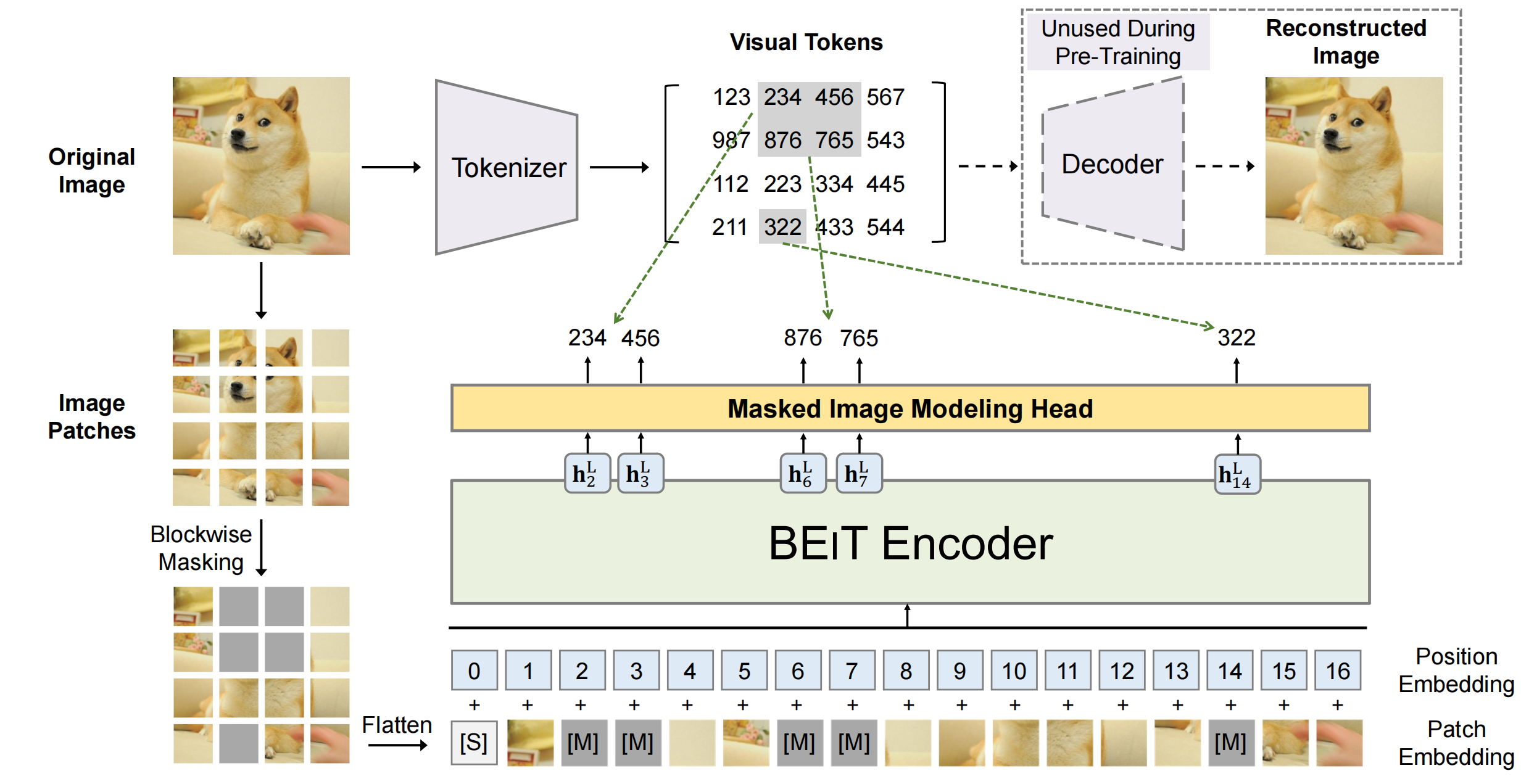
本系列是算法通关手册LeeCode的学习笔记
算法通关手册(LeetCode) | 算法通关手册(LeetCode) (itcharge.cn)
目录
并查集(Union Find)
基于数组实现的快速查询并查集
基于森林实现的快速合并并查集
路径压缩
隔代压缩
完全压缩
按深度合并
按大小合并
例题
并查集(Union Find)
一种树型的数据结构,用于处理一系列灭有重复元素集合的合并及查询问题。
合并(Union):将两个元素合并成一个集合;
查找(Find):确定某个元素属于哪个集合。通常返回集合内的某个【代表元素】。
并查集的主要任务有:
合并 union(x, y):将集合 x 和集合 y 合并成一个集合;
查找 find(x):查找元素 x 属于哪个集合;
查找 is_connected(x, y):查询元素 x 和元素 y 是否在同一个集合中。
出于【快速查询】和【快速合并】两种目的,可以有两种实现方式。
基于数组实现的快速查询并查集
如果希望并查集的查询效率高一些,可以使用一个数组来表示集合中的元素,数组元素和集合元素是一一对应的,可以将数组的索引值作为每个元素的集合编号,称为 id。
初始化:将每个元素的集合编号初始化为数组下标索引。则所有元素的 id 都是唯一的,代表着每个元素单独属于一个集合;
合并:将其中一个集合中的所有元素 id 更改为另一个集合中的 id;
查找:如果两个元素的 id 一样,则说明它们属于同一个集合,否则不属于同一集合。

初始化后,每个元素属于各自的集合,即有 0 到 7 这 8 个集合,每个集合有 1 个元素
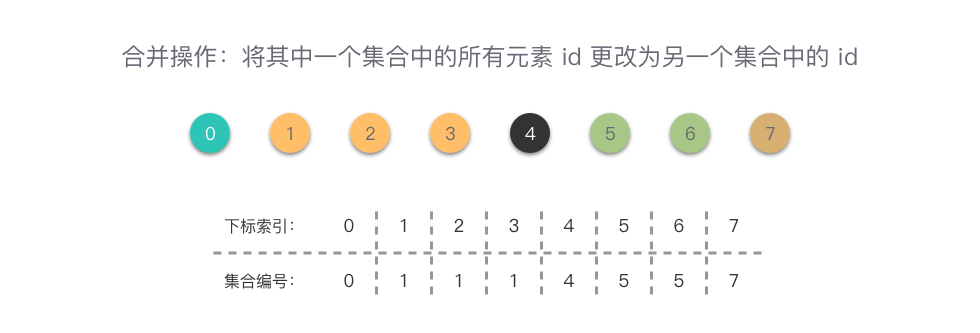
合并后,为 { 0 }, { 1, 2, 3 }, { 4 }, { 5, 6 }, { 7 } 这 5 个集合。
class UnionFindArray:def __init__(self, n):self.ids = [i for i in range(n)]def find(self, x):return self.ids[x]def union(self, x, y):x_id = self.find(x)y_id = self.find(y)if x_id == y_id:returnfor i in range(len(self.ids)):if self.ids[i] == y_id: # 找到要合并的数组self.ids[i] = x_id # 完成合并,合并后的数组标号为 x_idreturndef is_connected(self, x, y):return self.find(x) == self.find(y)单次查询操作的时间复杂度是 O(1);
单次合并操作的时间复杂度为 O(n)
基于森林实现的快速合并并查集
为提高合并操作的效率,我们可以使用一个【森林】来存储所有集合。每一棵树代表一个集合,树上的每个节点都是一个元素,树根节点为这个集合的代表元素。
PS:与普通树形结构不同的是,基于森林实现的并查集中,树中的子节点是指向父节点的。
我们使用一个数组 fa 来记录这个森林。我们用 fa[x] 来保存 x 的父节点的集合编号,代表着 x 指向父节点 fa[x]。
初始化:将每个元素的集合编号初始化为数组 fa 的下标索引。所有元素的根节点的集合编号不一样,代表着每个元素单独属于一个集合;
合并操作:需要将两个集合的树根节点相连接,令其中一个集合的树根节点指向另一个集合的树根节点;
查找操作:分别从两个元素开始,通过数组 fa 存储的值,不断访问父节点,直到达到树根节点。判断两个元素的树根节点是否一样。

进行合并操作:
union(4,5)、union(6,7)、union(4,7)
fa[4] = fa[5] = fa[6] = fa[fa[7]]

结果为 { 0 },{ 1 },{ 2 },{ 3 },{ 4,5,6,7 }
class UnionFind:def __init__(self, n):self.fa = [i for i in range(n)]def find(self, x):while self.fa[x] != x:x = self.fa[x]return xdef union(self, x, y):root_x = self.find(x)root_y = self.find(y)if root_x == root_y:returnself.fa[root_x] = root_yreturndef is_connected(self, x, y):return self.find(x) == self.find(y)路径压缩
在集合很大或者树很不平衡时,使用【快速合并】实现并查集的代码效率很差
如

单词查询的复杂度会达到 O(n)。
为避免上图情况,可以使用路径压缩:
在从底向上查找根节点的过程中,如果此时访问的不是根节点,则可以把这个节点尽量
向上移动以下,从而减少树的层数,这个过程叫做路径压缩,又分为隔代压缩和完全压缩。
隔代压缩
在查询时,两步一压缩,循环执行【把当前节点指向它父节点的父节点】这一操作,从而减少树的深度。
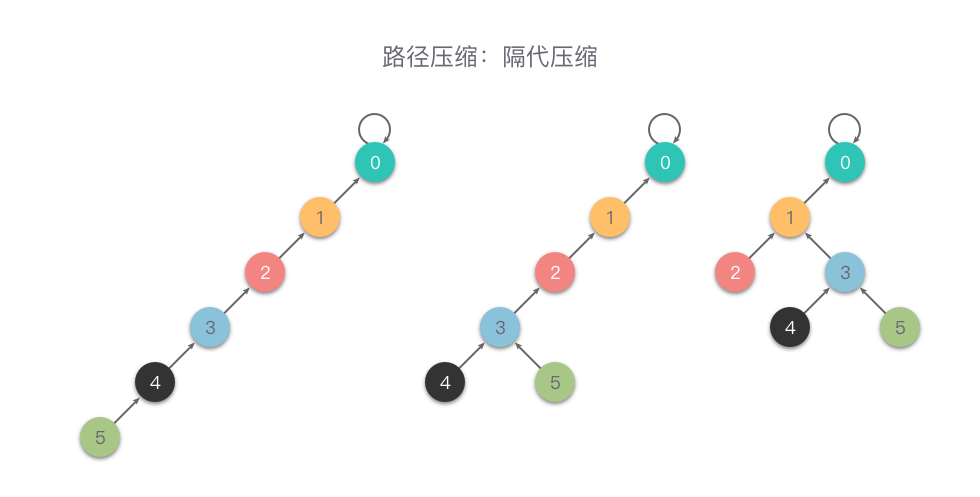
def throwBackFind(self, x):while self.fa[x] != x:self.fa[x] = self.fa[self.fa[x]]x = self.fa[x]return x完全压缩
在查询时,把被查询的节点到根节点的路径上的所有节点的父节点设置为根节点,从而减小树的深度。

def completeFind(self, x):if self.fa[x] != x:self.fa[x] = self.completeFind(self.fa[x])return self.fa[x]后续还有【按深度合并】与【按大小合并】,这里给出图解与代码,思路与上述大致相同,具体的细节可以看代码中的注释。
按深度合并
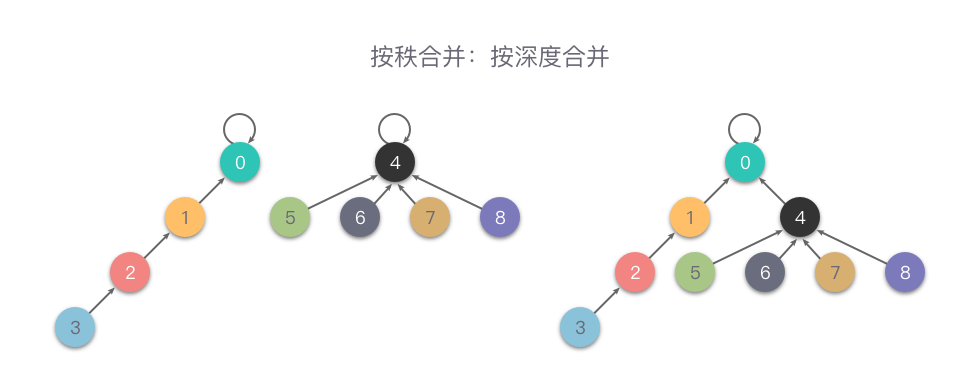
class UnionFind:def __init__(self, n): # 初始化self.fa = [i for i in range(n)] # 每个元素的集合编号初始化为数组 fa 的下标索引self.rank = [1 for i in range(n)] # 每个元素的深度初始化为 1def find(self, x): # 查找元素根节点的集合编号内部实现方法while self.fa[x] != x: # 递归查找元素的父节点,直到根节点self.fa[x] = self.fa[self.fa[x]] # 隔代压缩x = self.fa[x]return x # 返回元素根节点的集合编号def union(self, x, y): # 合并操作:令其中一个集合的树根节点指向另一个集合的树根节点root_x = self.find(x)root_y = self.find(y)if root_x == root_y: # x 和 y 的根节点集合编号相同,说明 x 和 y 已经同属于一个集合return Falseif self.rank[root_x] < self.rank[root_y]: # x 的根节点对应的树的深度 小于 y 的根节点对应的树的深度self.fa[root_x] = root_y # x 的根节点连接到 y 的根节点上,成为 y 的根节点的子节点elif self.rank[root_y] > self.rank[root_y]: # x 的根节点对应的树的深度 大于 y 的根节点对应的树的深度self.fa[root_y] = root_x # y 的根节点连接到 x 的根节点上,成为 x 的根节点的子节点else: # x 的根节点对应的树的深度 等于 y 的根节点对应的树的深度self.fa[root_x] = root_y # 向任意一方合并即可self.rank[root_y] += 1 # 因为层数相同,被合并的树必然层数会 +1return Truedef is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合return self.find(x) == self.find(y)
按大小合并

class UnionFind:def __init__(self, n): # 初始化self.fa = [i for i in range(n)] # 每个元素的集合编号初始化为数组 fa 的下标索引self.size = [1 for i in range(n)] # 每个元素的集合个数初始化为 1def find(self, x): # 查找元素根节点的集合编号内部实现方法while self.fa[x] != x: # 递归查找元素的父节点,直到根节点self.fa[x] = self.fa[self.fa[x]] # 隔代压缩优化x = self.fa[x]return x # 返回元素根节点的集合编号def union(self, x, y): # 合并操作:令其中一个集合的树根节点指向另一个集合的树根节点root_x = self.find(x)root_y = self.find(y)if root_x == root_y: # x 和 y 的根节点集合编号相同,说明 x 和 y 已经同属于一个集合return Falseif self.size[root_x] < self.size[root_y]: # x 对应的集合元素个数 小于 y 对应的集合元素个数self.fa[root_x] = root_y # x 的根节点连接到 y 的根节点上,成为 y 的根节点的子节点self.size[root_y] += self.size[root_x] # y 的根节点对应的集合元素个数 累加上 x 的根节点对应的集合元素个数elif self.size[root_x] > self.size[root_y]: # x 对应的集合元素个数 大于 y 对应的集合元素个数self.fa[root_y] = root_x # y 的根节点连接到 x 的根节点上,成为 x 的根节点的子节点self.size[root_x] += self.size[root_y] # x 的根节点对应的集合元素个数 累加上 y 的根节点对应的集合元素个数else: # x 对应的集合元素个数 小于 y 对应的集合元素个数self.fa[root_x] = root_y # 向任意一方合并即可self.size[root_y] += self.size[root_x]return Truedef is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合return self.find(x) == self.find(y)
例题
990. 等式方程的可满足性
class UnionFind:def __init__(self, n): # 初始化self.fa = [i for i in range(n)] # 每个元素的集合编号初始化为数组 fa 的下标索引def __find(self, x): # 查找元素根节点的集合编号内部实现方法while self.fa[x] != x: # 递归查找元素的父节点,直到根节点self.fa[x] = self.fa[self.fa[x]] # 隔代压缩优化x = self.fa[x]return x # 返回元素根节点的集合编号def union(self, x, y): # 合并操作:令其中一个集合的树根节点指向另一个集合的树根节点root_x = self.__find(x)root_y = self.__find(y)if root_x == root_y: # x 和 y 的根节点集合编号相同,说明 x 和 y 已经同属于一个集合return Falseself.fa[root_x] = root_y # x 的根节点连接到 y 的根节点上,成为 y 的根节点的子节点return Truedef is_connected(self, x, y): # 查询操作:判断 x 和 y 是否同属于一个集合return self.__find(x) == self.__find(y)class Solution:def equationsPossible(self, equations: List[str]) -> bool:union_find = UnionFind(26)for eqation in equations:if eqation[1] == "=":index1 = ord(eqation[0]) - 97index2 = ord(eqation[3]) - 97union_find.union(index1, index2)for eqation in equations:if eqation[1] == "!":index1 = ord(eqation[0]) - 97index2 = ord(eqation[3]) - 97if union_find.is_connected(index1, index2):return Falsereturn True
547. 省份数量
class UnionFind:def __init__(self, n):self.fa = [i for i in range(n)]def find(self, x):if self.fa[x] != x:self.fa[x] = self.find(self.fa[x])return self.fa[x]def union(self, x, y):root_x = self.find(x)root_y = self.find(y)if root_x == root_y:returnself.fa[root_x] = root_yreturndef is_connected(self, x, y):return self.find(x) == self.find(y)class Solution:def findCircleNum(self, isConnected: List[List[int]]) -> int:n = len(isConnected)uf = UnionFind(n)for i in range(n):for j in range(i + 1, n):if isConnected[i][j] == 1:uf.union(i, j)res = set()for i in range(n):res.add(uf.find(i))return len(res)1319. 连通网络的操作次数
class UnionFind:def __init__(self, n):self.fa = [i for i in range(n)]self.size = [1 for i in range(n)]def find(self, x):if self.fa[x] != x:self.fa[x] = self.find(self.fa[x])return self.fa[x]def union(self, x, y):root_x = self.find(x)root_y = self.find(y)if root_x == root_y:returnself.fa[root_x] = root_yself.size[root_y] += self.size[root_x]returndef is_connected(self, x, y):return self.find(x) == self.find(y)class Solution:def makeConnected(self, n: int, connections: List[List[int]]) -> int:if len(connections) < n - 1 :return -1uf = UnionFind(n)res = 0for num in connections:if uf.find(num[0]) == uf.find(num[1]):continueuf.union(num[0], num[1])for i in range(1, n):if uf.is_connected(i - 1, i):continueuf.union(i - 1, i)res += 1return res
算法通关手册(LeetCode) | 算法通关手册(LeetCode)
原文内容在这里,如有侵权,请联系我删除。