文章目录
- 前言
- 一、连接过程
- 二、为什么要使用端口
- 三、端口访问
- 四、动态连接
- 五、标准化数据接口
- 六、BulkIO
- 1、流 API
- ①、数据类型
- ②、输出流
- <1>、创建
- <2>、修改流元数据
- <3>、写入
- <4>、写入复数数据
- <5>、写缓冲
- <6>、关闭
- ③、输入流
- <1>、流轮询
- <2>、高级轮询(仅限 C++)
- <3>、流回调
- <4>、数据块
- <5>、读取数据块
- <6>、固定大小读取
- <7>、重叠读取
- <8>、读取失败
- <9>、跳过
- <10>、非阻塞读取
- ④、与数据块交互
- <1>、内存管理(C++)
- <2>、有效性检查
- <3>、元数据
- <4>、数据
- <5>、实数数据
- <6>、复数数据
- ⑤、时间戳
- ⑥、忽略流
- 2、流相关信息 (SRI)
- ①、连续数据
- ②、帧数据
- ③、SRI 传输
- ④、SRI 关键字
- ⑤、将 SRI 关键字添加到 C++ 中
- ⑥、验证 SRI 关键字
- 3、可附加流
- ①、SDDS 流定义
- 4、pushPacket 数据流
- ①、矢量数据
- ②、字符串数据/XML 文档
- ③、URL/文件数据
- ④、URI 选项
- 5、位数据
- ①、通用
- ②、C++
- ③、只读
- ④、读/写
- ⑤、创建
- ⑥、共享
- ⑦、位操作
- 6、处理复数数据
- ①、在 C++ 中转换复杂数据
- 7、时间戳
- ①、时间戳运算符 (C++)
- 8、端口统计
- 9、例子
- ①、高速数据
前言
在讨论连接时,REDHAWK 中有几个经常被提到的术语:使用(uses)、提供(provides)、端口(port)、接口(interfaces)、接口描述语言(IDL)等等。本节将揭开连接的神秘面纱,介绍一些关键概念,这些概念使基于 REDHAWK 的系统能够轻松与其他 REDHAWK 系统以及在 REDHAWK 范围之外开发的外部工具进行交互。
一、连接过程
所有连接都采用客户端-服务器模式。所有调用都是从客户端到服务器进行的。服务器的作用是提供一组可供客户端调用的函数。客户端的作用是了解服务器提供的接口并调用(使用)它们。这是使用/提供端口命名法的基础。
所有使用端口都实现了 CF::Port 接口。CF::Port 是 REDHAWK 核心框架(CF)的一部分的一个接口;它只包含两个方法:connectPort() 和 disconnectPort()。要将一个使用端口连接到一个提供端口,一个外部实体需要在使用端口上调用 connectPort() 函数,其中的参数是一个指向提供端口的 CORBA指针和一个标识该连接的字符串。要切断一个连接,一个外部实体需要在使用端口上调用 disconnectPort() 函数,其唯一参数是用于建立连接的字符串ID。在应用程序的情况下,连接的建立/销毁由域管理器进程空间中的一个对象根据波形的 XML 文件执行。在沙盒的情况下,沙盒基于用户输入做出正确的调用来建立和销毁连接。
所有提供端口都必须实现一个用接口描述语言(IDL)描述的接口。这个接口实现了连接建立后使用端口调用的方法。当一个使用端口被给定一个指向提供端口的指针时,它本质上将这个通用指针转换为它认为提供端口应该实现的接口。如果这个转换过程失败,在 connectPort() 调用期间会抛出一个异常。
二、为什么要使用端口
通过端口对象连接组件似乎是一种繁琐的做法;这是一个额外的间接层,增加了另一层复杂性。之所以采取这种方法,主要是因为当组件有多个输入或输出端口时,它允许接口模块化。
三、端口访问
端口属于一个组件或设备(设备是特殊的组件 - 有关更多信息,请参见与设备工作)。要检索一个端口,外部实体需要在拥有该端口的组件上调用 getPort()。getPort() 函数的参数是端口的字符串名称,返回值是指向该端口对象的 CORBA 指针。通过这个函数调用,可以从组件中检索到使用端口和提供端口。基础支持的接口不通过 getPort() 检索,因为它们不是端口。相反,这些引用是直接从实体(如域管理器或设备管理器)中检索的。
四、动态连接
除非组件正在被终止的过程中,否则在组件的任何其他生命周期点检索端口引用都是有效的。任何人都可以在任何时候对组件调用 getPort()。对于使用端口,任何人都可以在任何时候调用 connectPort() 或 disconnectPort()。对于提供端口,任何人都可以对该端口引用进行类型转换并开始调用它。组件开发者的任务是确保组件能够平稳地处理这样的变化。REDHAWK 提供的基类和代码生成器处理了因这种变化而产生的绝大多数问题,尤其是当提供端口实现了 REDHAWK 标准接口之一时。
这种动态连接行为为应用程序开发者提供了巨大的好处。例如,如果想要检查从一个组件传递到下一个组件的数据,可以创建一个临时的提供方实现并建立一个新的连接。使用端口的标准行为是将相同的数据发送给它所有现有的连接。这种动态连接方式对于 REDHAWK 的绘图机制是必不可少的。
五、标准化数据接口
REDHAWK 资源(组件和设备)之间的数据流通过两组接口管理:批量输入/输出(BulkIO)和突发输入/输出(BurstIO)。BulkIO 模块旨在用于流数据,最大化资源之间大批量数据传输的效率,而 BurstIO 则为需要小块且可能是非连续数据传输的应用设计。这两个接口还允许关联元数据、信号相关信息(SRI)和精确时间戳,这些都是为了支持内容处理而描述正在传输的内容。以下3个部分详细介绍了 BulkIO 和 BurstIO 实现的能力及它们提供的接口。
六、BulkIO
批量输入/输出(BulkIO)旨在提供一种标准化的方法论,并最大化 REDHAWK 资源(组件和设备)之间大批量数据传输的效率。这个接口支持传输数据向量(浮点型、双精度、字符(int8)、字节(uint8)、短整型(int16)、无符号短整型(uint16)、长整型(int32)、无符号长整型(uint32)、长长整型(int64)、无符号长长整型(uint64))、字符字符串(char *)和 SDDS 数据流的带外连接描述符。
这些接口还允许元数据、信号相关信息(SRI)和精确时间戳(在以下小节中详细描述),这些描述了正在传输的内容并支持内容处理。在 REDHAWK 组件之间传递数据的所需方法论的一部分是,所有通过 pushPacket() 进行的数据传输都至少需要一次调用 pushSRI(),并且提供一个适当的 SRI 对象。SRI 数据是从内容数据中分离出来传递的,以减少组件之间传输数据的开销。精确时间戳代表数据的生成日期,是那些需要此信息的组件的 pushPacket() 方法调用的一部分。
组件的 BulkIO 端口接口的数据流实现是由共享的 bulkio 基类库提供的。结果组件代码实例化一个 bulkio 基类对象,并在部署和执行期间使用共享库。
1、流 API
批量输入/输出 (BulkIO) 流 API 提供了通过 BulkIO 端口发送和接收数据的高级接口。每个流都绑定到一个端口,并封装信号相关信息 (SRI) 和与其关联的数据。
流由创建它们的端口自动管理。用户代码并不拥有流本身;相反,用户实例是不透明的流句柄。这允许它们按值传递或安全地存储在其他数据结构中。
所有 BulkIO 端口类型(SDDS 和 VITA49 除外)都支持流 API。
大多数流方法都不是线程安全的;假定每个流将由单个线程写入或读取。然而,同时使用多个流是安全的。
①、数据类型
下表描述了典型读或写操作的数据类型。
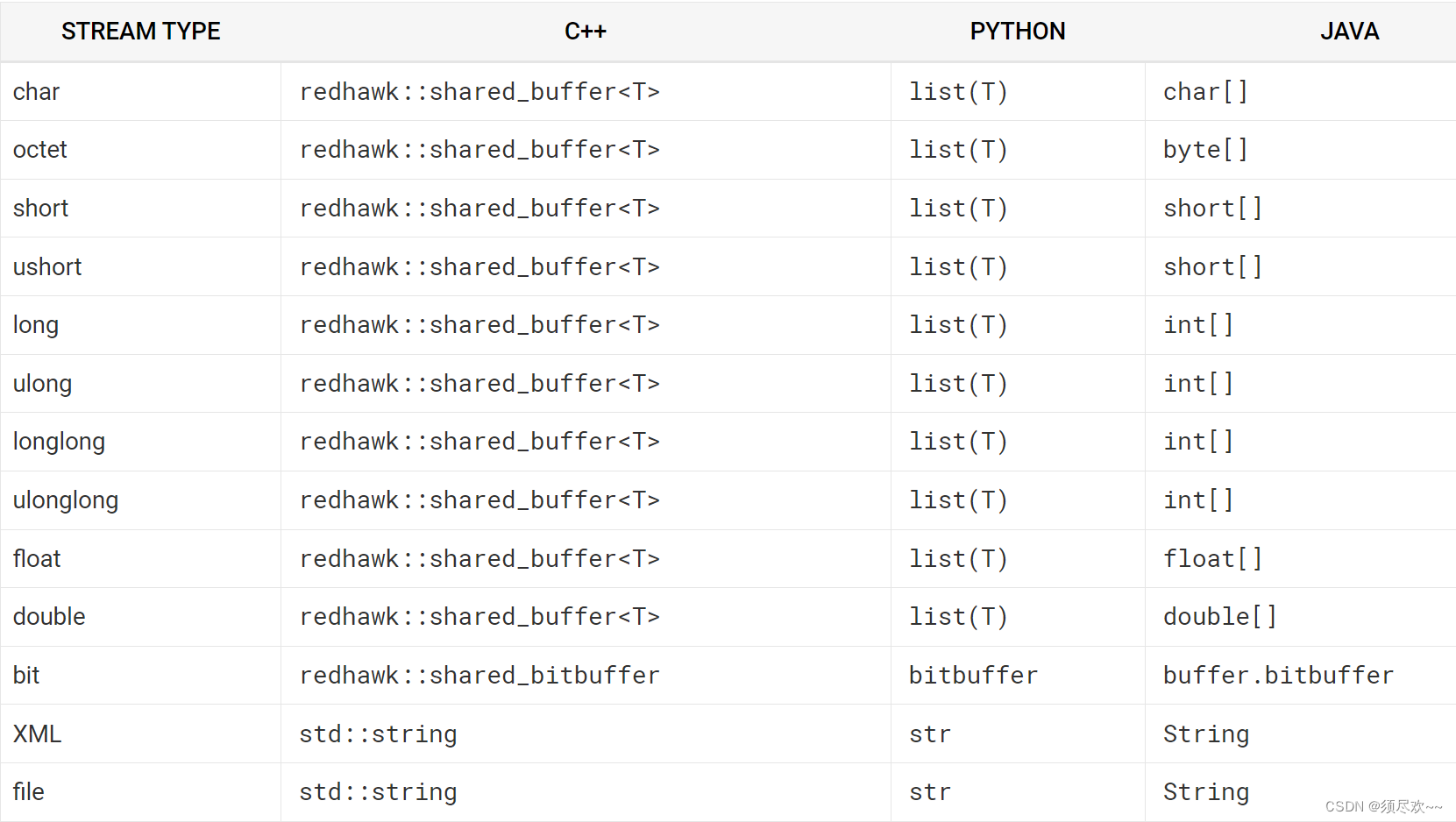
下表描述变量 “T” 的元素类型。

②、输出流
输出流确保数据始终与活动的 SRI 相关联,并简化流生命周期的管理。
输出流类型 (C++)
- 每种数值输出端口类型都有一个相应的流类型(例如,bulkio::OutFloatPort 对应bulkio::OutFloatStream),它提供了发送流数据的接口。
<1>、创建
通过端口的 createStream() 方法创建一个输出流。以下示例创建了一个具有 ID “my_stream_id” 和默认 SRI 的新流。
C++:
bulkio::OutFloatStream stream = dataFloat_out->createStream("my_stream_id");
该 createStream() 方法还接受 SRI。
输出端口会跟踪已创建的流,直到它们关闭。该 ·getStream()· 方法提供了一种通过 ID 查找流的方法,从而无需保留对输出流的本地引用。
<2>、修改流元数据
输出流提供了用于修改公共 SRI 字段的便捷方法 (C++) 或属性 (Python)。以下示例配置复数据的输出流,采样率为 250Ksps,中心频率为 91.1MHz。
C++:
stream.complex(true);
stream.xdelta(1.0 / 250000.0);
stream.setKeyword("CHAN_RF", 91.1e6);
SRI 可以用 C++ 或 Java 中的 sri() 方法整体更新:
stream.sri(newSri);
除流 ID 外,所有 SRI 字段均根据新 SRI 进行更新。Stream ID 是不可变的,创建后无法更改。
SRI 的更新会在下一个数据包发出之前存储并推送。
使用流时不需要手动调用
pushSRI()。
<3>、写入
数据通过 write() 方法发送。除了不支持时间戳的 XML 流外,write() 必须被赋予一个表示所写数据中第一个元素出生日期的 PrecisionUTCTime。
redhawk::buffer<float> data(1024);
// ...fill data...
stream.write(data, bulkio::time::utils::now());
<4>、写入复数数据
在 C++ 中,如果流配置为复数数据,请给出 write() 复杂数据类型:
redhawk::buffer< std::complex<float> > data(1024);
// ...fill data...
stream.write(buffer, size, bulkio::time::utils::now());
将标量数据写入复杂流时,请确保大小是 2 的倍数。
<5>、写缓冲
大多数 BulkIO 输出流类型,除了 XML 和 File 外,支持缓冲写模式。当启用缓冲时,流可以将多个小写操作排队成一个单独的推送。
默认情况下,写缓冲是禁用的。要启用缓冲,请使用 setBufferSize() 方法设置所需的大小。在写操作时,流会将数据复制到其内部缓冲区,直到达到所需的大小,然后将缓冲的数据作为单个推送输出。
如果 SRI 发生变化或在关闭时,缓冲的数据将立即被推送到端口。也可以通过调用 flush() 方法显式触发推送。
一旦启用了缓冲,要禁用它,将缓冲大小设置为 0。
写缓冲并不保留每个时间戳。如果需要精确的时间信息,请禁用写缓冲。
<6>、关闭
当输出流完成时,关闭流。close() 方法发送一个流结束(EOS)数据包,并将流与输出端口解除关联。
③、输入流
输入流封装了 SRI 和与该流 ID 关联的所有接收到的数据包。内建了缓冲和重叠功能,消除了客户端代码实现这些功能的需求。
当接收到带有新流 ID 的 SRI 时,输入端口会自动创建输入流。每个端口只能存在一个具有给定流 ID 的流;如果一个输入流有一个未确认的 EOS 等待中,带有相同流 ID 的新 SRI 将被排队,直到 EOS 被处理。
接受或返回样本数量的方法会考虑输入流的复数模式。例如,从一个复杂流请求 1024 个样本会返回 1024 对复杂数,这等同于 2048 个标量值。
有两种方法可以检索输入流:流轮询或流回调。
输入流类型 (C++)
- 每种输入端口类型都有一个对应的流类型(例如,bulkio::InFloatPort 的对应流类型是 bulkio::InFloatStream)。
<1>、流轮询
在基本情况下,getCurrentStream() 方法返回下一个准备好读取的输入流。这与 getPacket() 相似,会参考队列中的下一个数据包;然而,如果任何流从之前的读取中有缓冲数据(例如,在使用固定大小读取时),它将被优先处理。习惯于使用 getPacket() 的开发者会发现,getCurrentStream() 提供了一个熟悉的流程,同时扩展了可用的功能。
可选的超时参数与 getPacket 的超时参数相同。如果省略超时参数,getCurrentStream() 默认为阻塞模式。以下示例无限期等待流准备就绪。
C++:
bulkio::InFloatStream stream = dataFloat_in->getCurrentStream();
if (!stream) {return NOOP;
}
如果没有准备好的流,例如当超时到期或组件接收到 stop() 调用时,返回的流将是无效的。在执行任何操作之前,应检查流的有效性。在 C++中,布尔非(!)操作符如果流无效则返回 true。
<2>、高级轮询(仅限 C++)
对于更高级的使用,输入端口的 pollStreams() 方法族允许您等待一个或多个流准备好读取。与 getCurrentStream() 一样,pollStreams 接受一个超时参数来设置最大等待时间。
准备好的流被作为一个列表返回:
// Wait up to 1/8th second for a stream to be ready
bulkio::InFloatPort::StreamList streams = dataFloat_in->pollStreams(0.125);
if (streams.empty()) {return NOOP;
}
for (bulkio::InFloatPort::StreamList::iterator stream = streams.begin();stream != streams.end();++stream) {// Handle each stream; note that stream is an iteratorLOG_TRACE(Component_i, "Reading stream " << stream->streamID());
}
如果没有流准备好,返回的列表为空。一旦一个流准备就绪,pollStreams() 就会返回。
如果需要最小样本数,可以在 pollStreams() 调用中提供:
bulkio::InFloatPort::StreamList streams = dataFloat_in->pollStreams(1024, bulkio::Const::BLOCKING);
<3>、流回调
与轮询相反,回调函数可以注册到输入端口,以便在创建新流时收到通知。使用回调支持更复杂的模式,例如在单独的线程中处理每个流或禁用不需要的流。
该回调没有返回值,并且采用单个参数,即输入流。
C++:
void MyComponent_i::newStreamCreated(bulkio::InFloatStream newStream) {// Store the stream in the component, set up supporting data structures, etc.
}
回调应该在 REDHAWK 构造函数中注册到端口。
C++
void MyComponent_i::constructor()
{// Other setup code...dataFloat_in->addStreamListener(this, &MyComponent_i::newStreamCreated);
}
<4>、数据块
在基于 BulkIO 输入流的代码中,数据作为块从数据流中检索。数据块可以按包的基础上检索,或者可以作为一个确定大小的缓冲区检索,无论是否重叠。
Data Block Types (C++)
- 每个输入流数据类型都有对应的数据块类型,例如 bulkio::FloatDataBlock.
<5>、读取数据块
read() 方法族同步地从流中获取数据。基本的 read() 返回流的下一个数据包的数据,必要时进行阻塞。
对于常见的用例,一次读取一个数据包是最有效的方法,因为它避免了复制数据的需要。
bulkio::FloatDataBlock block = stream.read();
<6>、固定大小读取
您可以通过提供样本数量来请求一定数量的数据。以下示例读取 1K 样本。
bulkio::FloatDataBlock block = stream.read(1024);
read() 调用会阻塞,直到至少请求的样本数量可用。必要时将组合或拆分数据包以返回正确数量的数据。如果流已结束或组件已停止,返回的块可能包含的样本数量少于请求的数量。
XML 和 File 流不支持指定大小的读取。
<7>、重叠读取
对于需要读取指针移动到除请求数据集末尾以外的点的算法,您也可以传递要消耗的样本数量。以下示例读取1K样本,重叠50%。
C++:
bulkio::FloatDataBlock block = dataFloat_in->read(1024, 512);
输入流的读取指针会前进到消耗长度的位置。下一次调用 read() 时,将从那个点开始返回数据。如果消耗长度大于请求的数据长度,read 调用将阻塞,直到满足请求的消耗长度。
XML 和 File 流不支持自定义消耗量。
<8>、读取失败
如果接收到 EOS 标志,或组件被中断,read() 可能会提前返回。在重叠的情况下,如果在接收到请求的样本数量之前到达 EOS,所有剩余的数据都将被消耗,且不再可能进行进一步的读取。
当 read() 返回一个无效的块时,检查 EOS 是很重要的。
C++:
if (!block) {if (stream.eos()) {// Stream has ended, no more data will be received}
}
<9>、跳过
数据可以通过 skip() 方法被丢弃。在以下示例中,将丢弃 256 个样本。
C++:
size_t skipped = stream.skip(256);
<10>、非阻塞读取
read() 方法族总是阻塞的。对于非阻塞读取,使用 tryread()。
C++:
bulkio::FloatDataBlock block = stream.tryread(2048);
tryread() 只有在整个请求都能被满足或者不会再接收到更多数据的情况下才会返回一个有效的数据块。如果流已经结束或组件已被停止,流中所有剩余排队的数据将被返回。
④、与数据块交互
数据块包含输入数据以及描述数据的 SRI。数据块中包含了多种函数,帮助开发者管理和与数据块的内容进行交互。
<1>、内存管理(C++)
内存在对象内部自动管理,以最大限度地减少副本,因此无需显式删除数据块。
<2>、有效性检查
如果读取失败,例如当组件接收到 stop() 调用时,它将返回一个无效的块。在尝试访问块的数据或元数据之前,应使用布尔测试检查块的有效性。
在 C++中,数据块对象支持布尔测试。通常,使用布尔非运算符(!)测试块的有效性:
bulkio::FloatDataBlock block = stream.read();
// Check if a valid block was returned
if (!block) {return NOOP;
}
// Operate on the block
<3>、元数据
数据块提供了方法(C++/Java)或属性(Python)来访问常见的元数据:
- sri 返回接收数据时的 SRI
- xdelta 返回 SRI 的 xdelta
偶尔,输入流的状态可能会在数据块之间发生变化。为了处理这种情况,数据块提供了方法(C++/Java)或属性(Python)来检查这些条件:
- inputQueueFlushed
- sriChanged
- sriChangeFlags 返回作为位字段的改变了的 SRI 字段
C++示例:
if (block.inputQueueFlushed()) {// Handle data discontinuity...
}
if (block.sriChangeFlags() & bulkio::XDELTA) {// Update processing...
}
<4>、数据
buffer方法(C++/Java)或属性(Python)提供了对存储在数据块中的数据的访问,且开销最小。对于基于样本的数据块类型(如float),请参考实数数据或复数数据。
<5>、实数数据
对于基于样本的数据块类型,buffer 将数据作为实数样本进行访问。
在 C++ 中:
float blocksum = 0.0;
const redhawk::shared_buffer<float>& data = block.buffer();
for (size_t index = 0; index < block.size(); ++index) {blocksum += data[index];
}
<6>、复数数据
如果输入流是复数的,返回的数据缓冲区应当被视为复数数据。数据块对象提供了便捷方法(C++/Java)或属性(Python),以便于处理复数数据:
- complex 返回真如果数据是复数的(即,SRI模式是1)。
- cxbuffer 返回样本数据,重新解释为复数。
if (block.complex()) {std::complex<float> blocksum = 0.0;redhawk::shared_buffer<std::complex<float> > data = block.cxbuffer();for (size_t index = 0; index < data.size(); ++index) {blocksum += data[index];}
}
⑤、时间戳
因为一个单独的数据块可能跨越多个输入包,所以它可以包含多个时间戳。从输入流返回的数据块(XML流除外)保证至少有一个时间戳。
可以通过 getStartTime() 方法访问第一个时间戳。这返回第一个样本的 PrecisionUTCTime。
如果数据块包含多于一个的时间戳,可以通过 getTimestamps() 方法访问时间戳的完整列表。
C++:
std::list<bulkio::SampleTimestamp> timestamps = block.getTimestamps();
SampleTimestamp 类包含三个字段:
- time - 一个 PrecisionUTCTime 时间戳
- offset - 此时间戳适用的样本编号
- synthetic - 如果时间戳是基于之前的数据块计算出来的,则为真
当数据块的开始与包不完全匹配时,输入流将使用最后已知的时间戳、SRI xdelta 和样本数量来计算时间戳。一个数据块中只有第一个时间戳可以是合成的。
⑥、忽略流
一些组件可能更倾向于一次只处理一个流。可以通过调用 disable() 方法来禁用不需要的输入流。
直到达到 EOS 为止,该流的所有数据都将被丢弃,从而防止由于未处理的数据导致队列堵塞。
2、流相关信息 (SRI)
SRI(Stream Runtime Interface)随数据一起传送(当在带内时),描述了数据负载。SRI关键字提供了如何在 SRI 中操纵关键字的指南。以下表格描述了 SRI 数据结构字段。

Bulk 输入/输出(BulkIO)有两种操作模式:连续数据模式和帧数据模式,分别对应于子大小(subsize)等于零或等于帧大小。
①、连续数据
BulkIO 最常见的用途是传输连续数据,通常是数字化样本。SRI 子大小字段必须设置为 0。主轴通常以时间为单位。辅助轴未使用。下表描述了连续数据的 SRI 字段。

②、帧数据
BulkIO 支持帧数据,例如快速傅立叶变换 (FFT) 的输出,其中一维具有固定大小。SRI subsize 字段设置为帧长度。下表描述了帧数据的 SRI 字段。

③、SRI 传输
SRI 通过使用端调用提供端函数 pushSRI() 在连接上进行传输。pushSRI() 函数包含单个参数,即一个 SRI 对象的实例。
实现 BulkIO 接口的每个提供端端口都期望在传输任何数据之前,关于正在接收的数据的 SRI 变得可用。当使用 REDHAWK 开发工具中的代码生成器和基类时,这种行为被硬编码到使用端 BulkIO 端口中。如果 BulkIO 连接的使用端用户代码在发送任何数据之前没有明确调用 pushSRI(),自动生成的代码会创建一个具有规范化值的简单 SRI 消息。
使用端 BulkIO 端口上的硬编码行为的一部分是在建立新连接到新连接对象时发出 pushSRI()。例如,创建了一个系统,数据在组件 A 和 B 之间流动。在这些组件之间数据流动时,组件 A 和 C 之间建立了新的连接。当这个连接建立时,自动地从组件 A 向组件 C 发出 pushSRI() 方法调用。
④、SRI 关键字
SRI 是用来描述被推送的载荷(例如,采样周期)的元数据。虽然可以用来描述一些通用参数,特定信号的参数则存储在一个称为 SRI 关键字的通用结构中。SRI 关键字以键/值对(CF::DataType)的序列形式传递,类型为 CF::Properties。在属性中,键是字符串,值是一种称为 CORBA::Any 的 CORBA 类型。CORBA::Any 是一种结构,可用于封装各种类型。REDHAWK 开发了辅助 API 来与关键字序列交互。
⑤、将 SRI 关键字添加到 C++ 中
考虑一个具有简单属性 chan_rf 和 col_rf 的组件,这些属性的类型为 double,初始值为 -1。在名为 sri 的 BulkIO StreamSRI 实例中,以下 C++ 的实现将这些属性值作为 COL_RF 和 CHAN_RF 关键字推送出去。
C++实现:
红鹰(redhawk)的 PropertyMap 属性映射使您能够操纵关键字序列。
include <ossie/PropertyMap.h>redhawk::PropertyMap &tmp = redhawk::PropertyMap::cast(sri.keywords);
tmp["CHAN_RF"] = chan_rf;
tmp["COL_RF"] = col_rf;
⑥、验证 SRI 关键字
可以通过连接一个 DataSink() 组件到 Python 沙盒中来验证正在推送的关键词和值。这假设测试组件至少有一个 BulkIO 输出端口,并且在该端口上进行了 pushSRI() 调用。以下代码演示了这种验证:
from ossie.utils import sb
comp = sb.launch("<component name>")
sink = sb.DataSink()
comp.connect(sink)
sb.start()
print sink.sri().keywords
在 C++ 中检索 SRI 关键字:
因为 redhawk::PropertyMap 包含了 CORBA::Any 值,检索内容需要使用 getter 来转换成原生类型。假设某个关键词的内容是一个双精度浮点数:
redhawk::PropertyMap &tmp = redhawk::PropertyMap::cast(sri.keywords);
chan_rf = tmp["CHAN_RF"].toDouble();
3、可附加流
可附加流提供了一种使用带外数据传输的方法。数据传输的机制由单独的网络协议定义,而 REDHAWK 提供连接管理。对于批量输入/输出(BulkIO),支持的两种可附加流是 SDDS 和 VITA49。BulkIO 通过使用 attach 方法将 StreamDefinition 对象传递给连接的端口。连接的输入端口为下游资源提供 StreamDefinition 对象,以创建到实际数据源的连接。传递的 StreamDefinition 对象被映射到底层的 BulkIO 数据类型。BulkIO SDDS 端口传递 SDDSStreamDefinition 对象,而 BulkIO VITA49 端口传递 VITA49StreamDefinition 对象。
①、SDDS 流定义
SDDS 流定义对象从网络接口定义了到数据源的连接。SDDS 流定义接口的方法不遵循常规的 BulkIO pushPacket() 约定;相反,该接口定义了 attach() 和 detach() 方法。attach() 和 detach() 方法在以下代码片段中提供。
/*** SDDS Stream Definition Interface*//*** attach : request to an attachment to a specified network data source*/
char *attach( BULKIO::SDDSStreamDefinition stream, const char * userid );/*** detach: unlatch from a network data source*/
void detach( const char* attachId );
下表描述 attach() 和 detach() 方法以及 SDDS 流定义成员。



4、pushPacket 数据流
强烈推荐对于C++和Python中的BulkIO数据,使用批量输入/输出(BulkIO)流 API,该 API 提供了一个高级接口来通过 BulkIO 端口发送和接收数据。
数据传输通过 REDHAWK 组件的端口对象的 pushPacket() 方法调用来实现。该方法将数据从使用方端口传输到相应连接的提供方端口。数据由中间件(omniORB)编组,并放置在一个队列中,等待接收组件处理。pushPacket() 方法的实现最大化了数据吞吐量的效率,同时提供了网络可访问的数据输入/输出,并尽量减少了实现的复杂性。
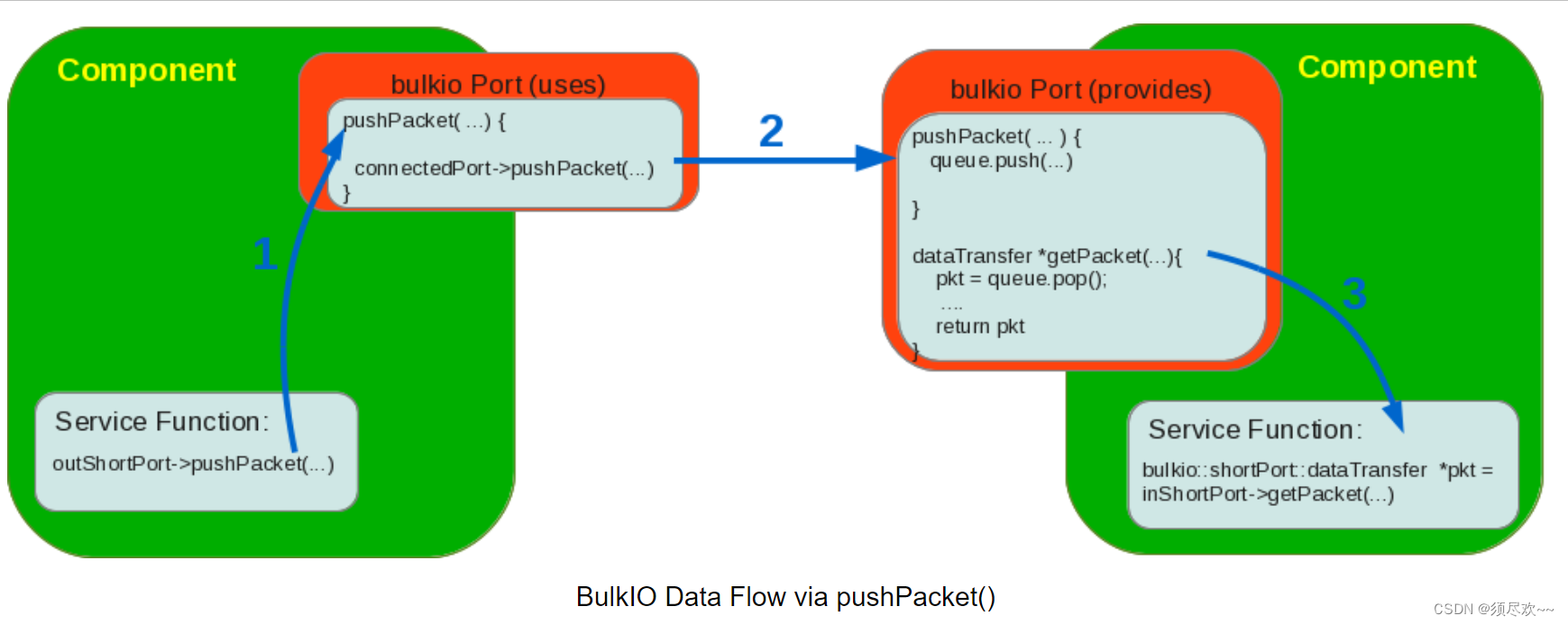
每个实现都维护着在接收任何数据传输之前提供一个信号相关信息(SRI)对象的必要行为。这是通过使用 SRI 对象调用端口的 pushSRI() 方法来实现的。在大多数情况下,组件接收来自输入端口的 ingest SRI 对象,根据需要进行任何必要的修改,并通过其输出端口将此对象下游传递。如果组件在其第一个 pushPacket() 之前没有提供 SRI 对象,端口将创建一个具有名义值的默认 SRI 对象以传出端口。
以下部分解释了组件传输支持的数据类型的不同方法。
对于当前的 omniORB 实现,/etc/omniORB.cfg 维护了由 giopMaxMsgSize 值定义的可配置最大传输大小。默认最大传输大小设置为 2097152(2MB)。对于每个
pushPacket(),数据+头部必须小于此值;否则,中间件会抛出一个 MARSHAL 异常。这个最大值可以在运行时使用omniORB::giopMaxMsgSize()函数调用或 bulkio::Const::MAX_TRANSFER_BYTES 值找到
①、矢量数据
组件通常在其服务函数中从端口摄取和输出数据。拥有提供端口(输入)的组件,使用 getPacket() 方法从端口抓取数据。此方法从输入端口的数据队列返回一个 dataTransfer 对象(在DataTransfer 成员描述中描述),如果队列为空,则返回 null/None 值。
以下代码片段是 getPacket() 方法的一个示例。
/**Grab data from the port's getPacket method*/
bulkio::InFloatPort::dataTransfer *pkt;
pkt = inFloatPort->getPacket( bulkio::Const::NON_BLOCKING );// check if a valid packet was returned
if ( pkt == NULL ) {return NOOP;
}// check if any SRI changes occurred
if ( pkt->sriChanged ) {outFloatPort->pushSRI( pkt->SRI );
}... perform some algorithm on the data: pkt->dataBuffer ...
下表描述了 DataTransfer 成员。

当队列中的数据包数量超过队列深度时,会发生队列刷新条件。当发生刷新时,队列中的每个流都会被单个数据包替换。每个数据包包含最后的数据有效载荷和相应的时间戳,以及可能发生的任何 SRI 变更、队列刷新和 EOS 指示。如果在刷新发生时一个流只包含单个数据包,那么该流的 inputQueueFlushed 标志不会被设置,因为没有数据丢失。如果一个流标识符多次出现(流 ID 重用),每个这样的流都包含一个具有正确的数据有效载荷、时间戳、SRI 变更、队列刷新和 EOS 指示器的单个数据包。
以下代码片段是一个示例,演示了带有示例参数的向量数据的 pushPacket() 方法调用。
std::vector<short> data;... perform algorithm and save results to data vector ...BULKIO::PrecisionUTCTime tstamp = bulkio::time::utils::now();
outShortPort->pushPacket( data, tstamp, false, "sample" );
下表描述向量数据的 pushPacket() 参数。

②、字符串数据/XML 文档
以下代码片段是使用 pushPacket() 示例参数调用字符串数据的方法的示例。
std::string data;... generate some text data to transfer ...outStringPort->pushPacket( data.c_str(), false, "sample" );
下表描述了字符串数据的 pushPacket() 参数。

③、URL/文件数据
下面的代码片段是 pushPacket() 方法调用的示例,用于带有示例参数的文件传输。
std::string uri;uri = "file:///data/samples.8t";... open the file, fill with samples of data, close the file ...BULKIO::PrecisionUTCTime tstamp = bulkio::time::utils::now();
outURLPort->pushPacket( uri.c_str(), tstamp, false, "sample" );
下表描述了用于文件传输的 pushPacket() 参数。

数据文件可以通过批量输入/输出(BulkIO)dataFile 类型发送。使用 BulkIO dataFile 类型时,文件名会传递给 pushPacket() 方法。文件的位置由指向本地文件系统或软件定义无线电(SDR)文件系统的URI 指定。为了支持可移植性,推荐使用 SDR 文件系统。
④、URI 选项
下表描述了 URI 路径选项。

5、位数据
在 REDHAWK 2.2.0 及以上版本中,批量输入/输出(BulkIO)包括了一种打包位数据格式,即 BULKIO::dataBit。在处理阶段之间传输打包位数据已经标准化,包括传输非字节对齐位数的能力。
①、通用
REDHAWK 将位作为字节数组管理,每个字节包含最多8个连续位。位索引从最重要的位开始:位索引 0 是第一个字节的最重要位,位索引 1 是第二重要位,依此类推。
②、C++
在 C++中,有两个类,redhawk::shared_bitbuffer 和 redhawk::bitbuffer,它们提供对位数据的高级访问。这些类分别类似于 redhawk::shared_buffer 和 redhawk::buffer,但用于位数据。
BulkIO 打包位流设计为与 redhawk::shared_bitbuffer 一起工作。
③、只读
redhawk::shared_bitbuffer 类提供对存储在后备字节数组中的打包位数据的只读访问。
可以通过索引访问单个位:
int bit = buf[0];
位以整数值返回,始终为0或1。
可以使用 getint() 方法从给定位偏移中提取大小最多为 64 位的整数。以下示例在位 36 处提取一个 24 位整数值:
int value = buf.getint(36, 24);
返回的值是一个无符号的64位整数,提取的值在最低有效位中。
④、读/写
redhawk::bitbuffer 类添加了提供对 redhawk::shared_bitbuffer 类写访问的方法。
可以通过索引设置单个位:
buf[0] = 1;
任何非零值都设置位,而零清除位。
在 C++ 中,没有表示单个位的原始类型;索引赋值是用一个私有代理类实现的。取一个索引值的地址是一个编译错误。
可以使用 setint() 方法在给定位偏移处设置最多 64 位的整数值。以下示例在位 36 处设置一个 24 位整数值:
buf.setint(36, 0xABCDEF, 24);
值的最低有效24位被存储。
⑤、创建
要分配足够空间容纳 256 位的新 bitbuffer:
redhawk::bitbuffer data(256);
新 bitbuffer中 的位值未初始化。
要创建一个现有 shared_bitbuffer 的可写副本:
redhawk::bitbuffer data = shared.copy();
要解析字符串字面量,使用静态类方法 from_string():
redhawk::bitbuffer data = redhawk::bitbuffer::from_string("0101101010101");
from_string() 方法解析输入字符串,并返回一个拥有内存的新 bitbuffer。
要从最多 64 位的整数字面量创建 bitbuffer,使用静态类方法 from_int()。以下示例从一个十六进制字面量创建一个 36 位的 bitbuffer:
redhawk::bitbuffer data = redhawk::bitbuffer::from_int(0x123456789, 36);
只有字面量的最低有效 36 位被取出;任何高于最低有效36位的位都被丢弃。
⑥、共享
创建新的位数据或转换现有位数据的算法应为每次迭代分配一个新的 bitbuffer。一旦 bitbuffer 被写入输出流,就不得修改。对 bitbuffer 内容的修改对共享相同数据的所有实例可见。然而,需要历史记录的算法可以保留一个对即将输出数据的只读引用,成本较低:
redhawk::shared_bitbuffer history = data;
⑦、位操作
shared_bitbuffer 类包括几个用于位级处理的有用功能:
distance(other)返回两个 bitbuffers 之间的汉明距离。find(pattern, maxDistance)在最大汉明popcount()返回人口计数(1位的数量)。takeskip(M,N)执行一个取/跳过操作,迭代地复制 M 位并跳过 N 位,直到数据的末尾。
6、处理复数数据
如果传入数据的 StreamSRI 模式字段设置为 1,则关联的输入数据是复数的(即,它由实部和虚部组成)。复数数据以交替的实数和虚数值发送。开发人员可以以任何方式处理这些数据;然而,本节提供了将数据转换为更可操作形式的常用方法。
①、在 C++ 中转换复杂数据
在 C++ 中,传入的 Bulk Input/Output(BulkIO)数据块提供了一个 complex() 方法来检查数据是否是复数的,以及一个 cxbuffer() 方法来将样本数据重新解释为 redhawk::shared_buffer 中的 std::complex 值。例如:
bulkio::ShortDataBlock block = stream.read();
if (block.complex()) {redhawk::shared_buffer<std::complex<short> > data = block.cxbuffer();const size_t size = data.size();
}
7、时间戳
Bulk Input/Output(BulkIO)使用 BULKIO::PrecisionUTCTime 时间戳,表示自 1970 年 1 月 1 日午夜(Unix纪元)起的 UTC 时间。时间戳包含几个元素。在 BulkIO 中,时间戳对应于被推送的数据中第一个元素的出生日期。下表描述了构成 BULKIO::PrecisionUTCTime 结构的不同元素。

上表中描述的两个元素对应于预定义的值。tcstatus 只能取两个值,TCS_INVALID(0)和TCS_VALID(1),表示时间戳是否有效。无效的时间戳不包含有效的时间数据,应该被忽略。tcmode 是获取时间戳的方法,但这种用法已经被弃用,这个值被忽略。tcmode 的默认值是1。
以下代码片段提供了如何构造要在 pushPacket() 调用中发送的时间戳的示例。now() 方法返回当前的时间。
C++:
BULKIO::PrecisionUTCTime tstamp = bulkio::time::utils::now();
①、时间戳运算符 (C++)
在 C++中,BULKIO::PrecisionUTCTime 支持常见的算术、比较和流运算符。
向时间戳添加偏移量:
/*** Add 1/8th of a second to the current time*/
BULKIO::PrecisionUTCTime time1 = bulkio::time::utils::now();
time1 += 0.125;
减去两个时间戳返回以秒为单位的差值:
/*** Check if time2 is less than a second after time1*/
if (time2 - time1 < 1.0) {...
}
比较两个时间戳:
/*** Check if the second time stamp occurs before the first*/
if (time2 < time1) {...
}
流格式(输出格式为“YYYY:MM:DD::HH::MM::SS.SSSSSS”):
/*** Write the current time out to the console*/
std::cout << bulkio::time::utils::now() << std::endl;
8、端口统计
所有 Bulk Input/Output(BulkIO)端口都包含一个名为 statistics 的只读属性。statistics 属性的类型是 BULKIO::PortStatistics,它包含了关于端口性能的信息。下表包含了一个统计结构的描述:

提供方端口包含单个 PortStatistics 结构。使用方端口包含一系列 PortStatistics 结构;每一个都与单个连接相关联。
一个有趣的练习是创建在 REDHAWK 支持的三种语言中生成和消费数据的组件。数据生成器和消费器尽可能快地生成/消费数据。统计数据结构可以提供有关数据传输速率、平均延迟和其他相关数据的指标。通过改变 pushPacket() 调用中序列的大小来调整传输长度,并观察其对连接性能的影响,也是很有教育意义的。
9、例子
这两个示例展示了两个 C++ 组件之间的高速数据交换以及通过沙盒进行的基本数据操作。
①、高速数据
在这个例子中,创建了两个 C++ 组件:一个源和一个接收。然后,我们将通过沙盒部署这些组件,并评估它们之间数据传输的统计数据。
-
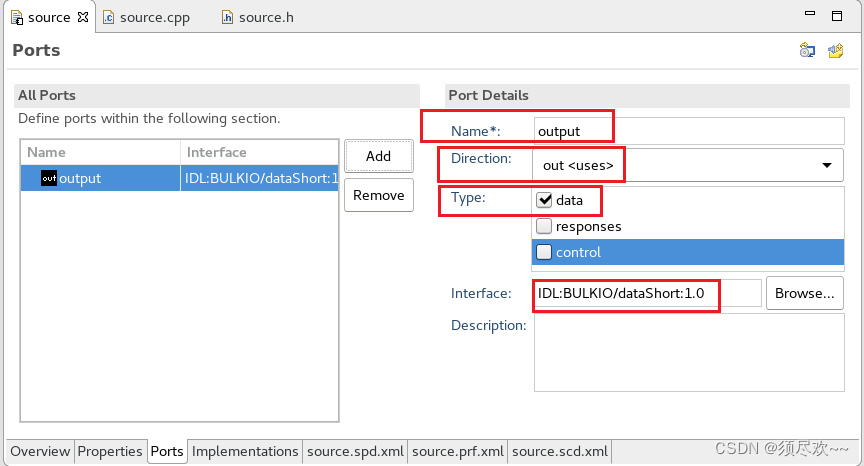
1)创建一个名为 source 的 C++ 组件,带有一个类型为 dataShort 的 uses 端口,名为 output。添加一个简单的属性,ID 为 xfer_length,类型为 ulong,默认值为 100000。生成组件代码。

-
2)打开文件 source.h,并向 source_i 类添加以下成员:
std::vector<short> data; bulkio::OutShortStream stream;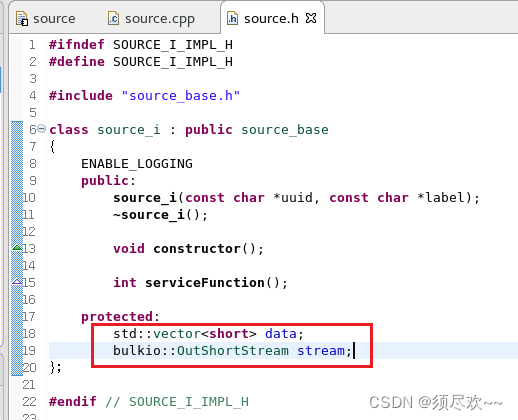
-
3)打开 source.cpp 文件,并通过以下方式对其进行编辑:
-
在 source_i 构造函数
data.resize(0);
-
在 serviceFunction() 中注释掉 RH_DEBUG 语句并添加以下行:
if (data.size() != this->xfer_length) {data.resize(xfer_length); } if (!stream) {stream = output->createStream("sample"); } BULKIO::PrecisionUTCTime tstamp = bulkio::time::utils::now(); stream.write(data,tstamp); return NORMAL;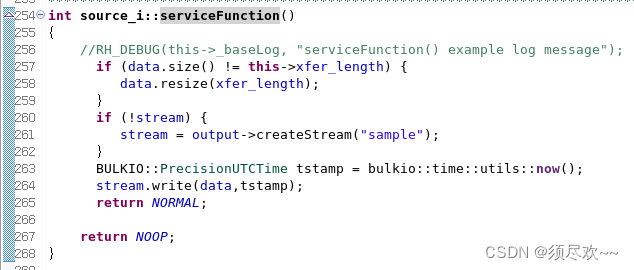
-
-
4)编译 source 组件并将其安装到 Target SDR上。(拖动项目到Target SDR)

-
5)创建一个名为 sink 的 C++ 组件,其提供端口称为 dataShort 类型的输入。生成组件代码。

-
6)打开该文件 sink.cpp 并通过以下方式对其进行编辑:
- 在 serviceFunction() 中,注释掉该 RH_DEBUG 语句
- 添加以下行:
bulkio::InShortStream stream = input->getCurrentStream(); if (!stream) {return NOOP; }bulkio::ShortDataBlock block = stream.read(); if (!block) {return NOOP; }return NORMAL;
-
7)编译该 sink 组件并将其安装在 Target SDR 上。(拖动项目到Target SDR)
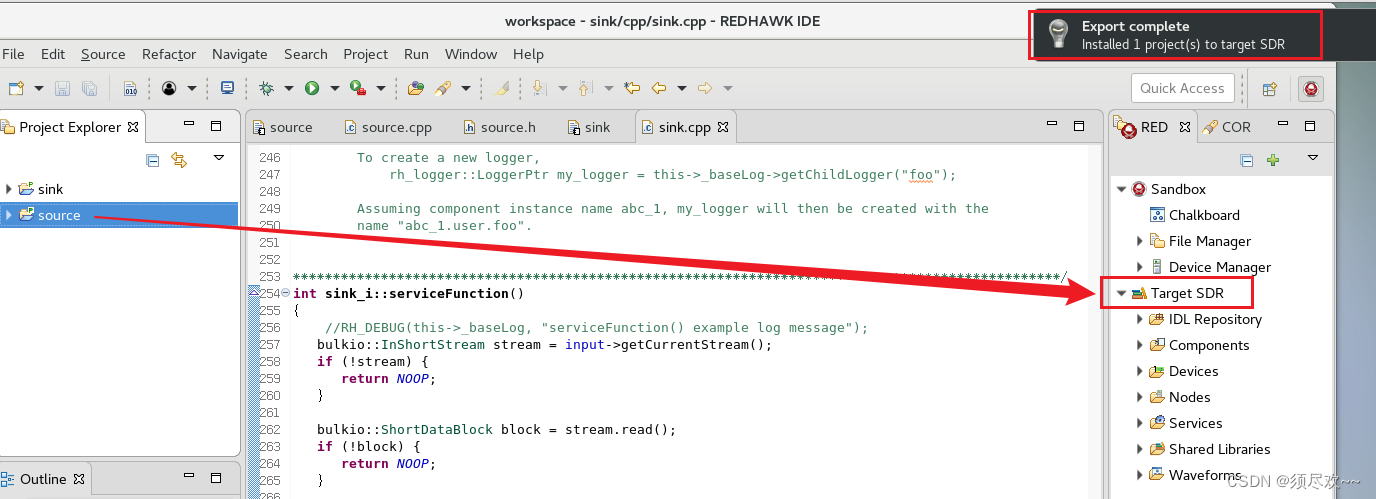
将 source 和 sink 组件成功将其安装在 Target SDR 上后可以看到 rh 下多了 sink 和 source 组件

-
8)在命令行终端中启动 Python 会话并运行以下命令:
from ossie.utils import sb source = sb.launch("source") sink = sb.launch("sink") source.connect(sink) sb.start() print source._ports[0]._get_statistics()[0].statistics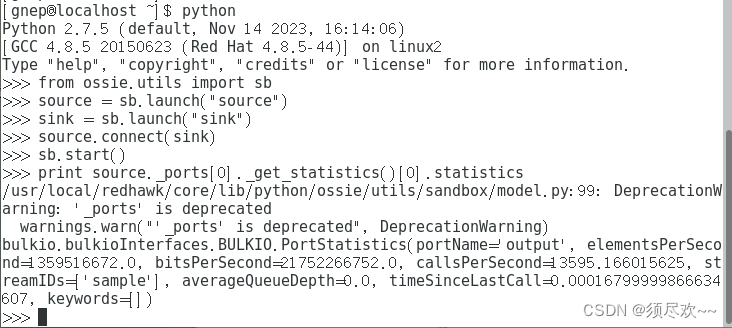
print 语句的输出是 Bulk Input/Output(BulkIO)中的 PortStatistics 结构体的一个实例。该结构体包含了从这个连接收集的统计信息。数据速率的衡量单位是每秒比特数。
要显示每秒千兆比特的数量,请运行以下命令:print source._ports[0]._get_statistics()[0].statistics.bitsPerSecond/1e9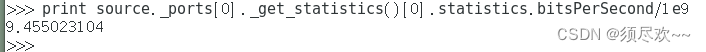
得到的值是两个组件之间测量的数据传输速率。可以通过输入以下内容来查看当前的 xfer_length 属性:source.xfer_length
默认值是 100000。通过运行以下命令将属性更新为 200000:source.xfer_length = 200000通过重复调用 _get_statistics() 来检查新的数据速率。结果显示的数据速率现在已经发生了变化。
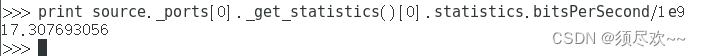
我的qq:2442391036,欢迎交流!