目录
- 引言
- 代码目录
- segment-anything 代码详解
- build_sam.py
- predictor.py
- automatic_mask_generator.py
引言
从去年年初至今,SAM(Segment Anything )已经问世快一年了,SAM凭借其强大而突出的泛化性能在各项任务上取得了优异的表现,广大的研究者竞相跟进,对SAM以及其应用做了广泛而深入的研究,产生了许许多多的研究成果。写下这篇文章的时间是2024年的3月13日,写作这篇文章一方面是让自己对SAM有一个更清晰透彻的了解,另一方面是为后来者提供一下学习上的方面。对于论文,网上有很多很多的讲解,我在此就不加赘述了,本文主要关注代码的部分,对代码进行逐层的剖析。
代码目录
论文链接地址:https://ai.facebook.com/research/publications/segment-anything/
github仓库:https://github.com/facebookresearch/segment-anything
我下载代码的时间是2024年的3月13日,代码的完整目录结构是这样的
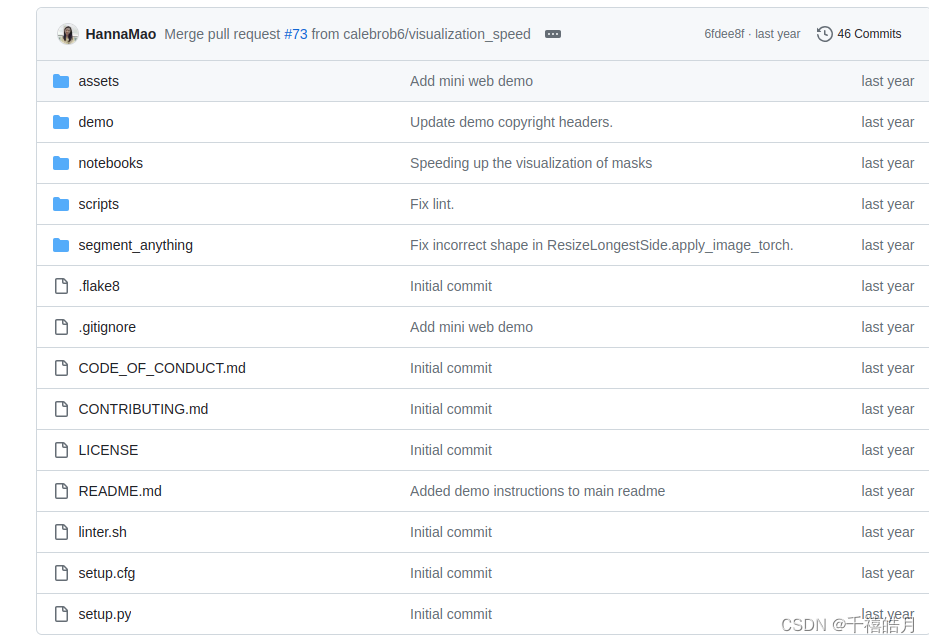
其中:
assets:存放的是图片
demo:存放的是前端部署的代码
notebooks:存的是使用的教程,包含三部分,第一部分是onnx跨平台实例,第二部分automatic_mask_generator_example是全景分割,第三部分predictor_example是prompt(使用point或bbox)分割
script:存放的是一些导出的脚本
segment_anything:这个是项目的核心代码
其余的目录和文件可以忽略不计
因此作为一个初学者,你可以对这个目录进行化简,方便学习和理解代码的全貌。(注:项目的代码可以不安装,从github下载下来后,配置完权重后可以直接运行,这种方式比较适合学习和后续研究)
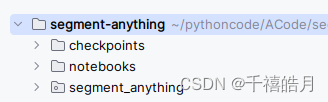
上图是目录化简后的全貌,多出的checkpoints 目录存放的是网络的权重:vit_h,vit_l,vit_b ,在显存不是很充足的情况下(GPU 显存小于12G)请选用vit_b。
segment-anything 代码详解
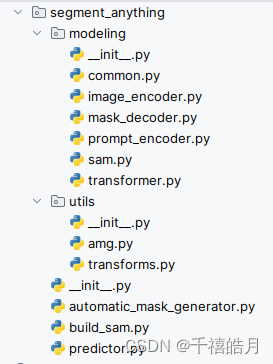
build_sam.py
这个文件包含三层的封装,最外层是sam_model_registry,它提供了统一的接口,用来选择vit_h,vit_l,vit_b,默认使用vit_h
sam_model_registry = {"default": build_sam_vit_h,"vit_h": build_sam_vit_h,"vit_l": build_sam_vit_l,"vit_b": build_sam_vit_b,
}
然后是三种模型的构建,也就是第二层build_sam_vit_x,这三个sam模型的差别主要体现维度,深度,注意力机制头的个数,在哪几层做注意力机制
def build_sam_vit_h(checkpoint=None):return _build_sam(encoder_embed_dim=1280,encoder_depth=32,encoder_num_heads=16,encoder_global_attn_indexes=[7, 15, 23, 31],checkpoint=checkpoint,)build_sam = build_sam_vit_hdef build_sam_vit_l(checkpoint=None):return _build_sam(encoder_embed_dim=1024,encoder_depth=24,encoder_num_heads=16,encoder_global_attn_indexes=[5, 11, 17, 23],checkpoint=checkpoint,)def build_sam_vit_b(checkpoint=None):return _build_sam(encoder_embed_dim=768,encoder_depth=12,encoder_num_heads=12,encoder_global_attn_indexes=[2, 5, 8, 11],checkpoint=checkpoint,)
这段代码是sam 模型构建的统一代码,主要构建一个image_encoder,prompt_encoder,mask_decoder,以及在有权重的情况下加载sam的权重
def _build_sam(encoder_embed_dim,encoder_depth,encoder_num_heads,encoder_global_attn_indexes,checkpoint=None,
):prompt_embed_dim = 256image_size = 1024vit_patch_size = 16image_embedding_size = image_size // vit_patch_sizesam = Sam(image_encoder=ImageEncoderViT(depth=encoder_depth,embed_dim=encoder_embed_dim,img_size=image_size,mlp_ratio=4,norm_layer=partial(torch.nn.LayerNorm, eps=1e-6),num_heads=encoder_num_heads,patch_size=vit_patch_size,qkv_bias=True,use_rel_pos=True,global_attn_indexes=encoder_global_attn_indexes,window_size=14,out_chans=prompt_embed_dim,),prompt_encoder=PromptEncoder(embed_dim=prompt_embed_dim,image_embedding_size=(image_embedding_size, image_embedding_size),input_image_size=(image_size, image_size),mask_in_chans=16,),mask_decoder=MaskDecoder(num_multimask_outputs=3,transformer=TwoWayTransformer(depth=2,embedding_dim=prompt_embed_dim,mlp_dim=2048,num_heads=8,),transformer_dim=prompt_embed_dim,iou_head_depth=3,iou_head_hidden_dim=256,),pixel_mean=[123.675, 116.28, 103.53],pixel_std=[58.395, 57.12, 57.375],)sam.eval()if checkpoint is not None:with open(checkpoint, "rb") as f:state_dict = torch.load(f)sam.load_state_dict(state_dict)return sam
predictor.py
predictor.py文件实现了SamPredictor类,该类中包含两个重要的函数,一个是set_image函数,一个是predict函数,通过这两个函数可以反复高效地预测图片。
首先来看set_image这个函数
- 对输入的图像按照长边和目标尺寸的比例缩放
- 转换成tensor
- 转换成[1,3,h,w]的形式
- 调用
set_torch_image函数获得image在经过了image_encoder之后的特征或者说是image_embedding
def set_image(self,image: np.ndarray, # 需要是[h,w,c]的形式,uint8类型image_format: str = "RGB", #RGB ,BGR) -> None:assert image_format in ["RGB","BGR",], f"image_format must be in ['RGB', 'BGR'], is {image_format}." #对类型进行断言判断if image_format != self.model.image_format:image = image[..., ::-1]# Transform the image to the form expected by the modelinput_image = self.transform.apply_image(image) #对按长边和目标尺寸的比例缩放input_image_torch = torch.as_tensor(input_image, device=self.device) #转换成tensorinput_image_torch = input_image_torch.permute(2, 0, 1).contiguous()[None, :, :, :] #转换成[1,3,h,w]self.set_torch_image(input_image_torch, image.shape[:2])
对于set_torch_image这个函数,主要有两个功能
- 对transformed_image进行预处理
减去imagenet均值,除以imagenet标准差 - 对输入图像进行
image_encoder编码
def set_torch_image(self,transformed_image: torch.Tensor,original_image_size: Tuple[int, ...], #原始的未经转换过的图像的大小) -> None:assert (len(transformed_image.shape) == 4and transformed_image.shape[1] == 3and max(*transformed_image.shape[2:]) == self.model.image_encoder.img_size), f"set_torch_image input must be BCHW with long side {self.model.image_encoder.img_size}."self.reset_image()self.original_size = original_image_sizeself.input_size = tuple(transformed_image.shape[-2:])input_image = self.model.preprocess(transformed_image) #图像预处理,减去均值,除以方差self.features = self.model.image_encoder(input_image) #对图像进行进行image_encoder编码self.is_image_set = True
set_image只需要做一次,反复使用,predict函数可以做多次,predict函数有以下几个参数
point_coords: 是一个nx2的数组,以[x,y]的形式传入
point_labels: 长度为n的数组,前景点为1,背景点为0
bbox :长度为4的数组,形式为xyxy
mask_input:低分辨率的mask,来源于前一个迭代,形状为1xhxw, 其中h=w=256
multimask_output :当为true的时候会返回3个mask,对于模棱两可的prompt比如一个点,多输出可以比单单输出产生更高质量的Mask,如果只有一个mask是被需要的,可以通过quality score 来筛选mask,对于非模棱两可的输入,比如多个prompt,将multmask_output设置为false可以得到更好的结果
return_logits:如果设置为true,返回非抑制后的值,否则返回二值化的mask
def predict(self,point_coords: Optional[np.ndarray] = None,point_labels: Optional[np.ndarray] = None,box: Optional[np.ndarray] = None,mask_input: Optional[np.ndarray] = None,multimask_output: bool = True,return_logits: bool = False,) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:"""Predict masks for the given input prompts, using the currently set image.Returns:(np.ndarray): The output masks in CxHxW format, where C is thenumber of masks, and (H, W) is the original image size.(np.ndarray): An array of length C containing the model'spredictions for the quality of each mask.(np.ndarray): An array of shape CxHxW, where C is the numberof masks and H=W=256. These low resolution logits can be passed toa subsequent iteration as mask input."""if not self.is_image_set:raise RuntimeError("An image must be set with .set_image(...) before mask prediction.")# Transform input promptscoords_torch, labels_torch, box_torch, mask_input_torch = None, None, None, Noneif point_coords is not None:assert (point_labels is not None), "point_labels must be supplied if point_coords is supplied."point_coords = self.transform.apply_coords(point_coords, self.original_size) #和图像尺寸一致coords_torch = torch.as_tensor(point_coords, dtype=torch.float, device=self.device)labels_torch = torch.as_tensor(point_labels, dtype=torch.int, device=self.device)coords_torch, labels_torch = coords_torch[None, :, :], labels_torch[None, :] #在原有的基础上扩充一个维度[1,n,2] ,[1,n]if box is not None:box = self.transform.apply_boxes(box, self.original_size)box_torch = torch.as_tensor(box, dtype=torch.float, device=self.device)box_torch = box_torch[None, :] #在原有的基础上扩充一个维度[1,n,4]if mask_input is not None:mask_input_torch = torch.as_tensor(mask_input, dtype=torch.float, device=self.device)mask_input_torch = mask_input_torch[None, :, :, :]masks, iou_predictions, low_res_masks = self.predict_torch(coords_torch,labels_torch,box_torch,mask_input_torch,multimask_output,return_logits=return_logits,)masks_np = masks[0].detach().cpu().numpy()iou_predictions_np = iou_predictions[0].detach().cpu().numpy()low_res_masks_np = low_res_masks[0].detach().cpu().numpy()return masks_np, iou_predictions_np, low_res_masks_np
在predict函数中调用了 predict_torch这个函数来完成mask的预测,首先是调用了prompt_encoder,然后调用mask_decoder进行解码,最后对mask进行后处理
def predict_torch(self,point_coords: Optional[torch.Tensor],point_labels: Optional[torch.Tensor],boxes: Optional[torch.Tensor] = None,mask_input: Optional[torch.Tensor] = None,multimask_output: bool = True,return_logits: bool = False,) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:if not self.is_image_set:raise RuntimeError("An image must be set with .set_image(...) before mask prediction.")if point_coords is not None:points = (point_coords, point_labels)else:points = None# Embed promptssparse_embeddings, dense_embeddings = self.model.prompt_encoder(points=points,boxes=boxes,masks=mask_input,)# Predict maskslow_res_masks, iou_predictions = self.model.mask_decoder(image_embeddings=self.features,image_pe=self.model.prompt_encoder.get_dense_pe(),sparse_prompt_embeddings=sparse_embeddings,dense_prompt_embeddings=dense_embeddings,multimask_output=multimask_output,)# Upscale the masks to the original image resolutionmasks = self.model.postprocess_masks(low_res_masks, self.input_size, self.original_size)if not return_logits:masks = masks > self.model.mask_thresholdreturn masks, iou_predictions, low_res_masks
图像处理流程
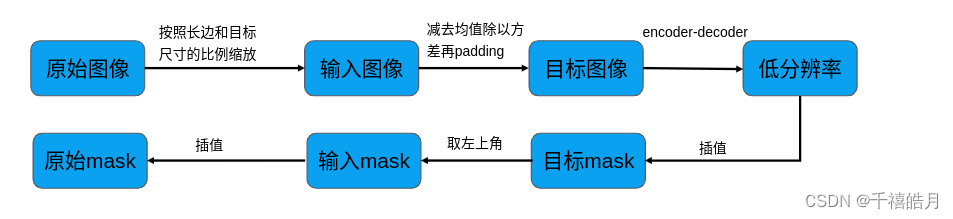
automatic_mask_generator.py
automatic_mask_generator.py中实现了自动全景分割的类SamAutomaticMaskGenerator,通过产生一些列的网格点prompt,调用SamPredictor生成mask,然后去除低质量的点
model :SAM 模型
points_per_side:每条边的采样点个数,总点数是points_per_side的平方,如果该参数没有指定,需要显示指定point_grids
points_per_batch:每批次运行的点的个数,数字越大越快,但是会消耗更多的显存
pred_iou_thresh: iou阈值
stability_score_thresh :score阈值
stability_score_offset:没看懂
box_nms_thresh:非极大值抑制
crop_n_layers :层数,大于n>0时,在这张图片上进行n次全图分割
crop_nms_thresh:非极大值抑制
crop_overlap_ratio:crop的重合比例
crop_n_points_downscale_factor :每层每条边的点数降多少倍,就比如如果为2,每条边的点数就变成16,总点数256
point_grids :一系列的点
min_mask_region_area :最小区域面积
output_mode :输出模式
def __init__(self,model: Sam,points_per_side: Optional[int] = 32,points_per_batch: int = 64,pred_iou_thresh: float = 0.88,stability_score_thresh: float = 0.95,stability_score_offset: float = 1.0,box_nms_thresh: float = 0.7,crop_n_layers: int = 0,crop_nms_thresh: float = 0.7,crop_overlap_ratio: float = 512 / 1500,crop_n_points_downscale_factor: int = 1,point_grids: Optional[List[np.ndarray]] = None,min_mask_region_area: int = 0,output_mode: str = "binary_mask",) -> None:"""Using a SAM model, generates masks for the entire image.Generates a grid of point prompts over the image, then filterslow quality and duplicate masks. The default settings are chosenfor SAM with a ViT-H backbone.assert (points_per_side is None) != (point_grids is None), "Exactly one of points_per_side or point_grid must be provided."#生成网格点,或者批量指定if points_per_side is not None:self.point_grids = build_all_layer_point_grids(points_per_side,crop_n_layers,crop_n_points_downscale_factor,)elif point_grids is not None:self.point_grids = point_gridselse:raise ValueError("Can't have both points_per_side and point_grid be None.")assert output_mode in ["binary_mask","uncompressed_rle","coco_rle",], f"Unknown output_mode {output_mode}."if output_mode == "coco_rle":from pycocotools import mask as mask_utils # type: ignore # noqa: F401if min_mask_region_area > 0:import cv2 # type: ignore # noqa: F401self.predictor = SamPredictor(model)self.points_per_batch = points_per_batchself.pred_iou_thresh = pred_iou_threshself.stability_score_thresh = stability_score_threshself.stability_score_offset = stability_score_offsetself.box_nms_thresh = box_nms_threshself.crop_n_layers = crop_n_layersself.crop_nms_thresh = crop_nms_threshself.crop_overlap_ratio = crop_overlap_ratioself.crop_n_points_downscale_factor = crop_n_points_downscale_factorself.min_mask_region_area = min_mask_region_areaself.output_mode = output_mode
在__init__()函数中最终要的是生成网格点,默认每条边生成32个点,总共生成32的平方个点,这些点是归一化的点
generate函数用来生成mask,它是一系列操作的一个封装,返回的是一个list,列表里包含每个mask_region的相关信息
def generate(self, image: np.ndarray) -> List[Dict[str, Any]]:# Generate masksmask_data = self._generate_masks(image) #核心函数# Filter small disconnected regions and holes in masksif self.min_mask_region_area > 0:mask_data = self.postprocess_small_regions(mask_data,self.min_mask_region_area,max(self.box_nms_thresh, self.crop_nms_thresh),)# Encode masksif self.output_mode == "coco_rle":mask_data["segmentations"] = [coco_encode_rle(rle) for rle in mask_data["rles"]]elif self.output_mode == "binary_mask":mask_data["segmentations"] = [rle_to_mask(rle) for rle in mask_data["rles"]]else:mask_data["segmentations"] = mask_data["rles"]# Write mask recordscurr_anns = []for idx in range(len(mask_data["segmentations"])):ann = {"segmentation": mask_data["segmentations"][idx],"area": area_from_rle(mask_data["rles"][idx]),"bbox": box_xyxy_to_xywh(mask_data["boxes"][idx]).tolist(),"predicted_iou": mask_data["iou_preds"][idx].item(),"point_coords": [mask_data["points"][idx].tolist()],"stability_score": mask_data["stability_score"][idx].item(),"crop_box": box_xyxy_to_xywh(mask_data["crop_boxes"][idx]).tolist(),}curr_anns.append(ann)return curr_anns
在generate函数中会调用 _generate_masks函数
def _generate_masks(self, image: np.ndarray) -> MaskData:orig_size = image.shape[:2]crop_boxes, layer_idxs = generate_crop_boxes(orig_size, self.crop_n_layers, self.crop_overlap_ratio)# Iterate over image cropsdata = MaskData()for crop_box, layer_idx in zip(crop_boxes, layer_idxs):crop_data = self._process_crop(image, crop_box, layer_idx, orig_size)data.cat(crop_data)# Remove duplicate masks between cropsif len(crop_boxes) > 1:# Prefer masks from smaller cropsscores = 1 / box_area(data["crop_boxes"])scores = scores.to(data["boxes"].device)keep_by_nms = batched_nms(data["boxes"].float(),scores,torch.zeros_like(data["boxes"][:, 0]), # categoriesiou_threshold=self.crop_nms_thresh,)data.filter(keep_by_nms)data.to_numpy()return data
对crop出来的图片进行进行预测
def _process_crop(self,image: np.ndarray,crop_box: List[int],crop_layer_idx: int,orig_size: Tuple[int, ...],) -> MaskData:# Crop the image and calculate embeddingsx0, y0, x1, y1 = crop_boxcropped_im = image[y0:y1, x0:x1, :]cropped_im_size = cropped_im.shape[:2]self.predictor.set_image(cropped_im)# Get points for this croppoints_scale = np.array(cropped_im_size)[None, ::-1]points_for_image = self.point_grids[crop_layer_idx] * points_scale# Generate masks for this crop in batchesdata = MaskData()for (points,) in batch_iterator(self.points_per_batch, points_for_image):batch_data = self._process_batch(points, cropped_im_size, crop_box, orig_size)data.cat(batch_data)del batch_dataself.predictor.reset_image()# Remove duplicates within this crop.keep_by_nms = batched_nms(data["boxes"].float(),data["iou_preds"],torch.zeros_like(data["boxes"][:, 0]), # categoriesiou_threshold=self.box_nms_thresh,)data.filter(keep_by_nms)# Return to the original image framedata["boxes"] = uncrop_boxes_xyxy(data["boxes"], crop_box)data["points"] = uncrop_points(data["points"], crop_box)data["crop_boxes"] = torch.tensor([crop_box for _ in range(len(data["rles"]))])return data
输入批量的点批量预测
def _process_batch(self,points: np.ndarray,im_size: Tuple[int, ...],crop_box: List[int],orig_size: Tuple[int, ...],) -> MaskData:orig_h, orig_w = orig_size# Run model on this batchtransformed_points = self.predictor.transform.apply_coords(points, im_size)in_points = torch.as_tensor(transformed_points, device=self.predictor.device)in_labels = torch.ones(in_points.shape[0], dtype=torch.int, device=in_points.device)masks, iou_preds, _ = self.predictor.predict_torch(in_points[:, None, :], #[b,n,2]in_labels[:, None], #[b,n]multimask_output=True,return_logits=True,)# Serialize predictions and store in MaskDatadata = MaskData(masks=masks.flatten(0, 1),iou_preds=iou_preds.flatten(0, 1),points=torch.as_tensor(points.repeat(masks.shape[1], axis=0)),)del masks# Filter by predicted IoUif self.pred_iou_thresh > 0.0:keep_mask = data["iou_preds"] > self.pred_iou_threshdata.filter(keep_mask)# Calculate stability scoredata["stability_score"] = calculate_stability_score(data["masks"], self.predictor.model.mask_threshold, self.stability_score_offset)if self.stability_score_thresh > 0.0:keep_mask = data["stability_score"] >= self.stability_score_threshdata.filter(keep_mask)# Threshold masks and calculate boxesdata["masks"] = data["masks"] > self.predictor.model.mask_thresholddata["boxes"] = batched_mask_to_box(data["masks"])# Filter boxes that touch crop boundarieskeep_mask = ~is_box_near_crop_edge(data["boxes"], crop_box, [0, 0, orig_w, orig_h])if not torch.all(keep_mask):data.filter(keep_mask)# Compress to RLEdata["masks"] = uncrop_masks(data["masks"], crop_box, orig_h, orig_w)data["rles"] = mask_to_rle_pytorch(data["masks"])del data["masks"]return data