MYDB
- 0. 项目结构
- 0.1 引用计数缓存框架
- 为什么不使用LRU
- 引用计数缓存
- 缓存框架实现
- 0.2 共享内存数组
- 1. 事务管理器--TM
- 1.1 XID 文件
- XID 规则
- XID 文件结构
- 读取方式
- 事务状态
- 1.2 代码实现
- 2. 数据管理器--DM
- 2.1 页面缓存
- 页面结构
- 页面缓存
- 数据页管理
- 第一页
- 普通页
- 2.2 日志文件
- 3. 版本管理器--VM
- 4. 索引管理器--IM
- 5. 表管理器--TBM
0. 项目结构
- 原项目博客地址
- MYDB 分为后端和前端,前后端通过 socket 进行交互。
- 前端(客户端)读取用户输入,并发送到后端执行,输出返回结果,并等待下一次输入。
- 后端需要解析 SQL,如果是合法的 SQL,就尝试执行并返回结果。
- 后端划分为五个模块,每个模块都又一定的职责,通过接口向其依赖的模块提供方法。
五个模块如下:
- Transaction Manager(TM,事务管理器)
- Data Manager(DM,数据管理器)
- Version Manager(VM,版本管理器)
- Index Manager(IM,索引管理器)
- Table Manager(TBM,表管理器)
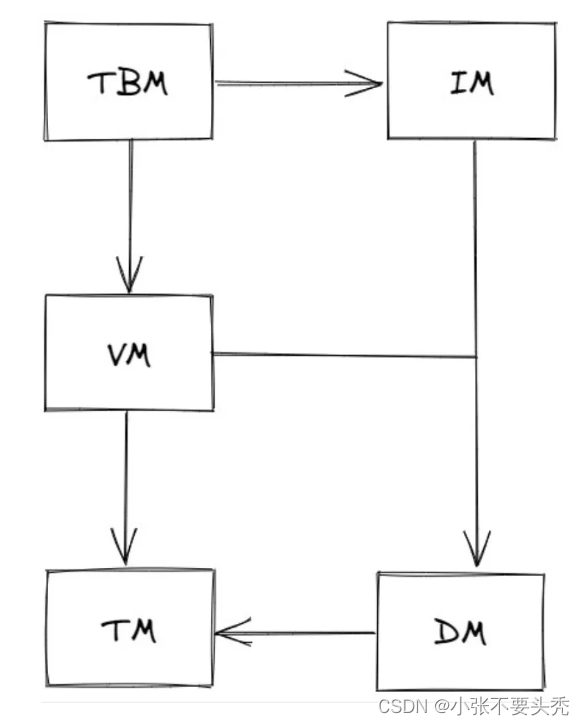
实现顺序:TM–>DM–>VM–>IM–>TBM
0.1 引用计数缓存框架
- 数据项管理、分页管理涉及缓存,设计实现更通用的缓存框架
为什么不使用LRU
- LRU 策略中,资源驱逐不可控,上层模块无法感知
- 引用计数缓存只有上层模块主动释放引用,缓存在确保没有模块在使用这个资源的时候,才会驱逐资源
引用计数缓存
- 只有在上层模块主动释放引用,缓存确保没有模块在使用这个资源,才会去驱逐资源。
- 新增release(key)方法,用于释放资源的引用
- 缓存满了之后,引用计数法无法自动释放缓存,直接报错OOM
缓存框架实现
- 定义抽象类AbstractCache< T >,包含两个抽象方法:
- getForCache():资源不在缓存时的获取缓存
- releaseForCache():当资源被驱逐时的写回行为
- 维护一个计数
- 针对多线程场景,记录哪些资源正在从数据源获取中:
- private HashMap<Long, T> cache; // 实际缓存的数据
- private HashMap<Long, Integer> references; // 资源的引用个数
- private HashMap<Long, Boolean> getting; // 正在被获取的资源
- get()方法,用于获取资源,首先要检查getting,死循环获取
- 资源在缓存中,直接返回,引用数 +1
- 资源不在缓存中,如果缓存没满,getting中注册,从数据源中获取资源,使用getForCache()获取,获取完成后删除getting
- release()方法,用于释放缓存,直接references - 1
- 如果已经减到 0,执行回源操作,并删除缓存中所有相关的结构
- close()方法,安全关闭方法,关闭时需要缓存中所有资源强制回源
0.2 共享内存数组
Java中,数组作为对象,以对象形式存储在内存中
- 在 Java 中,当你执行类似 subArray 的操作时,只会在底层进行一个复制,无法同一片内存。
- 因此,Java无法实现共享内存数组,这里单纯松散的规定数组的可使用范围,实现“共享”
- “共享” 是指多个对象引用同一个数组对象,并不是多个对象共享同一片内存
public class SubArray {public byte[] raw;public int start;public int end;public SubArray(byte[] raw, int start, int end) {this.raw = raw;this.start = start;this.end = end;}
}
1. 事务管理器–TM
TM 通过 XID 文件维护事务的状态,并提供接口供其他模块查询某个事务的状态
1.1 XID 文件
XID 规则
- 在 MYDB 中,每个事务都有一个XID,这个 ID 唯一标识了这个事务。
- 事务的 XID 从 1 开始标号,自增不可重复。
- 特殊规定 XID 0 是一个超级事务(Super Transaction)。
- 当一些操作想在没有申请事务的情况进行,那么可以将操作的 XID 设置为 0。
- XID 为 0 的事务的状态永远是committed。
XID 文件结构
- XID 文件头部,保存一个 8 字节的数字,记录这个 XID 文件管理的事务的个数。
- XID 文件给每个事务分配了一个字节的空间,用来保存其状态。
- 某个事务 xid 在文件中的状态就存储在 (xid-1)+8 字节处,Super XID 的状态不记录。
读取方式
- 采用 NIO 方式 的 FileChannel
事务状态
- activate,正在进行,尚未结束
- committed,已提交
- absorted,已撤销(回滚)
1.2 代码实现
- 在构造函数创建了一个 TransactionManager 之后,首先要对 XID 文件进行校验,以保证这是一个合法的 XID 文件。
- 校验方式:通过文件头的 8 字节数字反推文件的理论长度,与文件的实际长度做对比。如果不同则认为 XID 文件不合法。
- 对于校验没有通过的,会直接通过 panic 方法,强制停机。
- 在一些基础模块中出现错误都会如此处理,无法恢复的错误只能直接停机。
create方法:创建事务管理器
public static TransactionManagerImpl create(String path) {File f = new File(path + TransactionManagerImpl.XID_SUFFIX);try {if (!f.createNewFile()) {// 文件已存在Panic.panic(Error.FileExistsException);}} catch (IOException e) {Panic.panic(e);}if (!f.canRead() || !f.canWrite()) {// 文件不可读或不可写Panic.panic(Error.FileCannotRWException);}FileChannel fc = null;RandomAccessFile raf = null;try {raf = new RandomAccessFile(f, "rw");fc = raf.getChannel();} catch (IOException e) {Panic.panic(e);}// 写空XID文件头ByteBuffer buf = ByteBuffer.wrap(new byte[TransactionManagerImpl.LEN_XID_HEADER_LENGTH]);try {fc.position(0);fc.write(buf);} catch (IOException e) {Panic.panic(e);}return new TransactionManagerImpl(raf, fc);
}
open方法:开启事务管理器
public static TransactionManagerImpl open(String path) {File f = new File(path + TransactionManagerImpl.XID_SUFFIX);if (!f.exists()) {Panic.panic(Error.FileNotExistsException);}if (!f.canRead() || !f.canWrite()) {Panic.panic(Error.FileCannotRWException);}FileChannel fc = null;RandomAccessFile raf = null;try {raf = new RandomAccessFile(f, "rw");fc = raf.getChannel();} catch (FileNotFoundException e) {Panic.panic(e);}return new TransactionManagerImpl(raf, fc);}
begin方法:开启事务
// 开启一个事务 并返回xid
public long begin() {counterLock.lock();try {long xid = xidCounter + 1;updateXID(xid, FIELD_TRAN_ACTIVE);incrXIDCounter();return xid;} finally {counterLock.unlock();}
}
commit方法:提交事务
// 提交事务
@Override
public void commit(long xid) {updateXID(xid, FIELD_TRAN_COMMITTED);
}
abort方法:回滚事务
// 回滚事务
@Override
public void abort(long xid) {updateXID(xid, FIELD_TRAN_ABORTED);
}
2. 数据管理器–DM
DM 直接管理数据库 DB 文件和日志文件
- 上层模块和文件系统之间的一个抽象层,向下直接读写文件,向上提供数据包装
- 日志功能
主要职责:
- 分页管理 DB 文件,并进行缓存
- 管理日志文件,保证在发生错误时,可以根据日志进行恢复
- 抽象 DB 文件为 DataItem 供上层模块使用,并提供缓存
2.1 页面缓存
页面结构
- 存储在内存中的页面,与已经持久化到磁盘的抽象页面有区别
- 设置默认数据页大小定位8K
- 脏页面是指已经被修改但尚未写回磁盘的数据库页
public class PageImpl implements Page{private int pageNumber; // 页面页号,页号从1开始private byte[] data; // 实际包含的字节数据private boolean dirty; // 是否是脏页面,脏页面需要被写回磁盘private Lock lock;// 用来方便在拿到 Page 的引用时可以快速对这个页面的缓存进行释放操作private PageCache pc;
}
页面缓存
- 页面缓存接口
public interface PageCache {int newPage(byte[] initData); // 新增页面Page getPage(int pgno) throws Exception; // 获取页数// 抽象缓存框架中定义的方法void close(); // 关闭缓存,写回所有资源void release(Page page); // 释放缓存void truncateByPgno(int maxPgno); // 根据页号截断缓存int getPageNumber(); // 获取当前打开的数据库文件页数void flushPage(Page pg); // 刷回数据源
}
- 页面缓存实现类,需要继承抽象缓存框架,实现getForCache() 和 releaseForCache() 抽象方法
- 由于数据源就是文件系统,getForCache() 直接从文件中读取,并包裹成 Page 即可
- releaseForCache() 驱逐页面时,也只需要根据页面是否是脏页面,来决定是否需要写回文件系统
@Override
protected Page getForCache(long key) throws Exception {// 数据源就是文件系统 直接从文件中读取,并包裹成 Pageint pgno = (int) key;long offset = PageCacheImpl.pageOffset(pgno);ByteBuffer buf = ByteBuffer.allocate(PAGE_SIZE);fileLock.lock();try {fc.position(offset);fc.read(buf);} catch (IOException e) {Panic.panic(e);}fileLock.unlock();return new PageImpl(pgno, buf.array(), this);
}
private static long pageOffset(int pgno) {// 页号从 1 开始return (pgno-1) * PAGE_SIZE;
}// ===========================================@Override
protected void releaseForCache(Page pg) {if (pg.isDirty()) {flush(pg);pg.setDirty(false);}
}
- PageCache 还使用了一个 AtomicInteger,来记录了当前打开的数据库文件有多少页。
- 这个数字在数据库文件被打开时就会被计算,并在新建页面时自增。
@Override
public int newPage(byte[] initData) {// 打开时计算,新增页面时自增int pgno = pageNumbers.incrementAndGet();Page pg = new PageImpl(pgno, initData, null);flush(pg); // 新建的页面需要立刻写回文件系统return pgno;
}
数据页管理
数据库文件的第一页通常用作一些特殊用途,比如存储一些元数据,启动检查等
第一页
- MYDB第一页只用来做启动检查
- 每次数据库启动时,会生成一串随机字节,存储在 100 ~ 107 字节。在数据库正常关闭时,会将这串字节,拷贝到第一页的 108 ~ 115 字节。
- 这样数据库在每次启动时,就会检查第一页两处的字节是否相同,以此来判断上一次是否正常关闭。如果是异常关闭,就需要执行数据的恢复流程。
// 启动时设置初始字节
public static void setVcOpen(Page pg) {pg.setDirty(true);setVcOpen(pg.getData());
}
private static void setVcOpen(byte[] raw) {System.arraycopy(RandomUtil.randomBytes(LEN_VC), 0, raw, OF_VC, LEN_VC);
}// 关闭时拷贝字节
public static void setVcClose(Page pg) {pg.setDirty(true);setVcClose(pg.getData());
}
private static void setVcClose(byte[] raw) {System.arraycopy(raw, OF_VC, raw, OF_VC + LEN_VC, LEN_VC);
}// 校验字节
public static boolean checkVc(Page pg) {return checkVc(pg.getData());
}
private static boolean checkVc(byte[] raw) {return Arrays.equals(Arrays.copyOfRange(raw, OF_VC, OF_VC + LEN_VC), Arrays.copyOfRange(raw, OF_VC + LEN_VC, OF_VC + 2 * LEN_VC));
}
普通页
Free Space Offset(自由空间偏移量)通常用于数据库管理系统中的页分配和管理。在数据库中,数据通常存储在页(Page)中,每个页都有固定大小的存储空间。自由空间偏移量表示了一个页中空闲空间开始的位置,即从该偏移量开始的位置可以用来存储新的数据。当向页中插入新的数据时,数据库系统会根据当前的自由空间偏移量来确定新数据的存储位置,并更新自由空间偏移量以反映已使用的空间。
对普通页的管理,基本都是围绕着对 FSO 进行的
- 开头 2 字节无符号数,表示这一页的空闲位置的偏移 FSO
- 剩下的部分都是实际存储的数据
// 向页面插入数据
// 将raw插入pg中,返回插入位置
public static short insert(Page pg, byte[] raw) {pg.setDirty(true);short offset = getFSO(pg.getData()); // 获取到FSO// 将 raw 中的内容复制到 pg.getData() 中 offset 开始的地方System.arraycopy(raw, 0, pg.getData(), offset, raw.length);setFSO(pg.getData(), (short)(offset + raw.length));return offset;
}/*recoverInsert()和recoverUpdate()用于在数据库崩溃后重新打开时,恢复例程直接插入数据以及修改数据使用*/// 将raw插入pg中的offset位置,并将pg的offset设置为较大的offset
public static void recoverInsert(Page pg, byte[] raw, short offset) {pg.setDirty(true);System.arraycopy(raw, 0, pg.getData(), offset, raw.length);short rawFSO = getFSO(pg.getData());if(rawFSO < offset + raw.length) {setFSO(pg.getData(), (short)(offset + raw.length));}
}// 将raw插入pg中的offset位置,不更新update
public static void recoverUpdate(Page pg, byte[] raw, short offset) {pg.setDirty(true);System.arraycopy(raw, 0, pg.getData(), offset, raw.length);
}
2.2 日志文件
- MYDB 提供了崩溃后的数据恢复功能。
- DM 层在每次对底层数据操作时,都会记录一条日志到磁盘上。
- 在数据库奔溃之后,再次启动时,可以根据日志的内容,恢复数据文件,保证其一致性。
3. 版本管理器–VM
VM 基于两段锁协议实现调度序列的可串行化,并实现 MVCC ,实现两种隔离级别
4. 索引管理器–IM
IM 实现了基于 B+ 树的索引,BTW,目前只支持已索引字段
5. 表管理器–TBM
TBM 实现对字段和表的管理。同时,解析 SQL 语句,并根据语句操作表