前言
本期给大家分享介绍如何用Dataloader创建数据集
背景

示例代码
from torch import nn
import torch
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
import torch.functional as F
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
#####----绘制混淆矩阵图----#
from sklearn.metrics import confusion_matrix
from matplotlib.pylab import style
# style.use('ggplot')
from matplotlib import rcParamsconfig = {"font.family": 'serif', # 衬线字体"font.size": 10, # 相当于小四大小"font.serif": ['SimSun'], # 宋体"mathtext.fontset": 'stix', # matplotlib渲染数学字体时使用的字体,和Times New Roman差别不大'axes.unicode_minus': False # 处理负号,即-号
}
rcParams.update(config)
加载数据、创建数据集
def data_read(file_path):""":fun: 读取cwru mat格式数据:param file_path: .mat文件路径 eg: r'D:.../01_示例数据/1750_12k_0.021-OuterRace3.mat':return accl_data: 读取到的加速度数据"""import scipy.io as sciodata = scio.loadmat(file_path) # 加载mat数据data_key_list = list(data.keys()) # mat文件为字典类型,将key变为list类型accl_key = data_key_list[3] # mat文件为字典类型,其加速度列在key_list的第4个accl_data = data[accl_key].flatten() # 获取加速度信号,并展成1维数据accl_data = (accl_data-np.mean(accl_data))/np.std(accl_data) #Z-score标准化数据集return accl_data
def data_spilt(data, num_2_generate=20, each_subdata_length=1024):""":Desription: 将数据分割成n个小块。输入数据data采样点数是400000,分成100个子样本数据,每个子样本数据就是4000个数据点:param data: 要输入的数据:param num_2_generate: 要生成的子样本数量:param each_subdata_length: 每个子样本长度:return spilt_datalist: 分割好的数据,类型为2维list"""data = list(data)total_length = len(data)start_num = 0 # 子样本起始值end_num = each_subdata_length # 子样本终止值step_length = int((total_length - each_subdata_length) / (num_2_generate - 1)) # step_length: 向前移动长度i = 1spilt_datalist = []while i <= num_2_generate:each_data = data[start_num: end_num]each_data = (each_data-np.mean(each_data))/(np.std(each_data)) # 做Z-score归一化spilt_datalist.append(each_data)start_num = 0 + i * step_length;end_num = each_subdata_length + i * step_lengthi = i + 1spilt_data_arr = np.array(spilt_datalist)return spilt_data_arr
划分子样本
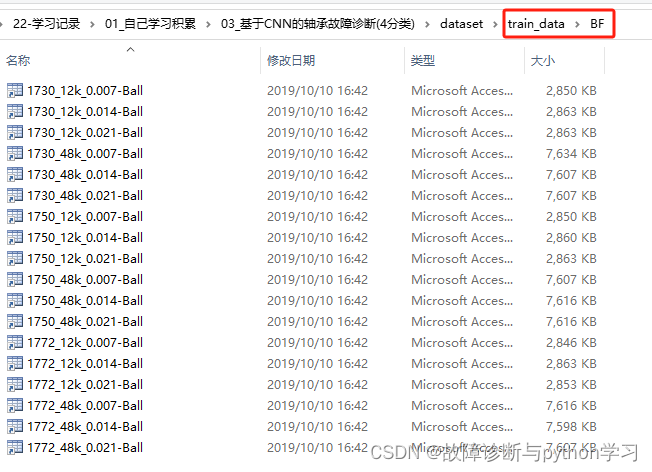
data_base_dir = r'D:\22-学习记录\01_自己学习积累\03_基于CNN的轴承故障诊断(4分类)\dataset/train_data'
fault_type_list = os.listdir(data_base_dir)
file_path_list = list()
train_data = []
train_label = []
for fault_type in fault_type_list:file_name_list = os.listdir(os.path.join(data_base_dir, fault_type))for file_name in file_name_list:print(file_name)num_2_generate = 60 # 每个mat文件生成60个子样本if 'Normal' in file_name:num_2_generate = num_2_generate*6 # Normal状态,每个mat文件生成360个子样本file_path = os.path.join(data_base_dir, fault_type, file_name)fault_type2fault_label = {'BF':'0', 'OF':'1', 'IF':'2', 'Normal':'3'} ##=========获取数据===========##data = data_read(file_path) # 读取单个mat数据##======基于滑动窗方法划分获取更多子样本数据======##sub_data_list = data_spilt(data=data, num_2_generate=num_2_generate)train_label.extend(list(fault_type2fault_label[fault_type]*len(sub_data_list))) # 训练标签 eg: ['0', '0', ...,'3',]train_data.extend(sub_data_list) # 训练数据
输出结果:
1730_12k_0.007-Ball.mat
1730_12k_0.014-Ball.mat
1730_12k_0.021-Ball.mat
1730_48k_0.007-Ball.mat
1730_48k_0.014-Ball.mat
1730_48k_0.021-Ball.mat
...
1772_12k_0.021-OuterRace3.mat
1772_48k_0.007-OuterRace3.mat
1772_48k_0.014-OuterRace6.mat
1772_48k_0.021-OuterRace3.mat
data_base_dir = r'D:\22-学习记录\01_自己学习积累\03_基于CNN的轴承故障诊断(4分类)/dataset/test_data'
fault_type_list = os.listdir(data_base_dir)
file_path_list = list()
test_data = []
test_label = []
for fault_type in fault_type_list:file_name_list = os.listdir(os.path.join(data_base_dir, fault_type))for file_name in file_name_list:print(file_name)num_2_generate = 30 # 每个mat文件生成30个子样本 if 'Normal' in file_name:num_2_generate = num_2_generate*6 # Normal状态,每个mat文件生成180个子样本file_path = os.path.join(data_base_dir, fault_type, file_name)fault_type2fault_label = {'BF':'0', 'OF':'1', 'IF':'2', 'Normal':'3'}##=========获取数据===========##data = data_read(file_path) # 读取单个mat数据##======基于滑动窗方法划分获取更多子样本数据======##sub_data_list = data_spilt(data=data, num_2_generate=num_2_generate)test_label.extend(list(fault_type2fault_label[fault_type]*len(sub_data_list))) # 测试标签 eg: ['0', '0', ...,'3',]test_data.extend(sub_data_list) # 测试数据
输出结果:
1797_12k_0.007-Ball.mat
1797_12k_0.014-Ball.mat
1797_12k_0.021-Ball.mat
1797_48k_0.007-Ball.mat
...
1797_12k_0.021-OuterRace3.mat
1797_48k_0.007-OuterRace3.mat
1797_48k_0.014-OuterRace6.mat
1797_48k_0.021-OuterRace3.mat
创建dataloader
from torch.utils.data import DataLoader
from torch.utils.data import TensorDatasettrain_data = np.array(train_data) #训练数据
train_label = np.array((train_label), dtype=int) #训练标签 array([0, 0, 0, ..., 1, 1, 1])train_x = torch.from_numpy(train_data).type(torch.float32) ##torch.Size([2880, 1024])
train_y = torch.from_numpy(train_label).type(torch.LongTensor) ##torch.Size([2880])
train_x = torch.unsqueeze(train_x, dim=1) ##扩展成3维 torch.Size([2880, 1, 1024])test_data = np.array(test_data) #测试数据
test_label = np.array((test_label), dtype=int) #测试标签array([0, 0, 0, ..., 1, 1, 1])test_x = torch.from_numpy(test_data).type(torch.float32) ##torch.Size([720, 1024])
test_y = torch.from_numpy(test_label).type(torch.LongTensor) ##torch.Size([720])
test_x = torch.unsqueeze(test_x, dim=1) ##torch.Size([720, 1, 1024])
看看train_data的维度
train_data.shape
# 输出结果
(4320, 1024)
#创建dataset
from sklearn.model_selection import train_test_split
train_ds = TensorDataset(train_x, train_y)
train_ds,valid_ds = train_test_split(train_ds, test_size = 0.2,random_state = 42) #将训练集分隔维训练集和测试集,分割比例5:1
test_ds = TensorDataset(test_x, test_y)
#创建dataloader
batch_size = 64 # 批次大小
train_dl = DataLoader(dataset = train_ds, batch_size = batch_size, shuffle=True) #shuffle是进行乱序
valid_dl = DataLoader(dataset = valid_ds, shuffle=True, batch_size = batch_size)
test_dl = DataLoader(dataset = test_ds, batch_size = batch_size, shuffle=False)
for i, (imgs, labels) in enumerate(train_dl):print(i, imgs, labels)
## 输出结果
0
tensor([[[-0.3515, 0.3796, 1.1076, ..., -1.5466, -1.2220, -0.3242]],[[ 1.3776, 1.4640, 0.7423, ..., 0.1370, 0.3632, 0.6326]],[[-0.4793, -0.6978, -0.5840, ..., -0.6917, -1.3257, -1.4273]],...,[[-0.2387, -0.5382, -1.1767, ..., 0.8166, 0.7749, -2.3905]],[[-0.9560, -1.3880, -1.7271, ..., 0.4720, 0.2392, 0.1732]],[[ 0.2588, 0.0780, -0.5720, ..., -0.0647, 0.4554, 1.2545]]]) tensor([3, 3, 3, 1, 2, 3, 3, 0, 2, 3, 2, 1, 3, 2, 2, 2, 3, 2, 2, 0, 2, 1, 2, 2,1, 2, 3, 3, 1, 2, 1, 0, 2, 1, 3, 0, 1, 3, 1, 3, 3, 1, 1, 3, 2, 0, 0, 1,0, 0, 0, 2, 1, 0, 0, 3, 1, 3, 3, 0, 2, 2, 0, 3])...