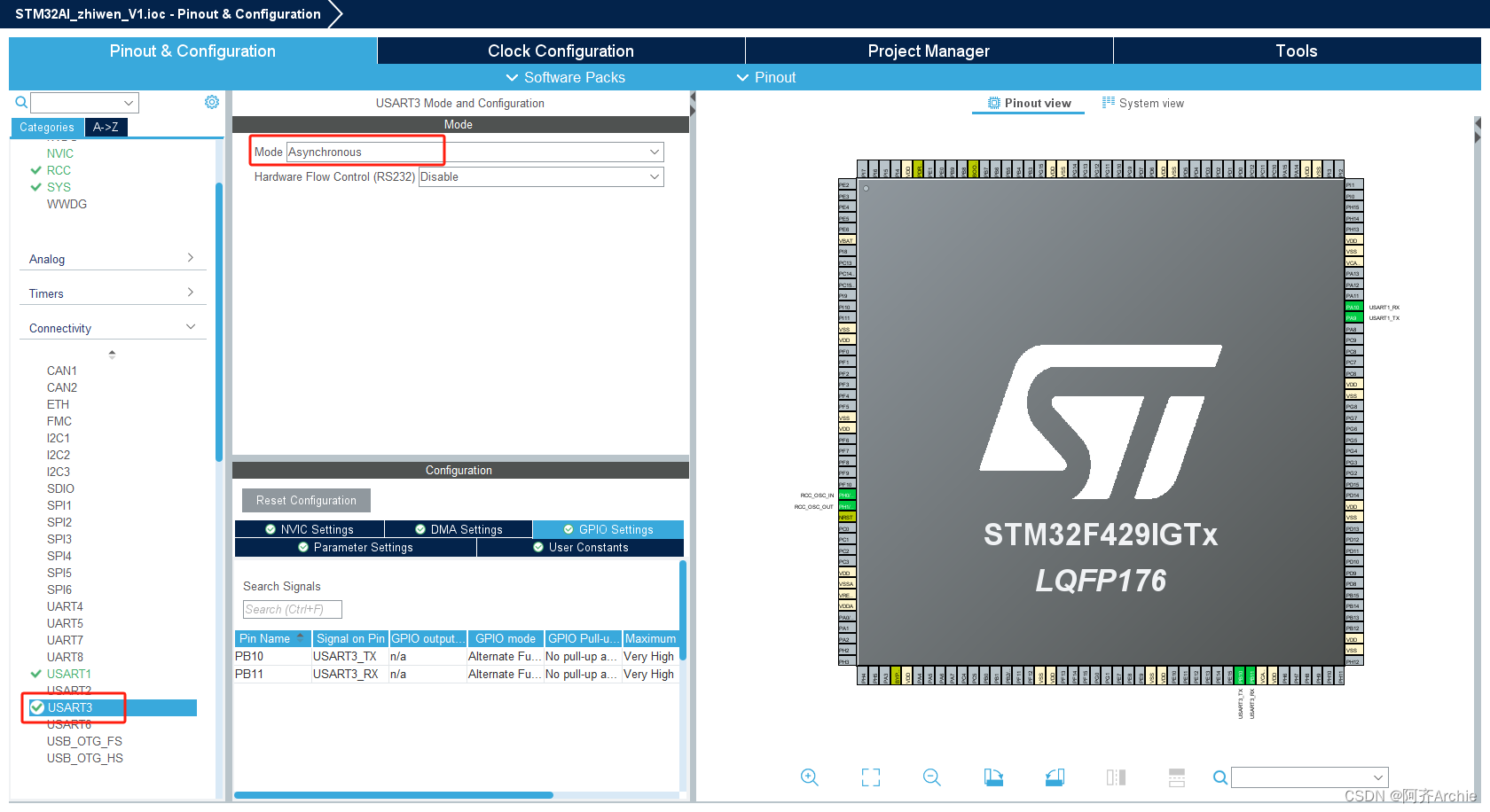
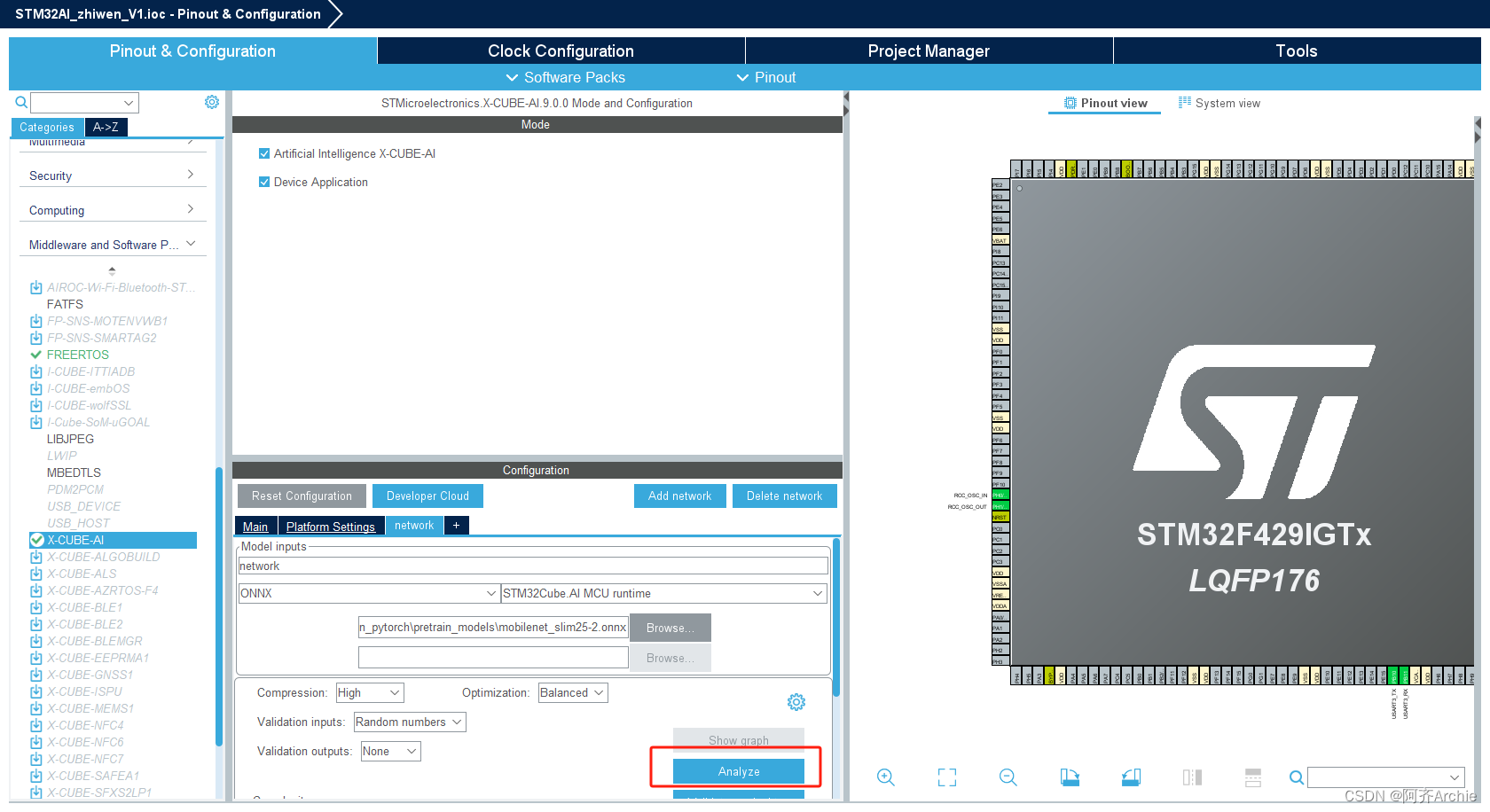
回到引脚配置页面,最下方就是上面导入的CUBE-AI工具包,点击进入配置,选中上方两个√号,然后在configration下方platform setting 选择并配置串口,用来进行数据交互的

回到cube-ai,选择添加网络

根据训练产生的文件进行配置:选择模型文件、压缩比、加载验证数据

点击分析:工具会根据模型与模型参数推断出模型占用(ROM、RAM),进而判断神经网络能否部署到开发板。
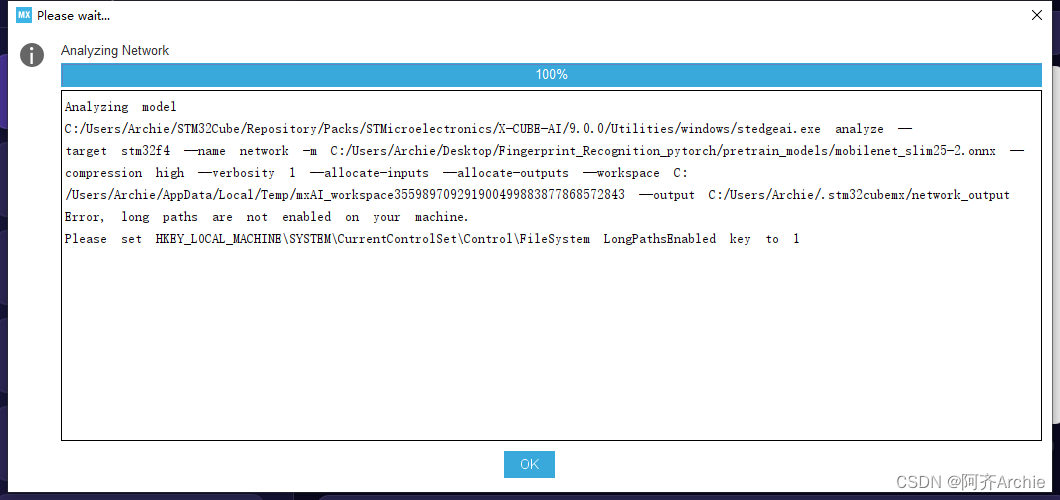
若出现以下报错
错误信息建议通过将注册表中的
LongPathsEnabled键设置为1来启用长路径。以下是具体操作步骤:
- 通过在Windows搜索栏中键入“regedit”并按Enter来打开注册表编辑器。
- 导航至以下键:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem- 在右侧窗格上右键单击,然后选择“新建” -> “DWORD (32位) 值”。
- 将新值命名为
LongPathsEnabled。- 双击
LongPathsEnabled并将其值设置为1。- 单击“确定”以保存更改。
- 关闭注册表编辑器,然后尝试重新运行命令。
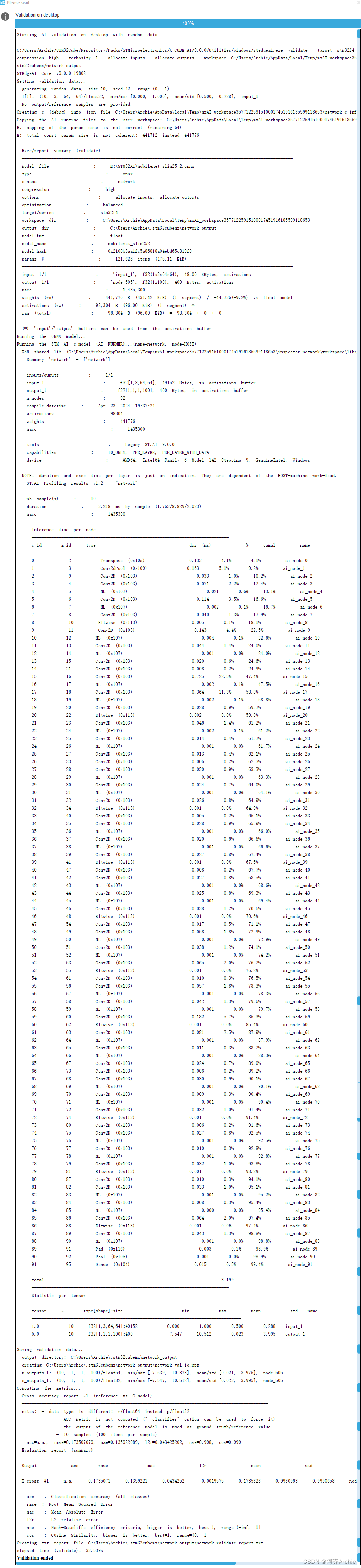
网络分析运行成功

根据ROM、RAM判断出模型可部署
 点击,validation on desktop 在pc上进行模型验证。(也可以实现原模型与转换后模型的对比。)
点击,validation on desktop 在pc上进行模型验证。(也可以实现原模型与转换后模型的对比。)
在前面步骤基础上,点时钟配置栏,系统会自动进行时钟配置

点项目管理栏,进行配置

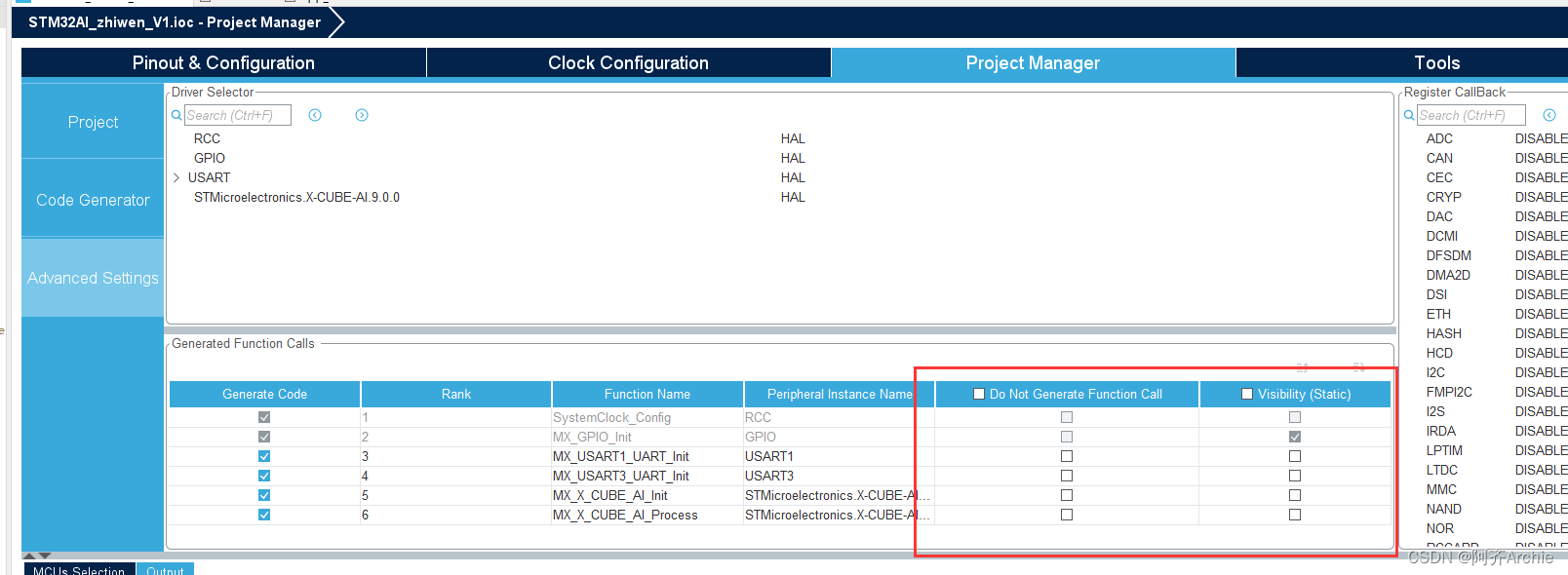
在IDE编译器中,选择project,选择生成代码

生成代码后,右键工程,选择build project

修改代码,等待编译完成后,若没有错误则下一步。
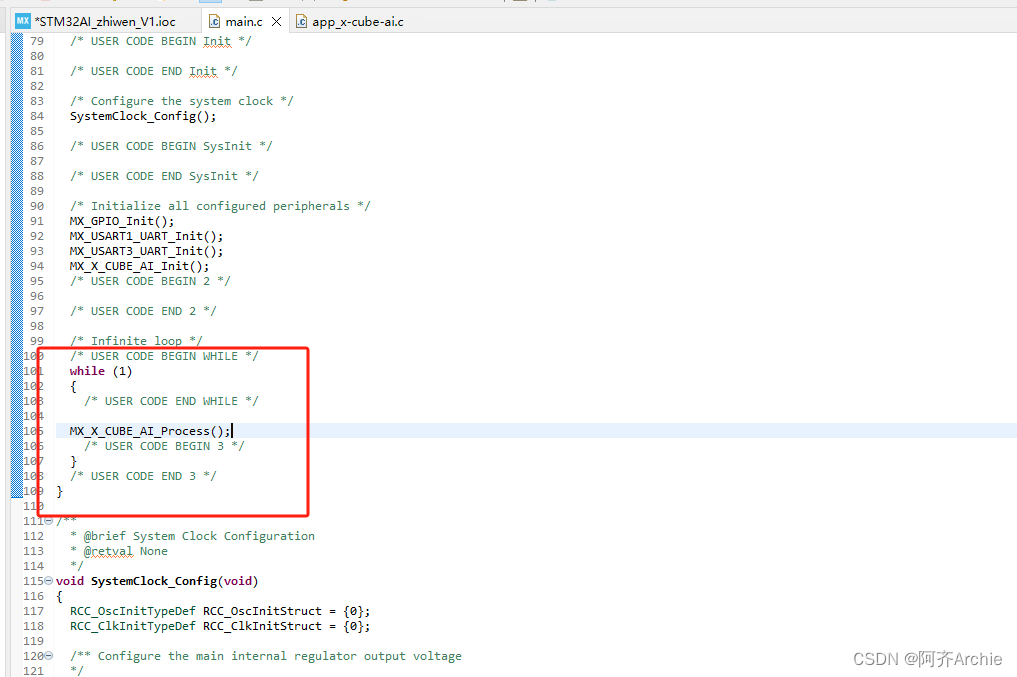

重新编译后,右下侧可以看到占用的flash与RAM,表明模型是否成功部署,
右键工程名运行。

配置,默认即可

烧录完成

至此,模型部署完成,下面开始进行板上模型验证。
4. STM32 CubeUDE上进行模型验证
基于上述步骤,下面进行模型验证,验证AI模型在目标板上的运行情况。验证原理如下:

现在tinyML解决方案厂商都在做AutoML,就是为方便初学者不需要掌握专门的硬件知识就能够自动部署到MCU开发板。因此开发者只需要按照指定的格式准备好数据,validate on target 就是将准备好的数据通过串口传输到RAM内存中,一般是神经网络指定的输入缓冲块,经神经网络后再将结果通过串口传回前端程序显示。
运行前,不要忘记连接开发板,以及检测端口号

双击.ioc文件,会自动返回cubeMX页面,与validate on desktop相同的配置进行validate on target
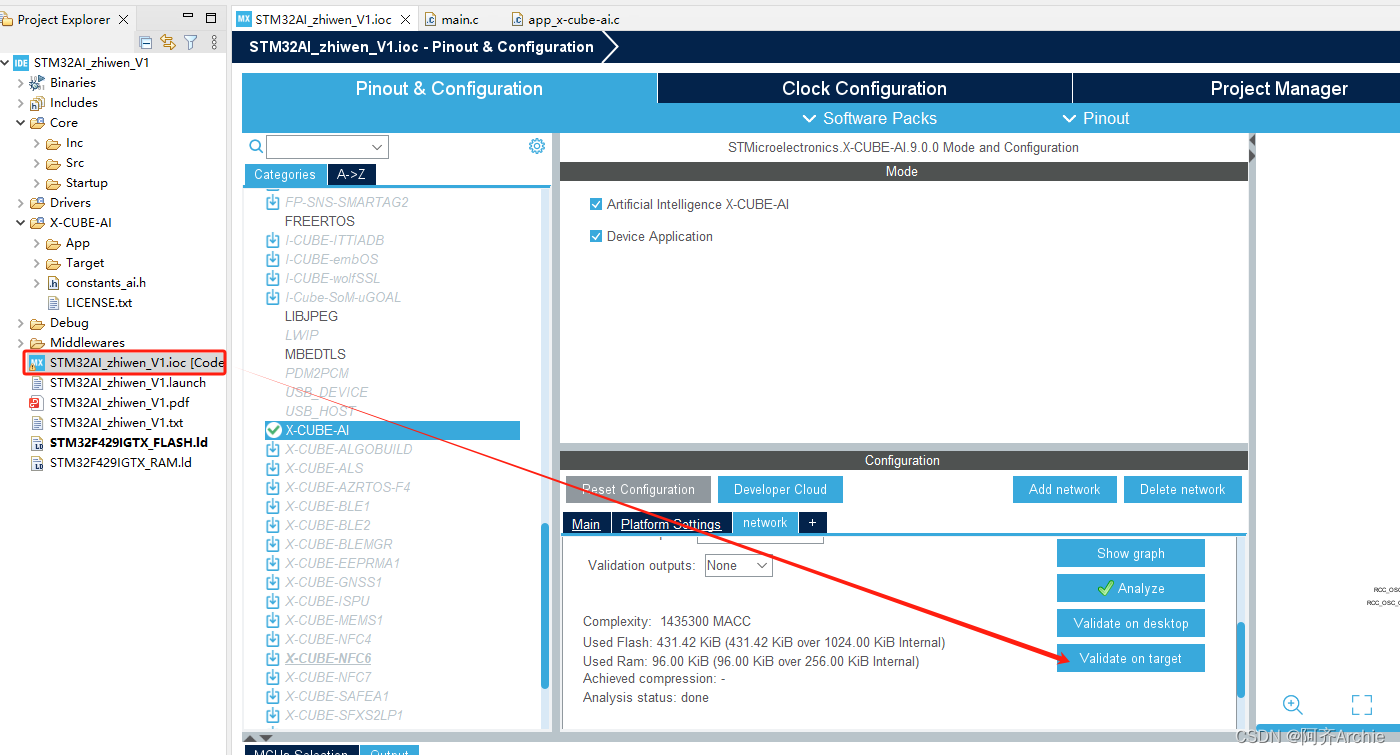
自动即可

validation on target结果如下

重新 validation on desktop和validation on target,结果是一样的,
参数分析

运行时间

5. 结果统计与分析
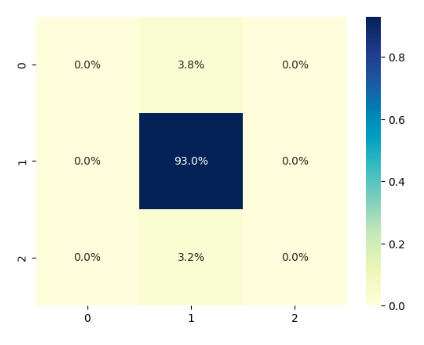
结果分析如下:

当前暂时没有加入测试与验证数据集,将在第二篇加入。
更多详细信息需参考txt报告:





![[vite] ts写配置根目录别名](https://img-blog.csdnimg.cn/direct/1b5be4d8a2e046d19016f146c396a9b3.png)